Структурированный протокол обмена данных Protobuf или JSON во фронтенде?

В новом проекте в нашей команде мы выбрали frontend framework VUE для нового продукта, бэкенд написан на PHP, и уже как 17 лет успешно работает.
Когда код начал разрастаться, нужно было думать над упрощением обмена данных с сервером, об этом я и расскажу.
Про бэкенд
Проект достаточно большой, и функционал очень замороченный, следовательно код написанный на DDD имел определенные структуры данных, они были сложные и объемные для некой универсальности в проекте в целом.
Про фронтенд
4мес. разработки фронта мы использовали JSON в качестве ответа от сервера, мапили в State Vuex в удобном нам формате. Но для отдачи на сервер нам требовалось преобразовывать в обратную сторону, чтобы сервер смог прочитать и замапить свои DTO объекты (может показаться странным, но так надо 🙂 )
Проблемы
Вроде бы ничего, работали с тем что есть, состояние разрасталось до объектов больших размеров. Начали разбивать на еще меньшие модули в каждом из которых были свои состояния, мутации и т.п… API стало меняться вслед новым задачам от менеджеров, и все сложнее стало управлять всем этим, то там замапили не так, то поля изменились…
И тут мы начали думать об универсальных структурах данных на сервере и фронте чтобы исключить ошибки в парсингах, мапингах и т.п.
После некоторых поисков, мы пришли к двум вариантам:
Хватит болтовни, давайте посмотрим как все это выглядит
Как это выглядит на стороне PHP я не буду описывать, там примерно все тоже самое, объекты те же.
Покажу на примере простого клиентского JS и мини сервера на Node.js.
Для начала описываем структуры данных которые нам потребуется. Дока.
Поясню немного про сервис, зачем он нужен, если даже не используется. Сервис описывается только ради документации в нашем случае, что принимает и что отдает, чтобы мы могли подставлять нужные объекты. Он нужен только для gRPC.
Далее скачивается генератор кода на основании структур.
И запускается команда генерации под JS.
После генерации появляется 3 JS файла, в которых уже все приведено к объектам, с функционалом сериализации в буфер и десериализации из буфера.
price_pb.js
product_pb.js
service_pb.js
Далее описываем уже JS код.
В принципе клиент готов.
На сервере заюзаем Express
Что мы имеем в итоге
Я взял lorem ipsum на 10 абзацев, получилось 5.5кб данных с учетом заполненных объектов Price, Product. И погонял данные по Protobuf и JSON (все тоже самое только заполненные JSON схемы, вместо Protobuf объектов)
Как работать с protobuf в Go
E-commerce давно перестали быть сайтами с картинками — сегодня это огромные онлайн-платформы с множеством высоконагруженных сервисов. В Ozon порядка 60% сервисов — от инфраструктурных проектов до пользовательских — написано на Go, в IT-лаборатории компании сейчас одна из самых больших golang-команд России. Об инструментах разработки и трендах в развитии языка рассказывает Владимир Сердюков, ведущий разработчик группы «Личный кабинет» Ozon.

ведущий разработчик группы «Личный кабинет» Ozon
Как-то ко мне пришел тестировщик и показал тестовый смартфон, на котором было запущено наше приложение — но вместо текста и элементов интерфейса на нем был белый экран. Мы начали разбираться.
Понять, почему это произошло, можно будет ближе к концу статьи, но забегая вперед (спойлер) — отсутствовало одно из обязательных полей в выдаче от бэкенда.
Почему эту проблему стоит обсуждать?
Страница сайта и экран мобильного приложения состоят из множества виджетов. Каждый из них — это контракт, то есть договоренность, в каком виде он придет от бэкенда и как его показывать на клиенте. Если в контракте будет ошибка, это может нарушить работоспособность целого приложения (на самом деле уже нет, но раньше могло).
Подобные проблемы сложно локализовать, и они не заметны на этапе тестирования. Как же тогда их решить? Я бы рекомендовал следующее:
proto 2 vs proto 3
Для работы с контрактами мы в Ozon используем protobuf — механизм, придуманный Google для сериализации структур данных. Чтобы из proto-файлов сгенерировать код, мы используем proto 3 с набором плагинов, один из которых — gogoproto, призванный упростить этот процесс и частично забороть особенности proto v3.
Предыдущая версия протокола (proto 2) позволяла реализовывать обязательные поля при помощи тега optional и задавать стандартное значение. Однако это приводило к проблемам портирования возможности генерации кода на другие языки программирования.
Это стало причиной появления proto 3. В новой версии протокола поменялось отношение к обязательным полям: все поля стали необязательные, а значения по умолчанию просто не отправляются. Кроме того, были исправлены enum, улучшен декодинг в json и внесены другие мелкие изменения.
Как сделать поля обязательными в proto 3
Чтобы сделать поля обязательными, можно использовать Well-known типы данных. Это может быть строка, булево значение, число, timestamp и тому подобное.

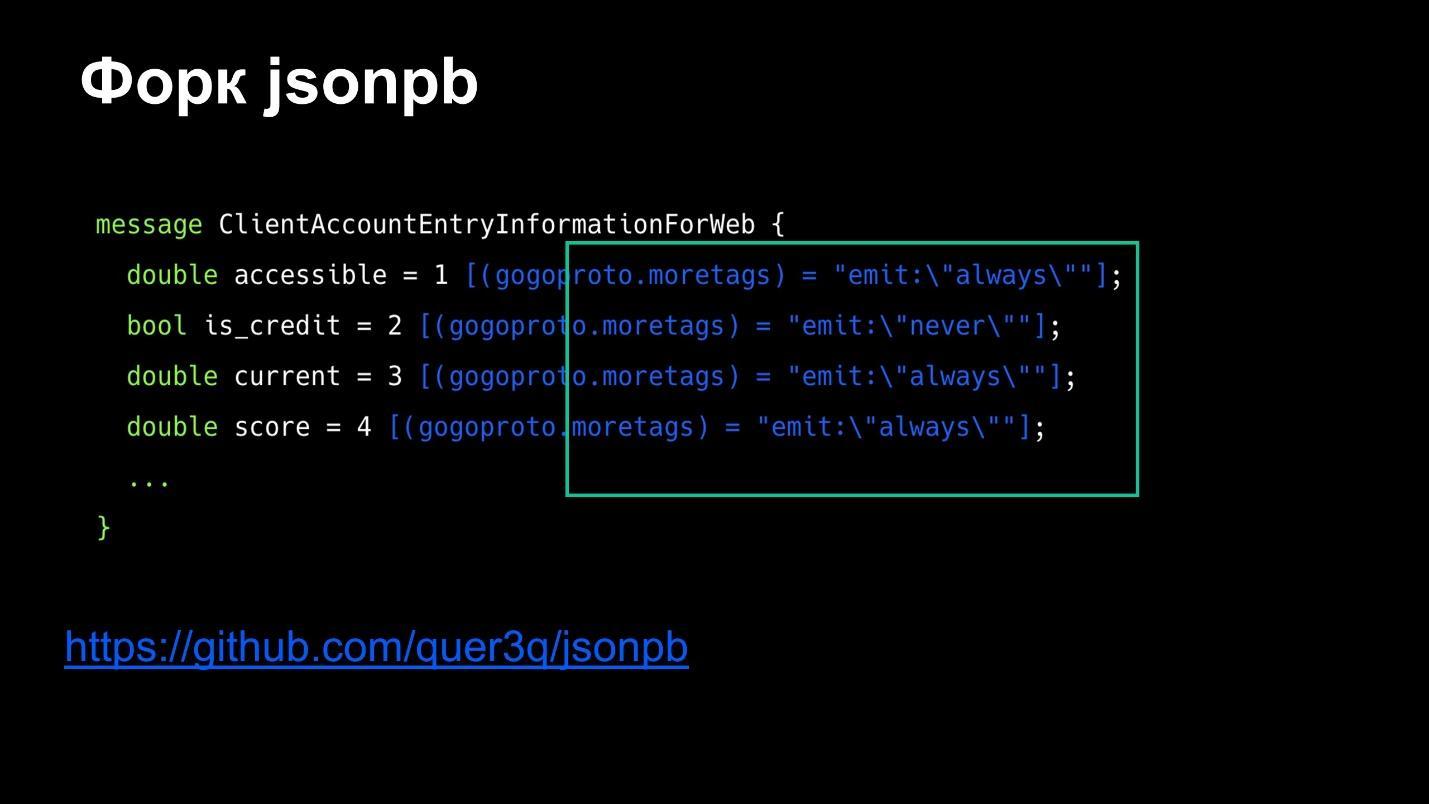
Если появляется такая строка, значит поле отправится вне зависимости от того, что вы в него записали. Однако сложные типы данных (proto-сообщение) все равно остаются необязательными. Тут на помощь приходит плагин gogoproto, где можно указать, что ваша структура не nullable.

Кроме того, можно сделать свой собственный форк jsonpb. Это библиотека, которая proto-сообщения генерирует в json. В нее добавлены три вида тегов — написав их в любом месте файла, можно не переживать, что сообщение не будет отправлено.
Как проверить, что новые изменения не ломают контракты?
Теперь понятно, как можно сделать поля обязательными, но что делать, если вдруг поле перестало быть обязательным или произошло что-то еще?
Для этого есть несколько инструментов для валидации proto-файлов, например buf.build и uber/prototool.
Оба инструмента работают по схожей схеме: чтобы запустить валидацию, создайте yaml-файл, в нем укажите конфигурацию, какие proto-файлы надо проверить, а какие нет. Также можно указать, какую ветку из репозитория брать. В обоих случаях работа идет только с git.
uber/protool пока не поддерживает apiv2, поэтому стоит приглядеться внимательнее к buf.build.
Что такое apiv2?
Поддержка работы с protobuf в Go впервые была анонсирована в 2010 году, первая версия Go вышла только спустя два года. С тех пор прошло много времени, изменились требования.
В итоге, несколько месяцев назад, 2 марта 2020 года, была анонсирована apiv2. Вот что изменилось по сравнению с прошлой версией:
Давайте рассмотрим пример того, что теперь можно сделать из коробки. Есть api, возвращающее данные, которые мы не хотим показывать в логах (например, пароли пользователей, номера банковских карт и т.п.).

Дальше в функции-обработчике где-нибудь в середине формирования сообщения делаем следующее:
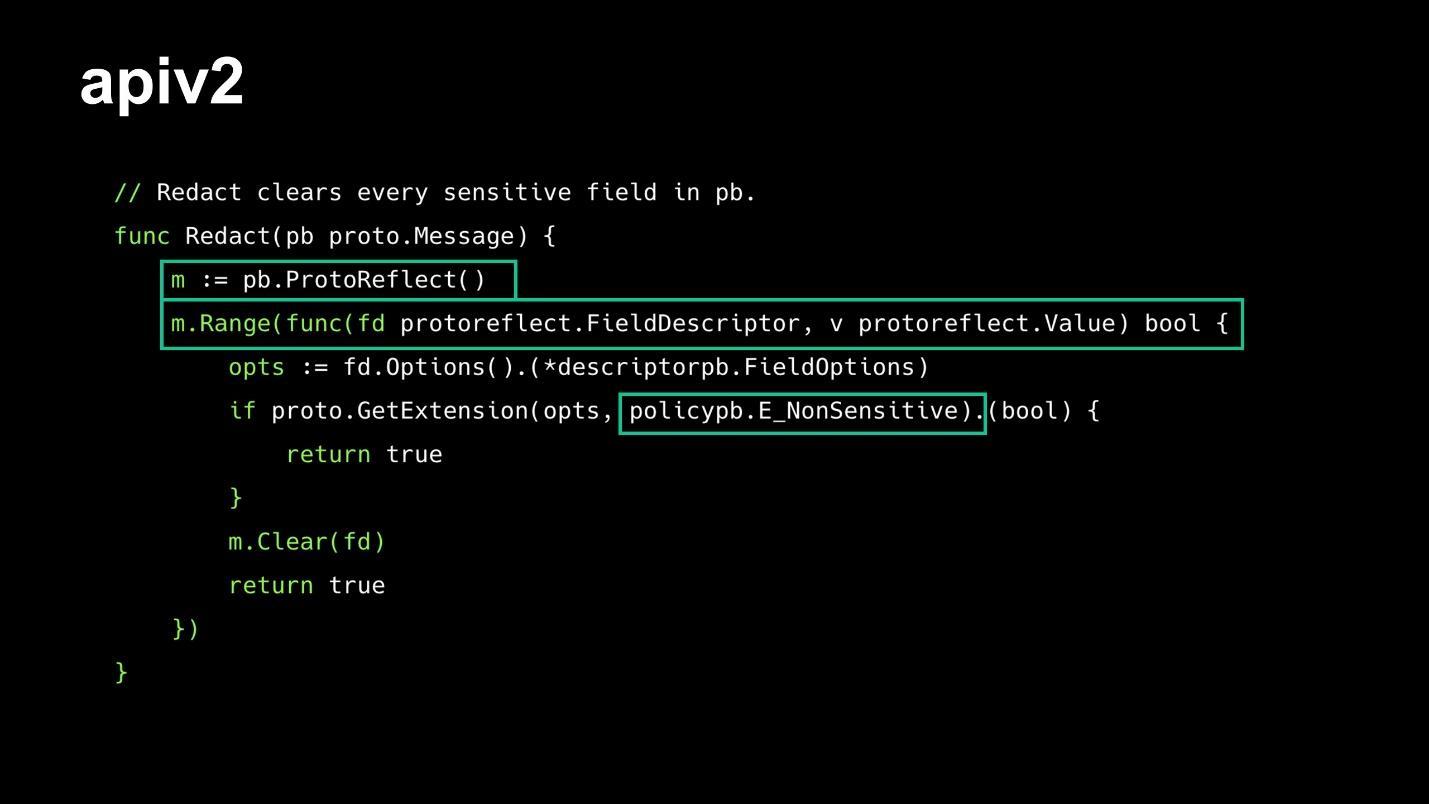
Таким нехитрым способом можно реализовать разные бизнес-кейсы.
Диспетчер произвольных сообщений на базе google protocol buffers
Краткое описание библиотеки protobuf
Компилятор автоматически генерирует C++ код для сериализации и десериализации подобных сообщений. Библиотека protobuf также предоставляет дополнительные возможности: сериализация в файл, в поток, в буфер.
Я использую CMake в качестве системы сборки, и в нем уже есть поддержка protobuf:
PROTOBUF_GENERATE_CPP — данный макрос вызывает компилятор protoc для каждого *.proto файла, и генерирует соответствующие cpp и h файлы, которые добавляются к сборке.
Все делается автоматически, и никаких дополнительных приседаний делать не надо (Под *nix может понадобиться дополнительный пакет Threads и соответствующий флаг линковщику).
Описание диспетчера
Я решил попробовать написать диспетчер сообщений, который принимает какое-то сообщение, вызывает соответствующий обработчик и отправляет ответ на полученное сообщение. При этом диспетчер не должен знать типы передаваемых ему сообщений. Это может быть необходимо в случае, если диспетчер добавляет или удаляет соответствующие обработчики в процессе работы (например, подгрузив соответствующий модель расширения, *.dll, *.so).
Итак, реализация очень проста:
Мы определяем виртуальную функцию process, но также добавляем виртуальную функцию doProcess, которая уже работает с нашими конкретными сообщениями! Данный прием основан на механизме инстанцирования шаблонов: типы подставляются в момент реального использования шаблона, а не в момент декларации. А так как данный класс наследуется от MessageProcessorBase, то мы смело можем передавать наследников данного класса в наш диспетчер. Также необходимо заметить, что данный класс осуществляет сериализацию и десериализацию наших конкретных сообщений и кидает исключения в случае возникновения ошибок.
Ну и напоследок приведу пример использования данного диспетчера, допустим у нас есть два вида сообщений:
Как видно из описания — данные сообщения запрашивают у сервера его внутреннее состояние (ServerStatus), и просто возвращает полученный запрос (Echo). Реализация самих обработчиков тривиальна, я приведу реализацию только ServerStatus:
Сама реализация:
Вот как это работает:
Protobuffers — это неправильно
Значительную часть своей профессиональной жизни я выступаю против использования Protocol Buffers. Они явно написаны любителями, невероятно узкоспециализированы, страдают от множества подводных камней, сложно компилируются и решают проблему, которой на самом деле нет ни у кого, кроме Google. Если бы эти проблемы протобуферов остались в карантине абстракций сериализации, то мои претензии на этом и закончились бы. Но, к сожалению, плохой дизайн Protobuffers настолько навязчив, что эти проблемы могут просочиться и в ваш код.
Узкая специализация и разработка любителями
Остановитесь. Закройте свой почтовый клиент, где уже написали мне полписьма о том, что «в Google работают лучшие в мире инженеры», что «их разработки по определению не могут быть созданы любителями». Не хочу этого слышать.
Давай просто не будем обсуждать эту тему. Полное раскрытие: мне доводилось работать в Google. Это было первое (но, к сожалению, не последнее) место, где я когда-либо использовал Protobuffers. Все проблемы, о которых я хочу поговорить, существуют в кодовой базе Google; это не просто «неправильное использование протобуферов» и тому подобная ерунда.
Безусловно, самая большая проблема с Protobuffers — ужасная система типов. Поклонники Java должны чувствовать себя здесь как дома, но, к сожалению, буквально никто не считает Java хорошо спроектированной системой типов. Ребята из лагеря динамической типизации жалуются на излишние ограничения, в то время как представители лагеря статической типизации, вроде меня, жалуются на излишние ограничения и отсутствие всего того, что вы на самом деле хотите от системы типов. Проигрыш в обоих случаях.
Узкая специализация и разработка любителями идут рука об руку. Многое в спецификациях словно прикручено в последний момент — и оно явно было прикручено в последний момент. Некоторые ограничения заставят вас остановиться, почесать голову и спросить: «Какого чёрта?» Но это всего лишь симптомы более глубокой проблемы:
Очевидно, протобуферы созданы любителями, потому что предлагают плохие решения широко известных и уже решённых проблем.
Отсутствие композиционности
Protobuffers предлагают несколько «фич», которые не работают друг с другом. Например, посмотрите на список ортогональных, но в то же время ограниченных функций типизации, которые я нашёл в документации.
Ваши догадки о проблеме с enum так же верны, как и мои.
Что так расстраивает во всём этом, так это слабое понимание, как работают современные системы типов. Это понимание позволило бы кардинально упростить спецификацию Protobuffers и одновременно удалить все произвольные ограничения.
Решение заключается в следующем:
Например, можно переделать поля optional :
Создание полей repeated тоже просто:
Конечно, реальная логика сериализации позволяет делать что-то умнее, чем пушить связанные списки по сети — в конце концов, реализация и семантика не обязательно должны соответствовать друг другу.
Сомнительный выбор
Конечно же, в двух разновидностях типов совершенно разная семантика.
Невозможно отличить поле, которое отсутствовало в протобуфере, от поля, которому присвоено значение по умолчанию. Предположительно, это решение сделано для оптимизации, чтобы не пересылать скалярные значения по умолчанию. Это лишь предположение, потому что в документации не упоминается эта оптимизация, так что ваше предположение будет не хуже моего.
Когда будем обсуждать претензии Protobuffers на идеальное решение для обратной и будущей совместимости с API, мы увидим, что эта неспособность различать неустановленные значения и значения по умолчанию — настоящий кошмар. Особенно если это действительно сознательное решение, чтобы сохранить один бит (установлено или нет) для поля.
Сравните это поведение с типами сообщений. В то время как скалярные поля являются «тупыми», поведение полей сообщений совершенно безумно. Внутренне, поля сообщений либо есть, либо их нет, но поведение сумасшедшее. Небольшой псевдокод для их аксессора стоит тысячи слов. Представьте такое в Java или где-то ещё:
Такое поведение особенно вопиюще, потому что оно нарушает закон! Мы ожидаем, что задание msg.foo = msg.foo; не будет работать. Вместо этого реализация фактически втихаря изменяет msg на копию foo с инициализацией нулями, если её раньше не было.
(но макросы препроцессора запрещены руководством по стилю Google).
Это не очень приятно слышать, тем более тем из нас, кто любит параметрический полиморфизм, который обещает в точности противоположное.
Ложь обратной и будущей совместимости
Одна из часто упоминаемых «киллер-фич» Protobuffers — их «беспроблемная способность писать обратно- и вперёд-совместимые API». Это утверждение повесили у вас перед глазами, чтобы заслонить правду.
Что Protobuffers являются разрешительными. Им удаётся справиться с сообщениями из прошлого или будущего, потому что они не дают абсолютно никаких обещаний, как будут выглядеть ваши данные. Всё опционально! Но если вам это нужно, Protobuffers с удовольствием приготовит и подаст вам что-то с проверкой типов, независимо от того, имеет ли это смысл.
Это означает, что Protobuffers выполняют обещанные «путешествия во времени», втихую делая неправильные вещи по умолчанию. Конечно, осторожный программист может (и должен) написать код, выполняющий проверку корректности полученных протобуферов. Но если на каждом сайте писать защитные проверки корректности, может, это просто означает, что шаг десериализации был слишком разрешительным. Всё, что вам удалось сделать, это децентрализовать логику проверки корректности с чётко определённой границы и размазать её по всей кодовой базе.
Один из возможных аргументов — что протобуферы сохранят в сообщении любую информацию, которую не понимают. В принципе, это означает неразрушающую передачу сообщения через посредника, который не понимает эту версию схемы. Это же явная победа, не так ли?
Конечно, на бумаге это классная функция. Но я ни разу не видел приложения, где действительно сохраняется это свойство. За исключением программного обеспечения для маршрутизации, ни одна программа не хочет проверять только некоторые биты сообщения, а затем пересылать его в неизменном виде. Подавляющее большинство программ на протобуферах будут декодировать сообщение, трансформировать его в другое и отправлять в другое место. Увы, эти преобразования делаются на заказ и кодируются вручную. И ручные преобразования из одного протобуфера в другой не сохраняют неизвестные поля, потому что это буквально бессмысленно.
Это повсеместное отношение к протобуферам как универсально совместимым проявляется и другими уродливыми способами. Руководства по стилю для Protobuffers активно выступают против DRY и предлагают по возможности встраивать определения в код. Они аргументируют тем, что это позволит в будущем использовать отдельные сообщения, если определения разойдутся. Подчеркну, они предлагают отказаться от 60-летней практики хорошего программирования на всякий случай, вдруг когда-то в будущем вам потребуется что-то изменить.
Корень проблемы в том, что Google объединяет значение данных с их физическим представлением. Когда вы находитесь в масштабе Google, такое имеет смысл. В конце концов, у них есть внутренний инструмент, который сравнивает почасовую оплату программиста с использованием сети, стоимостью хранения X байтов и другими вещами. В отличие от большинства технологических компаний, зарплата программистов — одна из самых маленьких статей расходов Google. Финансово для них имеет смысл тратить время программистов, чтобы сэкономить пару байтов.
Кроме пяти ведущих технологических компаний, больше никто не находится в пределах пяти порядков масштаба Google. Ваш стартап не может позволить тратить инженерные часы на экономию байтов. Но экономия байтов и трата времени программистов в процессе — это именно то, для чего оптимизированы Protobuffers.
Давайте посмотрим правде в глаза. Вы не соответствуете масштабу Google, и никогда не будете соответствовать. Прекратите карго-культ использования технологии только потому, что «Google использует её», и потому что «это лучшие отраслевые практики».
Protobuffers загрязняет кодовые базы
Если бы можно было ограничить использование Protobuffers только сетью, я бы не высказывался так жёстко об этой технологии. К сожалению, хотя в принципе существует несколько решений, ни одно из них не достаточно хорошо, чтобы фактически использоваться в реальном программном обеспечении.
Protobuffers соответствуют данным, которые вы хотите отправить по каналу связи. Они часто соответствуют, но не идентичны фактическим данным, с которыми приложение хотело бы работать. Это ставит нас в неудобное положение, необходимо выбирать между одним из трёх плохих вариантов:
Вместо этого код, использующий протобуферы, позволяет им распространяться по всей кодовой базе. Это реальность. Моим основным проектом в Google был компилятор, который брал «программу», написанную на одной разновидности Protobuffers, и выдавал эквивалентную «программу» на другой. Форматы ввода и вывода достаточно отличались, чтобы их правильные параллельные версии C++ никогда не работали. В результате мой код не мог использовать ни одну из богатых техник написания компиляторов, потому что данные Protobuffers (и сгенерированный код) были слишком жёстким, чтобы сделать с ними что-нибудь интересное.
В результате вместо 50 строк схем рекурсии использовались 10 000 строк специального тасования буфера. Код, который я хотел написать, был буквально невозможен при наличии протобуферов.
Хотя это один случай, он не уникален. В силу жёсткой природы генерации кода, проявления протобуферов в языках никогда не будут идиоматическими, и их невозможно сделать такими — разве что переписать генератор кода.
Но даже тогда у вас останется проблема встроить дерьмовую систему типов в целевой язык. Поскольку большинство функций Protobuffers плохо продуманы, эти сомнительные свойства просачиваются в наши кодовые базы. Это означает, что мы вынуждены не только реализовывать, но и использовать эти плохие идеи в любом проекте, который надеется взаимодействовать с Protobuffers.
На прочной основе легко реализовать бессмысленные вещи, но если пойти в другом направлении, в лучшем вы столкнётесь со сложностями, а в худшем — с настоящим древним ужасом.
В общем, оставь надежду каждый, кто внедрит Protobuffers в свои проекты.
Авторы: Джеймс Ньютон-Кинг (James Newton-King) и Марк Рендл (Mark Rendle)
Сообщения Protobuf
Помимо имени, каждое поле в определении сообщения имеет уникальный номер. Номера полей используются для задания полей при сериализации сообщения в protobuf. Сериализация небольшого числа выполняется быстрее, чем сериализация всего имени поля. Поскольку номера полей указывают на поле, важно соблюдать осторожность при их изменении. Дополнительные сведения об изменении сообщений protobuf см. в разделе Управление версиями gRPC Services.
Дополнительные сведения о сообщениях protobuf см. в разделе Руководство по языку protobuf.
Скалярные типы значений
Protobuf поддерживает ряд собственных скалярных типов значений. В следующей таблице перечислены все типы с эквивалентными им типами в C#.
| Тип protobuf | Тип C# |
|---|---|
| double | double |
| float | float |
| int32 | int |
| int64 | long |
| uint32 | uint |
| uint64 | ulong |
| sint32 | int |
| sint64 | long |
| fixed32 | uint |
| fixed64 | ulong |
| sfixed32 | int |
| sfixed64 | long |
| bool | bool |
| string | string |
| bytes | ByteString |
Типы оболочек, допускающие значение NULL, могут использоваться для поддержки значений NULL.
Даты и время
В следующей таблице показаны типы даты и времени.
Типы, допускающие значение NULL
В следующей таблице приведен полный список типов оболочек с эквивалентным им типом C#.
| Тип C# | Оболочка хорошо известного типа |
|---|---|
| bool? | google.protobuf.BoolValue |
| double? | google.protobuf.DoubleValue |
| float? | google.protobuf.FloatValue |
| int? | google.protobuf.Int32Value |
| long? | google.protobuf.Int64Value |
| uint? | google.protobuf.UInt32Value |
| ulong? | google.protobuf.UInt64Value |
| string | google.protobuf.StringValue |
| ByteString | google.protobuf.BytesValue |
Байты
Используйте ByteString.CopyFrom(byte[] data) для создания экземпляра из массива байтов:
Десятичные знаки
Создание настраиваемого десятичного типа для protobuf
Существует несколько других алгоритмов кодирования значений decimal в виде строк байтов, но это сообщение проще понять, чем любое из них. На значения не влияет обратный порядок байтов или прямой порядок байтов в разных платформах.
Преобразование между этим типом и типом BCL decimal может быть реализовано в C# следующим образом:
Коллекции
Списки
Списки в protobuf указываются с помощью ключевого слова префикса repeated в поле. В следующем примере показано, как создать список.
Словари
Неструктурированные и условные сообщения
Для поддержки этих сценариев Protobuf предлагает языковые функции и типы.
Любой
Oneof
Поля в наборе oneof должны иметь уникальные номера полей в общем объявлении сообщения.
При использовании oneof созданный код C# включает перечисление, указывающее, какое из полей было задано. Можно проверить перечисление, чтобы узнать, какое поле задается. Поля, которые не заданы, возвращают null или значение по умолчанию вместо создания исключения.
Значение
Использование Value напрямую может быть подробным. Альтернативный способ использования Value — встроенная поддержка protobuf для сопоставления сообщений с JSON. Типы JsonFormatter и JsonWriter protobuf можно использовать с любым сообщением protobuf. Value особенно хорошо подходит для преобразования в JSON и обратно.


