☸️ Первое знакомство с Kubernetes: публикация приложения в интернет

Андрей Трошин

Health check probe
Проверки работоспособности дают кластеру k8s понять, когда с нашим приложением что-то не так и нам нужно зафиксировать это в логах или перезапустить под. Есть два типа проверок: Liveness и Readiness.
Liveness
В этом случае мы определяем работоспособность контейнера. Узнать его состояние можно несколькими способами – это httpGet (запрос HTTP к приложению), tcpSocket (k8s попробует создать соединение на указанный порт вашего приложения) и gRPC (grpc-health-probe). Рассмотрим первые два варианта.
Для приложения с HTTP-сервером определение работоспособности через httpGet выглядит примерно так:
Делается HTTP-запрос к указанным URI и порту (в нашем случае это / на порте 8080). В случае успешного ответа вида 2xx, k8s считает приложение работоспособным. Другой ответ или отсутствие такового говорит о том, что контейнер отключен и его нужно перезапустить.
Если приложение не умеет обрабатывать HTTP-запросы, можно использовать проверку через tcpSoket:
Если TCP-соединение будет успешным, k8s считает приложение работоспособным.
Readiness
С технической точки зрения эта проверка похожа на предыдущую. Разница в том, что если мы не проходим Liveness, то под с нашим приложением уходит в перезагрузку, а в случае с провалом Readiness он блокируется на Service. На приложение в этом случае не будет направляться трафик.
Описать проверку Readiness можно так:
Внимательный читатель увидит, что разница только в одной строчке.
Ingress
От проверок переходим к объекту Ingress, который организует сетевое взаимодействие с подами (как Service), но прокидывает трафик на доменное имя и позволяет добраться до приложения из Internet. Еще одна его функция – балансировка трафика, при этом в настройках можно указать правила маршрутизации на определенные Service.
Ingress сверху мапится с доменным именем, а снизу – с Service, который обслуживает трафик для подов нашего приложения.
Описать YAML можно так:
В статьях цикла мы сделали следующее:
После публикации приложение в Internet с помощью Ingress архитектурная схема нашего кластера выглядит так:
Liveness probes в Kubernetes могут быть опасны
Прим. перев.: Ведущий инженер из компании Zalando — Henning Jacobs — не раз замечал у пользователей Kubernetes проблемы в понимании предназначения liveness (и readiness) probes и их корректного применения. Посему он собрал свои мысли в эту ёмкую заметку, которая со временем станет частью документации K8s.

Проверки состояния, известные в Kubernetes как liveness probes (т.е., дословно, «тесты на жизнеспособность» — прим. перев.), могут быть весьма опасными. Рекомендую по возможности избегать их: исключениями являются только случаи, когда они действительно необходимы и вы полностью осознаете специфику и последствия их использования. В этой публикации речь пойдет о liveness- и readiness-проверках, а также будет рассказано, в каких случаях стоит и не стоит их применять.
Мой коллега Sandor недавно поделился в Twitter’е самыми частыми ошибками, которые ему встречаются, в том числе связанными с использованием readiness/liveness probes:

Неправильно настроенная livenessProbe может усугубить ситуации с высокой нагрузкой (лавинообразное отключение + потенциально долгий запуск контейнера/приложения) и привести к другим негативным последствиям вроде падения зависимостей (см. также мою недавнюю статью об ограничении числа запросов в связке K3s+ACME). Еще хуже, когда liveness probe сочетается с проверкой здоровья зависимости (health check’ом), в роли которой выступает внешняя база данных: единственный сбой БД перезапустит все ваши контейнеры!
Общий посыл «Не используйте liveness probes» в данном случае помогает мало, поэтому рассмотрим, для чего предназначены readiness- и liveness-проверки.
Примечание: бόльшая часть приведенного ниже теста изначально была включена во внутреннюю документацию для разработчиков Zalando.
Проверки Readiness и Liveness
Kubernetes предоставляет два важных механизма, называемых liveness probes и readiness probes. Они периодически выполняют некоторое действие — например, посылают HTTP-запрос, открывают TCP-соединение или выполняют команду в контейнере, — чтобы подтвердить, что приложение работает должным образом.
Kubernetes использует readiness probes, чтобы понять, когда контейнер готов принимать трафик. Pod считается готовым к работе, если все его контейнеры готовы. Одно из применений этого механизма состоит в том, чтобы контролировать, какие pod’ы используются в качестве бэкендов для сервисов Kubernetes (и особенно Ingress’а).
