Программно-определяемые СХД: сравниваем 7 решений
В этой статье я кратко расскажу о программно-определяемых хранилищах (Software-Defined Storage, SDS) и о возможностях их применения, которые они дают при построении ИТ-инфраструктуры. В конце статьи вас ждет сравнение семи SDS-решений. Я протестировал их, когда мы с коллегами из «Онланты» прорабатывали варианты развития инфраструктуры облака OnCloud.ru. Надеюсь, что сравнительная таблица сэкономит вам кучу времени и сил при выборе продукта.

Источник
Я работаю системным инженером группы облачной интеграции компании «Онланта». Одно из направлений моей деятельности — это исследовательские работы (R&D) по изучению и сравнению новых технологий, которые могли бы помочь нам повысить качество и снизить стоимость облачных услуг OnCloud.ru, предоставляемых «Онлантой». С результатами такого сравнения SDS-решений вы познакомитесь в этой статье.
Тренд к снижению стоимости владения ИТ-инфраструктурой
В крупных организациях системы хранения данных занимают значительную долю стоимости ИТ-инфраструктуры (по оценкам специалистов – до 25%). Эта цифра может существенно вырасти. Причины – рост объема данных и увеличение потребности в емкостях систем хранения данных (СХД), в том числе из-за законов, которые обязывают эти данные хранить. В то же время компании активно стараются экономить ИТ-бюджеты, что вынуждает их находиться в постоянном поиске наиболее выгодных технологических решений, которые бы позволили сократить эти расходы не в ущерб качеству сервиса. Это же относится к хранению и обработке данных.
Требования заказчиков к снижению стоимости владения ИТ-инфраструктурой заставляют поставщиков инвестировать в разработки и предлагать новые технологии. Одна из них — программно-определяемые системы хранения данных (Software-Defined Storage, SDS). Компании начинают задумываться о внедрении SDS, когда процедуры работы с данными становятся неэффективными и их поиск отнимает много времени.

Источник
Концепция SDS позволяет получить такие преимущества, как:
Когда и зачем нужна SDS
ПО управления СХД должно обеспечивать гибкую организацию хранения данных, а также:
SDS определяют в Storage Networking Industry Association (SNIA, Ассоциация производителей и потребителей систем хранения) как виртуализированную среду хранения данных с интерфейсом управления сервисами, которая должна включать в себя:
Сравниваем SDS-решения
Software-Defined Storage предлагают многие вендоры:
Условно все SDS-решения можно разделить на три категории:
Решения архитектурно строятся по двум принципам:
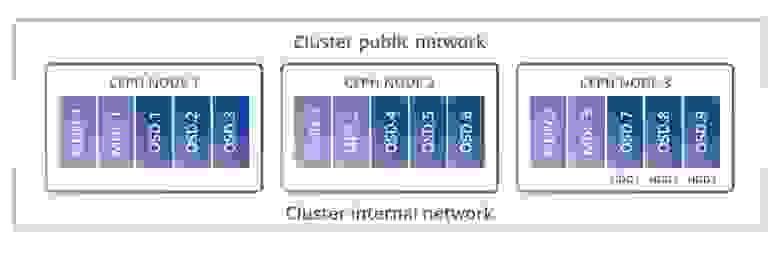
В системах без общих элементов данные записываются на один узел, а потом с заданной периодичностью копируются на другие для обеспечения отказоустойчивости. При этом записи не являются транзакционными. Такой подход наиболее дешев. Чаще всего в качестве интерконнекта в нем используется Ethernet. Данная архитектура удобна с точки зрения масштабируемости. Яркий ее представитель — CEPH.
Сейчас многие компании занимаются разработкой как программной SDS (например, Atlantis Computing, Maxta, StarWind, DataCore Software, Sanbolic, Nexenta, CloudByte), так и выпуском комплексных решений (Dell EMC, IBM) или специализированных устройств (Tintri, Nimble, Solidfire).

