Git: советы новичкам – часть 3

Глава 16. Откуда взялась ветка?
Набираемся терпения и продолжаем рассматривать разные рабочие ситуации. Если мы сделаем несколько коммитов, а потом выполним команду fetch (скачаем свежие коммиты, но пока не применим их в рабочий каталог), то увидим немного сбивающую с толку картину:
Что это ещё за ветка получилась? Мы ведь не создавали никакой ветки. Может её создал кто-то из сотрудников? Нет, никто её не создавал. Восстановим хронологию событий:
Итого, разные люди независимо друг от друга поменяли результат коммита «2» – вот и возникла ветка. Кстати, эта ветка сейчас есть только в нашем локальном репозитории. В origin её пока нет, поскольку коммиты «3» и «4» мы до сих пор не запушили.
Что дальше? Поскольку мы сделали fetch, а не pull, то скачанные коммиты ещё не применились к нашему рабочему каталогу. Давайте применим их – для этого выполним merge. Результат представлен на картинке:
Произошедшее уже знакомо нам. Образовался автоматический merge-commit «8» – master и head теперь указывают на него. В рабочей копии появились изменения из коммитов «5», «6» и «7», которые объединились с нашими изменениями из коммитов «3» и «4». origin/master по-прежнему указывает на «7», поскольку последние наши операции проходили на локальном компьютере. А origin/master может сдвинуться только после общения нашего репозитория с origin.
Наконец, делаем push, и вот теперь origin/master тоже указывает на «8», ведь:
Не поддавайтесь малодушному желанию пропустить эти объяснения. В них нет ничего сложного, нужна лишь внимательность. Обязательно пройдитесь по шагам до тех пор, пока не поймете, почему все так работает.
Глава 17. Почему push выдаёт ошибку?
Вы обязательно столкнетесь с тем, что Git выдаёт ошибку при команде push. В чём проблема? Почему он не принимает наши коммиты? Push успешно завершится, только если для каждого отправляемого в origin коммита Git сможет найти предшественника. Пример:
Здесь слева изображены коммиты в вашем локальном репозитории, а справа – коммиты в удалённом репозитории (origin).
Хронология этих коммитов следующая:
Теперь наша попытка запушить «3» и «4» в origin завершится ошибкой. Git откажется пристыковать наши коммиты к последнему коммиту «5» в origin, поскольку в local предшественником для коммита «3» является коммит «2» – а вовсе не «5», как в origin! Для Git важно, чтобы предшественник был тот же.
Проблема решается легко. Перед тем, как сделать push, мы сделаем pull (забираем коммит «5» себе). Тут вы можете спросить: «Секунду! А почему это забрать коммит «5» Git может, а послать коммиты «3» и «4» он не может? Вроде же ситуация симметричная в обе стороны». Правильный вопрос! А ответ на него простой. Если бы Git позволил отправить коммиты «3» и «4» в такой ситуации, то пришлось бы делать merge на стороне origin – а кто там будет разрешать конфликты? Некому. Поэтому Git заставляет вас сначала забрать свежие коммиты себе, сделать merge на своем компьютере (если будут конфликты, то разрешить их), а уже готовый результат он позволит вам отправить в origin командой push. При этом, никаких конфликтов в origin уже быть не может.
Давайте посмотрим, как будет выглядеть локальная история, после того, как вы заберете коммит «5» командой pull.
Здесь у «3» и «5» предок «2», как и на предыдущей картинке. А новый коммит «6» – это уже давно известный нам merge-commit.
В таком состоянии локальные коммиты уже можно запушить. Пусть тут и появилось разветвление истории, но обе ветки при мерже объединились. А значит голова у ветки снова одна. То есть, ничего не мешает сделать push. После этого в origin коммиты будут выглядеть такой же точно «петелькой».
Теперь, когда push выдаст вам ошибку, вы уже знаете почему и что с этим делать.
Глава 18. Rebase
В предыдущей главе мы сделали несколько локальных коммитов, а потом командой pull забрали коммиты других сотрудников из удалённого репозитория. У нас в локальном репозитории образовалась как бы «ветка», которая потом обратно объединилась с основной. После push это временное раздвоение ветки попало в origin, откуда его скачают сотрудники и увидят в своей истории. Часто такие «петли» считаются нежелательными. Поскольку вместо красивой линейной истории получается куча петель, которые затрудняют просмотр.
Git предлагает альтернативу. Выше мы делали fetch+merge. Первая команда забирает свежие коммиты, вторая объединяет их с нашими незапушенными коммитами (если они есть) и создаёт merge-commit с результатом объединения.
Так вот, оказывается можно вместо fetch+merge делать fetch+rebase. Что за rebase и чем он отличается от merge? Вспомним ещё раз, как проходил merge в предыдущем примере:
Rebase действует по-другому – он отсоединяет вашу цепочку незапушенных коммитов от своего предка. Напомним, это были коммиты «3» и «4». Они отсоединяются от своего предка «2» и rebase ставит их «сверху» на только что скачанный коммит «5». То есть, «3» и «4» будут прицеплены сверху к «5» (а мерж-коммит «6» вообще не появится). Итог будет таким:
Никакой петли больше нет, история линейная и красивая! Да здравствует rebase! Теперь мы знаем, что при скачивании коммитов из origin лучше объединять их со своими локальными коммитами при помощи rebase, а не merge.
Хорошо, а если речь не о паре-тройке ваших коммитов, а о большой ветке с разработкой новой фичи. Когда настанет время влить эту фичу в главную ветку, как это лучше сделать – через rebase или merge? У обоих способов есть преимущества:
Глава 19. Эпилог
Мы с вами разобрались в множестве команд Git для работы с репозиториями:
Консольный – работает на всех платформах, но у него крайне аскетичный интерфейс. Если вы не привыкли работать в консоли, то скорее всего вам будет в нем некомфортно.
SourceTree — графический клиент с довольно простым интерфейсом. Есть версии для наших основных платформ: Win и Mac. Однако, сотрудники часто жалуются на его медленную работу и глюки.
TortoiseGit — еще один графический клиент. Есть версия для Win, для Mac`а нет. Интерфейс несколько непривычный, но многим нравится. Жалоб на глюки и тормоза существенно меньше, чем в случае с SourceTree.
Интересно, что и SourceTree, и TortoiseGit не работают с репозиторием Git напрямую. Внутри себя они используют консольный Git. Когда вы нажимаете на красивые кнопки, вызываются консольные команды Git с разными хитрыми параметрами, а результат вызова снова показывают в красивом виде. Использование всеми клиентами консольного Git означает, что все они работают со стандартной файловой структурой Git-хранилища на вашем жёстком диске. А значит можно использовать смешанный стиль работы: одни операции выполнять в одном клиенте, а другие – в другом.
Итак, вы узнали основные концепции, используемые системой контроля версий Git. А также, как работают основные команды. Наверняка при чтении статьи вам не хватало описания «какие кнопки нажимать». Однако, в каждом Git-клиенте это выглядит по-разному, поэтому нам пришлось отделить описание логики от описания интерфейса. Настало время выбрать один из клиентов и изучить его интерфейс пользователя.
Git для начинающих. Урок 6.
git push и git pull
Видеоурок
Конспект урока
Краткое содержание урока, основные инструкции для командной строки, полезные ссылки и советы.
Во втором уроке мы создавали репозитории на github и научились клонировать их. После этого мы работали только с локальным репозиторием, на своей машине. Сегодня мы рассмотрим взаимодействие с удаленным репозиторием.
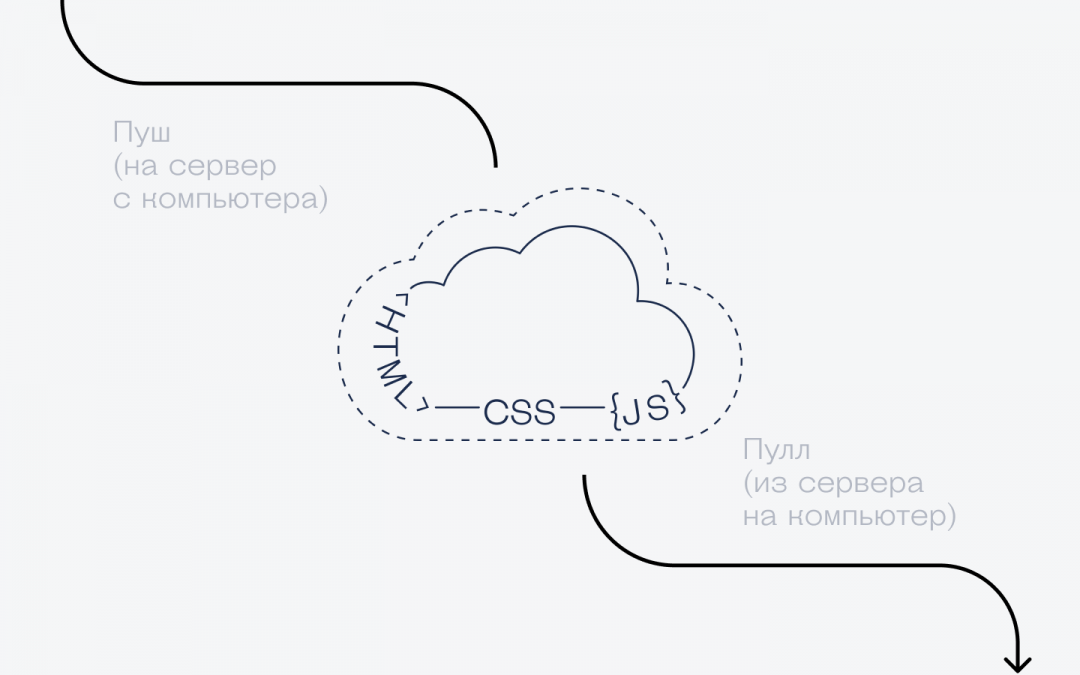
Что такое push (пуш)
Зачем пушить на сервер
Когда пушить на сервер
Когда сделали новый коммит или несколько коммитов
Как узнать, что есть незапушенные коммиты
В командной строке набрать git status
Ключевая фраза здесь «Your branch is ahead of ‘origin/master’ by 5 commits.». Это значит, что у нас есть 5 неотправленных на сервер коммитов. Если незапушенных коммитов нет, то картина будет такая
«is up-to-date» означает, что у нас нет незапушенных коммитов
master и origin/master
git push в терминале
Как пушить в PhpStorm
Что такое pull (пулл)
Это скачивание данных с сервера. Похоже на клонирование репозитория, но с той разницей, что скачиваются не все коммиты, а только новые.
Зачем пулиться с сервера
Чтобы получать изменения от ваших коллег. Или от себя самого, если работаете на разных машинах
git pull в терминале
Как пулить в PhpStorm
Когда что-то пошло не так.
Иногда при работе в команде git push и git pull могут вести себя не так, как пишут в учебниках. Рассмотрим примеры
git push rejected
Вы сделали новый коммит, пытаетесь запушить его, а git в ответ выдает такое
Написано много, но суть в том, что коммит отклонен, пуш не прошел. Почему?
Git устроен так, что локально мы можем коммитить сколько угодно. Но прежде чем отправить свои коммиты на сервер, то есть запушить, нужно подтянуть новые коммиты с сервера. Те самые, которые успели сделать наши коллеги. То есть сделать git pull.
Все, наши коммиты на сервере. При этом появится странный коммит «Merge branch ‘master’ of github.com:Webdevkin/site-git». Это так называемый мердж-коммит, о нем чуть ниже.
Если же при попытке пуша новых коммитов на сервере нет, то git push пройдет сразу и отправит наши коммиты на сервер.
Как избавиться от мердж-коммита
Мердж-коммит появляется, когда вы сделали локальный коммит, а после этого подтянули новые коммиты с сервера. Мердж-коммит не несет смысловой информации, кроме самого факта мерджа. Без него история коммитов выглядит чище.
При этом ваш локальный коммит окажется «поверх» нового коммита с сервера, а мердж-коммита не будет. И не забудьте после этого запушить свой коммит на сервер.
Мердж-коммит в PhpStorm
PhpStorm помогает избавиться от мердж-коммитов через меньшее количество действий. Если мы запушим локальные коммиты и получим rejected из-за того, что на сервере есть новые коммиты, то PhpStorm выдаст предупреждение, где предложит выбрать вариант: как подтянуть новые коммиты, с мерждем или ребейзом. Жмите кнопку «Rebase», мердж-коммита не будет и при этом локальный коммит сразу запушится на сервер.
Что могу посоветовать
Если мы работаем в одиночку, то удаленный репозиторий нужен только для сохранения резевной копии. Скорее всего, мы будем в него только пушить.
Но при работе в команде имеет смысл подумать над такими вещами:
Не переживайте, если иногда будете чувствовать себя, как друзья ниже. Это нормально, новый инструмент не осваивается за 5 минут. Немного практики, и мы будем понимать, почему иногда git ведет себя не так, как хочется, и главное, будем понимать, как это исправить.

В следующем уроке мы узнаем, что такое ветки и будем активно работать с ними. Там мы будем активно использовать git push и git pull, и это поможет закрепить уже пройденный материал.
Гит-словарик для начинающих программистов
Мёржим бранчи и коммитим реквесты
Мы часто упоминаем Git — способ организации хранения и контроля версий файлов в рабочем проекте. Сегодня расскажем о странных словах: «бранч», «коммит», «пулл-реквест» и об остальных понятиях в гите.
О чём речь
Гит — это такой способ хранения файлов и их версий. Гит позволяет смотреть историю изменений файлов, кто какие дополнения и когда вносил, как развивался проект, кто что в него добавлял и почему.
Главная особенность гита — он помнит всё, что вы в него внесли, и может показать, какие именно строчки вы правили несколько лет назад, когда чинили ошибку авторизации, например.
На базе гита есть сервис «Гитхаб». Работает так:
Это полезно, например, когда несколько человек параллельно пилят совместный проект. Каждый работает над своим файлом или даже своим куском одного файла. Всю работу авторы синхронизируют между собой: чтобы не было ситуации, что два человека редактируют один и тот же файл, а потом затирают результаты работы друг друга, сами того не зная.
Это если вкратце. Теперь будут подробности.
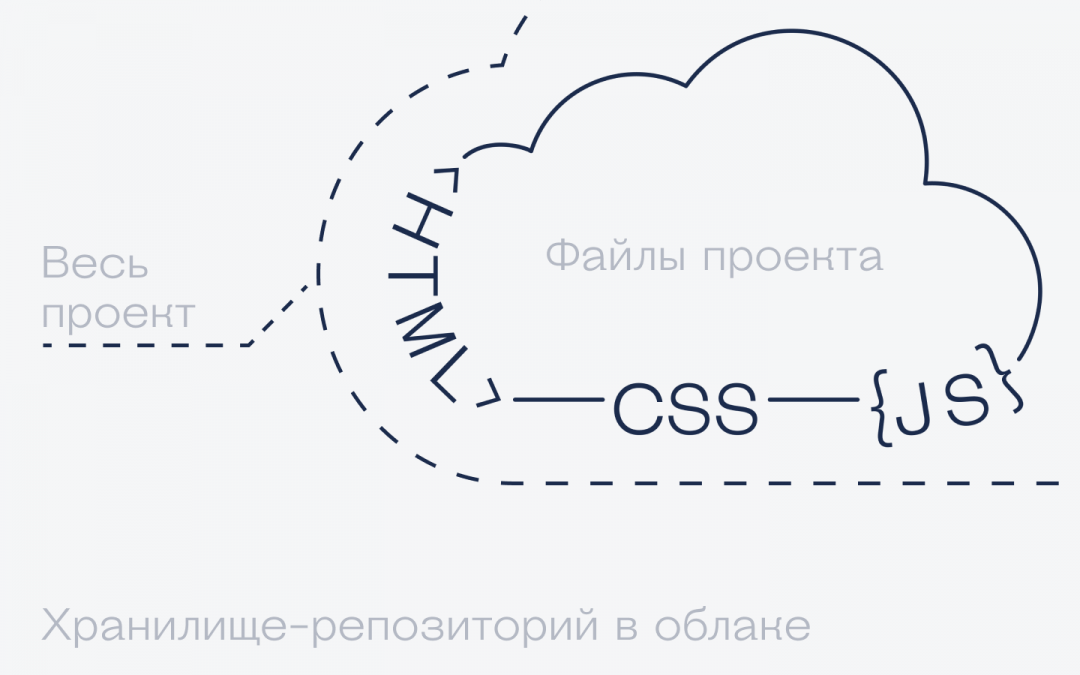
Что такое репозиторий (git repository)
Гит-репозиторий — это облачное хранение вашего проекта на сервере (например, на сервере Гитхаба, но можно и на другом).
У каждого программиста может быть сколько угодно репозиториев, по одному на каждый проект. А можно вести все проекты в одном репозитории, но тогда это превратится в мешанину. Но каждый имеет право на мешанину.
В репозитории могут храниться:
Что такое бранч (git branch)
Бранч — это ветка или копия проекта, в которую можно вносить любые изменения и они не повлияют на основной проект.
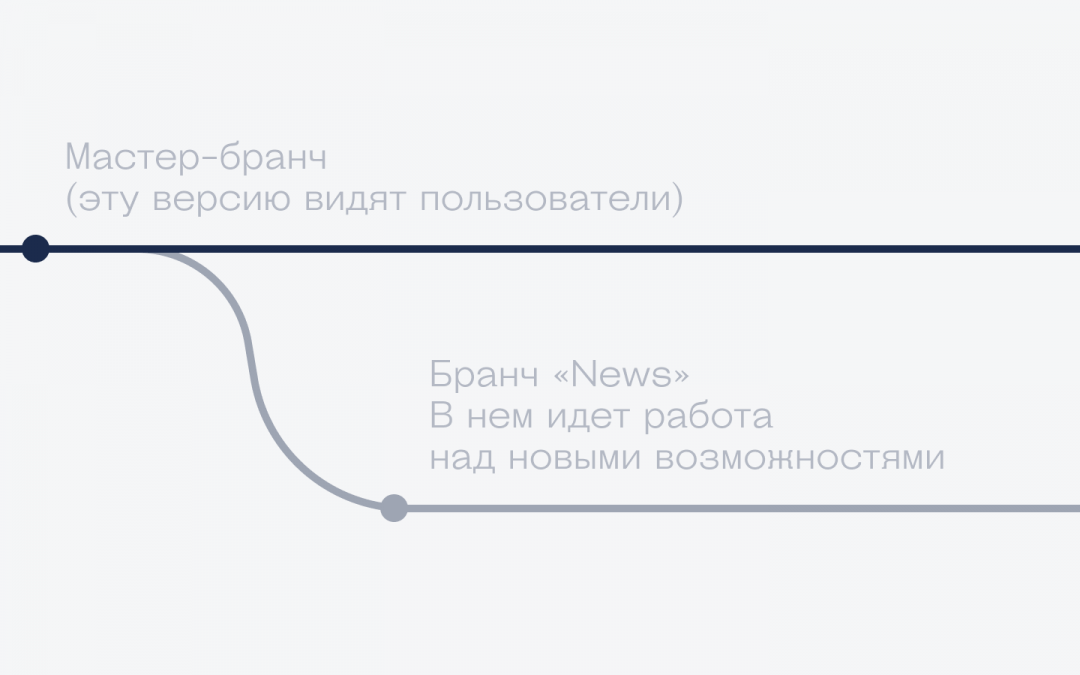
В гит-репозитории всегда есть как минимум один бранч, который называется master. Если не создавать других веток, то все изменения будут сразу идти в главную ветку проекта. Для очень маленьких или учебных проектов это терпимо, но в любом коммерческом коде поступают иначе: создают ветки.
Дело в том, что ветка master используется для выпуска новых версий проекта, которые будут доступны всем. То, что добавляется в мастер-бранч, сразу становится доступно пользователям.
Но представьте такую ситуацию: мы только что запустили сайт для заказчика и он срочно хочет добавить интерактивный раздел со скидками. Можно сделать так: править рабочие файлы проекта «по живому», чтобы сразу видеть результат. А можно сделать из мастера отдельную ветку news и работать уже в ней (и это очень похоже на форк). В этом случае мы получим полную копию проекта, в которую можно вносить любые правки и они никак не повлияют на запущенный сайт. Мы в этой ветке пилим всё, что нужно клиенту, показываем ему результат на секретном сайте, а потом объединяем её с мастером. Это называется «смёржить бранчи».
Что такое клонирование (git clone)
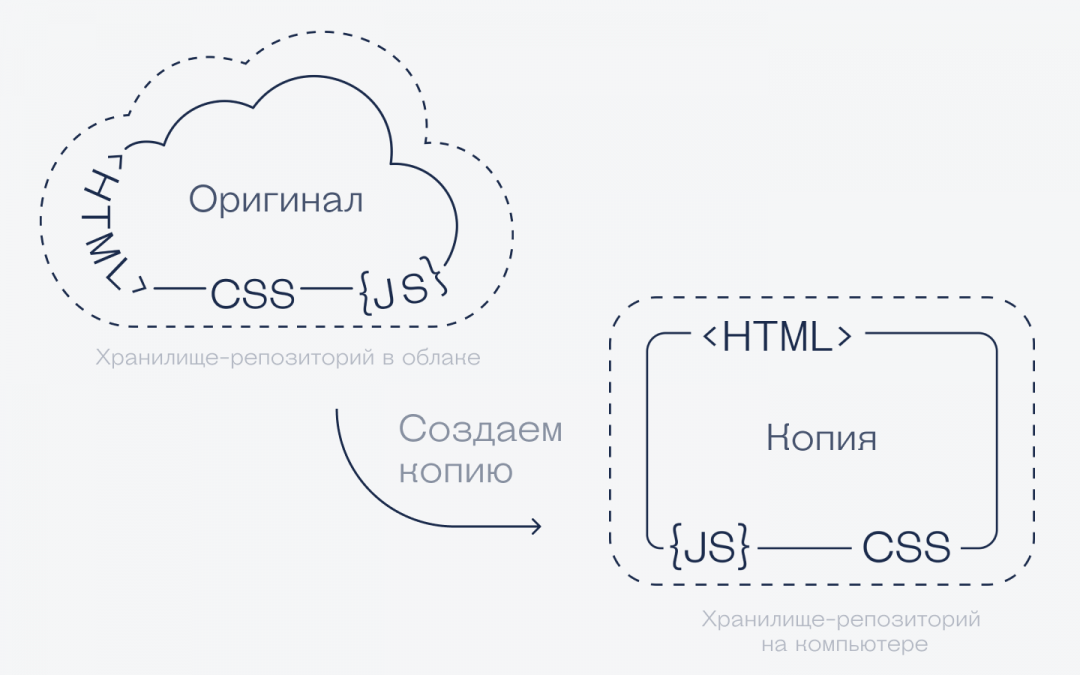
Клонирование — это когда вы копируете репозиторий себе на жёсткий диск. Это нужно, чтобы начать в нём что-то менять.
Чем это отличается от простого копирования: когда вы клонируете репозиторий, вместе с файлами вашего проекта вы также тянете всю историю версий, все ветки, всю историю работы. И если кто-то дальше будет вносить изменения в проект, благодаря этим данным вы сможете тоже их получить.
А если просто скопировать нужные файлы с чужого компьютера, то никаких историй и никаких связей не сохранится. Синхронизации не будет. Просто какие-то файлы.
Что значит «смёржить» (git merge)
Смёржить (от англ. merge — объединять, совмещать) — это когда мы отправляем всё, что сделали в одной ветке, в другую. Весь новый код, исправления ошибок, дополнительные функции — всё это отправится в новую ветку. Если же мы что-то удалим в коде, то при объединении этот фрагмент тоже удалится из основной ветки.
Получается, что схема работает так:
Что такое коммит (git commit)
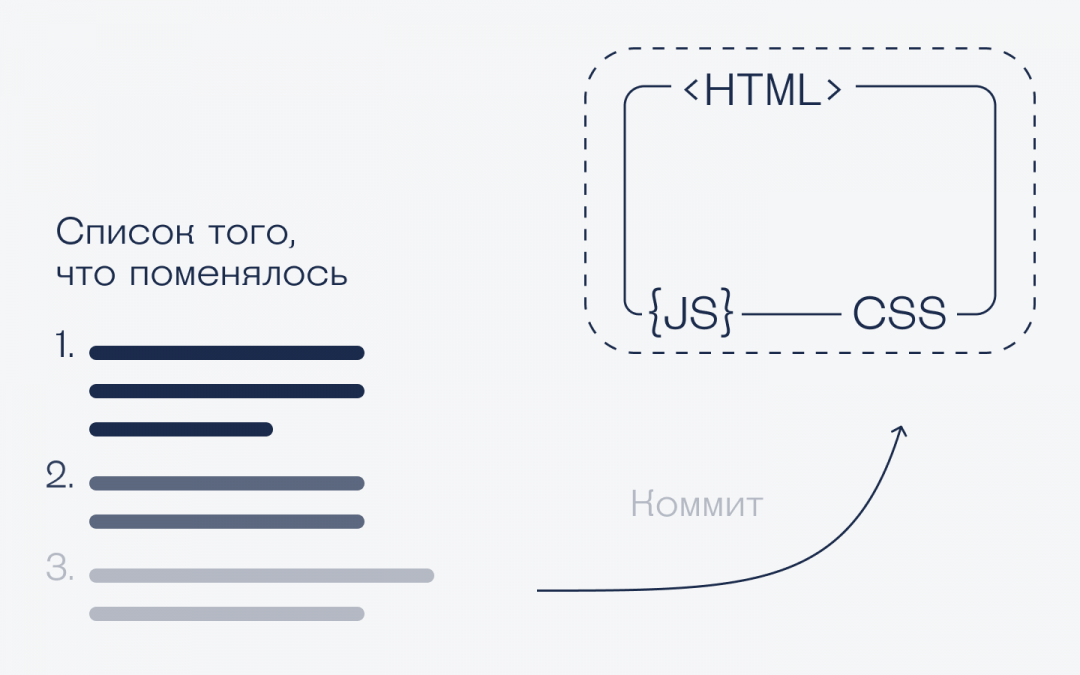
Программировать только в облаке неудобно — проще скачать себе на компьютер весь проект и писать код на своей машине. Но чтобы правки увидели остальные, их нужно отправить обратно в репозиторий. Это и есть коммит.
Коммитить можно и один файл, и сразу несколько. Система сама найдёт, что изменилось в каждом файле, и добавит эти изменения в проект. Но все эти правки внесутся в репозиторий за один раз, потому что при коммите обрабатываются сразу все добавленные в список файлы.
Например, вы изменили файл главной страницы index.html и добавили его в список файлов текущего коммита. Теперь его можно отправить на сервер, а можно ещё поправить сразу style.css и внести в этот же коммит. Системе всё равно, сколько файлов обрабатывать, поэтому как и что коммитить — решает программист.
Единственное требование к коммитам — указывать, что именно вы поменяли в проекте, человеческим языком. Хорошим тоном и правильным подходом считается писать, что именно вы изменили: «Добавил цвет и стили основной кнопки», «Убрали метод вызова старого API», «Сделали рефакторинг функции SetOutOfDate()». Это описание будут читать другие разработчики.
Коммитить можно хоть после правки каждой строчки — весь вопрос в том, насколько нужна такая детализация в проекте. Но иногда и изменения из одной строчки можно закоммитить, если оно действительно важное.
Что такое пуш и пулл (git push, git pull)
Чтобы отправить данные из своего проекта на сервер, используют gut push. Для этого программист указывает имя ветки, в которую хочет отправить свой код, а сервер их принимает, проверяет и добавляет к себе.
Иногда бывает так, что сервер отказывается это сделать, потому что у программиста на компьютере была неактуальная ветка. За то время, пока он писал свои правки, другие программисты сделали несколько изменений, закоммитили их у себя и отправили на сервер. Получилось, что у одних эта ветка осталась свежей и актуальной, а у других она устарела. Чтобы не принимать запросы из устаревших веток, гитхаб просит сначала обновить данные у себя на комьютере с помощью git pull.
Пулл работает просто: он скачивает с сервера актуальную версию ветки и добавляет код оттуда вам на компьютер. Иногда этот код вступает в противоречие с тем, что уже успел сделать программист, и тогда возникает конфликт — нужно принять решение, какая версия одинакового кода останется в проекте, а что нужно будет убрать.
Чем коммит отличается от пуша
Коммит — это когда вы фиксируете изменения в проекте, как бы подводите итог своей работе.
Пуш — это когда вы отправляете сделанную работу туда, где хранится копия вашего кода.
Получается, последовательность действий такая:
Что дальше
Чтобы все эти бранчи и реквесты стали понятнее, в следующий раз сделаем вот что: заведём учебный проект на Гитхабе и будем работать с ним так, как делают настоящие программисты.

Я слышал, что умение ответить на этот вопрос на собеседовании в некоторых компаниях является критерием прохождения собеседования на сеньорские позиции. Но чтобы лучше понять ответ на него, нужно разобраться, почему вообще плохо переписывание истории?
Для этого, в свою очередь, нам понадобится быстрый экскурс в физическую структуру git-репозитория. Если вы точно уверены, что знаете об устройстве репо всё, то можете пропустить эту часть, но даже я в процессе выяснения узнал для себя довольно много нового, а кое-что старое оказалось не вполне релевантным.
На самом низком уровне git-репо представляет собой набор объектов и указателей на них. Каждый объект имеет свой уникальный 40-значный хэш (20 байт, записанные в 16-ричной системе), который вычисляется на основе содержимого объекта.
Основные типы объектов — это blob (просто содержимое файла), tree (набор указателей на blobs и другие trees) и commit. Объект типа commit представляет собой только указатель на tree, на предыдущий коммит и служебную информацию: дата/время, автор и комментарий.
Где здесь ветки и тэги, которыми мы привыкли оперировать? А они не являются объектами, они являются просто указателями: ветка указывает на последний коммит в ней, тэг — на произвольный коммит в репо. То есть когда мы в IDE или GUI-клиенте видим красиво нарисованные веточки с кружочками-коммитами на них — они строятся на лету, пробегая по цепочкам коммитов от концов веток вниз к «корню». Самый первый коммит в репо не имеет предыдущего, вместо указателя там null.
Итак, почему же переписывание истории репозитория вредно?
Итак, развеяв опасения перед изменением истории репозитория, можно, наконец, перейти к главному вопросу: зачем оно нужно и когда оправдано?
Но это тривиальный случай. Давайте рассмотрим более интересные.
Допустим, вы сделали большую фичу, которую пилили несколько дней, отсылая ежедневно результаты работы в репозиторий на сервере (4-5 коммитов), и отправили свои изменения на ревью. Двое-трое неутомимых ревьюверов закидали вас крупными и мелкими рекомендациями правок, а то и вовсе нашли косяки (ещё 4-5 коммитов). Затем QA нашли несколько краевых случаев, тоже требующих исправлений (ещё 2-3 коммита). И наконец при интеграции выяснились какие-то несовместимости или попадали автотесты, которые тоже надо пофиксить.
Но бывает также, что к код-ревью вы уже подошли с историей репо, напоминающей салат «Оливье». Такое бывает, если фича пилилась несколько недель, ибо была плохо декомпозирована или, хотя за это в приличных коллективах бьют канделябром, требования изменились в процессе разработки. Вот, например, реальный merge request, который приехал ко мне на ревью две недели назад:
У меня рука машинально потянулась к кнопке «Report abuse», потому что как ещё можно охарактеризовать реквест из 50 коммитов с почти 2000 изменённых строк? И как его, спрашивается, ревьюить?
Честно говоря, у меня ушло два дня просто на то, чтобы заставить себя приступить к этому ревью. И это нормальная реакция для инженера; кто-то в подобной ситуации, просто не глядя, жмёт Approve, понимая, что за разумное время всё равно не сможет сделать работу по обзору этого изменения с достаточным качеством.
Но есть способ облегчить жизнь товарищу. Помимо предварительной работы по лучшей декомпозиции задачи, уже после завершения написания основного кода можно привести историю его написания в более логичный вид, разбив на атомарные коммиты с зелёными тестами в каждом: «создал новый сервис и транспортный уровень для него», «построил модели и написал проверку инвариантов», «добавил валидацию и обработку исключений», «написал тесты».
Каждый из таких коммитов можно ревьюить по отдельности (и GitHub, и GitLab это умеют) и делать это набегами в моменты переключения между своими задачами или в перерывах.
50 (подставьте вместо “50” вашу цифру).
Кстати, если вы в процессе работы над задачей подливали к себе ветку master, то сначала надо будет сделать rebase на эту ветку, чтобы merge-коммиты и коммиты из мастера не путались у вас под ногами.
Вооружившись знаниями о внутреннем устройстве git-репозитория, понять принцип действия rebase на master будет несложно. Эта команда берёт все коммиты в нашей ветке и меняет родителя первого из них на последний коммит в ветке master. См. схему:
Иллюстрации взяты из книги Pro Git
Если изменения в C4 и C3 конфликтуют, то после разрешения конфликтов коммит C4 изменит своё содержание, поэтому он переименован на второй схеме в C4’.
Да, и кстати, вы можете поменять коммиты местами. Возможно, это создаст конфликты, но в целом процесс rebase редко обходится совсем уж без конфликтов. Как говорится, снявши голову, по волосам не плачут.
Вы можете повторять rebase несколько раз, затрагивая только части истории, и оставляя остальные нетронутыми при помощи pick, придавая своей истории всё более и более законченный вид, как гончар кувшину. Хорошим тоном, как я уже написал выше, будет сделать так, что тесты в каждом коммите будут зелёными (для этого отлично помогает edit и на следующем проходе — squash).
Поначалу вы, скорее всего, будете тратить на этот процесс (включая первоначальный rebase на master) час, а то и два, если фича реально развесистая. Но даже это намного лучше, чем ждать два дня, когда ревьювер заставит себя наконец взяться за ваш реквест, и ещё пару дней, пока он сквозь него продерётся. В будущем же вы, скорее всего, будете укладываться в 30-40 минут. Особенно помогают в этом продукты линейки IntelliJ со встроенным инструментом разрешения конфликтов (full disclosure: компания FunCorp оплачивает эти продукты своим сотрудникам).
Последнее, от чего хочется предостеречь, — не переписывайте историю ветки в процессе код-ревью. Помните, что добросовестный ревьюер возможно клонирует ваш код к себе локально, чтобы иметь возможность смотреть на него через IDE и запускать тесты.
Спасибо за внимание всем, кто дочитал до конца! Надеюсь, что статья будет полезна не только вам, но и коллегам, которым ваш код попадает на ревью. Если у вас есть клёвые хаки для git — делитесь ими в комментариях!


