40 ГБ памяти и TDP 250 Вт. Nvidia A100 PCIe — первая графическая карта компании с PCIe 4.0
Это ускоритель вычислений для ИИ
В мае компания Nvidia представила графический ускоритель A100, который ранее назывался бы Tesla A100, но компания решила избавляться от бренда Tesla, чтобы не было путаницы с известным американским автогигантом.
Nvidia A100 основана на монструозном GPU GA100, состоящем из 54 млрд транзисторов. Карта содержит 6912 ядра CUDA (из 8192 ядер, имеющихся в GPU) и обеспечивает производительность 19,5 TFLOPS (FP32) либо 9,7 TFLOPS (FP64). При этом представленная в мае A100 имеет форм-фактор SMX. И вот сегодня, согласно данным источника, Nvidia представила A100 PCIe, то есть версию с соответствующим интерфейсом. При этом речь идёт о PCIe 4.0, и это первый графический адаптер компании с этим интерфейсом и соответствующим исполнением.

Несмотря на практически идентичные названия, карты очень сильно отличаются. Сама Nvidia утверждает, что версия PCIe при постоянной нагрузке на 10-50% менее производительна, чем версия SXM, хотя пиковые показатели одинаковы. TDP новой модификации составляет всего 250 Вт, тогда как карта SXM характеризуется значением 400 Вт. Не уступает старшей сестре новая версия и по объёму памяти. Это всё те же 40 ГБ HBM2. Конфигурация GPU также осталась неизменной.
Скорее всего, Nvidia A100 PCIe будет ощутимо дешевле версии SXM, но пока цен мы всё равно не знаем.
Разбираем редкого зверя от Nvidia — DGX A100

Крупные IT-компании располагают дорогими «игрушками», которые скрыты от взоров большинства пользователей. Сегодня мы приоткроем завесу тайны и расскажем про систему, которая оптимизирована для работы с искусственным интеллектом.
Задачи ИИ предъявляют высокие требования к вычислительным и сетевым ресурсам, поэтому наш сегодняшний «гость» приятно порадует своей конфигурацией. Встречайте: NVIDIA DGX A100.
Встречают по одежке
Техника безопасности предписывает использовать механический лифт для работы с сервером
NVIDIA DGX A100 — это стоечный сервер, высотой в 6U и массой более 130 килограмм. Сервер даже в коробке способен повергнуть в легкий трепет. Большой корпус и красивый золотистый цвет притягивают взгляды проходящих мимо коллег.
Сервер прибыл в сопровождении инженера, который оказывал нам как физическую, так и моральную поддержку. Пока наши сотрудники снимали упаковку и готовили инструменты для транспортировки сервера к месту установки, инженер рассказывал интересные факты об этом сервере. Так, техника безопасности предписывает использовать лифт для монтажа в стойку, а для разборки сервера нужно минимум два человека.
Количество портов ввода-вывода на этом сервере зашкаливает
Корпус сервера не открывается сверху. Вместо этого в задней части сервера есть два трея — это составные части сервера, которые содержат «начинку» сервера. Обратите внимание, что винты-фиксаторы треев в шасси окрашены в зеленый цвет, а фиксаторы крышки трея — в черный.
В глаза бросается шесть блоков питания по 3 КВт каждый с возможностью горячей замены. Интересно, что максимальное заявленное энергопотребление — 6.5 КВт. Разгадка проста: блоки питания работают по схеме 3+3, то есть резервирование 2N. Большинство обычных корпусов для GPU предоставляют 4 блока питания и схему 3+1.
На нижнем трее видно десять портов сетевых карт с пропускной способностью до 200 Гбит/с. По умолчанию двухпортовая карта сконфигурирована в режиме Ethernet, а остальные — в режиме Infiniband. Эти сетевые карты используются для объединения нескольких DGX в вычислительный кластер. У нас всего один DGX, поэтому порты не используются.
Один из суперкомпьютеров России, Кристофари, собран из 75 серверов DGX-2, в основе которого лежат графические ускорители предыдущего поколения.
Сперва мы хотели попытаться запустить DGX самостоятельно, но, к сожалению, столкнулись с неожиданной проблемой. Во время пуско-наладочных работ сервер вывел ошибку связи с BMC и раскрутил все вентиляторы до 18 000 оборотов в минуту. При помощи сопровождающего инженера ошибка была устранена, и сервер стал работать в штатном режиме. Даже в процессе стресс-тестирования на такие обороты он больше не выходил.
В ходе тестов было выявлено, что данная крышка не имеет значительного влияния на теплоотвод, вентиляторы сервера отлично справляются со своей работой.
После внешнего осмотра сервер был перенесен на прочный стол и разобран.
Филигранная техника
Специфические коннекторы GPU-трея
Как уже говорилось ранее, сервер состоит из двух треев: CPU и GPU. Каждый трей — это часть сервера, заключенная в свою железную коробку, которая установлена в шасси. Связь между треями, вентиляторами и корзинами на передней панели обеспечивает объединительная плата, установленная в корпусе. В некотором смысле DGX — это классическое blade-шасси, только вместо отдельных серверов (лезвий) устанавливаются части одного сервера.
GPU-трей. Много радиаторов
Вверху находится GPU-трей, занимающий 3U. Он тяжеловат даже для двух человек. На верхней крышке трея также есть предупреждающий знак о тяжести объекта и необходимости работать с ним вдвоем.
В этом трее установлены восемь видеокарт NVIDIA Tesla A100 в модификации 40 GB. Их особенностью является форм-фактор SXM4. Данная версия видеокарты отличается мезонинным исполнением и повышенным тепловыделением: 400 Вт против 300 у PCIe-версии.
Помимо восьми больших радиаторов видеокарт, на трее расположены шесть радиаторов поменьше. Эти радиаторы охлаждают микросхемы, которые реализуют интерконнект видеокарт. Технологии NVLINK и NVSWITCH соединяют восемь видеокарт многосвязной топологией (каждая видеокарта соединена с каждой) с пропускной способностью 600 Гбит/с.
CPU-трей. Здесь тоже много радиаторов
CPU-трей имеет два способа извлечения: полное и частичное.
Во втором случае трей выезжает из шасси чуть больше чем на длину части с PCIe-слотами и фиксируется, а крышка трея открывается вверх. Это позволяет провести работы с сетевыми картами или накопителем для ОС, не извлекая трей целиком.
Со стороны CPU-трей выглядит как обычный 2U сервер без блоков питания. Под большими радиаторами прячется пара процессоров AMD EPYC 7742, суммарно 128 физических ядер или 256 логических. Рядом стоят шестнадцать планок DDR4 с частотой 3200 МГц и объемом 64 ГБ каждая. Суммарный объем оперативной памяти 1 ТБ.
Интересно, что радиаторы процессоров расположены друг за другом, то есть второй процессор охлаждается теплом первого. Тем не менее, с системой охлаждения DGX это выглядит незначительно. Непривычно большие радиаторы заметны и на этом трее. Взаимодействие с GPU-треем создает большую нагрузку на PCIe-мосты, которые тоже требуют охлаждения.
Электронный город
Между слотами находится небольшая плата с максимальной плотностью электронных компонентов. Это выглядит как маленький электронный город. Здесь узнается чип ASPEED, который является «сердцем» BMC-модуля. Помимо этого, здесь есть модули доверенной загрузки, которые обеспечивают безопасность платформы.
Существует «старшая» модификация DGX A100 на 640 ГБ видеопамяти. В ней объем оперативной памяти расширен до 2 ТБ, а также увеличен объем постоянного хранилища.
На этом знакомство с внутренним миром DGX закончено. Давайте посмотрим на него в работе.
Душа титана
Для отображения всех ядер в htop разрешения 203×53 мало
В коробке с DGX лежит флешка, а на флешке — подготовленный образ операционной системы для начала работы. Основой образа является операционная система Ubuntu 20.04.3 LTS с предустановленными драйверами и специальными утилитами.
Сервер, который мы запускаем, прошел длинный путь, в ходе которого был разобран и собран. После транспортировки и манипуляций стоит проверить целостность систем сервера. По регламенту установки операции, сопряженные с первым запуском DGX, должен проводить сопровождающий инженер, но нам было очень любопытно, поэтому все операции проводились совместно.
Часть операций производится через утилиту nvsm, консольный интерфейс для nvidia system management. Всего одна команда проверит «теоретическое» состояние сервера:
Команда проверяет все, до чего может «дотянуться», а именно:
Следующий этап регламента — запуск стресс-теста. Это не только проверит систему в работе, но заодно предоставит нам информацию о максимальном практическом энергопотреблении и температуре на различных компонентах сервера. В этой задаче также помогает утилита nvsm.
Стресс-тест сделан достаточно удобно. Утилита нагружает процессор, видеокарты, оперативную память и постоянное хранилище и начинает отслеживать системные события, температуры, обороты вентиляторов и энергопотребление. Через 20 минут, в конце теста, выводится табличка статистики.
Здесь видно, что температура процессоров и видеокарт не превышала 69 градусов, при этом вентиляторы работали чуть меньше, чем в полсилы. Энергопотребление составило 4.7 КВт, что почти на два киловатта меньше заявленного в спецификации. Впрочем, данный стресс-тест не учитывает десяти внешних сетевых карт, да и наша версия DGX не старшая.
Теперь, когда сервер проверен и готов к работе, хочется провести тесты, чтобы узнать, на что способна эта машина для вычислений. Хотя данный сервер больше предназначен для задач ИИ, желания провести обычные тесты никто не отменял.
Мы начали с GeekBench 5 Compute. К сожалению, данный бенчмарк не задействует интерконнект между видеокартами и тестирует исключительно одно устройство за раз. Тем не менее, с его помощью можно сравнить, насколько SXM4-версия Tesla A100 лучше, чем PCIe-версия.
| Категория | PCIe Tesla A100 40G | SXM4 Tesla A100 40G |
|---|---|---|
| OpenCL | 170137 | 188380 (+11%) |
| CUDA | 213899 | 234890 (+10%) |
| Категория | PCIe Tesla A100 40G | SXM4 Tesla A100 40G |
|---|---|---|
| Inference Score | 25177 | 30158 (+20%) |
| Training Score | 23775 | 27837 (+17%) |
| AI Score | 48952 | 57995 (+19%) |
В качестве тестирования задач ИИ был выбран MLPerf от MLCommons. На сайте NVIDIA упоминается этот тест, а в турнирных таблицах MLPerf встречаются результаты старшей версии DGX A100 за авторством производителя.
Несмотря на наличие инструкции и четкий регламент, большинство тестов не запускалось из-за ошибок в зависимостях Docker-контейнеров. Однако вместе с DGX A100 поставляется контракт на техническую поддержку, который включает в себя в том числе возможность пообщаться с экспертами в области ИИ, а также удаленную помощь с настройкой ПО.
На данный момент у нас нет возможности сравнить DGX A100 с сервером с восемью Tesla A100 без интерконнекта, поэтому тестирование MLPerf пока отложено до момента появления тестового стенда с необходимой конфигурацией.
Заключение
NVIDIA DGX A100 — мощный сервер, призванный ускорить решение задач, связанных с искусственным интеллектом. DGX имеет множество сложных технических нюансов и особенностей, но их нельзя прочувствовать на паре общих тестов производительности. Чтобы узреть настоящую мощь этого сервера, нужно «потрогать» его самостоятельно.
