Хранение данных в кластере Kubernetes
Настроить хранение данных приложений, запущенных в кластере Kubernetes, можно несколькими способами. Одни из них уже устарели, другие появились совсем недавно. В этой статье рассмотрим концепцию трёх вариантов подключения СХД, в том числе самый последний — подключение через Container Storage Interface.

Способ 1. Указание PV в манифесте пода
Типичный манифест, описывающий под в кластере Kubernetes:

Цветом выделены части манифеста, где описано, какой том подключается и куда.
В разделе volumeMounts указывают точки монтирования (mountPath) — в какой каталог внутри контейнера будет монтироваться постоянный том, а также имя тома.
В разделе volumes перечисляют все тома, которые используются в поде. Указывают имя каждого тома, а также тип (в нашем случае: awsElasticBlockStore) и параметры подключения. Какие именно параметры перечисляются в манифесте, зависит от типа тома.
Один и тот же том может быть смонтирован одновременно в несколько контейнеров пода. Таким образом разные процессы приложения могут иметь доступ к одним и тем же данным.
Этот способ подключения придумали в самом начале, когда Kubernetes только зарождался, и на сегодня способ устарел.
При его использовании возникает несколько проблем:
Всё это очень неудобно, поэтому в реальности подобным способом пользуются для подключения только некоторых специальных типов томов: configMap, secret, emptyDir, hostPath:
configMap и secret — служебные тома, позволяют создать в контейнере том с файлами из манифестов Kubernetes.
emptyDir — временный том, создаётся только на время жизни пода. Удобно использовать для тестирования или хранения временных данных. Когда pod удаляется, том типа emptyDir тоже удаляется и все данные пропадают.
hostPath — позволяет смонтировать внутрь контейнера с приложением любой каталог локального диска сервера, на котором работает приложение, — в том числе /etc/kubernetes. Это небезопасная возможность, поэтому обычно политики безопасности запрещают использовать тома этого типа. Иначе приложение злоумышленника сможет замонтировать внутрь своего контейнера каталог /etc/kubernetes и украсть все сертификаты кластера. Как правило, тома hostPath разрешают использовать только системным приложениям, которые запускаются в namespace kube-system.
Способ 2. Подключение к подам SC/PVC/PV
Альтернативный способ подключения — концепция Storage class, PersistentVolumeClaim, PersistentVolume.
Storage class хранит параметры подключения к системе хранения данных.
PersistentVolumeClaim описывает требования к тому, который нужен приложению.
PersistentVolume хранит параметры доступа и статус тома.
Суть идеи: в манифесте пода указывают volume типа PersistentVolumeClaim и указывают название этой сущности в параметре claimName.
В манифесте PersistentVolumeClaim описывают требования к тому данных, который необходим приложению. В том числе:
В манифесте Storage class хранятся тип и параметры подключения к системе хранения данных. Они нужны кублету, чтобы смонтировать том к себе на узел.
В манифестах PersistentVolume указывается Storage class и параметры доступа к конкретному тому (ID тома, путь, и т. д.).
Создавая PVC, Kubernetes смотрит, том какого размера и из какого Storage class потребуется, и подбирает свободный PersistentVolume.
Если таких PV нет в наличии, Kubernetes может запустить специальную программу — Provisioner (её название указывают в Storage class). Эта программа подключается к СХД, создаёт том нужного размера, получает идентификатор и создает в кластере Kubernetes манифест PersistentVolume, который связывается с PersistentVolumeClaim.
Всё это множество абстракций позволяет убрать информацию о том, с какой СХД работает приложение, с уровня манифеста приложений на уровень администрирования.
Все параметры подключения к системе хранения данных находятся в Storage class, за который отвечают администраторы кластера. Всё, что надо сделать при переезде из AWS в Google Cloud, — это в манифестах приложения изменить название Storage class в PVC. Persistance Volume для хранения данных будут созданы в кластере автоматически, с помощью программы Provisioner.
Способ 3. Container Storage Interface
Весь код, который взаимодействует с различными системами хранения данных, является частью ядра Kubernetes. Выпуск исправлений ошибок или нового функционала привязан к новым релизам, код приходится изменять для всех поддерживаемых версий Kubernetes. Всё это тяжело поддерживать и добавлять новый функционал.
Чтобы решить проблему, разработчики из Cloud Foundry, Kubernetes, Mesos и Docker создали Container Storage Interface (CSI) — простой унифицированный интерфейс, который описывает взаимодействие системы управления контейнерами и специального драйвера (CSI Driver), работающего с конкретной СХД. Весь код по взаимодействию с СХД вынесли из ядра Kubernetes в отдельную систему.
Как правило, CSI Driver состоит из двух компонентов: Node Plugin и Controller plugin.
Node Plugin запускается на каждом узле и отвечает за монтирование томов и за операции на них. Controller plugin взаимодействует с СХД: создает или удаляет тома, назначает права доступа и т. д.
Пока в ядре Kubernetes остаются старые драйверы, но пользоваться ими уже не рекомендуют и всем советуют устанавливать CSI Driver конкретно для той системы, с которой предстоит работать.
Нововведение может напугать тех, кто уже привык настраивать хранение данных через Storage class, но на самом деле ничего страшного не случилось. Для программистов точно ничего не меняется — они как работали только с именем Storage class, так и продолжат. Для администраторов добавилась установка helm chart и поменялась структура настроек. Если раньше настройки вводились в Storage class напрямую, то теперь их сначала надо задать в helm chart, а потом уже в Storage class. Если разобраться, ничего страшного не произошло.
Давайте, на примере, рассмотрим какие преимущества можно получить, перейдя на подключение СХД Ceph с помощью CSI драйвера.
При работе с Ceph плагин CSI даёт больше возможностей для работы с СХД, чем встроенные драйверы.
Как подключить Ceph к кластеру Kubernetes через CSI, смотрите в практической части лекции вечерней школы Слёрм. Так же можно подписаться на видео-курс Ceph, который будет запущен 15 октября.
Автор статьи: Сергей Бондарев, практикующий архитектор Southbridge, Certified Kubernetes Administrator, один из разработчиков kubespray.
Хранилища данных (Persistent Volumes) в Kubernetes
В предыдущих статьях мы установили и немного научились работать с кластером kubernetes. При этом я не рассмотрел вопрос с хранением данных, а вынес его в отдельную тему. Сегодня как раз хранение данных в кластере Kubernetes я и рассмотрю. Настраиваются эти хранилища в кластере с помощью абстракции под названием Persistent Volumes.
Цели статьи
Работа с дисками в Kubernetes
Работа с дисковыми томами в Kubernetes проходит по следующей схеме:
Что такое Persistent Volumes
Условно Persistent Volumes можно считать аналогом нод в самом кластере Kubernetes. Допустим, у вас есть несколько разных хранилищ. К примеру, одно быстрое на SSD, а другое медленное на HDD. Вы можете создать 2 Persistent Volumes в соответствии с этим, а затем выделять подам место в этих томах. Кубернетис поддерживает огромное количество подключаемых томов с помощью плагинов.
Вот список наиболее популярных:
Полный список можно посмотреть в документации.
Persistent Volume Claim
PersistentVolumeClaim (PVC) есть не что иное как запрос к Persistent Volumes на хранение от пользователя. Это аналог создания Pod на ноде. Поды могут запрашивать определенные ресурсы ноды, то же самое делает и PVC. Основные параметры запроса:
Типы доступа у PVC могут быть следующие:
Ограничение на тип доступа может налагаться типом самого хранилища. К примеру, хранилище RBD или iSCSI не поддерживают доступ в режиме ReadWriteMany.
Один PV может использоваться только одним PVС. К примеру, если у вас есть 3 PV по 50, 100 и 150 гб. Приходят 3 PVC каждый по 50 гб. Первому будет отдано PV на 50 гб, второму на 100 гб, третьему на 150 гб, несмотря на то, что второму и третьему было бы достаточно и 50 гб. Но если PV на 50 гб нет, то будет отдано на 100 или 150, так как они тоже удовлетворяют запросу. И больше никто с PV на 150 гб работать не сможет, несмотря на то, что там еще есть свободное место.
Из-за этого нюанса, нужно внимательно следить за доступными томами и запросами к ним. В основном это делается не вручную, а автоматически с помощью PV Provisioners. В момент запроса pvc через api кластера автоматически формируется запрос к storage provider. На основе этого запроса хранилище создает необходимый PV и он подключается к поду в соответствии с запросом.
Storage Classes
StorageClass позволяет описать классы хранения, которые предлагают хранилища. Например, они могут отличаться по скорости, по политикам бэкапа, либо какими-то еще произвольными политиками. Каждый StorageClass содержит поля provisioner, parameters и reclaimPolicy, которые используются, чтобы динамически создавать PersistentVolume.
Можно создать дефолтный StorageClass для тех PVC, которые его вообще не указывают. Так же storage class хранит параметры подключения к реальному хранилищу. PVC используют эти параметры для подключения хранилища к подам.
Работа с PV в кластере
Проверим, есть ли у нас какие-то PV в кластере.
Ничего нет. Попробуем создать и применить какой-нибудь PVC и проверим, что произойдет. Для примера создаем pvc.yaml следующего содержания.
Просим выделить нам 1 гб пространства с типом доступа ReadWriteMany. Применяем yaml.
Ждем немного и проверяем статус pvc.
Статус pending. Проверяем почему так.
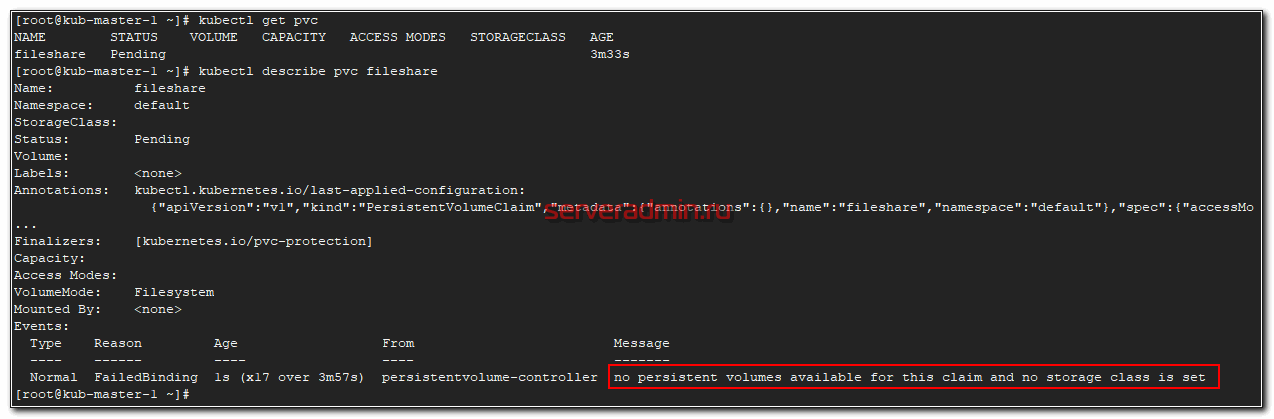
Все понятно. Запрос находится в ожидании, так как у нас в кластере нет ни одного PV, который бы удовлетворял запросу. Давайте это исправим и добавим одно хранилище для примера на основе внешнего nfs сервера.
NFS хранилище в качестве Persistence Volume
Для простоты я взял в качестве хранилища PV nfs сервер. Для него не существует встроенного Provisioner, как к примеру, для Ceph. Возможно в будущем я рассмотрю более сложный пример с применением хранилища на основе ceph. Но перед этим надо будет написать статью про установку и работу с ceph.
Создаем yaml файл pv-nfs.yaml с описанием Persistence Volume на основе NFS.
Reclaim Policy
Все остальное и так понятно, описывать не буду. Добавляем описанный pv в кластер kubernetes.
Проверяем список pv и pvc

Мы просили в pvc только 1 Гб хранилища, но в pv было только хранилище с 10 Гб и оно было выдано. Как я и говорил раньше. Так что в случае ручного создания PV и PVC нужно самим следить за размером PV.
Подключаем хранилище к поду
Теперь подключим наш PVC в виде volume к какому-нибудь поду. Опишем его в конфиге pod-with-nfs.yaml
Затем проверяйте статус запущенного пода.
У меня он не стартовал. Я решил посмотреть из-за чего.
Я сразу понял в чем проблема. На ноде, где стартовал под, не были установлены утилиты для работы с nfs. В моем случае система была Centos и я их установил.
После этого в течении минуты pod запустился. Зайдем в его консоль и посмотрим, подмонтировалась ли nfs шара.

Как видите, все в порядке. Попробуем теперь что-то записать в шару. Снова заходим на под и создаем текстовый файл.
Теперь запустим еще один под и подключим ему этот же pvc. Для этого просто немного изменим предыдущий под, обозвав его pod-with-nfs2.
Запускаем под и заходим в него.

Все в порядке, файл на месте. С внешними хранилищем в Kubernetes закончили. Расскажу дальше, как можно работать с локальными дисками нод, если вы хотите их так же пустить в работу.
Создаем SC sc-local.yaml.
Создаем вручную PV pv-local-node-1.yaml, который будет располагаться на kub-node-1 в /mnt/local-storage. Эту директорию необходимо вручную создать на сервере.
Создаем PVC pvc-local.yaml для запроса сторейджа, который передадим поду.
И в завершении создадим тестовый POD pod-with-pvc-local.yaml для проверки работы local storage.
Применяем все вышеперечисленное в строго определенном порядке:
После этого посмотрите статус всех запущенных абстракций.
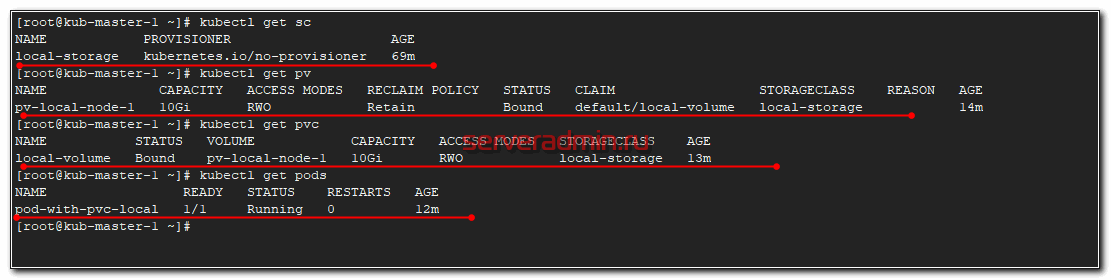
Проверим, что Local Persistent Volume правильно работает. Зайдем в под и создадим тестовый файл.
Теперь идем на сервер kub-node-1 и проверяем файл.
Все в порядке. Файл создан.
Если у вас возникли какие-то проблемы с POD, то в PVC будет ошибка:
И в это же время в поде:
Возникли ошибки из-за того, что в описании PV я ошибся в названии сервера, где будет доступен local storage. В итоге pod запускался, проверял pvc, а pvc смотрел на pv и видел, что адрес ноды с pv не соответствует имени ноды, где будет запущен pod. В итоге все висело в ожидании разрешения этих несоответствий.
С локальным хранилищем разобрались, можно использовать в работе.
Заключение
На наглядных примерах я показал, как можно работать с данными в кластере Kubernetes. Можно использовать как отказоустойчивые внешние хранилища для размещения постоянных данных. А можно сырые диски на серверах и использовать кластер для работы какой-то распределенной базы данных или сервиса, которые сами следят за количеством копий данных и распределяют их по нодам.
В последнем случае можно использовать самое обычное железо для кластера Kубернетиса, без рейд контроллеров и дублирования дорогих и быстрых SSD дисков. Необходимо только следить за количеством реплик приложения на нодах, чтобы их количество было достаточно для стабильной работы системы.
Два этих подхода можно комбинировать. Внешние хранилища для холодных данных и внутренние SSD диски для кэшей.
Другие статьи на тему Kubernetes:
На этом у меня все. Надеюсь мой цикл статей по k8s был для вас полезен.
Почему в Kubernetes так сложно с хранилищами?

Когда пришли оркестраторы контейнеров, вроде Kubernetes, подход к разработке и деплою приложений изменился кардинально. Появились микрослужбы, а для разработчика логика приложения больше не связана с инфраструктурой: создавай себе приложения и предлагай новые функции.
Kubernetes абстрагируется от физических компьютеров, которыми управляет. Только скажите ему, сколько надо памяти и вычислительной мощности, — и все получите. Ифраструктура? Не, не слыхали.
Управляя образами Docker, Kubernetes и приложения делает переносимыми. Разработав контейнерные приложения с Kubernetes, их можно деплоить хоть куда: в открытое облако, локально или в гибридную среду, — и при этом не менять код.
Мы любим Kubernetes за масштабируемость, переносимость и управляемость, но вот состояния он не хранит. А ведь у нас почти все приложения stateful, то есть им нужно внешнее хранилище.
В Kubernetes очень динамичная архитектура. Контейнеры создаются и уничтожаются в зависимости от нагрузки и указаний разработчиков. Поды и контейнеры самовосстанавливаются и реплицируются. Они, по сути, эфемерны.
Внешнему хранилищу такая изменчивость не по зубам. Оно не подчиняется правилам динамического создания и уничтожения.
Чуть только надо развернуть stateful-приложение в другую инфраструктуру: в другое облако там, локально или в гибридную модель, — как у него возникают проблемы с переносимостью. Внешнее хранилище можно привязать к конкретному облаку.
Вот только в этих хранилищах для облачных приложений сам черт ногу сломит. И поди пойми хитровыдуманные значения и смыслы терминологии хранилищ в Kubernetes. А еще есть собственные хранилища Kubernetes, опенсорс-платформы, управляемые или платные сервисы…
Казалось бы, разверни базу данных в Kubernetes — надо только выбрать подходящее решение, упаковать его в контейнер для работы на локальном диске и развернуть в кластер как очередную рабочую нагрузку. Но у базы данных свои особенности, так что мысля — не айс.
Контейнеры — они же так слеплены, что своё состояние не сохраняют. Потому-то их так легко запускать и останавливать. А раз нечего сохранять и переносить, кластер не возится с операциями чтения и копирования.
С базой данных состояние хранить придется. Если база данных, развернутая на кластер в контейнере, никуда не переносится и не запускается слишком часто, в игру вступает физика хранения данных. В идеале контейнеры, которые используют данные, должны находиться в одном поде с базой данных.
В некоторых случаях базу данных, конечно, можно развернуть в контейнер. В тестовой среде или в задачах, где данных немного, базы данных комфортно живут в кластерах.
Для продакшена обычно нужно внешнее хранилище.
Kubernetes общается с хранилищем через интерфейсы плоскости управления. Они связывают Kubernetes с внешним хранилищем. Привязанные к Kubernetes внешние хранилища называются плагинами томов. С ними можно абстрагировать хранение и переносить хранилища.
Раньше плагины томов создавались, привязывались, компилировались и поставлялись с помощью кодовой базы Kubernetes. Это очень ограничивало разработчиков и требовало дополнительного обслуживания: хочешь добавить новые хранилища — изволь менять кодовую базу Kubernetes.
Теперь деплой плагины томов в кластер — не хочу. И в кодовой базе копаться не надо. Спасибо CSI и Flexvolume.
Собственное хранилище Kubernetes
Как Kubernetes решает вопросы хранения? Решений несколько: эфемерные варианты, постоянное хранение в постоянных томах, запросы Persistent Volume Claim, классы хранилищ или StatefulSets. Поди разберись, в общем.
Постоянные тома (Persistent Volumes, PV) — это единицы хранения, подготовленные админом. Они не зависят от подов и их скоротечной жизни.
Persistent Volume Claim (PVC) — это запросы на хранилище, то есть PV. С PVC можно привязать хранилище к ноде, и эта нода будет его использовать.
С хранилищем можно работать статически или динамически.
При статическом подходе админ заранее, до запросов, готовит PV, которые предположительно понадобятся подам, и эти PV вручную привязаны к конкретным подам с помощью явных PVC.
На практике специально определенные PV несовместимы с переносимой структурой Kubernetes — хранилище зависит от среды, вроде AWS EBS или постоянного диска GCE. Для привязки вручную нужно указать на конкретное хранилище в файле YAML.
Статический подход вообще противоречит философии Kubernetes: ЦП и память не выделяются заранее и не привязываются к подам или контейнерам. Они выдаются динамически.
Для динамической подготовки мы используем классы хранилища. Администратору кластера не нужно заранее создавать PV. Он создает несколько профилей хранилища, наподобие шаблонов. Когда разработчик делает запрос PVC, в момент запроса один из этих шаблонов создается и привязывается к поду.
Вот так, в самых общих чертах, Kubernetes работает с внешним хранилищем. Есть много других вариантов.
CSI — Container Storage Interface
Есть такая штука — Container Storage Interface. CSI создан рабочей группой CNCF по хранилищам, которая решила определить стандартный интерфейс хранения контейнеров, чтобы драйверы хранилища работали с любым оркестратором.
Спецификации CSI уже адаптированы для Kubernetes, и есть куча плагинов драйвера для деплоя в кластере Kubernetes. Надо получить доступ к хранилищу через драйвер тома, совместимый с CSI, — используйте тип тома csi в Kubernetes.
С CSI хранилище можно считать еще одной рабочей нагрузкой для контейнеризации и деплоя в кластер Kubernetes.
Если хотите подробностей, послушайте, как Цзе Юй рассказывает о CSI в нашем подкасте.
Опенсорс-проекты
Инструменты и проекты для облачных технологий шустро плодятся, и изрядная доля опенсорс-проектов — что логично — решают одну из главных проблем продакшена: работа с хранилищами в облачной архитектуре.
Самые популярные из них — Ceph и Rook.
Ceph — это динамически управляемый, распределенный кластер хранилища с горизонтальным масштабированием. Ceph дает логическую абстракцию для ресурсов хранилища. У него нет единой точки отказа, он сам собой управляет и работает на базе ПО. Ceph предоставляет интерфейсы для хранения блоков, объектов и файлов одновременно для одного кластера хранилища.
У Ceph очень сложная архитектура с RADOS, librados, RADOSGW, RDB, алгоритмом CRUSH и разными компонентами (мониторы, OSD, MDS). Не будем углубляться в архитектуру, достаточно понимать, что Ceph — это распределенный кластер хранилища, который упрощает масштабируемость, устраняет единую точку отказа без ущерба для производительности и предоставляет единое хранилище с доступом к объектам, блокам и файлам.
Естественно, Ceph адаптирован для облака. Деплоить кластер Ceph можно по-разному, например с помощью Ansible или в кластер Kubernetes через CSI и PVC.
Архитектура Ceph
Rook — это еще один интересный и популярный проект. Он объединяет Kubernetes с его вычислениями и Ceph с его хранилищами в один кластер.
Rook — это оркестратор облачных хранилищ, дополняющий Kubernetes. С ним пакуют Ceph в контейнеры и используют логику управления кластерами для надежной работы Ceph в Kubernetes. Rook автоматизирует деплой, начальную загрузку, настройку, масштабирование, перебалансировку, — в общем все, чем занимается админ кластера.
С Rook кластер Ceph можно деплоить из yaml, как Kubernetes. В этом файле админ в общих чертах описывает, что ему нужно в кластере. Rook запускает кластер и начинает активно мониторить. Это что-то вроде оператора или контролера — он следит, чтобы все требования из yaml выполнялись. Rook работает циклами синхронизации — видит состояние и принимает меры, если есть отклонения.
У него нет своего постоянного состояния и им не надо управлять. Вполне в духе Kubernetes.
Rook, объединяющий Ceph и Kubernetes, — это одно из самых популярных облачных решений для хранения: 4000 звезд на Github, 16,3 млн загрузок и больше сотни контрибьюторов.
Проект Rook уже приняли в CNCF, а недавно он попал в инкубатор.
Больше о Rook вам расскажет Бассам Табара в нашем эпизоде о хранилищах в Kubernetes.
Если в приложении есть проблема, нужно узнать требования и создать систему или взять нужные инструменты. Это относится и к хранилищу в облачной среде. И хотя проблема не из простых, инструментов и подходов у нас завались. Облачные технологии продолжают развиваться, и нас обязательно ждут новые решения.
Русские Блоги
Kubernetes Storage (хранилище Kubernetes)
Каталог статей
Шесть, Kubernetes Storage (хранилище Kubernetes)
Временное хранилище: emptydir
Полупостоянное хранилище: путь к хосту
Постоянное хранилище: пвх, пв, нфс
Распределенное хранилище: glusterfs, rbd, cephfs, облачное хранилище (EBS и др.)
Проверьте, сколько типов хранилищ поддерживает K8s: kubectl объясните pods.spec.volumes
Система хранения K8S примерно разделена на три уровня от базового до расширенного: обычный том, постоянный том и предоставление динамического хранилища.
1.Volume
Срок службы рулона в K8s такой же, как и у капсулы, в которой он заключен. Жизненный цикл тома длиннее, чем у всех контейнеров в модуле, и данные по-прежнему могут быть сохранены при перезапуске контейнера. Под не существует, том не существует
Объем в контейнере
Том контейнера фактически связывает и монтирует каталог на хост-машине с каталогом в контейнере.
Каталог на хосте является «постоянным». То есть: содержимое этого каталога не будет очищено из-за удаления контейнера и не будет привязано к текущему хосту. Таким образом, когда контейнер перезапускается или перестраивается на других узлах, он все еще может получить доступ к этому содержимому путем монтирования тома.
Тип тома
2.PV(Persistent Volume)
PV описывает постоянный том хранилища, который в основном определяет каталог, постоянно хранящийся на хост-машине, такой как каталог монтирования NFS.
Обычно создается эксплуатационным и обслуживающим персоналом
2.1 Режим доступа PV
PV может быть установлен на хосте способом, поддерживаемым поставщиком ресурсов. У поставщиков разные функции, и каждый режим доступа к PV будет установлен на определенный режим, поддерживаемый объемом. Например, NFS может поддерживать несколько клиентов для чтения и записи, но определенные PV NFS могут быть экспортированы на сервер только для чтения, и каждый PV имеет свой собственный набор режимов доступа для описания определенных функций.
2.2 PVC(Persistent Volume Claim)
Обычно создается разработчиком
2.3 Связывание
Пользователь создает (или был создан при динамическом развертывании) PVC в соответствии с требуемым размером дискового пространства и режимом доступа. Узел Kubernetes Master зацикливается для мониторинга вновь созданного PVC, находит соответствующий PV (если есть) и связывает их вместе. Во время динамической конфигурации цикл будет связывать PV с этим PVC до тех пор, пока PV не будет полностью соответствовать PVC. Избегайте несоответствия между запросом PVC и полученным PV. После формирования привязки привязка PersistentVolumeClaim становится уникальной, независимо от режима привязки.
Если соответствующий том не найден, запрос пользователя останется несвязанным. После того, как соответствующий том станет доступен, пользовательский запрос будет привязан.
Контроллер объема: управление несколькими циклами управления, привязка PV и PVC (имя PV записывается в spec.volumeName объекта PVC)
Первым условием, конечно же, является спецификация PV и PVC. Например, размер хранилища PV должен соответствовать требованиям PVC.
2.4 Обработка PV процесса
2.4.1 Два этапа
1) Первый этап Прикрепить
/ var / lib / kubelet / pods / /volumes/kubernetes.io
2) Крепление второй ступени
После завершения фазы подключения, чтобы иметь возможность использовать удаленный диск, kubelet необходимо выполнить вторую операцию, а именно: отформатировать дисковое устройство, а затем подключить его к точке монтирования, указанной хостом.
Свяжите каталог хоста с каталогом определения модуля VolumeMount
2.5 Жизненный цикл PV

Provisioning ——-> Binding ——–>Using——>Releasing——>Reclaiming
2.5.1 Provisioning
Есть два способа предоставить PV: статический или динамический.
2.5.2 Binding
В случае динамической конфигурации пользователь создает или создал PersistentVolumeClaim с определенным количеством запросов к хранилищу и определенным режимом доступа. Контур управления в хосте отслеживает новый PVC, находит соответствующий PV (если возможно) и связывает их вместе. Если PV динамически настроен для нового PVC, цикл всегда будет связывать PV с PVC. В противном случае пользователи всегда получают как минимум то, что запрашивают, но объем может превышать требования. После привязки привязка PersistentVolumeClaim является эксклюзивной, независимо от режима, используемого для их привязки.
Если соответствующий том не существует, PVC останется на неопределенный срок. Когда появятся подходящие объемы, ПВХ будет переплетен. Например, кластер, который предоставляет много PV 50Gi, не будет соответствовать PVC, для которого требуется 100Gi. Когда к кластеру добавляется 100Gi PV, можно связать PVC.
2.5.3 Using
Pod использует ПВХ как рулон. Кластер проверяет оператор, чтобы найти связанный том, и монтирует том этого тома. Для тома, поддерживающего несколько режимов доступа, пользователь указывает желаемый режим при использовании его в качестве тома в модуле.
Как только у пользователя есть претензия и она связана, привязанная PV принадлежит пользователю до тех пор, пока она ему нужна. Пользователь упорядочивает поды и получает доступ к их заявленному PV, включая persistentVolumeClaim в блок томов своего пода.
2.5.4 Releasing
Когда пользователи завершат создание тома, они могут удалить объект PVC из API, который позволяет восстанавливать ресурсы. Когда требование удаляется, том считается «освобожденным», но его нельзя использовать для другого требования. Данные предыдущего заявителя остаются в томе, который необходимо обработать в соответствии с политикой.
2.5.5 Reclaiming
Стратегия повторного использования PersistentVolume сообщает кластеру, что делать с томом после отзыва заявки. В настоящее время том можно зарезервировать, переработать или удалить. Резервный может вернуть ресурсы вручную. Для тех подключаемых модулей томов, которые его поддерживают, при удалении будет удален объект PersistentVolume из Kubernetes, а также ресурсы хранилища, связанные с внешней инфраструктурой (например, AWS EBS, GCE PD, Azure Disk или тома Cinder). Динамически настроенные тома всегда удаляются
2.5.6 Стратегия переработки
В настоящее время переработку поддерживают только NFS и HostPath, а тома AWS EBS, GCE PD и Cinder поддерживают только удаление.
2.5.7 Состояние тома
2.6 StorageClass
2.6.1 StorageClass

Атрибуты PV. Например, тип хранилища, размер тома и т. Д.
Плагин хранилища, необходимый для создания такого рода PV. Такие как Ceph и т. Д.
kubectl describe pvc claim1
2.7 Тип PV
Тип PV реализован как плагин. K8s в настоящее время поддерживает следующие типы плагинов:
NFS
RBD(Ceph Block Device)
CephFS
Cinder
Glusterfs
HostPath
VMware
GCEPersistentDisk
AWSElasticStore
AzureFile
Fibre Channel
FlexVolume
ISCSI
и т. д.
2.8 Актуальный бой 1
PV на основе типа NFS
1) Сначала создайте службу NFS
Все узлы nfs-utils должны быть установлены
systemctl restart rpcbind nfs
Редактировать общий файл конфигурации
/ etc / export write / mnt / share * (rw)
chmod 777 /mnt/share
kubectl describe pv nfs

kubectl describe pvc nfs

4) Создайте модуль и вызовите pvc.
Напишите в / mnt / share / 1
Войти в представление пакета
Выйти из просмотра
Удалить / mnt / share / 1
Вернуться к просмотру пакета
2.9 Актуальный бой 2
Динамический PV на основе NFS
Тогда среда реального боя 1
Сначала проделайте подготовительную работу
Напишите / nfs3 * (rw) в / etc / exports
1) Создаем RBAC авторизацию rbac.yaml
2) файл serviceaccount.yaml
3) Создайте Storageclass storageclass-nfs.yaml
4) Создайте развертывание nfs, измените соответствующий IP-адрес сервера nfs и путь монтирования. развертывание-nfs.yaml
Вытащить зеркало registry.cn-hangzhou.aliyuncs.com/open-ali/nfs-client-provisioner
Содержимое файла deployment-nfs.yaml
5) Создайте тестовое заявление
6) Создайте тестовый модуль, используя этот PVC, и напишите файл test-pod.yaml следующим образом
Проверьте, изменился ли статус модуля на «Завершено». Если это так, вы должны увидеть файл SUCCESS на общем пути системы NFS.
Таким образом, успешно реализована функция StorageClass для динамического создания PV.
7) Создайте кейс StatefulSet

Вернуться к хосту kubernetes01
Вернуться в Интернет-0
В это время хозяин ушел,
Web-1 и web-0 изолированы и не влияют друг на друга.
3.Local Persistent Volume
«Локальное» постоянное хранилище напрямую использует каталог локального диска на хост-машине, не полагаясь на службы удаленного хранилища для обеспечения «постоянного» контейнерного тома.
3.1 Сценарии применения
3.2 Принцип реализации
Преобразование локального жесткого диска в PV: один диск на PV?
Под обычно назначается указанный узел
Прежде чем вы начнете использовать локальный постоянный том, вам сначала необходимо настроить диски или блочные устройства в кластере.
3.3 Фактический бой
1) Создайте точку монтирования на хосте kubernetes02 и используйте RAM Disk для имитации локального диска
2) Создайте PV соответствующий локальному диску: local-pv.yaml
3) Создайте StorageClass для описания этого PV: local-sc.yaml
Provisioner: kubernetes.io/no-provisioner: Поскольку локальный постоянный том в настоящее время не поддерживает динамическое предоставление, он не может автоматически создать соответствующий PV, когда пользователь создает PVC. Другими словами, мы не можем пропустить операцию создания PV.
volumeBindingMode = WaitForFirstConsumer: отложенное связывание. После того, как вы отправите YAML-файлы PV и PVC, Kubernetes свяжет их в соответствии с их атрибутами и указанным StorageClass. Только после успешного связывания Pod может использовать соответствующий PV, объявив PVC.
Оператор Pod PVC pvc1, соответствие узла: node2
pv2: узел node2, на котором расположен диск
#kubectl create Pod
Поэтому переплет пвх продвигать нельзя.
4) Создайте PVC: local-pvc.yaml
5) Напишите pod и используйте этот PVC pod.yaml
6) Запись тестового файла
7) Удалить тест pod
В это время вы обнаружите, что исходные данные все еще там
Создайте pod.yaml снова
4. Резюме
4.1 Volume
4.2 PV
Постоянный том, называемый PV, является объектом ресурса K8S, поэтому мы можем создать PV отдельно. Он не имеет прямого отношения к Pod, но обеспечивает динамическую привязку через Persistent Volume Claim, или сокращенно PVC. PVC указан в определении Pod, а затем PVC автоматически привяжет соответствующий PV к Pod в соответствии с требованиями Pod.
4.3 PVC
4.4 LPV
4.5 В чем разница между PV и нормальным объемом
Постоянный том, называемый PV, является объектом ресурса K8S, поэтому мы можем создать PV отдельно. Он не имеет прямого отношения к Pod, но обеспечивает динамическую привязку через Persistent Volume Claim, или сокращенно PVC. PVC указан в определении Pod, а затем PVC автоматически привяжет соответствующий PV к Pod в соответствии с требованиями Pod.
Есть три режима доступа к PV:
Первый, ReadWriteOnce: это самый простой метод, который доступен для чтения и записи, но поддерживает монтирование только одним модулем.
Второй, ReadOnlyMany: может монтироваться несколькими модулями только для чтения.


