PDF OCR
Распознавать текст с помощью OCR и создавать файлы PDF с возможностью поиска
Информация
Как распознавать текст
Выберите файлы, к которым вы хотите применить OCR или перетащите файлы в активное поле. Измените настройки и запустите OCR. Через несколько секунд вы можете скачать ваши новые файлы PDF с возможностью поиска.
Настройки OCR
Вы можете изменить несколько параметров для управления процессом OCR. Вы можете сохранить в формате PDF/A, удалить артефакты и помехи, просмотреть страницы, установить мета информацию и присоединить к одному финальному файлу.
Просто в использовании
Мы максимально упрощаем распознавание текста через OCR. Вам не нужно устанавливать и беспокоиться о каком-либо программном обеспечении, вам просто нужно выбрать файлы, для которых вы хотите применить OCR.
Поддерживает вашу систему
Вам не нужна специальная система для распознавания текста через OCR. Этот инструмент OCR работает в вашем браузере и, следовательно, функционирует во всех операционных системах. Просто перетащите свои файлы и запустите OCR.
Установка не требуется
Вам не нужно загружать или устанавливать какое-либо программное обеспечение. Текст распознается на наших серверах в облаке и, следовательно, не будет потреблять какие-либо ресурсы вашего компьютера.
Безопасность важна для нас
Это приложение OCR не хранит ваши файлы на нашем сервере дольше, чем это необходимо. Ваши файлы и результаты будут удалены с нашего сервера через короткий промежуток времени. Передача файлов защищена SSL.
Что говорят другие
Этот инструмент позволяет мне очень легко применять OCR к моим отсканированным документам и счетам-фактурам. Я получаю PDF/A с возможностью поиска и архивирования.
Я использую это приложение для конвертации изображений и фотографий, сделанных с помощью моего смартфона в файлы PDF с возможностью поиска, чтобы я мог выполнять поиск и копировать текст.
Вопросы и ответы
Как распознать текст в файлах с помощью OCR?
Безопасно ли использовать инструменты PDF24?
PDF24 серьезно относится к защите файлов и данных. Мы хотим, чтобы пользователи могли доверять нам. Поэтому мы постоянно работаем над проблемами безопасности.
Могу ли я использовать PDF24 на Mac, Linux или смартфоне?
Да, вы можете использовать PDF24 Tools в любой системе, в которой у вас есть доступ в Интернет. Откройте PDF24 Tools в веб-браузере, таком как Chrome, и используйте инструменты прямо в веб-браузере. Никакого другого программного обеспечения устанавливать не нужно.
Вы также можете установить PDF24 в качестве приложения на свой смартфон. Для этого откройте инструменты PDF24 в Chrome на своем смартфоне. Затем щелкните значок «Установить» в правом верхнем углу адресной строки или добавьте PDF24 на начальный экран через меню Chrome.
Могу ли я использовать PDF24 в офлайн без подключения к Интернету?
Да, пользователи Windows также могут использовать PDF24 в офлайн, то есть без подключения к Интернету. Просто скачайте бесплатный PDF24 Creator и установите программное обеспечение. PDF24 Creator переносит все инструменты PDF24 на ваш компьютер в виде настольного приложения. Пользователи других операционных систем должны продолжать использовать PDF24 Tools.
Что такое OCR
Представьте, вам надо оцифровать журнальную статью или распечатанный договор. Конечно, вы можете провести несколько часов, перепечатывая документ и исправляя опечатки. Либо вы можете перевести все требуемые материалы в редактируемый формат за несколько минут, используя сканер (или цифровую камеру) и программу для оптического распознавания символов (OCR).
ЧТО ПОДРАЗУМЕВАЮТ ПОД ТЕХНОЛОГИЕЙ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ
Оптическое распознавание символов (англ. Optical Character Recognition – OCR) – это технология, которая позволяет преобразовывать различные типы документов, такие как отсканированные документы, PDF-файлы или фото с цифровой камеры, в редактируемые форматы с возможностью поиска.