Сервер предоставлен компанией Forsite. Forsite — российский производитель суперкомпьютеров и провайдер решений NVIDIA уровня Elite.
Графическая карта с 40 ГБ памяти и шиной с пропускной способностью 4,8 ТБ/с. Параметры ускорителя Nvidia Tesla A100 просто невероятны
Хотя остаются вопросы
Обновлено: состоялся официальный анонс Nvidia Tesla A100, и часть информации в этом материале оказалась ошибочной. Рекомендуем обратиться к новости с подтвержденными сведениями об A100 и рабочей станции DGX A100.
Несмотря на то, что на сайте Nvidia ещё никакой информации ни о топовом GPU Ampere, ни об ускорители Tesla A100, в Сети уже появились подробные данные.
Напомним, сегодня мы уже узнали о том, что GPU, который некоторые источники называют не GA100, а A100, содержит невероятные 54 млрд транзисторов, а ускоритель Tesla A100 превосходит Tesla V100 в задачах ИИ и вычислениях с одинарной точностью (FP32) в 20 раз.
Теперь же появились подробности о конфигурации Tesla A100, хотя к этим данным есть вопросы. Начнём с того, что источник говорит о наличии у ускорителя 6912 ядер CUDA FP32 и 3456 ядер FP64, и совершенно неясно, что имеется в виду. Учитывая, что сам GPU относительно предшественника содержит более чем вдвое больше транзисторов, конечно, можно предположить, что в его конфигурацию входит более 10 000 ядер CUDA, но это вряд ли. К тому же другой источник считает, что сам GPU GA100 включает 8192 ядра CUDA, а в Tesla A100 просто активны не все. И это нормальная практика, однако и тут всё сходится не очень хорошо, ибо получается, что в топовом специализированном графическом ускорителе неактивно около 15% всех ядер, что было бы странно. К примеру, в Tesla V100 у графического процессора были отключены лишь 5% имеющихся у него ядер. Таким образом, этот вопрос пока остаётся открытым.

Также источник сообщает о наличии 432 тензорных ядер, 40 ГБ памяти HBM2e с 5120-разрядной шиной. Что интересно, при всей невероятной мощности TDP ускорителя составляет лишь 400 Вт. Да, в абсолютном выражении это очень много, но относительно характеристик, напротив, можно было бы ожидать большего.
Но это, конечно, не всё. Nvidia заявляет, что с GPU GA100 ей удалось добиться крупнейшего скачка производительности за все восемь поколений GPU, что стало возможным благодаря пяти технологическим прорывам.
Судя по всему, сюда входит новый семинанометровый техпроцесс TSMC, гигантское количество транзисторов, новые тензорые ядра третьего поколения, которые впервые поддерживают операции с плавающей запятой с одинарной и двойной точностью, межсетевое соединение NVLink с пропускной способностью в 4,8 ТБ/с (600 ГБ/с при подключении GPU-GPU), а также некая возможность «разделения» одного GPU на семь отдельных кластеров, каждый из которых якобы может выступать в роли отдельного графического процессора, но подробностей, к сожалению, нет.

Nvidia пока не называет цену ускорителя Tesla A100, но вот станция DGX A100 с восемью такими адаптерами обойдётся покупателям в 200 000 долларов.
Видеокарта NVIDIA Tesla A100 в майнинге
Видеокарта NVIDIA Tesla A100 отлично подходит для майнинга. Далее мы подберем оптимальные параметры разгона для майнинга на NVIDIA Tesla A100. Выясним какие драйвера использовать наиболее правильно и эффективно. Посмотрим на основные характеристики и замерим хешрейт для популярных алгоритмов.
Характеристики
NVIDIA Tesla A100 была выпущена 14 мая 2020 г. Среднее энергопотребление – 250,0W. Максимальная допустимая температура графического чипа — 94 °C
Доходность NVIDIA Tesla A100
Текущая рыночная цена и доходность видеокарты NVIDIA Tesla A100 в майнинге колеблется в зависимости от стоимости криптовалюты. Информация в табличке обновляется один раз в день.
Посмотрите полную таблицу доходности видеокарт с возможностью сортировки по цене, доходу и окупаемости.
| Цена |  ETH |  ETC |  EXP |  UBQ |  RVN |  BEAM | Прибыль | Окупаемость |
|---|
Хешрейт NVIDIA Tesla A100
Мы составили таблицу хешрейта NVIDIA Tesla A100 для популярных алгоритмов. Если вы только выбираете видеокарту для майнинга, и уже знаете какую монету будете добывать, то по таблице можете оценить примерную производительность. А еще у нас есть статья о том, что такое хешрейт.
Драйвер NVIDIA Tesla A100
При установке драйверов NVIDIA Tesla A100 всегда рекомендуется сначала удалять текущие драйверы. Таким образом вы точно сможете быть уверены, что драйверы DCH не будут установлены Windows 10.
Вы можете загрузить драйверы NVIDIA Tesla A100 здесь. Мы рекомендуем попробовать разные версии драйверов. Некоторые версии драйверов могут приводить к проблемам во время майнинга. Установка более старой версии может исправить проблему.
Разгон NVIDIA Tesla A100 для майнинга
Разгонять NVIDIA Tesla A100 для майнинга будем программой MSI Afterburner. Вы можете найти ее в яндексе. Интерфейс программы очень простой, хоть и немного пестрый) Для разгона видеокарты нам понадобиться два ползунка:
Менять значения частоты нужно по немного. Затем тестировать стабильность работы. Если все хорошо, то увеличиваем частоту еще. Если видеокарта начала сбоить или вылетать драйвера, то просто уменьшаем частоту и все. Вреда никакого не будет. Далее мы рассмотрим параметры разгона для популярных алгоритмов.
Разгон NVIDIA Tesla A100 под Эфир
Для разгона NVIDIA Tesla A100 для майнинга эфира или других монет на алгоритме DaggerHashimoto нужно увеличивать частоту память, а ядро наоборот занижать для экономии энергии т.к. оно не влияет на скорость добычи.
Обзор вычислительной архитектуры Nvidia Ampere и графического процессора A100
Оглавление
Каждую весну компания Nvidia собирает GPU Technology Conference — большую конференцию с несколькими тысячами участников, посвященную аспектам применения графических процессоров в различных сферах. Основная часть конференции проходит в калифорнийском городе Сан-Хосе, и чаще всего именно на ней глава компании Дженсен Хуанг представляет новые архитектуры. Наш сайт по возможности старается не пропускать эти мероприятия, публикует новости с них и большие отчетные статьи. В новостях про Ampere и A100 мы уже вкратце рассказывали, настало время более подробного материала.
По понятным причинам мартовская конференция в этом году была отменена, и ее формат был переведен в цифровой. Конечно же, это довольно серьезно повлияло и на анонсы Nvidia. Сначала программное выступление главы было отменено вовсе, вроде как, но в мае он все-таки решил выступить перед сообществом, представив несколько новых продуктов, технологий и идей. Главными из которых являются новая архитектура Ampere и первый вычислительный процессор A100 на ее основе. Сегодня мы расскажем обо всех их особенностях подробно настолько, насколько это возможно на данный момент.
Вычислительные решения Nvidia уже много лет используются в весьма требовательных к производительности сферах, таких как глубокое обучение, анализ данных, научные вычисления, анализ видеоданных, облачные сервисы и многих других. Именно решения этой компании предоставляют необходимые возможности по ускорению большого количества вычислительных задач с параллельной обработкой огромных массивов данных, которыми заняты современные серверы.
Nvidia является одним из лидеров в деле освоения задач искусственного интеллекта, они предлагают вычислительные платформы, дающие многократный прирост в приложениях, использующих нейронные сети. Также их процессоры обеспечивают отличную скорость и в более традиционных высокопроизводительных вычислениях и при анализе больших объемов данных. Важно, что вычислительная платформа Nvidia универсальна, решения предлагаются в различных вариантах, от миниатюрных изделий для небольших роботов до мощнейших суперкомпьютеров.
В уже довольно далеком 2017 вышел ускоритель Tesla V100 с новым типом вычислительных блоков — тензорными ядрами, которые позволили в разы увеличить производительность матричных вычислений в задачах глубокого обучения, использующих мощь нейросетей. Через год вышла Tesla T4 на основе архитектуры Turing с тензорными ядрами и различными улучшениями эффективности. Тензорные ядра затем появились и в массовых решениях линейки GeForce на основе этой же архитектуры, и они позволили раскрыть некоторые возможности ИИ, вроде метода повышения производительности 3D-рендеринга под названием DLSS, который использует способности тензорных ядер.
Но сегодня мы говорим не об играх, а о куда более серьезных применениях GPU. Мощные вычислительные решения компании показали отличные результаты в индустриальных тестах производительности и были хорошо приняты рынком, да и пользовательские продукты и решения для автопилотируемых автомобилей и роботов также завоевали определенный успех. Немалая его доля была достигнута и за счет программного обеспечения — весьма удачной платформы для разработки CUDA, включающей API, библиотеки, программные стеки и оптимизаторы — все это и помогло раскрыть возможности аппаратных решений Nvidia, которые выпускаются несколько лет подряд. Этой весной пришло время обновить архитектуру и выпустить новый ускоритель вычислений — A100.
Графический процессор Nvidia A100 Tensor Core
Для начала, давайте сразу разберемся с названиями, а то многих слегка запутали схожие названия, относящиеся к несколько разным вещам. GA100 — это внутреннее кодовое имя чипа, а A100 — наименование первого решения компании на основе этого чипа (аналогично GV100 и V100 для Volta). Это важно в том числе и потому, что технические характеристики полного чипа и решений на его основе могут отличаться. В частности, у A100 некоторые из исполнительных блоков неактивны, о чем мы подробно расскажем далее. А ведь есть еще и DGX A100 — уже готовая система Nvidia на базе одноименного процессора. Вот такая путаница.
Итак, вычислительный процессор «A100 Tensor Core» (полное название показывает важность тензорных ядер, но мы его сократим до A100) основан на новой архитектуре Ampere, и, по сравнению с аналогом из предыдущего поколения в виде Tesla V100, добавляет немало новых возможностей и обеспечивает более высокую производительность в различных типах вычислительных задач — ИИ, при анализе данных, в высокопроизводительных вычислениях и многих других задачах.
Также A100 обеспечивает гибкое масштабирование для вычислительных задач в составе рабочих станций с одним или несколькими GPU, в серверах, кластерах, облачных центрах обработки данных, суперкомпьютерах и т. д. Новый графический процессор позволяет создавать масштабируемые и универсальные высокопроизводительные центры обработки данных с разным количеством GPU, от одного до сотен штук.
Чип GA100 производится на тайваньской фабрике TSMC по новому для компании Nvidia техпроцессу N7 — они впервые используют 7 нм для производства своих GPU. Да и вообще, такой большой и сравнительно массовый чип на основе этого техпроцесса компания TSMC выпускает впервые — GA100 включает 54,2 млрд транзисторов и имеет площадь кристалла в 826 мм² (физические размеры чипа составляют порядка 26×32 мм). По словам главы компании Nvidia, они выжали максимум возможного из этого техпроцесса, и в это довольно легко поверить, глядя на характеристики нового GPU.