Из наиболее известных на рынке мы выбрали для сравнения семь решений, которые интереснее всего для задач «Онланты». Это:
Инструмент будущего
Технология SDS начала развиваться еще в начале 2000-х, но пока не смогла заменить классические СХД по целому ряду причин — сейчас мы их обсуждать не будем. Но производители активно занимаются развитием своих продуктов и интерес к технологиям SDS растет. По нашим оценкам, в ближайшее время они станут тем инструментом, который позволит сокращать стоимость ИТ-инфраструктуры при росте потребности в увеличении емкости СХД.

В заключение отмечу, что в настоящем материале я не пытался предложить варианты выбора подходящего для вас решения. Такое решение нужно выбирать, исходя из нагрузки, SLA и т.д. В предлагаемой таблице сравниваются лишь возможности решений, и не сравниваются производительность, скорость репликации, время переключения нод и др. Т.е. это именно сравнительный анализ возможностей, а не продуктивное тестирование.
После тщательного знакомства с продуктами SDS мы пришли к выводу, что в текущей своей реализации под наши задачи они подходят не очень хорошо. Для себя мы все же выбрали классическое решение, внедрением которого мы в данный момент занимаемся, и о чём, возможно, в ближайшее время вам расскажем.
Но надеюсь, что представленные результаты сравнения помогут вам сориентироваться, сэкономят время и облегчат задачу выбора, какое решение подходит в вашем случае.
Если кто-то из читателей сочтёт возможным поделиться какой-либо дополнительной информацией по обсуждаемому предмету, а возможно, и рассказать о своем выборе, было бы очень интересно.
Краткое сравнение архитектуры SDS или поиск подходящей платформы хранения (GlusterVsCephVsVirtuozzoStorage)
Данная статья написана для того, чтобы помочь выбрать для себя подходящее решение и понять отличия между такими SDS как Gluster, Ceph и Vstorage (Virtuozzo).
В тексте используются ссылки на статьи с более детальным раскрытием тех или иных проблем, поэтому описания будут максимально краткими с использованием ключевых моментов без лишней воды и вводной информации, которую вы сможете при желании самостоятельно добыть на просторах интернета.
На самом деле конечно затронутые темы требуют тоны текста, но в современном мире все больше и больше люди не любят много читать))), поэтому можно бегло прочесть и сделать выбор, а если что непонятно пройтись по ссылкам или погуглить непонятные слова))), а эта статья как прозрачная обертка для этих глубоких тем, показывающая начинку – главные ключевые моменты каждого решения.
Gluster
Начнем с Gluster, который активно используется у производителей гиперконвергентных платформ с SDS на базе open source для виртуальных сред и его можно найти на сайте RedHat в разделе storage, где предлагается выбрать из двух вариантов SDS: Gluster или Ceph.
Gluster состоит из стека трансляторов – службы которые выполняют все работы по распределению файлов и т.д. Brick – служба которая обслуживает один диск, Volume – том(пул) – который объединяет эти brick’и. Далее идет служба распределения файлов по группам за счет функции DHT(distributed hash table). Службу Sharding включать в описание не будем так как в ниже выложенных ссылках будет описание проблем связанных с ней.

При записи файл целиком ложится в brick и его копия параллельно пишется на brick на втором сервере. Далее второй файл уже будет записываться в вторую группу из двух briсk(или более) на разных серверах.
Если файлы примерно одного размера и том будет состоять только из одной группы, то все нормально, но вот при других условиях возникнут из описаний следующие проблемы:
Эти выводы также связаны с описанием опыта использования Gluster и при сравнении с Ceph, а также есть описание опыта к приходу понимания этой более производительной и более надежной конфигурации “Replicated Distributed”.
В картинке показано распределение нагрузки при записи двух файлов, где копии первого файла раскладываются по трем первым серверам, которые объединены в volume 0 группу и три копии второго файла ложатся на вторую группу volume1 из трех серверов. Каждый сервер имеет один диск.
Общий вывод такой, что использовать можно Gluster, но с пониманием того, что в производительности и отказоустойчивости будут ограничения, которые создают трудности при определенных условиях гиперконвергентного решения, где ресурсы нужны еще и для вычислительных нагрузок виртуальных сред.
Есть некоторые также показатели производительности Gluster, которых можно добиться при определенных условиях ограничиваясь в отказоустойчивости.