Liveness probes помогают Kubernetes понять, когда пришло время перезапустить контейнер. Например, подобная проверка позволяет перехватить deadlock, когда приложение «застревает» на одном месте. Перезапуск контейнера в таком состоянии помогает сдвинуть приложение с мертвой точки, несмотря на ошибки, при этом он же может привести к каскадным сбоям (см. ниже).
Если вы попытаетесь развернуть обновление приложения, которое проваливает проверки liveness/readiness, его выкатывание застопорится, поскольку Kubernetes будет ждать статуса Ready от всех pod’ов.
Пример
Вот пример readiness probe, проверяющей путь /health через HTTP с настройками по умолчанию (interval: 10 секунд, timeout: 1 секунда, success threshold: 1, failure threshold: 3):
Рекомендации
Предостережения
Резюме
Дополнительные материалы по теме
Обновление №1 от 2019-09-29
EJ напомнил мне о PDB: одна из бед liveness-проверок — отсутствие координации между pod’ами. В Kubernetes есть Pod Disruption Budgets (PDB) для ограничения числа параллельных сбоев, которое может испытывать приложение, однако проверки не учитывают PDB. В идеале мы можем приказать K8s: «Перезапусти один pod, если его проверка окажется неудачной, но не перезапускай их все, чтобы не сделать еще хуже».
Bryan отлично сформулировал: «Используйте liveness-зондирование, когда точно знаете, что лучшее, что можно сделать, — это «убить» приложение» (опять же, увлекаться не стоит).
Обновление №2 от 2019-09-29
Касаемо чтения документации перед использованием: я создал соответствующий запрос (feature request) на дополнение документации о liveness probes.
Вам (вероятно) нужны liveness и readiness probes
Один из самых частых вопросов, которые мне задают как консультанту это: “В чем разница между liveness и readiness пробами?”. Следующий самый частый вопрос: “Какие из них нужны моему приложению?”.
Любой, кто пробовал за Duck Duck Go-ить этот вопрос знает, что на него непросто найти ответ в интернете. В этой статье, надеюсь, я смогу помочь вам ответить на эти вопросы самостоятельно. Я поделюсь своим мнением о том, каким образом лучше использовать liveness и readiness пробы в приложениях развернутых в Red Hat OpenShift. И я предлагаю не строгий алгоритм, а, скорее, общую схему, которую вы можете использовать для принятия своих собственных архитектурных решений.
Чтобы сделать абстракции более конкретными я предлагаю рассмотреть четыре общих примера приложений. Для каждого из них мы выясним нужно ли нам настраивать liveness и readiness probes, и если нужно, то как. Прежде чем перейти к примерам, давайте ближе посмотрим на эти два разных типа проб.
Примечание: Kubernetes недавно внедрили новую “startup” probe, доступную в OpenShift 4.5 clusters. Вы быстро разберетесь со startup probe, когда поймете liveness и readiness probes. Здесь я не буду рассказывать о startup probes.
Liveness и readiness probes
Liveness (работоспособности) и readiness (готовности) пробы это два основных типа проверок, доступных в OpenShift. Они имеют схожий интерфейс настройки, но разные значения для платформы.
Когда liveness проверка не проходит, то это сигнализирует OpenShift’у, что контейнер мертв и должен быть перезагружен. Когда readiness проверка не проходит, то это опознается OpenShift’ом как то, что проверяемый контейнер не готов к принятию входящего сетевого трафика. В будущем это приложение может прийти в готовность, но сейчас оно не должно принимать трафик.
Далее мы подробнее рассмотрим специфику использования каждой из этих проверок. Как только мы поймем как работает каждая из них, я покажу примеры того, как они работают вместе в OpenShift.
Для чего нужны liveness проверки?
Liveness проверка отправляет сигнал OpenShift’у, что контейнер либо жив (прошел проверку), либо мертв (не прошел). Если контейнер жив, тогда OpenShift не делает ничего, потому что текущее состояние контейнера в порядке. Если контейнер мертв, то OpenShift пытается починить приложение через его перезапуск.
Название liveness проверки (проверка живучести) имеет семантическое значение. По сути проверка отвечает “Да” или “Нет” на вопрос: “Жив ли этот контейнер?”.