Кратко перечислим главные особенности A100. Во-первых, в нем применяется уже третье поколение тензорных ядер, которые были серьезно модифицированы, по сравнению с аналогичными исполнительными устройствами V100. Они стали более гибкими и производительными, а также получили некоторые нововведения, предназначенные для упрощения их использования разработчиками. Одним из самых важных изменений стал новый формат вычислений TensorFloat-32 (TF32) для задач ИИ, который способен повысить скорость таких вычислений до 10-20 раз для формата FP32 в уже существующих задачах — при этом, изменения кода не требуется.
Также тензорные ядра A100 поддерживают и формат вычислений FP64 (IEEE-совместимый), что повышает скорость работы в высокопроизводительных вычислениях до 2,5 раз по сравнению с Volta. Такой же прирост скорости новинка обеспечивает и для операций смешанной точности FP16/FP32 по сравнению с V100 — для этого пригодится еще один новый тип операций — Bfloat16 (BF16), который обсчитывается на той же скорости, что и операции со смешанной точностью FP16/FP32. Что касается ускорения INT8, INT4 и бинарных операций при инференсе в задачах глубокого обучения, то преимущество A100 в них может достигать 10-20 раз, а то и больше.
Для наглядности приведем таблицу возможностей A100 и V100 по вычислениям в основных форматах и на различных исполнительных блоках, которые используются в высокопроизводительных вычислениях и задачах ИИ (уточнение TC означает использование возможностей тензорных ядер). Все значения даны с учетом турбо-частоты GPU (1410 МГц), а значения в скобках — эффективная производительность с учетом разреженности данных, о которой написано далее.
| Пиковая производительность | V100 | A100 | Ускорение |
|---|---|---|---|
| A100 FP16 против V100 FP16 | 31,4 тфлопс | 78 тфлопс | 2,5× |
| A100 FP16 TC против V100 FP16 TC | 125 тфлопс | 312 (624) тфлопс | 2,5× (5×) |
| A100 BF16 TC против V100 FP16 TC | 125 тфлопс | 312 (624) тфлопс | 2,5× (5×) |
| A100 FP32 против V100 FP32 | 15,7 тфлопс | 19,5 тфлопс | 1,25× |
| A100 TF32 TC против V100 FP32 | 15,7 тфлопс | 156 (312) тфлопс | 10× (20×) |
| A100 FP64 против V100 FP64 | 7,8 тфлопс | 9,7 тфлопс | 1,25× |
| A100 FP64 TC против V100 FP64 | 7,8 тфлопс | 19,5 тфлопс | 2,5× |
| A100 INT8 TC против V100 INT8 | 62 TOPS | 624 (1248) TOPS | 10× (20×) |
Но это лишь пиковые теоретические цифры, вряд ли достижимые на практике. Давайте посмотрим на то, что получается в конкретных задачах. По данным самой компании Nvidia, графический процессор A100 обеспечивает увеличение производительности над V100 в реальных задачах по тренировке и инференсу ИИ, и преимущество новинки в них достигает нескольких раз.
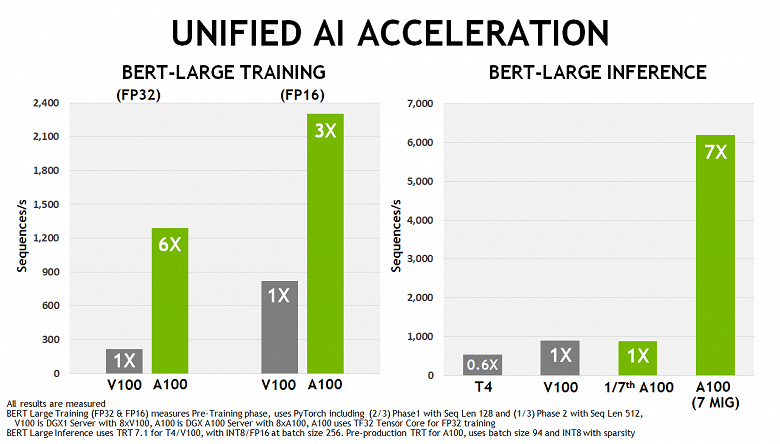
На диаграмме сравнивается скорость аналогичных 8-процессорных решений на основе вычислительных процессоров A100 и V100 в сценариях глубокого обучения BERT. При обучении нейросети, преимущество A100 составляет от 3 раз для FP16-точности до 6 раз для FP32 (на A100 автоматически используется формат TF32), а при инференсе A100 уже в 7 раз быстрее, так как позволяет запускать на одном чипе сразу семь виртуальных GPU, каждый со скоростью одного V100, чего вполне достаточно для этой нагрузки.
Понятно, что такие условия специально подобраны для того, чтобы показать новые возможности A100, да еще и используются несколько разные форматы вычислений, но и преимущество получилось очень большим. А что мы увидим в задачах высокопроизводительных вычислений, в которых новый GPU даже по теории должен быть мощнее лишь в пару-тройку раз от силы?
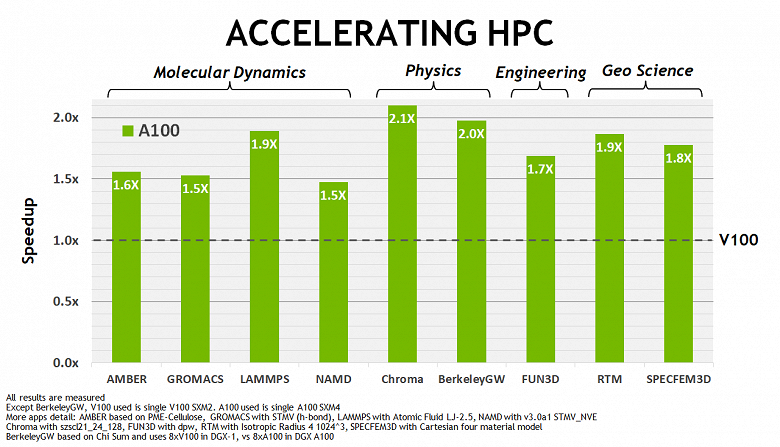
Судя по данным Nvidia, сразу в нескольких подобных задачах новый A100 показывает приличное ускорение, по сравнению с Tesla V100 — преимущество новинки в основном составляет 1,5-2 раза. Конечно, это заметно меньше, чем 6-7 раз в сфере ИИ, но ведь упор в случае Ampere делался в основном на тензорные операции. А для HPC-задач ускорение вдвое при даже меньшей теоретической разнице в пиковом темпе FP64-вычислений (если не брать возможности тензорных ядер), выглядит неплохо. Наверняка также сказываются и многочисленные оптимизации подсистемы памяти и кэширования. Обо всем этом мы сейчас и поговорим подробнее.
Архитектурные новшества Ampere
Все современные графические процессоры Nvidia состоят из укрупненных блоков — потоковых мультипроцессоров (streaming multiprocessor — SM), и архитектура Ampere и чип GA100 — не исключение. Как и более ранние графические процессоры компании Nvidia, новый чип состоит из нескольких кластеров GPU processing cluster (GPC), которые содержат кластеры текстурной обработки (TPC — texture processing cluster), а те, в свою очередь, составлены уже из потоковых мультипроцессоров (SM — streaming multiprocessor). Также в состав чипа входят контроллеры памяти (в случае GA100 — HBM2-памяти), кэш-память второго уровня и управляющая логика.
Полная модификация чипа GA100 включает 8 GPC из 8 TPC каждый, по два SM на каждый TPC — то есть 128 мультипроцессоров всего. Каждый мультипроцессор состоит из 64 CUDA-ядер для FP32-вычислений, и общее их количество на чип составляет 8192 штуки. Каждый мультипроцессор также имеет по четыре тензорных ядра, что дает в результате 512 тензорных ядер на GPU. Что касается видеопамяти, то на чипе может быть установлено до 6 стеков HBM2-памяти, которую обслуживают 12 контроллеров с шириной шины по 512 бит каждый.
А теперь внимание: в отличие от полной версии GA100, в конкретной модели A100, которая была анонсирована недавно, было отключено несколько исполнительных блоков. В частности, неактивен один из кластеров GPC, также может быть 7 или 8 разблокированных текстурных кластера на каждый GPC. То есть в целом эта версия чипа содержит лишь 108 мультипроцессоров SM с общим количество CUDA-ядер в 6912 штуки и 432 тензорными ядрами. Память тоже немного порезали — до пяти стеков HBM2-памяти и десятка 512-битных контроллеров.
Изменения в мультипроцессорах
Новый мультипроцессор архитектуры Ampere хоть и основан на том, что мы уже видели в Volta и Turing, но в него добавлены несколько новых возможностей. Так, мультипроцессоры прошлых двух поколений имеют по восемь тензорных ядер на SM, и каждое из них умеет исполнять 64 FMA-операции смешанной точности (FP16/FP32) за такт. А мультипроцессоры в GA100 имеют улучшенные тензорные ядра третьего поколения, которые исполняют по 256 FMA-операций FP16/FP32 за такт, поэтому вполне достаточно и четырех таких ядер на каждый SM, ведь общие вычислительные возможности GA100 даже в таком случае выросли вдвое по сравнению с Volta и Turing — с 512 до 1024 операций с точностью FP16/FP32 за такт.
Ключевые возможности мультипроцессоров Ampere:
Кроме разного количества блоков и описанной выше разницы в объеме L1-кэша и общей памяти, на схеме мультипроцессора все выглядит довольно знакомо. Единственное, что наметанный взгляд постоянного читателя нашего раздела может заметить, так это то, что на диаграмме нет RT-ядер, которые были в Turing. Все верно, аппаратной поддержки трассировки в GA100 нет. Но это неудивительно, ведь эта модель GPU — чисто вычислительный процессор, которому RT-ядра просто не нужны. Как и блок кодирования видеоданных NVEnc, например, и разъемы вывода информации на дисплеи. Все это обязательно появится далее в игровых решениях семейства GeForce и профессиональных графических видеокартах Quadro.
На следующей схеме показана разница в темпе исполнения стандартных операций над данными различных типов на процессорах V100 и A100: FP16, FP32 против TF32, FP64 и INT8, соответственно. Естественно, больше всего выросла производительность в тех случаях, когда вместо основных исполнительных блоков V100 вычисления проводятся при помощи тензорных блоков A100, которые получили расширенную поддержку разных форматов, да еще и с учетом возможности использования разреженности матриц на A100.
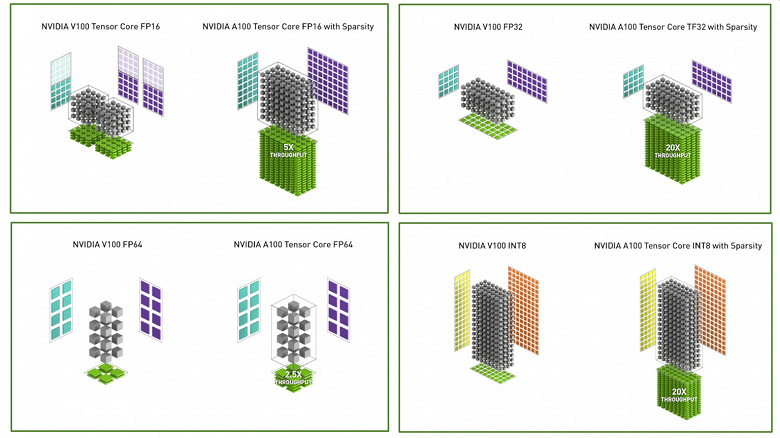
В случае с FP16-форматом у V100 показано два столбца тензорных ядер, так как каждый мультипроцессор этого GPU содержит по два тензорных ядра, а у A100 он всего один. Но все равно, с учетом разреженности, прирост скорости на Ampere достигает 5 раз в пике, а без разреженности — 2,5 раза, что тоже совсем неплохо.