Теперь рассмотрим Сeph из описаний архитектуры, которые мне удалось найти. Также есть сравнение между Glusterfs и Ceph, где можно сразу понять что Ceph желательно разворачивать на отдельных серверах, так как его сервисам необходимы все ресурсы железа при нагрузках.
Архитектура Сeph более сложнее чем Gluster и есть такие сервисы как службы метаданных, но весь стек компонентов довольно непрост и не очень гибок для использования его в решении с виртуализацией. Данные укладываются по блокам, что выглядит более производительным, но есть в иерархии всех служб(компонентов), потери и latency при определенных нагрузках и аварийных условиях в пример следующая статья.
Из описания архитектуры сердцем выступает CRUSH, благодаря которому выбирается место для размещения данных. Далее идет PG — это наиболее сложная абстракция (логическая группа) для понимания. PG нужны для того, чтобы CRUSH был более эффективным. Основное предназначение PG — группировка объектов для снижения ресурс-потребления, повышения производительности и масштабируемости. Адресация объектов на прямую, по отдельности, без объединения их в PG была бы очень затратной. OSD – это сервис для каждого отдельного диска.
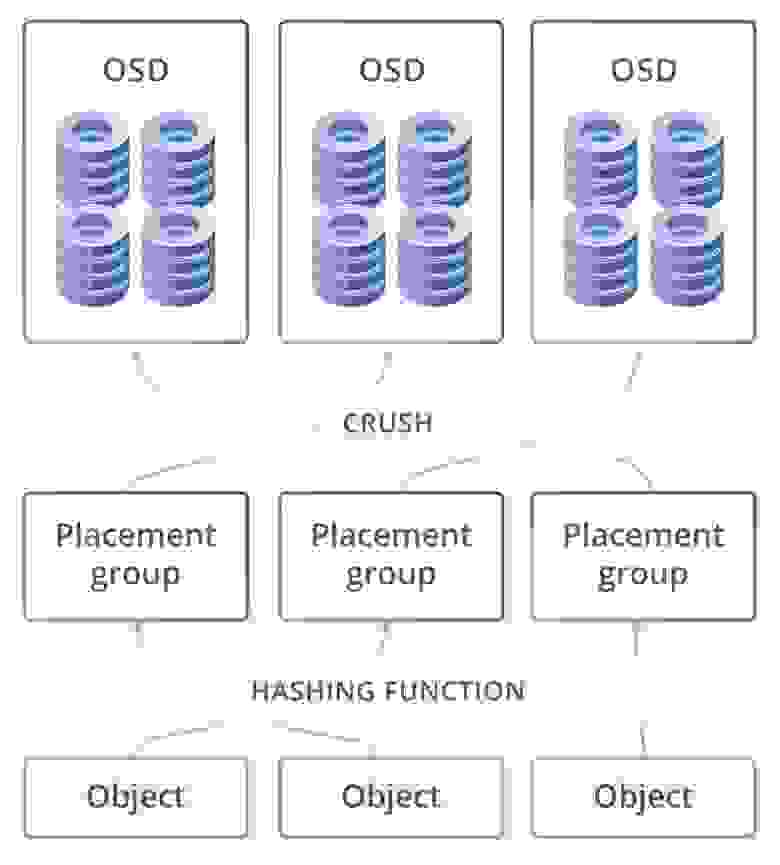
Кластер может иметь один или много пулов данных разного назначения и с разными настройками. Пулы делятся на плейсмент-группы. В плейсмент-группах хранятся объекты, к которым обращаются клиенты. На этом логический уровень заканчивается, и начинается физический, потому как за каждой плейсмент-группой закреплен один главный диск и несколько дисков-реплик (сколько именно зависит от фактора репликации пула). Другими словами, на логическом уровне объект хранится в конкретной плейсмент-группе, а на физическом — на дисках, которые за ней закреплены. При этом диски физически могут находиться на разных узлах или даже в разных датацентрах.