Что если я не установил liveness проверку?
Если вы не задали liveness проверку, тогда OpenShift будет принимать решение о перезапуске вашего контейнера на основе статуса процесса в контейнере с PID 1. Процесс с PID 1 это родительский процесс для всех других процессов, которые запущены внутри контейнера. Так как каждый контейнер начинает жить внутри его собственного пространства имен процессов, первый процесс в контейнере берет на себя особенные обязательства процесса с PID 1.
Если ваше приложение это один процесс, и он имеет PID 1, то это поведение по умолчанию может быть именно тем, что вам нужно, и тогда нет необходимости в liveness пробах. Если вы используйте init инструменты, такие как tini или dumb-init, тогда это может быть не то, что вы хотите. Решение о том, задавать ли свои liveness вместо того, чтобы использовать поведение по умолчанию, зависит от специфики каждого приложения.
Для чего нужны readiness пробы?
Сервисы OpenShift используют readiness проверки (проверки готовности) для того, чтобы узнать когда проверяемый контейнер будет готов принимать сетевой трафик. Если ваш контейнер вошел в состояние, когда он все ещё жив, но не может обрабатывать входящий трафик (частый сценарий во время запуска), вам нужно, чтобы readiness проверка не проходила. В этом случае OpenShift не будет отправлять сетевой трафик в контейнер, который к этому не готов. Если OpenShift преждевременно отправит трафик в контейнер, это может привести к тому, что балансировщик (или роутер) вернет 502 ошибку клиенту и завершит запрос, либо клиент получит сообщение с ошибкой “connection refused”.
Как и liveness проверки, название readiness проба (проба готовности) передает семантическое значение. Фактически это проверка отвечает на вопрос: “Готов ли этот контейнер принимать сетевой трафик?”.
Что если я не задам readiness пробу?
Если вы не зададите readiness проверку, OpenShift решит, что контейнер готов к принятию трафика как только процесс с PID 1 запустился. Это никогда не является желаемым поведением.
Принятие готовности без проверки приведет к ошибкам (таким, как 502 от роутера OpenShift) каждый раз при запуске нового контейнера, при масштабировании или развертывании. Без readiness проб вы будете получать пакет ошибок при каждом развертывании, когда старые контейнеры выключаются и запускаются новые. Ели вы используете автоматическое масштабирование, тогда в зависимости от установленного порога метрик новые инстансы могут запускаться и останавливаться в любое время, особенно во время колебаний нагрузки. Когда приложение будет масштабироваться вверх или вниз, вы будете получать пачки ошибок, так как контейнеры, которые не совсем готовы получать сетевой трафик включаются в распределение балансировщиком.
Вы можете легко исправить эти проблемы через задание readiness проверки. Проверка дает OpenShift’у возможность спросить ваш контейнер, готов ли он принимать трафик.
Теперь давайте взглянем на конкретные примеры, которые помогут нам понять разницу между двумя типами проб и то, как важно задать их правильно.
Пример 1: Сервер для отдачи статического контента (Nginx)
Нужны ли liveness пробы?
Приложение запускается быстро и завершается, если обнаружит ошибку, которая не позволит ему отдавать страницы. Поэтому, в данном случае, нам не нужны liveness пробы. Завершенный процесс Nginx означает, что приложение умерло и его нужно перезапустить (отметим, что неполадки, такие как проблемы с SELinux или неправильно настроенные права в файловой системе могут быть причиной выключений Nginx, но перезапуск не исправит их в любом случае).
Нужны ли readiness пробы?
Nginx обрабатывает входящий трафик поэтому нам нужны readiness пробы. Всегда, когда вы обрабатываете сетевой трафик вам нужны readiness пробы для предотвращения возникновения ошибок во время запуска контейнеров, при развертывании или масштабировании. Nginx запускается быстро, поэтому может вам повезет и вы не успеете увидеть ошибку, но мы все ещё хотим предотвратить передачу трафика до тех пор, пока контейнер не придет в готовность, в соответствии с best practice.
Добавление readiness проб для сервера
Здесь настройка проверки для первого примера:
Рис. 2: Реализация сервера Nginx для отдачи статики с настроенными readiness проверками
Пример 2: Сервер заданий (без REST API)
Многие приложения имеют HTTP веб-компонент, а так же компонент выполняющий асинхронные “задания”. Серверу с “заданиями” не нужны readiness проверки, так как он не обрабатывает входящий трафик. Однако, ему в любом случае нужны liveness проверки. Если процесс, выполняющий задания умирает, то контейнер становится бесполезным, и задания будут накапливаться в очереди. Обычно, перезапуск контейнера является правильным решением, поэтому liveness пробы идеальны для такого случая.
