OpenStack — разворачиваем «руками» Kilo
Привет всем Хабралюдям!
В общем-то эта система позволит нам запускать множество виртуальных машин (сколько позволит памяти и CPU на compute), создавать виртуальные сети, создавать виртуальные диски и подключать их к VM, ну и конечно управлять всем этим через удобный дашборд.
Осторожно! Много «портянок» со списком команд и конфигами!
Не надо бездумно «копипастить». Это, конечно, поможет установить OpenStack-среду по данному руководству, но не научит использовать это знание в полевых условиях.
Что будем использовать?
Подготовка
В оригинальном руководстве используется 4 сети:
Management — 10.0.0.0/24 — VLAN 10
Tunnel — 10.0.1.0/24 — VLAN 11
Storage — 10.0.2.0/24 — VLAN 12
External — 192.168.1.0/24
External-сеть в нашем случае смотрит куда-нибудь в домашнюю сеть, но по большому счёту этот интерфейс может смотреть и во «всемирную паутину» — всё зависит от того, для чего разворачиваете облако.
Будет очень неплохо иметь работоспособный dns-server. Я использовал dnsmasq.
Проверяем, чтобы обе машины видели друг друга и ходили в сеть.
На вычислительной ноде:
Репозиторий Kilo
Kilo довольно молодой выпуск — апрель 2015 года. Больше всего в этом релизе мне понравился русский язык в интерфейсе Horizon.
Более подробно можно почитать тут.
SQL + RabbitMQ
В роли SQL сервера может быть MySQL, PostgreSQL, Oracle или любой другой, который поддерживается SQLAlchemy. Мы будем устанавливать MariaDB как и в официальном мануале.
Если есть лишние HDD с хорошей производительностью, то файлы БД можно положить на него и это не будет лишним, если вы планируете развивать стенд вычислительными нодами.
Ну и конечно же RabbitMQ:
Мы устанавливаем рээбита и запускаем административную WebGUI, для удобства слежения за очередями.
Создаём пользователя и устанавливаем права ему:
Keystone
Keystone — центр авторизации для OpenStack. Все авторизации проходят через него. Данные Keystone хранит в SQL-БД, но использует так же и memcache.
Естественно, не забудьте подставить свой пароль, как и везде.
Отключаем автозагрузку keystone сервиса и устанавливаем все необходимые компоненты:
В конфиге /etc/keystone/keystone.conf прописываем следующие строки:
Мы меняем ServerName на имя нашего контроллера.
Рабочие скрипты мы берём с репозитория openstack.
Настроим endpoint`ы. Вообщем-то именно благодаря endpoint`ам openstack будет знать где и какой сервис работает.
Добавим переменные окружения, для того чтобы не указывать их каждый раз в параметрах keystone:
Теперь создаём сервис:
Ну и создаём API endpoint:
RegionOne можно поменять на любое удобочитаемое имя. Я буду использовать его, чтобы не «заморачиваться».
Создаём проекты, пользователей и роли.
Будем продолжать делать по официальному ману, так что всё так же: админ и демо
Пароль для админа придумайте сами. По порядку: создали проект «Admin Project», пользователя и роль admin, и соединяем проект и пользователя с ролью.
Теперь создаём проектservice:
По аналогии с admin`ом создаём demo:
Создадим скрипты окружения:
На этом настройка сервиса keystone закончена.
Glance
Glance — это инструмент OpenStack для хранения шаблонов (образов) виртуальных машин. Образы могут храниться в Swift, в собственном хранилище Glance`а, но и где-то ещё — главное чтобы этот образ можно было получить по http.
Начнём как всегда с mysql:
Создадим в keystone информацию о будущем сервисе:
Мы создаём пользователя glance и подключаем его к роли admin, т.к. все сервисы будут работать именно от этой роли, мы создаём сервис glance, задаём endpoint.
Теперь приступим к установке:
Что бы ни было в секции openstack nova что это — это нужно удалить. GLANCE_PASS — пароль от пользователя glance в keystone. filesystem_store_datadir это путь к хранилищу, где будут лежать наши образы. Рекомендую подмонтировать к этой директории или рейд-массив или надёжное сетевое хранилище, чтобы случайно не потерять все наши образы из-за отказа диска.