В этой схеме плейсмент-группы выглядят как необходимый уровень для гибкости всего решения, но в тоже время и как лишнее звено в этой цепочки, что невольно наводит мысли о потери производительности. Например при записи данных системе необходимо разбивать их на эти группы и потом на физическом уровне на главный диск и на диски для реплик. То есть Хеш функция работает при поиске и вставке объекта, но есть побочный эффект – это очень большие затраты и ограничения на перестройку хэша (при добавлении, удалении диска). Ещё одна проблема хэша – это чётко прибитое расположение данных, которые нельзя менять. То есть если как-то диск испытывает повышенную нагрузку, то система не имеет возможности не писать на него (выбрав другой диск), хеш функция обязывает располагать данные по правилу, независимо от того насколько диску плохо, поэтому Ceph ест много памяти при перестроении PG в случае self-healing или увеличения хранилища. Вывод, что Ceph работает хорошо(хоть и медленно), но только когда нет масштабирования, аварийных ситуаций и обновления.
Есть конечно варианты повышения производительности за счет кеширования и кеш-тиринга, но при этом необходимо хорошее железо и все равно будут потери. Но в целом Ceph выглядит заманчивее чем Gluster для продуктива. Также при использовании этих продуктов необходимо учитывать немаловажный фактор – это высокий уровень компетенций, опыта и профессионализма с большим акцентом на linux, так как очень важно все правильно развернуть, настроить и поддерживать, что накладывает еще больше ответственности и нагрузки на администратора.
Vstorage
Еще более интереснее выглядит архитектура у Virtuozzo storage(Vstorage), которую можно использовать совместно с гипервизором на тех же узлах, на том же железе, но очень важно правильно все сконфигурировать, чтобы добиться хорошей производительности. То есть развернув такой продукт с коробки на какой попало конфигурации без учета рекомендаций в соответствии с архитектурой будет очень легко, но не производительно.
Что же может сосуществовать для хранения рядом с сервисами гипервизора kvm-qemu, а это всего лишь несколько служб, где найдена компактная оптимальная иерархия компонентов: сервис клиента монтируемый через FUSE(модифицированный, не open source), служба метаданных MDS (Metadata service), служба блоков данных Chunk service, которая на физическом уровне равна одному диску и на этом все. По скорости конечно оптимально использовать отказоустойчивую схему в две реплики, но если задействовать кеширование и журналы на диски SSD, то помехоустойчивое кодирование (erase coding или raid6) можно прилично разогнать на гибридной схеме или даже лучше на all flash. С EC(erase coding) некоторый минус: при изменении одного блока данных необходимо пересчитать суммы четности. Для обхода потерь на эту операцию Сeph пишет в EC отложено и проблемы с производительностью могут произойти при определенном запросе, когда например понадобятся считать все блоки, а в случае с Virtuozzo Storage запись измененных блоков осуществляется используя подход “log-structured file system”, что минимизирует затраты на вычисления четности. Чтобы прикинуть приблизительно варианты с ускорением работы при EC и без, есть калькулятор. – цифры можно получить приблизительные зависит от коэффициента точности производителя оборудования, но результат вычислений хорошо помогает запланировать конфигурацию.
Простая схема компонентов хранения это не значит, что эти компоненты не поглощают ресурсы железа, но если подсчитать все расходы заранее, то можно рассчитывать на совместную работу рядом с гипервизором.
Есть схема сравнения потребления ресурсов железа службами Сeph и Virtuozzo storage.
Если ранее сравнивать Gluster и Ceph можно было по старым статьям, используя самые важные строки из них, то с Virtuozzo сложнее. Статей по этому продукту не так много и информацию можно черпать только с документации на английском или на русском если рассматривать Vstorage в качестве хранилища используемого в некоторых гиперконвергентных решениях в таких компаниях как Росплатформа и Акронис.
Попробую помочь с описанием этой архитектуры поэтому текста будет чуть больше, но чтобы самому разобраться в документации необходимо много времени, а имеющуюся документацию можно использовать только как справочник с помощью пересмотра оглавления или поиск по ключевому слову.
Рассмотрим процесс записи в гибридной конфигурации железа с выше описанными компонентами: запись начинает идти на тот узел с которого ее инициировал клиент(служба точки монтирования FUSE), но компонент мастер службы метаданных(MDS) конечно направит клиента на прямую к нужному чанк сервису(службе хранения блоков CS), то есть MDS не участвует в процессе записи, а просто направляет на необходимый чанк сервис. В общем можно привести аналогию записи с разливом воды по бочкам. Каждая бочка, это блок данных в 256МБ.
То есть один диск, это какое-то количество таких бочек, то есть объем диска разделить на 256МБ. Каждая копия разливается на один узел, вторая почти параллельно уже на другой узел и т.д… Если у нас три реплики и есть SSD диски, для кеша (под чтение и журналы записи), то подтверждение записи будет происходить после записи журнала в SSD, а параллельный сброс с SSD, будет продолжаться на HDD, как бы в фоновом режиме. В случае трех реплик коммит записи будет после подтверждения от SSD третьего узла. Может показаться, что сумму скорости записи трех SSD можно поделить на три и мы получим скорость записи одной реплики, но запись копий идет параллельно и скорость Latency сети обычно выше, чем у SSD, и по сути производительность записи будет зависеть от сети. В связи с этим, чтобы увидеть реальные IOPS необходимо правильно нагрузить весь Vstorage по методике, то есть тестировать реальную нагрузку, а не память и кэш, где необходимо учесть правильный размер блока данных, количество потоков и т.д.
Выше упомянутый журнал записи на SSD, работает так, что как только в него попадают данные, то сразу считываются службой и пишутся на HDD. Служб метаданных (MDS) несколько на кластер и их количество определяется кворумом, который работает по алгоритму Paxos. С точки зрения клиента точка монтирования FUSE, это папка кластерного хранилища, которая одновременно видна всем нодам кластера, каждая нода имеет смонтированного клиента по такому принципу поэтому каждому узлу доступно это хранилище.
Для производительности любого из выше описанного подхода очень важно, на этапе планирования и развертывания, правильно настроить сеть, где будет балансировка за счет агрегации и правильно подобранная пропускная способность сетевого канала. В агрегации важно правильно подобрать режим хеширования и размеры фреймов. Есть также очень сильное отличие от выше описанных SDS, это fuse с технологией fast path в Virtuozzo Storage. Который по мимо модернизированного fuse в отличие от остальных open source решений, значительно прибавляет IOPS-ов и позволяет не ограничиваться горизонтальным или вертикальным масштабированием. В общем по сравнению с выше описанными архитектурами эта выглядит более мощнее, но за такое удовольствие конечно же необходимо покупать лицензии в отличии от Сeph и Gluster.
Подводя итоги можно подчеркнуть топом из трех: первое место по производительности и надежности архитектуры занимает Virtuozzo Storage, второе Ceph и третье Gluster.
Критерии, по которому выбран Virtuozzo Storage: это оптимальный набор компонентов архитектуры, модернизированный под этот подход Fuse с fast path, гибкий набор конфигурации железа, меньшее потребление ресурсов и возможность совместного использования с compute(вычислениями/виртуализации), то есть полностью подходит для гиперконвергентного решения, в составе которого он и идет. Второе место Ceph, потому что это более производительная архитектура перед Gluster, за счет оперирования блоками, а также более гибкими сценариями и возможностью работы в более масштабных кластерах.
В планах есть желание написать сравнение между vSAN, Space Direct Storage, Vstorage и Nutanix Storage, тестирование Vstorage на оборудовании HPE, Huawei, а также сценарии интеграции Vstorage с внешними аппаратными СХД, поэтому если статья вам понравилась, то неплохо было бы получить от вас отзывы, которые могли бы усилить мотивацию на новые статьи с учетом ваших замечаний и пожеланий.
Обзор функционала SDS




Время просмотра: 4.4 мин.
Локальная сеть как транспорт
Быстрая скорость передачи данных и низкие задержки всегда были на стороне SAN вообще и Fibre Channel в частности. Но с появлением доступных 10 Гбит/с Ethernet-коммутаторов стало возможным использовать ЛВС для передачи данных между сервером и хранилищем на сравнимых с SAN скоростях. Производители SAN-коммутаторов и HBA (Host Bus Adapter) даже предприняли попытку создания конвергентных решений, использующих Ethernet для транспорта FC.
Другие статьи автора
Статьи по теме
Поделиться
А с увеличением скоростей Ethernet вплоть до 100 Гбит/с и появлением таких расширений протокола, как iWARP и RoCE, даже для чувствительных к задержкам приложений скорость доступа к SSD-накопителю в соседнем сервере по сети стала сравнимой (а порой даже равной) скорости доступа к локальным накопителям, подключенным к PCIe-шине.
Программно-определяемые СХД получили возможность стать распределенными по множеству узлов, теперь можно на порядок увеличить объемы хранилища без ущерба для производительности. И если раньше (в пределах сервера) точкой отказа был диск, то теперь быстрая сеть позволяет рассматривать сервер целиком (или блейд-шасси, или даже всю стойку) как потенциально сбойный компонент с соответствующей защитой.
Серверы с внутренними дисками как узлы распределенного хранилища
Появление же таких технологий, как NVMe, NVMe over Fabrics, вместе с ростом объемов SSD-накопителей до HDD позволит и вовсе отказаться от использования дисковых массивов. Таким образом, запросы самых требовательных по скорости и задержкам приложений будут удовлетворены программно-определяемой СХД.
При этом смешивание в SDS устройств хранения с различными характеристиками (например, NVDIMM, NVMe и HDD) с помощью многоуровневого хранения данных решает проблему избытка емкости при нехватке скорости (и наоборот).
Характеристики типовых SDS
Объектное хранение данных и масштабируемость
Большинство программно-определяемых СХД, в первую очередь, представляют собой объектное хранилище, позволяющее по названию объекта получить его содержимое. Преимуществом такого подхода является отсутствие необходимости (либо значительное упрощение) индексирования содержимого. При заранее известном количестве узлов СХД нахождение объекта устанавливается путем хэширования его названия и, грубо говоря, деления результата на количество узлов. Полученный остаток от деления и будет указывать на ноду, содержащую искомый объект. Подобный подход позволяет равномерно распределять данные между множеством узлов хранения без создания узких мест вроде выделенных серверов метаданных. При необходимости хранения объектов большого размера их можно делить на блоки фиксированной длины, распределяя эти блоки между всеми узлами СХД.
Иногда объектное хранилище используется для предоставления блочных устройств или файловых систем. И то, и другое будет преобразовано в объекты с распределением между всеми узлами СХД. Здесь нужно отметить, что блочный/файловый доступ для объектного хранилища – это все-таки дополнительный уровень абстракции и не основной функционал. В некоторых объектных хранилищах их нет вовсе, где-то этот функционал только развивается.
Erasure Coding вместо RAID
Для защиты от выхода из строя устройства хранения или целиком узла в программно-определяемых СХД обычно используются 2 механизма – репликация данных между несколькими узлами (обычно хранятся 2 или 3 копии данных) и Erasure Coding. Репликация обеспечивает лучшую производительность, но ценой кратного сокращения полезного дискового пространства. Например, при защите от одновременного выхода из строя двух узлов полезная дисковая емкость составит всего 33% от «сырой».
Erasure Coding представляет собой математический алгоритм генерации из K исходных блоков данных M блоков избыточной информации таким образом, что исходные данные могут быть восстановлены из K любых получившихся блоков. При M=1 и M=2 получаются конструкции, похожие на RAID5 и RAID6 соответственно. При M=3 (и K=7, например) система защищается от одновременного выхода из строя трех узлов, при этом полезная дисковая емкость составит уже 70% от «сырой», в отличие от 33% при 3-кратной репликации.
Как репликация, так и кодирование в программно-определяемых СХД обычно реализованы таким образом, что данные распределяются по всем узлам СХД независимо от кратности репликации или соотношения K/M. Из-за этого восстановление избыточности при выходе узла из строя происходит не на выделенный spare-диск (это долго и с дисками больше 4 ТБ может быть опасным), а на свободное пространство всех оставшихся узлов. В итоге время восстановления сокращается во много раз.
Адаптивная производительность
Ранее приходилось вручную рассчитывать размер каждого уровня многоуровневого хранилища, но сейчас появляются технологии, позволяющие на основе декларативных требований к скорости и надежности хранения автоматически размещать данные на нужном количестве узлов и носителей. В будущем приложения будут запрашивать у СХД необходимые ресурсы без вовлечения в процесс человека.
Также некоторые программно-определяемые СХД могут «запоминать» последовательности обращения к разным данным в разное время и переносить на быстрый уровень данные, которые скоро понадобятся, в том объеме, в котором они понадобятся. Это позволяет удешевить СХД, храня на быстром уровне не весь объем «горячих» данных, а лишь его часть (необходимую сейчас и в течение ближайшего времени) без существенного влияния на производительность.
Хранилище для облачного века
Драйвером развития программно-определяемых СХД можно считать Amazon Web Services с его хранилищем S3 (Simple Storage Services), появившимся в 2006–2007 годах. S3 – это распределенное объектное хранилище, доступное поверх протокола HTTP. В настоящий момент S3-интерфейс стал де-факто стандартом для работы с объектами и поддерживается практически всеми объектными хранилищами других вендоров.
Популярность S3 обусловлена его гипермасштабируемостью – буквально в масштабах интернета. Это то, что требуется поколению приложений, запускаемых в облаке, – отделенное от самого приложения, доступное из любого уголка интернета, надежное, быстрое, безопасное и недорогое хранилище. Масштабирование облачного приложения заключается в увеличении или уменьшении количества его запущенных экземпляров, при этом хранилище его данных масштабируется автоматически при возросшем или уменьшившемся количестве запросов.
Составляющие стоимости
Идея создания SDS обычно приходит в ответ на требование о снижении стоимости хранилища. Но здесь есть подводные камни.
Для возможности быстрого восстановления избыточности при выходе из строя каких-либо компонент требуются, как минимум, 10 Гбит/с сетевые соединения. Поэтому в определенных конфигурациях предпочтительнее создать даже выделенную межузловую сеть, чтобы снизить влияние ребалансировки на клиентские запросы. Но зачастую в имеющейся инфраструктуре порты доступа только гигабитные, и стоимость модернизации участка сети с добавлением 10 Гбит/с коммутаторов может ощутимо увеличить общую стоимость программно-определяемой СХД. Особенно в случае приверженности к дорогим сетевым брендам.
Серверы и диски
С выбором серверов все довольно просто: они в значительной мере уже стали потребительским товаром, их стоимость у разных производителей примерно одинаковая. Но есть 2 нюанса.
Первый – серверов нужно много (десятки, если не сотни), и даже в минимальной конфигурации их стоимость может оказаться больше стоимости дисков. Одним из решений проблемы является размещение приложений на тех же серверах, что «участвуют» в СХД. В некоторых конфигурациях приложение от этого только выиграет, получив возможность читать данные с локального хранилища без использования сетевой передачи.
Второй нюанс – многие производители серверов ревниво относятся к установке в них «чужеродных» дисков. Некоторые прямо это запрещают, другие просто не продают салазки для установки дисков в слоты отдельно от самих дисков. Все бы ничего, но подобная наценка на диски в 100, 200 и более % удорожает хранилище в разы. Другими словами, если ваша цель – сделать SDS максимально дешевой, то диски (и, возможно, серверы) должны приобретаться у лояльных к этому компаний.
Программное обеспечение
Большинство ПО, позволяющего создавать программно-определяемые СХД, является коммерческим. Многие программы по факту являются «швейцарскими ножиками», способными организовать и объектное, и блочное, и файловое хранилища, причем сразу по нескольким протоколам. Здесь стоит сказать несколько слов о рынке производителей этого ПО. Часть компаний-стартаперов в сфере SDS были приобретены ИТ-гигантами, и теперь их продукты поставляются только в виде комплексных решений вместе с оборудованием. Другие договорились о партнерстве с производителями серверов, которые тоже стали предлагать комплексные решения на своем оборудовании. Часть коммерческих решений пока еще относительно свободна, но сложность используемых технологий и статус амбициозного стартапа не добавляют нам уверенности в их надежности. По стоимости же все коммерческое ПО ориентировано на решение широкого спектра задач, и дешевое хранилище в него не входит.
Некоммерческого ПО не так много, и оно обычно менее функционально по сравнению с коммерческим. Но здесь вполне можно найти хорошее решение под конкретную задачу, даже с возможностью поддержки от вендора. Таким образом, вы гарантируете себе низкую стоимость хранилища вместе с отсутствием жесткой привязки к конкретному производителю (как ПО, так и железа).
Решаемые задачи
Хранилище как услуга
Для организации хранилища в виде услуги СХД должна обеспечивать базовые функции:
Среди классических СХД подобные решения придется поискать. В SDS же эти функции обычно заложены изначально, либо они несложно реализуются.
Гиперконвергентные системы
В случае если программное решение занимает не один сервер (с виртуализацией или без) и ему требуются внушительные дисковые емкости, программно-определяемая СХД позволяет сократить общую стоимость системы. К тому же использование SDS позволит масштабировать приложение и хранилище, добавляя (удаляя) узлы с необходимым количеством вычислительных или дисковых ресурсов.
Облачное хранилище для облачных приложений
Облачное приложение – в первую очередь мобильное и масштабируемое. Хранилище для него должно быть соответствующим – доступным для приложения из любой точки его запуска, масштабируемым, без явных узких мест. Яркий пример – контейнеры. Все данные контейнерного приложения располагаются во внешнем хранилище, которое либо доступно приложению по сети, либо динамически подключается к контейнеру при его запуске. Современные программно-определяемые СХД успешно справляются с такими задачами, так как, по сути, для них и создавались.
Архивное/холодное хранилище петабайтного масштаба
Дисковый массив на пару петабайт для холодного хранения данных? Он получится «золотым» и будет лишь греть воздух. А через несколько лет стоимость его поддержки станет «платиновой», и будет открыт проект по миграции данных на новый «золотой» массив. Файловая система подобного объема после сбоя сервера будет проверяться не один день, при этом хранилище будет недоступно.
Объектное программно-определяемое хранилище на таких объемах выходит значительно дешевле классических СХД. С помощью Erasure Coding (12+6, например) достигается необходимая отказоустойчивость (показатель сохранности данных – 99,9999999999999%). А при распределении этих данных между тремя и более ЦОД отключение одного из них не вызовет недоступности СХД. При этом отсутствуют недостатки классической репликации в виде кратного дублирования дискового пространства.
Хранилище для СРК
Производители СРК уже включили поддержку объектных хранилищ в свои продукты. И Veritas NetBackup, и CommVault Simpana научились работать с хранилищами как по протоколу S3, так и по специальным протоколам отдельных объектных хранилищ.
Технологии SDS как нельзя лучше подходят для создания систем холодного/архивного хранения данных, например архивов медиа-контента, записей переговоров в call-центрах, записей систем видеонаблюдения, почтовых архивов и т.д. Одним словом, использование программно-определяемых СХД оптимально, когда речь идет о длительном хранении больших объёмов информации, которые не подвергаются постоянной оперативной обработке, но должны быть легко доступны при необходимости.
Отдельно стоит отметить, что использование программно-определяемого хранилища возможно даже для Oracle ASM с суб-миллисекундным доступом. На стенде в нашей компании мы протестировали конфигурацию программно-определяемой СХД, в которой SSD-диски каждого сервера по выделенной сети были предоставлены остальным серверам в виде блочных устройств. На протестированных дисках разницы между сетевым и локальным обращением к SSD для приложения не было. То есть для Oracle ASM (и Oracle RAC, в частности) с современными объемами SSD-накопителей необязательно покупать разделяемый дисковый массив. Достаточно сделать внутренние диски серверов доступными другим серверам кластера по сети.
Программно-определяемые СХД пока еще кажутся экзотикой, но уже сейчас они позволяют решать большой пул задач – от архивного хранения до высокоскоростной обработки – за меньшие или сопоставимые с использованием классических дисковых массивов деньги. При этом стандартные СХД все еще с трудом выходят за пределы ЦОД, в то время как SDS уже масштабируются до размеров интернета.