Предположим, у вас есть бумажный документ, например, статья в журнале, брошюра или договор в формате PDF, присланный вам партнером по электронной почте. Очевидно, для того чтобы получить возможность редактировать документ, его недостаточно просто отсканировать. Единственное, что может сделать сканер, – это создать изображение документа, представляющее собой всего лишь совокупность черно-белых или цветных точек, то есть растровое изображение.
Для того чтобы копировать, извлекать и редактировать данные, вам понадобится программа для распознавания символов, которая сможет выделить в изображении буквы, составить их в слова, а затем объединить слова в предложения, что в дальнейшем позволит работать с содержимым исходного документа.
КАКИЕ ПРИНЦИПЫ ЛЕЖАТ В ОСНОВЕ ТЕХНОЛОГИИ FINEREADER OCR?
Наиболее совершенные системы распознавания символов, такие как ABBYY FineReader OCR, делают акцент на использовании механизмов, созданных природой. В основе этих механизмов лежат три фундаментальных принципа: целостность, целенаправленность и адаптивность (принципы IPA).
Изображение, согласно принципу целостности, будет интерпретировано как некий объект, только если на нем присутствуют все структурные части этого объекта и эти части находятся в соответствующих отношениях. Иначе говоря, ABBYY FineReader не пытается принимать решение, перебирая тысячи эталонов в поисках наиболее подходящего. Вместо этого выдвигается ряд гипотез относительно того, на что похоже обнаруженное изображение. Затем каждая гипотеза целенаправленно проверяется. И, допуская, что найденный объект может быть буквой А, FineReader будет искать именно те особенности, которые должны быть у изображения этой буквы. Как и следует поступать, исходя из принципа целенаправленности. Принцип адаптивности означает, что программа должна быть способна к самообучению, поэтому проверять, верна ли выдвинутая гипотеза, система будет, опираясь на накопленные ранее сведения о возможных начертаниях символа в данном конкретном документе.
КАКАЯ ТЕХНОЛОГИЯ ЛЕЖИТ В ОСНОВЕ OCR?
Компания ABBYY, опираясь на результаты многолетних исследований, реализовала принципы IPA в компьютерной программе. Система оптического распознавания символов ABBYY FineReader – единственная в мире система OCR, действующая в соответствии с вышеописанными принципами на всех этапах обработки документа. Эти принципы делают программу максимально гибкой и интеллектуальной, предельно приближая ее работу к тому, как распознает символы человек. На первом этапе распознавания система постранично анализирует изображения, из которых состоит документ, определяет структуру страниц, выделяет текстовые блоки, таблицы. Кроме того, современные документы часто содержат всевозможные элементы дизайна: иллюстрации, колонтитулы, цветной фон или фоновые изображения. Поэтому недостаточно просто найти и распознать обнаруженный текст, важно с самого начала определить, как устроен рассматриваемый документ: есть ли в нем разделы и подразделы, ссылки и сноски, таблицы и графики, оглавление, проставлены ли номера страниц и т. д. Затем в текстовых блоках выделяются строки, отдельные строки делятся на слова, слова на символы.
Важно отметить, что выделение символов и их распознавание также реализовано в виде составных частей единой процедуры. Это позволяет в полной мере использовать преимущества принципов IPA. Выделенные изображения символов поступают на рассмотрение механизмов распознавания букв, называемых классификаторами.
В системе ABBYY FineReader применяются классификаторы следующих типов: растровый, признаковый, контурный, структурный, признаково-дифференциальный и структурно-дифференциальный. Растровый и признаковый классификаторы анализируют изображение и выдвигают несколько гипотез о том, какой символ на нем представлен. В ходе анализа каждой гипотезе присваивается определенная оценка (так называемый вес). По итогам проверки мы получаем список гипотез, проранжированный по весу (то есть по степени уверенности в том, что перед нами именно такой символ). Можно сказать, что в данный момент система уже «догадывается», на что похож рассматриваемый символ.
После этого в соответствии с принципами IPA ABBYY FineReader проводит проверку выдвинутых гипотез. Это делается с помощью дифференциального признакового классификатора.