В /etc/glance/glance-registry.conf дублируем ту же информацию из секций database, keystone_authtoken, paste_deploy, DEFAULT.
Перезапускаем сервисы и удаляем локальную БД:
В официальном мануале загружается cirros, который в общем-то нам не нужен, так что мы загрузим образ Ubuntu:
Можно сразу залить все нужные нам образы, но думаю дождёмся момента, когда у нас появится Dashboard.
Целом — наш сервис Glance готов.
Nova — основная часть IaaS в OpenStack. Собственно благодаря Nova создаются виртуальные машины автоматически. Nova может взаимодействовать с KVM, Xen, Hyper-V, VMware и кажется Ironic (честно говоря не совсем понимаю как это работает). Мы будем использовать KVM, для других гипервизоров конфиги будут отличаться.
Контроллер
Опять начинаем с БД:
Добавляем информацию в keystone:
Устанавливаем необходимые пакеты:
Синхронизируем БД, перезапускаем сервисы и удаляем локальную БД.
Вычислительный узел
Теперь мы наконец начнём работать с вычислительным узлом. Все описанные действия справедливы для каждого вычислительного узла в нашей системе.
MANAGEMENT_INTERFACE_IP_ADDRESS это адрес вычислительного узла из VLAN 10.
В novncproxy_base_url controller должен соответствовать тому адресу, через который будет возможность обратиться через Web-browser. Иначе вы не сможете воспользоваться vnc-консолью из Horizon.
Перезапускаем сервис и удаляем локальную копию БД:
Проверяем всё ли правильно работает:
5ая строчка говорит о том, что мы всё правильно сделали.
Мы сделали самое главное — теперь у нас есть IaaS.
Neutron
Neutron это сервис предоставляющий сеть как услуга (NaaS). Вообще официальная документация немного другое определение даёт, но так думаю будет понятнее. Nova-networking объявлен как устаревший в новых версиях OpenStack, поэтому его мы использовать не будем. Да и функционал у neutron значительно шире.
Контроллер
Мы устанавливаем ядро сети на контроллере, хотя в мануале используется 3я нода. Если вычислительных нод будет достаточно много (>10) и/или сетевая нагрузка будет достаточно высокая, то лучше вынести Network-сервер на отдельную ноду.
Как всегда начнём с БД
Устанавливаем необходимые компоненты:
Так же необходимо подправить /etc/sysctl.conf
Убиваем все процессы dnsmasq
Из nova.conf не удаляем ничего, только добавляем.
Синхронизируем БД и перезапускаем сервисы:
Создаём мост и связываем его с external-интерфейсом
Вычислительный узел
Добавляем строчки в /etc/nova/nova.conf
Если я ничего не забыл упомянуть, то должно получиться так:
Сейчас мы сделаем начальную заготовку наших сетей. Мы создадим одну внешнюю сеть и одну внутреннюю.
Создаём виртуальную сеть:
Настраиваем нашу внешнюю подсеть:
Наша внешняя сеть 192.168.1.0/24 и маршрутизатор выпускающий в интернет 192.168.1.1. Внешние адреса для нашего облака будут выдаваться из диапазона 192.168.1.101-200.
Далее мы будем создавать внутреннюю сеть для проекта demo, поэтому следует загрузить переменные для demo-юзера:
Теперь создаём виртуальную внутреннюю сеть:
Понятно, что наша виртуальная сеть будет 172.16.1.0/24 и все инстансы из неё будут получать в качестве маршрутизатора 172.16.1.1.
Вопрос: что это за маршрутизатор?
Ответ: это виртуальный маршрутизатор.
«Фишка» в том, что в Neutron можно строить виртуальные сети с достаточно большим количеством подсетей, а значит для них необходим виртуальный маршрутизатор. Каждый виртуальный маршрутизатор можно добавлять порты в любую из доступных виртуальных и внешних сетей. И это действительно «сильно»! Мы назначаем маршрутизаторам только только доступ к сетям, а всеми правилами firewall мы управляем из групп безопасности. Более того! Мы можем создать виртуальную машину с программным маршрутизатором, настроить интерфейсы во все необходимые сети и управлять доступом через него (я пробовал использовать Mikrotik).
