Prometheus — практическое использование
Одной из важнейших задач при разработке приложений с микросервисной архитектурой является задача мониторинга. Слежение за состоянием сервисов и серверов позволяет не только вовремя реагировать на неисправности, но и анализировать их работу. Наличие такой информации трудно переоценить, ведь она предоставляет дополнительные возможности по улучшению производительности и качества работы Вашего ПО.

Знакомство с Prometheus
Всерьез с микросервисной архитектурой я столкнулся совсем недавно, начав работу с уже существующей инфраструктурой сервисов. Для слежения за состоянием серверов и сбора метрик использовался Zabbix. Конфигурацией Zabbix занимались администраторы и все изменения/добавления графиков должны были проходить через них. Такой подход позволяет разделить зону ответственности, особенно в случаях, когда одной системой мониторинга пользуются разные команды разработчиков. Но, в то же время, приводит к задержке или неточностям при добавлении новых графиков, ведь администратор может не обратить внимание на детали, очевидные для поставившего задачу разработчика или попросту будет занят другими задачами. Проблема становится особенно острой, когда для дальнейшей разработки требуется быстрый доступ к историческим данным по метрикам сервиса. В качестве средства решения этой проблемы, я решил поискать легкую и простую в настройке систему мониторинга, которая бы хорошо “ложилась” на уже существующую инфраструктуру и упрощала работу по анализу метрик.
Минимальная конфигурация системы мониторинга Prometheus состоит из сервера Prometheus и отслеживаемого приложения, достаточно только указать по какому адресу необходимо запрашивать метрики. Сбор метрик выполняется согласно pull-модели по протоколу HTTP, но существует и push-gateway компонент для слежения за короткоживущими сервисами. При использовании pull-модели Ваши приложения не знают о системе мониторинга, а значит можно запускать несколько серверов Prometheus для мониторинга, тем самым застраховавшись от возможных потерь данных. Для подготовки приложений к дальнейшему мониторингу предлагается использовать клиентские библиотеки, реализующие необходимый инструментарий по созданию и выводу метрик для различных языков. Рекомендуется использовать именно их, но при этом Вы можете применить свою реализацию, если она будет удовлетворять спецификации exposition formats.
Такой подход полностью удовлетворял моим требованиям, так как сбор метрик для Zabbix производился по схожей схеме. Для сохранения совместимости с Zabbix и с уже используемой библиотекой метрик был написан адаптер, преобразовывающий существующий формат в подходящий для Prometheus. Такое решение позволило безболезненно экспериментировать с Prometheus не “задевая” мониторинг в Zabbix и сохраняя стабильность работы существующих сервисов.
Использование
Преимущество использования Prometheus обнаружилось сразу же. Возможность в любой момент получать динамику изменения метрики, сравнивать с другими, преобразовывать, просматривать их в текстовом формате или в виде графика не покидая главной страницы web-интерфейса трудно переоценить.
Для фильтрации и преобразования метрик используется очень удобный язык запросов. К сожалению, отсутствует возможность сохранить сформированный запрос непосредственно через web-интерфейс. Для этого нужно создавать консоль, представляющую собой html-страницу, с возможностью использования Go-templates, и уже в ней строить графики, таблицы, сводки и т.д.
Хорошим решением будет создание обобщенных консолей. К примеру, необходимо мониторить несколько HTTP-серверов. Каждый из них имеет метрику, например, “http_requests_total”, показывающую количество принятых HTTP-запросов. Создадим консоль, отображающую список таких сервисов в виде ссылок на консоли с более подробной информацией:
В результате, мы получим список из ссылок на консоль “job-overview.html”, в которую передается параметр «instance». Теперь этот параметр можно использовать в качестве фильтра для построения графиков:
Как источник дополнительных примеров можно использовать стандартный набор консолей.
Производительность
Как утверждают разработчики, один сервер Prometheus может с легкостью обслуживать миллионы time-series. Этого достаточно для сбора данных с тысячи серверов с интервалом в 10 секунд. В случаях же, когда этого недостаточно — предусмотрена возможность масштабирования.
На практике заявленная производительность подтверждается. При мониторинге 800 сервисов, около 80 метрик в каждом, Prometheus использует около 6% одного ядра и 3 GB RAM, а собранные за 15 дней метрики занимают 17 GB памяти на диске. Не обязательно выделять для Prometheus отдельный сервер, с таким незначительным потреблением ресурсов он может быть установлен рядом с другими сервисами не принося никаких неудобств.
Prometheus хранит собранные метрики в оперативной памяти и при достижении лимита по размеру, или по прошествии определенного интервала времени, сохраняет их на диск. В случаях, когда приходится собирать большое количество данных (больше 100к time series, к примеру) может возрасти нагрузка на диск. В документации Prometheus приводятся полезные советы по оптимизации в таких случаях.
Бывают случаи, когда нужно сформировать график, требующий тяжелых вычислений, захватывающий большие временные периоды или имеющий высокое посещение. Для того, чтобы облегчить работу Prometheus и не вычислять такие данные на каждом запросе, существует возможность предварительного расчета. Такая опция будет особенно полезной при создании дашбордов.
Кастомизация
Откровенно говоря, web-интерфейс показался мне немного “сыроватым”. При работе с графиками, метриками, разделом наблюдаемых сервисов (/targets) возникала необходимость дополнительного функционала. С этим не возникло никаких проблем, и, вскоре, я добавил возможность быстрого поиска по тэгам метрик, а так же изменил layout раздела консолей. Когда раздел /targets увеличился до 800 сервисов — пришлось скрыть эндпоинты на странице, объединив их в группы (иначе они занимали слишком много места). Когда какой-то из эндпоинтов перестает нормально работать, то к группе добавляется иконка, уведомляющая об ошибке. Развернув лист, можно найти проблемный эндпоинт и узнать подробную информацию об ошибке:
Простота web-интерфейсов Prometheus открывает широкие возможности для создания themes, модифицирующих стандартный интерфейсы или добавляя новые разделы. Как подтверждение сказанного, предлагаю ознакомится с графическим генератором конфигурации.
Дополнительное ПО
Команда разработчиков Prometheus создает максимально открытый для интеграции проект, который можно использовать совместно с другими технологиями, а комьюнити всячески старается в этом помочь. На сайте Prometheus Вы сможете найти перечень поддерживаемых exporters — пакетов, снимающих метрики с других сервисов и технологий. Мы используем только некоторые: node_exporter, postgres_exporter и grok_exporter. Для них построены обобщенные консоли, графики в которых строятся относительно просматриваемого сервиса. Все ново добавленные или обнаруженные (service discovery) сервисы автоматически становятся доступными для просмотра в ранее созданных консолях. Если у Вас целый “зоопарк” технологий, то придется установить массу exporters для их мониторинга, но такому подходу есть вполне логическое обоснование.
Странной может показаться ситуация с безопасностью. Изначально, сервис Prometheus и установленные exporters “открыты миру”. Любой желающий, знающий нужный адрес и порт, сможет получить данные по вашим метрикам. Позиция разработчиков здесь такова — Prometheus это система мониторинга, а не безопасности. Пользователям не составит труда использовать в этих целях сторонние 3rd-party продукты, давно и успешно реализовывающие такие задачи, позволив разработчикам Prometheus сфокусироваться на задачах мониторинга. В моем же случае, успешно используется Nginx как reverse-proxy с http basic auth, настройка которого заняла совсем незначительное время.
Для тех, кто хочет лишить себя сна и покоя, разработчики предоставляют возможность использования AlertManager. Он чрезвычайно прост в настройке и позволяет работать с уже упомянутым языком запросов. AlertManager может интегрироваться с HipChat, Slack, PagerDuty, а в случае необходимости интеграции с еще не поддерживаемыми сервисами, рекомендую ознакомиться со статьей интеграции для аудио-оповещения.
В качестве практического примера привожу правило из моей текущей конфигурации AlertManager:
Это правило сработает в случае заполнения дискового пространства более чем на 70% на любом из серверов, где запущен node_exporter, после чего будет выслано соответствующее уведомление на почту.
Заключение
Я рекомендую Вам непременно познакомиться с Prometheus ближе. Для меня он стал легкой, простой и понятной системой мониторинга, с которой просто приятно работать, расширять и модифицировать под свои нужды. Если у кого-то возникнут вопросы относительно практического применения — буду рад ответить в комментариях.
Мониторинг с помощью Prometheus: как это работает
IT-продукт без метрик — как корабль без руля и ветрил. Метрики нужно собирать, анализировать и только на основе их значений принимать решения. Поговорим о том, что такое Prometheus, как он собирает метрики и почему для этого не всегда подходят стандартные базы данных.
Как появился Prometheus
Управление бизнесом без знания цифр — невозможно. Для принятия взвешенных решений нужно знать ключевые бизнес-метрики: выручку, прибыль, количество заказов, количество активных пользователей, плюс как можно больше менее значимых параметров: распределение активности пользователей по регионам, самые популярные продукты на сайте, загрузка серверов. Только владея всей этой аналитической информацией можно понять, где вы находитесь в море бизнеса и куда нужно грести.
В 2012 году онлайн-платформа для распространения звуковых треков SoundCloud озадачилась поиском нового инструмента для аналитики. Взвесив все варианты и попробовав всё, что было на рынке в тот момент, в компании принялись за разработку своего решения.
В то время аналитические СУБД были либо слишком сложными, либо слишком ненадежными и медленными. В то же время начал набирать популярность язык Go. Система сбора метрик на Go могла стать на порядок круче аналогов, поэтому разработчики из SoundCloud решили написать собственный инструмент на нем.
Почему для сбора метрик нельзя использовать, скажем, MySQL?
Можно! Если у вас небольшой проект, малое количество значений в аналитике и данные редко обновляются — еще как можно. В остальных случаях стандартные СУБД не могут обеспечить нужной производительности и надежности. Все эти классные штуки типа индексов и транзакций, важные в других случаях, только замедляют работу базы данных, от которой требуется максимальная скорость и безотказность в записи метрик.
Поэтому для систем аналитики разработали концепцию time series database — систему хранения простых значений, привязанных к определенным моментам времени. У любой базы при таком подходе будет два измерения — момент времени и сами значения. Такой предельно простой подход к структуре хранимой информации позволяет заранее спланировать алгоритмы поиска и обработки значений, а также выжать максимальную скорость работы и надежность. Пространство состояний, в которых может находиться такая СУБД, предельно мало и хорошо описано.
🗽 Что такое Prometheus и почему он так популярен?
Prometheus – это решение для мониторинга с открытым исходным кодом для сбора и агрегирования метрик в виде временных рядов данных.
Проще говоря, каждый элемент в хранилище Prometheus – это метрическое событие, сопровождаемое временной меткой его возникновения.
Prometheus был первоначально разработан в компании Soundcloud, но сейчас это проект сообщества, поддерживаемый Cloud Native Computing Foundation (CNCF).
За последнее десятилетие он быстро приобрел известность, поскольку сочетание функций запросов и “облачной” архитектуры сделало его идеальным стеком мониторинга для современных приложений.
В этой статье мы объясним роль Prometheus, расскажем, как он хранит и предоставляет данные, и выделим, где заканчивается ответственность Prometheus.
Отчасти его популярность объясняется совместимостью с другими платформами, которые могут предоставлять данные в более удобных форматах.
Что делает Prometheus?
Prometheus хранит события в режиме реального времени. Эти события могут быть любыми, имеющими отношение к вашему приложению, например, потребление памяти, использование сети или отдельные входящие запросы.
Основной единицей данных является “метрика”. Каждой метрике присваивается имя, на которое можно ссылаться, а также набор меток. Метки – это произвольные пары данных “ключ-значение”, которые можно использовать для фильтрации метрик в вашей базе данных.
Метрики всегда основаны на одном из четырех основных типов инструментов:
Prometheus определяет текущее значение ваших метрик с помощью механизма получения данных на основе извлечения.
Он периодически опрашивает источник данных, который поддерживает каждую метрику, а затем сохраняет результат как новое событие в базе данных временных рядов.
Мониторируемое приложение отвечает за реализацию конечной точки, используемой в качестве источника данных; такие поставщики данных обычно называются экспортерами.
Модель на основе извлечения упрощает интеграцию Prometheus в ваши приложения.
Все, что вам нужно сделать, это предоставить совместимую конечную точку, которая отображает текущее значение метрики для сбора.
Все остальное Prometheus берет на себя.
Хотя это может привести к неэффективности – например, если Prometheus снова опросит конечную точку до того, как данные изменятся, – это означает, что вашему коду не нужно обрабатывать транспортировку метрик.
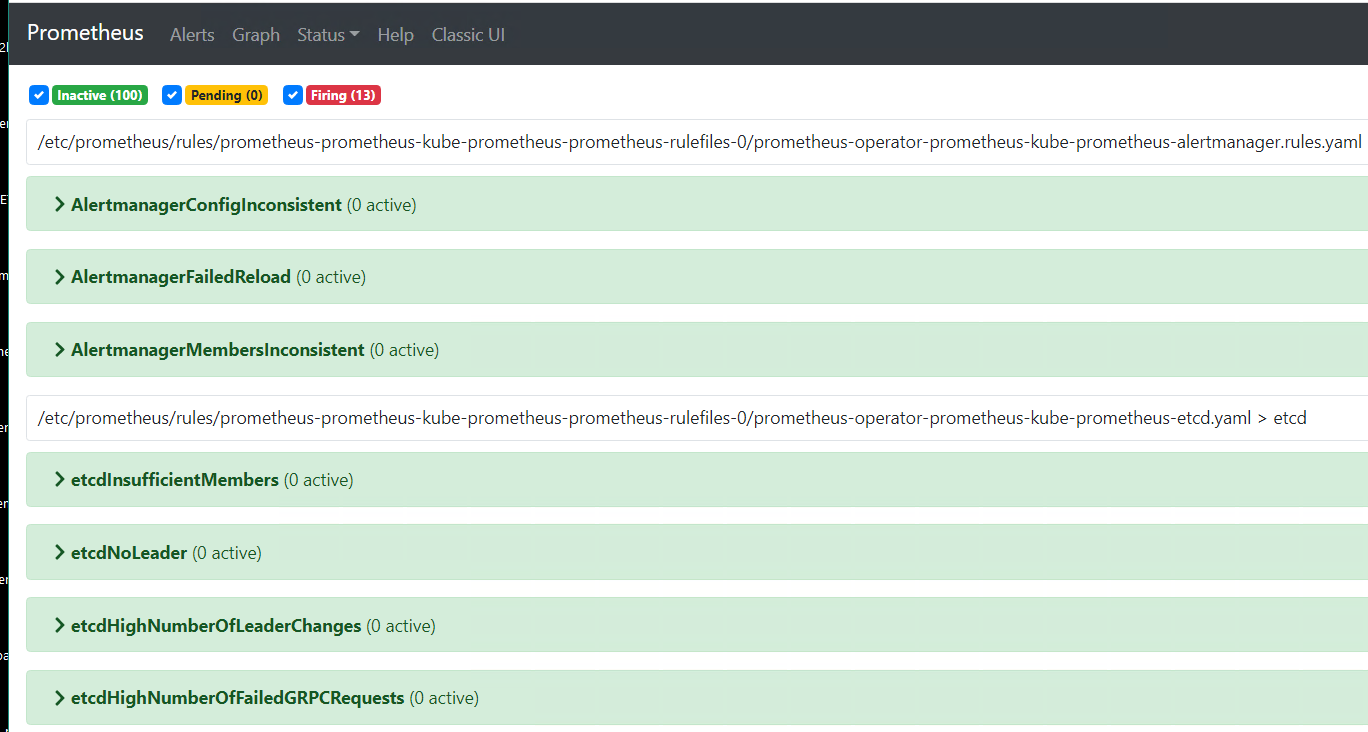
Подробнее об экспортерах
Экспортеры отвечают за отображение метрик вашего приложения, готовых для сбора Prometheus.
Многие пользователи начинают с простого развертывания Node Exporter, который собирает основные системные метрики с Linux-хоста, на котором он установлен.
Доступен широкий спектр экспортеров, многие из которых предоставляются самим Prometheus или официальными поставщиками сообщества.
Если вы отслеживаете популярный механизм баз данных, такой как MySQL, PostgreSQL и MongoDB, или отслеживаете HTTP-сервер, механизм регистрации или шину обмена сообщениями, велика вероятность того, что экспортер уже существует.
Вы можете отслеживать собственные метрики вашего приложения, написав свой собственный экспортер.
При таком подходе нет никаких ограничений – вы можете отслеживать время, проведенное на целевой странице, объем продаж, регистрацию пользователей или все остальное, что важно для вашей системы.
Экспортеры – это простые конечные точки HTTP API, поэтому они могут быть созданы на любом языке программирования.
Prometheus предоставляет официальные клиентские библиотеки для Go, Java/Scala, Python и Ruby, которые облегчают инструментарий вашего кода.
Инициативы сообщества предоставили неофициальные библиотеки для большинства других популярных языков.
Запрос данных Prometheus
Данные в Prometheus запрашиваются с помощью PromQL, встроенного языка запросов, который позволяет выбирать, анализировать и форматировать метрики с помощью различных операторов и функций.
Поскольку Prometheus использует хранение временных рядов, поддерживается выбор диапазона времени и продолжительности, что позволяет легко находить данные, добавленные за определенный период времени.
Вот пример, который отображает все события memory_consumption за последний час:
В этом примере отображаются только события потребления памяти, записанные за последний час.
Вы можете фильтровать по метке, добавляя пары ключ-значение внутри фигурных скобок:
Встроенные функции предоставляют возможности для более точного анализа.
Вот пример, в котором функция rate() используется для расчета скорости увеличения метрики memory_consumption за выбранный период времени:
Доступ к данным Prometheus можно получить с помощью встроенного веб-интерфейса, обычно открываемого через порт 9090, или HTTP API.
Последний обеспечивает надежный способ получения данных из Prometheus в другие инструменты, например, в дашборды.
Алерты
Prometheus поставляется с компонентом Alertmanager, который может отправлять вам уведомления при изменении метрик.
Он поддерживает политики на основе правил, которые определяют, когда следует отправлять оповещение.
Вы можете получать оповещения на адрес электронной почты, произвольные HTTP-вебхуки и популярные платформы обмена сообщениями, такие как Slack.
Alertmanager включает встроенную поддержку агрегирования и отключения повторяющихся оповещений, чтобы вы не были перегружены, когда несколько событий происходят в короткий промежуток времени.
Alertmanager настраивается независимо от основной системы Prometheus.
Вы устанавливаете правила оповещения в Prometheus, определяя условия, когда метрика должна отправить оповещение в Alertmanager.
Последний компонент затем принимает решение о том, следует ли доставлять оповещение на каждую настроенную платформу.

Чего не может Prometheus?
Хотя Prometheus является комплексным решением для мониторинга, есть некоторые функции, для которых он не подходит.
Prometheus разработан с учетом надежности и производительности в качестве основных принципов.
Это приводит к компромиссам в точности показателей.
Prometheus не гарантирует, что собранные данные будут на 100% точными.
Он предназначен для сценариев с большим объемом работы, где случайные падения не влияют на общую картину.
Если вы отслеживаете важные статистические данные, которые должны быть точными, вам следует использовать другую платформу для этих показателей. Вы можете использовать Prometheus для менее важных значений в вашей системе.
Кроме того, Prometheus может быть не единственным компонентом, который вам нужен в вашем стеке мониторинга.
Он сосредоточен на хранении и запросе ваших событий, в основном с использованием HTTP API.
Встроенный веб-интерфейс предоставляет базовые возможности построения графиков, но не может поддерживать продвинутые пользовательские панели.
Сценарии визуализации данных обычно решаются путем развертывания параллельно экземпляра Grafana, который предоставляет возможности построения информационных панелей и анализа метрик со встроенной интеграцией с Prometheus.
Заключение
В самом простом виде Prometheus – это хранилище данных временных рядов, которое можно использовать для управления любыми последовательными данными, основанными на времени.
Чаще всего он используется для мониторинга метрик других приложений в вашем стеке.
Хотя Prometheus является эффективной системой для хранения и запроса метрик, он обычно интегрируется с другими решениями для создания графических панелей и расширенных визуализаций.
Его популярность объясняется способностью работать с пользовательскими метриками, поддерживать насыщенные запросы и взаимодействовать с другими участниками экосистемы облачных решений.
Мониторинг с помощью Prometheus


Мониторинг приложений и серверов приложений — важная часть DevOps-культуры. Вы наверняка хотите постоянно мониторить состояние приложения и серверов, загрузку центрального процессора, потребление памяти, дисковую утилизацию и т.д. Также вы наверняка хотите получать уведомления, если у сервера заканчивается доступная память или приложение перестает отвечать на запросы, что позволит предотвратить проблемы.
Для мониторинга есть ряд бесплатных и платных инструментов, таких как Amazon CloudWatch, Nagios, New Relic, Prometheus, Zabbix и другие. В этом посте мы рассмотрим Prometheus — инструмент для одновременного мониторинга десятков тысяч служб.
Что такое Prometheus и чем он отличается от других систем мониторинга?
Prometheus — популярный CNCF-проект с открытым исходных кодом, большая часть компонентов которого написана на Golang, а часть — на Ruby. Это означает, что у вас будет всего один бинарный файл, который нужно скачать и запустить вместе с компонентами Prometheus. Prometheus полностью совместим с Docker и доступен на Docker Hub. Для начала давайте рассмотрим основные компоненты Prometheus.
Компоненты Prometheus
Сервер Prometheus
Prometheus имеет центральный компонент, называемый Prometheus Server. Его основная задача — хранить и мониторить определенные объекты. Объектом может стать что угодно: Linux-сервер, сервер Apache, один из процессов, сервер базы данных или любой другой компонент системы, которую вы хотите контролировать. В терминах Prometheus главная служба мониторинга называется сервером Prometheus, а объекты мониторинга — целевыми объектами. Как я сказал ранее, целевым объектом может быть один сервер, или целевые объекты для проверки конечных точек через HTTP, HTTPS, DNS, TCP и ICMP (*Black-Box Exporter), или простая конечная точка HTTP, которую выдает приложение. Через конечную точку HTTP сервер Prometheus проверяет статус приложения.
Каждый элемент целевого объекта, который вы хотите мониторить (статус центрального процессора, память или любой другой элемент), называется метрикой. Таким образом, Prometheus собирает через HTTP метрики целевых объектов, хранит их локально или удаленно и отображает.

Вы запрашиваете у базы данных временных рядов Prometheus информацию о месте хранения метрик, используя язык запросов PromQL. Другими словами, с помощью PromQL вы просите сервер Prometheus показать статус конкретного целевого объекта в данный момент времени и получаете метрики.
Prometheus предоставляет клиентские библиотеки на нескольких языках, которые вы можете использовать для обеспечения работоспособности приложения. Но Prometheus — это не только мониторинг приложений. Вы можете использовать экспортеры (exporters) для мониторинга сторонних систем (таких как сервер Linux, демон MySQL и т.д.). Экспортер — часть программного обеспечения, которое получает существующие метрики от сторонней системы и экспортирует их в формат, понятный серверу Prometheus.

Примерной метрикой с сервера Prometheus может быть текущее использование свободной памяти или файловой системы через Node Exporter на сервере Prometheus.
Важно знать, что Prometheus использует стандартную модель данных с метрикой на основе ключа, которая может не совпадать с моделью сторонней системы Именно поэтому вы используете экспортеры для преобразования метрик. Я не буду вдаваться в подробности каждого синтаксиса показателей Prometheus и того, как они отличаются.
Уровень визуализации с Grafana
Вы можете использовать Grafana в качестве стороннего компонента для визуализации метрик, хранящихся в базе данных временных рядов Prometheus. Вместо того чтобы писать запросы PromQL непосредственно на сервер Prometheus, вы используете доски графического интерфейса Grafana для запроса метрик с сервера Prometheus и визуализации их на панели мониторинга Grafana.
Управление оповещениями с Prometheus Alert Manager
Prometheus имеет компонент управления оповещениями, называемый AlertManager. Он служит для запуска оповещений через Email, Slack или другие клиентские уведомления.
Настройка Prometheus в контейнерах Docker
Добавление Node Exporter
Следующее, что нужно сделать, — развернуть контейнер Node Exporter и прикрепить его к серверу Prometheus, как показано в следующем файле YAML:
Здесь вы добавили еще один сервис docker-compose под названием nodexporter. Как упоминалось выше, экспортер – часть программного обеспечения, которая переводит метрики из сторонней системы в метрический формат, понятняй Prometheus. Node Exporter экспортирует метрики ОС на сервер Prometheus, который получает и хранит их в базе данных временных рядов. Вы монтируете тома хост-системы и передаете пару флагов службе Node Exporter, чтобы помочь обнаружить информацию о хост-системе, используя точки монтирования procfs и sysfs. procfs и sysfs – файловые системы в Unix-подобных операционных системах, которые показывают в иерархической файловой структуре и каталогах информацию о процессах и другую системную информацию, такую как хранилище и т. д. Структура варьируется от дистрибутива к дистрибутиву. Вы монтируете эти каталоги хоста в виде volumes в сервис Node Exporter, чтобы Node Exporter мог видеть системную информацию узла и вы могли передавать некоторые флаги командной строки со значением местоположения этих каталогов в контейнер Node Exporter.
При запуске сервера Prometheus вы должны увидеть или выполнить запросы PromQL с префиксом node_ на сервере Prometheus. Запуск PromQL-запросов в Prometheus покажет информацию о процессах хоста, хранении и другие метрики.
Добавление визуализации с Grafana
Grafana — средство визуализации и мониторинга данных с поддержкой нескольких баз данных, включая TSDB Prometheus. С помощью Grafana вы можете создать графический пользовательский интерфейс для метрик, которые собираете на сервере Prometheus, как показано ниже:
Вы пишете запросы PromQL в элементах панели Grafana, а не на сервере Prometheus. Но Grafana вытаскивает метрики с сервера Prometheus с интервалом, который вы выбираете в верхнем правом углу панели мониторинга Grafana, и графически отображает их в своей панели мониторинга. Grafana запускается в контейнере Docker, поэтому добавьте службу Grafana в файл compose. Окончательный docker-compose файл выглядит так:
Перейдите на публичный IP-адрес системы с портом 3000 и вбейте admin: admin в качестве имени пользователя и пароля, чтобы увидеть статистику сервера в панели Grafana. Вы увидите что-то подобное:

Заключение
Вы увидели простейший пример того, как настроить сервер Prometheus с Node Exporter и Grafana для визуализации статистики сервера на Ubuntu 16.0. Вы можете хранить данные временного ряда Prometheus в стороннем хранилище, таком как InfluxDB, а не в локальной файловой системе. Важно отметить, что Prometheus не связан с логированием и трассировкой. Мы рассмотрели, как добавить компонент Prometheus Alert Manager в вышеуказанный стек для отправки оповещений по электронной почте или в Slack, если что-то идет не так, и как использовать service discovery в Prometheus.
Здесь вы можете найти полный исходный код. Также рекомендую прочитать документациюPrometheus, чтобы узнать больше о его компонентах и архитектуре.


