Rdd spark что это
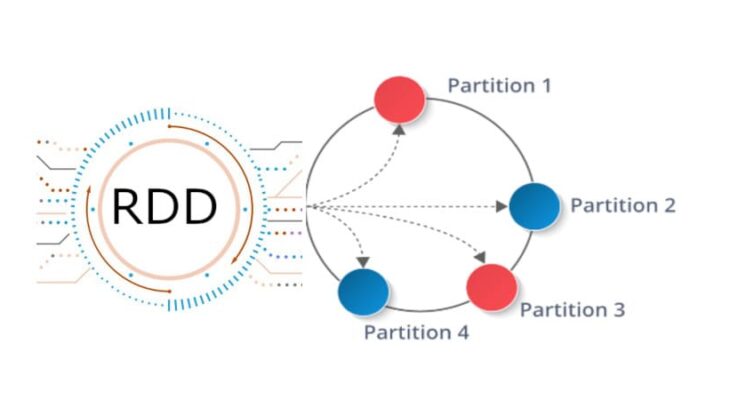
RDD (Resilient Distributed Dataset) – это простая, неизменяемая, распределенная коллекция объектов во фреймворке Apache Spark. RDD представляет собой распределенный набор данных, который делится на множество частей, обрабатывающихся различными узлами в кластере. Наборы РДД могут содержать объекты с любыми типами данных на языках Python, JAVA или Scala [1].
Как устроен RDD: свойства и структура
RDD – это разновидность датасета (простого набора данных), который разделен на множество машин, работающих в кластере.
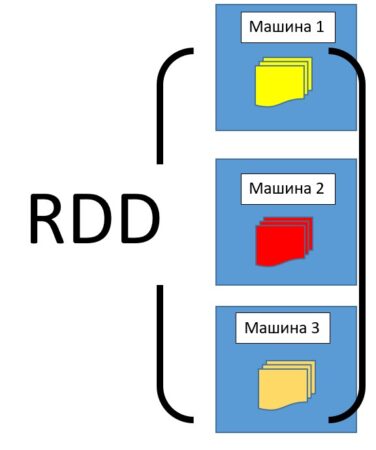 Структура RDD
Структура RDD
RDD имеет следующие свойства:
RDD можно создавать вручную, а можно загружать из внешних источников. Источниками хранения РДД могут служить следующие источники:
Как появился RDD: краткая история Apache Spark
Работа над структурой RDD началась в 2009 году. Это было связано с идеей проекта для распределенной работы с данными – Apache Spark. Таким образом, наборы РДД стали неотъемлемой частью Spark, автором которого является румынско-канадский ученый в области информатики Матей Захария.
В 2010 году проект был опубликован под лицензией BSD (Berkeley Software Distribution), а уже в 2013 году передан фонду Apache и переведен на лицензию Apache 2.0. В 2014 году был принят в число проектов верхнего уровня Apache [2].
Основными достоинствами RDD считают отказоустойчивость и ленивые вычисления, благодаря которым возрастает скорость работы с данными, и уменьшается риск потери данных при выходе из строя одного из составляющих кластерного оборудования.
Apache Spark: что там под капотом?
Вступление
Небольшая предыстория:
Spark — проект лаборатории UC Berkeley, который зародился примерно в 2009г. Основатели Спарка — известные ученые из области баз данных, и по философии своей Spark в каком-то роде ответ на MapReduce. Сейчас Spark находится под «крышей» Apache, но идеологи и основные разработчики — те же люди.
Spoiler: Spark в 2-х словах
Spark можно описать одной фразой так — это внутренности движка массивно-параллельной СУБД. То есть Spark не продвигает свое хранилище, а живет сверх других (HDFS — распределенная файловая система Hadoop File System, HBase, JDBC, Cassandra,… ). Правда стоит сразу отметить проект IndexedRDD — key/value хранилище для Spark, которое наверное скоро будет интегрировано в проект.Также Spark не заботится о транзакциях, но в остальном это именно движок MPP DBMS.