Рис. 3: Реализация сервера заданий без liveness проверок.
Я уже упоминал, что этот тип приложений выигрывает от наличия liveness проб, но более детальное пояснение не повредит в любом случае.
Нужны ли нам liveness пробы?
Когда сервер заданий запущен корректно, это будет живой процесс. Если контейнер сервера заданий перестает работать, это скорее всего означает сбой, необработанное исключение или что-то в этом духе. В этом случае настройка проверки будет зависеть от того, запущен ли процесс нашего задания с PID 1.
Однако, в реальной жизни ситуации могут быть сложнее. Например, если наш процесс с заданием получил deadlock, он может все ещё считаться живым, так как процесс запущен, но он определенно в нерабочем состоянии и должен быть перезапущен.
Нужны ли readiness проверки?
В это случае readiness не нужны. Помним, что readiness пробы отправляют OpenShift сигнал о том, что контейнер готов принимать трафик и поэтому может быть добавлен в конфигурацию балансировщика. Так как это приложение не обрабатывает входящий трафик, оно не нуждается в проверке на готовность. Мы можем отключить readiness пробу. Рис. 4 показывает реализацию сервиса заданий с настроенными liveness проверками.
Рис. 4: Реализация сервера заданий с liveness проверками
Пример 3: Приложение с рендерингом на стороне сервера с API
Это пример стандартного приложение рендеринга на стороне сервера SSR: оно отрисовывает HTML-страницы на сервере по востребованию, и отправляет его клиенту. Мы можем собрать такое приложение используя Spring Boot, PHP, Ruby on Rails, Django, Node.js, или любой другой похожий фреймворк.
Нужны ли нам liveness проверки?
Если приложение запускается за несколько секунд или меньше, то liveness проверки, скорее всего, не обязательны. Если запуск занимает больше нескольких секунд, мы должны настроить liveness проверки, чтобы понять, что контейнер инициализировался без ошибок и не произошел сбой.
В этом случае мы могли бы использовать liveness пробы типа exec, которые запускает команду в shell, чтобы убедиться, что приложение по-прежнему работает. Эта команда будет отличаться в зависимости от приложения. Например, если приложение создает PID файл, мы можем проверить, что он все еще жив:
Нужны ли readiness пробы?
Так как данное приложение обрабатывает входящий трафик нам определенно нужны readiness пробы. Без readiness OpenShift немедленно отправит сетевой трафик в наш контейнер после его запуска, независимо от того, готово приложение или нет. Если контейнер начинает отбрасывать запросы, но не завершает работу аварийно, он продолжит получать трафик бесконечно, что, конечно же, не то, что нам нужно.
Мы хотим, чтобы OpenShift удалил контейнер из балансировщика, если приложение перестанет возвращать правильные ответы. Мы можем использовать readiness пробы, подобные этой, чтобы сообщить OpenShift, что контейнер готов к приему сетевого трафика:
Для удобства, вот полный YAML для этого приложения из этого примера:
На рисунке 6 показана схема приложения SSR с настроенными liveness и readiness пробами.
Рис. 6. Приложение SSR с настроенными liveness и readiness пробами.
Пример 4: Собираем все вместе
В конечном, сложном и реалистичном приложении у вас могут быть элементы из всех трех предыдущих примеров. Рассмотрение их по отдельности полезно при анализе работы проб, но также полезно увидеть, как они могут работать вместе для обслуживания большого приложения с миллионами запросов. Этот последний пример объединяет остальные три.
Рис. 7: Реалистичный пример приложения в OpenShift для изучения использования проб.
В примере приложение состоит из трех частей, это контейнеры:
Сервер приложений: Этот сервер предоставляет REST API и выполняет рендеринг на стороне сервера для некоторых страниц. Эта конфигурация широко распространена, поскольку приложения, которые создаются в качестве простых серверов для отрисовки, позже расширяются для обеспечения конечных точек REST API.