Кроме того, следует отметить, что ABBYY FineReader поддерживает 192 языка распознавания. Интеграция системы распознавания со словарями помогает программе при анализе документов: распознавание происходит более точно и упрощает дальнейшую проверку результата с учетом данных об основном языке документа и словарной проверки отдельных предположений. После подробной обработки огромного числа гипотез программа принимает решение и предоставляет пользователю распознанный текст.
РАСПОЗНАВАНИЕ ЦИФРОВЫХ ФОТОГРАФИЙ
Изображения, полученные при помощи цифровой камеры, отличаются от отсканированных документов или PDF, представляющих собой изображение.
У них зачастую могут быть определенные дефекты, например искажения перспективы, засветки от фотовспышки, изгибы строк. При работе с большинством приложений такие дефекты могут существенно усложнить процесс распознавания. В связи с этим последние версии ABBYY FineReader содержат технологии предварительной обработки изображения, которые успешно выполняют задачи по подготовке изображений к распознаванию.
КАК ПОЛЬЗОВАТЬСЯ OCR-ПРОГРАММАМИ
Технология ABBYY FineReader OCR проста в использовании – процесс распознавания в целом состоит из трех этапов: открытие (или сканирование) документа, распознавание и сохранение в наиболее подходящем формате (DOC, RTF, XLS, PDF, HTML, TXT и т. д.) либо перенос данных напрямую в офисные программы, такие как Microsoft® Word®, Excel® или приложения для просмотра PDF.
Кроме того, последняя версия ABBYY FineReader позволяет автоматизировать задачи по распознаванию и конвертации документов с помощью приложения ABBYY Hot Folder. С помощью него можно настраивать однотипные или повторяющиеся задачи по обработке документов и увеличить производительность работы.
КАКИЕ ПРЕИМУЩЕСТВА ВЫ ПОЛУЧАЕТЕ ОТ РАБОТЫ С OCR-ПРОГРАММАМИ
Высокое качество технологий распознавания текста ABBYY OCR обеспечивает точную конвертацию бумажных документов (сканов, фотографий) и PDF-документов любого типа в редактируемые форматы. Применение современных OCR-технологий позволяет сэкономить много сил и времени при работе с любыми документами. С ABBYY FineReader OCR вы можете сканировать бумажные документы и редактировать их. Вы можете извлекать цитаты из книг и журналов и использовать их без перепечатывания. С помощью цифровой фотокамеры и ABBYY FineReader OCR вы можете моментально сделать снимок увиденного постера, баннера, а также документа или книги, когда под рукой нет сканера, и распознать полученное изображение. Кроме того, ABBYY FineReader OCR можно использовать для создания архива PDF-документов с возможностью поиска.
Весь процесс преобразования из бумажного документа, снимка или PDF занимает меньше минуты, а сам распознанный документ выглядит в точности как оригинал!
Soda PDF OCR
Конвертируйте любое изображение, отсканированный документ или распечатанный файл PDF в редактируемые документы за считанные секунды с помощью нашей БЕСПЛАТНОЙ* онлайновой функции оптического распознавания символов. Воспользуйтесь нашей БЕСПЛАТНОЙ* онлайновой функцией для распознавания текста в изображениях.
Переместите файл сюда или
Ваши файлы хранятся на наших серверах только 24 часа, после чего они навсегда удаляются.
Использование функции OCR
1 В режиме онлайн или офлайн
Создавайте текст из файлов изображений с помощью бесплатного онлайнового программного обеспечения для оптического распознавания символов Soda PDF. Вы можете использовать функцию оптического распознавания символов из любого приложения, в любое время и в любом месте! Работайте в режиме онлайн с помощью Soda PDF Online или офлайн, загрузив Soda PDF Desktop на свой компьютер. Используйте наши простые и удобные инструменты для работы с файлами PDF, включая функцию оптического распознавания символов и другие наши онлайновые и офлайновые приложения для редактирования файлов PDF!
2 Запустите функцию OCR
Выполняйте больше операций с вашими документами PDF! Загрузите необходимые файлы и используйте функцию оптического распознавания символов для конвертирования отсканированных изображений, содержащих текст в документе PDF, в простой текст, который можно копировать, вставлять и редактировать так же, как в редакторе Microsoft Word.
