Oracle RAC. Общее описание / Часть 2
Продолжение статьи про Real Application Cluster (RAC). Окончание.
Считаем, что кластер поднялся и все закрутилось.
Взаимодействие узлов. Cache-fusion.
Много экземпляров БД, много дисков. Хлынули пользовательские запросы… вот они, клиенты, которых мы так ждали. =)
Самым узким местом любой БД являются дисковый ввод-вывод. Поэтому все базы данных стараются как можно реже обращаться к дискам, используя отложенную запись. В RAC все так же, как и для single-instance БД: у каждого узла в RAM располагается область SGA (System Global Area), внутри нее находится буферный кэш (database buffer cache). Все блоки, некогда прочитанные с диска, попадают в этот буфер, и хранятся там как можно дольше. Но кэш не бесконечен, поэтому, чтобы оценить важность хранимого блока, используется TCA (Touch Count Algorithm), считающий количество обращений к блокам. При первом попадании в кэш, блок размещается в его cold-end. Чем чаще к блоку обращаются, тем ближе он к hot-end. Если же блок «залежался», он постепенно утрачивает свои позиции в кэше и рискует быть замещенным другой записью. Перезапись блоков начинается с наименее используемых. Кэш узла – крайне важен для производительности узлов, поэтому для поддержания высокой производительности в кластере кэшем нужно делиться (как завещал сами-знаете-кто). Блоки, хранимые в кэше узла кластера, могут иметь роль локальных, т.е. для его собственного пользования, но некоторые уже будут иметь пометку глобальные, которыми он, поскрипев зубами дисками, будет делится с другими узлами кластера.
Технология общего кэша в кластере называется Cache-fusion (синтез кэша). CRS на каждом узле порождает синхронные процессы LMSn, общее их название как сервиса — GCS (Global Cache Service). Эти процессы копируют прочитанные на этом экземпляре блоки (глобальные) из буферного кэша к экземпляру, который за ними обратился по сети, и также отвечают за откат неподтвержденных транзакций. На одном экземпляре их может быть до 36 штук (GCS_SERVER_PROCESSES). Обычно рекомендуется по одному LMSn на два ядра, иначе они слишком сильно расходуют ресурсы. За их координацию отвечает сервис GES (Global Enqueue Service), представленный на каждом узле процессами LMON и LMD. LMON отслеживает глобальные ресурсы всего кластера, обращается за блоками к соседним узлам, управляет восстановлением GCS. Когда узел добавляется или покидает кластер, он инициирует реконфигурацию блокировок и ресурсов. LMD управляет ресурсами узла, контролирует доступ к общим блоками и очередям, отвечает за блокировки запросов к GCS и управляет обслуживанием очереди запросов LMSn. В обязанности LMD также входит устранение глобальных взаимоблокировок в рамках нескольких узлов кластера.

Таблица GRD распределена между узлами кластера. Каждый узел принимает участие в распределении ресурсов кластера, обновляя свою часть GRD. Часть таблицы GRD относится к ресурсам – объектам: таблицы, индексы и.т.п. Она постоянно синхронизируется (обновляется) между узлами.
Когда узел прочел блок данных с диска, он становится master-ом этого ресурса и делает соответствующую отметку в своей части таблицы GRD. Блок помечается как локальный, т.к. узел пока использует его в одиночку. Если же этот блок потребовался другому узлу, то процесс GCS пометит этот блок в таблице как глобальный («опубликован» для кластера) и передаст затребовавшему узлу.
| DBA | location | mode | role | SCN | PI/XI |
| 500 | узел №3 | shared | local | 9996 | 0 |
Без необходимости никаких записей на диск не происходит. Всегда копия блока хранится на узле, на котором он чаще используется. Если определенного блока пока еще нет в глобальном кэше, то при запросе master попросит соответствующий узел прочитать блок с диска и поделиться им с остальными узлами (по мере надобности).
Taking fire, need assistance! Workload distribution.
Описанное устройство Cache-fusion, предоставляет кластеру возможность самому (автоматически) реагировать на загрузку узлов. Вот как происходит workload distribution или resource remastering (перераспределение вычислительных ресурсов):
Если, скажем, через узел №1 1500 пользователей обращается к ресурсу A, и примерно в это же время 100 пользователей обращается к тому же ресурсу A через узел №2, то очевидно, что первый узел имеет большее количество запросов, и чаще будет читать с диска. Таким образом узел №1 будет определен как master для запросов к ресурсу A, и GRD будет создано и координироваться начиная с узла №1. Если узлу №2 потребуются те же самые ресурсы, то для получения доступа к ним он должен будет согласовать свои действия с GCS и GRD узла №1, для получения ресурсов через interconnect.