В общем, Neutron даёт простор фантазии.
Создаём виртуальный маршрутизатор, назначаем ему интерфейс в demo-subnet и присоединяем его к внешней сети:
Теперь из внешней сети должен пинговаться наш виртуальный маршрутизатор:
В целом, у нас уже есть работоспособное облако с сетью.
Cinder (Блочное хранилище)
Cinder — сервис предоставляющий возможность управлять блочными устройствами (виртуальными дисками), присоединять их к виртуальным инстансам. Виртуальные диски могут быть и загрузочными. Это может быть очень удобно для переноса VM на другой вычислительный инстанс.
Установка необходимых пакетов:
Далее синхронизируем БД и перезапускаем сервисы:
Т.к. наш контроллер будет так же и хранилищем, то следующие действия так же проводим на нём.
Устанавливаем необходимые пакеты:
Помните я упоминал в конфигурации про два 500Гб диска? Мы из них сделаем RAID 1 (уж это описывать я не буду). Чисто технически, мы могли бы просто создать lvm-раздел из двух физических дисков, но такой вариант плох тем, что у нас не HA-проект и падение одного из дисков может быть критичным. Разбирать как создать RAID-массив я не буду, это легко гуглится. Будем считать, что наш рейд называется /dev/md1:
Мы создали физическое LVM-устройство и создали lvm-группу cinder-volumes.
Далее правим /etc/lvm/lvm.conf.
Находим (или добавляем) туда такую строку:
Будем считать, что кроме как на рейд-разделе у нас ничего связанного с lvm нет. Если рабочий раздел так же развёрнут на lvm, то следует его добавить. Например, если наша система развёрнута на /dev/md0 и поверх неё развёрнут lvm, то наш конфиг будет выглядеть так:
В целом, думаю для тех, кто сталкивался с lvm это не должно быть сложно.
Устанавливаем необходимые пакеты:
добавляем в конфиг:
И перезапускаем сервисы:
Horizon (dashboard)
Horizon — дашбоард для OpenStack, написан на Python 2.7, движком является Django. Из него ведётся полное управление всей средой OpenStack: управление пользователями/проектами/ролями, управление образами, виртуальными дисками, инстансами, сетями и т.д.
Установка
Установку можно производить на отдельном сервере с доступом к Controller-ноде, но мы установим на контроллере.
Поправим конфиг /etc/openstack-dashboard/local_settings.py:
TIME_ZONE — ваш часовой пояс может быть (и скорее всего будет) другой. Тут найдёте свой.
Теперь можно заходить на controller/horizon. В предыдущей моей публикации можно посмотреть скрины дашборда. В ubuntu дополнительно устанавливается пакет openstack-dashboard-ubuntu-theme, который добавляет некоторые ссылки с намёком на Juju. Если захочется вернуть оригинальную версию, то можно просто удалить пакет.
Так же можно в профиле пользователя выбрать язык интерфейса Русский, то изрядно облегчит работу Developer`ам.
Публикация получилась весьма громоздкая, но не хотелось разделять.
Надеюсь статья поможет кому-либо.
В следующей публикации (если мою карму не закидают «помидорами») буду описывать примитивную установку Chef-сервера и простого рецепта.
Русские Блоги
введение nova:
Назначение и функции:
1 Управление жизненным циклом экземпляра
2. Управление вычислительными ресурсами
3 Управление сетями и сертификацией
4 API стиля REST
5 Асинхронная и последовательная связь
6 Прозрачный гипервизор: поддержка Xen, XenServer / XCP, KVM, UML, VMware vSphere и Hyper-V

Как видно на рисунке выше, Nova находится в центре архитектуры Openstak, а другие компоненты обеспечивают поддержку Nova: Glance предоставляет образ для виртуальной машины, Cinder и Swift предоставляют блочное хранилище и хранилище объектов для виртуальной машины соответственно, а Neutron обеспечивает сетевое соединение для виртуальной машины.
