Оптимизация скорости бэкапов средствами файловой системы (read ahead, опережающее чтение)
Данная статья адресована инженерам и консультантам работающим с производительностью операций, связанных с последовательным чтением файлов. В основном, это конечно бэкапы. Cюда же можно включить чтение больших файлов с файловых хранилищ, некоторые операции баз данных, например полное сканирование таблиц (зависит от размещения данных).
Примеры приведены для файловой системы VxFS (Symantec). Данная файловая система достаточно широко используется в серверных системах и поддерживается на HP-UX, AIX,Linux, Solaris.
Зачем это нужно?
Вопрос состоит в том, как получить максимальную скорость при последовательном чтении данных в один поток (!) из большого файла (бэкап большого числа мелких файлов за рамками данной статьи). Последовательным чтением считаем такое, когда блоки данных с физических дисков запрашиваются один за другим, по порядку. Считаем, что фрагментация файловых систем отсутствует. Это обоснованно, так как если на файловой системе расположено немного файлов большого размера, и они редко пересоздаются, то практически не фрагментированы. Это обычная ситуация для баз данных, типа Oracle. Чтение из файла в таком случае мало отличается от чтения с сырого устройства.
Чем ограничена скорость однопоточного чтения?
Самые быстрые из современных дисков (15K rpm) имеют время доступа (service time) около 5.5 мс (для почитателей queuing theory, считаем время ожидания равным 0).
Определим количество операций ввода-вывода, которое может выполнить процесс(бэкапа):
1/0.0055 = 182 IO per second (iops).
Если процесс последовательно выполняет операции, каждая из которых длится 5.5 мс, за секунду он выполнит 182 штуки. Предположим, что размер блока составляет 256KB. Таким образом, максимальная пропускная способность данного процесса составит: 182* 256= 46545 KB/s. (46 MB/s). Скромно, правда? Особенно скромно это выглядит для систем с сотнями физических шпинделей, когда мы расчитываем на гораздо большую скорость чтения. Возникает вопрос, как это оптимизировать. Уменьшить время доступа к диску нельзя, так как это технологические ограничения. Распараллелить бэкап тоже не всегда удается. Для снятия данного ограничения на файловых системах реализуется механизм опережающего чтения (read ahead).
Как работает опережающее чтение
В cовременных *nix системах существует два типа запросов ввода-вывода: синхронные и асинхронные. При синхронном запросе, процесс блокируется до получения ответа от дисковой подсистемы. При асинхронном, не блокируется и может делать что-либо еще. При последовательном чтении, мы читаем данные синхронно. Когда включается механизм опережающего чтения, код файловой системы, сразу после синхронного запроса, делает еще несколько асинхронных. Предположим, процесс запросил блок номер 1000. При включенном read ahead, кроме блока 1000 будут запрошены еще и 1001,1002,1003,1004. Таким образом, при запросе блока 1001 нам нет необходимости ждать 5.5 мс. C помощью настройки read ahead можно значительно (в разы) увеличить скорость последовательного чтения.
Как настраивается?
Ключевой настройкой опережающего чтения является его размер. Забегая вперед скажу, что с read ahead есть две основные проблемы: недостаточный read ahead и чрезмерный. Итак, на VxFS read ahead настраивается с помощью параметров “read_pref_io” и “read_nstream” команды vxtunefs. Когда на VxFS включается опережающее чтение, изначально запрашивается 4 блока размером “read_pref_io”. Если процесс продолжает читать последовательно, то прочитывается 4*read_pref_io*read_nstream.
Пример
Пусть read_pref_io=256k и read_nstream=4
Таким образом начальный read ahead составит: 4*256KB =1024KB.
Если последовательное чтение продолжается, то: 4*4*256KB=4096KB
Необходимо заметить, что в последнем случае, в дисковую подсистему отправятся практически одновременно 16 запросов с блоком 256KB. Это не мало и на короткое время может хорошенько подгрузить массив. В общем случае, в настройке read_pref_io и read_nstream сложно давать какие-то общие советы. Конкретные решения всегда зависят от числа дисков в массиве и характера нагрузки. Для некоторых нагрузок отлично работает read_pref_io=256k и read_nstream=32 (очень много). Иногда, read_ahead лучше отключить совсем. Так как настройка простая и ставится она на на лету, проще всего подбирать оптимальное значение. Единственное, что можно посоветовать, всегда ставить read_pref_io по степеням 2. Или как минимум, чтобы они были кратными размеру блока данных в кеше ОС. Иначе, последствия могут быть непредсказуемыми.
Влияние буферного кеша ОС
Когда read ahead асинхронно прочитывает данные, их надо хранить где-то в памяти. Для этого используется файловый кеш операционной системы. В ряде случаев, файловую систему можно смонтировать с отключенным файловым кешем (direct IO). Соответственно, функциональность read ahead в этом случае отключается.
Основные проблемы с опережающим чтением:
1) Недостаточный read ahead. Размер блока, который запросило приложение, больше блока считанного через read ahead. Например, команда ‘cp’ может читать блоком 1024 KB, а опережающее чтение настроено на чтение 256KB. То есть данных просто не хватит чтобы удовлетворить приложение и необходим еще один синхронный запрос ввода-вывода. В данном случае, включение read ahead не принесет увеличения скорости.
2) Чрезмерный read ahead
— слишком агрессивный read ahead может попросту перегрузить дисковую подсистему. Особенно, если в бэкенде установлено мало шпинделей. Большое число практически параллельных запросов свалившихся с хоста могут зафлудить дисковый массив. В этом случае, вместо ускорения вы увидите замедления в работе.
— другой проблемой с read ahead могут быть промахи, когда файловая система ошибочно определяет последовательное чтение прочитывает ненужные данные в кеш. Это приводит к паразитным операциям ввода-вывода, и создает дополнительную нагрузку на диски.
— так как данные read ahead хранятся в кеше файловой системы, большой объем read ahead может приводить к вымыванию из кеша более ценных блоков. Эти блоки потом придется прочитывать с диска снова.
3) Конфликт между read ahead файловой системы и read ahead дискового массива
К счастью, это крайне редкий случай. В большинстве современных дисковых массивов, оснащенных кеш-памятью и логикой, на аппаратном уровне реализован собственный механизм read ahead. Логика массива cама определяет последовательное чтение и контроллер оптом считывает данные с физических дисков в кеш массива. Это позволяет значительно сократить время отклика от дисковой подсистемы и увеличить скорость последовательного чтения. Опережающее чтение файловой системы несколько отличается от обычного синхронного чтения и может сбивать с толку контроллер дискового массива. Он может не распознать характер нагрузки и не включить аппаратный read ahead. Например, если дисковый массив подключен по SAN (Storage Area Networking) и до него есть несколько путей. Из-за балансировки нагрузки асинхронные запросы могут приходить на разные порты дискового массива практически одновременно. В таком случае, запросы могут быть обработаны контроллером не в том порядке, как они отправлены с сервера. Как следствие, массив не распознает последовательное чтение. Решение подобных проблем может быть наиболее долгим и трудоемким. Иногда решение лежит в области настройки, иногда помогает отключение одного из read ahead (если это возможно), иногда необходимо изменение кода одного из компонент.
Пример влияния опережающего чтения
Заказчик был неудовлетворен временем резервного копирования базы данных. В качестве теста, выполнялся бэкап одного файла размером 50 GB. Дальше приведены результаты трех тестов с различными настройками файловой системы.
Directories… 0
Regular files… 1
— Objects Total… 1
Total Size… 50.51 GB
1. Опережающее чтение выключено (Direct IO)
Run Time… 0:17:10
Backup Speed… 71.99 MB/s
2. Стандартные настройки опережающего чтения (read_pref_io = 65536, read_nstream = 1)
Run Time… 0:05:17
Backup Speed… 163.16 MB/s
3. Увеличенный (сильно) размер опережающего чтения (read_pref_io = 262144, read_nstream = 64)
Run Time… 0:02:27
Backup Speed… 222.91 MB/s
Как видно из примера, read ahead позволил значительно сократить время бэкапа. Дальнейшая эксплуатация показала, что все остальные задачи на системе нормально работали с таким большим размером read ahead (тест 3). Каких-либо проблем из-за чрезмерного read ahead не было замечено. В результате, эти настройки и оставили.
Read ahead что это
 Всем привет, давно хотел написать для себя напоминалку, по поводу того какие виды кэша на рейд контроллерах LSI и Intel бывают, и какие настройки лучше всего выставлять для достижения максимальной производительности на ваших RAID контроллерах. Сразу хочу отметить, что если у вас есть запас времени, перед, тем как отдать сервер в продашен заказчику, то не поленитесь все же провести несколько тестов с разными настройками, и не забывайте, до их начала обновить все прошивки на оборудование и RAID контроллер.
Всем привет, давно хотел написать для себя напоминалку, по поводу того какие виды кэша на рейд контроллерах LSI и Intel бывают, и какие настройки лучше всего выставлять для достижения максимальной производительности на ваших RAID контроллерах. Сразу хочу отметить, что если у вас есть запас времени, перед, тем как отдать сервер в продашен заказчику, то не поленитесь все же провести несколько тестов с разными настройками, и не забывайте, до их начала обновить все прошивки на оборудование и RAID контроллер.
Общие понятия по видам кэш
Существует три разновидности cache на RAID контроллерах:
Рассмотрим более детально, что из себя представляет каждая политика кэширования.
Read policy (Политика чтения)
Политика Read Ahead Policy: При ее включении контроллер начинает считывать последовательно сектора на диске, находящиеся за сектором с которого извлекается информация. При низкой фрагментации данная политика позволяет увеличить скорость чтения. Каждая операция чтения будет потреблять больше ресурсов жесткого диска, но если запросы на чтение последовательные это может существенно уменьшить количество запросов на чтение на жесткие диски и может существенно повысить производительность. Этот параметр будет работать только если типичный размер запроса на чтения меньше, чем ширина полосы пропускания.
Политика No Read Ahead (Normal) : При данном режиме контроллер не будет считывать последовательно данные, данный режим предпочтительнее когда будут производиться рандомные (случайные) чтения. Также этот режим рекомендуется при измерении последовательного чтения с помощью I/O meter под Windows.
Политика Adaptive Read Policy : по сути политика адаптивного чтения при которой контроллер запускает политику упреждающего чтения только после того, как две последние операции запрашивали доступ к последовательно идущим блокам данных. Если далее идут блоки рандомно разбросанные по дисковой подсистеме контроллер возвращается в нормальный режим работы. Этот режим рекомендуется использовать, если нагрузка на RAID контроллере подразумевает смешанные и последовательные операции.
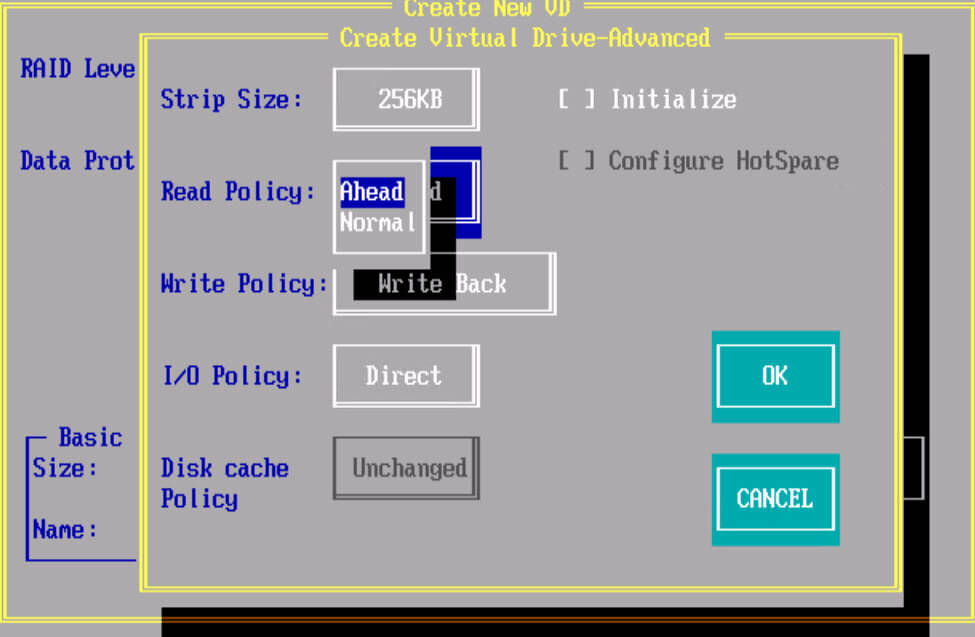
Write policy (Политика записи)
Политика W rite-Through : Включая данную политику контроллер начинает посылает сигнал о завершении записи только тогда, когда информация упадет на физические носители, т.е. 100 процентов будет уже на жестких дисках. Обеспечивает более высокую безопасность. Данный режим не использует кэш для ускорения записи, и будет медленнее других, однако позволяет так же достичь хороших показателей при RAID 0 и RAID 10.
Политика Write-Back : Включая данный режим политика кэширования RAID контроллера начинает посылать сигнал о завершении записи только тогда, когда информация попадает в кэш контроллера, но еще не записана на дисковый массив. Обеспечивает более высокую прозводительность чем при политике write-through. Приложение продолжает работать, не дожидаясь, чтобы данные были физически записаны на жесткие диски. Но есть одно большое, но если во время работы RAID контроллера в таком режиме у вас пропадет электричество, то с 99 процентной вероятностью вы потеряете данные, для предотвращения этого есть BBU батарейки или модули защиты данных, так же советую проверить что у вашего сервера есть UPS (источник бесперебойного питания) и дублирующее подключение питания от блока питания.
Политика Write-Back with BBU : Данный режим это все тот же Write-Back, но разница в том, что у нас есть батарейка BBU, которая предотвращает потерю данных при выключении электропитания.
BBU или Battery Backup Unit (Модуль Резервной Батареи). BBU дает батарейную защиту питания для cache RAID контроллера. В случае сбоя питания, BBU поможет сохранить данные в кэше.
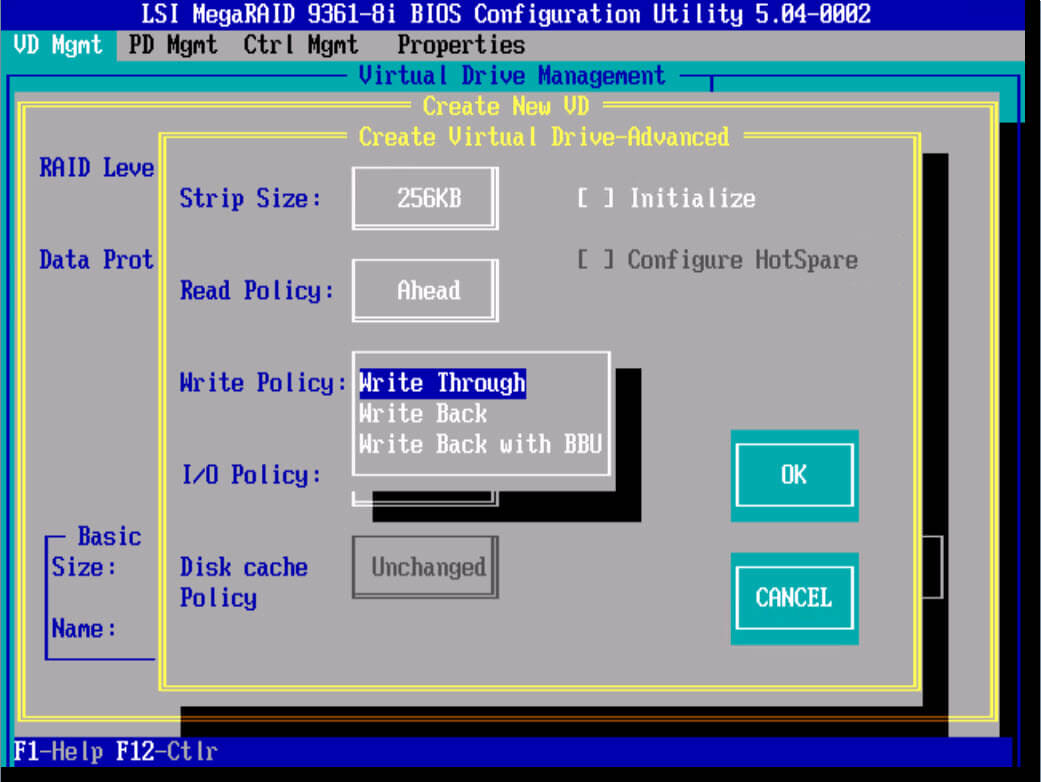
I/O Policy (Политика ввода/вывода)
Политика ввода/вывода определяет, будет ли RAID контроллер сохранять данные в кэше, который может уменьшить время доступа к ним при последующих запросах на чтение сделаными в те же самые блоки данных.
Политика direct IO : чтение происходит с дисков. Прямой режим I/O рекомендуется в большинстве случаев. Большинство файловых систем и множество приложений имеют свой собственный кэш и не требуют кэширования данных на уровне контроллера RAID.
Политика Cached IO : При ее включении чтение происходит с дисков, но прочитанные данные одновременно кладутся в кэш. Запросы тех же данных в последствии берутся из кэша. Этот режим может потребоваться, если приложение или файловая система не кэширует запросы чтения
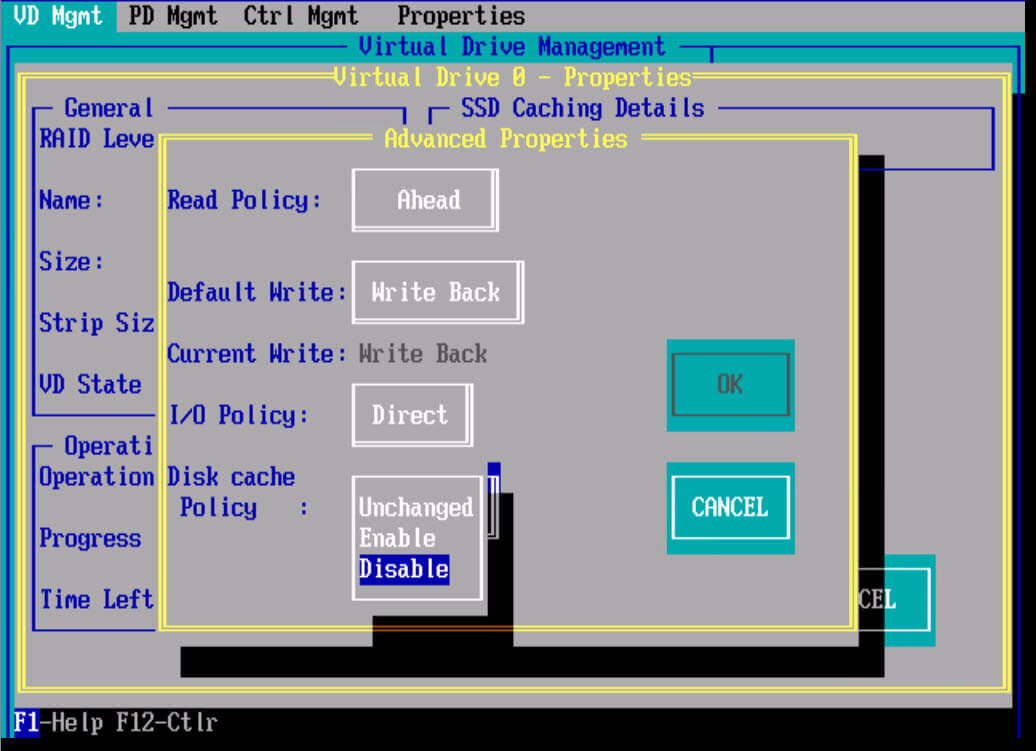
Disk cache policy : это политика кэша диска. Если ее включить то на дисках будет храниться дополнительный кэш, это будет влиять на скорость записи в худшую сторону, но будут быстрее считывание, так же при включенном режиме есть риск потери данных.
Настройка RAID контроллера для лучшей производительности
Любой инженер по системам хранения данных, хочет чтобы его инфраструктура работала как можно быстрее и использовала весь функционал заложенный в ней. Каждый вендор RAID контроллеров, имеет некий best prictice для своей продукции, давайте сегодня рассмотрим их на примере контроллеров Intel и LSI.
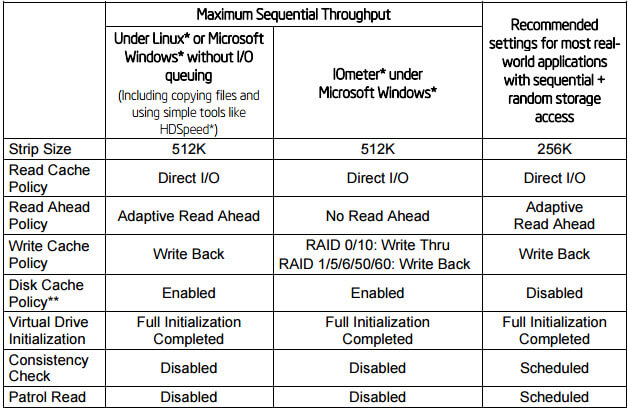
Оптимальные настройки для контроллеров Intel
Ниже представлена таблица с рекомендуемыми настройками для контроллеров Intel, для достижения максимальной производительности. О таких параметрах как Stripe size, Virtual Drive initialization, Consistency Check, Patrol Read мы поговорим ниже. Как видите лучшим режимом чтения является Adaptive Read Ahead, а режимом записи Write Back.
Оптимальные настройки для контроллеров LSI
Ниже представлена таблица с рекомендуемыми настройками для контроллеров LSI, для достижения максимальной производительности. Будут рассмотрены сводные таблицы для HDD и для SSd дисков.
Оптимальные настройки для HDD
Размер stripe 256 kb, включение disk Cache Policy включен, выбран I/O Policy Direct IO, нужно дать закончить lun инициализацию

MegaRAID Settings for Maximum HDD Performance
Оптимальные настройки для SSD
Размер stripe 256 kb, включение disk Cache Policy включен, выбран I/O Policy Direct IO, нужно дать закончить lun инициализацию, режимы записи для разных видов RAID разные.

MegaRAID Settings for Maximum SSD Performance
Оптимальные настройки для HP контроллеров
Факторы влияющие на производительность
Рассмотрим что такое Stripe size, Virtual Drive initialization, Consistency Check, Patrol Read.
HelpDesk
Чем мы можем вам сегодня помочь?
Виды кэша, настройка производительности на рейд контроллерах LSI и Intel Печать
Изменено: Сб, 2 Июл, 2016 at 1:52 AM
Общие понятия по видам кэш
Рассмотрим более детально, что из себя представляет каждая политика кэширования.
Read policy (Политика чтения)
Политика Read Ahead Policy: При ее включении контроллер начинает считывать последовательно сектора на диске, находящиеся за сектором с которого извлекается информация. При низкой фрагментации данная политика позволяет увеличить скорость чтения. Каждая операция чтения будет потреблять больше ресурсов жесткого диска, но если запросы на чтение последовательные это может существенно уменьшить количество запросов на чтение на жесткие диски и может существенно повысить производительность. Этот параметр будет работать только если типичный размер запроса на чтения меньше, чем ширина полосы пропускания.
Политика No Read Ahead (Normal): При данном режиме контроллер не будет считывать последовательно данные, данный режим предпочтительнее когда будут производиться рандомные (случайные) чтения. Также этот режим рекомендуется при измерении последовательного чтения с помощью I/O meter под Windows.
Политика Adaptive Read Policy: по сути политика адаптивного чтения при которой контроллер запускает политику упреждающего чтения только после того, как две последние операции запрашивали доступ к последовательно идущим блокам данных. Если далее идут блоки рандомно разбросанные по дисковой подсистеме контроллер возвращается в нормальный режим работы. Этот режим рекомендуется использовать, если нагрузка на RAID контроллере подразумевает смешанные и последовательные операции.
Write policy (Политика записи)
Disk cache policy: это политика кэша диска. Если ее включить то на дисках будет храниться дополнительный кэш, это будет влиять на скорость записи в худшую сторону, но будут быстрее считывание, так же при включенном режиме есть риск потери данных.
Адаптивный Read-Ahead
Применение
Назначением технологии упреждающего чтения (read-ahead) является существенное сокращение времени доступа и повышение пропускной способности системы хранения данных при работе с последовательным запросами на чтение.
Особую ценность механизм упреждающего чтения представляет в СХД, используемых для задач видеопроизводства, где нагрузка последовательного чтения может возникать одновременно с нескольких рабочих станций. При работе с множественными последовательными потоками происходит перемешивание траффика (блендер-эффект), при котором на входе в СХД поступает поток случайной нагрузки. Для эффективной работой в такой ситуации требуются особые механизмы распознавания и обнаружения запросов.
Принцип работы
Принцип работы технологии упреждающего чтения заключается в том, чтобы на основании уже существующих запросов определить, какие данные будут запрошены следующими, и заранее переносить их с жестких дисков на более быстрые носители, такие как RAM или SSD.
При этом, работа механизма упреждающего чтения состоит из двух этапов: (1) обнаружение запросов последовательного чтения в потоке всех запросов и (2) принятие решения, о необходимости считывания данных наперед, и их объеме.
Основная особенность механизма read-ahead в RAIDIX заключается в собственном алгоритме обнаружении запросов, который основан на понятии диапазонов, соответствующих связным интервалам адресного пространства. Для каждого пришедшего запроса на чтение происходит поиск ближайших диапазонов, по которому оценивается его тип нагрузки. Если запрос оказывается в последовательном диапазоне, то для него может быть произведено упреждающее чтение.
Далее в зависимости от скорости и размеров блоков для потока определяется оптимальное количество прогнозируемых данных, которые следует поместить в кэш (RAM). Поместив «горячие данные» на быстрый накопитель, система сокращает время запросов к этим блокам, что значительно повышает общую производительность СХД.
Работа с Незнайкой — технологии упреждающего чтения и гибридные СХД

Одним из способов улучшения производительности и уменьшения латентности в системах хранения данных (СХД) является использование алгоритмов, анализирующих входящих трафик.
С одной стороны, кажется, что запросы к СХД сильно зависят от пользователя и, соответственно, мало предсказуемы, но на деле это не так.
Утро практически любого человека одинаково: мы просыпаемся, одеваемся, умываемся, завтракаем, едем на работу. Рабочий день же, в зависимости от профессии, у всех разный. Также и загрузка СХД изо дня в день одинакова, а вот рабочий день зависит от того, где используется СХД и какая у неё типичная нагрузка (workload).
Для того, чтобы нагляднее представить наши идеи, мы воспользовались образами персонажей из детских рассказов о Николая Носова. В данной статье основными действующими лицами выступят Незнайка (случайное чтение) и Знайка (последовательное чтение).

Случайное чтение (random read) — Незнайка. C Незнайкой никто не хочет иметь дело. Его поведение не поддается логике. Хотя некоторые алгоритмы все-таки пытаются предсказать его поведение, например, изощренные алгоритмы упреждающей выборки из памяти типа C-Miner (о нем будет подробнее рассказано ниже). Это алгоритмы машинного обучения – значит, они требовательны к ресурсам СХД и не всегда успешны, но в связи с колоссальным развитием вычислительных мощностей процессоров в дальнейшем будут использоваться все больше и больше.
Если в СХД приходят одни Незнайки, то лучшим решением будет СХД на базе SSD (All-Flash Storage).
Последовательное чтение (sequential read) — Знайка. Строг, педантичен и предсказуем. Благодаря такому поведению его можно считать лучшим другом для СХД. Существуют алгоритмы упреждающего чтения (read ahead), которые умеют хорошо работать со Знайкой, они заранее помещают нужные данные в оперативную память, сводя латентность запроса к минимуму.
Блендер-эффект
Неужели Знайки в результате такой неразберихи станут Незнайками?
На помощь Знайке приходят алгоритм упреждающего чтения и детектор, который умеет идентифицировать разные типы запросов.
Упреждающее чтение
Одним из главных способов оптимизации, призванных сократить время доступа и повысить пропускную способность, является применение технологии упреждающего чтения (read ahead). Технология позволяет на основании уже запрошенных данных предугадывать, какие данные будут запрошены следующими, и переносить их с более медленных носителей информации (например, с жёстких дисков) на более быстрые (например, оперативная память и твёрдотельные накопители) до того, как к этим данным обратятся (рис. 2).
В большинстве случаев упреждающее чтение применяется при последовательных операциях.
Рис. 2. Упреждающее чтение
Работу алгоритма упреждающего чтения принято разделять на два этапа:
Реализация детектора в RAIDIX
Алгоритм упреждающего чтения в RAIDIX основан на понятии диапазонов, соответствующих связным интервалам адресного пространства.
Диапазоны обозначаются парами ( ), что соответствует адресу и длине запроса, и отсортированы по
), что соответствует адресу и длине запроса, и отсортированы по  . Они разделяются на случайные, длина которых меньше некоторого порога, и последовательные. Одновременно отслеживается до
. Они разделяются на случайные, длина которых меньше некоторого порога, и последовательные. Одновременно отслеживается до  случайных диапазонов и до
случайных диапазонов и до  последовательных.
последовательных.
Алгоритм детектора работает следующим образом:
1. Для каждого приходящего запроса на чтение производится поиск ближайших диапазонов в радиусе strideRange.
1.1. Если таковых не нашлось, создаётся новый случайный диапазон с адресом и длиной, соответствующим характеристикам запроса. При этом один из существующих диапазонов может быть вытеснен по LRU.
1.2. Если нашёлся один диапазон, запрос добавляется в него с расширением интервала. Случайный диапазон при этом может быть преобразован в последовательный.
1.3. Если нашлось два диапазона (слева и справа), они объединяются в один. Получившийся в результате этой операции диапазон также может быть преобразован в последовательный.
2. В случае, если запрос оказался в последовательном диапазоне, для этого диапазона может быть произведено упреждающее чтение.
Параметр упреждающего чтения может меняться в зависимости от скорости потока и размера блока.
На рисунке 3 схематично представлен алгоритм адаптивного упреждающего чтения, реализованный в RAIDIX.
Рис.3. Схема упреждающего чтения
Все запросы к СХД от клиента сначала попадают в детектор, его задача выделить последовательные потоки (отличить последовательные запросы от случайных).
Далее для каждого последовательного потока определяется его скорость  и размер
и размер  — средний размер запроса в потоке (обычно в потоке все запросы одинакового размера).
— средний размер запроса в потоке (обычно в потоке все запросы одинакового размера).
Каждый поток сопоставляется с параметром упреждающего чтения  .
.
Таким образом, с помощью алгоритма упреждающего чтения мы справляемся c эффектом «I/O блендера» и для последовательных запросов гарантируем пропускную способность и latency, сопоставимую с параметрами оперативной памяти.
Таким образом Знайка побеждает Незнайку!
Производительность случайного чтения
Как же можно поднять производительность случайного чтения?
Для этих целей разработчики Винтик и Шпунтик предлагают использовать более быстрые носители, а именно SSD и гибридное решение (тиринг или SSD-кэш).

Также можно воспользоваться ускорителем случайных запросов — алгоритмом упреждающего чтения С-Miner.
Основная задача всех этих методов — посадить Незнайку на «быстрый» автомобиль 🙂 Проблема в том, что автомобилем надо уметь управлять, а у Незнайки уж слишком непредсказуемый характер.

C-Miner
Одним из наиболее интересных алгоритмов, используемых для упреждающего чтения при случайных запросах, является C-Miner, основанный на поиске корреляций между адресами последовательно запрашиваемых блоков данных.
Этот алгоритм обнаруживает семантические связи между запросами, такими как запрос метаданных файловой системы перед чтением соответствующих им файлов или поиск записи в индексе СУБД.
Работа C-Miner состоит из следующих этапов:
Алгоритм C-Miner хорошо подходит для систем хранения, данные в которых редко обновляются, но запрашиваются часто и небольшими порциями. Такой сценарий использования позволяет составить набор правил, который не устареет долгое время, а также не замедлит выполнение первых запросов (появившихся до создания правил).
В классической реализации зачастую возникает множество правил с низкой надежностью. В связи с этим алгоритмы упреждающего чтения довольно плохо справляются со случайными запросами. Гораздо эффективнее использовать гибридное решение, в рамках которого наиболее популярные запросы попадают на более производительные накопители, например, SSD- или NVME-диски.
SSD-кэш или SSD-тиринг?
Возникает вопрос, какую технологию лучше выбрать: SSD-кэш или SSD-тиринг? Ответить на этот вопрос поможет детальный анализ рабочей нагрузки.
SSD-кэш схематично изображен на рисунке 4. Здесь запросы сначала попадают в оперативную память, а далее, в зависимости от типа запроса, могут быть вытеснены в SSD-кэш или в основную память.
Рис. 4. SSD-кэш
SSD-тиринг имеет другую структуру (рис. 5). При тиринге ведется статистика горячих областей, и в фиксированные моменты времени горячие данные переносятся на более быстрый носитель.
Рис. 5. SSD-тиринг
Основное отличие SSD-кэша от SSD-тиринга заключается в том, что данные в тиринге не дублируются в отличие от SSD-кэша, в котором «горячие» данные хранятся как в кэше, так и на диске.
В таблице ниже приведены некоторые критерии выбора того или иного решения.
| Тиринг | Кэш | |
|---|---|---|
| Метод исследования | Предсказание будущих значений | Выявление локальностей в данных |
| Нагрузка (workload) | Предсказуемая. Слабо меняющаяся | Динамичная, непредсказуемая. Требует мгновенной реакции |
| Данные | Не дублируются (диск) | Дублируются (буфер) |
| Миграция данных | Offline-алгоритм, окно релокации (relocation window). Есть временной параметр перемещения данных | Online-алгоритм, данные вытесняются и попадают в кэш на лету. |
| Способы исследования | Регрессионные модели, модели предсказания, долговременная память | Кратковременная память, алгоритмы вытеснения |
| Взаимодействие | HDD-SSD | RAM-SSD, взаимодействие с SSD через алгоритмы упреждающего чтения |
| Блок | Большой (например, 256 МБ) | Маленький (например, 64 КБ) |
| Алгоритм | Функция, зависящая от времени переноса и статистических характеристик адресов памяти | Алгоритмы вытеснения и заполнения кэша |
| Чтение/запись | Случайное чтение | Любые запросы, в том числе на запись, за исключением последовательного чтения (в большинстве случаев) |
| Девиз | Чем сложнее, тем лучше | Чем проще, тем лучше |
| Ручной режим переноса нужных данных | Возможен | Не возможен — противоречит логике кэша |
В основе любого гибридного решения, так или иначе, лежит предсказание будущей нагрузки. В тиринге мы пытаемся по прошлому предсказать будущее, в SSD-кэше считаем, что вероятность использования недавних и частотных запросов выше, чем давно используемых и низкочастотных. В любом случае в основе алгоритмов лежит исследование «прошлой» нагрузки. Если характер нагрузки меняетcя, например, начинает работать новое приложение, то нужно время, чтобы алгоритмы адаптировались к изменениям.
Незнайка не виноват (характер у него такой — случайный), что гибридное решение плохо управляется в неизвестной новой местности!

Но даже при правильном «предсказании» производительность гибридного решения будет невысокой (значительно ниже максимальной производительности, которую может выдать SSD-диск).
Сколько IOPS ожидать от SSD-кэша?
Допустим, что у нас есть SSD-кэш размером 2ТБ, а кэшируемый том имеет размер 10ТБ. Мы знаем, что какой-то процесс читает случайным образом весь том с равномерным распределением. Также знаем, что из SSD-кэша мы умеем читать со скоростью 200К IOPS, а из некэшированной области со скоростью 3К IOPS. Предположим, что кэш уже наполнился, и в нём лежат 2ТБ из 10 читаемых. Сколько IOPS мы получим? На ум приходит очевидный ответ: 200К * 0,2 + 3К * 0,8 = 42,4К. Но так ли всё просто на самом деле?
Давайте попробуем разобраться, применив немного математики. Наши расчеты несколько отклоняются от реальной практики, но вполне допустимы в целях оценки.
Пусть x% читаемых данных (или даже запросов) лежат (обрабатываются) в кэше SSD.
Считаем, что SSD-кэш обрабатывает запросы со скоростью u IOPS. А запросы, идущие на HDD, обрабатываются со скоростью v IOPS.
Для начала рассмотрим случай, когда iodepth (глубина очереди запросов) = 1.
Примем размер всего читаемого пространства за 1. Тогда доля данных (запросов), находящихся (обрабатываемых) в кэше составит x/100.
Пусть за 1 секунду обрабатывается  запросов. Тогда из них
запросов. Тогда из них  обработаются в кэше, а остальные
обработаются в кэше, а остальные  пойдут на HDD. Это верно вследствие того, что чтение происходит с равномерным распределением.
пойдут на HDD. Это верно вследствие того, что чтение происходит с равномерным распределением.
Примем за  общее время, потраченное на те запросы, которые пошли в SSD, а за
общее время, потраченное на те запросы, которые пошли в SSD, а за  время, потраченное на запросы к HDD.
время, потраченное на запросы к HDD.
Так как сейчас рассматриваем всего одну секунду, то  (сек).
(сек).
Имеем такое равенство (1):  . С использованием единиц измерения: IOPS * сек + IOPS * сек = IO.
. С использованием единиц измерения: IOPS * сек + IOPS * сек = IO.
Также имеем следующее (2):  . Выразим I:
. Выразим I:  .
.
Подставим в (1) полученное из (2) I:  . Выразим , учитывая, что
. Выразим , учитывая, что  .
.
Знаем , тогда знаем и  .
.
Получили времена и , теперь можем их подставить в (1):  .
.
Упрощаем равенство:  .
.
Отлично! Теперь мы знаем количество IOPS при iodepth = 1.
Что же будет при iodepth > 1? Эти выкладки станут неверными, а точнее, не совсем верными. Можно попробовать рассмотреть несколько параллельных потоков, для каждого из которых iodepth = 1, или придумать иной способ, однако при достаточной длительности теста эти неточности сгладятся, и картина окажется такой же, как и при iodepth = 1. Полученный результат всё равно будет отражать реальную картину.
Итак, отвечая на вопрос «а сколько же будет IOPS?», применяем формулу:

ОБОБЩЕНИЕ
А что, если у нас не равномерное распределение, а какое-нибудь более близкое к жизни?
Возьмём, например, распределение Парето (правило 80/20 — к 20% самых «горячих» данных идёт 80% запросов).
В этом случае полученная формула также работает, т. к. мы нигде не опирались на размер пространства и размер SSD. Нам лишь важно знать, сколько % запросов (в данном случае – именно запросов!) обработается в SSD.
Если размер SSD-кэша составляет 20% от всего читаемого пространства и вмещает в себя эти 20% самых «горячих» данных, то 80% запросов будет идти в SSD. Тогда по формуле I(80, 200000, 3000) ≈ 14150 IOPS. Да, скорее всего, это меньше, чем вы думали.
Давайте построим график I(x) при u = 200000, v = 3000.
Результат существенно отличается от интуитивно понятного. Таким образом, вручая Незнайке ключи от быстрого автомобиля, мы не всегда можем ускорить производительность системы. Как видно из графика выше, только All-Flash решение (где все диски — твердотельные) может реально ускорить случайное чтение до максимума, «выжимаемого» из SSD-диска. Виноват в этом не Незнайка и, конечно, не разработчики систем хранения данных, а простая математика.