Если же распределение ресурсов поменяется в пользу узла №2, то процессы №2 и №1 скоординируются свои действия через interconnect, и master-ом ресурса A станет узел №2, т.к. теперь он будет чаще обращаться к диску.
Это называется родственность (affinity) ресурсов, т.е. ресурсы будут выделяться тому узлу, на котором происходит больше действий по получению и их блокированию. Политика родственности ресурсов скоординирует деятельность узлов, чтобы ресурсы более доступны были там, где это более необходимо. Вот, кратко, и весь workload distribution.
Перераспределение (remastering) также происходит, когда какой-то узел добавляется или покидает кластер. Oracle перераспределяет ресурсы по алгоритму называемому «ленивое перераспределение» (lazy remastering), т.к. Oracle почти не принимает активных действий по перераспределению ресурсов. Если какой-то узел упал, то все, что предпримет Oracle – это перекинет ресурсы, принадлежавшие обвалившемуся узлу, на какой-то один из оставшихся (менее загруженный). После стабилизации нагрузки GCS и GES заново (автоматически) перераспределят ресурсы (workload distribution) по тем позициям, где они более востребованы. Аналогичное действие происходит при добавлении узла: примерно равное количество ресурсов отделяется от действующих узлов и назначается вновь прибывшему. Потом опять произойдет workload distribution.
Как правило, для инициализации динамического перераспределения, загруженность на определенном узле должна превышать загруженность остальных в течение более 10 минут.
Вот пуля пролетела, и… ага? Recovery.
Но пока все эти процессы происходят, нетерпеливому клиенту есть что предложить.
Пока узлы спасают друг друга… Failover.
Virtual IP (VIP) – логический сетевой адрес, назначаемый узлу на внешнем сетевом интерфейсе. Он предоставляет возможность CRS спокойно запускать, останавливать и переносить работу с этим VIP на другой узел. Listener (процесс, принимающий соединения) на каждом узле будет прослушивать свой VIP. Как только какой-то узел становится недоступным, его VIP подхватывает на себя другой узел в кластере, таким образом, временно обслуживая свои и запросы упавшего узла.
Если узел восстановится и выйдет в online, CRS опознает это и попросит сбросить в offline на подменяющем его узле и вернет VIP адрес обратно владельцу. VIP относится к CRS, и может не перебросится если выйдет из строя именно экземпляр БД.
Важно отметить, что при failover переносятся только запросы select, вместе и открытыми курсорами (возвращающими результат). Транзакции не переносятся (PL/SQL, temp tables, insert, update, delete), их всегда нужно будет запускать заново.
Туда не ходи, сюда ходи… Load-balancing.
При выполнении любых операций, информацию, относящуюся к производительности запросов (наподобие «отладочной»), Oracle собирает в AWR (Automatic Workload Repository). Она хранится в tablespace SYSAUX. Сбор статистики запускается каждые 60 минут (default): I/O waits, wait events, CPU used per session, I/O rates on datafiles (к какому файлу чаще всего происходит обращение).
Необходимость в Load-balancing (распределении нагрузки) по узлам в кластере определяется по набору критериев: по числу физических подключений к узлу, по загрузке процессора (CPU), по трафику. Жаль что нельзя load-balance по среднему времени выполнения запроса на узлах, но, как правило, это некоторым образом связано с задействованными ресурсами на узлах, а следовательно оставшимися свободными ресурсам.
О Client load-balancing было немного сказано выше. Он просто позволяет клиенту подключаться к случайно выбранному узлу кластера из списка в конфигурации. Для осуществления же Server-side load-balancing отдельный процесс PMON (process monitor) собирает информацию о загрузке узлов кластера. Частота обновления этой информации зависит от загруженности кластера и может колебаться в пределе от приблизительно 1 минуты до 10 минут. На основании этой информации Listener на узле, к которому подключился клиент, будет перенаправлять его на наименее загруженный узел.
Если в приложении реализован connection pool, Oracle предоставляет вариант Runtime Connection Load Balancing (RCLB). Вместо обычного варианта, когда мы пытаемся предугадать, который из узлов будет менее загружен, и направить запрос туда, будет использован механизм оповещений (events) приложения о загрузке на узлах. И теперь уже само приложение будет определять куда отправить запрос, опираясь на эти данные. Оповещение происходит через ONS (Oracle Notification Service). RCLB регулярно получает данные (feedback) от узлов кластера, и connection pool будет раздавать подключения клиентам, опираясь на некоторое относительное число, отображающее какой процент подключений каждый экземпляр может выполнить. Эти метрики (средняя загрузка узла), которые пересылает RAC, каждый узел строит сам в AWR. На их основании формируется required load advisory и помещается в очередь AQ (advanced querying), откуда данные пересылаются через ONS клиенту.
Кластерные технологии СУБД Oracle. Часть 1
Кластерные системы традиционно рассматриваются в качестве альтернативы большим компьютерам, созданным на основе архитектуры симметричной мультипроцессорной обработки (SMP). Объединение вычислительных мощностей множества независимых компьютеров в единую систему для решения одной задачи позволяет вычислительным кластерам получить следующие преимущества над большими ЭВМ:
Система управления базами данных (СУБД) Oracle с помощью опции Real Application Clusters (RAC) может производить обработку единой базы данных одновременно с множества серверов объединенных в кластер. Механизм Oracle RAC поддерживает приложения с любым типом нагрузки, начиная от оперативной обработки транзакций до хранилищ и аналитических систем. В качестве приложений могут быть как «коробочные» продукты, так и самостоятельно разработанные приложения.
RAC обеспечивает для приложений высочайшие уровни доступности и масштабируемости:
• Выход из строя, какого либо из серверов не приводит к останову СУБД Oracle, работа будет продолжена на оставшихся узлах;
• Более высокая вычислительная мощность достигается простым добавлением требуемого количество серверов в кластер «на лету» без прерывания работы пользователей.
Технология Oracle RAC позволяет системам, построенным на основе недорогой аппаратной платформы, предоставлять высочайшее качество сервиса, сравнимое и даже превосходящее уровни доступности и масштабируемости самых дорогих SMP-систем и мэйнфреймов. Существенно сокращая расходы на обслуживание, и обеспечивая новые гибкие методы администрирования, программное обеспечение Oracle может быть использовано для создания среды Grid-вычислений предприятия.
Технология Oracle Real Application Clusters как опция СУБД Oracle была впервые представлена в Oracle 9i. На сегодняшний день Oracle RAC является проверенным решением, которое используется тысячами заказчиков по всему миру во всех отраслях экономики и для любых типов приложений.
Архитектура Real Applications Clusters
В «обычной» некластерной конфигурации к базе данных эксклюзивно имеет доступ один экземпляр программного обеспечения СУБД Oracle.
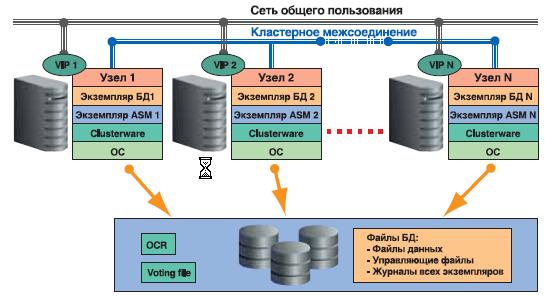
С кластерной базой данных, расположенной на общих дисковых устройствах, одновременно могут работать множество экземпляров СУБД Oracle, запущенных на различных узлах кластера. При увеличении вычислительных потребностей в кластер без остановки его работы можно добавить дополнительные узлы и экземпляры. Новые ресурсы могут быть задействованы в работу сразу после подключения. Для объединения аппаратных компонентов в единую вычислительную систему необходимо кластерное программное обеспечение, управляющее членством узлов в кластере, осуществляющее мониторинг состояния и управление различных составляющих и служб кластера, предоставляющее механизм для взаимодействия между приложениями работающими на разных узлах и другие важные базовые функции.
В качестве таких дисковых устройств могут быть использованы дисковые устройства, подключаемые через сеть (NAS), специализированные сети устройств хранения (SAN) или SCSI-диски. На выбор типа устройства хранения часто влияет размер кластера, используемая платформа сервера и поддержка производителя аппаратного обеспечения. Устройство хранения должно обеспечить достаточную производительность операций ввода-вывода приложений и быть хорошо масштабируемым при добавлении в кластер дополнительных узлов.
Для работы кластера необходимо две изолированных друг от друга сети. Публичная сеть для связи между клиентами и серверами кластера. С использованием этой сети производится подключение клиентских сессий к базе данных, их балансировка между узлами и аварийное переключение в случае сбоя. Приватная или внутренняя сеть, обычно называемая межсоединением, необходима для передачи сообщений между узлами. В RAC межсоединение используется для реализации технологии «слияния» кэш (Cache Fusion) различных узлов кластера.
В большинстве случаев для обеспечения межсоединения в кластере вполне достаточно использование Gigabit Ethernet.
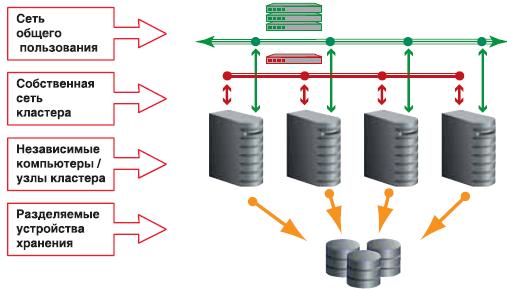
Дублирование сетевых интерфейсов увеличивает надежность кластерной конфигурации. Кластерное программное обеспечение Oracle Clusterware поддерживает до 100 узлов в кластере. Узлы кластера могут быть неидентичными, но должны иметь одинаковую аппаратную архитектуру, операционную систему и версию Oracle Cluserware.
Файловые системы и управление дисковым пространством
В качестве альтернативы Oracle поддерживает использование неформатированных дисковых разделов (сырых устройств) и некоторых кластерных файловых систем, например, таких как Oracle Cluster File System, доступная в операционных системах Windows и Linux.
Виртуальный IP адрес (VIP)
Это предотвращает длительные ожидания окончания IP-таймаутов и позволяет быстро идентифицировать недоступность узла. В конечном итоге это увеличивает скорость переключения на другой узел работающего приложения, повышая его доступность.
7 Рабочая нагрузка создаваемая сессиями одного Сервиса, распределяется и балансируется между узлами, которые назначены для обслуживания этого Сервиса. Интеграция с диспетчером ресурсов Database Resource Manager позволяет производить распределение ресурсов между сессиями различных Сервисов внутри каждого узла.
Производительность и качество выполнения каждого «Сервиса» отслеживается в автоматизированном репозитарии данных о рабочих нагрузках Automatic Workload Repository, входящем в состав СУБД начиная с Oracle Database 10g. Контроль за качеством выполнения «Cервиса» может осуществляться установкой пороговых показателей производительности, в случае нарушений которых производится автоматическое оповещение или выполнение заданных процедур. По каждому Сервису собирается детальная статистика его выполнения. Сервисы интегрируются с механизмом Oracle Streams Advanced Queuing и системой выполнения фоновых пакетных задач.
Каждый Сервис может выполняться на одном или нескольких экземплярах СУБД Oracle, а каждый экземпляр может поддерживать несколько Сервисов. Количество и состав экземпляров, которые обслуживает тот или иной Сервис определяются администратором базы данных независимо от самого приложения. При возникновении сбоя выполнение Сервисов автоматически восстанавливается на работающих экземплярах.
Использование приложением механизма быстрого оповещения приложения Fast Application Notification (FAN) позволяет ускорить реакцию приложения на сбои внутри кластера и улучшить качество распределения рабочей нагрузки между доступными вычислительными ресурсами. FAN обеспечивает интеграцию между базой данных RAC и приложением. Благодаря этому механизму приложение обладает информацией о конфигурации кластера в любой момент времени, поэтому приложения могут подключаться только к тем экземплярам, которые в текущий момент отвечают на запросы приложений. Инфраструктура высокой доступности Oracle RAC немедленно посылает событие FAN при изменении состояния кластера.
Клиентское приложение получает возможность быстрой реакции на события, происходящие в кластере. В качестве реакции на стороне сервера настраиваются вызовы внешних программ, которые можно, например, использовать для протоколирования проблем или уведомления администраторов о сбое. Клиенты Oracle JDBC, ODP.NET и OCI интегрированы с FAN. Другие приложения могут использовать возможности FAN при помощи программируемого интерфейса приложений и прямой подписки на события FAN.
Обеспечение высокой доступности для приложений
Беспрерывность при выполнении сервисного обслуживания
Real Application Clusters обеспечивает непрерывное обслуживание, как при сбоях, так и при выполнении запланированных сервисных работ. Большинство сервисных операций с базами данных может быть выполнено без остановки в обслуживании и прозрачно для пользователя. Другая часть работ по обслуживанию могут выполняться на узлах кластера поочередно, что приводит к значительной минимизации простоев.
В случае если обновление программного обеспечения Oracle сопровождается внесением изменений в словарь базы данных, Oracle предлагает использовать логическую резервную базу данных Oracle Data Guard. Такой подход позволяет минимизировать остановку в обслуживании только на время переключения ролей между основной и резервной базами данных. Эта процедура обновления включает в себя обновление логической резервной базы данных до следующего выпуска, запуск ее в смешанном режиме для проверки работоспособности обновления, изменение роли посредством переключения на обновленную базу данных, а затем обновление старой основной базы данных. При проведении тестирования в смешанном режиме возможна отмена установки обновления и восстановление старого программного обеспечения без потери данных. Для обеспечения защиты данных при этих процедурах можно использовать дополнительную резервную базы данных. Благодаря возможности поочередных обновлений с минимальными задержками Data Guard уменьшает время обслуживания для большинства административных задач, тем самым обеспечивая непрерывную работу системы 24×7 (7 дней в неделю по 24 часа).
Oracle Real Application Clusters обладает уникальной технологией масштабирования приложений. Типичный подход без использования кластеров заключается в замене сервера, которому уже не хватает мощности, новым сервером большего размера. Использование технологии RAC является альтернативой наращиванию вычислительной мощности одиночных серверов. Для того, что бы сохранить инвестиции, вложенные в уже имеющееся аппаратное обеспечение, можно просто добавить новый сервер к кластеру (или создать кластер). Приложения, обычно работающие на больших SMP-системах, могут быть переведены на кластеры, состоящие из небольших серверов.
Балансировка рабочей нагрузки
Для эффективного использования вычислительных ресурсов и обеспечения требуемого качества выполнения задач приложений, необходимо оптимальное распределение нагрузки между узлами кластера. Oracle Real Application Clusters обладает инновационной технологией распределения нагрузок, которая обеспечивает наилучшую производительность приложений и их высокую доступность на заданной конфигурации.
Пользователи приложений или серверы приложений промежуточного уровня соединяются с базой данных при помощи имени Сервиса. Oracle автоматически распределяет нагрузку пользователей среди множества узлов кластера обслуживающих запрошенный Сервис. Выделяя вычислительные мощности для определенного Сервиса, администраторы баз данных имеют возможность определять, на каких узлах работают клиенты выполняющие тот или иной круг задач. Администраторы для сервиса могут безболезненно добавлять вычислительные мощности при росте требований приложений.
Сетевой стек программного обеспечения Oracle SQL*NET, который обеспечивает взаимодействие между клиентом и сервером баз данных, обладает функцией балансировки нагрузки на уровне соединений. Балансировка нагрузки на уровне соединений осуществляется как на стороне клиента, так и на стороне сервера. Для балансировки нагрузки на стороне клиента необходимо в описании подключения к сервису перечислить все узлы кластера. SQL*NET случайно выбирает один из серверов. Если выбранный сервер недоступен, то производится попытка подключения к следующему серверу. Балансировка нагрузки на стороне сервера производится прослушивающим процессом (LISTENER). Каждый прослушивающий процесс получает информацию от всех экземпляров кластера об обслуживаемых Сервисах и о качестве их выполнения. В зависимости от целей, определенной для конкретного Сервиса, прослушивающий процесс выбирает экземпляр, наиболее точно подходящий для данной задачи, и производит с ним соединение.
Рассылка рекомендаций по балансировке нагрузки
Построение отказоустойчивого решения на базе Oracle RAC и архитектуры AccelStor Shared-Nothing
Немалое число Enterprise приложений и систем виртуализации имеют собственные механизмы для построения отказоустойчивых решений. В частности, Oracle RAC (Oracle Real Application Cluster) представляет собой кластер из двух или более серверов баз данных Oracle, работающих совместно с целью балансировки нагрузки и обеспечения отказоустойчивости на уровне сервера/приложения. Для работы в таком режиме необходимо общее хранилище, в роли которого обычно выступает СХД.
Как мы уже рассматривали в одной из своих статей, сама по себе СХД, несмотря на наличие дублированных компонент (в том числе и контроллеров), все же имеет точки отказа – главным образом, в виде единого набора данных. Поэтому, для построения решения Oracle с повышенными требованиями к надежности, схему «N серверов – одна СХД» необходимо усложнить.

Сперва, конечно, нужно определиться, от каких рисков мы пытаемся застраховаться. В рамках данной статьи мы не будем рассматривать защиту от угроз типа «метеорит прилетел». Так что построение территориально разнесенного решения disaster recovery останется темой для одной из следующих статей. Здесь мы рассмотрим так называемое решение Cross-Rack disaster recovery, когда защита строится на уровне серверных шкафов. Сами шкафы могут находиться как в одном помещении, так и в разных, но обычно в пределах одного здания.
Эти шкафы должны содержать в себе весь необходимый набор оборудования и программного обеспечения, который позволит обеспечивать работу баз данных Oracle независимо от состояния «соседа». Другими словами, используя решение Cross-Rack disaster recovery, мы исключаем риски при отказе:
Дублирование серверов Oracle подразумевает под собой сам принцип работы Oracle RAC и реализуется посредством приложения. Дублирование средств коммутации тоже не представляет собой проблему. А вот с дублированием системы хранения все не так просто.
Самый простой вариант – это репликация данных с основной СХД на резервную. Синхронная или асинхронная, в зависимости от возможностей СХД. При асинхронной репликации сразу встает вопрос об обеспечении консистентности данных по отношению к Oracle. Но даже если имеется программная интеграция с приложением, в любом случае, при аварии на основной СХД, потребуется вмешательство администраторов в ручном режиме для того, чтобы переключить кластер на резервное хранилище.
Более сложный вариант – это программные и/или аппаратные «виртуализаторы» СХД, которые избавят от проблем с консистентностью и ручного вмешательства. Но сложность развертывания и последующего администрирования, а также весьма неприличная стоимость таких решений отпугивает многих.
Как раз для таких сценариев, как Cross-Rack disaster recovery отлично подходит решение All Flash массив AccelStor NeoSapphire™ H710 с использованием архитектуры Shared-Nothing. Данная модель представляет собой двухнодовую систему хранения, использующую собственную технологию FlexiRemap® для работы с флэш накопителями. Благодаря FlexiRemap® NeoSapphire™ H710 способна обеспечивать производительность до 600K IOPS@4K random write и 1M+ IOPS@4K random read, что недостижимо при использовании классических RAID-based СХД.
Но главная особенность NeoSapphire™ H710 – это исполнение двух нод в виде отдельных корпусов, каждая из которых имеет собственную копию данных. Синхронизация нод осуществляется через внешний интерфейс InfiniBand. Благодаря такой архитектуре можно разнести ноды по разным локациям на расстояние до 100м, обеспечив тем самым решение Cross-Rack disaster recovery. Обе ноды работают полностью в синхронном режиме. Со стороны хостов H710 выглядит как обыкновенная двухконтроллерная СХД. Поэтому никаких дополнительных программных и аппаратных опций и особо сложных настроек выполнять не нужно.
Если сравнить все вышеописанные решения Cross-Rack disaster recovery, то вариант от AccelStor заметно выделяется на фоне остальных:
| AccelStor NeoSapphire™ Shared Nothing Architecture | Программный или аппаратный «виртуализатор» СХД | Решение на базе репликации | |
|---|---|---|---|
| Доступность | |||
| Отказ сервера | No Downtime | No Downtime | No Downtime |
| Отказ коммутатора | No Downtime | No Downtime | No Downtime |
| Отказ системы хранения | No Downtime | No Downtime | Downtime |
| Отказ всего шкафа | No Downtime | No Downtime | Downtime |
| Стоимость и сложность | |||
| Стоимость решения | Низкая* | Высокая | Высокая |
| Сложность развертывания | Низкая | Высокая | Высокая |
*AccelStor NeoSapphire™ – это все же All Flash массив, который по определению стоит не «3 копейки», тем более имея двукратный запас по емкости. Однако сравнивая итоговую стоимость решения на его базе с аналогичными от других вендоров, стоимость можно считать низкой.
Топология подключения серверов приложений и нод All Flash массива будет выглядеть следующим образом:
При планировании топологии также крайне рекомендуется сделать дублирование коммутаторов управления и интерконнекта серверов.
Здесь и далее речь будет идти о подключении через Fibre Channel. В случае использования iSCSI будет все то же самое, с поправкой на используемые типы коммутаторов и немного другие настройки массива.
Подготовительная работа на массиве
Спецификации серверов и коммутаторов
| Компоненты | Описание |
|---|---|
| Oracle Database 11g servers | Два |
| Server operating system | Oracle Linux |
| Oracle database version | 11g (RAC) |
| Processors per server | Два 16 cores Intel® Xeon® CPU E5-2667 v2 @ 3.30GHz |
| Physical memory per server | 128GB |
| FC network | 16Gb/s FC with multipathing |
| FC HBA | Emulex Lpe-16002B |
| Dedicated public 1GbE ports for cluster management | Intel ethernet adapter RJ45 |
| 16Gb/s FC switch | Brocade 6505 |
| Dedicated private 10GbE ports for data synchonization | Intel X520 |
Спецификация AccelStor NeoSapphhire™ All Flash массива
| Компоненты | Описание |
|---|---|
| Storage system | NeoSapphire™ high availability model: H710 |
| Image version | 4.0.1 |
| Total number of drives | 48 |
| Drive size | 1.92TB |
| Drive type | SSD |
| FC target ports | 16х 16Gb ports ( 8 на ноду) |
| Management ports | The 1GbE ethernet cable connecting to hosts via an ethernet switch |
| Heartbeat port | The 1GbE ethernet cable connecting between two storage node |
| Data synchronization port | 56Gb/s InfiniBand cable |
Перед началом использования массива его необходимо инициализировать. По умолчанию адрес управления обоих нод одинаковый (192.168.1.1). Нужно поочередно подключиться к ним и задать новые (уже разные) адреса управления и настроить синхронизацию времени, после чего Management порты можно подключить в единую сеть. После производится объединение нод в HA пару путем назначения подсетей для Interlink соединений.
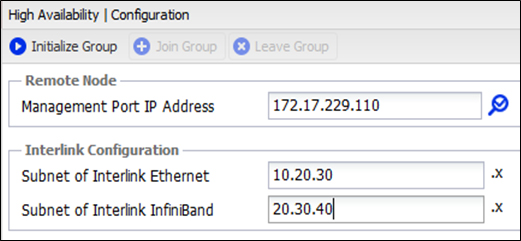
После завершения инициализации управлять массивом можно с любой ноды.
Далее создаем необходимые тома и публикуем их для серверов приложений.
Крайне рекомендуется создать несколько томов для Oracle ASM, поскольку это увеличит количество target для серверов, что в итоге улучшит общую производительность (подробнее об очередях в другой статье).
| Storage Volume Name | Volume Size |
|---|---|
| Data01 | 200GB |
| Data02 | 200GB |
| Data03 | 200GB |
| Data04 | 200GB |
| Data05 | 200GB |
| Data06 | 200GB |
| Data07 | 200GB |
| Data08 | 200GB |
| Data09 | 200GB |
| Data10 | 200GB |
| Grid01 | 1GB |
| Grid02 | 1GB |
| Grid03 | 1GB |
| Grid04 | 1GB |
| Grid05 | 1GB |
| Grid06 | 1GB |
| Redo01 | 100GB |
| Redo02 | 100GB |
| Redo03 | 100GB |
| Redo04 | 100GB |
| Redo05 | 100GB |
| Redo06 | 100GB |
| Redo07 | 100GB |
| Redo08 | 100GB |
| Redo09 | 100GB |
| Redo10 | 100GB |
Некоторые пояснения по поводу режимов работы массива и происходящих процессах при нештатных ситуациях
У набора данных каждой ноды имеется параметр «номер версии». После первичной инициализации он одинаков и равен 1. Если по каким-либо причинам номер версии различен, то всегда происходит синхронизация данных от старшей версии к младшей, после чего у младшей версии номер выравнивается, т.е. это означает, что копии идентичны. Причины, по которым версии могут быть различны:
В любом случае нода, остающаяся в online, увеличивает свой номер версии на единицу, чтобы после восстановления связи с парой синхронизировать ее набор данных.
Если происходит обрыв соединения по Ethernet линку, то Heartbeat временно переключается на InfiniBand и возвращается обратно в течение 10с при его восстановлении.
Настройка хостов
Для обеспечения отказоустойчивости и увеличения производительности необходимо включить поддержку MPIO для массива. Для этого нужно добавить в файл /etc/multipath.conf строки, после чего перезагрузить сервис multipath
devices <
device <
vendor «AStor»
path_grouping_policy «group_by_prio»
path_selector «queue-length 0»
path_checker «tur»
features «0»
hardware_handler «0»
prio «const»
failback immediate
fast_io_fail_tmo 5
dev_loss_tmo 60
user_friendly_names yes
detect_prio yes
rr_min_io_rq 1
no_path_retry 0
>
>
Далее, для того, чтобы ASM работал с MPIO через ASMLib, необходимо изменить файл /etc/sysconfig/oracleasm и затем выполнить /etc/init.d/oracleasm scandisks
# ORACLEASM_SCANORDER: Matching patterns to order disk scanning
ORACLEASM_SCANORDER=«dm»
# ORACLEASM_SCANEXCLUDE: Matching patterns to exclude disks from scan
ORACLEASM_SCANEXCLUDE=«sd»
Примечание
Если нет желания использовать ASMLib, можно использовать правила UDEV, которые являются основой для ASMLib.
Начиная с версии 12.1.0.2 Oracle Database опция доступна для установки как часть ПО ASMFD.
Обязательно следует убедиться, чтобы создаваемые диски для Oracle ASM были выровненными по отношению к размеру блока, с которым физически работает массив (4K). Иначе возможны проблемы с производительностью. Поэтому необходимо создавать тома с соответствующими параметрами:
parted /dev/mapper/device-name mklabel gpt mkpart primary 2048s 100% align-check optimal 1
Распределение баз данных по созданным томам для нашей тестовой конфигурации
| Storage Volume Name | Volume Size | Volume LUNs mapping | ASM Volume Device Detail | Allocation Unit Size |
|---|---|---|---|---|
| Data01 | 200GB | Map all storage volumes to storage system all data ports | Redundancy: Normal Name:DGDATA Purpose:Data files | 4MB |
| Data02 | 200GB | |||
| Data03 | 200GB | |||
| Data04 | 200GB | |||
| Data05 | 200GB | |||
| Data06 | 200GB | |||
| Data07 | 200GB | |||
| Data08 | 200GB | |||
| Data09 | 200GB | |||
| Data10 | 200GB | |||
| Grid01 | 1GB | Redundancy: Normal Name: DGGRID1 Purpose:Grid: CRS and Voting | 4MB | |
| Grid02 | 1GB | |||
| Grid03 | 1GB | |||
| Grid04 | 1GB | Redundancy: Normal Name: DGGRID2 Purpose:Grid: CRS and Voting | 4MB | |
| Grid05 | 1GB | |||
| Grid06 | 1GB | |||
| Redo01 | 100GB | Redundancy: Normal Name: DGREDO1 Purpose: Redo log of thread 1 | 4MB | |
| Redo02 | 100GB | |||
| Redo03 | 100GB | |||
| Redo04 | 100GB | |||
| Redo05 | 100GB | |||
| Redo06 | 100GB | Redundancy: Normal Name: DGREDO2 Purpose: Redo log of thread 2 | 4MB | |
| Redo07 | 100GB | |||
| Redo08 | 100GB | |||
| Redo09 | 100GB | |||
| Redo10 | 100GB |
# vi /etc/sysctl.conf
✓ fs.aio-max-nr = 1048576
✓ fs.file-max = 6815744
✓ kernel.shmmax 103079215104
✓ kernel.shmall 31457280
✓ kernel.shmmn 4096
✓ kernel.sem = 250 32000 100 128
✓ net.ipv4.ip_local_port_range = 9000 65500
✓ net.core.rmem_default = 262144
✓ net.core.rmem_max = 4194304
✓ net.core.wmem_default = 262144
✓ net.core.wmem_max = 1048586
✓ vm.swappiness=10
✓ vm.min_free_kbytes=524288 # don’t set this if you’re using Linux x86
✓ vm.vfs_cache_pressure=200
✓ vm.nr_hugepages = 57000
# vi /etc/security/limits.conf
✓ grid soft nproc 2047
✓ grid hard nproc 16384
✓ grid soft nofile 1024
✓ grid hard nofile 65536
✓ grid soft stack 10240
✓ grid hard stack 32768
✓ oracle soft nproc 2047
✓ oracle hard nproc 16384
✓ oracle soft nofile 1024
✓ oracle hard nofile 65536
✓ oracle soft stack 10240
✓ oracle hard stack 32768
✓ soft memlock 120795954
✓ hard memlock 120795954
sqlplus “/as sysdba”
alter system set processes=2000 scope=spfile;
alter system set open_cursors=2000 scope=spfile;
alter system set session_cached_cursors=300 scope=spfile;
alter system set db_files=8192 scope=spfile;
Тест на отказоустойчивость
В целях демонстрации использовался HammerDB для эмуляции OLTP нагрузки. Конфигурация HammerDB:
| Number of Warehouses | 256 |
| Total Transactions per User | 1000000000000 |
| Virtual Users | 256 |
В результате был получен показатель 2.1M TPM, что далеко от предела производительности массива H710, но является «потолком» для текущей аппаратной конфигурации серверов (прежде всего из-за процессоров) и их количества. Целью данного теста все же является демонстрация отказоустойчивости решения в целом, а не достижения максимумов производительности. Поэтому будем просто отталкиваться от этой цифры.
Тест на отказ одной из нод
Хосты потеряли часть путей до хранилища, продолжив работать через оставшиеся со второй нодой. Производительность просела на несколько секунд из-за перестройки путей, а затем вернулась к нормальным показателям. Перерыва в обслуживании не произошло.
Тест на отказ шкафа со всем оборудованием
В этом случае производительность также просела на несколько секунд из-за перестройки путей, а затем вернулась к половинному значению от исходного показателя. Результат снизился вдвое от первоначального из-за исключения из работы одного сервера приложений. Перерыва в обслуживании также не произошло.
Если имеются потребности в реализации отказоустойчивого решения Cross-Rack disaster recovery для Oracle за разумную стоимость и с небольшими усилиями по развертыванию/администрированию, то совместная работа Oracle RAC и архитектуры AccelStor Shared-Nothing будет одним из лучших вариантов. Вместо Oracle RAC может быть любое другое ПО, предусматривающее кластеризацию, те же СУБД или системы виртуализации, например. Принцип построения решения останется тем же. И итоговый показатель – это нулевое значение для RTO и RPO.