Архитектура Nova выглядит следующим образом: 
nova-api: отправьте запрос в openstack для работы службы и вызовите службу, чтобы запустить новый экземпляр nova.
nova-scheduler: планировщик nova, используемый для выбора запроса для соответствующего запущенного экземпляра сервера.
nova-compute: управление основными службами виртуальных машин и реализация управления жизненным циклом виртуальных машин с помощью вызова API гипервизора.
nova-проводник: nova-compute часто требуется обновить базу данных, например обновить состояние виртуальной машины. По соображениям безопасности и масштабируемости
nova-compute не имеет прямого доступа к базе данных, но делегирует эту задачу nova-проводнику
nova-novncproxy: доступ к VNC через веб-браузер
nova-consoleauth: отвечает за аутентификацию токена для запросов на доступ к консоли виртуальной машины
Архитектура Nova более сложна и содержит множество компонентов. Эти компоненты работают как вспомогательные службы (фоновые процессы демона) и могут быть разделены на следующие категории:
nova-api
Это портал всего компонента Nova, который принимает и отвечает на запросы API клиентов. Все запросы к Nova сначала обрабатываются nova-api. nova-api предоставляет внешнему миру несколько интерфейсов HTTP REST API. В keystone мы можем запрашивать конечные элементы nova-api.
Затем клиент может отправить запрос на адрес, указанный endponits, и запросить операцию из nova-api. Конечно, как конечные пользователи, мы не будем отправлять запросы Rest API напрямую. OpenStack CLI, Dashboard и другие компоненты, которые необходимо обменять с Nova, будут использовать эти API.
Nova-api обработает полученный запрос HTTP API следующим образом:
Какие запросы принимает nova-api?
Проще говоря, если это операция, связанная с жизненным циклом виртуальной машины, nova-api может ответить. Большинство операций можно найти на панели инструментов. Откройте интерфейс управления экземплярами

Compute Core
nova-scheduler:
Служба планирования виртуальных машин отвечает за решение, на каком вычислительном узле запустить виртуальную машину. При создании экземпляра пользователь предложит требования к ресурсам, например, сколько потребуется ЦП, памяти и диска. OpenStack определяет эти требования в вариантах, и пользователям нужно только указать, какой вариант использовать (можно указать ЦП, память и диск).
Далее описывается, как nova-scheduler реализует планирование. В /etc/nova/nova.conf nova настраивает nova-scheduler с помощью параметра driver = filter_scheduler.
Nova позволяет использовать сторонний планировщик, просто настройте scheduler_driver. Это еще раз отражает открытость OpenStack. Планировщик может использовать несколько фильтров для фильтрации по очереди, а отфильтрованные узлы могут затем выбрать наиболее подходящий узел, вычислив вес.
nova-compute:
nova-conductor:
nova-compute часто требуется обновление базы данных, например обновление и получение статуса виртуальной машины. По соображениям безопасности и масштабируемости nova-compute не имеет прямого доступа к базе данных, но делегирует эту задачу nova-проводнику. 
Это дает два важных преимущества:
Console Interface
nova-console: пользователи могут получить доступ к консоли виртуальной машины различными способами
nova-novncproxy: доступ к VNC через веб-браузер
nova-spicehtml5proxy: доступ к SPICE на основе браузера HTML5
nova-xvpnvncproxy: доступ VNC на основе клиента Java
nova-consoleauth: отвечает за аутентификацию токена для запросов на доступ к консоли виртуальной машины
nova-cert: поддержка сертификата x509
Database
У Nova есть некоторые данные, которые необходимо сохранить в базе данных, обычно используется MySQL. База данных установлена на управляющем узле. Nova использует базу данных под названием «nova».
Message Queue
Ранее мы узнали, что Nova содержит множество вспомогательных услуг, и эти вспомогательные услуги должны координироваться и взаимодействовать друг с другом. Чтобы разделить подуслуги, Nova использует очередь сообщений в качестве станции передачи информации для подуслуг. Итак, на схеме архитектуры мы видим, что нет прямого соединения между подслужбами, но они связаны через очередь сообщений.

Из процесса создания виртуальной машины, чтобы увидеть, как под-сервисы nova- * работают вместе Как под-сервисы работают вместе

1. Заказчик (это может быть конечный пользователь OpenStack или другая программа) отправляет запрос к API (nova-api): «Помогите мне создать виртуальную машину»
2. После того, как API выполнит необходимую обработку запроса, он отправит сообщение в Messaging (RabbitMQ): «Разрешить планировщику создать виртуальную машину».
3. Планировщик (nova-scheduler) получает сообщение, отправленное ему API-интерфейсом из Messaging, а затем выполняет алгоритм планирования для выбора узла A из нескольких вычислительных узлов.
4. Планировщик отправляет сообщение в Messaging: «Создайте эту виртуальную машину на вычислительном узле A».
5. Compute (nova-compute) вычислительного узла A получает сообщение, отправленное ему планировщиком из Messaging, а затем запускает виртуальную машину на гипервизоре этого узла.
6. В процессе создания виртуальной машины, если Compute необходимо запросить или обновить информацию о базе данных, она отправит сообщение в Conductor (nova-проводник) через Messaging, а Conductor отвечает за доступ к базе данных.
Процесс запуска виртуальной машины OpenStack

Конфигурация
Узел управления
Установите nova в качестве администратора
Создать конечную точку службы
Создать пользователей места размещения
Установить как администратор
Создать конечную точку службы
Измените файл конфигурации
Импортировать базу данных nova-api
Импортировать библиотеку сертификатов
Создать сертификат cell1
Импортировать библиотеку nova
Посмотреть список сертификатов
вычислить узел






Узел управления обновляет базу данных
Файл конфигурации узла управления
[scheduler]
discover_hosts_in_cells_interval = 300
Автоматическое обнаружение вычислительных узлов
Education Ecosystem Blog
The Education Ecosystem Blog is a hub for in-depth development blogs and new technology announcements written by professional software engineers in the Education Ecosystem network
Featured in
5 вещей, которые следует знать об OpenStack

За последние несколько лет OpenStack привлек к себе немало внимания. Это можно объяснить тем, что крупные компании, такие как IBM, Cisco, Dell EMC, Red Hat и др., проявили интерес к платформе OpenStack.
Огромное внимание привлекло к себе мероприятие OpenStack Summit 2016, в частности на нем присутствовало более 7500 человек с различными интересами, выходцев из разных слоев общества и регионов. OpenStack уже вошел в общее употребление, и, следовательно, мы сосредоточимся на том, что следует знать об OpenStack каждому, кто только начинает пользоваться данной платформой. Если вы знаете, что такое OpenStack и как им пользоваться, тогда проходите мимо — эта статья не для вас! Возможно, вас заинтересуют другие обучающие видео, которые вы можете найти в видеоархиве LiveEdu.tv, перейдя по ссылке OpenStack tutorial videos.
Итак, давайте не будем больше откладывать и начнем наше знакомство с OpenStack.
1. Что такое OpenStack?
OpenStack — это платформа для облачных вычислений с открытым исходным кодом, ориентированная на предоставление бесплатных услуг, связанных с облачными вычислениями. В частности, это набор инструментов, которые могут быть использованы для управления любой платформой облачных вычислений как для частных, так и для публичных облаков. В создании OpenStack было задействовано сообщество разработчиков, целью которых было непрерывное развитие этой платформы. OpenStack предлагает системных подход управления комплексными услугами платформы облачных вычислений, которые включают в себя: обеспечение безопасности, систему хранения данных, межсетевое взаимодействие, управление работой виртуальных машин, отслеживание действий, происходящих внутри проекта, при помощи информационной панели и т.д.
OpenStack дает возможность компаниям полностью контролировать свои активы. Теперь, в случае необходимости расширения компаниям не придется полностью полагаться на собственные решения в области облачных вычислений. Например, если вы хотите добавить какую-либо деталь к вашему решению облачных вычислений, то вам всего лишь следует нанять OpenStack разработчика и все что вам необходимо он сделает за вас.
Другим огромным преимуществом использования OpenStack является возможность избежать привязки к поставщику, а также широкие возможности выбора основной технологии, возможность полностью контролировать систему, высокая производительность и экономия расходов. Если вы заинтересованы в том, чем руководствуются компании при выборе OpenStack, то всю необходимую информацию вы можете найти, перейдя по ссылке OpenStack Atlanta User Survey.
2. Компоненты OpenStack
OpenStack — это набор компонентов, осуществляющих совместную работу, целью которой является предоставление инфраструктуры как услуги. Благодаря открытой природе компонентов пользователь может применять такие компоненты в зависимости от собственных потребностей. Таким образом, именно пользователь имеет больше контроля над экосистемой, нежели программное обеспечение. Единственным способом достичь такой открытой структуры является объединение уникальных решений для различных частей облачной обработки данных. Давайте поближе рассмотрим компоненты, приведенные ниже.
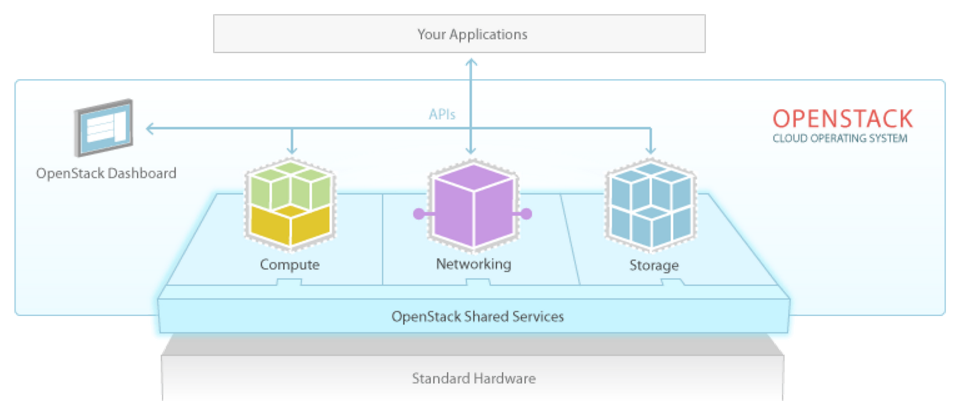
Nova — это контроллер, управляющий работой виртуальных машин OpenStack. Данный компонент предоставляет услуги в виде платформы, а также дает вам возможность управлять собственными гостевыми ОС. Nova отвечает за модуль управления и подготовку к работе, обеспечивающую корректную визуализацию. Помимо этого, Nova выступает в роли центра управления всей системой и, в частности, гипервизорами.
Swift — это система хранения различных файлов и объектов. Благодаря этой системе разработчики могут работать с уникальным идентификатором, при этом Swift может хранить информацию, необходимую данной системе. Такой метод обработки данных позволяет с легкостью масштабировать и облегчать работу с данными для разработчиков. Кроме того, Swift обеспечивает доступность к данным.
Cinder — это реализация блочного хранилища, принцип работы которого является схожим с принципом работы жесткого диска. Cinder является важным компонентом в платформе OpenStack, выступающей в роли предоставляемой услуги, ввиду определенных сценариев, требующих постоянного и быстрого доступа к данным. Использование Cinder позволяет беспрепятственно достичь этого. Помимо этого, тот факт, что в случае кратковременного завершения работы данные не будут потеряны позволяет разработчикам хранить необходимую информацию, используя блочное хранилище Cinder.
Neutron — это сетевой компонент OpenStack, ранее известный как Quantum, который обеспечивает надлежащее межсетевое взаимодействие между различными компонентами.
Horizon — это информационная панель в стиле Канбан, предназначенная для отслеживания всех действий, происходящих внутри OpenStack. Для пользователей, Horizon — это инструмент позволяющий отслеживать все, что происходит внутри платформы. Для разработчиков, Horizon — это работа с прикладным программным интерфейсом и его настройка для системных администраторов, которым предстоит проследить за тем, что работа облачной платформы со всей информацией, к которой она получает доступ, происходит с максимальной эффективностью.
Keystone — играет роль идентификатора и картографического сервиса для приложений и пользователей. Благодаря данному сервису разработчик может отобразить в виде карты необходимые пользователю сервисы и приложения в облаке, и, кроме того, системные администраторы имеют возможность установить права доступа и управлять ими.
Glance — это инструмент, предназначенный для хранения образов виртуальных машин. Glance позволяет легко обрабатывать образы или настраивать виртуальные машины и шаблоны для постоянного использования.