RDD — основная концепция Spark
Ключ к пониманию Spark — это RDD: Resilient Distributed Dataset. По сути это надежная распределенная таблица (на самом деле RDD содержит произвольную коллекцию, но удобнее всего работать с кортежами, как в реляционной таблице). RDD может быть полностью виртуальной и просто знать, как она породилась, чтобы, например, в случае сбоя узла, восстановиться. А может быть и материализована — распределенно, в памяти или на диске (или в памяти с вытеснением на диск). Также, внутри, RDD разбита на партиции — это минимальный объем RDD, который будет обработан каждым рабочим узлом.
Ну и уже исходя из этого понимания следует Spark рассматривать как параллельную среду для сложных аналитических банч заданий, где есть мастер, который координирует задание, и куча рабочих узлов, которые участвуют в выполнении.
Давайте рассмотрим такое простое приложение в деталях (напишем его на Scala — вот и повод изучить этот модный язык):
Пример Spark приложения (не все включено, например include)
Мы отдельно разберем, что происходит на каждом шаге.
А что же там происходит?
Теперь пробежимся по этой программе и посмотрим что происходит.
Ну во-первых программа запускается на мастере кластера, и прежде чем пойдет какая-нибудь параллельная обработка данные есть возможность что-то поделать спокойно в одном потоке. Далее — как уже наверное заметно — каждая операция над RDD создает другой RDD (кроме saveAsTextFile). При этом RDD все создаются лениво, только когда мы просим или записать в файл, или например выгрузить в память на мастер — начинается выполнение. То есть выполнение происходит как в плане запроса, конвеером, где элемент конвеера — это партиция.
Что происходит с самой первой RDD, которую мы сделали из файла HDFS? Spark хорошо синтегрирован с Hadoop, поэтому на каждом рабочем узле будет закачиваться свое подмножество данных, и закачиваться будет по партициям (которые в случае HDFS совпадают с блоками). То есть все узлы закачали первый блок, и пошло выполнение дальше по плану.
После чтения с диска у нас map — он выполняется тривиально на каждом рабочем узле.
Дальше идет groupBy. Это уже не простая конвеерная операция, а настоящая распределенная группировка. По хорошему, лучше этот оператор избегать, так как пока он реализован не слишком умно — плохо отслеживает локальность данных и по производительности будет сравним с распределенной сортировкой. Ну это уже информация к размышлению.
Давайте задумаемся о состоянии дел в момент выполнения groupBy. Все RDD до этого были конвеерными, то есть они ничего нигде не сохраняли. В случае сбоя, они опять бы вытащили недостающие данные из HDFS и пропустили через конвеер. Но groupBy нарушает конвеерность и в результате мы получим закэшированный RDD. В случае потери теперь мы вынуждены будем переделать все RDD до groupBy полностью.
Чтобы избежать ситуации, когда из-за сбоев в сложном приложении для Spark приходится пересчитывать весь конвеер, Spark позволяет пользователю контролировать кэширование оператором persist. Он умеет кэшировать в память (в этом случае идет пересчет при потере данных в памяти — она может случится при переполнении кэша), на диск (не всегда достаточно быстро), или в память с выбросом на диск в случае переполнения кэша.
После, у нас опять map и запись в HDFS.
Ну вот, теперь более менее понятно что происходит внутри Spark на простом уровне.
А как же подробности?
Например хочется знать как именно работает операция groupBy. Или операция reduceByKey, и почему она намного эфективнее, чем groupBy. Или как работает join и leftOuterJoin. К сожалению большинство подробностей пока легче всего узнать только из исходников Spark или задав вопрос на их mailing list (кстати, рекомендую подписаться на него, если будете что-то серьезное или нестандартное делать на Spark).
Еще хуже с понимаем, что творится в различных коннекторах к Spark. И насколько ими вообще можно пользоваться. Например нам на время пришлось отказаться от идеи интегрироваться с Cassandra из-за их непонятной поддержки коннектора к Spark. Но надежда есть что документация качественная в скором будущем появится.
Обработка больших данных: первые шаги в понимании Hadoop MapReduce и Spark
Big Data как концепт довольно понятна, но из-за того, что она включает в себя множество процессов, сложно сказать, с чего именно нужно начать изучение. Как хранятся файлы? Или как получать эти файлы? А может, сразу — как анализировать данные? О своём опыте работе с Big Data и почему Spark лучше, чем Hadoop MapReduce в обработке данных, рассказывает Эмилия Межекова, ETL-developer в Luxoft.
Мой первый опыт
До 2020 года я, как и большинство Python-девелоперов, работала с привычным стеком Python+Django+РСУБД. В этом стеке для меня было многое понятно. Транзакции, обработка на стороне бэкенда, вывод его на фронтенд к пользователю, как РСУБД хранит данные, как подчищает от мусора, какие существуют трюки для оптимизации поиска данных и подобные вещи.
В 2020-м я получила должность ETL-девелопера (от англ. Extract, Transform, Load) в Luxoft. Изначально название этой позиции мне ни о чём не говорило, я только знала, что это связано с Big Data. Этот термин мне был лишь немного знаком, я никогда не интересовалась данным направлением, и мне казалось, что там очень много математики, графиков, расчёта вероятности и так далее. Как оказалось, в Big Data не только данные большие, но и инфраструктура, и найдутся места, где можно применить свои знания и без математики.
Сейчас я работаю в проекте, занимающемся количественными хедж-фондами — инвестиционными фондами, ориентированными на максимизацию доходности участников. Мы анализируем много данных из разных источников: соцсети, новости, транзакции и так далее. На их основе формируются «сигналы» для принятия решения о продаже или покупке акций. В основном я взаимодействую с фреймворком Spark, он служит для обработки данных (you must be joking!). Сначала я использовала его для манипулирования небольшими файлами и добавления определённой логики, это было довольно просто и понятно. Но когда меня пустили на прод, и файлы стали размером под сотни гигабайтов, а обработка этих файлов занимала всего несколько минут, мне стало интересно, как же шестерёнки крутятся внутри.
Я изучала всё довольно сумбурно. Так как я работала немного с Pandas, то команды Spark не казались сложными, потому что они в чём-то схожи. Я изначально читала про него, но очень часто авторы ссылались на Hadoop MapReduce и внесённые по сравнению с этой моделью улучшения. Поэтому я начала изучать Hadoop MapReduce. В итоге у меня есть представление о том и другом направлении, поэтому я решила рассказать, что лучше подходит для обработки данных.
Структура Big Data

Выше показана экосистема больших данных и примеры инструментов, которые можно использовать для каждой группы. Выглядит устрашающе, но нам нужно разобраться лишь в том, как именно данные обрабатываются, — вернее, рассмотреть два варианта, как это можно сделать с помощью следующих фреймворков: Hadoop MapReduce и Apache Spark.
Hadoop MapReduce и что его окружает
Apache Hadoop — инфраструктура, упрощающая работу с кластерами. Основные элементы Hadoop — это:
распределённая файловая система (HDFS);
метод крупномасштабного выполнения программ (MapReduce).
HDFS — распределённая файловая система Hadoop для хранения файлов больших размеров с возможностью потокового доступа к информации, поблочно распределённой по узлам вычислительного кластера. Здесь мы храним, читаем, записываем и перекладываем данные.
MapReduce — модель распределённых вычислений, представленная компанией Google, используемая для параллельных вычислений над очень большими, вплоть до нескольких петабайт, наборами данных в компьютерных кластерах.
Алгоритм легко понять по аналогии:
Представьте, что вам предложено подсчитать голоса на национальных выборах. В вашей стране 25 партий, 2500 избирательных участков и 2 миллиона граждан. Как это можно сделать? Можно собрать все избирательные бюллетени со всех участков и подсчитать их самостоятельно, либо приказать каждому избирательному участку подсчитать голосов по каждой из 25 партий и передать вам результат, после чего объединить их по партиям.
Ниже представлена схема выполнения данного алгоритма на примере подсчёта слов в выборке.
Разберём, что происходит, по этапам;
Input — входные данные для обработки;
Splitting — разбивка данных на порционные данные;
Mapping — обработка этих порционных данных воркерами (вычислительными процессами) в формате ключ-значение. Для этого алгоритма ключ — слово, значение — количество вхождений данного слова;
Shuffling — ключи сортируются, чтобы упростить обобщение данных и сделать всю работу в одном воркере, не раскидывая их по разным местам;
Reducing — после того, как мы посчитали количество одинаковых слов на каждом отдельном воркере, объединяем их вместе.
Между этапами происходит запись промежуточных данных на диск, воркеры и данные обособлены друг от друга. Данный алгоритм отлично подходит для кластеров. Подсчёт происходит в разы быстрее, чем на одной машине.
Но есть и недостатки, обусловленные архитектурными особенностями этой вычислительной модели:
недостаточно высокая производительность: классическая технология, в частности, реализованная в ядре Apache Hadoop, обрабатывает данные ациклично в пакетном режиме. При этом функции Reduce не запустятся до завершения всех процессов Map. Все операции проходят по циклу чтение-запись с жёсткого диска, что влечёт задержки в обработке информации;
ограниченность применения: высокие задержки распределённых вычислений, приемлемые в пакетном режиме обработки, не позволяют использовать классический MapReduce для потоковой обработки в режиме реального времени повторяющихся запросов и итеративных алгоритмов на одном и том же датасете, как в задачах машинного обучения. Для решения этой проблемы, свойственной Apache Hadoop, были созданы другие Big Data – фреймворки, в частности Apache Spark;
программисту необходимо прописывать код для этапов Map и Reduce самостоятельно.
Apache Spark
В своей работе мне приходится очень часто писать SQL-запросы и смотреть, какие данные приходят на вход и что внутри них хранится. Для этих целей мне хочется, чтобы инструмент был более интерактивным и не приходилось ждать выполнения запроса часами (но скорость зависит от количества данных, естественно). В этом поможет Spark, он работает намного быстрее Hadoop MapReduce.
Spark — инфраструктура кластерных вычислений, сходная с Hadoop MapReduce. Однако Spark не занимается ни хранением файлов в файловой системе, ни управлением ресурсами. Spark обрабатывает данные ещё быстрее с помощью встроенных коллекций RDD (Resilient Distributed Datasets), которые дают возможность выполнять вычисления в больших кластерах. Благодаря RDD можно совершать такие операции, как map, join, reduce, записывать данные на диск и загружать их.
Добавлю таблицу для сравнения Hadoop MapReduce и Spark.
Но как же достигается данное ускорение? Ниже представлены самые значимые решения в архитектуре Spark.
Промежуточные данные вычислений не записываются на диск, а образуют своего рода общую оперативную память. Это позволяет разным рабочим процессам использовать общие переменные и их состояния.
Отложенные вычисления: Spark приступает к выполнению запроса лишь при непосредственном обращении к нему (вывод на экран, запись конечных данных на диск). В этом случае срабатывает планировщик, соединяя все преобразования, написанные ранее.
Из-за некоторых архитектурных особенностей Hadoop MapReduce уступает по скорости Spark. Для своих задач я выбрала Spark, потому что при моём наборе данных и итерациях он работает быстрее. Мне было интересно посмотреть, что было до инструмента, которым я пользуюсь, и каким образом всё развивалось. Это лишь общее описание работы этих фреймворков, дающее немного понять, как всё внутри обрабатывается. Зная, как работает тот и другой алгоритм, вы теперь можете выбрать для себя подходящий.
Rdd spark что это
В прошлый раз мы рассмотрели понятия датафрейм (DataFrame), датасет (DataSet) и RDD в контексте интерактивной аналитики больших данных (Big Data) с помощью Spark SQL. Сегодня поговорим подробнее, чем отличаются эти структуры данных, сравнив их по разным характеристикам: от времени возникновения до специфики вычислений.
Критерии для сравнения структур данных Apache Spark
Прежде всего, определим, по каким параметрам мы будем сравнивать DataFrame, DataSet и RDD. Для этого выделим несколько точек зрения:
Перед тем, как приступить к сравнению RDD, DataFrame и DataSet по вышеперечисленным критериям, отметим разный порядок появления этих структур данных в Apache Spark [1]:
Стоит также сказать, что, начиная с релиза 2.0 (2016 г.), DataSet API можно рассматривать с 2-х позиций: строго типизированный и нетипизированный. Таким образом, концептуально DataFrame является коллекцией универсальных объектов DataSet[Row], где Row – это универсальный нетипизированный JVM-объект. DataSet, напротив, представляет собой набор строго типизированных объектов JVM, определяемых классом в Scala или Java [2].
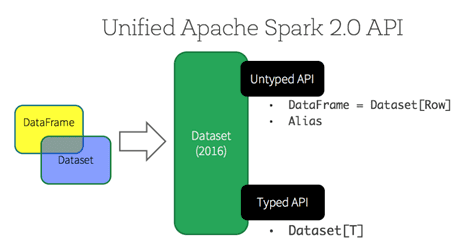 2 типа API Dataset в Apache Spark
2 типа API Dataset в Apache Spark
Данные в RDD, DataFrame и DataSet: представления, форматы и схемы
Начнем с представления данных [1]:
RDD, DataFrame и DataSet по-разному используют схемы данных [1]:
Как реализуются вычисления в Apache Spark
Напомним, сериализация представляет собой процесс перевода данных из формата – структуры, семантически понятной человеку, в двоичное представление для машинной обработки [3]. Это необходимо для хранения объекта на диске или в памяти и его передаче по сети. В этом отношении рассматриваемые структуры данных Apache Spark также отличаются друг от друга:
Таким образом, из-за особенностей сериализации, датасет, датафрейм и распределенная коллекция данных по-разному потребляют память: DataFrame и DataSet обрабатываются быстрее, чем RDD. Это сказывается и при выполнении простых операций группировки и агрегирования. В частности, API RDD выполняет их медленнее. Из-за этого DataFrame оптимально использовать для генерации агрегированной статистики для больших наборов данных, а DataSet – для быстрого выполнения операций агрегации на множестве массивов Big Data [1]. Такая ситуация обусловлена тем, что API-интерфейсы DataFrame и Dataset построены на основе движка Spark SQL, который использует Catalyst для создания оптимизированного логического и физического плана запросов. В этих API-интерфейсах для R, Java, Scala или Python все запросы типов отношений подвергаются одному и тому же оптимизатору кода, обеспечивая эффективность использования пространства и скорости. При том, что строго типизированный API Dataset оптимизирован для задач разработки, нетипизированный набор данных (DataFrame) обрабатывается еще быстрее и подходит для интерактивного анализа [2]. Подробнее про оптимизацию и другую специфику, важную с точки зрения Big Data разработчика, мы поговорим в нашей следующей статье. А о самом SQL-оптимизаторе Catalyst мы рассказываем здесь.
Наконец, поговорим про отложенные (ленивые) вычисления, которые откладываются до тех пор, пока не понадобится их результат. Эти операции реализуются с RDD, DataFrame и DataSet практически одинаково. Например, при работе с RDD результат вычисляется не сразу – вместо этого просто запоминается преобразование, примененное к некоторому базовому набору данных. А само преобразование Spark выполняет только тогда, когда для действия необходимо отправить результат. В DataFrame и DataSet вычисления происходят только тогда, когда появляется действие, к примеру, результат отображения, сохранение вывода [1].
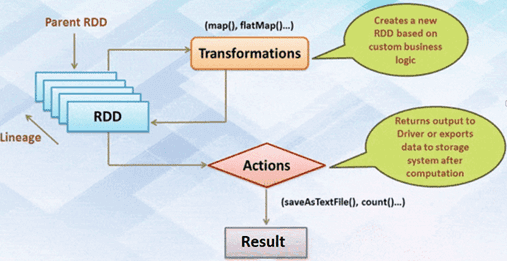 Отложенные (ленивые) вычисления Apache Spark на примере RDD
Отложенные (ленивые) вычисления Apache Spark на примере RDD
Читайте в нашей следующей статье про разницу RDD, DataFrame и DataSet с точки зрения разработчика. А все необходимые знания и реальный опыт прикладной работы с этими структурами больших данных вы приобретете на нашем практическом курсе SPARK2: Анализ данных с Apache Spark в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве.
Знакомство с Apache Spark
Здравствуйте, уважаемые читатели!
Мы наконец-то приступаем к переводу серьезной книги о фреймворке Spark:

Сегодня мы предлагаем вашему вниманию перевод обзорной статьи о возможностях Spark, которую, полагаем, можно с полным правом назвать слегка потрясающей.
Я впервые услышал о Spark в конце 2013 года, когда заинтересовался Scala – именно на этом языке написан Spark. Несколько позже я принялся ради интереса разрабатывать проект из области Data Science, посвященный прогнозированию выживаемости пассажиров «Титаника». Оказалось, это отличный способ познакомиться с программированием на Spark и его концепциями. Настоятельно рекомендую познакомиться с ним всем начинающим Spark-разработчикам.
Сегодня Spark применяется во многих крупнейших компаниях, таких, как Amazon, eBay и Yahoo! Многие организации эксплуатируют Spark в кластерах, включающих тысячи узлов. Согласно FAQ по Spark, в крупнейшем из таких кластеров насчитывается более 8000 узлов. Действительно, Spark – такая технология, которую стоит взять на заметку и изучить.

В этой статье предлагается знакомство со Spark, приводятся примеры использования и образцы кода.
Что такое Apache Spark? Введение
Spark – это проект Apache, который позиционируется как инструмент для «молниеносных кластерных вычислений». Проект разрабатывается процветающим свободным сообществом, в настоящий момент является наиболее активным из проектов Apache.
Spark предоставляет быструю и универсальную платформу для обработки данных. По сравнению с Hadoop Spark ускоряет работу программ в памяти более чем в 100 раз, а на диске – более чем в 10 раз.
Кроме того, код на Spark пишется быстрее, поскольку здесь в вашем распоряжении будет более 80 высокоуровневых операторов. Чтобы оценить это, давайте рассмотрим аналог “Hello World!” из мира BigData: пример с подсчетом слов (Word Count). Программа, написанная на Java для MapReduce, содержала бы около 50 строк кода, а на Spark (Scala) нам потребуется всего лишь:
При изучении Apache Spark стоит отметить еще один немаловажный аспект: здесь предоставляется готовая интерактивная оболочка (REPL). При помощи REPL можно протестировать результат выполнения каждой строки кода без необходимости сначала программировать и выполнять все задание целиком. Поэтому написать готовый код удается гораздо быстрее, кроме того, обеспечивается ситуативный анализ данных.
Кроме того, Spark имеет следующие ключевые черты:
Ядро Spark дополняется набором мощных высокоуровневых библиотек, которые бесшовно стыкуются с ним в рамках того же приложения. В настоящее время к таким библиотекам относятся SparkSQL, Spark Streaming, MLlib (для машинного обучения) и GraphX – все они будут подробно рассмотрены в этой статье. Сейчас также разрабатываются другие библиотеки и расширения Spark.
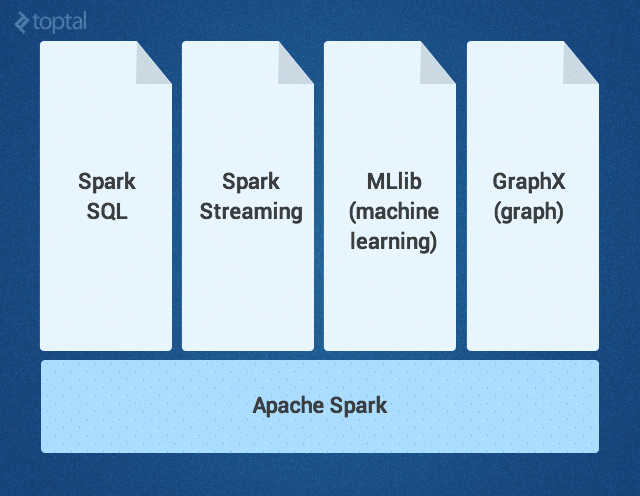
Ядро Spark
Ядро Spark – это базовый движок для крупномасштабной параллельной и распределенной обработки данных. Ядро отвечает за:
Трансформации в Spark осуществляются в «ленивом» режиме — то есть, результат не вычисляется сразу после трансформации. Вместо этого они просто «запоминают» операцию, которую следует произвести, и набор данных (напр., файл), над которым нужно совершить операцию. Вычисление трансформаций происходит только тогда, когда вызывается действие, и его результат возвращается основной программе. Благодаря такому дизайну повышается эффективность Spark. Например, если большой файл был преобразован различными способами и передан первому действию, то Spark обработает и вернет результат лишь для первой строки, а не станет прорабатывать таким образом весь файл.
По умолчанию каждый трансформированный RDD может перевычисляться всякий раз, когда вы выполняете над ним новое действие. Однако RDD также можно долговременно хранить в памяти, используя для этого метод хранения или кэширования; в таком случае Spark будет держать нужные элементы на кластере, и вы сможете запрашивать их гораздо быстрее.
SparkSQL – это компонент Spark, поддерживающий запрашивание данных либо при помощи SQL, либо посредством Hive Query Language. Библиотека возникла как порт Apache Hive для работы поверх Spark (вместо MapReduce), а сейчас уже интегрирована со стеком Spark. Она не только обеспечивает поддержку различных источников данных, но и позволяет переплетать SQL-запросы с трансформациями кода; получается очень мощный инструмент. Ниже приведен пример Hive-совместимого запроса:
Spark Streaming поддерживает обработку потоковых данных в реальном времени; такими данными могут быть файлы логов рабочего веб-сервера (напр. Apache Flume и HDFS/S3), информация из соцсетей, например, Twitter, а также различные очереди сообщений вроде Kafka. «Под капотом» Spark Streaming получает входные потоки данных и разбивает данные на пакеты. Далее они обрабатываются движком Spark, после чего генерируется конечный поток данных (также в пакетной форме) как показано ниже.
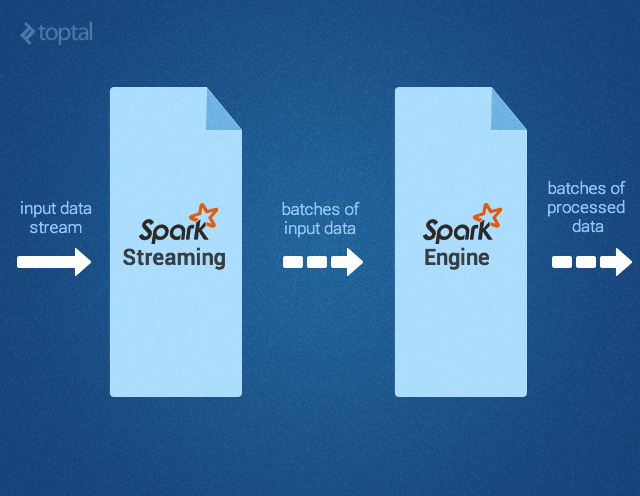
API Spark Streaming точно соответствует API Spark Core, поэтому программисты без труда могут одновременно работать и с пакетными, и с потоковыми данными.
MLlib – это библиотека для машинного обучения, предоставляющая различные алгоритмы, разработанные для горизонтального масштабирования на кластере в целях классификации, регрессии, кластеризации, совместной фильтрации и т.д. Некоторые из этих алгоритмов работают и с потоковыми данными — например, линейная регрессия с использованием обычного метода наименьших квадратов или кластеризация по методу k-средних (список вскоре расширится). Apache Mahout (библиотека машинного обучения для Hadoop) уже ушла от MapReduce, теперь ее разработка ведется совместно с Spark MLlib.
GraphX – это библиотека для манипуляций над графами и выполнения с ними параллельных операций. Библиотека предоставляет универсальный инструмент для ETL, исследовательского анализа и итерационных вычислений на основе графов. Кроме встроенных операций для манипуляций над графами здесь также предоставляется библиотека обычных алгоритмов для работы с графами, например, PageRank.
Как использовать Apache Spark: пример с обнаружением событий
Теперь, когда мы разобрались, что такое Apache Spark, давайте подумаем, какие задачи и проблемы будут решаться с его помощью наиболее эффективно.
Недавно мне попалась статья об эксперименте по регистрации землетрясений путем анализа потока Twitter. Кстати, в статье было продемонстрировано, что этот метод позволяет узнать о землетрясении более оперативно, чем по сводкам Японского Метеорологического Агентства. Хотя технология, описанная в статье, и не похожа на Spark, этот пример кажется мне интересным именно в контексте Spark: он показывает, как можно работать с упрощенными фрагментами кода и без кода-клея.
Во-первых, потребуется отфильтровать те твиты, которые кажутся нам релевантными – например, с упоминанием «землетрясения» или «толчков». Это можно легко сделать при помощи Spark Streaming, вот так:
Затем нам потребуется произвести определенный семантический анализ твитов, чтобы определить, актуальны ли те толчки, о которых в них говорится. Вероятно, такие твиты, как «Землетрясение!» или «Сейчас трясет» будут считаться положительными результатами, а «Я на сейсмологической конференции» или «Вчера ужасно трясло» — отрицательными. Авторы статьи использовали для этой цели метод опорных векторов (SVM). Мы поступим также, только реализуем еще и потоковую версию. Полученный в результате образец кода из MLlib выглядел бы примерно так:
Если процент верных прогнозов в данной модели нас устраивает, мы можем переходить к следующему этапу: реагировать на обнаруженное землетрясение. Для этого нам потребуется определенное число (плотность) положительных твитов, полученных в определенный промежуток времени (как показано в статье). Обратите внимание: если твиты сопровождаются геолокационной информацией, то мы сможем определить и координаты землетрясения. Вооружившись этими знаниями, мы можем воспользоваться SparkSQL и запросить имеющуюся таблицу Hive (где хранятся данные о пользователях, желающих получать уведомления о землетрясениях), извлечь их электронные адреса и разослать им персонализированные предупреждения, вот так:
Другие варианты использования Apache Spark
Потенциально сфера применения Spark, разумеется, далеко не ограничивается сейсмологией.
Вот ориентировочная (то есть, ни в коем случае не исчерпывающая) подборка других практических ситуаций, где требуется скоростная, разноплановая и объемная обработка больших данных, для которой столь хорошо подходит Spark:
В игровой индустрии: обработка и обнаружение закономерностей, описывающих игровые события, поступающие сплошным потоком в реальном времени; в результате мы можем немедленно на них реагировать и делать на этом хорошие деньги, применяя удержание игроков, целевую рекламу, автокоррекцию уровня сложности и т.д.
В электронной коммерции информация о транзакциях, поступающая в реальном времени, может передаваться в потоковый алгоритм кластеризации, например, по k-средним или подвергаться совместной фильтрации, как в случае ALS. Затем результаты даже можно комбинировать с информацией из других неструктутрированных источников данных — например, с отзывами покупателей или рецензиями. Постепенно эту информацию можно применять для совершенствования рекомендаций с учетом новых тенденций.
В финансовой сфере или при обеспечении безопасности стек Spark может применяться для обнаружения мошенничества или вторжений, либо для аутентификации с учетом анализа рисков. Таким образом можно получать первоклассные результаты, собирая огромные объемы архивированных логов, комбинируя их с внешними источниками данных, например, с информацией об утечках данных или о взломанных аккаунтах (см., например, https://haveibeenpwned.com/), а также использовать информацию о соединениях/запросах, ориентируясь, например, на геолокацию по IP или на данные о времени
Итак, Spark помогает упростить нетривиальные задачи, связанные с большой вычислительной нагрузкой, обработкой больших объемов данных (как в реальном времени, так и архивированных), как структурированных, так и неструктурированных. Spark обеспечивает бесшовную интеграцию сложных возможностей – например, машинного обучения и алгоритмов для работы с графами. Spark несет обработку Big Data в массы. Попробуйте – не пожалеете!


