Понимание функции Pandas groupby()
Эй, ребята! В этой статье мы будем понимать функцию Pandas groupby() вместе с различными функциями, которые она выполняет.
Эй, ребята! В этой статье мы будем понимать функцию Pandas groupby () вместе с различными функциями, которые она выполняет.
Что такое функция groupby ()?
Модуль Python Pandas широко используется для лучшей предварительной обработки данных и используется для визуализации данных.
Модуль Pandas имеет различные встроенные функции для более эффективной работы с данными. Функция dataframe.groupby() модуля Pandas используется для разделения и выделения некоторой части данных из целого набора данных на основе определенных предопределенных условий или параметров.
Используя приведенный выше синтаксис, мы можем разделить набор данных и выбрать все данные, принадлежащие переданному столбцу, в качестве аргумента функции.
Входной набор данных:
В приведенном выше примере мы использовали функцию groupby() для разделения и раздельного создания нового фрейма данных со всеми данными, принадлежащими столбцу “семейное положение”, соответственно.
Функция Pandas groupby() с несколькими столбцами
Функция Pandas groupby() для просмотра групп
Вот снимок образца набора данных, используемого в этом примере:
Как было показано выше, мы разделили данные и сформировали новый фрейм данных значений из столбца – “брачный”.
Кроме того, мы использовали функцию group by().groups для отображения всех категорий значений, присутствующих в этом конкретном столбце.
Кроме того, он также представляет положение этих категорий в исходном наборе данных, а также тип данных и количество присутствующих значений.
Выбор группы с помощью функции Pandas groupby()
Как видно до сих пор, мы можем просматривать различные категории обзора уникальных значений, присутствующих в столбце, с его подробностями.
В приведенном выше примере мы отобразили данные, относящиеся к значению столбца “разведен” столбца “женат”.
Вывод
Таким образом, в этой статье мы подробно разобрались в работе функции Pandas groupby ().
Groupby aggregation в pandas

Агрегация является одной из самых частых операций при анализе данных. Разные технологии предлагают нам кучу способов эффективно группировать и агрегировать интересующие нас поля(столбцы, признаки). В этой статье будет рассказано про реализацию агрегации в pandas.
По своей специализации я очень мало работаю с python, но часто слышу про плюсы и мощь этого языка, в особенности когда речь заходит про работу с данными. Поэтому я проведу здесь параллель операций с T-SQL и приведу некотрые примеры кода. В качестве данных я буду использовать наверное самый популярный data set — Ирисы Фишера.
Первое, что приходит в голову, это получить максимальное, минимальное или среднее значение по какому-либо из параметров ириса и сгруппировать по видам этого растения, что на python с помощью pandas будет выглядить примерно следующим образом:
| variety | sepal.length |
|:————|—————:|
| Setosa | 5.8 |
| Versicolor | 7 |
| Virginica | 7.9 |
| variety | maxSepalLength | minSepalLength |
|:————|——————:|——————:|
| Setosa | 5.8 | 4.3 |
| Versicolor | 7 | 4.9 |
| Virginica | 7.9 | 4.9 |
Или с помощью лямбда выражений:
Функция экземпляра DataFrame позволяет вывести в привычном(консольном) виде таблицу(DataFrame).
На T-SQL такая операция выглядит приблизительно так:
Setosa 5.8
Versicolor 7.0
Virginica 7.9
Но допустим, теперь мы хотим получить и максимальное и минимальное (если угодно среднее) значения по всем параметрам ириса, естественно для каждого вида растения, здесь саначала код на T-SQL:
Setosa 5.8 4.3 4.4 2.3 1.9 1.0 0.6 0.1
Versicolor 7.0 4.9 3.4 2.0 5.1 3.0 1.8 1.0
Virginica 7.9 4.9 3.8 2.2 6.9 4.5 2.5 1.4
В pandas возможность групповой агрегации появилась только в версии 0.25.0 от 18 июля 2019(что было делать раньше?) и тут есть несколько вариации, рассмотрим их:
Setosa 5.8 4.3 4.4 2.3 1.9 1.0 0.6 0.1
Versicolor 7.0 4.9 3.4 2.0 5.1 3.0 1.8 1.0
Virginica 7.9 4.9 3.8 2.2 6.9 4.5 2.5 1.4
Функция
позволяет проводить агрегацию из нескольких операций над заданной осью. В качестве параметров функция получает **kwargs(именнованные аргументы, подробнее можно посмотреть в статье на habr), которые представляют собой столбец, над которым производится операция и собтсвенно имя функции агрегирования в одинарных кавычках. Запись выглядит довольно пространно. Идем дальше.
То же решение с применением лямбда выражений выглядит гораздо более лаконично и просто:
Setosa 5.8 4.3 4.4 2.3 1.9 1.0 0.6 0.1
Versicolor 7.0 4.9 3.4 2.0 5.1 3.0 1.8 1.0
Virginica 7.9 4.9 3.8 2.2 6.9 4.5 2.5 1.4
Мне часто доводится слышать о гораздо меньшем количестве написанного когда Python при решении однотипных задача в сравнении с другими языками. Здесь, в сравнении с T-SQL, с этим можно согласится, однако понятность и последовательность выражений лингвистических средств таких как SQL или T-SQL напрочь теряется(личное мнение).
pandas.DataFrame.groupby¶
Group DataFrame using a mapper or by a Series of columns.
A groupby operation involves some combination of splitting the object, applying a function, and combining the results. This can be used to group large amounts of data and compute operations on these groups.
Parameters by mapping, function, label, or list of labels
Split along rows (0) or columns (1).
level int, level name, or sequence of such, default None
If the axis is a MultiIndex (hierarchical), group by a particular level or levels.
as_index bool, default True
For aggregated output, return object with group labels as the index. Only relevant for DataFrame input. as_index=False is effectively “SQL-style” grouped output.
sort bool, default True
Sort group keys. Get better performance by turning this off. Note this does not influence the order of observations within each group. Groupby preserves the order of rows within each group.
group_keys bool, default True
When calling apply, add group keys to index to identify pieces.
squeeze bool, default False
Reduce the dimensionality of the return type if possible, otherwise return a consistent type.
Deprecated since version 1.1.0.
This only applies if any of the groupers are Categoricals. If True: only show observed values for categorical groupers. If False: show all values for categorical groupers.
dropna bool, default True
If True, and if group keys contain NA values, NA values together with row/column will be dropped. If False, NA values will also be treated as the key in groups
New in version 1.1.0.
Returns a groupby object that contains information about the groups.
Convenience method for frequency conversion and resampling of time series.
Hierarchical Indexes
We can groupby different levels of a hierarchical index using the level parameter:
We can also choose to include NA in group keys or not by setting dropna parameter, the default setting is True :
Основы Pandas №2 // Агрегация и группировка
Во втором уроке руководства по работе с pandas речь пойдет об агрегации (min, max, sum, count и дргуих) и группировке. Это популярные методы в аналитике и проектах data science, поэтому убедитесь, что понимаете все в деталях!
Примечание: это руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Агрегация данных — теория
Агрегация — это процесс превращения значений набора данных в одно значение. Например, у вас есть следующий набор данных…
| animal | water_need |
|---|---|
| zebra | 100 |
| lion | 350 |
| elephant | 670 |
| kangaroo | 200 |
Агрегация данных — практика
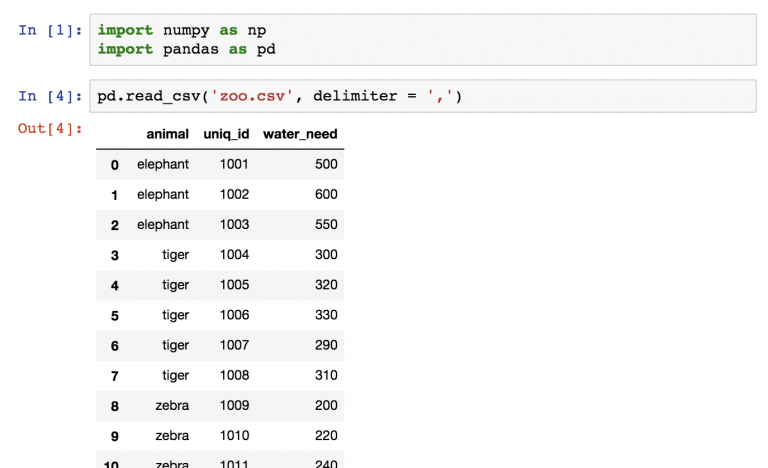
Теперь нужно проделать пять шагов:
Посчитать количество животных — то же самое, что применить функцию count к набору данных zoo :

А что это за строки? На самом деле, функция count() считает количество значений в каждой колонке. В случае с zoo было 3 колонки, в каждой из которых по 22 значения.
Чтобы сделать вывод понятнее, можно выбрать колонку animal с помощью оператора выбора из предыдущей статьи:
В этом случае результат будет даже лучше, если написать следующим образом:
Также будет выбрана одна колонка, но набор данных pandas превратится в объект series (а это значит, что формат вывода будет отличаться).

Следуя той же логике, можно с легкостью найти сумму значений в колонке water_need с помощью:

Просто из любопытства можно попробовать найти сумму во всех колонках:


То же и с максимальным значением:

Наконец, стоит посчитать среднестатистические показатели, например среднее и медиану:


Это было просто. Намного проще, чем агрегация в SQL.
Но можно усложнить все немного с помощью группировки.
Группировка в pandas
Работая аналитиком или специалистом Data Science, вы наверняка постоянно будете заниматься сегментациями. Например, хорошо знать количество необходимой воды ( water_need ) для всех животных (это 347,72 ). Но удобнее разбить это число по типу животных.
Вот упрощенная репрезентация того, как pandas осуществляет «сегментацию» (группировку и агрегацию) на основе значений колонок!
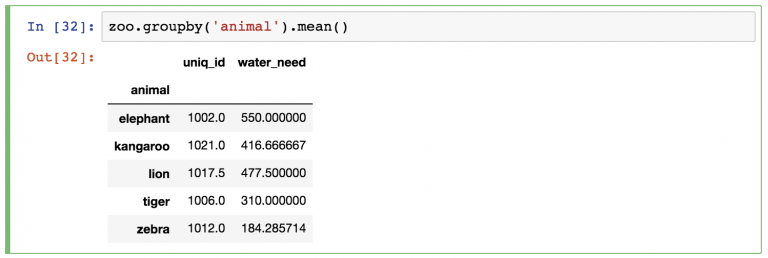
zoo.groupby(‘animal’).mean()[[‘water_need’]] — возвращает объект DataFrame.
zoo.groupby(‘animal’).mean().water_need — возвращает объект Series.
Проверить себя №1
Примечание: стоит напомнить, что в этом наборе хранятся данные из блога о путешествиях. Скачать его можно отсюда. Пошаговый процесс загрузки, открытия и сохранения есть в прошлом материале руководства.
Если все готово, вот первое задание:
Какой источник используется в article_read чаще остальных?
Правильный ответ:
Reddit!
Получить его можно было с помощью кода:

Также можно удалить ненужные колонки и сохранить только user_id :
Проверить себя №2
Вот еще одна, более сложная задача:
Правильный ответ: Reddit (источник) и Азия (тема) с 139 прочтениями.
Вот Python-код для получения результата:

Вот краткое объяснение:
А функция count() — заключительный элемент пазла.
Итого
Это была вторая часть руководства по работе с pandas. Теперь вы знаете, что агрегация и группировка в pandas— это простые операции, а использовать их придется часто.
Примечание: если вы ранее пользовались SQL, сделайте перерыв и сравните методы агрегации в SQL и pandas. Так лучше станет понятна разница между языками.
Понимание функции Pandas groupby()
В этой статье мы поймем работу функции Pandas groupby() на различных примерах.

Что такое функция groupby()?
Модуль Python Pandas широко используется для улучшения предварительной обработки данных и используется для визуализации данных.
Модуль Pandas имеет различные встроенные функции для более эффективной работы с данными. Функция dataframe.groupby() function используется для разделения и выделения некоторой части данных из всего набора данных на основе определенных предопределенных условий или параметров.
Используя приведенный выше синтаксис, мы можем разделить набор данных и выбрать все данные, принадлежащие переданному столбцу, в качестве аргумента функции.
Входной набор данных:

В приведенном выше примере мы использовали функцию groupby() для разделения и отдельного создания нового фрейма данных со всеми данными, принадлежащими столбцу marital, соответственно.

groupby() с несколькими столбцами

Для просмотра групп
Вот снимок образца набора данных, используемого в этом примере:

Как видно выше, мы разделили данные и сформировали новый фрейм данных значений из столбца — «семейный».
Кроме того, мы использовали функцию groupby(). Groups для отображения всех категорий значений, присутствующих в этом конкретном столбце.
Кроме того, он также представляет положение этих категорий в исходном наборе данных вместе с типом данных и количеством имеющихся значений.
Выбор группы
Как мы видели до сих пор, мы можем просматривать различные категории обзора уникальных значений, представленных в столбце с его деталями.
В приведенном выше примере мы отобразили данные, принадлежащие значению столбца «divorced» столбца «marital».