Рассмотрим новый формат вычислений TensorFloat-32 (TF32) — он обеспечивает ускорение операций над данными в FP32-формате в задачах глубокого обучения хитрым образом. Для удобства числа с плавающей запятой представляются в экспоненциальной записи — к примеру, для формата FP32 один бит отводится на знак числа, 8 бит уходит на порядок (экспоненту), который определяет максимально возможный диапазон чисел, а оставшиеся 23 бита — на мантиссу, обеспечивающую точность вычислений.
Для FP16-формата меньше и порядок (лишь 5 бит) и точность (10 бит). Такие вычисления в современных GPU производятся значительно быстрее, но зачастую разработчикам в задачах глубокого обучения хватает и той точности, которая обеспечивается 10-битной мантиссой, но бывает недостаточно диапазона значений, который могут дать 5 бит в FP16-формате.
Поэтому сейчас большинство задач ИИ для обучения используют формат FP32, который не ускоряется на тензорных ядрах, и Nvidia вышла из положения хитрым образом, представив новый 32-битный формат вычислений TF32, обеспечивающий диапазон значений FP32 при точности FP16: 8-битная экспонента и 10-битная мантисса. Но самое главное — такие вычисления проводятся над FP32-значениями на входе, да и на выход подается именно FP32, и накопление данных при этом производится в формате FP32, так что точность не теряется.
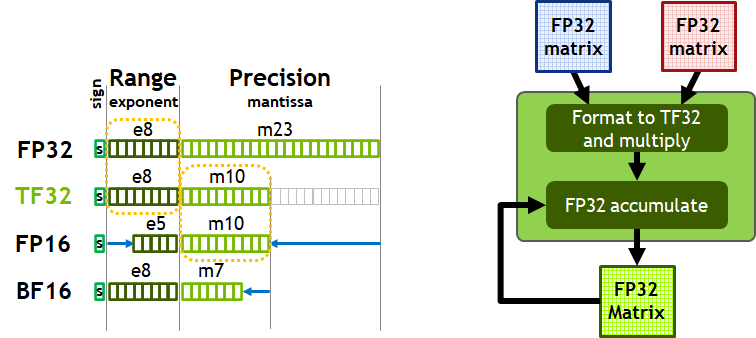
Архитектура Ampere использует TF32-вычисления при использовании тензорных ядер над данными формата FP32 по умолчанию, пользователю не нужно ничего делать для этого, он получит ускорение автоматически. А вот не тензорные операции будут использовать обычные FP32-блоки. Но на выходе в обоих случаях — стандартный IEEE FP32-формат. Автоматическое использование смешанной точности BF16 позволяет еще вдвое повысить производительность, по сравнению с TF32, но для этого понадобится поменять пару строк кода.
То есть для процесса обучения нейросетей у разработчика при использовании A100 есть два высокопроизводительных варианта:

Мы говорили о теоретических пиковых показателях, но на диаграмме выше можно оценить примерную производительность тензорных вычислений при перемножении матриц разных размеров по данным компании Nvidia. Как видите, использование новых типов тензорных операций над матрицами на A100 позволяет увеличить производительность вычислений в несколько раз. И это уже не теоретическая, а практическая производительность.
Ускорение высокопроизводительных вычислений на тензорных ядрах
Кроме задач искусственного интеллекта, не менее важными являются высокопроизводительные вычисления (HPC), и потребность в высокой скорости в таких системах растет огромными темпами. Такие вычисления используются большим количеством научных приложений, которые предпочитают формат двойной точности FP64 — именно по причине его высокой точности, простите за тавтологию.
Для того, чтобы улучшить характеристики A100 в этом плане, в Nvidia решили обеспечить новый графический процессор A100 возможностью исполнения таких операций и на тензорных ядрах, а не только основных. И A100 теперь поддерживает ускорение вычисления в IEEE-совместимом формате FP64 на тензорных ядрах, обеспечивая пиковую производительность в 2,5 раза выше, чему Tesla V100. Новая инструкция для совмещенного умножения-сложения матриц с двойной точностью у A100 заменяет сразу восемь DFMA-инструкций на V100, что сокращает количество выборок команд и чтение из регистров, снижает накладные расходы и требования к пропускной способности разделяемой памяти.
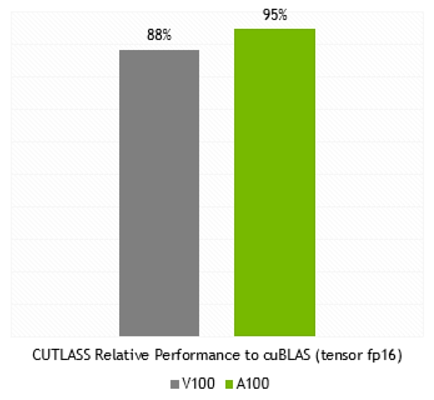
Каждый мультипроцессор SM умеет вычислять 64 такие FMA-операции с точностью FP64 за один такт (то есть всего 128 FP64-операций за такт), что вдвое больше, чем у Tesla V100. И 108 активных мультипроцессоров в составе A100 обеспечивают пиковую производительность для FP64 в 19,5 терафлопс, что в 2,5 раза больше, чем может V100. Причем, почти такой же прирост уже можно получить и в реальности — в cuBLAS DGEMM, умеющем использовать новые возможности A100.
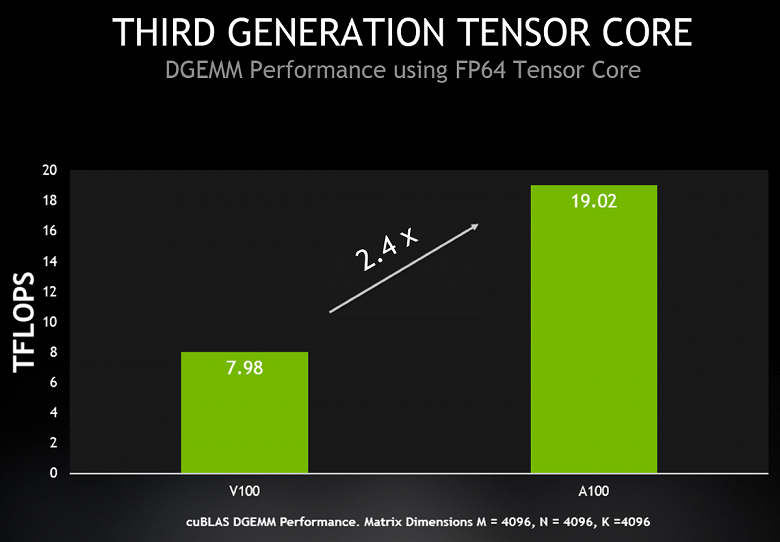
Приведем сводную сравнительную таблицу характеристик процессоров A100, V100 и P100, а также сравнение их пиковой теоретической производительности для разных типов данных и операций. В следующей таблице показаны отличия между GPU производства Nvidia трех разных поколений, с учетом их турбо-частот. В скобках указаны данные пиковой производительности A100 с учетом разреженности матриц, о которой написано в следующем разделе нашего материала.
| Модель GPU | P100 | V100 | A100 |
|---|---|---|---|
| Кодовое имя | GP100 | GV100 | GA100 |
| Архитектура | Pascal | Volta | Ampere |
| Техпроцесс, нм | 16 | 12 | 7 |
| Кол-во транзисторов, млрд | 15,3 | 21,1 | 54,2 |
| Площадь кристалла, мм² | 610 | 815 | 826 |
| Потребление энергии, Вт | 300 | 300 | 400 |
| Кол-во мультипроцессоров | 56 | 80 | 108 |
| Кол-во кластеров TPC | 28 | 40 | 54 |
| Кол-во FP32-ядер | 3584 | 5120 | 6912 |
| Кол-во FP64-ядер | 1792 | 2560 | 3456 |
| Кол-во INT32-ядер | — | 5120 | 6912 |
| Кол-во тензорных ядер | — | 640 | 432 |
| Турбо-частота, МГц | 1480 | 1530 | 1410 |
| Производительность тензорных FP16, терафлопс | — | 125 | 312 (624) |
| Производительность тензорных BF16, терафлопс | — | — | 312 (624) |
| Производительность тензорных TF16, терафлопс | — | — | 156 (312) |
| Производительность тензорных FP64, терафлопс | — | — | 19,5 |
| Производительность тензорных INT8, топс | — | — | 624 (1248) |
| Производительность тензорных INT4, топс | — | — | 1248 (2496) |
| Производительность FP16, терафлопс | 21,2 | 31,4 | 78 |
| Производительность BF16, терафлопс | — | — | 39 |
| Производительность FP32, терафлопс | 10,6 | 15,7 | 19,5 |
| Производительность FP64, терафлопс | 5,3 | 7,8 | 9,7 |
| Производительность INT32, топс | — | 15,7 | 19,5 |
| Кол-во текстурных модулей | 224 | 320 | 432 |
| Ширина HBM2-памяти, бит | 4096 | 4096 | 5120 |
| Объем памяти, ГБ | 16 | 16/32 | 40 |
| Частота памяти, МГц | 703 | 877,5 | 1215 |
| Пропускная способность памяти, ГБ/с | 720 | 900 | 1555 |
| Объем L2-кэша, МБ | 4 | 6 | 40 |
| Объем разделяемой памяти на SM, КБ | 64 | До 96 | До 164 |
| Объем регистрового файла, КБ | 14336 | 20480 | 27648 |
Хорошо видно, что с каждым поколением Nvidia не только тупо ускоряла математическую производительность исполнительных блоков GPU и увеличивала кэши, но и внедряла все более широкие возможности по исполнению специфических вычислений с повышенной производительностью, а также улучшала общую эффективность своих процессоров. В особенности это касается различных типов вычислений на тензорных блоках, но не только их. Увы, и без минусов не обошлось — потребление энергии новым GPU выросло с 300 до 400 Вт, и это — при отключенной части чипа. Похоже, что высокое потребление энергии является одним из его недостатков.
Использование разреженных матриц
В A100 также внедрили новую технологию структурированной разреженности (Structured Sparsity), которая помогает удвоить производительность вычислений над матрицами, используя разреженность данных. Разреженная матрица — это матрица с преимущественно нулевыми элементами в ней, и подобные матрицы довольно часто встречаются в приложениях, связанных с использованием ИИ.
Так как нейросети способны адаптировать весовые коэффициенты в процессе обучения на основе его результатов, то подобное структурное ограничение не особенно влияет на точность обученной сети для инференса, что позволяет выполнять его с разреженностью. Чтобы получить повышение производительности, нужно использовать разреженность на ранних этапах обучения, и подобное ускорение без потерь в точности является предметом для дальнейших исследований.
Структура использует определение разреженной матрицы в виде 2:4, которая допускает два ненулевых значения в каждом векторе с четырьмя входными значениями. A100 поддерживает структурированную разреженность 2:4 построчно, как показано на схеме. Благодаря четкой структуре матрицы, ее можно эффективно сжать, сократив требуемый объем памяти и пропускную способность почти вдвое.
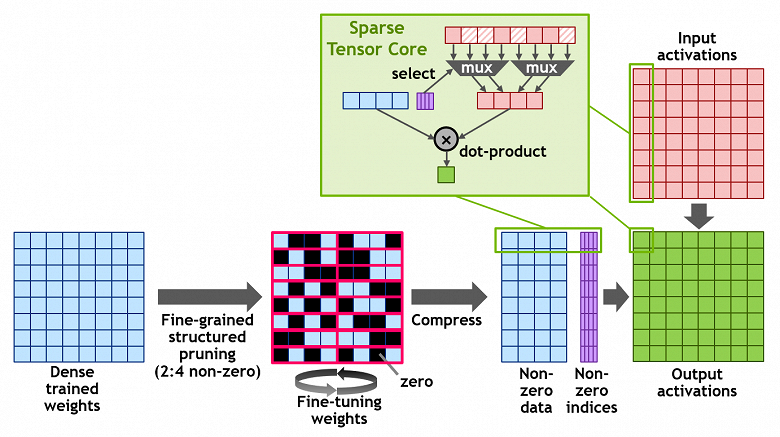
В Nvidia разработали универсальный метод прореживания нейросетей для инференса, используя структурированный шаблон разреженности 2:4. Сначала сеть обучается с использованием плотных весов, затем применяется мелкозернистое структурированное прореживание, а оставшиеся ненулевые веса корректируются на дополнительных этапах обучения. Такой метод вроде бы не приводит к значительной потере точности инференса на примере десятков проверенных специалистами компании нейросетей, включая задачи машинного зрения, определения объектов, сегментацию, перевод с одного языка на другой и т. д.
Чтобы все это работало, графический процессор A100 поддерживает новые инструкции Sparse Tensor Core, пропускающие вычисления для записей с нулевыми значениями, что и приводит к удвоению производительности вычислений, использующих разреженность матриц.
Одновременное исполнение операций FP32 и INT32
Как и все решения семейств Volta и Turing, новый GPU архитектуры Ampere A100 содержит отдельные вычислительные ядра FP32 и INT32, что позволяет одновременно исполнять соответствующие виды операций каждый такт, что увеличивает скорость выдачи команд. Мы уже неоднократно останавливались на этой возможности, которая помогает повысить производительность в некоторых задачах. Многие приложения содержат циклы, выполняющие вычисления целочисленных адресов памяти в сочетании с вычислениями с плавающей запятой, вот они и получат преимущество от одновременного исполнения операций FP32 и INT32.
Подсистема памяти и кэширования
Повышение производительности мультипроцессоров не имеет смысла без соответствующей поддержки со стороны подсистемы памяти и ее кэширования. Если просто повысить возможности исполнительных блоков, то «прокормить» их данными без увеличения пропускной способности и снижения задержек просто не получится, и роста производительности не произойдет.
Кэш-память первого уровня, объединенная с разделяемой памятью, была впервые представлена в Tesla V100, и это архитектурное решение значительно повысило производительность во многих задачах, а также упростило программирование, снизив необходимость в кропотливой оптимизации для того, чтобы добиться близкой к пиковой производительности. В A100 в полтора раза увеличили объем объединенного блока L1-кэша и общей памяти, по сравнению с их объемом в V100 — 192 КБ против 128 КБ на каждый мультипроцессор. Во многих задачах высокопроизводительных вычислений и ИИ одно это изменение дает приличный прирост производительности.
Так как требовательность высокопроизводительных вычислений, аналитики и задач ИИ к пропускной способности памяти и ее объему постоянно растут, то в Tesla P100 впервые внедрили HBM2-память, работающую с очень высокой пропускной способностью, а в Tesla V100 улучшили ее реализацию. Напомним, что тип памяти HBM2 отличается тем, что стеки чипов памяти расположены прямо на той же упаковке вместе с кристаллом графического процессора, что как раз и обеспечивает рост пропускной способности, а также снижение потребления и требуемой площади, по сравнению с традиционными типами памяти вроде GDDR5/GDDR6. Кроме роста ПСП, это решение также позволяет установить в серверы большее количество GPU.
Неудивительно, что и продукт на архитектуре Ampere получил определенные улучшения в этом плане. Новый графический процессор GA100 несет на себе 48 ГБ оперативной памяти типа HBM2 в виде шести стеков по 8 кристаллов, которые присоединены к GPU при помощи 12 контроллеров памяти с общей шириной шины в 6144-бит. Но конкретно модификация A100 слегка урезана и по возможностям памяти — в ней отключена пара контроллеров памяти и один стек HBM2, поэтому активными остались лишь пять стеков. Соответственно, общий объем памяти в новом решении сократился до 40 ГБ, а ширина шины до 5120 бит. И так как память в A100 работает на частоте 1215 МГц (DDR), то это обеспечивает пропускную способность памяти в 1,555 ТБ/с, что более чем в 1,7 раза выше пропускной способности памяти у V100.

Уточним, что мы говорим о конкретном решении A100, а у полного чипа GA100 видеопамяти установлено 48 ГБ — как понятно по фотографии чипа, они составлены шестью стеками. В случае A100 один из них отключен вместе с соответствующими контроллерами памяти. Интересно, что не участвующий в работе стек памяти полностью работоспособен, он просто отключен. Возможно, не ставить его на упаковку вовсе получается чуть ли не затратнее, чем просто отсоединить.
Вполне возможно, что со временем компания Nvidia выпустит и более мощное решение на основе полноценного GA100. Вероятнее всего, сейчас они упираются в высокое энергопотребление и тепловыделение A100, достигающее 400 Вт. К слову, количество памяти в 40 ГБ и не слишком сильно смотрится на фоне 32 ГБ у последней модификации V100, ведь все остальные характеристики чипа увеличили в два и более раз.
Подсистема памяти A100 HBM2 поддерживает исправление ошибок ECC с исправлением одиночной ошибки (single-error correcting double-error detection — SECDED) для защиты данных. ECC обеспечивает более высокую надежность для вычислений, чувствительных к повреждению данных, что важно в масштабных многокластерных вычислительных средах, в которых GPU обрабатывают большие объемы данных на протяжении длительного времени. В A100 также защищены SECDED ECC и другие структуры памяти — кэш-память первого и второго уровней, а также регистровые файлы в мультипроцессорах.
Еще более важными являются изменения в кэш-памяти второго уровня, которые можно назвать чуть ли не революционными! Графический процессор GA100 содержит 48 МБ кэш-памяти второго уровня, а модификация A100 лишена его 1/6 части, поэтому активным объемом является 40 МБ, что в 6,7 раз больше, чем у V100 — и это очень большой прирост! Такой объем кэша позволит заметно реже лазить в разы более медленную видеопамять, и это увеличит производительность во многих вычислительных задачах.
Инженеры Nvidia пришли к такому объему опытным путем — проверяя, что дают разные объемы кэша в имитации различных типов вычислений. Ну и новый техпроцесс позволил им добавить много L2-кэша, оставаясь в рамках определенного размера кристалла, конечно же. Возможно, эти лишние транзисторы также пригодились и для того, чтобы сделать кристалл физически большего размера — для более эффективного отвода тепла от него.
Но мы отвлеклись, а ведь интересное в этом разделе только начинается. Если вы обратите внимание на диаграмму чипа или фото его ядра, то заметите новую структуру разделенного кэша с кроссбаром. L2-кэш в GA100 разделен на два раздела — для того, чтобы обеспечить более широкую полосу пропускания и снизить задержки доступа к памяти для каждой половины мультипроцессоров. Каждый из двух разделов L2-кэша локализует и кэширует данные для доступа к памяти от мультипроцессоров в тех кластерах GPC, которые напрямую подключены именно к этому разделу.
Такая структура позволила увеличить пропускную способность L2-кэша в 2,3 раза по сравнению с V100. Специалистам Nvidia пришлось так сделать, так как аналогичное V100 решение кэширования второго уровня попросту было бы неспособно прокормить данными увеличенное количество более мощных мультипроцессоров конфигурации Ampere, ведь их требования превышают возможности L2-кэша Volta в 1,3-2,5 раза, как видно по прикидкам:

На схеме показано, что гипотетический V100 с улучшенными до уровня A100 тензорными ядрами не смог бы получить достаточное количество данных из кэш-памяти. Правда, с разделенным L2 в редких случаях задержки могут и увеличиться, если какому-то мультипроцессору вдруг понадобятся данные из другого раздела. Но это лишь в теории. Когерентность кэша на аппаратном уровне поддерживается моделью программирования CUDA, и приложения автоматически будут использовать преимущества новой организации L2-кэша.
Существенное увеличение объема L2-кэша в GA100 значительно повышает производительность многих алгоритмов высокопроизводительных вычислений и задач ИИ, так как это позволяет кэшировать большие части наборов данных и моделей, получая доступ к ним с гораздо большей скоростью и меньшими задержками, по сравнению с чтением и записью в память HBM2. Некоторые рабочие нагрузки, ограниченные именно ПСП, вроде нейросетей с небольшим размером пакетов, больше других выиграют от увеличенного объема L2-кэша, и разница в скорости будет многократной.
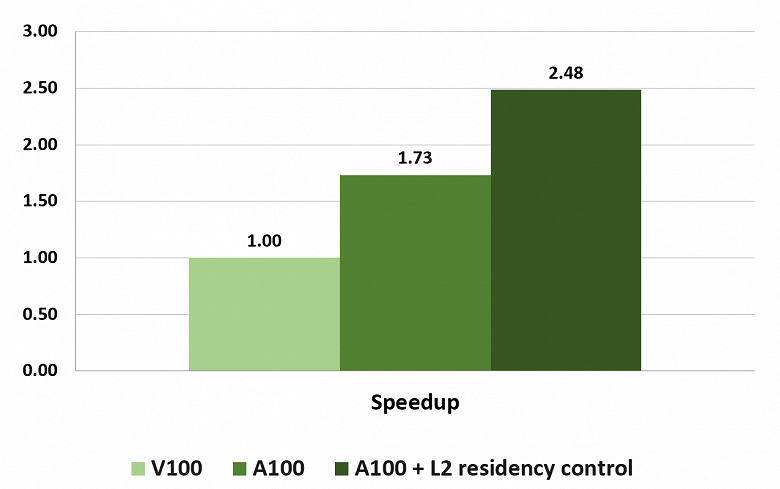
А чтобы оптимизировать использование столь немалого объема кэш-памяти, в архитектуре Ampere появилась возможность управления процессом кэширования данных в L2-кэше. A100 предоставляет новые элементы управления L2-кэшем для указания данных, которые нужно хранить в кэш-памяти. Так, в A100 можно прямо выделить часть L2-кэша (максимум до 30 МБ) для постоянного сохранения некоторых данных.

Например, для задач глубокого обучения, пинг-понг буферы можно постоянно закэшировать в L2-кэше для максимально быстрого доступа к этим данным, как и для предотвращения их обратной записи в HBM2-память. И для реализации модели «поставщик-потребитель» при обучении нейросетей, при помощи управления L2-кэшем также можно оптимизировать процесс кэширования, как и во многих других задачах. Увеличение производительности в некоторых из применений добавляет к уже и так неплохим результатам A100 по сравнению с V100, еще и дополнительный весомый прирост.
Но и это еще не все изменения в подсистеме памяти архитектуры Ampere. Также была добавлена возможность сжатия данных, находящихся в L2-кэше и локальной памяти GPU. Nvidia не делится конкретным алгоритмом, но это довольно простой метод сжатия без потерь, когда сжимаются данные с нулями или одинаковыми значениями. Берутся две соседние строки L1-кэша — 8 блоков по 32 байта, в них ищутся одинаковые байты. Если таких байтов достаточно много, то один или несколько из 32-байтных блоков в L2/глобальную память не попадает.

Сжатие данных обеспечивает увеличение пропускной способности чтения и записи HBM2-памяти и чтения из L2-кэша до четырех раз (запись в L2 ускоряется вдвое), и до двукратного увеличения эффективного объема L2. Причем, подобного ускорения можно добиться и во вполне реальных примерах — например, в задаче линейной алгебры SAXPY (Scalar Alpha X Plus Y) — скалярном умножении и векторном сложении с разным количеством блоков:
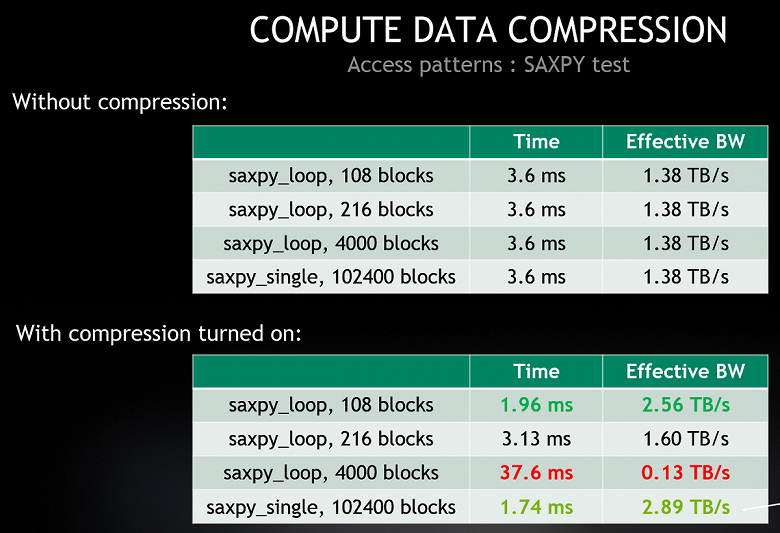
Как видите по таблице, сжатие данных не всегда приводит к положительному результату, возможен и обратный пример, когда оно не просто бесполезно, но даже вредит. Зато когда работает эффективно, то прирост скорости приличный. Автоматически режим компрессии не включается, надо выделять память специальной командой. Эффективная пропускная способность даже в реальной задаче может быть повышена вдвое, но полезность сжатия данных в кэше нужно проверять в каждом конкретном случае.
Асинхронное копирование и асинхронные барьеры
Графический процессор A100 включает новую инструкцию асинхронного копирования, которая загружает данные напрямую из памяти GPU (через L2-кэш) в разделяемую память мультипроцессора SM, минуя регистровый файл и даже L1-кэш, при необходимости. Асинхронное копирование уменьшает нагрузку на регистровый файл, используя меньше регистров, эффективнее использует пропускную способность памяти, давая другим данным возможность дольше сохраняться в L1, и все это в итоге увеличивает эффективность вычислений, снижая энергопотребление.
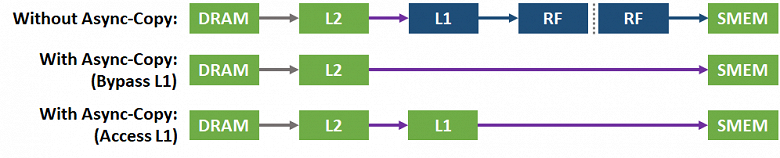
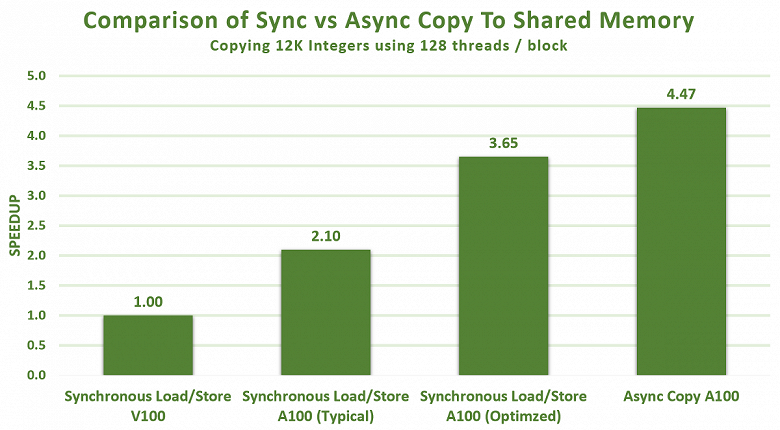
Асинхронное копирование может выполняться в фоновом режиме — в то время, когда мультипроцессор выполняет другие вычисления. И результаты в некоторых примерах поражают — мало того, что оптимизация загрузки и хранения данных в разделяемой памяти A100 и так значительно выше, чем у V100, асинхронное копирование дает еще больший прирост, и в итоге разница достигает 3-4 раз и даже более:
Также A100 поддерживает аппаратно-ускоренные асинхронные барьеры в разделяемой памяти. Их использование доступно в CUDA 11 в форме объектов барьеров ISO C++. Асинхронные барьеры могут использоваться для перекрытия асинхронных копий из глобальной памяти в общую с вычислениями в мультипроцессоре, их можно использовать для реализации модели «поставщик-потребитель». Барьеры также дают механизмы для синхронизации потоков CUDA на разных уровнях детализации, а не только на уровне варпа или блока.
Нововведения в передаче данных
NVLink третьего поколения
Для связи между графическими процессорами в вычислительных системах на базе решений Nvidia используют интерфейс NVLink, и в A100 используется уже его третье поколение, которое удваивает скорость высокоскоростного соединения между GPU, что позволяет добиться более эффективного масштабирования подобных систем. В новой версии используется больше линий на GPU и NVSwitch, она обеспечивает большую пропускную способность между GPU и улучшенные функции обнаружения и восстановления ошибок.
Третье поколение NVLink имеет скорость передачи данных в 50 Гбит/с на сигнальную пару, что почти вдвое выше скорости 25,78 Гбит/с в случае V100. Каждый линк обеспечивает пропускную способность 25 ГБ/с в каждом направлении, как и у V100, но использует вдвое меньшее сигнальных пар на канал по сравнению с V100. Общее количество линков было увеличено с 6 у V100 до 12 для A100, поэтому общая пропускная способность возросла с 300 ГБ/с до 600 ГБ/с.
Также в многопроцессорных системах на основе A100 используется и новая версия NVSwitch, значительно повышающая масштабируемость, производительность и надежность при совместной работе нескольких графических процессоров. Чип новой версии NVSwitch содержит 6 млрд транзисторов и также производится по 7 нм техпроцессу на TSMC (но на другом типе — 7FF), поддерживает 36 портов с пропускной способностью в 25 ГБ/с каждый.
Поддержка решений Magnum IO и Mellanox
Новый графический процессор A100 полностью совместим и с высокоскоростными решениями интерконнекта Nvidia Magnum IO и Mellanox InfiniBand и Ethernet для обеспечения взаимодействия многоузловых систем на основе нового GPU. Вовремя Nvidia завершила сделку по приобретению Mellanox — израильского производителя телекоммуникационного оборудования, ключевого разработчика технологии InfiniBand.
Magnum IO API объединяет вычислительные системы, сети, файловые системы и хранилища, чтобы максимизировать производительность ввода-вывода для многоядерных и многоузловых систем на основе GPU. Он взаимодействует с библиотеками CUDA-X для ускорения ввода-вывода в широком диапазоне задач, включая ИИ, анализ данных и визуализацию.
Поддержка шины PCI Express 4.0 и технологии виртуализации SR-IOV
Графический процессор A100 поддерживает шину новой версии PCI Express 4.0 (PCIe Gen 4), удваивающую пропускную способность, по сравнению с PCIe 3.0/3.1 — обеспечивается скорость передачи данных в 31,5 ГБ/с против 15,75 ГБ/с для привычных для нас разъемов x16. Это особенно важно при использовании A100 в серверных системах с центральными процессорами, поддерживающими PCIe 4.0, вроде AMD Epyc второго поколения (кодовое имя «Rome»), а также при использовании быстрых сетевых интерфейсов, вроде 200 Гбит/с InfiniBand.
A100 также поддерживает технологию виртуализации устройств SR-IOV, позволяющую предоставлять виртуальным машинам прямой доступ к аппаратным возможностям, разделяя один разъем PCIe на несколько виртуальных машин или процессов. К слову о виртуализации, тут также есть кое-что новое.
Технология виртуализации Multi-Instance GPU
Хотя потребности многих вычислительных задач постоянно растут, некоторые применения GPU не столь требовательны — например, инференс сравнительно простых моделей малого размера в задачах глубокого обучения. И для эффективного управления центрами обработки данных нужно не просто расширять возможности вверх, но и уметь эффективно ускорять меньшие рабочие нагрузки, не тратя впустую ресурсы высокопроизводительных чипов. Для этого обычно применяется разделение возможностей мощного устройства на виртуальные части, и работает это не всегда эффективно, поэтому Nvidia решила внедрить кое-что новое и тут.
В прошлом поколении GPU их вычислительные возможности позволяли нескольким приложениям одновременно исполняться на отдельных ресурсах, но ресурсы памяти были распределены между всеми приложениями, и одно из них могло создавать помехи остальным, если оно имело повышенные требования к пропускной способности памяти и кэша. В Ampere технология разделения ресурсов работает несколько иначе:
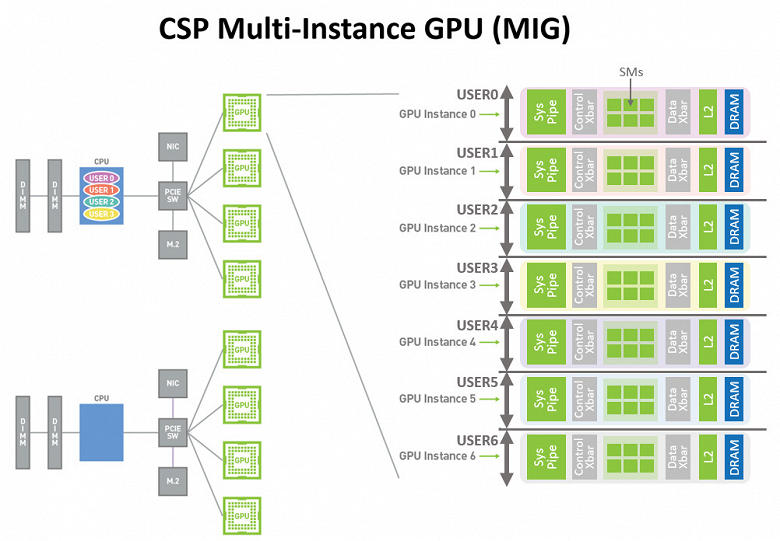
Новая возможность графического процессора A100 под названием Multi-Instance GPU (MIG) позволяет разделить графический процессор A100 на несколько разделов, называемых экземплярами графического процессора (GPU instance) — поддерживается до семи отдельных виртуальных GPU, занимающихся выполнением задач разной сложности. Каждому экземпляру обеспечивается свой набор ресурсов, включая память и кэши.
В режиме MIG, процессор A100 позволяет полнее загрузить работой его исполнительные блоки, обеспечивая параллельную работу до семи виртуальных GPU с высокой степенью надежности и безопасности. Решение обеспечивает нескольким пользователям доступ к ресурсам GPU для ускорения их приложений, оно полезно для оптимизации использования возможностей GPU, и особенно пригодится поставщикам облачных услуг — cloud service providers (CSP).
Мультипроцессоры каждого такого экземпляра GPU имеют собственные изолированные массивы данных во всей подсистеме памяти: банки кэш-памяти L2, контроллеры памяти и шины памяти назначаются для каждого экземпляра отдельно. Это гарантирует предсказуемую пропускную способность и задержки для всех пользователей, с одинаковыми объемом и пропускной способностью L2-кэша и памяти, вне зависимости от того, что делают соседние виртуальные системы.
Эта возможность эффективно разделяет доступные вычислительные ресурсы GPU для обеспечения определенного качества обслуживания (QoS) с изоляцией клиентов, что позволяет нескольким экземплярам GPU параллельно работать на одном физическом процессоре A100. Архитектура Ampere позволяет выполнять задачи на экземплярах виртуальных GPU так, как будто это физически разные устройства.
Таким образом, подключение MIG максимально увеличивает загрузку GPU при обеспечении качественного сервиса и изоляции между клиентами. Эта новая возможность особенно полезна для поставщиков облачных услуг, так как гарантирует, что ни один из клиентов не повлияет на работу других клиентов, и это касается как производительности, так и безопасности. Провайдеры облачных сервисов могут использовать MIG для повышения эффективности использования их серверов с графическими процессорами, предоставляя до 7 раз большее количество экземпляров GPU без дополнительных затрат с гарантией того, что ни один клиент (виртуальная машина, контейнер, процесс) не повлияет на работу других клиентов.
Очень важно увеличить время работы и доступности GPU при помощи обнаружения, сдерживания и исправления ошибок и сбоев, вместо принудительного сброса графического процессора. Графический процессор A100 поддерживает новую технологию, позволяющую улучшить обнаружение приложений, вызывающих ошибки, их изоляцию и локализацию. В кластерах с несколькими GPU и конфигурациях вроде MIG это особенно важно — для обеспечения изоляции и безопасности между клиентами, использующими один графический процессор.
Графические процессоры архитектуры Ampere, подключенные к NVLink, имеют более надежные функции обнаружения и восстановления ошибок — ошибки страниц на удаленном GPU отправляются обратно на исходный процессор по NVLink. Обмен сообщениями об ошибках при удаленном доступе является важной функцией устойчивости для больших вычислительных кластеров, чтобы сбои в одном процессе или виртуальной машине не приводили к сбоям в других.
Аппаратный JPEG-декодер
Из не самых ожидаемых, но любопытных новинок A100 можно отметить изменения, связанные с декодированием изображений самого популярного формата JPEG. Уже довольно давно известна ускоренная на GPU библиотека для декодирования изображений nvJPEG. Совместно с Nvidia DALI, библиотекой для загрузки и обработки изображений, она помогает ускорять задачи по классификации изображений и другие алгоритмы компьютерного зрения. Эти библиотеки ускоряют загрузку, декодирование и предварительную обработку изображений для дальнейшего использования при глубоком обучении.
Ранее уже было доступно ускорение декодирования JPEG при помощи CUDA-ядер, но в состав A100 решили включить пятиядерный аппаратный блок для декодирования JPEG, который может использовать библиотека nvJPEG для пакетной обработки соответствующих изображений. Ускорение декодирования JPEG при помощи выделенного аппаратного блока позволяет более эффективно использовать обработку на GPU, так как зачастую при глубоком обучении именно декодирование этого формата оказывалось наиболее узким местом.
Аппаратные возможности нового блока применяются на A100 автоматически при использовании функции nvjpegDecode для изображений или при помощи явного выбора аппаратного бэкэнда функцией инициализации nvjpegCreateEx. Аппаратный декодировщик ускоряет декодирование JPEG последовательного (в смысле — не прогрессивного) формата при цветовой субдискретизации YUV 420, 422 и 444.

На диаграмме показан прирост производительности декодирования JPEG-изображений YUV 420 при использовании CUDA-декодера и аппаратного декодера A100 в двух распространенных разрешениях: Full HD и 4K. Получается прирост более чем в 4 раза, а если сравнивать с полностью программным декодированием на CPU, то прирост скорости достигает 17-18 раз.
Улучшения в CUDA 11 для поддержки Ampere
Конечно же, все архитектурные улучшения Ampere были немедленно поддержаны в новой версии вычислительной платформы CUDA, объявленной одновременно с анонсом GPU. Эта платформа является наиболее популярной среди аналогичных специализированных решений. Уже тысячи приложений, использующих вычисления на GPU, используют именно решение компании Nvidia. Гибкость и программируемость их платформы, а также постоянные улучшения сделали ее предпочтительной для использования в алгоритмах глубокого обучения и других типов параллельных вычислений.
Новые функции CUDA 11 обеспечивают полную поддержку тензорных ядер третьего поколения Ampere, как и всех новых типов тензорных вычислений: Bfloat16, TF32 и FP64, умеют использовать разреженность матриц, CUDA-графы, технологию виртуализации ресурсов MIG, управление L2-кэшем и другие новые возможности нового графического процессора A100.
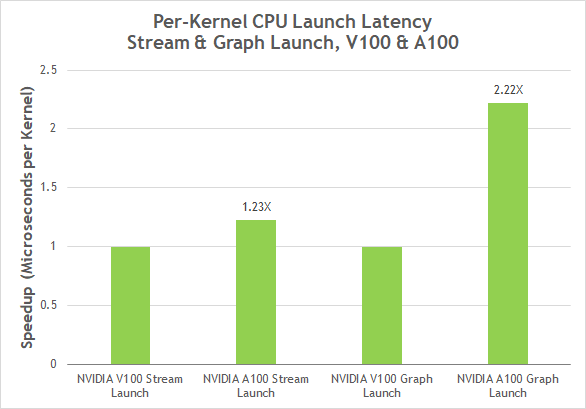
CUDA-графы, представленные в CUDA 10, представляют новую модель для запуска CUDA-вычислений. Граф состоит из нескольких операций, вроде копирования памяти и запуска связанных ядер (кернелов) на исполнение. Графы разрешают поток выполнения в формате однократного определения и многократного исполнения, и могут снизить общие накладные расходы на запуск, повысив общую производительность приложений глубокого обучения, запускающих несколько ядер, имеющих сложные зависимости. Графы CUDA теперь имеют упрощенный механизм обновлений для уже созданных экземпляров графов без необходимости их перестроения, что позволило снизить задержки при запуске ядер на исполнение на A100 до двух раз, по сравнению с V100.
В CUDA 11 к уже существующему инструментарию для разработчиков добавились новые элементы и возможности. В состав его входят плагины для Visual Studio с интеграцией Nvidia Nsight и Eclipse с Nsight Eclipse Plugins Edition. Также платформа включает автономные инструменты, вроде Nsight Compute для профилирования ядер (кернелов) и Nsight Systems — для анализа производительности всей системы. Nsight Compute и Nsight теперь поддерживаются для трех архитектур CPU: x86, POWER и ARM64.
Nvidia также анонсировала обновления программного стека компании, включая новые версии нескольких десятков библиотек CUDA-X, используемых для ускорения графики, моделирования и ИИ; CUDA 11, Nvidia Jarvis, Nvidia Merlin, фреймворка для рекомендательных систем; а также Nvidia HPC SDK, включающего компиляторы, библиотеки и инструменты, помогающие отлаживать и оптимизировать свой код для новых процессоров.
Применение A100 в вычислительных системах
Nvidia ожидает, что процессоры A100 будут использовать многие поставщики облачных услуг и сборщики систем, в том числе: Alibaba Cloud, Amazon Web Services (AWS), Atos, Baidu Cloud, Cisco, Dell Technologies, Fujitsu, Gigabyte, Google Cloud, H3C, Hewlett Packard Enterprise (HPE), Inspur, Lenovo, Microsoft Azure, Oracle, Quanta/QCT, Supermicro и Tencent Cloud.
Новые графические процессоры также будут использоваться и в суперкомпьютерах нового поколения в лабораториях и исследовательских организациях: Университет Индианы (США), Юлихский исследовательский центр (Германия), Технологический Институт Карлсруэ (Германия), Общество Макса Планка (Max Planck Computing and Data Facility, Германия), Научно-исследовательский вычислительный центр Министерства энергетики США в Национальной лаборатории Лоуренса в Беркли.
Вместе с графическим процессором A100 была анонсирована и система DGX A100 — уже третьего поколения, которая включает восемь таких GPU, связанных между собой интерфейсом NVLink. Эта система уже доступна у Nvidia и будет доступна у партнеров компании. На базе процессора A100 ожидается линейка серверов у всех ведущих производителей, включая Atos, Dell Technologies, Fujitsu, Gigabyte, H3C, HPE, Inspur, Lenovo, Quanta/QCT и Supermicro.
Чтобы ускорить разработку серверов, Nvidia создала референсный дизайн модулей HGX A100 — в форме интегрируемых плат с различными конфигурациями GPU. Соединение четырех GPU в модулях HGX A100 обеспечивает технология NVLink, а в модулях с восемью такими GPU взаимодействие между ними происходит при помощи NVSwitch. Благодаря технологии MIG, каждый модуль HGX A100 можно разбить на 56 отдельных виртуальных GPU, каждый из которых будет быстрее Nvidia T4 — отличное решение для облачных сервисов.
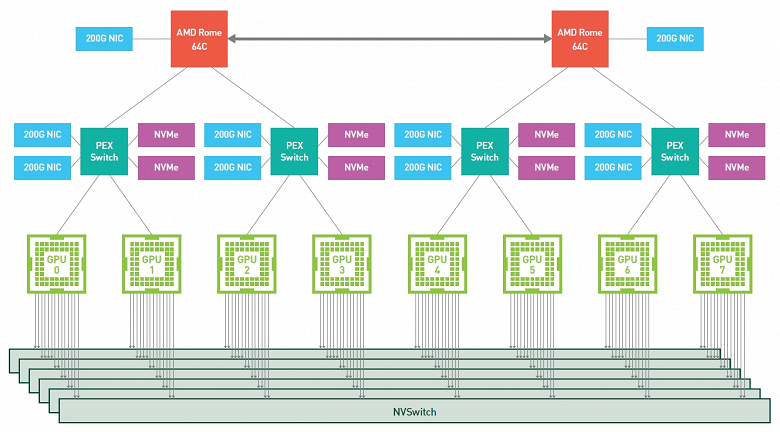
Но нас сейчас несколько больше интересует DGX A100, как готовое решение именно Nvidia. Оно предлагает производительность в задачах ИИ уровня 5 петафлопс и состоит из пары 64-ядерных центральных процессоров AMD Epyc второго поколения «Rome», имеющих 1 ТБ оперативной памяти, восьми графических процессоров A100 с тензорными ядрами, с общим объемом HBM2-памяти 320 ГБ и полосой ее пропускания в 12,4 ТБ/с. В качестве накопителей применяются твердотельные NVMe-устройства с поддержкой PCIe 4.0 и общим объемом в 15 ТБ.