3 Отправьте по почте
После создания файла PDF загрузите на свой компьютер распознанный документ PDF и просмотрите его непосредственно в своем веб-браузере. После создания нового редактируемого файла PDF в нашем программном обеспечении вы сможете отправить распознанный документ и поделиться им с другими пользователями по электронной почте.
Что представляет собой функция оптического распознавания символов?
Функция оптического распознавания символов помогает своевременно и быстро оцифровывать документы. Вместо набора текста в файлах или изображениях вручную вы можете использовать функцию оптического распознавания символов для автоматического сканирования и распознавания текста в изображениях и отсканированных документах.
Пример: отсканируйте распечатанный документ, откройте приложение Soda PDF на компьютере или в Интернете и используйте нашу функцию оптического распознавания символов для сканирования текста в изображении и конвертирования изображения в редактируемый файл! Функция оптического распознавания символов используется для экономии времени и быстрой оцифровки файлов для более эффективной работы или документооборота. Наведите порядок на столе и используйте цифровой формат благодаря функции оптического распознавания символов в приложении Soda PDF!
Бесплатный сервис по распознаванию
текста из изображений
который поможет получить напечатанный текст из PDF документов и фотографий
Принцип работы ресурса
Отсканируйте или сфотографируйте текст для распознавания

Загрузите файл
Выберите язык содержимого текста в файле

После обработки файла, получите результат * длительность обработки файла может составлять до 60 секунд
Наши преимущества
Основные возможности

Распознавание отсканированных файлов и фотографий, которые содержат текст
Форматирование бумажных и PDF-документов в редактируемые форматы
Приветствуем студентов, офисных работников или большой библиотеки!
У Вас есть учебник или любой журнал, текст из которого необходимо получить, но нет времени чтобы напечатать текст?
Наш сервис поможет сделать перевод текста с фото. После получения результата, Вы сможете загрузить текст для перевода в Google Translate, конвертировать в PDF-файл или сохранить его в Word формате.
OCR или Оптическое Распознавание Текста никогда еще не было таким простым. Все, что Вам необходимо, это отсканировать или сфотографировать текст, далее выбрать файл и загрузить его на наш сервис по распознаванию текста. Если изображение с текстом было достаточно точным, то Вы получите распознанный и читабельный текст.
Сервис не поддерживает тексты написаны от руки.
© 2014-2021 img2txt Сервис распознавания изображений / v.0.6.6.0
Сервисы для распознавания текста (обзор 14 OCR)

Давайте вспомним далекие 2000-е годы… Когда так хотелось перенести текст с учебника в шпаргалку или сохранить важную информацию с газеты либо книги. В те времена распознавание текста было под силу только сканеру или специализированной программе.
Но эпоха операционной системы XP канула в прошлое, и теперь, сидя с ноутом или держа в руке смартфон, мы можем «перенести» без усилий текст с картинки в вордовский файл. Выполняют такое нелёгкое дело сервисы для распознавания текста — все они разные, поэтому мы решили проанализировать их и взвесить все «за» и «против».
Что это такое и откуда появилось?
Интересно, что прототипом подобных сервисов стала машина Таушека — механизм, запатентованный Густавом Таушеком в 1929 году в Германии. В нём использовался фотодетектор и шаблоны.

Прошло почти столетие, и на смену подобного рода механизмам пришел сервис распознавания текста (либо сокращенно OCR-сервис), который преобразует печатные, отсканированные или графические документы в текстовый формат данных. Кстати, с английского языка OCR расшифровывается как оптическое распознавание символов.
Сейчас такие сервисы доступны как на ПК, так и на смартфоне. Их используют, чтобы оцифровать книгу либо документ. Также эти сервисы нужны при автоматизации различных бизнес-процессов.
Список лучших OCR-сервисов
Чтобы выбрать лучшие сервисы для распознавания текста, мы учли несколько факторов — количество входящих и исходящих форматов, «знание» языков, поддерживаемые платформы, а также функционал в зависимости от платной и бесплатной версии.
Итак, в наш список попали:
Ниже мы подробно изучили преимущества и недостатки каждого сервиса, чтобы вы смогли подобрать для себя оптимальный вариант.
Google Disk
Самое первое, что вам придется сделать, если у вас нет Google-аккаунта, это пройти регистрацию. Но с этим не должно быть каких-либо проблем, так как сегодня почти каждый имеет свой Google-аккаунт.
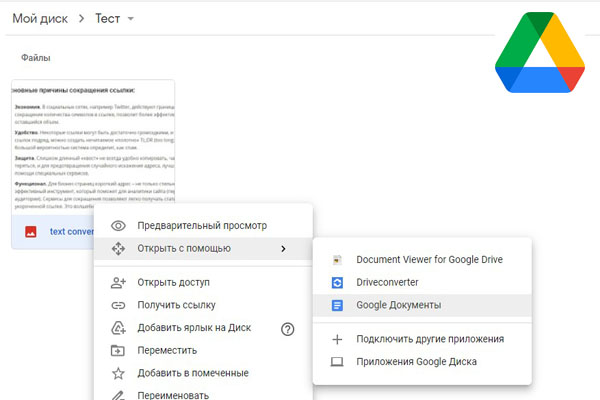
Гугл Диск работает со стандартными картинками (TIF, JPG, PNG и др.), размер которых не больше 2 Мб. Кроме того, он способен определять PDF-документы. У вас могут возникнуть неудобства при считывании многостраничных документов. Дело в том, что сервис распознает первые 10 страниц. Но если вам нужно «перенести» пару страниц, то он с этим отлично справится. Google Disk предлагает сохранить готовый текст в формате MS Word или блокнота, а также в PDF, ODT, RTF, HTML и т.д. Доступен Google Disk почти на всех популярных платформах: Windows, macOS, Android, iOS, Chrome OS.
OCR Convert
Данный онлайн-сервис вы можете использовать в веб-версии совершенно бесплатно. Но, к сожалению, его функционал ограничен: вы сможете конвертировать только самые распространенные форматы: GIF, JPEG, BMP, PDF и PNG.
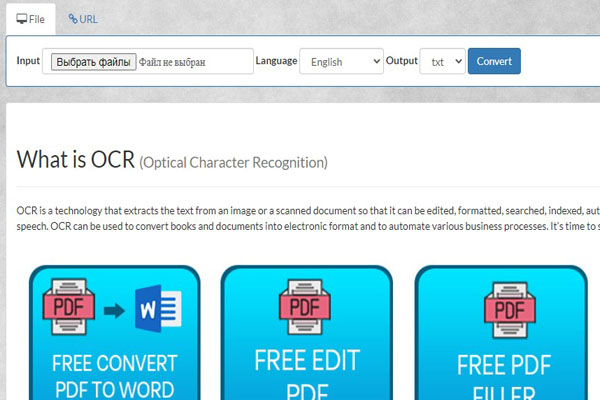
Готовый текст сохраняется как URL-ссылка с расширением TXT. Многократно вы можете загружать до 5 файлов. Лимит на объем — до 5 Мб.
Microsoft Office Lens
Вы сможете определить текст с картинки при помощи камеры. Но насколько хорошо Office Lens умеет это делать? Мягко говоря, не очень. Работает через раз, часто глючит и вылетает. В связи с тем, что Office Lens бесплатный, готовьтесь к просмотру рекламных объявлений.
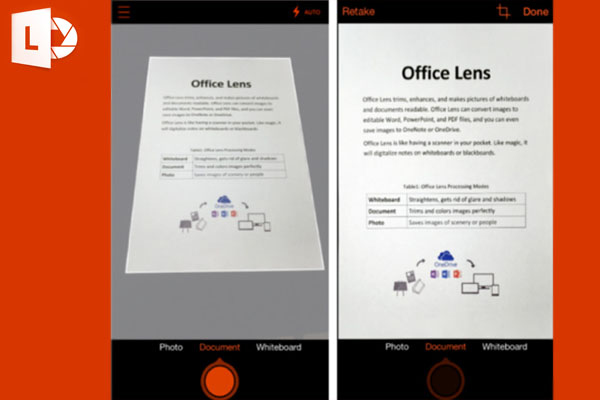
Но если вы все-таки выбрали его, то у вас получится конвертировать картинки в три распространенных формата: Adobe PDF, Word и PowerPoint. Плюс ко всему, изображения можно сохранить в OneNote и OneDrive. Приготовьтесь к тому, что приложение регулярно будет предлагать поделиться текстом и использовать облако OneDrive. MS Office Lens поддерживается такими платформами: iOS, Android, Windows.
FineReader
Онлайн-сервис популярен благодаря высокой точности распознавания текста. Но, к сожалению, возможности бесплатной версии очень ограничены. Сервис разрешает отсканировать до 10 страниц после регистрации. Но есть один приятный момент: каждый месяц вы будете получать +5 бонусных страниц.
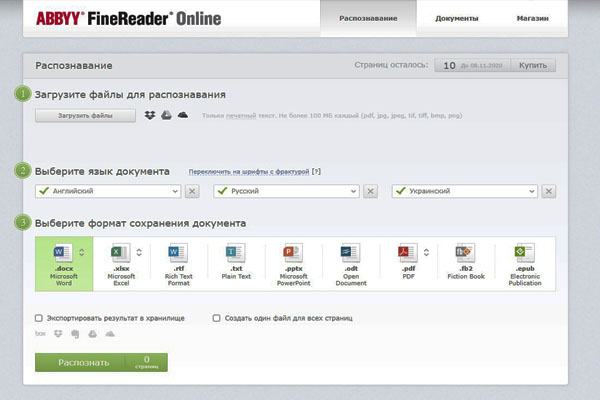
Платная версия (129 евро в год) позволит отсканировать 5 тысяч страниц и откроет доступ к PDF‑редактору. В целом, сервис обрабатывает и сохраняет много распространенных форматов. FineReader распознает более 190 языков.
img2txt
Дизайн сайта привлекает своих посетителей удобством и простотой. Характеристики img2txt.сom тоже весьма неплохи, и производительность достойная.
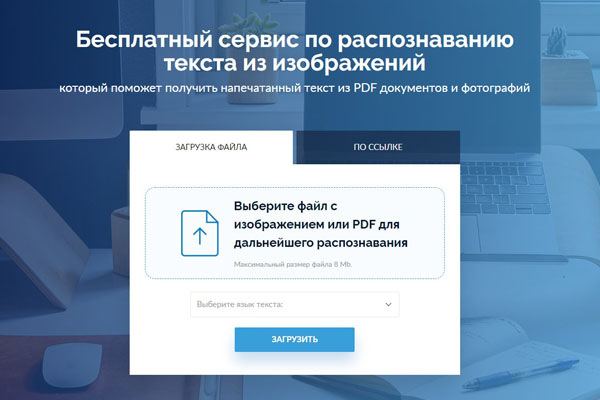
Работает почти со всеми форматами, но не распознает текст, написанный от руки. Помимо этого, img2txt.сom поддерживает PDF-документы. Сервис предлагает сохранить результат в ODF, DOCX, PDF, TXT либо XLS. Ограничение на размер исходника составляет до 8 MB. У сервиса нет мобильного либо Desktop-приложения.
i2OCR
Если вы совсем не готовы платить и хотите распознать текст бесплатно, то обратите внимание на этот онлайн-сервис. Вам предоставляется возможность загрузить исходники популярных форматов (даже TIF, PBM, PGM и PPM). А вот с сохранением выбор невелик: вордовский документ, блокнот, PDF либо HTML. При этом приложение может похвастаться «знанием» более 60 языков (конечно же, и русского тоже).
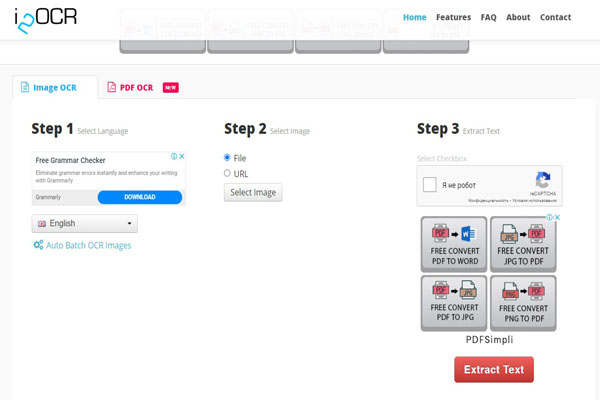
Из недостатков i2OCR стоит упомянуть лимит на объем — до 10 Мб. Кроме того, он не определяет рукописный текст. i2OCR доступен в веб-версии.
Adobe Scan
Так же, как и рассмотренное ранее приложение Office Lens, Adobe Scan использует камеру телефона и сканирует изображения на бумаге. Но он сохраняет их всего лишь в ПДФ-формате.

Распознавание текста с экрана удобно экспортировать в Adobe Acrobat, позволяющий отредактировать PDF-файл (подчеркивать/зачеркивать слова, выделять их, искать слова и словосочетания в тексте, а также добавлять комментарии. Бесплатное приложение доступно на Android и iOS.
NewOCR
С помощью этого помощника вы сможете распознать почти любой графический файл и даже ZIP-архивы. NewOCR отлично владеет 122 языками. Правда, конвертирует из изображений всего лишь три формата текста: MS Word, блокнот и PDF.
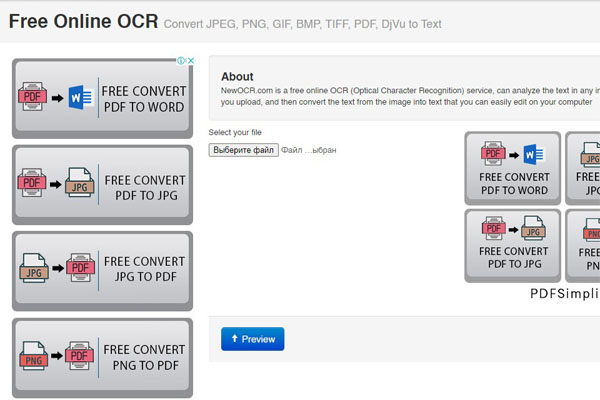
Отличная плюшка сервиса — он не требует регистрации. Также стоит учесть, что все ваши данные защищены. NewOCR хорошо распознает многоколоночный текст, а также позволяет считывать информацию с определенной области макета. Доступен сервис в веб-версии.
Onlineocr
В отличие от остальных конкурентов Оcr-онлайн считывает с большого количества форматов изображений. Но размер этих картинок не должен быть более 15 Мб в свободном доступе.
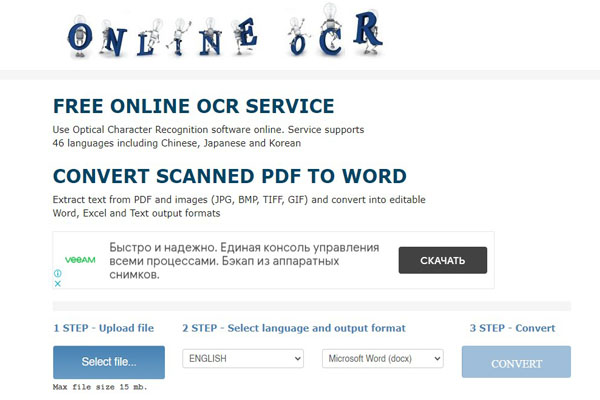
Несмотря на поддержку множества файлов, он преобразует результат только в три формата: MS Excel, MS Word и блокнот. Доступен Оcr-онлайн сервис распознавания текста только в веб-версии.
Microsoft OneNote
Известный всем блокнот умеет также распознавать текст на изображениях. Когда вы кликаете правой кнопкой мыши по снимку и выбираете во всплывающем меню «Копировать текст из рисунка», то содержимое текста перемещается в буфер обмена. Сохраняется результат в вордовском либо ПДФ-документе.