Сервер для отдачи статики Nginx: У этого контейнера есть две задачи: он отображает статические ресурсы для приложения (например, ресурсы JavaScript и CSS). И также он реализует завершение TLS-соединений (Transport Layer Security) для сервера приложений, действуя как обратный прокси для определенных URL. Это также широко используемая настройка.
Сервер заданий: этот контейнер не обрабатывает входящий сетевой трафик самостоятельно, но обрабатывает задания. Сервер приложений помещает каждое задание в очередь, где сервер заданий берет его и выполняет. Сервер заданий разгружает сервер приложений, чтобы он мог сосредоточиться на обработке сетевых запросов, а не на обработке длинных заданий.
Приложение также включает в себя несколько сервисов хранения данных:
Реляционная база данных: реляционная база данных будет хранить состояние для нашего приложения. Почти каждое приложение нуждается в какой-либо базе данных, и реляционные являются наиболее предпочтительным выбором.
Наши контейнеры разделены на два пода:
Первый под состоит из нашего сервера приложений и Nginx TLS-прокси или сервера для статики. Это упрощает работу сервера приложений, позволяя ему взаимодействовать напрямую через HTTP. Благодаря расположению в одном поде эти контейнеры могут безопасно и напрямую связываться с минимальной задержкой. Они также могут получить доступ к общему volume space. Эти контейнеры также нужно масштабировать вместе и рассматривать как единое целое, поэтому под является идеальным решением.
Второй под состоит из сервера заданий. Этот сервер необходимо масштабировать независимо от других контейнеров, поэтому он должен находиться в собственном поде. Поскольку весь стейт хранится в базе данных и очереди, сервер заданий может легко получить доступ к необходимым ему ресурсам.
Если вы читали предыдущие примеры, решению здесь вы не удивитесь. Для интеграции мы переключаем сервер приложений на использование HTTP и порта 8080 вместо HTTPS и 8443 для readiness проб. Мы также добавляем liveness пробы на сервер приложений, чтобы прикрыть нас, если сервер приложений не завершает работу в случае ошибки. Таким образом, наш контейнер будет перезапущен Kubelet’ом, когда он «мертв»:
На рисунке 8 показаны полные примеры приложений с обеими настроенными пробами.
Рис. 8: Полный пример приложений с обеими настроенными пробами.
Что насчет одинаковых liveness и readiness проб?
На мой взгляд, хотя этот шаблон используется чересчур часто, в некоторых случаях он имеет смысл. Если приложение начинает некорректно отвечать на HTTP-запросы и, вероятно, никогда не восстановит свою работу без перезапуска, то вы, вероятно, захотите, чтобы OpenShift перезапустил под. Было бы лучше, если бы ваше приложение восстанавливалось само по себе, но это бывает нецелесообразно в реальном мире.
Если у вас есть HTTP endpoint, который может быть исчерпывающим индикатором, вы можете настроить и liveness и readiness пробы на работу с этим endpoint. Используя один и тот же endpoint убедитесь, что ваш под будет перезапущен, если этот endpoint не сможет вернуть корректный ответ.
Финальные мысли
Liveness и readiness пробы отправляют разные сигналы в OpenShift. Каждый имеет свое определенное значение и они не взаимозаменяемы. Не пройденная liveness проверка говорит OpenShift, что контейнер должен быть перезапущен. Не пройденная readiness проба говорит OpenShift придержать трафик от отправки в этот контейнер.
Нет универсального рецепта для проб, потому что “правильный” выбор будет зависеть от того, как написано приложение. Приложению, которое умеет самовосстанавливаться нужна иная настройка от того, которое просто дает сбой и умирает.
Выбирая корректные проверки для приложения я обращаюсь к семантическому смыслу в сочетании с поведением приложения. Зная, что проваленная liveness проба перезапустит контейнер, а проваленная readiness проба удалит его из балансировщика. Обычно это не сложно, определить какие пробы нужны приложению.
Мы рассмотрели реалистичные примеры, но вы можете увидеть значительно более сложные случаи в реальных системах. Для инстанса в сервис-ориентированной архитектуре (SOA), сервис может зависеть от другого сервиса при обработке соединений. Если нисходящий сервис не готов, должен ли проходить readiness проверку восходящий сервис или нет? Ответ зависит от приложения. Вам нужно провести анализ стоимости/преимуществ решения, чтобы определить, что добавочная сложность того стоит.
Визуальное руководство по диагностике неисправностей в Kubernetes
Прим. перев.: Эта статья входит в состав опубликованных в свободном доступе материалов проекта learnk8s, обучающего работе с Kubernetes компании и индивидуальных администраторов. В ней Daniele Polencic, руководитель проекта, делится наглядной инструкцией о том, какие шаги стоит предпринимать в случае возникновения проблем общего характера у приложений, запущенных в кластере K8s.
TL;DR: вот схема, которая поможет вам отладить deployment в Kubernetes:
Блок-схема для поиска и исправления ошибок в кластере. В оригинале (на английском) она доступна в PDF и как изображение.
При развертывании приложения в Kubernetes обычно необходимо определить три компонента:
1) В Kubernetes приложения получают трафик из внешнего мира через два слоя балансировщиков нагрузки: внутренний и внешний.
2) Внутренний балансировщик называется Service, внешний – Ingress.
3) Deployment создает pod’ы и следит за ними (они не создаются вручную).
Предположим, вы хотите развернуть простенькое приложение а-ля Hello World. YAML-конфигурация для него будет выглядеть следующим образом:
Определение довольно длинное, и легко запутаться в том, как компоненты связаны друг с другом.
Связь Deployment’а и Service’а
Вы удивитесь, но Deployment’ы и Service’ы никак не связаны. Вместо этого Service напрямую указывает на Pod’ы в обход Deployment’а.
Таким образом, нас интересует, как связаны друг с другом Pod’ы и Service’ы. Следует помнить три вещи:
1) Представим, что сервис направляет трафик в некий pod:
2) При создании pod’а необходимо задать containerPort для каждого контейнера в pod’ах:
5) Допустим, в контейнере открыт порт 3000. Тогда значение targetPort должно быть таким же.
В YAML-файле лейблы и ports / targetPort должны совпадать:
А как насчет лейбла track: canary в верхней части раздела Deployment? Должен ли он совпадать?
Этот лейбл относится к развертыванию, и не используется сервисом для маршрутизации трафика. Другими словами, его можно удалить или присвоить другое значение.
Он всегда должен совпадать с лейблами Pod’а, поскольку используется Deployment’ом для отслеживания pod’ов.
Предположим, что вы внесли верные правки. Как их проверить?
Проверить лейбл pod’ов можно следующей командой:
Или, если pod’ы принадлежат нескольким приложениям:
Можно подключиться к pod’у! Для этого надо использовать команду port-forward в kubectl. Она позволяет подключиться к сервису и проверить соединение.
Если соединение установить не удалось, значит проблема с лейблами или порты не совпадают.
Связь Service’а и Ingress’а
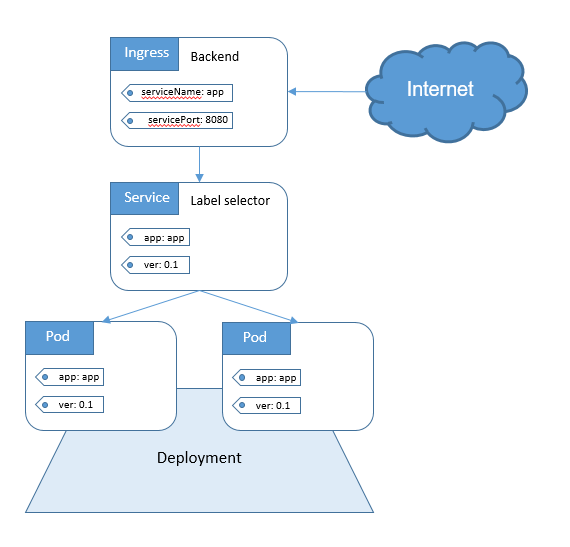
Следующий шаг в обеспечении доступа к приложению связан с настройкой Ingress’а. Ingress должен знать, как отыскать сервис, затем найти pod’ы и направить к ним трафик. Ingress находит нужный сервис по имени и открытому порту.
В описании Ingress и Service должны совпадать два параметра:
1) Как вы уже знаете, Service слушает некий port :
2) У Ingress’а есть параметр, называемый servicePort :
3) Этот параметр ( servicePort ) всегда должен совпадать с port в определении Service:
4) Если в Service задан порт 80, то необходимо, чтобы servicePort также был равен 80:
На практике необходимо обращать внимание на следующие строки:
Как проверить, работает ли Ingress?
Сначала нужно узнать имя pod’а с контроллером Ingress:
Наконец, подключитесь к pod’у:
Теперь каждый раз, когда вы будете посылать запрос на порт 3000 на компьютере, он будет перенаправляться на порт 80 pod’а с контроллером Ingress. Перейдя на http://localhost:3000, вы должны будете увидеть страницу, созданную приложением.
Резюме по портам
Давайте еще раз вспомним о том, какие порты и лейблы должны совпадать:
Что случается, когда что-то идет не так?
Возможно, pod не запускается или он падает.
3 шага для диагностики неисправностей в приложениях в Kubernetes
Прежде чем приступать к отладке deployment’а, необходимо иметь хорошее представление о том, как работает Kubernetes.
Поскольку в каждом выкаченном в K8s приложении имеются три компонента, проводить их отладку следует в определенном порядке, начиная с самого низа.
1) Начинать поиск проблем следует с самого низа. Сперва проверьте, что pod’ы имеют статусы Ready и Running :
2) Если pod’ы готовы ( Ready ), следует выяснить, распределяет ли сервис трафик между pod’ами:
3) Наконец, нужно проанализировать связь сервиса и Ingress’а:
1. Диагностика pod’ов
Как понять, что пошло не так?
Есть четыре полезные команды для диагностики pod’ов:
Дело в том, что нет универсальной команды. Следует использовать их комбинацию.
Типичные проблемы pod’ов
Существует два основных типа ошибок pod’ов: ошибки во время запуска (startup) и ошибки во время работы (runtime).
ImagePullBackOff
Эта ошибка появляется, когда Kubernetes не может получить образ для одного из контейнеров pod’а. Вот три самых распространенных причины этого:
CrashLoopBackOff
Она выводит сообщения об ошибках из предыдущей реинкарнации контейнера.
RunContainerError
Эта ошибка возникает, когда контейнер не в состоянии запуститься. Она соответствует моменту до запуска приложения. Обычно ее причиной является неправильная настройка, например:
Pod’ы в состоянии Pending
Почему такое происходит?
Вот возможные причины (я исхожу из предположения, что планировщик работает нормально):
Pod’ы не в состоянии Ready
2. Диагностика сервисов
Сервисы занимаются маршрутизацией трафика к pod’ам в зависимости от их лейблов. Поэтому первое, что нужно сделать — проверить, сколько pod’ов работают с сервисом. Для этого можно проверить endpoint’ы в сервисе:
Если раздел Endpoins пуст, возможны два варианта:
Как проверить работоспособность сервиса?
Независимо от типа сервиса, можно использовать команду kubectl port-forward для подключения к нему:
3. Диагностика Ingress
Если вы дочитали до этого места, то:
Это означает, что, скорее всего, неправильно настроен контроллер Ingress. Поскольку контроллер Ingress является сторонним компонентом в кластере, существуют различные методы отладки в зависимости от его типа.
Но прежде чем прибегнуть к помощи специальных инструментов для настройки Ingress’а, можно сделать нечто совсем простое. Ingress использует serviceName и servicePort для подключения к сервису. Необходимо проверить, правильно ли они настроены. Сделать это можно с помощью команды:
Если столбец Backend пуст, высока вероятность ошибки в конфигурации. Если бэкэнды на месте, но доступа к приложению по-прежнему нет, то проблема может быть связана с:
Наконец, подключитесь к pod’у:
Теперь все запросы на порт 3000 на компьютере будут перенаправляться на порт 80 pod’а.
Работает ли он теперь?
Существует много разновидностей контроллеров Ingress. Самыми популярными являются Nginx, HAProxy, Traefik и др. (подробнее о существующих решениях см. в нашем обзоре — прим. перев.) Следует воспользоваться руководством по устранению неполадок в документации соответствующего контроллера. Поскольку Ingress Nginx является самым популярным контроллером Ingress, мы включили в статью несколько советов по решению связанных с ним проблем.
Отладка контроллера Ingress Nginx
У проекта Ingress-nginx имеется официальный плагин для kubectl. Команду kubectl ingress-nginx можно использовать для:
Резюме
Диагностика в Kubernetes может оказаться непростой задачей, если не знать, с чего начать. К проблеме всегда следует подходить по принципу «снизу-вверх»: начинайте с pod’ов, а затем переходите к сервису и Ingress’у. Методы отладки, описанные в статье, могут применяться и к другим объектам, таким как:


