Why marshmallow?В¶
The Python ecosystem has many great libraries for data formatting and schema validation.
In fact, marshmallow was influenced by a number of these libraries. Marshmallow is inspired by Django REST Framework, Flask-RESTful, and colander. It borrows a number of implementation and design ideas from these libraries to create a flexible and productive solution for marshalling, unmarshalling, and validating data.
Here are just a few reasons why you might use marshmallow.
Agnostic.В¶
Marshmallow makes no assumption about web frameworks or database layers. It will work with just about any ORM, ODM, or no ORM at all. This gives you the freedom to choose the components that fit your application’s needs without having to change your data formatting code. If you wish, you can build integration layers to make marshmallow work more closely with your frameworks and libraries of choice (for examples, see Flask-Marshmallow and Django REST Marshmallow).
Concise, familiar syntax.В¶
If you have used Django REST Framework or WTForms, marshmallow’s Schema syntax will feel familiar to you. Class-level field attributes define the schema for formatting your data. Configuration is added using the class Meta paradigm. Configuration options can be overridden at application runtime by passing arguments to the Schema constructor. The dump and load methods are used for serialization and deserialization (of course!).
Class-based schemas allow for code reuse and configuration.В¶
Consistency meets flexibility.В¶
Marshmallow makes it easy to modify a schema’s output at application runtime. A single Schema can produce multiple output formats while keeping the individual field outputs consistent.
In this example, a single schema produced three different outputs! The dynamic nature of a Schema leads to less code and more consistent formatting.
Context-aware serialization.В¶
Marshmallow schemas can modify their output based on the context in which they are used. Field objects have access to a context dictionary that can be changed at runtime.
Here’s a simple example that shows how a Schema can anonymize a person’s name when a boolean is set on the context.
See the relevant section of the usage guide to learn more about context-aware serialization.
Advanced schema nesting.В¶
Most serialization libraries provide some means for nesting schemas within each other, but they often fail to meet common use cases in clean way. Marshmallow aims to fill these gaps by adding a few nice features for nesting schemas :
You can specify which subset of fields to include on nested schemas.
Object serialization and deserialization, lightweight and fluffy.
Donate
Your donation keeps marshmallow healthy and maintained.
Professional support
Professionally-supported marshmallow is available with the Tidelift Subscription.
Quickstart¶
This guide will walk you through the basics of creating schemas for serializing and deserializing data.
Declaring Schemas¶
Let’s start with a basic user “model”.
Create a schema by defining a class with variables mapping attribute names to Field objects.
Creating Schemas From Dictionaries¶
You can create a schema from a dictionary of fields using the from_dict method.
from_dict is especially useful for generating schemas at runtime.
Serializing Objects (“Dumping”)¶
Serialize objects by passing them to your schema’s dump method, which returns the formatted result.
Filtering Output¶
You may not need to output all declared fields every time you use a schema. You can specify which fields to output with the only parameter.
You can also exclude fields by passing in the exclude parameter.
Deserializing Objects (“Loading”)¶
By default, load will return a dictionary of field names mapped to deserialized values (or raise a ValidationError with a dictionary of validation errors, which we’ll revisit later ).
Notice that the datetime string was converted to a datetime object.
Deserializing to Objects¶
Now, the load method return a User instance.
Handling Collections of Objects¶
Set many=True when dealing with iterable collections of objects.
Validation¶
When validating a collection, the errors dictionary will be keyed on the indices of invalid items.
You can perform additional validation for a field by passing the validate argument. There are a number of built-in validators in the marshmallow.validate module.
You may implement your own validators. A validator is a callable that accepts a single argument, the value to validate. If validation fails, the callable should raise a ValidationError with a useful error message or return False (for a generic error message).
Validation occurs on deserialization but not on serialization. To improve serialization performance, data passed to Schema.dump() are considered valid.
You can register a custom error handler function for a schema by overriding the handle_error method. See the Extending Schemas page for more info.
Need schema-level validation? See the Extending Schemas page.
Field Validators as Methods¶
It is sometimes convenient to write validators as methods. Use the validates decorator to register field validator methods.
Required Fields¶
To customize the error message for required fields, pass a dict with a required key as the error_messages argument for the field.
Partial Loading¶
Specifying Defaults¶
missing specifies the default deserialization value for a field. Likewise, default specifies the default serialization value.
Handling Unknown Fields¶
By default, load will raise a ValidationError if it encounters a key with no matching Field in the schema.
This behavior can be modified with the unknown option, which accepts one of the following:
RAISE (default): raise a ValidationError if there are any unknown fields
EXCLUDE : exclude unknown fields
INCLUDE : accept and include the unknown fields
at instantiation time,
The unknown option value set in load will override the value applied at instantiation time, which itself will override the value defined in the class Meta.
This order of precedence allows you to change the behavior of a schema for different contexts.
Validation Without Deserialization¶
“Read-only” and “Write-only” Fields¶
In the context of a web API, the dump_only and load_only parameters are conceptually equivalent to “read-only” and “write-only” fields, respectively.
Specifying Serialization/Deserialization Keys¶
Schemas will (de)serialize an input dictionary from/to an output dictionary whose keys are identical to the field names. If you are consuming and producing data that does not match your schema, you can specify the output keys via the data_key argument.
Implicit Field Creation¶
When your model has many attributes, specifying the field type for every attribute can get repetitive, especially when many of the attributes are already native Python datatypes.
The fields option allows you to specify implicitly-created fields. Marshmallow will choose an appropriate field type based on the attribute’s type.
Let’s refactor our User schema to be more concise.
If instead you want to specify which field names to include in addition to the explicitly declared fields, you can use the additional option.
The schema below is equivalent to above:
Ordering Output¶
Next Steps¶
Need to represent relationships between objects? See the Nesting Schemas page.
Want to create your own field type? See the Custom Fields page.
Need to add schema-level validation, post-processing, or error handling behavior? See the Extending Schemas page.
For example applications using marshmallow, check out the Examples page.
Object serialization and deserialization, lightweight and fluffy.
Donate
Your donation keeps marshmallow healthy and maintained.
Professional support
Professionally-supported marshmallow is available with the Tidelift Subscription.
Строгая десериализация YAML в Python c библиотекой marshmallow
Исходная задача
То есть, проще говоря, нужна функция вида:
И эта функция будет использоваться следующим образом:
Классы конфигурации
Файл config.py выглядит следующим образом:
Вариант, который не работает
Исходная задача встречается часто, не так ли? Значит решение должно быть тривиальным. Просто импортируем стандартную yaml-библиотеку и задача решена?
Делаем импорт PyYaml и вызываем функцию load :
и в результате получим:
Yaml прекрасно загрузился, но в виде словаря. Это не проблема, можно передать словарь как **args в конструктор:
и результатом будет:
Вау! Легко! Но… Подождите-ка. Поле processor это словарь? Черт побери.
Решение, которое требует yaml-теги и почти работает
а код для загрузки так:
И что получится в результате десериализации?
Неплохо. Но теперь yaml-документ наполовину состоит из тегов и потерял читаемость. К тому же, Color по-прежнему читается как строка. Может нужно просто добавить YAMLObject в список родительских классов? Так? Увы, нет. Код
Я не нашел решения этой проблемы за разумное время. К тому же я не хотел добавлять теги к yaml-документу, поэтому продолжил искать другие варианты решения исходной задачи.
Решение с библиотекой marshmallow
и, в результате, получим:
Значит, marshmallow хочет имя enum, а не его значение. Можно немного изменить исходный yaml-документ на:
И, в результате, мы получим идеально десериализованный объект:
Но у меня все еще остается чувство, что можно использовать оригинальный yaml-документ. Я продолжил исследование документации marshmallow и нашел следующие строчки:
Оказывается, можно передать следующую конфигурацию в словарь metadata генератора датакласса field :
И таким образом, мы получим ту самую «магическую» функцию, которая сможет распарсить исходный yaml-документ.
Магическая функция
Теперь мы знаем, как выглядит тело магической функции:
Эта функция может потребовать дополнительной настройки для дата-классов, но решает исходную задачу и не требует наличия тегов в yaml.
Небольшая заметка о ForwardRef
Если определить дата-классы с ForwardRef (строка с именем класса) marshmallow будет озадачена и не сможет распарсить этот класс.
Например, такая конфигурация
И если переместить класс Processor выше, marshmallow потеряет класс Color с аналогичной ошибкой. Так что, по возможности, не используйте ForwardRef для ваших классов, если хотите парсить их с помощью marshmallow.
marshmallow 3.14.1
pip install marshmallow Copy PIP instructions
Released: Nov 15, 2021
A lightweight library for converting complex datatypes to and from native Python datatypes.
Navigation
Project links
Statistics
View statistics for this project via Libraries.io, or by using our public dataset on Google BigQuery
License: MIT License (MIT)
Tags serialization, rest, json, api, marshal, marshalling, deserialization, validation, schema
Requires: Python >=3.6
Maintainers
Classifiers
Project description
marshmallow is an ORM/ODM/framework-agnostic library for converting complex datatypes, such as objects, to and from native Python datatypes.
In short, marshmallow schemas can be used to:
Get It Now
Documentation
Requirements
Ecosystem
A list of marshmallow-related libraries can be found at the GitHub wiki here:
Credits
Contributors
This project exists thanks to all the people who contribute.
You’re highly encouraged to participate in marshmallow’s development. Check out the Contributing Guidelines to see how you can help.
Thank you to all who have already contributed to marshmallow!
Backers
If you find marshmallow useful, please consider supporting the team with a donation. Your donation helps move marshmallow forward.
Thank you to all our backers! [Become a backer]
Sponsors
Support this project by becoming a sponsor (or ask your company to support this project by becoming a sponsor). Your logo will show up here with a link to your website. [Become a sponsor]
Professional Support
Professionally-supported marshmallow is now available through the Tidelift Subscription.
Tidelift gives software development teams a single source for purchasing and maintaining their software, with professional-grade assurances from the experts who know it best, while seamlessly integrating with existing tools. [Get professional support]
Security Contact Information
To report a security vulnerability, please use the Tidelift security contact. Tidelift will coordinate the fix and disclosure.
Project Links
License
MIT licensed. See the bundled LICENSE file for more details.
API REST на Python с Flask, Connexion и SQLAlchemy — урок 2
Содержание
Как отмечалось в комментариях первого урока, структура People переинициализируется каждый раз при перезапуске приложения. В этом уроке вы узнаете, как сохранить структуру People в базе данных и действия, которые предоставляет API, используя SQLAlchemy и Marshmallow.
SQLAlchemy એ предоставляет объектно-реляционную модель (ORM એ ), которая хранит объекты Python для представления данных объекта в базе данных. Это может помочь вам продолжать мыслить в стиле Python и не беспокоиться о том, как данные объекта будут представлены в базе данных.
Marshmallow обеспечивает функциональность для сериализации и десериализации объектов Python по мере их поступления в наш REST API на основе JSON. Marshmallow преобразует экземпляры класса Python в объекты, которые можно преобразовать в JSON.
Мы можете найти код Python для этой статьи здесь.
Для кого этот урок
Если вам понравился первый урок нашего мини‑курса, то здесь вы ещё больше расширите свой арсенал инструментов. Вы будете использовать SQLAlchemy એ для доступа к базе данных, что более соответствует стилю Python, чем прямой SQL. Кроме того, мы будем использовать Marshmallow для сериализации и десериализации данных, управляемых REST API. Для этого мы будем использовать основные функции объектно-ориентированного программирования, доступные в Python.
веб‑приложение, представленное в первом уроке, будет иметь небольшие изменения в файлах HTML и JavaScript для поддержки изменений. Вы можете ознакомиться с окончательной версией кода первого урока здесь.
Дополнительные пакеты
Прежде чем приступить к созданию этой новой функциональности, вам необходимо обновить virtualenv. Мы создали его для выполнения кода первого урока или для создания нового кода для этого проекта. Самый простой способ сделать это после активации virtualenv — выполнить эту команду:
Это добавляет дополнительную функциональность в нашу виртуальну среду virtualenv:
Данные People
Как уже упоминалось выше, структура данных People в предыдущем уроке является словарем Python. В этом словаре мы использовали фамилию человека в качестве ключа поиска. Структура данных выглядела примерно так:
Так как фамилия есть ключ словаря, то ограничивается её изменение — изменить можно только имя. В нашем случае перенос в базу данных позволит изменять не только имя, но и фамилию, поскольку она больше не будет использоваться в качестве ключа для поиска человека.
Концептуально, таблицу базы данных можно рассматривать как двумерный массив, в котором строки являются записями, а столбцы — полями в этих записях.
Таблицы базы данных, обычно, в качестве ключа поиска записей имеют автоинкрементное целочисленное значение. Такое поле называется первичным ключом. Каждая запись в таблице будет иметь первичный ключ, значение которого уникально во всей таблице. Наличие первичного ключа, независимого от данных, хранящихся в таблице, освобождает вас беспокойсва об уникалности значения в любом другом поле записей.
Примечание:
Автоинкрементный первичный ключ означает, что база данных берет на себя заботу:
Согласно теории, сопоставим приведенную выше структуру People единственной в нашей базе данных таблице person :
Описание столбцов таблицы:
Взаимодействие с базой данных
Мы будем использовать SQLite એ в качестве СУБД એ (Системы управления базами данных) для хранения People. SQLite встроена в дистрибутив Python по умолчанию и в мире получила широкое распространение. SQLite использует планарные файлы, что обесечивает высокую скорость обработки, и язык запросов SQL, что подходит для очень многих проектов.
В отличие от алгоритмического программирования, такого как на Python, язык запросов SQL એ не определяет, как получить данные — он определяет какие нужны данные, оставляя «как» по капотом ядра СУБД.
Получение данных таким способом не очень Python‑ническое. Список записей в порядке, но каждая отдельная запись — это просто набор данных. Программа должна знать индекс каждого поля, чтобы получить конкретное поле. Следующий код Python использует SQLite, чтобы продемонстрировать, как выполнить вышеуказанный запрос и отобразить данные:
Программа выше делает следующее:
Переменная people из строки 6 выше будет выглядеть в Python так:
Результат работы программы, записанной выше, выглядит следующим образом:
В приведенной выше программе мы должны знать, что имя человека соответствует полю с индексом 0, а фамилия человека соответствует полю с индексом 1. Хуже того, внутренняя структура person должна также быть известна заранее, всякий раз, когда мы передаём переменную итерации person в качестве параметра функции или методу.
Было бы намного лучше, если бы мы получили объект person в Python, где каждое из полей является атрибутом объекта. Это одна из вещей, которая делает SQLAlchemy.
Маленькие таблички Бобби
В приведенной выше программе оператор SQL представляет собой простую строку, передаваемую непосредственно в базу данных для выполнения. В нашем случае это не проблема, потому что SQL является строковым литералом, полностью находящимся под контролем программы. Однако сценарий использования нашего REST API будет принимать пользовательский ввод из веб‑приложения и использовать его для создания запросов SQL. Это может сделать наше приложение уязвимым для атаки.
