Применение библиотеки FuzzyWuzzy для нечёткого сравнения в Python. Расстояние Левенштейна (редакционное расстояние)
У него не было уверенности, что он правильно расслышал. От этого так много зависело! Но не переспрашивать же? (с) Борис Акунин. Весь мир театр.
Работая над голосовым помощником, который упоминается в предыдущей статье, понял, что просто не могу с вами не поделиться прекраснейшей библиотекой FuzzyWuzzy.
Если коротко, то благодаря ей существует возможность произвести нечёткое сравнение строк без каких-либо страданий.
Первые шаги
Для начала работы необходимо проделать два шага:
/ВАЖНО! Версия Python 2.7 и выше/
Открываем командную строку и вписываем:
Нажимаем Enter.
Далее устанавливаем таким же образом python-Levenshtein для ускорения сопоставления строк в 3-10 раз.
После завершения установки библиотека готова к импортированию.
Шаг 2. Импортирование в проект.
Функционал
1. Самое обычное сравнение:
Если мы изменим пару символов, то на выходе получим другое число.
2. Частичное сравнение
Данный вид сравнения во всей второй строке ищет совпадение с начальной, например:
Но следует помнить про регистр, так как
3. Сравнение по токену
1) Token Sort Ratio
Слова сравниваются друг с другом, независимо от регистра или порядка
2) Token Set Ratio
Это сравнение, в отличие от прошлого, приравнивает строки, если их отличие заключается в повторении слов.
4. Продвинутое обычное сравнение
Во многих случаях более целесообразно использовать именно WRatio, так как оно учитывает регистр букв и знаки препинания (не делящие строку)
5. Работа со списком
Для сравнения строки со строками из списка используется модуль process
Если необходим только первый в списке, то лучше использовать extractOne
Применение
Как и где применять всё вышеизложенное решать вам, но вот пример из моей курсовой работы:
Давайте пробежимся по коду и поймём что к чему.
Командой os.listdir мы получаем список всех файлов, которые присутствуют в конце указанного пути (в нашем случае на рабочий стол).
Далее идёт сравнение строк списка файлов с именем файла, который назвал пользователь (переменная namerec). Надеюсь, вы обратили внимание, что результатом функции extractOne является кортеж из строки и цифры (индекс сходства)
Исходя из этого, делаем проверку индекса сходства filestart[1] >= 80 ([1], так как в кортеже нумерация с 0, как в массиве) и, если условие верно, то запускаем функцией os.startfile файл с названием filestart[0]. Иначе, если индекс сходства меньше 80 или вылетает ошибка, что файл не найден — сообщаем это пользователю через функцию speak.
Все дороги ведут к матану
Если вам не интересна математика, то можете смело закрывать статью, так как сейчас будет мясо(нет). Сейчас постараюсь кратко и понятно донести смысл расстояния Левенштейна до таких же чайников, как и я.
Расстояние Левенштейна (редакционное расстояние, дистанция редактирования) — метрика, измеряющая разность между двумя последовательностями символов.
У нас есть две строки S1 размером i и S2 размером j
S1=vrhk
S2=rhgr
Существует только 3 операции:
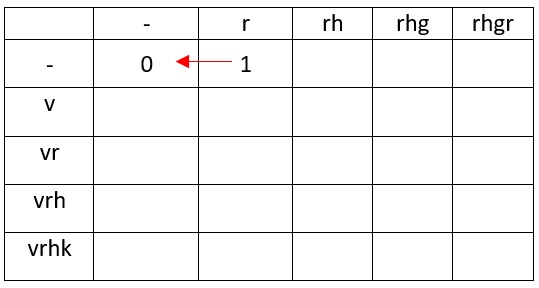
Откуда в таблице появились 0 и 1? Для превращения пустого символа в пустой символ нам никаких операций проводить не нужно (пишем в таблицу — «0»), а для превращения символа r в пустую строку, необходимо удалить r (одно действие, пишем в таблицу — «1»). С символом v аналогичная ситуация.
Для перехода rh в пустой символ необходимо сначала удалить h, а потом r (используется две операции), следовательно, таблица примет вид:

Теперь рассмотрим ситуацию превращения v в r (отмечена зелёным кругом на таблице).
Существует несколько путей, но мы выбираем наименьший — превращение пустого символа в v.
В ячейку заносим 1. Как так получилось? Мы представляем r как строку, которую нужно превратить в строку v. Перед r существует пустой символ, который мы заменяем на v, получая строку rv. Так как мы проверяем символы справа налево, то v совпадает с v.

Пришло время рассмотреть превращение v в rh
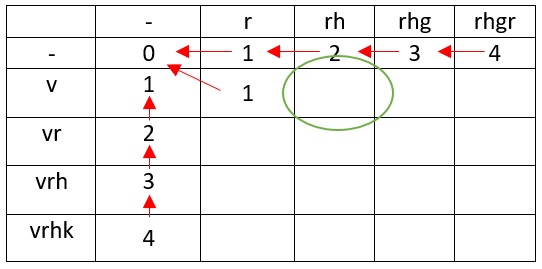
Самый удачный вариант — v мы заменяем на h и всё сводится к задаче превращения r в пустую строку.

Результат заносим в таблицу.

В сравнении vr с r нужно учесть, что последние символы совпадают, а это значит, что задача просто сводится до более простой, без изменения расстояния Левенштейна.

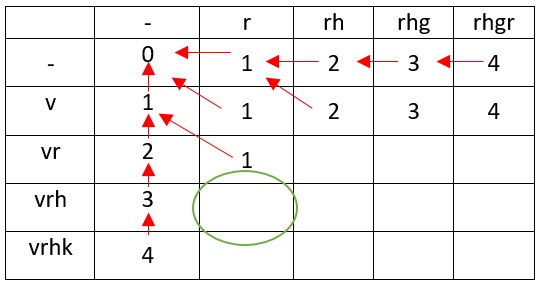
При преобразовании vrh в r достаточно удаления h и эта задача сводится к предыдущей (сравнение vr с r), следовательно расстояние будет равно 2


Как и в случае сравнения vr с r у нас совпадают окончание строк vrh и rh, следовательно, расстояние не изменится.
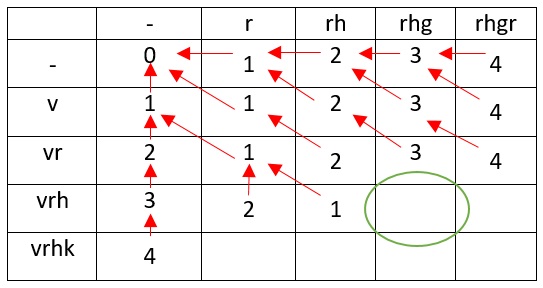
Заметьте, что vrh и rhg идентичны с нашим предыдущим преобразованием, но с отличием в одну букву, которую просто необходимо убрать, именно из-за этого наше расстояние увеличивается на единицу (обратите внимание на стрелку).
Опираясь на все примеры, описанные выше, мы получаем кратчайшое редакционное расстояние (расстояние Левенштейна) между двумя строками — vrhk и rhgr.
python-Levenshtein 0.12.2
pip install python-Levenshtein Copy PIP instructions
Released: Feb 1, 2021
Python extension for computing string edit distances and similarities.
Navigation
Project links
Statistics
View statistics for this project via Libraries.io, or by using our public dataset on Google BigQuery
License: GNU General Public License v2 or later (GPLv2+) (GPL)
Tags string, Levenshtein, comparison, edit-distance
Maintainers
Classifiers
Project description
Maintainer wanted
I am looking for a new maintainer to the project as it is apparent that I haven’t had the need for this particular library for well over 7 years now, due to it being a C-only library and its somewhat restrictive original license.
Introduction
The Levenshtein Python C extension module contains functions for fast computation of
It supports both normal and Unicode strings.
Python 2.2 or newer is required; Python 3 is supported.
StringMatcher.py is an example SequenceMatcher-like class built on the top of Levenshtein. It misses some SequenceMatcher’s functionality, and has some extra OTOH.
Levenshtein.c can be used as a pure C library, too. You only have to define NO_PYTHON preprocessor symbol (-DNO_PYTHON) when compiling it. The functionality is similar to that of the Python extension. No separate docs are provided yet, RTFS. But they are not interchangeable:
Installation
Documentation
License
Levenshtein is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version.
See the file COPYING for the full text of GNU General Public License version 2.
History
This package was long missing from the Python Package Index and available as source checkout only, but can now be found on PyPI again.
We needed to restore this package for Go Mobile for Plone and Pywurfl projects which depend on this.
Библиотека FuzzyWuzzy Python
В этом руководстве мы узнаем, как сопоставить строки, используя встроенную библиотеку fuzzyWuzzy в Python, и определим, насколько они похожи, на различных примерах.
Python предоставляет несколько методов для сравнения двух строк. Ниже приведены основные методы:
Но есть еще один метод для нечеткого сравнения строк, который можно эффективно использовать, он называется fuzzywuzzy. Этот метод довольно эффективен для различения двух строк, относящихся к одному и тому же объекту, но написанных немного по-разному. Иногда нам нужна программа, которая может автоматически определять неправильное написание.
Это процесс поиска строк, соответствующих заданному шаблону. Он использует расстояние Левенштейна для вычисления разницы между последовательностями.
Эта библиотека может помочь сопоставить базы данных, в которых отсутствует общий ключ, например, объединить две таблицы по названию компании, и они по-разному отображаются в обеих таблицах.
Посмотрим на следующий пример.
Приведенный выше код возвращает истину, потому что строки совпадают точно(100%), что, если мы внесем изменения в str2.
Здесь приведенный выше код возвращает ложь, строки почти идентичны для человеческого глаза, но не для интерпретатора. Однако мы можем решить эту проблему, преобразовав обе строки в нижний регистр.
Но если мы внесем изменения в кодировку, у нас возникнет другая проблема.
Чтобы решить такие проблемы, нам нужны более эффективные инструменты для сравнения строк. И fuzzywuzzy – лучший инструмент для вычисления строк.
Расстояние Левенштейна
Расстояние Левенштейна используется для вычисления расстояния между двумя последовательностями слов. Оно вычисляет минимальное количество правок, которые нам нужно изменить в данной строке. Эти изменения могут быть вставкой, удалением или заменой.
Мы будем использовать указанную выше функцию в предыдущем примере, где мы пытались сравнить «Добро пожаловать в javatpoint» и «Добро пожаловать в javatpoint». Мы видим, что обе строки, скорее всего, совпадают, потому что длина Левенштейна мала.
Пакет FuzzyWuzzy
Название этой библиотеки какое-то странное и забавное, но она очень полезна. Она имеет уникальный способ сравнения обеих строк и возвращает результат из 100 возможных для соответствия количеству строк. Для работы с этой библиотекой нам необходимо установить ее в нашей среде Python.
Установка
Мы можем установить эту библиотеку с помощью команды pip.
Теперь введите следующую команду и нажмите ввод.
Давайте разберемся в следующих методах библиотеки fuzzuwuzzy.
Модуль Fuzz
Модуль fuzz используется для одновременного сравнения двух заданных строк. Он возвращает оценку из 100 после сравнения с использованием различных методов.
Fuzz.ratio()
Это один из важных методов модуля fuzz. Он сравнивает строку и оценку на основе того, насколько данная строка соответствует. Давайте разберемся в следующем примере.
Как видно из приведенного выше кода, метод fuzz.ratio() вернул оценку, что означает очень небольшую разницу между строками.
Fuzz.partial_ratio()
Библиотека fuzzywuzzy предоставляет еще один мощный метод – partial_ratio(). Он используется для обработки сложного сравнения строк, такого как сопоставление подстрок. Посмотрим на следующий пример.
Метод partial_ratio() может обнаружить подстроку. Таким образом, дает 100% сходство. Он следует оптимальной частичной логике, в которой для короткой строки k и более длинной строки m алгоритм находит наилучшую совпадающую длину k-подстроки.
Fuzz.token_sort_ratio
Этот метод не гарантирует получения точного результата, потому что если мы внесем изменения в порядок строк, это может не дать точного результата.
Но модуль fuzzywuzzy предоставляет решение. Давайте разберем следующий пример.
В приведенном выше коде мы использовали метод token_sort_ratio(), который дает преимущество перед partial_ratio. В этом методе строковые токены сортируются в алфавитном порядке и объединяются. Но есть и другая ситуация, например, когда строки сильно различаются по длине.
В приведенном выше коде мы использовали другой метод, называемый fuzz.token_set_ratio(), который выполняет операцию набора и извлекает общий токен, а затем выполняет попарное сравнение ratio().
Пересечение отсортированного токена всегда одно и то же, потому что подстрока или меньшая строка состоит из больших фрагментов исходной строки, или оставшийся токен находится близко к другому.
Пакет fuzzywuzzy предоставляет модуль процесса, который позволяет нам вычислять строку с наибольшим сходством. Давайте разберемся в следующем примере.
Приведенный выше код вернет наивысший процент совпадений для данного списка строк.
Fuzz.WRatio
Модуль процесса также предоставляет WRatio, который дает лучший результат, чем простое соотношение. Он обрабатывает нижний и верхний регистры, а также некоторые другие параметры. Давайте разберемся в следующем примере.
Заключение
В этом уроке мы обсудили, как сопоставить строки и определить, насколько они схожи. Мы проиллюстрировали простые примеры, но их достаточно, чтобы понять, как компьютер обрабатывает несовпадающие строки. Многие реальные приложения, такие как проверка орфографии, биоинформатика для сопоставления, последовательность ДНК и т. д., основаны на нечеткой логике.
Как рассчитать расстояние Левенштейна в Python?
Прочитав этот урок, вы точно узнаете, как рассчитать расстояние редактирования в Python. [Бонус] Python Puzzle.
Автор оригинала: Chris.
После изучения этой статьи вы будете точно знать Как рассчитать расстояние редактирования в Python Отказ
Обучение требует первого открытия вашего разрыва знаний. Итак, давайте сделаем это. Какова производительность следующих пазл Python, показывающая вам краткий фрагмент кода для расчета расстояния редактирования в Python? ( Источник )
Исходный код Python
Теперь это жесткая гайка для трещины. Давайте посмотрим, как работает этот код!
Общая идея Левенштейна расстояние
Перед тем, как мы погрузимся в код, давайте сначала понять идею расстояния Левенштейна:
«В теории информации, лингвистике и информатике, расстояние левенштейна – это строковая метрика для измерения разницы между двумя последовательностями. Неофициально, расстояние Левенштейна между двумя словами является минимальное количество односимвольных редактиций (вставка, делеции или замены), необходимые для изменения одного слова в другое. — Википедия
Вот два самых важных пункта из определения:
Применение расстояния Левенштейна
Левенштейин Расстояние имеет важные приложения на практике. Подумайте о Функциональность автоматической коррекции на вашем смартфоне Отказ
Скажем, вы напечатаете “HELO” В вашем WhatsApp Messenger. Ваш смартфон распознает, что это не слово в его словаре. Затем он выбирает несколько высоких слов вероятности и может отсортировать их от расстояния Левенштейна. Один с минимальным расстоянием левенштейна (и, следовательно, максимальное сходство) является “Привет” Потому что вам просто нужно вставить один символ «L» идти от неверных «HELO» К правильному слову «Привет» что существует в словаре.
Объяснение исходного кода
Вот одна минимальная последовательность:
Итак, мы можем преобразовать строку «Кошка» В строке «Челло» с пятью редакциями. Нет быстрее пути вперед и попробуйте!
Но как алгоритм делает это?
Intermezzo: ценность прав истина Python
В Python каждый объект имеет значение правды. В Гарри Поттере вы либо хорошие или плохие. В Python вы либо правда или ложь.
Большинство объектов на самом деле «правда» (нормальные люди обычно хороши). Интуитивно, вы знаете несколько объектов, которые являются «ложными», не так ли? Например:
Понимание алгоритма Левенштейна
С этой информацией вы можете легко понять первые две линии функции левенштейна:
Покажем, обе строки не пустые (в противном случае решение тривиально, как показано ранее).
Теперь мы можем упростить проблему тремя способами.
Во-первых, мы игнорируем ведущие персонажи обоих строк А и B и рассчитать расстояние редактирования от А [1.:] к B [1:] в оформлении рекурсивный манера. Обратите внимание, что мы используем Slicing, чтобы получить подстроки, начиная со второго символа с индексом 1.
Связанная статья + Видеоурок: Введение в нарезку
В коде это выглядит следующим образом:
Во-вторых, мы удаляем первый персонаж A [0] Отказ Теперь мы проверяем минимальное расстояние редактирования рекурсивно для этой меньшей проблемы. Как мы убрали персонаж, мы увеличиваем результат на один.
В коде это выглядит следующим образом:
В-третьих, мы (концептуально) вставьте символ B [0] до начала слова А Отказ Теперь мы можем уменьшить эту проблему на меньшую проблему, которая возникает, если убрать первый символ B Отказ Как мы выполнили одну операцию редактирования (вставку), мы увеличиваем результат на одну.
Наконец, мы просто принимаем минимальное расстояние редактирования всех трех результатов (замените первый символ, удалите первый символ, вставьте первый символ).
Последние замечания
Спасибо за чтение этого учебника на блог Finxter! 🙂
У вас были трудности понять рекурсию и основы Python (их так много)? Почему бы не разрешить их, раз и для всех, и присоединиться к топ-10% Pythonistas?
Если вы хотите повысить свою карьеру и одновременно улучшить свои навыки Python, почему бы не начать зарабатывать деньги, когда вы узнаете как питонский фрилансеры?
Работая в качестве исследователя в распределенных системах, доктор Кристиан Майер нашел свою любовь к учению студентов компьютерных наук.
Чтобы помочь студентам достичь более высоких уровней успеха Python, он основал сайт программирования образования Finxter.com Отказ Он автор популярной книги программирования Python одноклассники (Nostarch 2020), Coauthor of Кофе-брейк Python Серия самооставленных книг, энтузиаста компьютерных наук, Фрилансера и владелец одного из лучших 10 крупнейших Питон блоги по всему миру.
Его страсти пишут, чтение и кодирование. Но его величайшая страсть состоит в том, чтобы служить стремлению кодер через Finxter и помогать им повысить свои навыки. Вы можете присоединиться к его бесплатной академии электронной почты здесь.
Расстояние Левенштейна и сходство текста в Python
Вступление
Написание текста-это творческий процесс, основанный на мыслях и идеях, которые приходят нам в голову. То, как написан текст, отражает нашу индивидуальность, а также очень сильно зависит от настроения, в котором мы находимся, от того, как мы организуем наши мысли, от самой темы и от людей, к которым мы обращаемся – наших читателей.
В прошлом случалось, что два или более авторов имели одну и ту же идею, записывали ее отдельно, публиковали под своим именем и создавали нечто очень похожее. До появления электронных изданий их идеи долго циркулировали и поэтому приводили к конфликтам о том, кто настоящий изобретатель и кто должен быть удостоен за это чести.
Сегодня каждая статья сразу же доступна в Интернете в цифровом формате. Онлайн – статьи правильно индексируются и привязываются к другим документам, что позволяет легко и быстро их находить. С одной стороны, такой способ работы упрощает обмен идеями, а также исследование темы, но с другой стороны, доступность открывает двери для простого копирования и вставки других работ без разрешения или признания их, что называется плагиатом.
В этот момент в игру вступают методы, которые имеют дело со сходством различных текстов. Основная идея этого заключается в том, чтобы иметь возможность ответить на вопросы, если два текста (или наборы данных в целом) полностью или хотя бы частично похожи, если они связаны друг с другом с точки зрения одной и той же темы и сколько правок необходимо сделать, чтобы преобразовать один текст в другой.
Например, эта технология используется информационно-поисковыми системами, поисковыми системами, системами автоматической индексации, текстовыми сумматорами, системами категоризации, системами проверки на плагиат, системами распознавания речи, рейтинговыми системами, анализом ДНК и алгоритмами профилирования (программы IR/AI для автоматической связи данных между людьми и тем, что они делают).
Методы поиска и сравнения
Кроме того, сходство может быть измерено тем, как звучат слова-они звучат одинаково, но написаны по-другому? Переводы с одного алфавита на другой часто дают более одного результата в зависимости от языка, поэтому для поиска родственников по разным написаниям их фамилии и имени был создан алгоритм Soundex, который до сих пор является одним из самых популярных и распространенных на сегодняшний день.
И последнее, но не менее важное: сколько изменений (правок) необходимо, чтобы перейти от одного слова к другому? Чем меньше правок нужно сделать, тем выше уровень сходства. Эта категория сравнения содержит расстояние Левенштейна, на котором мы остановимся более подробно ниже.
В таблице 1 представлен выбор способов поиска и сравнения текстовых данных. Правый столбец таблицы содержит выбор соответствующих модулей Python для выполнения этих задач.
| Точный поиск | string, re, Advas | Поиск строк Бойера-Мура, поиск строк Рабина-Карпа, Поиск строк Кнута-Морриса-Пратта (KMP), Регулярные выражения |
| In-точный поиск | Размытый | поиск биграмм, поиск триграмм, нечеткая логика |
| Фонетические алгоритмы | Адвас, Пушистый, медуза, фонетика, км / ч | Soundex, Metaphone, Double Metaphone, Caverphone, NYIIS, Кельн Фонетика, матч Рейтинг кодекс |
| Изменения или правки | расстояние редактирования, питон-Левенштейн, медуза | Расстояние Левенштейна, расстояние Хэмминга, расстояние Яро, расстояние Яро-Винклера |
Расстояние Левенштейна
Чем больше расстояние Левенштейна, тем больше разница между струнами. Например, от “test” до “test” расстояние Левенштейна равно 0, поскольку исходная и целевая строки идентичны. Никаких преобразований не требуется. Напротив, от “теста” до “команды” расстояние Левенштейна равно 2 – нужно сделать две замены, чтобы превратить “тест” в “команду”.
Вот отличное видео, объясняющее, как работает алгоритм:
Реализация расстояния Левенштейна в Python
Он начинается с пустой матрицы, размер которой равен длине строк. И первая строка, и столбец, начиная с нуля, индексируются все чаще:
Обратите внимание, что есть три возможных типа изменений, если два символа разные – вставка, удаление и замена. Наконец, матрица выглядит следующим образом:
Расстояние редактирования – это значение в позиции [4, 4] – в правом нижнем углу, которое на самом деле равно 1. Обратите внимание, что эта реализация находится в O(N*M) времени, для N и M длин двух строк. Другие реализации могут выполняться за меньшее время, но более амбициозны для понимания.
Вот соответствующий код для алгоритма расстояния Левенштейна, который я только что описал:


