Атрибуты и протокол дескриптора в Python
Рассмотрим такой код:
Сегодня мы разберём ответ на вопрос: «Что именно происходит, когда мы пишем foo.bar?»
Вы, возможно, уже знаете, что у большинства объектов есть внутренний словарь __dict__, содержащий все их аттрибуты. И что особенно радует, как легко можно изучать такие низкоуровневые детали в Питоне:
Давайте начнём с попытки сформулировать такую (неполную) гипотезу:
Пока звучит похоже на правду:

Теперь предположим, что вы уже в курсе, что в классах можно объявлять динамические аттрибуты:
Хм… ну ладно. Видно что __getattr__ может эмулировать доступ к «ненастоящим» атрибутам, но не будет работать, если уже есть объявленная переменная (такая, как foo.bar, возвращающая ‘hello!’, а не ‘goodbye!’). Похоже, всё немного сложнее, чем казалось вначале.
И действительно: существует магический метод, который вызывается всякий раз, когда мы пытаемся получить атрибут, но, как продемонстрировал пример выше, это не __getattr__. Вызываемый метод называется __getattribute__, и мы попробуем понять, как в точности он работает, наблюдая различные ситуации.
Пока что модифицируем нашу гипотезу так:
foo.bar эквивалентно foo.__getattribute__(‘bar’), что примерно работает так:
Проверим практикой, реализовав этот метод (под другим именем) и вызывая его напрямую:
Выглядит корректно, верно?
Отлично, осталось лишь проверить, что поддерживается присвоение переменных, после чего можно расходиться по дом… —
my_getattribute возвращает некий объект. Мы можем изменить его, если он мутабелен, но мы не можем заменить его на другой с помощью оператора присвоения. Что же делать? Ведь если foo.baz это эквивалент вызова функции, как мы можем присвоить новое значение атрибуту в принципе?
Когда мы смотрим на выражение типа foo.bar = 1, происходит что-то больше, чем просто вызов функции для получения значения foo.bar. Похоже, что присвоение значения атрибуту фундаментально отличается от получения значения атрибута. И правда: мы может реализовать __setattr__, чтобы убедиться в этом:
Пара вещей на заметку относительно этого кода:

А ведь у нас есть ещё и property (и его друзья). Декоратор, который позволяет методам выступать в роли атрибутов.
Давайте постараемся понять, как это происходит.
Просто ради интереса, а что у нас в f.__dict__?
В __dict__ нет ключа bar, но __getattr__ почему-то не вызывается. WAT?
bar — метод, да ещё и принимающий в качестве параметра self, вот только это метод находится в классе, а не в экземпляре класса. И в этом легко убедиться:
Ключ bar действительно находится в словаре атрибутов класса. Чтобы понять работу __getattribute__, нам нужно ответить на вопрос: чей __getattribute__ вызывается раньше — класса или экземпляра?
Видно, что первым делом проверка идёт в __dict__ класса, т.е. у него приоритет перед экземпляром.
Погодите-ка, а когда мы вызывали метод bar? Я имею в виду, что наш псевдокод для __getattribute__ никогда не вызывает объект. Что же происходит?
Вся суть тут. Реализуйте любой из этих трёх методов, чтобы объект стал дескриптором и мог менять дефолтное поведение, когда с ним работают как с атрибутом.
Если объект объявляет и __get__(), и __set__(), то его называют дескриптором данных («data descriptors»). Дескрипторы реализующие лишь __get__() называются дескрипторами без данных («non-data descriptors»).
Оба вида дескрипторов отличаются тем, как происходит перезапись элементов словаря атрибутов объекта. Если словарь содержит ключ с тем же именем, что и у дескриптора данных, то дескриптор данных имеет приоритет (т.е. вызывается __set__()). Если словарь содержит ключ с тем же именем, что у дескриптора без данных, то приоритет имеет словарь (т.е. перезаписывается элемент словаря).
Чтобы создать дескриптор данных доступный только для чтения, объявите и __get__(), и __set__(), где __set__() кидает AttributeError при вызове. Реализации такого __set__() достаточно для создания дескриптора данных.
Короче говоря, если вы объявили любой из этих методов — __get__, __set__ или __delete__, вы реализовали поддержку протокола дескриптора. А это именно то, чем занимается декоратор property: он объявляет доступный только для чтения дескриптор, который будет вызываться в __getattribute__.
Последнее изменение нашей реализации:
foo.bar эквивалентно foo.__getattribute__(‘bar’), что примерно работает так:
Попробуем продемонстрировать на практике:

Мы лишь немного поскребли поверхность реализации атрибутов в Python. Хотя наша последняя попытка эмулировать foo.bar в целом корректна, учтите, что всегда могут найтись небольшие детали, реализованные по-другому.
Надеюсь, что помимо знаний о том, как работают атрибуты, мне так же удалось передать красоту языка, который поощряет вас к экспериментам. Погасите часть долга знаний сегодня.
Интерпретатор Python: о чём думает змея? (часть I-III)
Данная серия статей рассчитана на тех, кто умеет писать на python в целом, но плохо представляет как этот язык устроен изнутри. Собственно, как и я три месяца назад.
Небольшой дисклеймер: свой рассказ я буду вести на примере интерпретатора python 2.7. Всё, о чем пойдёт речь далее, можно повторить и на python 3.x с поправкой на некоторые различия в синтаксисе и именование некоторых функций.
Часть I. Слушай Питон, а что у тебя внутри?
Начнём с немного (на самом деле, с сильно) высокоуровневого взгляда на то, что же из себя представляет наша любимая змея. Что происходит, когда вы набираете строку подобную этой в интерактивном интерпретаторе?
Ваш палец падает на enter и питон инициирует 4 следующих процесса: лексический анализ, парсинг, компиляцию и непосредственно интерпретацию. Лексический анализ – это процесс разбора набранной вами строки кода в определенную последовательность символов, называемых токенами. Далее парсер на основе этих токенов генерирует структуру, которая отображает взаимоотношения между входящими в неё элементами (в данном случае, структура это абстрактное синтаксическое древо или АСД). Далее, используя АСД, компилятор создаёт один или несколько объектных модулей и передаёт их в интерпретатор для непосредственного выполнения.
Я не буду углубляться в темы лексического анализа, парсинга и компиляции, в основном потому, что сам не имею о них ни малейшего представления. Вместо этого, давайте лучше представим, что умные люди сделали всё как надо и данные этапы в питоновском интерпретаторе отрабатывают без ошибок. Представили? Двигаем дальше.
Прежде чем перейти к объектным модулям (или объектам кода, или объектным файлам), следует кое-что прояснить. В данной серии статей мы будем говорить об объектах функций, объектных модулях и байткоде – всё это совершенно разные, хоть и некоторым образом связанные между собой понятия. Хотя нам и необязательно знать, что такое объекты функций для понимания интерпретатора, но я всё же хотел бы остановить на них ваше внимание. Не говоря уже о том, что они попросту крутые.
Объекты функций или функции, как объекты
Если это не первая ваша статья о программировании на питоне, вы должны быть наслышаны о неких «объектах функций». Это именно о них люди с умным видом рассуждают в контексте разговоров о «функциях, как объектах первого класса» и «наличии функций первого класса в питоне». Рассмотрим следующий пример:
Выражение «функции – это объекты первого класса» означает, что функции – это объекты первого класса, в том смысле, в коем и списки – это объекты, и экземпляр класса MyObject – объект. И так как foo это объект, он имеет значимость сам по себе, безотносительно вызова его, как функции (то есть, foo и foo() — это разные вещи). Мы можем передать foo в другую функцию в качестве аргумента, можем переназначить её на новое имя ( other_function = foo ). С функциями первого класса можно делать, что угодно и они всё стерпят.
Часть II. Объектные модули
На данном этапе we need to go deeper, чтобы узнать, что объект функции в свою очередь содержит объект кода:
Как видно из приведённого листинга, объектный модуль является атрибутом объекта функции (у которого есть и множество других атрибутов, но в данном случае особого интереса они не представляют в силу простоты foo ).
Объектный модуль генерируется питоновским компилятором и далее передаётся интерпретатору. Модуль содержит всю необходимую для выполнения информацию. Давайте посмотрим на его атрибуты:
Их, как видите, немало, поэтому все рассматривать не будем, для примера остановимся на трёх наиболее понятных:
Атрибуты выглядят довольно интуитивно:
co_varnames – имена переменных
co_consts – значения, о которых знает функция
co_argcount – количество аргументов, которые функция принимает
Всё это весьма познавательно, но выглядит несколько черезчур высокоуровнево для нашей темы, не правда ли? Где же инструкции интерпретатору для непосредственного выполнения нашего модуля? А такие инструкции есть и представлены они байткодом. Последний также является атрибутом объектного модуля:
Что за неведомая байтовая фигня, спросите вы?
Часть III. Байткод
Вы наверное и сами понимаете, но я, на всякий случай, озвучу – «байткод» и «объект кода» это разные вещи: первый является атрибутом второго, среди многих других (см. часть 2). Атрибут называется co_code и содержит все необходимые инструкции для выполнения интерпретатором.
Что же из себя представляет этот байткод? Как следует из названия, это просто последовательность байтов. При выводе в консоль выглядит она достаточно бредово, поэтому давайте приведём её к числовой последовательности, пропустив через ord :
Таким образом мы получили числовое представление питоновского байткода. Интерпретатор пройдётся по каждому байту в последовательности и выполнит связанные с ним инструкции. Обратите внимание, что байткод сам по себе не содержит питоновских объектов, ссылок на объекты и т.п.
Байткод можно попытаться понять открыв файл интерпретатора CPython (ceval.c), но мы этого делать не будем. Точнее будем, но позже. Сейчас же пойдём простым путём и воспользуемся модулем dis из стандартной библиотеки.
Дизассемблируй это
Итак, давайте применим dis и снимем паранжу с нашего объектного модуля. Для этого воспользуемся функцией dis.dis :
Числа в первой колонке – это номера строк анализируемых исходников. Вторая колонка отражает смещение команд в байткоде: LOAD_CONST находится в позиции «0», STORE_FAST в позиции «3» и т.д. Третья колонка даёт байтовым инструкциям человекопонятные названия. Названия эти нужны только жалким людишкам нам, в интерпретаторе они не используются.
Это также объясняет, почему инструкция STORE_FAST находится на третьей позиции в байткоде: если где-то в байткоде есть аргумент, следующие два байта будут представлять этот аргумент. Корректная обработка таких ситуаций также ложится на плечи интерпретатора.
Как dis переводит байты (например, 100) в осмысленные имена (например, LOAD_CONST ) и наоборот? Подумайте, как бы вы сами организовали подобную систему? Если у вас появились мысли, вроде «ну, может там есть какой-то список с последовательным определением байтов» или «по-любому словарь с названиями инструкций в качестве ключей и байтами как значениями», поздравляю – вы абсолютно правы. Именно так всё и устроено. Сами определения происходят в файле opcode.py (можно также посмотреть заголовочный файл opcode.h), где вы сможете увидеть
полторы сотни подобных строк:
(Какой-то любитель комментариев заботливо оставил нам пояснения к инструкциям.)
Теперь мы имеем некоторое представление о том, чем является (и чем не является) байткод и как использовать dis для его анализа. В следующих частях мы рассмотрим, как питон может компилироваться в байткод, оставаясь при этом динамическим ЯП.
Метаклассы в Python: что это такое и с чем его едят
Метаклассы – это классы, экземпляры которых являются классами. Давайте поговорим о специфике языка Python и его функционале.
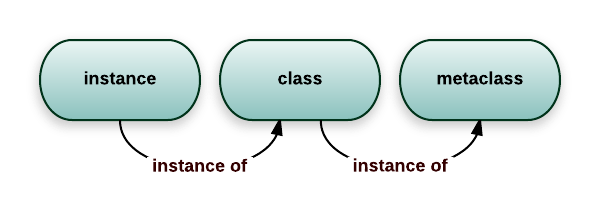
Чтобы создать свой собственный метакласс в Python, нужно воспользоваться подклассом type, стандартным метаклассом в Python. Чаще всего метаклассы используются в роли виртуального конструктора. Чтобы создать экземпляр класса, нужно сначала вызвать этот самый класс. Точно так же делает и Python: для создания нового класса вызывает метакласс. Метаклассы определяются с помощью базовых классов в атрибуте __metaclass__. При создании класса допускается использование методов __init__ и __new__. С их помощью можно пользоваться дополнительными функциями. Во время выполнения оператора class генерируется пространство имен, которое будет содержать атрибуты будущего класса. Затем, для непосредственного создания, вызывается метакласс с именем и атрибутами.
Классы как объекты
Перед тем как начинать разбираться в метаклассах, нужно хорошо понимать как работают обычные классы в Python, а они очень своеобразны. В большинстве языков это попросту фрагменты кода, которые описывают создание объекта. Данное суждение истинно и для Python:
Но есть один нюанс. Классы в Python это объекты. Когда выполняется оператор class, Python создает в памяти объект с именем ObjectCreator.
Объект способен сам создавать экземпляры, так что это класс. А объект вот почему:
Динамическое создание классов
Если классы в Python – это объекты, значит, как и любой другой объект, их можно создавать на ходу. Пример создания класса в функции с помощью class:
Но это не слишком-то динамично, так как все равно придется прописывать весь класс самостоятельно.
Исходя из того, что классы являются объектами, можно сделать вывод, что они должны чем-то генерироваться. Во время выполнения оператора class, Python автоматически создает этот объект, но есть возможность сделать это вручную.
Помните функцию type? Старая добрая функция, позволяющая определить тип объекта:
Эта функция может создавать классы на ходу. В качестве параметра type принимает описание класса, и возвращает класс.
Функция type работает следующим образом:
Можно создать вручную:
Вероятно, вы обратили внимание на то, что MyShinyClass выступает и в качестве имени класса, и в качестве переменной для хранения ссылок на класс.
type принимает словарь для определения атрибутов класса.
Можно написать как:
Используется как обычный класс:
Конечно же, его можно наследовать:
Затем в свой класс нужно будет добавить методы. Для этого просто определите функцию с соответствующей сигнатурой и назначьте ее в качестве атрибута.
После динамического создания можно добавить еще методов:
В чем же суть? Классы в Python являются объектами, поэтому можно динамически создавать класс на ходу. Именно это и делает Python во время выполнения оператора class.
Что же такое метакласс?
Если говорить в двух словах, то метакласс – это «штуковина», создающая классы. Чтобы создавать объекты, мы определяем классы, правильно? Но мы узнали, что классы в Python являются объектами. На самом деле метаклассы – это то, что создает данные объекты. Довольно сложно объяснить. Лучше приведем пример:
Ранее уже упоминалось, что type позволяет делать что-то вроде этого:
Скорее всего, вы задаетесь вопросом: почему имя функции пишется с маленькой буквы?
Скорее всего, это вопрос соответствия со str – классом, который отвечает за создание строк, и int – классом, создающим целочисленные объекты. type – это просто класс, создающий объекты класса. Проверить можно с помощью атрибута __class__. Все, что вы видите в Python – объекты. В том числе и строки, числа, классы и функции. Все это объекты, и все они были созданы из класса:
Интересный вопрос: какой __class__ у каждого __class__?
Можно сделать вывод, что метакласс создает объекты класса. Это можно назвать «фабрикой классов». type – встроенный метакласс, который использует Python. Также можно создать свой собственный метакласс.
Атрибут __metaclass__
При написании класса можно добавить атрибут __metaclass__:
Если это сделать, то для создания класса Foo Python будет использовать метакласс.
Если написать class Foo(object), объект класса Foo не сразу создастся в памяти.
Python будет искать __metaclass__. Как только атрибут будет найден, он используется для создания класса Foo. В том случае, если этого не произойдет, Python будет использовать type для создания класса.
Python делает следующее:
Проверит, есть ли атрибут __metaclass__ у класса Foo? Если он есть, создаст в памяти объект класса с именем Foo с использованием того, что находится в __metaclass__.
Если Python вдруг не сможет найти __metaclass__, он будет искать этот атрибут на уровне модуля и после этого повторит процедуру. В случае если он вообще не может найти какой-либо __metaclass__, Python использует собственный метакласс type, чтобы создать объект класса.
Теперь вопрос: что можно добавить в __metaclass__?
Ответ: что угодно, что может создавать классы.
А что может создать класс? type или его подклассы, а также всё, что его использует.
Пользовательские метаклассы
Основной целью метакласса является автоматическое изменение класса во время его создания. Обычно это делается для API, когда нужно создать классы, соответствующие текущему контексту. Например, вы решили, что все классы в модуле должны иметь свои атрибуты, и они должны быть записаны в верхнем регистре. Чтобы решить эту задачу, можно задать __metaclass__ на уровне модуля.
Таким образом, нужно просто сообщить метаклассу, что все атрибуты должны быть в верхнем регистре. __metaclass__ действительно может быть любым вызываемым объектом, он не обязательно должен быть формальным классом. Итак, начнем с простого примера, с использованием функции.
Теперь то же самое, но с использованием метакласса:
Но это не совсем ООП, так как type не переопределяется, а вызывается напрямую. Давайте реализуем это:
Скорее всего, вы заметили дополнительный аргумент upperattr_metaclass. В нём нет ничего особенного: этот метод первым аргументом получает текущий экземпляр. Точно так же, как и self для обычных методов. Имена аргументов такие длинные для наглядности, но для self все имена имеют названия обычной длины. Поэтому реальный метакласс будет выглядеть так:
Используя метод super, можно сделать код более “чистым”:
Вот и все. О метаклассах больше рассказать нечего.
Причина сложности кода, использующего метаклассы, заключается не в самих метаклассах. Код сложный потому, что обычно метаклассы используются для сложных задач, основанных на наследовании, интроспекции и манипуляции такими переменными, как __dict__. Также с помощью метаклассов можно:
Зачем использовать классы метаклассов вместо функций?
Есть несколько причин для этого:
Зачем использовать метаклассы?
«Метаклассы – это магия, о которой 99% пользователей не стоит даже задумываться. Если вам интересно, нужны ли они вам – тогда точно нет. Люди, которым они на самом деле нужны, знают, зачем, и что с ними делать.»
Гуру Python Tim Peters
В основном метаклассы используются для создания API. Типичным примером является Django ORM. Можно написать что-то вроде этого:
Но если написать так:
Он не вернет объект IntegerField. Он вернет код int и даже может взять его непосредственно из базы данных.
Последнее слово
Во-первых, классы – это объекты, создающие экземпляры. Классы сами являются экземплярами метаклассов.
В Python все является объектами. Все они являются либо экземплярами классов, либо экземплярами метаклассов. За исключением type. type – сам себе метакласс. Его невозможно создать в чистом Python, это можно сделать только при помощи небольшого читерства.
Во-вторых, метаклассы сложны. Если вам не нужны сложные изменения класса, метаклассы использовать не стоит. Просто изменить класс можно двумя способами:
В 99% случаев лучше использовать эти методы, а в 98% изменения класса вообще не нужны.
Почему во многих примерах функции называют foo?
2 ответа 2
What’s Foo? My uncle found this word engraved on the bottom of a jade statue in San Francisco’s China town. The word Foo means Good-Luck.
Что такое Foo? Мой дядя нашел это слово выгравированным на дне нефритовой статуэтки в «China town» в Сан Франциско. И обозначает (переводится) оно «удача» или «удачи!».
Также в популяризации данных слов сыграла роль военная аббревиатура FUBAR («Fucked Up Beyond All Repair», что можно перевести как «ремонту не подлежит», что относилось к военной технике, либо «Fucked Up Beyond All Recognition» — речь шла о людских жертвах, которые невозможно опознать), которая появилась во время второй мировой войны и по слухам была придумана неким рядовым, которого «задолбали» всякие военные аббревиатуры.
Технари из TRMC клуба в MIT использовали слово «FOO» для обозначения ситуаций когда была необходима аварийная остановка системы. В случае, когда кто-нибудь нажимал один из аварийных выключателей на системном табло вместо времени появлялась надпись «FOO» и поэтому эти выключатели назвали «Foo switches». Позже в этом клубе стали использовать кнопки с подписями «FOO» и «BAR» (уже как дань традиции), и использовались они в самых разных ситуациях.
Впоследствии это стало использоваться в IT мире как «placeholders», то есть для названия переменных/классов в тех случаях, когда это не важно (например в примерах) или когда на ум ничего лучшего не приходит.
Будущее аннотаций типов в Python
Предыстория
PEP 3107
Одним из нововведений Python 3.0 было введение нового синтаксиса, позволяющего сохранять произвольные метаданные аргументов и возвращаемого значения функций в виде аннотаций. Нововведение было описано в PEP 3107.
Согласно ему аннотации функций:
совершенно необязательны к использованию;
способ связать произвольные выражения Python с различными частями функции во время ее определения интерпретатором.
Для Python аннотации не представляют никакого интереса и никак им не используются. Он просто делает аннотации доступными для сторонних инструментов.
Эти инструменты могут использовать их как им будет угодно. К примеру, для добавления к аргументам функции дополнительного описания:
Или для обеспечения проверки типов аргументов и возвращаемого значения функций:
В PEP 3107 подчеркивалось, что сами по себе, описанные выше примеры, бессмысленны. Они приобретают смысл лишь для сторонних инструментов, таких как статические анализаторы и т.д.
Доступ к аннотациям можно получить с помощью специального словаря __annotations__ :
В PEP 3107 сознательно не была определена семантика аннотаций функций и способ их использования.
Однако с течением времени стало ясно, что большинство сторонних инструментов используют аннотации функций в качестве подсказок типов аргументов и возвращаемого значения функций. И команда разработчиков Python решила стандартизировать определение и использование аннотаций в качестве подсказок типов.
Так в Python 3.5 был представлен PEP 484, который включал в себя описание синтаксиса и способов использования подсказок типов. А также описание ситуаций, в которых подсказки типов не должны быть использованы или необходимо использовать специальный синтаксис их определения.
Опережающие ссылки
Подсказка типа указывающая на объект, который еще не был определен, называется опережающей ссылкой (forward reference).
Получается, что при использовании подсказок типа, для вспомогательных целей, не относящихся к основной работе кода, в него был добавлен баг. В PEP 484 опережающие ссылки предлагалось определять как обычные литералы строк:
Позже, при статическом анализе кода, инструменты должны были воспользоваться eval для преобразования литералов строки в объект Python.
В связи с этим, на подсказки типов определенные таким образом, накладывались следующие требования:
строковый литерал должен содержать синтаксически правильное выражение Python;
он должен оцениваться интерпретатором без ошибок, как только модуль будет полностью загружен;
локальное и глобальное пространство имен, в которых происходит их оценка, должны совпадать.
Такое решение имело ряд недостатков: приходилось запоминать случаи, когда следовало использовать литералы строк, вместо ссылки на класс, да и сам синтаксис определения выглядел странно.
PEP 563 решал следующие проблемы:
проблему опережающих ссылок (странный синтаксис их определения);
подсказки типов обрабатывались в момент определения функций, методов и модулей, что могло быть вычислительно затратно и увеличивало время запуска программы.
Теперь разработчик мог определить подсказки типов следующим образом:
Достигалось это за счет изменения способа оценки подсказок типов, после введения данного PEP все подсказки типов представлялись как литералы строк. То есть, для интерпретатора приведенный выше код выглядел бы так:
Статические анализаторы кода, не должны были испытывать особых проблем при анализе таких подсказок типа, так как уже умели их оценивать.
Такой способ оценки аннотаций накладывал на них следующие требования:
строковый литерал должен содержать синтаксически правильное выражение Python;
для оценки должны быть использованы аннотации только с именами, представленными в пространстве имен модуля, поскольку отложенная оценка локальных пространств имен не надежна.
Скрытая угроза
Однако с течением времени стало ясно, что предложенный способ оценки аннотаций хорошо подходит для статического анализа кода, но совсем не годится для использования аннотаций в период выполнения программы. Оказалось, что typing.get_type_hints имеет ограничения, которые делают его использование дорогостоящим во время выполнения программы и, что более важно, недостаточным для оценки всех типов.
В преддверии «заморозки» Python 3.10 автор Pydantic создал issue на Github, где заявил, что Pydantic возможно никогда не сможет адаптировать новый способ оценки аннотаций для использования их в период выполнения программы. Также была другая проблема, так как отложенная оценка аннотаций станет способом по умолчанию, без возможности перехода на старый способ, это сломает большую часть Pydantic и нарушит работу FastAPI.
Он призвал сообщество разработчиков, использующих его библиотеку, обратиться к Управляющему совету Python с просьбой отложить введение отложенной оценки и разработать новый способ оценки аннотаций. Благо такой способ уже был предложен в PEP 649.
В течение нескольких дней после публикации issue, Управляющий совет Python связался с авторами библиотек Pydantic и FastAPI для обсуждения сложившейся ситуации. Как оказалось основные разработчики даже не слышали про эти библиотеки и были удивлены, что кто-то использует аннотации в период выполнения программы.
После долгих обсуждений Управляющий совет Python объявил, что откладывает введение отложенной оценки аннотаций с использованием строк до Python 3.11. Тем самым давая возможность разработчикам решить проблемы обратной совместимости. Однако они также отложили рассмотрение PEP 649 в качестве замены для отложенной оценки с использованием строк до Python 3.11.
В Python 3.9 доступно два способа оценки аннотаций типов:
изначальный способ, оценивающий аннотации во время определения функции (PEP 484);
отложенная оценка аннотаций (PEP 563).
При использовании изначального способа, существовала проблема связанная с циклическими ссылками. Отложенная оценка аннотаций решала эту проблему, но добавляла новые, например, невозможность оценки аннотаций находящихся в локальных пространствах имен.
PEP 649 предлагает третий способ оценки аннотаций, объединяющий в себе лучшие стороны имеющихся способов. Он решает проблему циклических ссылок, оставляя семантику оценки аннотаций такой же как и в изначальном способе, то есть позволяя проводить оценку аннотаций локальных и классовых пространств имен.
Если предложенный способ будет принят, то он полностью заменит семантику PEP 563.
Рассмотрим следующий пример:
Аннотации доступны в период выполнения программы через атрибут __annotations__ функции, класса или модуля. Когда аннотации определены для одного из этих объектов, __annotations__ это отображение имен аргументов на значение определенные в аннотациях к этим аргументам.
В Python 3.9 по умолчанию оценка аннотаций происходит в момент определения функции, класса или модуля, результаты оценки записываются в словарь. В период выполнения программы, описанное выше, примерно выглядит так:
Этот код не выполнятся, так как содержит опережающие ссылки. Код, использующий отложенную оценку аннотаций, предложенную в PEP 563, приведен ниже:
Проблемы, связанные с такой оценкой, описаны выше. Пример оценки аннотаций новым способом приведен ниже:
Итоги
На текущий момент проблема опережающих ссылок остается до конца не решенной. Способ решения, подходящий для статического анализа кода, совершенно не подходит для использования в период выполнения. Сообщество разработчиков использующих Pydantic и FastAPI продолжает расти (FastAPI занимает третье место среди веб-фремворков Python) и разработчикам языка Python придется учитывать их мнение в вопросах развития аннотаций.
Несмотря на некоторую неопределенность, думаю, что в будущем нас ждет еще больше способов использования аннотаций в период выполнения программы. Спасибо за прочтение!