Из первой части мы помните, что REST API для получения одного person от People выглядело так:
Приведенный выше фрагмент кода выполняет следующие действия:
Приведенный выше код, для простоты, устанавливает переменную lname в константу, но на самом деле она будет получена из пути конечной точки URL-адреса API и может быть любой, введённой пользователем. SQL запрос, сгенерированный форматированием строки, выглядит так:
Когда этот SQL выполняется базой данных, он ищет в таблице person запись, в которой фамилия равна «Farrell». Это то, что нужно, но любая программа, которая принимает пользовательский ввод, также открыта для злоумышленников. В вышеприведенной программе, где переменная lname задается введенным пользователем вводом, это открывает для нашей программы так называемую SQL‑инъекцию. Это то, что ласково называют «Маленькими табличками Бобби»:
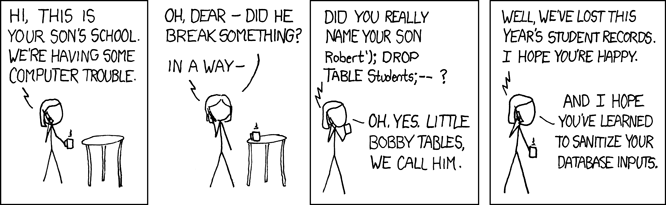
Например, представьте, что злонамеренный пользователь вызвал наш REST API следующим образом:
Приведенный выше запрос REST API устанавливает для переменной lname значение «Farrell»); DROP TABLE person; ‘, что в приведенном выше коде сгенерирует следующий оператор SQL:
Мы можем защитить свою программу, очистив все данные, которые получаем от пользователей нашего приложения. Очистка данных в этом контексте означает, что наша программа должна проверить предоставленные пользователем данные и убедиться, что они не содержат ничего опасного для программы. Это может быть сложно сделать правильно, но должно быть сделано везде, где пользовательские данные взаимодействуют с базой данных.
Есть еще один способ, который намного проще — использовать SQLAlchemy, который будет очищать пользовательские данные перед созданием операторов SQL. Это еще одно большое преимущество и мотив для использования SQLAlchemy при работе с базами данных.
Моделирование данных с SQLAlchemy
В соответствии с принципом инкапсуляции объектно-ориентированного программирования в объекте исвязывается данные с поведением, функциями, которые обработывают эти данными. Создав класс SQLAlchemy, мы можем связать поля из строк таблицы базы данных с поведением, позволяя нам взаимодействовать с данными. Вот определение класса SQLAlchemy для данных в таблице базы данных person :
Остальные определения являются атрибутами уровня класса, определенными следующим образом:
Примечание: метки времени UTC
Источником, или нулевым временем, является линия, проходящая с севера на юг от севера до южного полюса Земли через Великобританию. Это нулевой часовой пояс, от которого смещены все остальные часовые пояса. Используя его в качестве источника нулевого времени, наши временные метки будут смещены относительно этой стандартной контрольной точки.
Если к нашему приложению обращаются из разных часовых поясов, у вас есть способ выполнить вычисления даты/времени. Все, что вам нужно, это метка времени UTC и часовой пояс пункта назначения.
Если бы мы использовали местные часовые пояса в качестве источника меток времени, то мы не могли бы выполнять вычисления даты/времени без информации о смещении часовых поясов по местному времени от нуля. Без информации об источнике отметки времени мы вообще не могли бы сравнивать дату/время или выполнять математические операции.
Работа с временными метками на основе UTC является хорошим примером для подражания. Вот сайт с инструментарием для лучшего понимания и работы с датами и временем.
Но теперь, запишем небольшую программу с SQLAlchemy для выполнения этого запроса:
Использование SQLAlchemy позволяет мыслить с точки зрения объектов, обладающих некоторым поведением, а не с точки зрения простого SQL. Это становится еще более полезным, когда наши таблицы базы данных становятся больше и между ними усложняется взаимосвязь.
Сериализация/Десериализация смоделированных данных
Работа с данными, смоделированными в SQLAlchemy, внутри наших программ очень удобна. Особенно удобно в программах, где данными манипулируют, возможно, делают расчеты или используют их для создания презентаций. Наше приложение представляет собой REST API, по существу, обеспечивающее операции CRUD с данными и поэтому значительных манипуляций с данными оно не выполняет.
API REST работает с форматом JSON для данных и здесь можно столкнуться с проблемой модели SQLAlchemy. Поскольку данные, возвращаемые SQLAlchemy, являются экземплярами класса Python, Connexion не может сериализовать эти экземпляры класса в формате JSON. Помните из первого урока, что Connexion — это инструмент, который мы использовали для разработки и настройки REST API с использованием файла YAML, а так же для подключения к нему методов Python.
В этом контексте сериализация означает преобразование объектов Python, которые могут содержать другие объекты Python и сложные типы данных, в более простые структуры, преобразуемые в JSON. Здесь они перечислены:
Наш класс Person достаточно прост, поэтому получение атрибутов данных из него и создание словаря для возврата из конечных точек REST URL не составит большого труда. В более сложном приложении со многими более крупными моделями SQLAlchemy это было бы не так. Лучшее решение — использовать модуль Marshmallow, который сделает эту работу за вас.
Остальная часть определения выглядит следующим образом:
Создаём и инициализируем базу данных
SQLAlchemy обрабатывает многие взаимодействия, характерные для конкретных баз данных, и позволяет нам сосредоточиться на моделях данных, а также на том, как их использовать.
Теперь, когда мы на самом деле собираемся создать базу данных, то, как уже упоминалось ранее, будем использовать SQLite. Мы делаете это по нескольким причинам. SQLite встроен в дистрибутив Python и него не надо устанавливать, как отдельный модуль. Он сохраняет всю информацию базы данных в одном файле и поэтому прост в настройке и использовании.
Работа с отдельными серверами баз данных, такими, как MySQL или PostgreSQL, будет нормальной, но для этого потребуется установить эти системы и запустить их в работу, но это выходит за рамки нашего урока.
Поскольку SQLAlchemy управляет базой данных, во многих отношениях действительно не имеет значения, что является базовой базой данных.
Здесь мы можете найти исходный код для модулей, которые мы собираетесь создать, которые представлены здесь:
Модуль конфигурации
Хотя программа build_database.py не использует Flask, Connexion или Marshmallow, она использует SQLAlchemy для создания нашего соединения с базой данных SQLite. Вот код для модуля config.py:
Вот что делает приведенный выше код:
Модуль моделей
Модуль models.py создан для предоставления классов Person и PersonSchema в точности так, как описано в разделах выше о моделировании и сериализации данных. Вот код для этого модуля:
Вот что делает приведенный выше код:
Создание базы данных
Мы видели, как таблицы базы данных могут быть сопоставлены с классами SQLAlchemy. Теперь используйте то, что мы узнали, чтобы создать базу данных и заполнить ее данными. Мы собираетесь создать небольшую служебную программу для создания и создания базы данных с данными People. Вот программа build_database.py:
Вот что делает приведенный выше код:
Примечание. В строке 22 данные не были добавлены в базу данных. Все сохраняется в объекте сеанса. Только когда мы выполняете вызов db.session.commit () в строке 24, сеанс взаимодействует с базой данных и фиксирует действия для нее.
В SQLAlchemy сеанс является важным объектом. Он действует как канал связи между базой данных и объектами Python SQLAlchemy, созданными в программе. Сеанс помогает поддерживать согласованность между данными в программе и теми же данными, которые существуют в базе данных. Он сохраняет все действия с базой данных и соответственно обновляет базовую базу данных как явными, так и неявными действиями, предпринимаемыми программой.
Теперь мы готомы запустить программу build_database.py для создания и инициализации новой базы данных. Мы делаете это с помощью следующей команды, когда наша виртуальная среда Python активна:
Когда программа запускается, она выводит сообщения журнала SQLAlchemy на консоль. Это результат установки SQLALCHEMY_ECHO в True в файле config.py. Многое из того, что регистрирует SQLAlchemy, это команды SQL, которые он генерирует для создания и построения файла базы данных SQLite people.db. Вот пример того, что выводится при запуске программы:
Работа с базой данных
Как только база данных будет создана, мы можете изменить существующий код из первого урока, чтобы использовать ее. Все необходимые изменения связаны с созданием значения первичного ключа person_id в нашей базе данных в качестве уникального идентификатора, а не значения lname.
Обновим REST API
Ни одно из изменений не является очень существенным, и мы начнете с переопределения REST API. В приведенном ниже списке показано определение API из первого урока, но оно обновлено для использования переменной person_id в пути URL:


