Requests в Python – Примеры выполнения HTTP запросов


Библиотека requests является стандартным инструментом для составления HTTP-запросов в Python. Простой и аккуратный API значительно облегчает трудоемкий процесс создания запросов. Таким образом, можно сосредоточиться на взаимодействии со службами и использовании данных в приложении.
Содержание статьи
В данной статье представлены наиболее полезные особенности requests. Показано, как изменить и приспособить requests к различным ситуациям, с которыми программисты сталкиваются чаще всего. Здесь также даются советы по эффективному использованию requests и предотвращению влияния сторонних служб, которые могут сильно замедлить работу используемого приложения. Мы использовали библиотек requests в уроке по парсингу html через библиотеку BeautifulSoup.
Ключевые аспекты инструкции:
В статье собран оптимальный набор информации, необходимый для понимания данных примеров и особенностей их использования. Информация представлена в доступной в форме. Тем не менее, стоит иметь в виду, что для оптимального разбора инструкции потребуются хотя бы базовые знания HTTP.
Далее будут показаны наиболее эффективные методы использования requests в разрабатываемом приложении.
Python установка библиотеки requests
Получение/отправка заголовков сервера модулем requests в Python.
Получение заголовков headers в ответе сервера.
НО словарь особенный: он создан только для HTTP-заголовков. Согласно RFC 7230, имена заголовков HTTP не чувствительны к регистру символов.
Таким образом, можно получить доступ к любому заголовку, используя при его написании заглавные буквы:
Заголовки также особенные, т.к. сервер может отправить один и тот же заголовок несколько раз с разными значениями, но запросы объединяют их таким образом, чтобы они могут быть представлены в словаре в рамках одного сопоставления, согласно RFC 7230:
Получатель МОЖЕТ объединить несколько полей заголовка с одним и тем же именем поля в одну пару “field-name: field-value”, не изменяя семантику сообщения, добавляя каждое последующее значение поля к объединенному значению поля по порядку, разделенному запятой.
Если необходимо получить заголовки, которые МЫ отправили серверу, то просто получаем доступ к запросу, а затем к заголовкам запроса:
Отправка заголовков headers на сервер в запросе.
Например, в предыдущих примерах мы не указывали/устанавливали user-agent (тип браузера):
Примечание: Пользовательские заголовки имеют меньший приоритет, чем более конкретные источники информации. Например:
Кроме того, запросы вообще не меняют свое поведение в зависимости от того, какие пользовательские заголовки указаны. Заголовки просто передаются в окончательный запрос.
HTTP Headers для «чайников»
Russian (Pусский) translation by Yuri Yuriev (you can also view the original English article)
Являетесь вы программистом или нет, вы видели его повсюду в Интернете. На данный момент в адресной строке браузера отображается нечто, что начинается с «https: //». Даже ваш первый скрипт Hello World отправил HTTP-header без вашего понимания. В этой статье мы собираемся узнать об основах HTTP-заголовков и о том, как их можно использовать в наших веб-приложениях.
Что такое HTTP Headers?
HTTP значит «Hypertext Transfer Protocol» (Протокол передачи гипертекста). Всемирная паутина использует этот протокол. Он был создан в начале 1990-х годов. Почти всё, что вы видите в вашем браузере, передаётся на ваш компьютер через HTTP. Например, когда вы открыли страницу этой статьи, ваш браузер отправил более 40 HTTP-запросов и получил HTTP-ответы для каждого из них.
Заголовки HTTP являются основной частью этих HTTP-запросов и ответов, и они несут информацию о браузере клиента, запрошенной странице, сервере и многом другом.
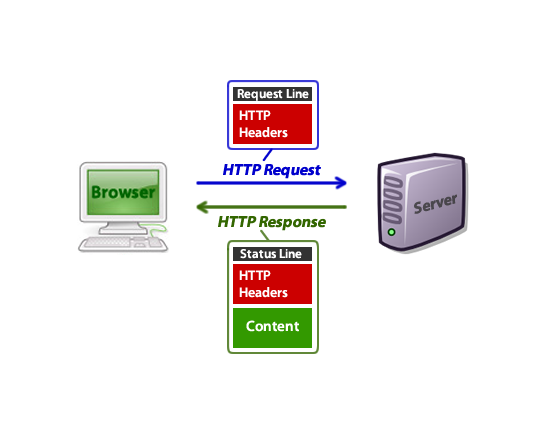

Пример
Когда вы вводите URL-адрес в адресной строке, ваш браузер отправляет HTTP-запрос, и он может выглядеть так:
После этого запроса ваш браузер получает ответ HTTP, который может выглядеть так:
Когда вы смотрите на исходный код веб-страницы в своём браузере, вы видите только часть HTML, а не заголовки HTTP, хотя они фактически были переданы вместе.
Эти HTTP-запросы также отправляются и принимаются для других вещей, таких как изображения, CSS-файлы, файлы JavaScript и т. д. Именно поэтому я сказал ранее, что ваш браузер отправил не менее 40 или более HTTP-запросов, поскольку вы загрузили только эту страницу статьи.
Теперь давайте рассмотрим структуру более подробно.
Как увидеть HTTP Headers
Для анализа HTTP-заголовков я использую следующие расширения Firefox:




Далее в этой статье мы увидим примеры кода в PHP.
Структура запроса HTTP

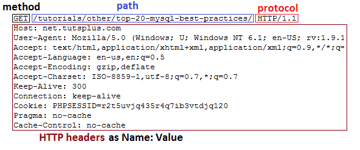
Первая строка HTTP-запроса называется линией запроса и состоит из трёх частей:
Остальная часть запроса содержит HTTP headers как пары «Name: Value» в каждой строке. Они содержат различную информацию о HTTP-запросе и вашем браузере. Например, строка «User-Agent» предоставляет информацию о версии браузера и операционной системе, которую вы используете. «Accept-Encoding» сообщает серверу, может ли ваш браузер принимать сжатый output, например gzip.
Возможно, вы заметили, что данные cookie также передаются внутри HTTP-заголовка. И если бы ссылочный url, это было бы в header тоже.
Большинство этих заголовков являются необязательными. Этот HTTP-запрос мог быть таким же маленьким:
И вы всё равно получите правильный ответ от веб-сервера.
Методы запроса
Три наиболее часто используемых метода запроса: GET, POST и HEAD. Вы, вероятно, уже знакомы с первыми двумя, начиная с написания html-форм.
GET: получение документа
Это основной метод, используемый для извлечения html, изображений, JavaScript, CSS и т. д. С использованием этого метода запрошено большинство данных, загружаемых в ваш браузер.
Например, при загрузке статьи Nettuts +, самая первая строка HTTP-запроса выглядит так:
Как только html загрузится, браузер начнет отправлять GET-запрос изображений, который может выглядеть так:
Веб-формы можно настроить под метод GET. Вот пример.
Когда эта форма отправлена, HTTP-запрос начинается так:
Вы можете видеть, что каждый ввод формы был добавлен в строку запроса.
POST: отправка данных на сервер
Даже если вы можете отправлять данные на сервер с помощью GET и строки запроса, во многих случаях POST будет предпочтительнее. Отправка больших объёмов данных с помощью GET нецелесообразна и имеет ограничения.
Запросы POST чаще всего отправляются веб-формами. Давайте изменим предыдущий пример формы на метод POST.
Отправка этой формы создает HTTP-запрос следующим образом:
Здесь нужно отметить три важных момента:
Запросы POST метода также могут быть сделаны через AJAX, приложения, cURL и т. д. И все формы загрузки файлов необходимы для использования метода POST.
HEAD: получение информации заголовка
HEAD идентичен GET, за исключением того, что сервер не возвращает содержимое HTTP-ответа. Когда вы отправляете запрос HEAD, это означает, что вас интересуют только код ответа и HTTP headers, а не сам документ.
«Когда вы отправляете запрос HEAD, это означает, что вас интересуют только код ответа и HTTP headers, а не сам документ».
С помощью этого метода браузер может проверить, был ли документ изменён для целей caching. Он также может проверить, существует ли документ вообще.
Например, если у вас много ссылок на веб-сайте, вы можете периодически отправлять HEAD-запросы каждой из них, чтобы проверить наличие неработающих ссылок. Это будет намного быстрее, чем при использовании GET.
Структура ответа HTTP
После того, как браузер отправляет HTTP-запрос, сервер отвечает HTTP-ответом. Исключая контент, он выглядит так:


Первой порцией данных является протокол. Обычно это снова HTTP/1.x или HTTP/1.1 на современных серверах.
Мы все видели «404» pages. Это число фактически приходит из части кода состояния HTTP-ответа. Если запрос GET будет создан для path, который сервер не может найти, он ответил бы 404, а не 200.
Остальная часть ответа содержит headers так же, как HTTP-запрос. Эти значения могут содержать информацию о софте сервера при последнем изменении страницы/файла, типе mime и прочее.
Опять же, большинство этих headers на самом деле являются необязательными.
Коды статуса HTTP
200 OK
Как упоминалось ранее, этот код состояния отправляется в ответ на успешный запрос.
206 Partial Content
Если приложение запрашивает только диапазон запрошенного файла, возвращается код 206.
Это часто используется с менеджерами закачек, которые могут остановить и возобновить загрузку или разделить загрузку на части.
404 Not Found


Когда запрашиваемая страница или файл не найдена, сервер отправляет код ответа 404.
401 Unauthorized
Защищённые паролем веб-страницы отправляют этот код. Если вы не ввели логин правильно, вы можете увидеть следующее в вашем браузере.


Обратите внимание, что это относится только к страницам, защищённым паролем HTTP, которые вызывают запросы для входа следующим образом:


403 Forbidden
Если вам не разрешен доступ к странице, этот код может быть отправлен в ваш браузер. Это часто происходит, когда вы пытаетесь открыть URL-адрес для папки, в которой нет индексной страницы. Если параметры сервера не позволяют отображать содержимое папки, вы получите ошибку 403.


Существуют другие способы блокировки доступа и 403 могут быть отправлены. Например, вы можете блокировать по IP-адресу с помощью некоторых директив htaccess.
302 (or 307) Moved Temporarily & 301 Moved Permanently
Эти два кода используются для перенаправления браузера. Например, когда вы используете службу сокращения URL, такую как bit.ly, именно так они перенаправляют людей, которые идут по ссылке.
302 и 301 обрабатываются браузером очень похоже, но они могут иметь различные значения для spiders поисковых систем. Например, если ваш сайт не готов для обслуживания, вы можете перенаправить его в другое место с помощью 302. Поисковая система продолжит проверку вашей страницы в будущем. Но если вы перенаправите с использованием 301, это сообщит spider, что ваш сайт переехал в это место навсегда. За более точной информацией: http://www.nettuts.com перейдите на https://net.tutsplus.com/ используя 301 код вместо 302.
500 Internal Server Error


Этот код обычно отображается при сбое веб-скрипта. Большинство скриптов CGI не выводят ошибки непосредственно в браузер, в отличие от PHP. Если есть фатальные ошибки, они просто отправят код статуса 500. И тогда программист должен искать в журналах ошибок сервера, чтобы найти сообщения об ошибках.
Complete List
Вы можете найти полный список кодов состояния HTTP с их пояснениями here.
Заголовки HTTP в запросах HTTP
HTTP-запрос отправляется на определенные IP-адреса. Но так как большинство серверов способны размещать несколько сайтов под одним IP, они должны знать, какое доменное имя ищет браузер.
Это в основном имя host, включая домен и поддомен.
User-Agent
Этот заголовок может содержать несколько частей информации, таких как:
Именно так веб-сайты могут собирать определённую общую информацию о своих системах surfers. Например, они могут определить, использует ли surfer мобильный браузер и перенаправляет их на мобильную версию своего веб-сайта, который лучше работает с низким разрешением.
Accept-Language
Этот заголовок отображает настройки языка по умолчанию. Если сайт имеет разные языковые версии, он может перенаправить нового surfer на основе этих данных.
Accept-Encoding
Большинство современных браузеров поддерживают gzip и отправляют это в header. Затем веб-сервер может отправить выходной HTML-код в сжатом формате. Это позволяет уменьшить размер до 80% для экономии пропускной способности и времени.
If-Modified-Since
Если веб-документ уже сохранен в кеше в браузере и вы посещаете его снова, ваш браузер может проверить, был ли документ обновлён, отправив следующее:
Существует также HTTP-заголовок Etag, который можно использовать для проверки текущего кэша. Мы поговорим об этом в ближайшее время.
Cookie
Как следует из названия, это отправляет файлы cookie, хранящиеся в вашем браузере для этого домена.
Это пары name=value, разделённые точками с запятой. Cookies могут также содержать id сеанса.
Referer
Как следует из названия, этот HTTP header содержит ссылочный url.
Например, если я зашел на домашнюю страницу Nettuts + и нажал ссылку на статью, этот header будет отправлен в мой браузер:
Возможно, вы заметили, что слово «referrer» написано с ошибкой, как «referer». К сожалению, он превратился в официальную спецификацию HTTP подобным образом и застрял.
Authorization
Когда веб-страница запрашивает авторизацию, браузер открывает окно входа в систему. Когда вы вводите имя пользователя и пароль в этом окне, браузер отправляет другой HTTP-запрос, но на этот раз он содержит этот header
Данные внутри header имеют кодировку base64. Например, base64_decode (‘bXl1c2VyOm15cGFzcw ==’) возвратит ‘myuser: mypass’
Подробнее об этом будет, когда мы поговорим о заголовке WWW-Authenticate.
Заголовки HTTP в ответах HTTP
Теперь мы рассмотрим некоторые из наиболее распространенных HTTP headers, найденных в HTTP-ответах.
В PHP вы можете установить заголовки ответа, используя функцию header(). PHP уже отправляет определённые заголовки автоматически, для загрузки содержимого и настройки файлов cookie и прочее. Вы можете увидеть headers, которые отправляются или будут отправляться с помощью функции headers_list (). Вы можете проверить, были ли уже отправлены заголовки с помощью функции headers_sent().
Cache-Control
Определение из w3.org: «Поле заголовка Cache-Control используется для указания директив, которые ДОЛЖНЫ выполняться всеми механизмами кэширования по цепочке запросов/ответов». Эти «механизмы кэширования» включают шлюзы и прокси, которые может использовать ваш интернет-провайдер.
«public» означает, что ответ может быть кэширован кем угодно. «max-age» указывает, сколько секунд действителен кеш. Разрешение кэширования вашего сайта может снизить нагрузку на сервер и пропускную способность, а также увеличить время загрузки в браузере.
Кэширование также может быть предотвращено с помощью директивы «no-cache».
Подробности смотрите в w3.org.
Content-Type
Этот header указывает «mime-type» документа. Затем браузер определяет, как интерпретировать содержимое на основании этого. Например, страница html (или PHP-скрипт с выходом html) может возвращать это:
Для gif-изображения это может быть отправлено.
Браузер может использовать внешнее приложение или расширение браузера на основе mime-type. Например, это приведет к загрузке Adobe Reader:
При загрузке напрямую Apache обычно может обнаружить mime-тип документа и отправить соответствующий header. Кроме того, большинство браузеров имеют некоторую степень отказоустойчивости и автоопределение типов mime, если заголовки указаны неверно или отсутствуют.
Вы можете найти список общих типов mime here.
В PHP вы можете использовать функцию finfo_file() для определения mime-типа файла.
Content-Disposition
Этот header указывает браузеру открыть окно загрузки файла, вместо того, чтобы пытаться проанализировать содержимое. Пример:
Это заставит браузер сделать это:


Обратите внимание, что соответствующий заголовок Content-Type также должен быть отправлен вместе с этим:
Content-Length
Когда контент будет передаваться браузеру, сервер может указать его размер (в байтах), используя этот header.
Это особенно полезно при загрузке файлов. Именно так браузер может определить ход загрузки.
Например, вот сценарий-макет, который я написал, имитирует медленную загрузку.


Теперь я собираюсь закомментировать заголовок Content-Length
Теперь результат такой:


Браузер может только сказать, сколько байтов было загружено, но он не знает общую сумму. И индикатор выполнения не показывает прогресс.
Это еще один header, который используется для кеширования. Это выглядит так:
Веб-сервер может отправлять этот header с каждым документом, который он обслуживает. Значение может быть основано на последней изменённой дате, размере файла или даже контрольной сумме файла. Браузер затем сохраняет это значение, так как он кэширует документ. В следующий раз, когда браузер запрашивает тот же файл, он отправляет это в HTTP-запросе:
Если значение Etag документа совпадает с этим, сервер будет отправлять код 304 вместо 200, и никакого содержимого. Браузер будет загружать содержимое из своего кеша.
Last-Modified
Как следует из названия, этот header указывает дату последнего изменения документа в формате GMT:
Это предлагает браузеру другой способ для cache документа. Браузер может отправить это в HTTP-запросе:
Мы уже говорили об этом ранее в разделе «If-Modified-Since».
Location
Этот заголовок используется для перенаправления. Если код ответа 301 или 302, сервер также должен отправить этот header. Например, когда вы перейдете на страницу http://www.nettuts.com, ваш браузер получит следующее:
В PHP вы можете перенаправить surfer так:
По умолчанию, это отправит 302 код ответа. Если вы хотите вместо 301 отправить:
Set-Cookie
Когда веб-сайт хочет установить или обновить файл cookie в вашем браузере, он будет использовать этот header.
Каждый файл cookie отправляется как отдельный header. Обратите внимание, что файлы cookie, установленные с помощью JavaScript, не проходят через HTTP headers.
В PHP вы можете установить cookie-файлы, используя функцию setcookie(), а PHP отправляет соответствующие HTTP headers.
Что приводит к отправке этого заголовка:
Если дата истечения срока действия не указана, cookie удаляется, когда окно браузера закрыто.
WWW-Authenticate
Сайт может отправить этот header для аутентификации пользователя через HTTP. Когда браузер увидит этот header, он откроет диалоговое окно входа в систему.
Что будет выглядеть так:
В руководстве PHP есть section, в котором приведены образцы кода, как это сделать в PHP.
Content-Encoding
Этот header обычно устанавливается, когда возвращаемое содержимое сжимается.
В PHP, если вы используете функцию обратного вызова ob_gzhandler(), она будет автоматически установлена.
Заключение
Спасибо за прочтение. Надеюсь, эта статья послужит хорошей отправной точкой для изучения HTTP Headers. Пожалуйста, оставьте свои комментарии и вопросы ниже, и я постараюсь дать как можно больше ответов.
Requests Python библиотека для отправки HTTP-запросов (очень краткое руководство)

Перевод статьи Python’s Requests Library (Guide) от замечательной команды Real Python, которая уже не в первый раз радует нас новыми интересными и полезными материалами о языке Python. И хотя в сети есть ее переводы, я немного адаптировал ее содержимое, добавив некоторые справочные данные. Так же я добавил подраздел об использовании механизма сессий при обращении к удаленным службам, которого как я считаю не хватало в оригинале статьи для понимания некоторых затрагиваемых вопросов.
Библиотека requests в настоящее время уже давно является стандартом де-факто для реализации отправки HTTP-запросов в Python. Она элегантно абстрагирует сложность написания запросов к серверу, используя красивый и простой API, так что вы можете спокойно сосредоточиться при работе над вашим приложении на вопросах организации взаимодействия с различными удаленными службами, а также дальнейшей обработки получаемых данных.
В этом руководстве вы узнаете, как:
Хотя я попытался включить в настоящее руководство столько информации, сколько нужно, чтобы понять все примеры кода, которые я включил в эту статью, но тем не менее я надеюсь, что для начала вы обладаете общими базовыми понятиями о работе протокола HTTP.
Начинаем работать с requests
Если же вы предпочитаете использовать Pipenv для управления пакетами Python, то можете запустить на исполнение следующую команду:
Установка библиотеки requests в операционной системе Windows и Linux практически не отличаются. В сети достаточно материалов, в которых описан принцип работы с пакетами Python в обеих системах. Поэтому в этой статье касаться этих вопросов мы далее не будем.
Запрос GET (GET request)
Такие методы запросов, как GET и POST, определяют, действие, которое вы пытаетесь выполнить при выполнении HTTP-запроса. Помимо GET и POST, есть еще несколько других достаточно распространенных методов запросов и их мы рассмотрим в этом руководстве позже.
Проверим это на практике: отправим GET-запрос к GitHub Root REST API, вызвав метод get() со следующим значением параметра url :
Отлично! Мы отправили свой первый запрос. Давайте изучим содержимое полученного ответа.
Ответ (response)
Объект Response является мощным средством для просмотра содержимого и обработки результатов наших запросов. Давайте пошлем, рассмотренный нами выше, запрос GET еще раз, но в этот раз сохраним принятое значение с объектом ответа в переменной, и затем поближе познакомиться с его атрибутами (свойствами), а также поведением:
Код состояния запроса (status codes)
Например, статус 200 OK означает, что ваш запрос был успешным, а статус 404 NOT FOUND означает, что искомый ресурс не найден. Существует много других кодов состояния запроса, которые могут дать вам более детальное представление о том, что же все таки произошло с отправленным запросом.
В большинстве случаев эту информацию мы будем использовать для реализации в своем коде различной логики: управлять дальнейшей работой нашего приложения:
Поэтому мы можем упростить последний пример, переписав код оператора if следующим образом:
Маленькая техническая деталь: этот тест на истинность значения показал такой результат возможным, так как в объекте Response специальный метод класса __bool__() переопределен.
Это означает то, что поведение по умолчанию объекта Response при вычислении его логического значения было переопределено для процедуры проверки кода состояния запроса.
Поэтому используете этот способ проверки, если захотите узнать, был ли запрос в целом успешным, а только затем, при необходимости, обработать содержимое ответа соответствующим образом на основе значения его кода состояния.
Для дальнейшего чтения: если вам не знакомы f-строки Python 3.6, то я призываю вас срочно познакомится с ими, поскольку они являются отличным способом упростить использование строковых шаблонов.
И так мы изучили некоторые приемы работы с кодами состояния ответов сервера. Однако, когда мы посылаем GET запрос, нам редко нужна информация лишь о коде состояния. Обычно мы хотим получить нечто больше. Далее мы научимся получать и обрабатывать содержимое данных, которые сервер отправляет обратно в теле ответа.
Содержимое ответа (Content)
Чтобы получить содержимое ответа в бинарном виде, мы можем использовать свойство Response.content :
Несмотря на то, что свойство Response.content предоставляет нам доступ к “сырым” байтам полезного содержимого ответа и в большинстве случаев мы будем преобразовывать их в строку с заданной кодировкой символов, например, UTF-8. Объект Response легко сделает это для нас, предоставляя доступ к свойству Response.text :
Поскольку для декодирования байтов bytes в строку str требуется схема кодирования, то requests в начале попытается угадать кодировку содержимого ответа на основе его заголовков Content-Type, в том если вы предварительно их не укажете. Вы также можете указать кодировку явно, установив значение свойства объекта Response.encoding перед обращением к Response.text :
Отлично, тип возвращаемого методом Response.json() значения словарь, поэтому мы можем, как обычно, получить доступ к его значениям по соответствующему ключу.
Вы можете по разному использовать информацию о коде состояния и содержимое полученного ответа сервера, но если нам нужна дополнительная информация, такая, например, как метаданные о самом ответе, то вам нужно иметь дело с заголовками полученного ответа.
Заголовки ответа (Headers)
Заголовки ответа сервера могут дать много полезной информации, такой, например, как тип полезного содержимого ответа, ограничение по времени, в течение которого ответ будет кэшироваться и т.д. Чтобы просмотреть содержимое заголовков, необходимо обратиться к свойству объекта Response.headers :
При обращении к свойству Response.headers будет возвращен схожий со словарем объект, позволяющий получить доступ к значениям заголовков полученного ответа по ключу. Например, чтобы определить тип полезного содержимого ответа, получаем доступ к значению заголовка Content-Type :
У этого, как мы уже говорили, схожим со словарем объекте заголовков есть еще одна особенность. Спецификация HTTP определяет названия заголовков без учета регистра, это означает, что мы можем получить доступ к их значениям, совершенно не беспокоясь об регистре их наименований:
Параметры строки запроса (Query String Parameters)
Одним из самых распространенных способов настройки запроса GET является передача серверу данных в URL строки запроса.
Мы можем передавать значения в params метода get() как в виде словаря, как мы это только что сделали, так и в виде списка кортежей:
Так же можно передать данные в бинарном виде bytes :
Строка запроса используется для передачи параметров в GET запросах. Еще одним способом управления запросами к удаленным службам, является добавление или изменение отправляемых в них заголовков.
Заголовки запроса (Request Headers)
Другие HTTP методы запроса
Помимо GET существуют и другие часто используемые HTTP методы, например, POST, PUT, DELETE, HEAD, PATCH и OPTIONS. И библиотека requests ожидаемо предоставляет методы, со схожей как у метода get() нотацией использования, для отправки и управления настройками каждого из этих HTTP методов запросов:
Содержимое заголовков, полезного содержимого ответов, коды состояния и многие другие данные возвращаются с объектом Response для каждого вашего запроса, отправленного любым из методов.
Тело сообщения запроса
Таким образом все отправляемые данные содержатся в самом теле вашего запроса. Кроме того, методом POST на удаленный сервер нередко загружаются файлы.
Параметр data принимает словарь, список кортежей, байтов или файлоподобный объект. В каком конкретно виде посылать данные в теле запроса вы должны выбрать самостоятельно, исходя из требований удаленной службы (сервера) с которой хотите взаимодействовать.
Вы можете отправить те же данные в виде списка кортежей следующим образом:
httpbin.org — отличный вспомогательный ресурс, созданный автором requests Кеннетом Рейтцем. Это сервис принимает тестовые запросы и отправляет в ответ информацию о них. Например, вы можете использовать его для проверки корректности вашего POST-запроса:
Инспектируем отправленный запрос
Когда вы делаете запрос, библиотека requests предварительно готовит запрос, прежде чем отправить его на целевой сервер. Подготовка запроса включает в себя такие вещи, как проверка корректности заголовков и сериализация содержимого в формате JSON.
Просмотр содержимого PreparedRequest дает вам доступ ко всей информации о выполненном запросе, такой как полезное содержимое, URL, отправленные заголовки, данные аутентификации и многое другое.
Использование механизма сессий (Session)
И так давайте сохраним некоторые данные cookie в запросе:
Механизм сессий также можно применять для предварительной установки значений некоторых настроек по умолчанию и дальнейшем их использовании при отправке запросов. Это делается путем изменения соответствующих свойств объекта Session :
Все данные, которые вы затем будете передавать методу запроса, будут объединены с установленными значениями текущего сеанса сессии. При этом те параметры, которые вы будете передавать в метод запроса переопределят параметры сеанса сессии, которые мы задали по умолчанию.
И так мы рассмотрели несколько разновидностей отправляемых запросов, однако у них есть одно ограничение: они не позволяют отправлять аутентифицированные запросы к публичным API. Многие удаленные службы, с которыми вы можете столкнуться, требуют, чтобы вы каким-либо образом предоставляли аутентификационную информацию о себе.
Аутентификация
Здесь ваш настраиваемый механизм TokenAuth получает токен, а затем включает этот токен в заголовок X-TokenAuth вашего запроса.
При реализации собственных способов аутентификации помните, что простые механизмы проверки подлинности могут привести к уязвимостям безопасности, поэтому, если удаленной службе по какой-либо причине не требуется настраиваемый механизм проверки подлинности, всегда используйте проверенные схемы аутентификации, такие как Basic authentication или OAuth.
И так пока мы задумались о безопасности, давайте рассмотрим вопросы применения в ваших запросах SSL-сертификатов.
Проверка подлинности SSL сертификата (SSL Certificate Verification)
Всякий раз, когда данные, которые вы пытаетесь отправить или получить, являются конфиденциальными, вы начинаете думать о вопросах их безопасности. Вы общаетесь с защищенными сайтами используя протокол HTTP, устанавливая шифрованное соединение с использованием SSL, это означает, что проверка SSL-сертификата целевого сервера имеет решающее значение.
И так если вы захотите отключить проверку SSL-сертификата на удаленном сервере, достаточно передать значение False в именованный параметр verify :
Запрос успешен, и как мы видим, requests даже предупреждают вас о том, что вы отправили небезопасный запрос, чтобы помочь вам сохранить ваши данные в безопасности!
Производительность
Тайм-ауты Timeouts
Допустим ваше приложение отправляет запрос к некоторой удаленной службе, далее основной поток выполнения кода будет приостановлен, пока приложение будет дождаться ответа на отправленный запрос, и лишь после его получения продолжит свою работу. Конечно, если ваше приложение будет слишком долго ожидать ответ от сервера, то это может привести к следующим негативным последствиям: незавершенные запросы к удаленным службам могут автоматически сохраняться и накапливаться в памяти, пострадает отзывчивость интерфейса приложения на действия пользователя, а фоновые задания могут просто зависнуть.
Уточнение для тех, кто пока не сталкивался с этой проблемой. При выполнении синхронного кода каждая операция ожидает окончания предыдущей, то есть код выполняется строго последовательно в одном потоке. Поэтому приложение может зависнуть, если какая-то операция выполняется слишком долго.
Асинхронный код убирает блокирующую операцию из основного потока программы в отдельный, так что она продолжает выполняться, но в другой области памяти, а основной поток продолжает выполнение кода приложения.
В первом запросе время ожидания истекает через 1 секунду. Во втором — через 3,05 секунды.
Рекомендуется устанавливать timeout чуть больше 3 секунд, что определяется величиной кратной длительности по умолчанию окна повторной передачи TCP-пакетов.
И так если наш запрос устанавливает соединение с сервером в течение 2 секунд и получает от него данные в течение 5 секунд после установления соединения, то содержимое ответа сервера будет возвращено, как это было и раньше. Если же время ожидания истекло, то будет генерироваться исключение типа Timeout :
Таким образом, при необходимости код вашего приложения может перехватить исключение Timeout и обработать его соответствующим образом.
Объект сессии Session
Как мы уже знаем, сессии используются для сохранения некоторого набора настроек от запроса к запросу при обращении к какое-либо удаленной службе. Например, если вы хотите использовать одни и те же данные аутентификации в течение определенного периода времени для отправки нескольких запросов, то можете использовать сессии следующим образом:
Первичная оптимизация производительности с использованием механизма сессий происходит по причине того, что устанавливается постоянное соединение с сервером. Когда ваше приложение устанавливает соединение с сервером, используя сессии, происходит сохранение текущего соединения в общем пуле сервера. И когда ваше приложение снова захочет подключиться к тому же серверу, то будет повторно использоваться соединение из пула, а не устанавливать новое. Это позволяет сократить время обращения за данными к удаленной службе, что конечно же отражается на производительности вашего приложения.
Количество повторов запроса
В случае если ваш запрос по той или иной причине был неудачен, то вы можете указать приложению повторить тот же запрос заданное число раз. Однако requests не будет это делать для вас по умолчанию. Чтобы использовать эту возможность, необходимо реализовать свой так называемый транспортный адаптер Transport Adapter.
В тех случаях, когда вы используете объект github_adapter класса HTTPAdapter в текущей сессии, в объекте session будут сохраняться заданные вами свойства конфигурации для каждого запроса, отправляемого по адресу https://api.github.com.
Заключение
Поскольку теперь мы познакомились, с использованием библиотеки requests то, у вас появилась отличная возможность самостоятельно исследовать особенности взаимодействия с различными веб-сервисами и создавать потрясающие приложения, используя полезные данные, которые они предоставляют по вашим запросам.