Связаны GPU между собой при помощи шести интерфейсов NVSwitch с применением NVLink третьего поколения с двунаправленной полосой пропускания в 4,8 ТБ/с (чтобы наглядно показать, насколько это много, Nvidia приводит такую аналогию — этой полосы достаточно для передачи 426 часов HD-видео за одну секунду). Также применяются девять интерфейсов Mellanox ConnectX-6 VPI HDR InfiniBand 200 Гбит/с с суммарной двунаправленной полосой пропускания в 450 ГБ/с.
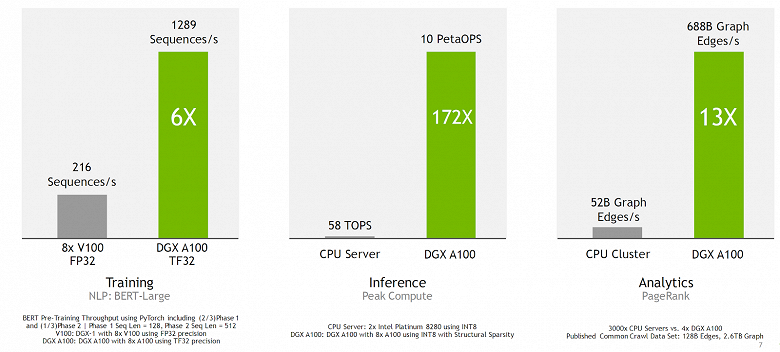
Общая производительность подобного сервера с восемью GPU на борту в ИИ задачах составляет до 10 петафлопс (с применением новой функции разреженности матриц), что значительно превышает возможности любых серверов чисто на CPU, как вы можете увидеть по следующим диаграммам, показывающим сравнительную производительность. Да и по сравнению с V100 новый графический процессор архитектуры Ampere оказался заметно быстрее — до 6 раз при обучении нейросети в задаче BERT (и в этом помог новый тип операций — TF32).
Интересно, что в Nvidia с третьим поколением DGX решили перейти на серверный процессор AMD второго поколения Epyc, а не Intel Xeon. Это было сделано по понятным причинам — как более высокой производительности за счет большего количества ядер, так и повышенной пропускной способности шины PCIe 4.0, которую решения Intel пока не поддерживают. Ведь чтобы выжать все из нескольких графических процессоров, им нужна быстрая связь между ними, и в случае с системой на Epyc все компоненты поддерживают четвертую версию PCIe: процессоры AMD, графические чипы, сетевые адаптеры Mellanox и NVMe-накопители.
Множество различных организаций по всему миру применяют системы DGX предыдущих поколений — ведущие автопроизводители, поставщики медицинских услуг, ритейлеры, финансовые институты и логистические компании. Многие из них заинтересованы в DGX A100. Поставки этих систем уже начались, крупные компании, поставщики услуг и правительственные учреждения уже разместили заказы на эти системы. Первые DGX третьего поколения отправились в Аргоннскую национальную лабораторию Министерства энергетики США, и обещано, что вычислительные возможности кластера будут направлены на борьбу с COVID-19.
Из учебных заведений первым DGX A100 получит университет Флориды, другими пользователями систем на A100 стали: Центр биомедицинского ИИ в Гамбурге, Университет Чулалонгкорна в Таиланде, Немецкий исследовательский центр ИИ, разработчик решений и услуг на базе ИИ Element AI из Монреаля, сиднейская медицинская компания Harrison.ai, компания Artificial Intelligence Office из ОАЭ, вьетнамская исследовательская лаборатория VinAI Research.
Чтобы помочь своим клиентам в создании дата-центров на базе графических процессоров A100, Nvidia также представила референсную архитектуру DGX SuperPOD нового поколения — кластера, созданного из 140 систем DGX A100, обеспечивающих производительность до 700 петафлопс в задачах ИИ. Этот кластер является одним из самых мощных суперкомпьютеров для работы с ИИ и обладает производительностью, которую могут обеспечить лишь тысячи традиционных серверов.

Объединение 140 систем DGX A100 при помощи решений свежеприобретенной Mellanox делает суперкомпьютер DGX SuperPOD особенно хорошо подходящим для обширных исследований в таких областях, как диалоговый ИИ, геномика и автономное вождение. А продуманная архитектура позволила построить столь мощную систему всего за три недели, тогда как обычно разработка компонентов с подобными возможностями требует нескольких лет.
В таком виде SuperPOD применяется в SATURNV, но ничто не мешает создать и менее производительные варианты из 20 систем DGX A100, к примеру. Системы DGX A100 уже доступны для заказа по цене от 199 000 долларов через Nvidia Partner Network. Поставщики систем хранения DDN Storage, Dell Technologies, IBM, NetApp, Pure Storage и Vast также планируют интегрировать DGX A100 в свой ассортимент.
Выводы
Nvidia уже давно нацелилась на то, чтобы их вычислительные решения прочно поселились в серверах и суперкомпьютерах по всему миру. Уже несколько лет трудно представить такие системы без GPU в решениях, предназначенных для выполнения большого количества важнейших задач человечества, вроде научных и медицинских исследований, производственных задач, исследовании больших объемов данных при использовании высокопроизводительных вычислений и искусственного интеллекта.
Nvidia является лидером в графических технологиях, поэтому компании с легкостью удается внедряться в серверы, и именно сегмент дата-центров и является самым быстро растущим для компании в целом, а другие сегменты хоть и не застаиваются, но все же не выглядят столь же мощными потенциально. Решения компании находят все более широкое применение в серверах и других высокопроизводительных системах, и совершенно неудивительно, что они вкладывают все больше и больше денег в проектирование больших чипов для высокопроизводительных вычислений и различные исследования, связанные с применением искусственного интеллекта.
Новый графический (а скорее даже вычислительный) процессор A100 обеспечивает очередной большой скачок в ускорении центров обработки данных любого масштаба, от небольшого сервера до гигантского суперкомпьютера. Мощное решение архитектуры Ampere поддерживает множество областей применения, включая HPC, исследование генома человека, 5G-сети, 3D-рендеринг, задачи глубокого обучения, анализ данных, робототехнику и многие другие.
Ускоритель вычислений A100 поддерживает платформу центров обработки данных Nvidia, включающую такие технологии как Mellanox HDR InfiniBand, NVSwitch, HGX A100 и Magnum IO SDK — эта группа технологий эффективно масштабируется от единиц до десятков тысяч GPU, предназначенных в том числе для обучения сложнейших нейросетей с максимально возможной скоростью. Развитие самых важных применений GPU требует постоянного роста производительности и возможностей вычислительных систем.
Новый графический процессор A100 по всем важнейшим параметрам превзошел своего предшественника V100, причем нужно отметить не только рост чистой вычислительной производительности, но и новые возможности по более эффективному использованию всего, что есть в этом GPU. Прирост почти по всем статьям составляет 2-3 раза, а рост объема кэш-памяти второго уровня поражает больше всего. Пожалуй, единственным по-настоящему спорным моментом в характеристиках А100 является возросший лишь в 1,3 раза объем локальной памяти — возможно, для столь мощного вычислителя стоило поставить больше HBM2-чипов. Но это частично нивелируется как раз тем самым огромным и быстрым L2-кэшем, да и возможностью сжатия данных.

Но не нужно смотреть только на цифры прироста пиковой производительности в базовых вычислениях. Да, эти показатели ближе к среднему приросту скорости реальных вычислений, но вся архитектура Ampere в основном вовсе не про это, по крайней мере в его «вычислительном» виде — A100. Даже полное название этого решения говорит о том, что основное внимание специалисты Nvidia уделили именно тензорным ядрам, которые теперь умеют вычислять гораздо быстрее и более гибко. Тензорные ядра нового GPU умеют выполнять операции новых типов, позволяя получить многократное ускорение в задачах ИИ и многих типах высокопроизводительных вычислений. Зачастую даже не требуя модификации уже существующего кода.
Конечно же, и обычные CUDA-ядра в GA100 также стали производительнее. И речь не столько о пиковых цифрах, сколько о максимально эффективном исполнении широкого ряда задач. Не зря среди приводимых Nvidia данных многие связаны именно с соотношением пиковых теоретических значений и реальной скорости вычислений. Многие улучшения в Ampere и A100 в частности направлены именно на это: серьезные изменения в работе с общей памятью и увеличенный L1-кэш, очень большой и быстрый L2-кэш, которым теперь стало можно управлять, возможности асинхронного копирования данных, сжатие данных в кэше и многое другое. По данным Nvidia, с новым A100 во многих случаях стало еще проще добиться реальной производительности, близкой к пиковой теоретической, вот лишь один из примеров:
Среди новых особенностей, предназначенных для компаний, предоставляющих облачные сервисы, можно отметить новую функцию MIG, которая позволяет разделить каждый процессор A100 на семь виртуальных ускорителей для оптимального использования ресурсов GPU, обеспечивая доступ к его возможностям для большего числа пользователей и приложений. Благодаря универсальности нового решения Nvidia, управляющие вычислительной инфраструктурой партнеры смогут удовлетворить разнообразные потребности в производительности, от несложной работы до многоузловой рабочей нагрузки.
Тут важно то, что новые технологии Nvidia позволяют подобрать требуемую вычислительную мощь для каждой задачи конкретно. Для задач попроще, типа инференса при глубоком обучении, каждый из A100 можно разделить на семь независимых инстансов GPU, а в самых сложных применениях и работе с масштабными задачами, придется делать наоборот — несколько графических процессоров объединять в один гигантский GPU при помощи интерфейса NVLink третьего поколения.
Главный вывод из всей изложенной теоретической информации состоит в том, что новая архитектура Ampere позволила графическому процессору A100 обеспечить максимальный прирост производительности в задачах ИИ среди всех предыдущих GPU компании — ускорение производительности достигает 10-20 раз по сравнению с предшественниками A100. Именно на этот тип задач Nvidia обращает внимание вот уже несколько лет, не забывая и другие применения.
Ждем и пользовательских решений компании, предназначенных для игрового сегмента. Говорят, что их появления можно ожидать к осени, и что в этот раз архитектуры вроде бы не будут отличаться (в прошлом поколении были Volta для вычислительных решений и Turing для игровых, хотя это разделение и можно считать номинальным). Будущие GeForce возьмут многое из того, что было сделано для вычислений в GA100, но наверняка в них добавятся ядра для аппаратного ускорения трассировки лучей. Также возможны интересные нововведения, связанные с улучшенными тензорными ядрами. DLSS 2.0 хорош, но ведь можно сделать еще лучше, правда?