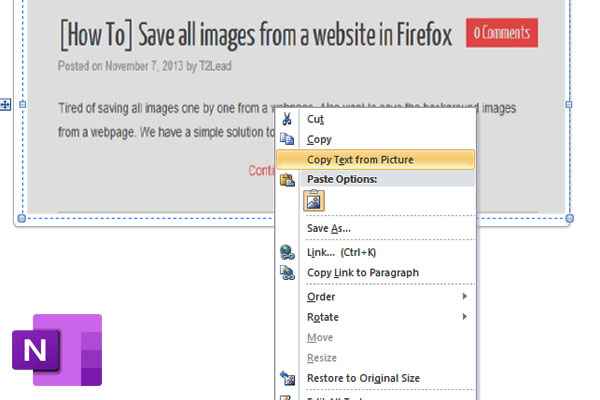
Приложение доступно бесплатно. Поддерживается на платформах Windows и macOS.
Go4convert
Это шустрая и лёгкая в использовании онлайн-платформа, преобразующая различные документы в PDF, WORD, EPUB, FB2, RTF, TXT и прочие форматы.
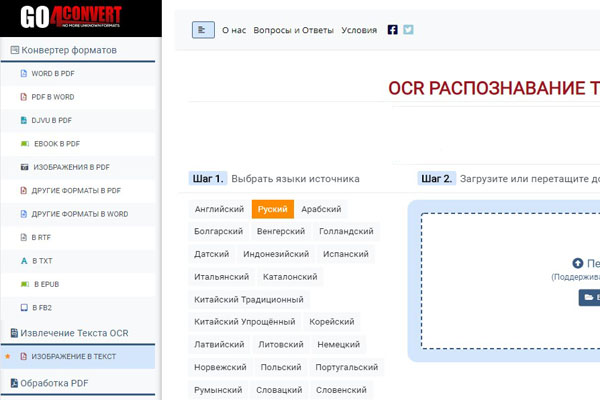
Основное преимущество — она не имеет ограничений по размеру загружаемых исходников. Не стоит только забывать, что чем больше изображение или документ, тем дольше сервис будет с ним работать. Go4convert доступен в веб-версии.
Readiris 17
Это мощная программа, которая достаточно быстро считывает текст с PDF-файлов и прочих форматов изображений. Предусматривает знание многих языков (русский в том числе). При конвертировании предложит вам сохранить результат в формат MS Word, MS Excel, PowerPoint, блокнот, ПДФ и т.д.
Но эта программа не бесплатная. Пробная версия после регистрации работает всего 10 дней, дальше нужно платить. Тариф колеблется от 49 до 199 евро зависимо от необходимых функций.
Convertio.co
Сравнивая с другими конкурентами, Convertio.co — удобный и производительный сервис. Он работает с разными форматами, однако сохраняет готовый материал только в DOCX, PLX, PDF и TXT. Также смущает небольшое количество языков.
Если вам нужно «перенести» текст с документа, Convertio.co сможет проработать всего лишь 10 страниц. Если хотите конвертировать больше, придется проходить регистрацию. Сервис доступен в веб-версии.
Sodapdf
Ранее этот сервис назывался Free-ocr.com. Он очень удобный и имеет простой дизайн. В активе sodapdf.com насчитывается 46 языков. С форматами дела обстоят не очень хорошо. В целом, он форматирует PDF в MS Word, PDF в Эксель, PDF в PowerPoint, PDF в HTML.
Главная фича — это возможность загружать файлы большого размера (до 800 Мб). Кроме того, sodapdf.com умеет объединять PDF, изменять размер данного формата и прочее. Работает в веб-версии.
Сложно представить, насколько сервисы для распознавания текста упростили нам жизнь. Теперь каждому под силу зайти на сайт, загрузить туда интересующее изображение и получить за считанные минуты текст. Если вам нужно преобразовать обычный JPEG или PNG, вам подойдет NewOCR, i2OCR, OCR Convert и прочие. Если вы — активный пользователь смартфона, то скачайте приложение Microsoft Office Lens или Adobe Scan.
А какое приложение или сервис используете вы? Поделитесь в комментариях!