Ceilometer — отвечает за всю информацию, связанную с метрикой и/или счетами. Эта услуга имеет решающее значение для формирования счетов и обработки ресурсов.
Heat — обеспечивает хранение в едином файле всей информации облачных приложений. Данный компонент оркестровки является необходимым при запуске любого облака и способствует работе разработчиков по управлению инфраструктурой.
3. Проблемы безопасности
OpenStack — это достаточно новый проект по сравнению с другими разработанными решениями в области облачных вычислений. Тот факт, что OpenStack является проектом с открытым исходным кодом способствует его работе, однако обеспечивать безопасность кодовой базы, которая состоит из 5 миллионов строк кода, является достаточно сложной задачей для проекта с открытым исходным кодом. Данная платформа является постепенно развивающейся, а постоянно происходящие изменения кода делают эту платформу более безопасной, надежной и многофункциональной.
Безопасность является важным фактором в облачной вычислительной среде. Многие компании не решаются вкладывать инвестиции в платформы, если их данные не защищены. Тем не менее, есть и хорошие новости, которые заключаются в постоянном выпуске обновлений системы безопасности, причем команда разработчиков постоянно работает над повышением эффективности, безопасности и надежности проекта OpenStack.
4. Невероятное сообщество разработчиков
Нам уже хорошо известно, что проект с открытым исходным кодом, какой бы он ни был, полностью зависит от сообщества разработчиков. Ни один из проектов с открытым исходным кодом не достигнет своего полного потенциала без действующего сообщества разработчиков. OpenStack является обладателем одного из крупнейших сообществ разработчиков программного обеспечения с открытым исходным кодом, причем в подлинности такого заявления можно убедиться, перейдя по ссылке openhub.net page в раздел OpenStack, где и находится информация, подтверждающая невероятные цифры. Согласно этой информации OpenStack насчитывает более 353914 фиксаций изменений, внесенных 6118 участвующий в проекте разработчиками, что в итоге составляет 3716027 строк кода. И это по-настоящему много!
5. Приступая к работе с OpenStack
Понравилась команда разработчиков и масштабы, в которых происходит работа OpenStack? Вы также можете стать частью команды OpenStack. Вам необходимо всего лишь попробовать DevStack или TryStack. TryStack поможет новичку начать работать с OpenStack, поскольку этот сервис имеет уже готовый вариант рабочей среды. DevStack, наоборот, является сервисом для более продвинутых пользователей, начинать с которого будет достаточно тяжело.
Хотите узнать больше? Вы можете отслеживать ряд обучающих видео, расположенных по ссылке OpenStack tutorial streams, и, кроме этого, заглянуть на Learn page, чтобы узнать об основных технологиях, например Python, которые используются в OpenStack. Наш блог постоянно пополняется новыми учебными пособиями, а также статьями для вашего профессионального развития или для подготовки к новым видам работ, которые, несомненно, помогут вам стать более востребованным на рынке труда.
Заключительные мысли
Платформа OpenStack является важным шагом навстречу созданию облака, доступного каждому. Компании с потребительскими требованиями движутся в сторону решений с открытым исходным кодом, что само по себе является достаточно прагматичным подходом. Одной из основных проблем на рынке труда является отсутствие разработчиков OpenStack. Сообщество OpenStack постоянно обучает новых разработчиков, при этом все внимание сообщества сосредоточено на улучшении рынка труда. Однако для того чтобы такой рынок вырос и стал стабильным должно пройти какое-то время.
Если вы заинтересованы в облачной обработке данных, то OpenStack может стать вашим помощником на пути получения большого учебного опыта, поскольку он является платформой с открытым исходным кодом. Так чего же вы ждете? Вы можете начать изучать его прямо сейчас и даже заявить о себе, поделившись своим учебным опытом на сайте LiveEdu.tv с такими же как и вы!
Оцените видео, в котором рассказывается об изучении OpenStack при помощи языка программирования Ruby.
Дайте нам знать о том, что вы думаете об OpenStack и о будущем этого проекта? Мы бы очень хотели узнать ваше мнение, которое вы можете оставить в комментариях ниже.


