Свойства мат платы для памяти
1)
ECC Поддерживается, запрещено
ChipKill ECC Поддерживается, запрещено
RAID не поддерживается
DRAM Scrub Rate запрещено
L1 Data Cache Scrub Rate запрещено
L2 Cache Scrub Rate запрещено
Включение этих функций что может дать? Ускорение работы?
2)
Разгон памяти и работа зависит от качества северного моста? ( в Евересте когда нажимаеншь на сер. мост показыаются свойства памяти)
3) Что это означает и какой режим быстрей? поговаривабт 2-ый
Контроллер памяти
Тип Dual Channel 128bit
Активный режим Single Channel 64 bit
получается у меня 64 bit стоит?
Разгон памяти и работа зависит от качества северного моста?
Модули памяти с контролем чётности имеют 9 микросхем не сторону, а не 8. Они дорогие, и встречаются редко.
Кроме АМД, в которых контроллер памяти встроен в процессор.
Дуал чаннэл работает быстрее сингла процентов на 10 примерно.
ура. я нашел форум где помогают в решении вопросов.))
собственно мой вопрос.
в биосе у меня выставлено IDE, если же я переключаюсь на RAID то система не грузится(Win7).(про райд говорит евер.)
вот показания евереста:
ECC Поддерживается, запрещено
ChipKill ECC Поддерживается, запрещено
RAID не поддерживается
DRAM Scrub Rate запрещено
L1 Data Cache Scrub Rate запрещено
L2 Cache Scrub Rate запрещено.
Конфиг процессора:
Свойства ЦП:
Тип ЦП DualCore AMD Athlon 64 X2, 2600 MHz (13 x 200) 5000+
Псевдоним ЦП Brisbane
Степпинг ЦП BH-G2
Наборы инструкций x86, x86-64, MMX, 3DNow!, SSE, SSE2, SSE3
Исходная частота 2600 МГц
Мин./макс. множитель ЦП 4x / 13x
Engineering Sample Нет
Кэш L1 кода 64 Кб per core (Parity)
Кэш L1 данных 64 Кб per core (ECC)
Кэш L2 512 Кб per core (On-Die, ECC, Full-Speed)
Выше упоминалось про модули памяти. вот мои характеристики:
Свойства модуля памяти:
Имя модуля Samsung M3 78T2863RZS-CF7
Серийный номер 5116B224h (615650897)
Дата выпуска Неделя 25 / 2008
Размер модуля 1 Гб (1 rank, 8 banks (этого должно быть 9??))
Тип модуля Unbuffered DIMM
Тип памяти DDR2 SDRAM
Скорость памяти DDR2-800 (400 МГц)
Ширина модуля 64 bit
Вольтаж модуля SSTL 1.8
Метод обнаружения ошибок Нет
Частота регенерации Сокращено (7.8 us), Self-Refresh
Тайминги памяти:
@ 400 МГц 6-6-6-18 (CL-RCD-RP-RAS) / 24-51-3-6-3-3 (RC-RFC-RRD-WR-WTR-RTP)
@ 333 МГц 5-5-5-15 (CL-RCD-RP-RAS) / 20-43-3-5-3-3 (RC-RFC-RRD-WR-WTR-RTP)
@ 266 МГц 4-4-4-12 (CL-RCD-RP-RAS) / 16-34-2-4-2-2 (RC-RFC-RRD-WR-WTR-RTP)
Функции модуля памяти:
Analysis Probe Нет
FET Switch External Запрещено
Weak Driver Поддерживается
Скажите пожалуйста у меня таже проблема с памятью что и у предыдущего?
Если я правильно понял, хотите получить двухканальный режим с одним модулем памяти?
Размер модуля 1 Гб (1 rank, 8 banks(этого должно быть 9?)
Если я правильно понял, хотите получить двухканальный режим с одним модулем памяти?
This posting is provided «AS IS» with no warranties, and confers no rights.
Материнская плата: ASUS S-AM3 M4A89GTD Pro/USB3, Процессор: AM3 AMD Phenom II X6 1055T OEM 3,7 GHz, Кулер процессора: Cooler Master Hyper 212 Plus, Оперативная память: DDR-3 Kingston 12 GB (3 x 4 GB KIT 1333 MHz PC10600), Видеокарта: GeForce GTX470 1280 MB PCI-E Leadtek Winfast [DX11, 320 bit, GDDR5], Жёсткий диск: HDD SATA-2 500 GB Seagate Barracuda, Привод DVD: DVD+RW Sony NEC Optiarc, Блок питания: 600W OCZ StealthXStream Gamers, Корпус: Cooler Master Elite 330 Black, ОС: Windows 7 Ultimate 64-bit RUS
Patrol scrub что это
Добрый день! Уважаемые читатели и гости популярного блога, о виртуализации и настройке серверов pyatilistnik.org. Я уже много информации вам рассказал, о различных настройках сервера Dell PowerEdge R740, но так и не удосужился рассказать, о нем самом. Сегодня я хочу вам показать, как он выглядит физически, как выглядит его BIOS, думаю, что для людей, кто задумывается над покупкой серверов 14-го поколения от компании Dell, эта информация окажется весьма полезной.
Как выглядит Dell Power Edge R740
И так, вот так вот выглядит данный, двух юнитовый сервер.

Подробные характеристики сервера Dell Power Edge R740, вы можете посмотреть по ссылке на официальном сайте:
Как я и писал выше сервер 14-го поколения, дисковая полка в нем защищается вот такой решеткой в виде сот улия. Есть возможность закрыть замок.


Ключ имеет фирменную запись Dell.

Когда я производил настройку IDRAC 9, я вам рассказывал, где находится пароль по умолчанию на него. Там я показывал вот такую карточку, которая идет вместе с сервером, с правой стороны.

Выдвинув ее вы найдете сервисные теги.

Диски в комплекте идут в формате 2,5 дюйма. С правой стороны будут:

BIOS в Dell PowerEdge R740
Вот так вот выглядит начальный экран с логотипом DellEMC. У вас начнется диагностика вашего сервера и определение его железа. В самом верху вы можете наблюдать версию BIOS и полученный IDRAC IP адрес.

Далее у вас появится меню загрузчика, в котором:
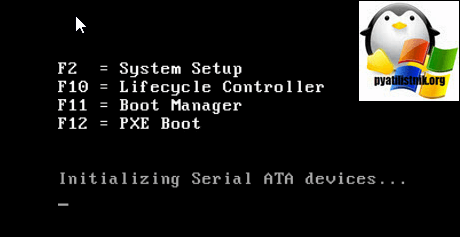
Нажимаем F2 для входа в BIOS сервера. В итоге вы попадете в «System Setup»
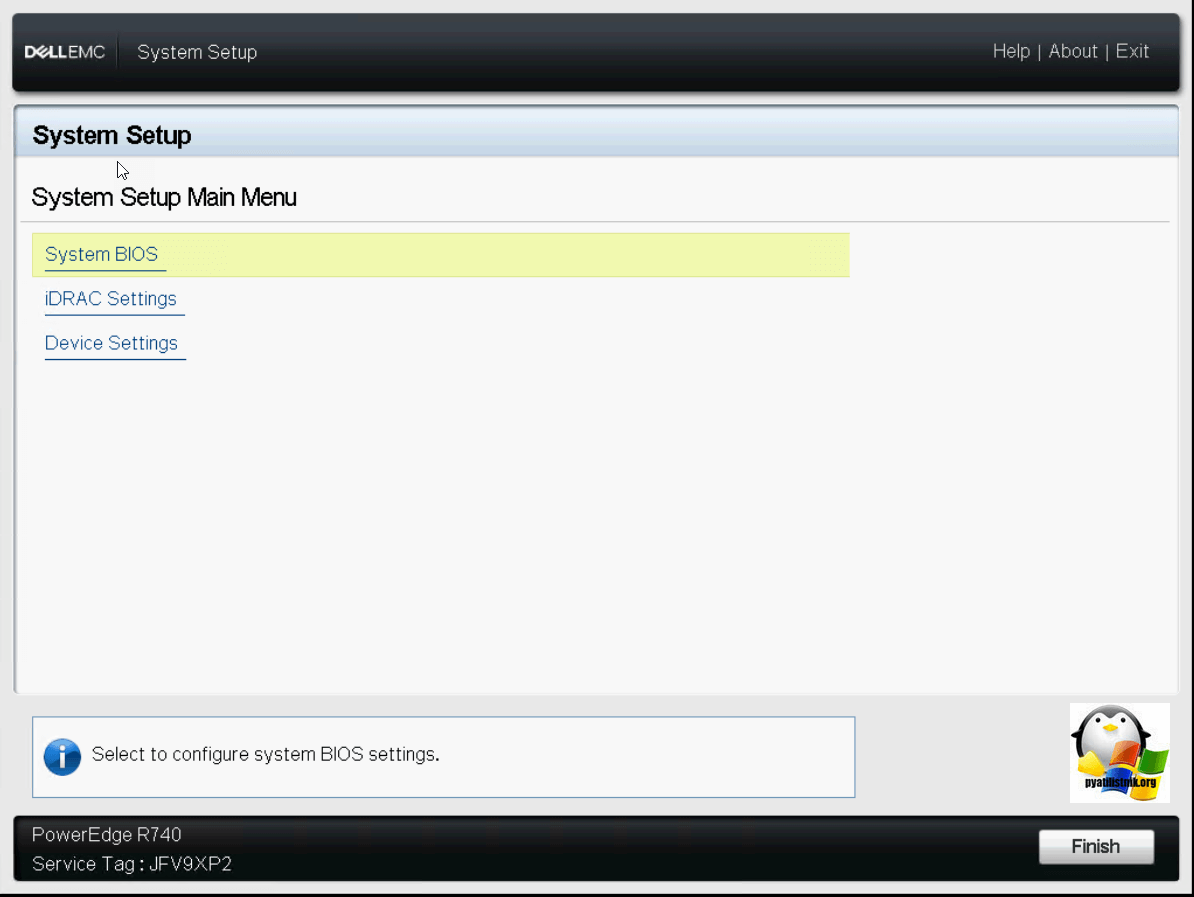
Посмотрим настройки биоса, для этого выберите пункт «System BIOS». У вас откроется окно «System BIOS Settings», в нем будут пункты:
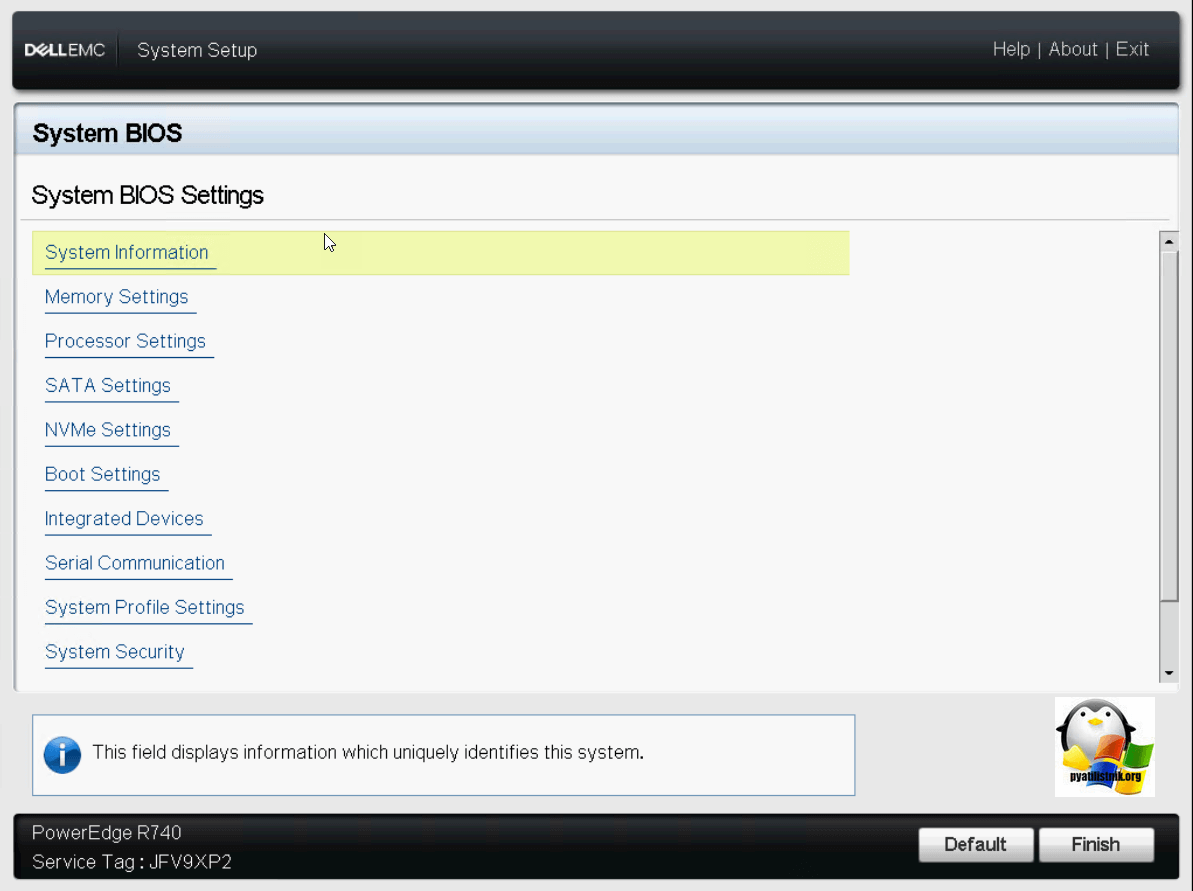
Обзор System Information
В данном пункте вы увидите:
* Имя модели
* Версию биос
System Management Engine Version
* Сервисные теги (System Service Tag)
* Имя производите
* Сайт производите
* System SPLD версию
* UEFI версию
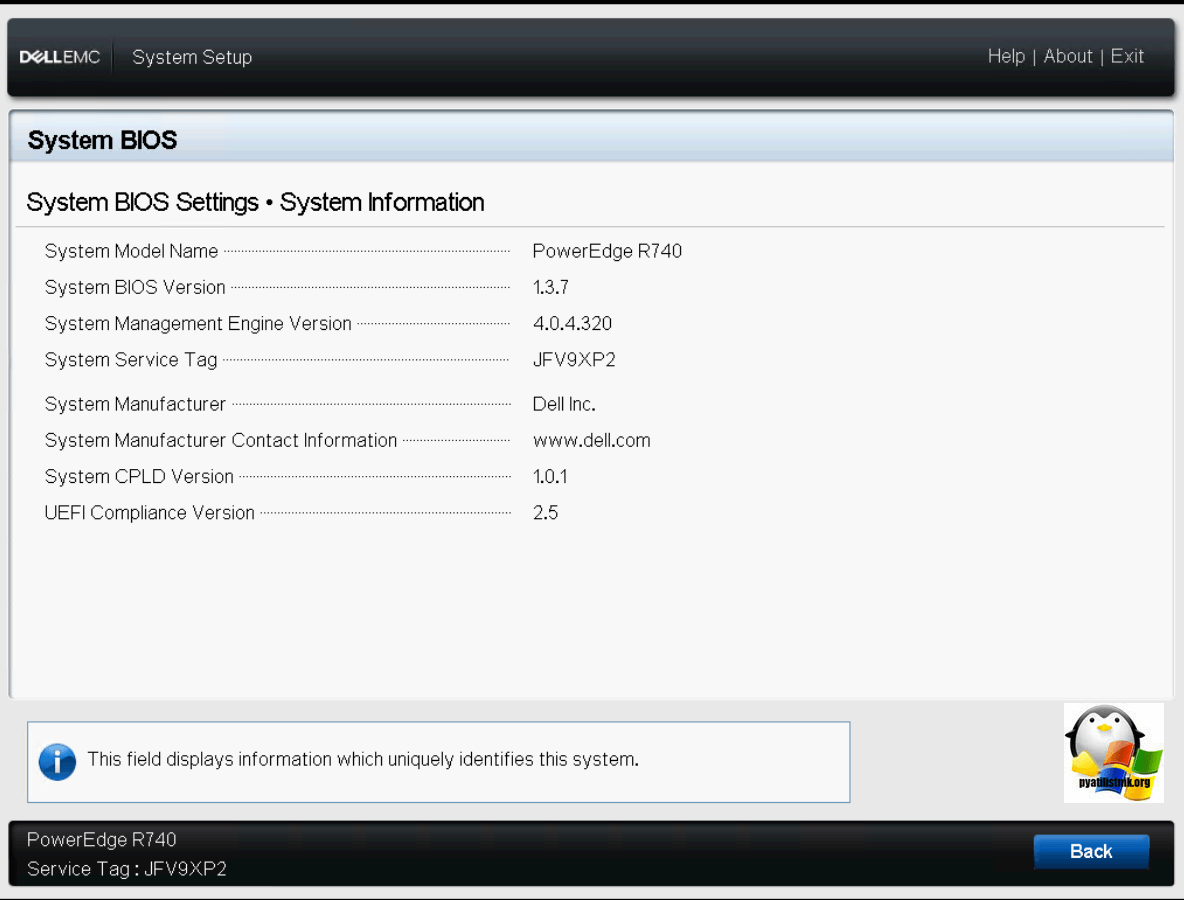
Изменить эти параметры вы не можете, они просто носят информативный вид.
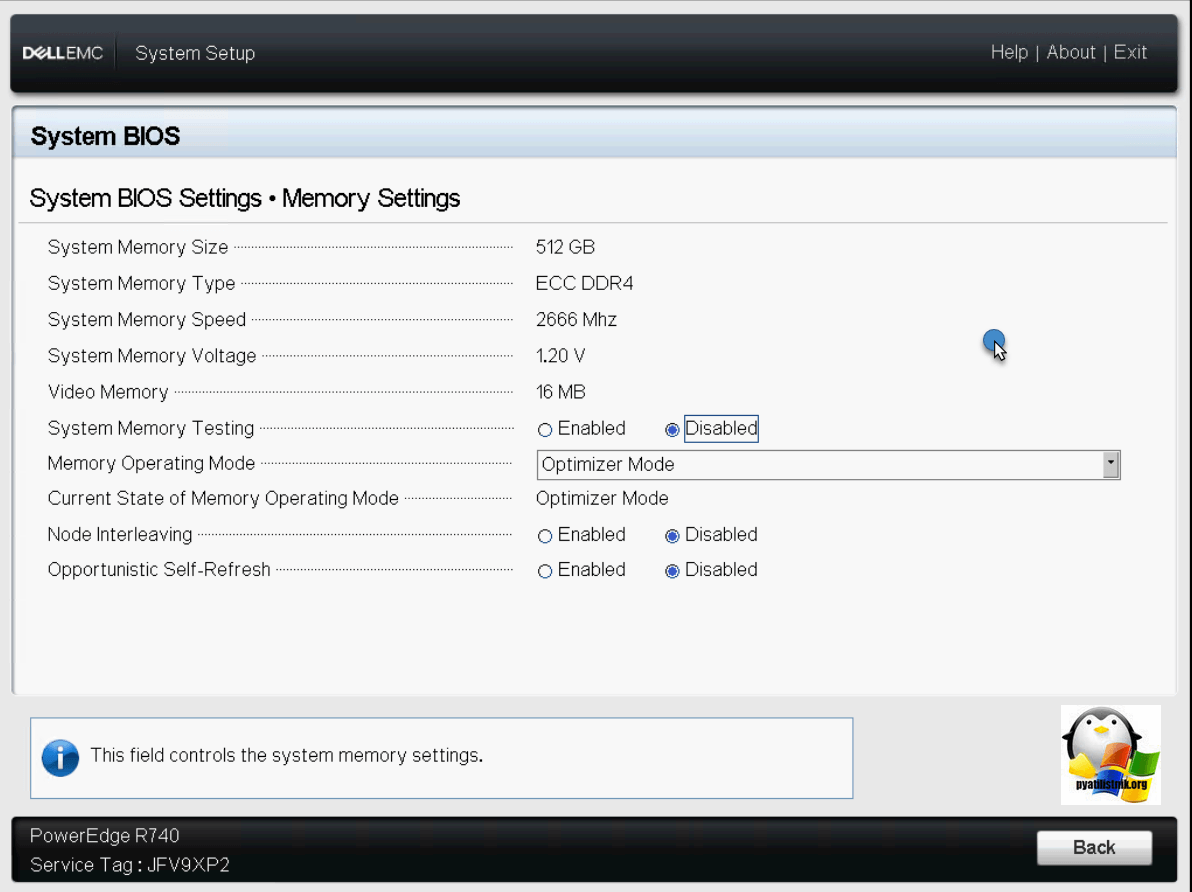
Обзор Memory Settings на Dell PowerEdge R740
В данном разделе вы найдете информацию, о:
Обзор Processor Setings на Dell PowerEdge R740
В данном разделе Dell PowerEdge R740 позволит настроить такие вещи:

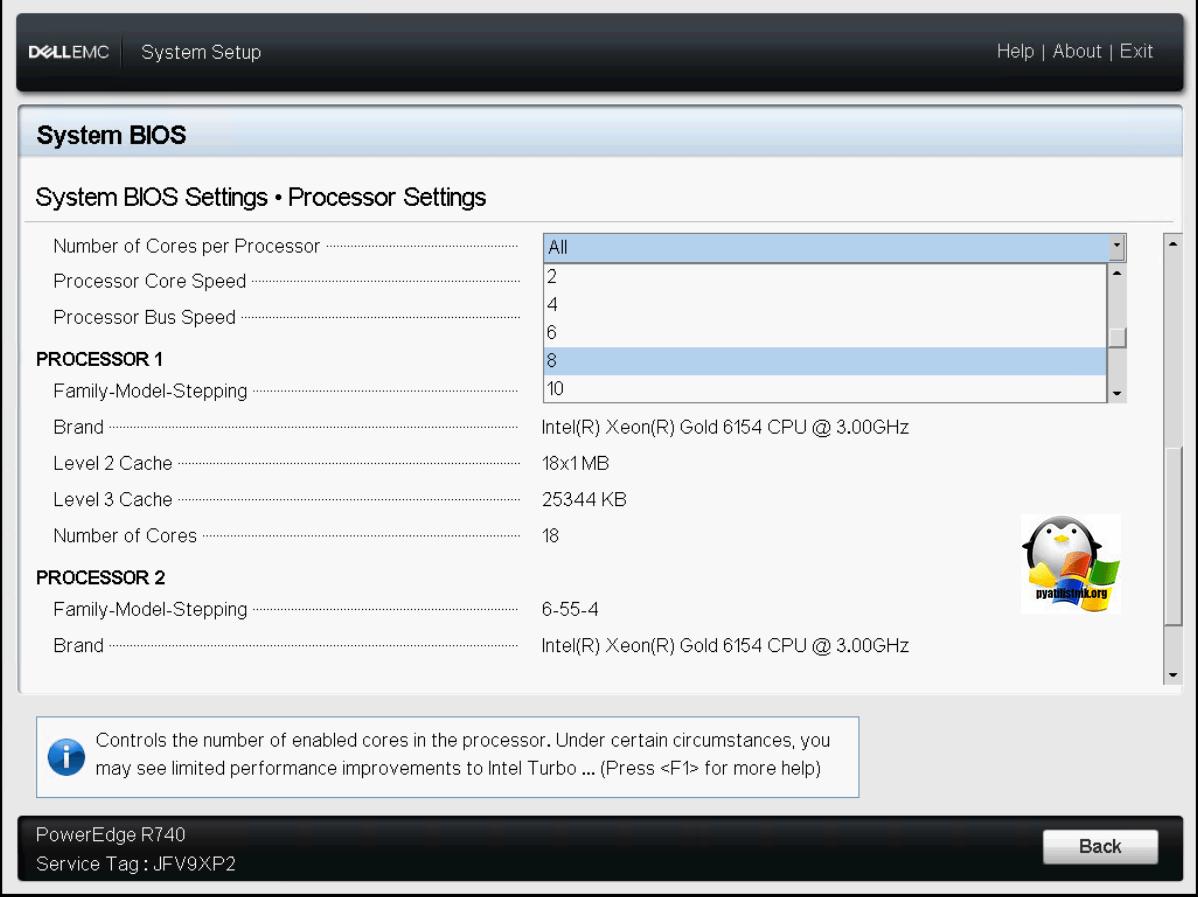
Ниже будет сводная информация, о процессоре, название, число ядер, уровни кэша.
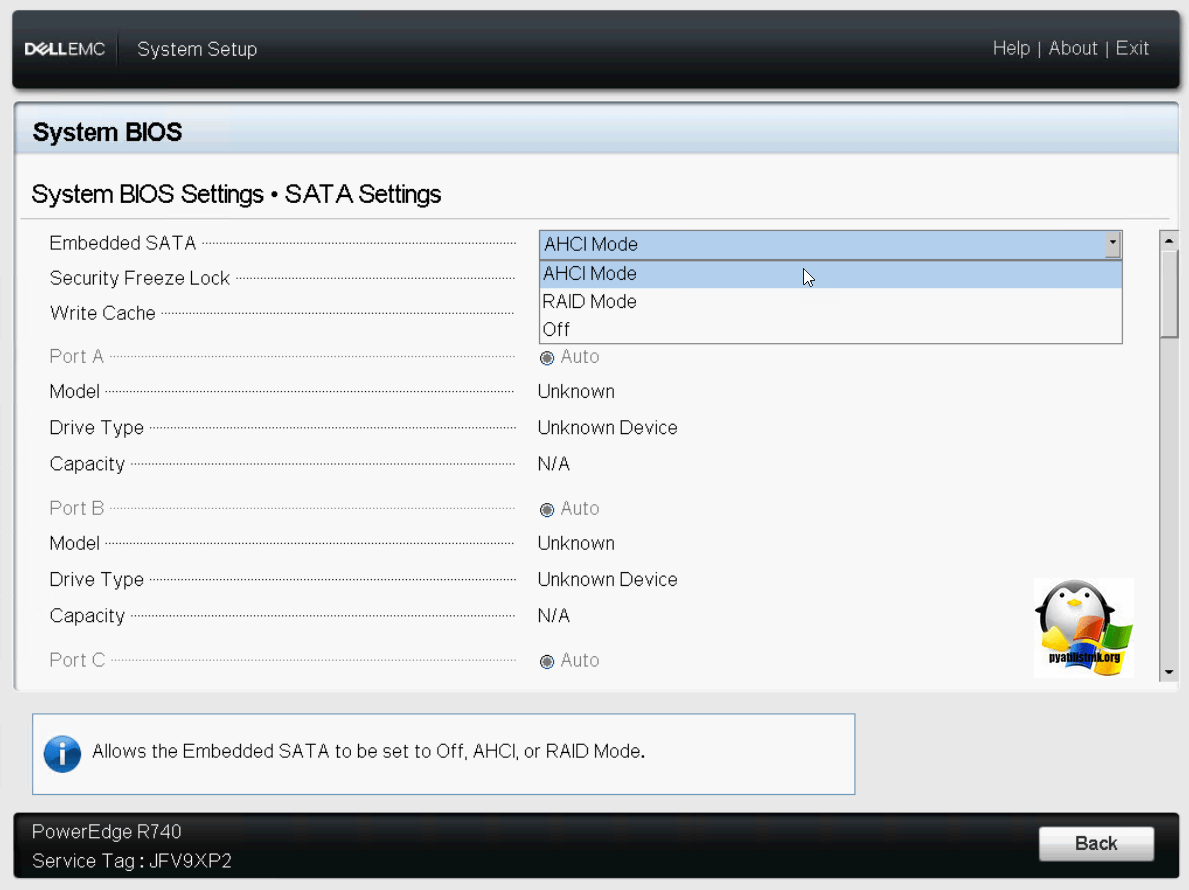
Обзор SATA Settings на Dell PowerEdge R740
Из интересных настроек, тут пункт Embedded SATA, где вы можете выбрать режим работы дисков:
Меню Boot Settings. Тут вы выбираете, в каком режиме будет работать BIOS, либо в старом режиме, либо в режиме UEFI, более продвинутый и новый.
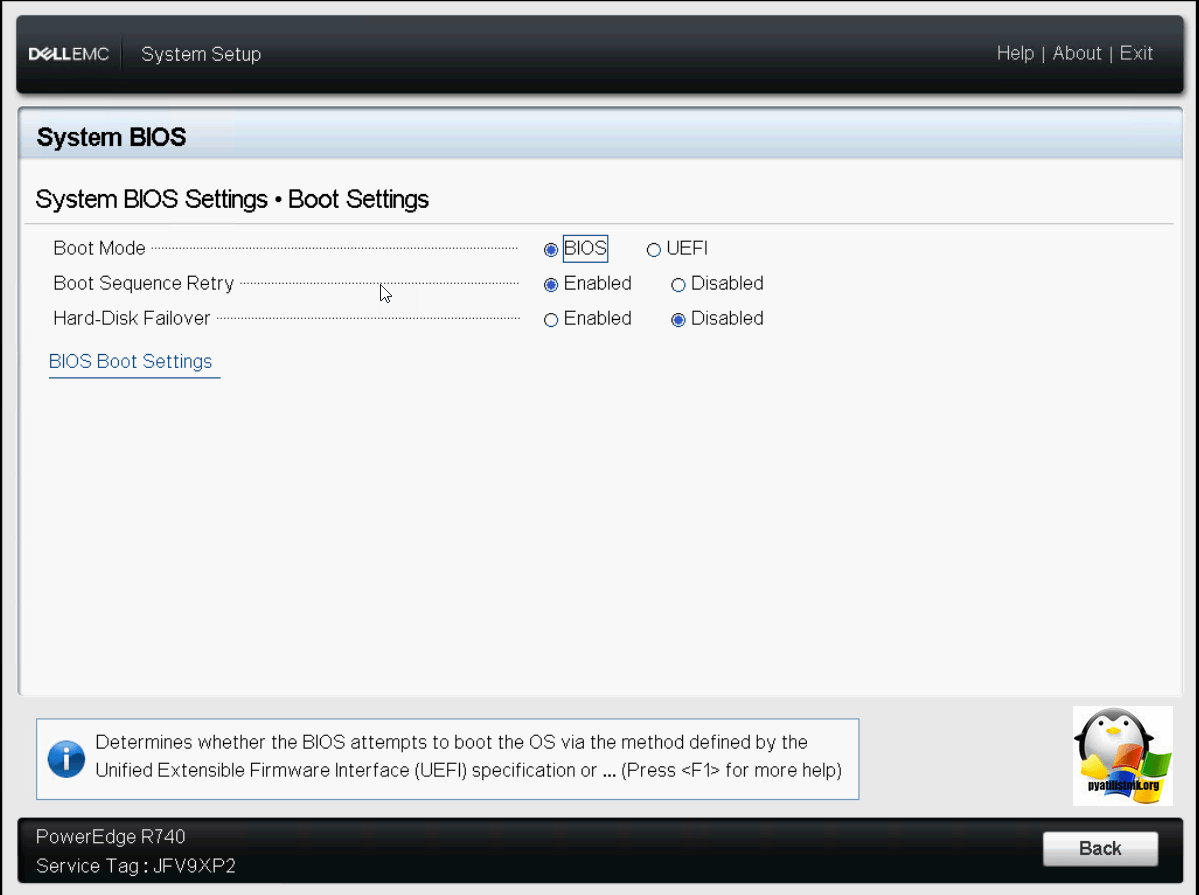
Нажмите кнопку дополнительного меню «BIOS Boot Setting». В нем вы сможете указать, с каких устройств можно производить загрузку системы. В серверах Dell PowerEdge R740, по мимо классического диска C:\ можно использовать встроенную SD карту, идущую в комплекте с сервером.

Обзор Integrated Device на Dell PowerEdge R740
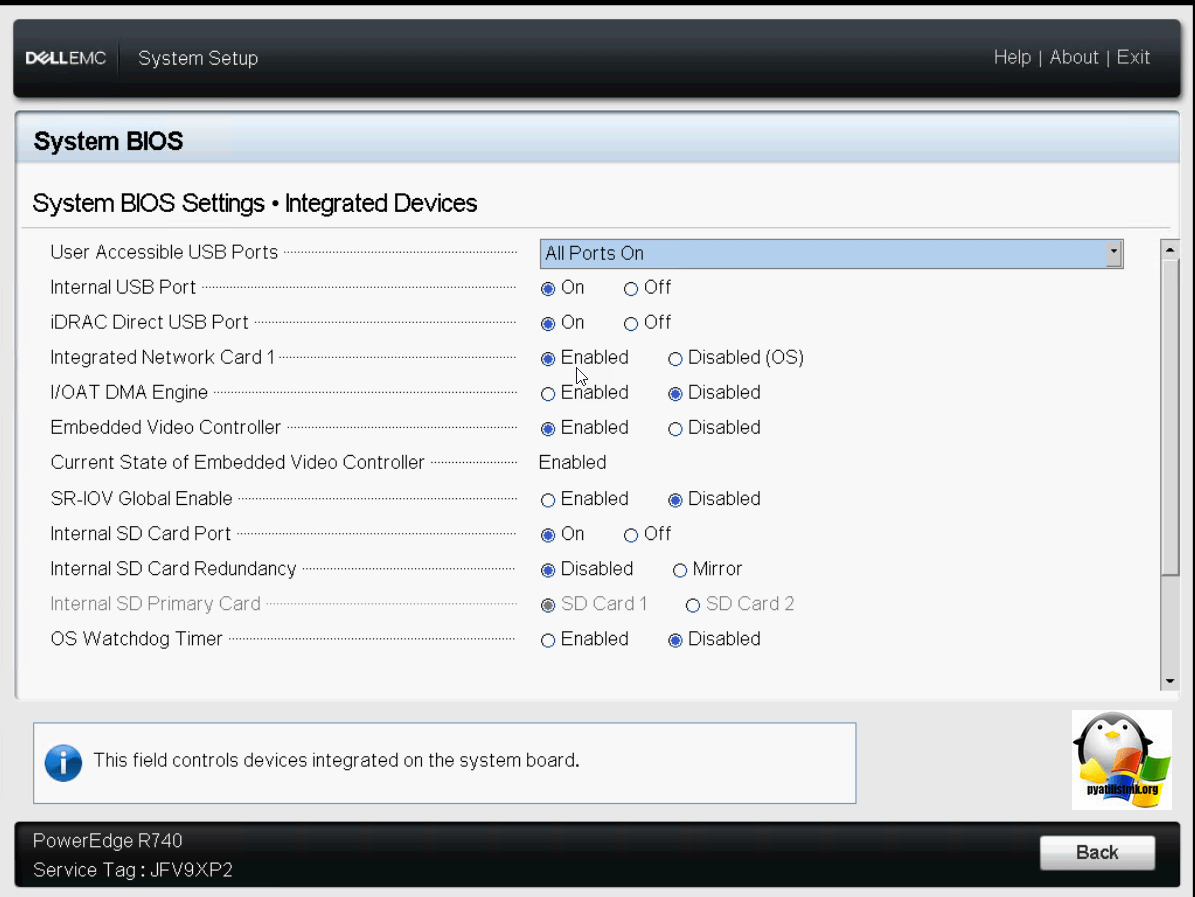
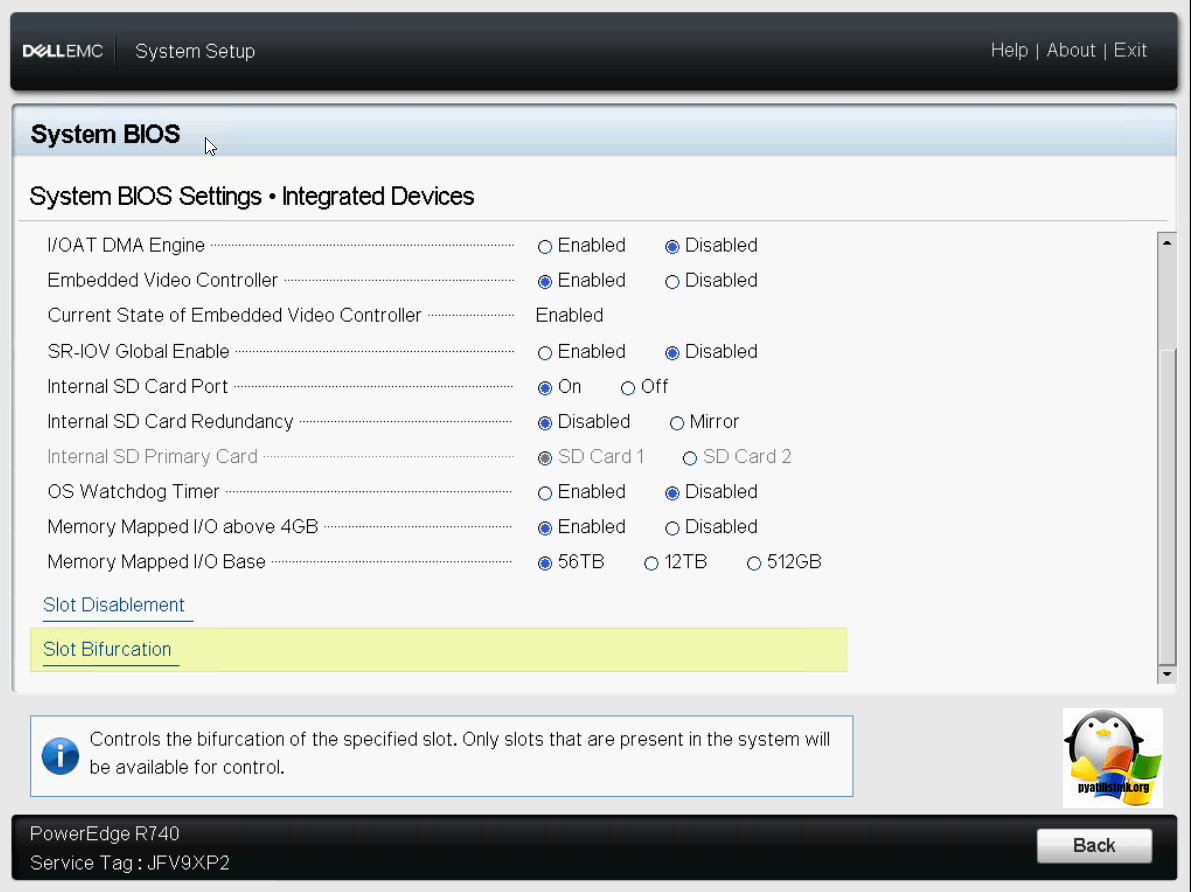
Обзор Serial Communication на Dell PowerEdge R740
В данном разделе вы сможете настроить передачу данных, через COM порт, который можно использовать, если по каким-то причинам у вас не работают основные механизмы доступа к серверу Dell PowerEdge R740.

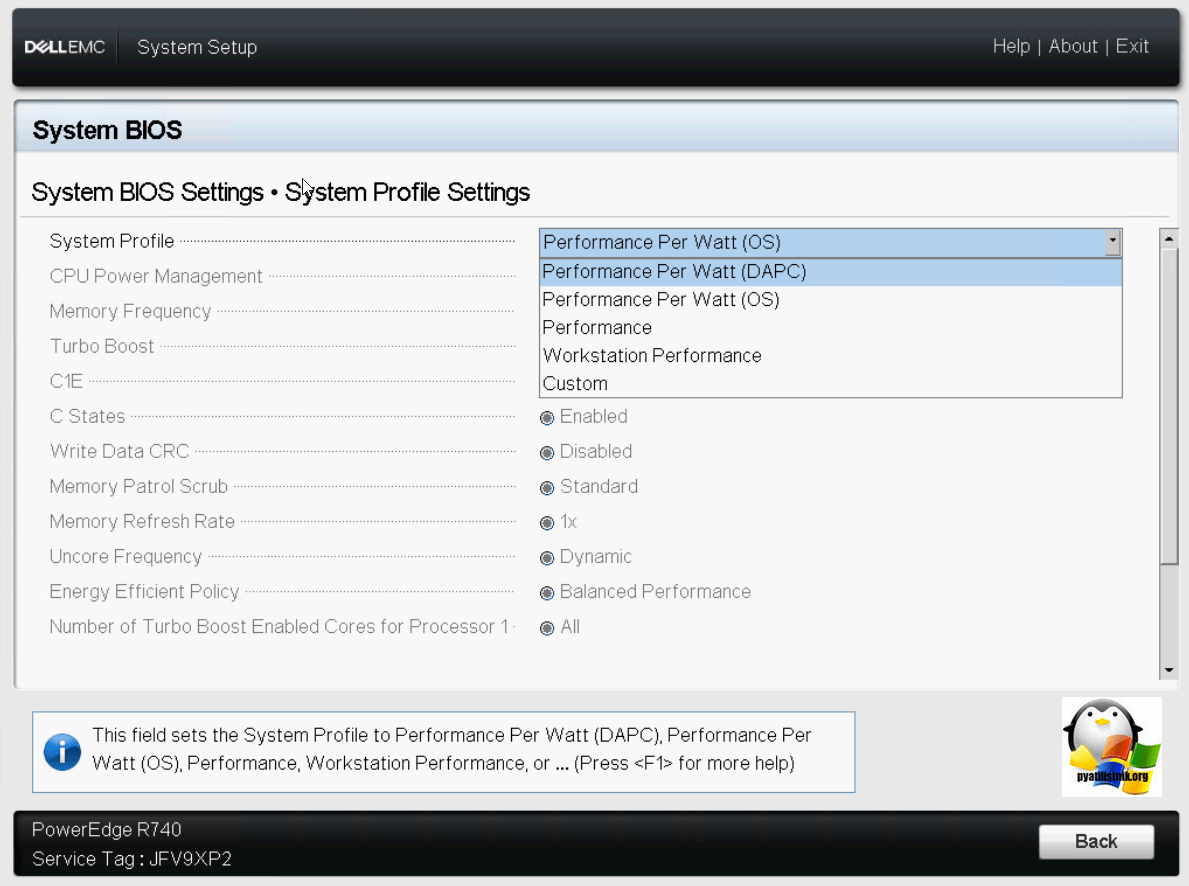
Обзор System Profile Settings на Dell PowerEdge R740
Теперь посмотрим на сервере Dell системные настройки профиля.
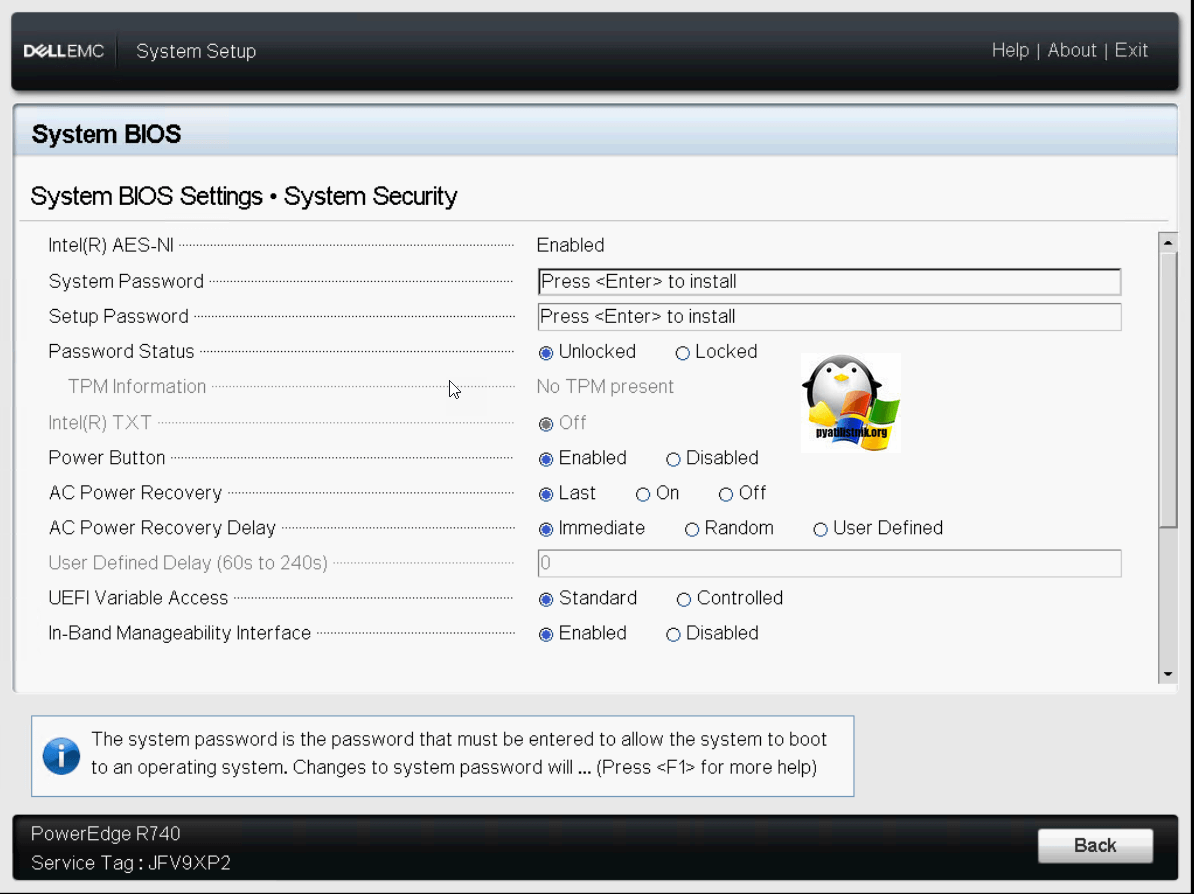
Настройка System Security на Dell PowerEdge R740
Далее переходим к настройкам безопасности. Для этого есть пункт «System Security».
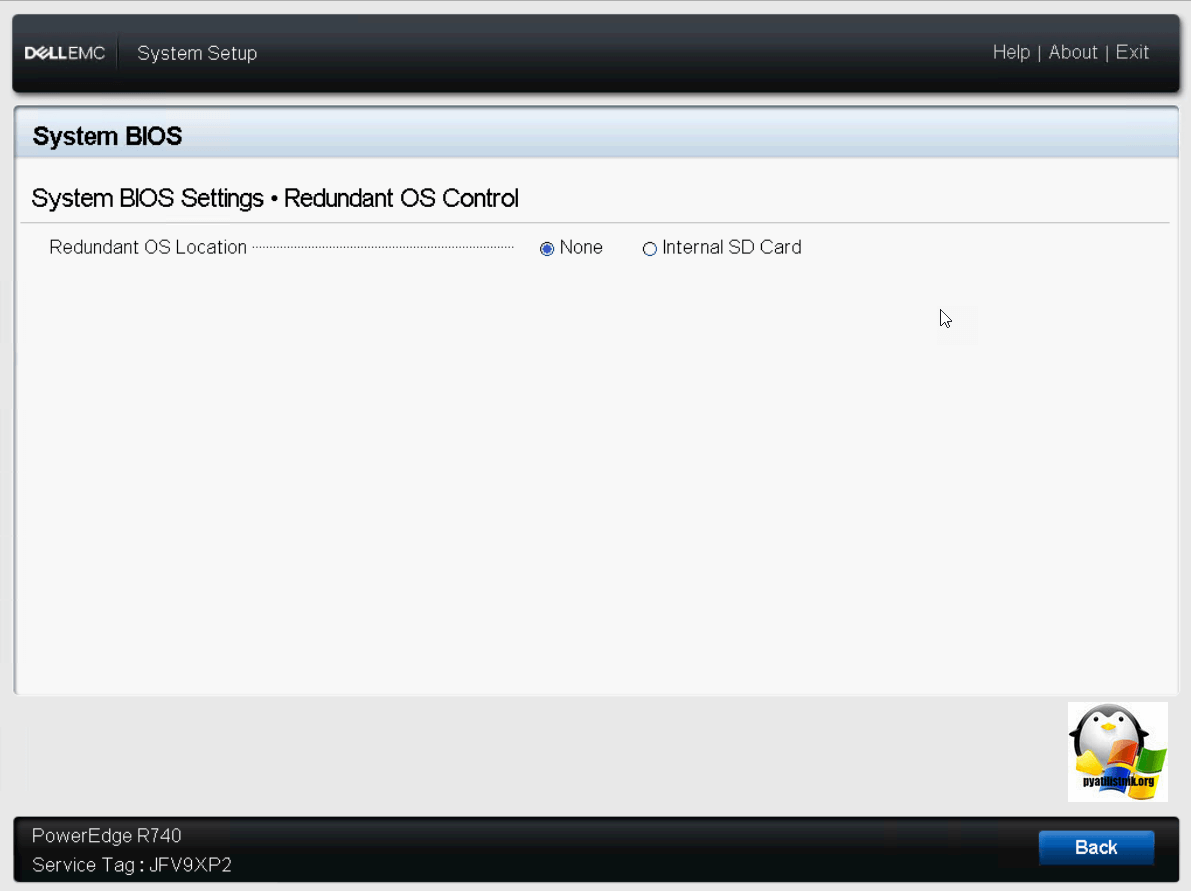
Настройка Miscellaneous Settings на Dell PowerEdge R740
Давайте посетив, другие, разные настройки (Miscellaneous Settings):
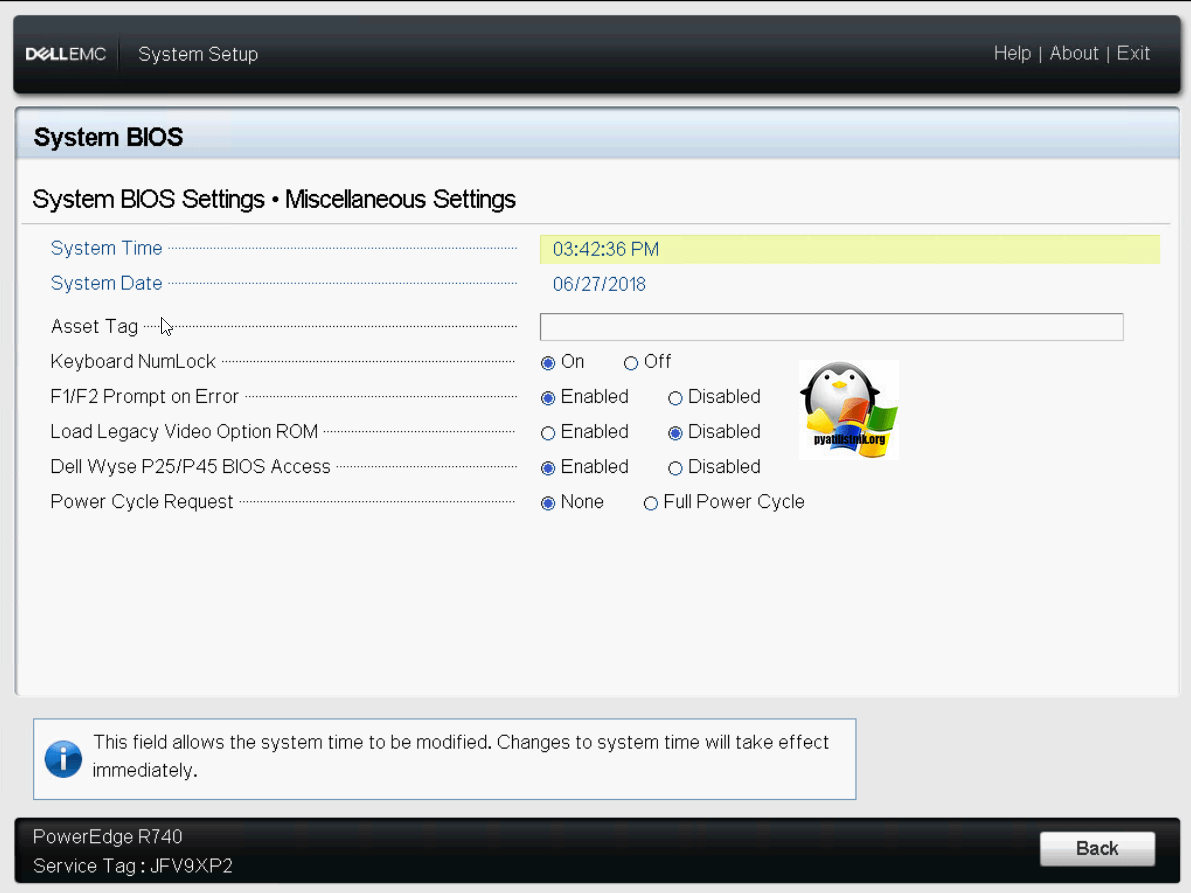
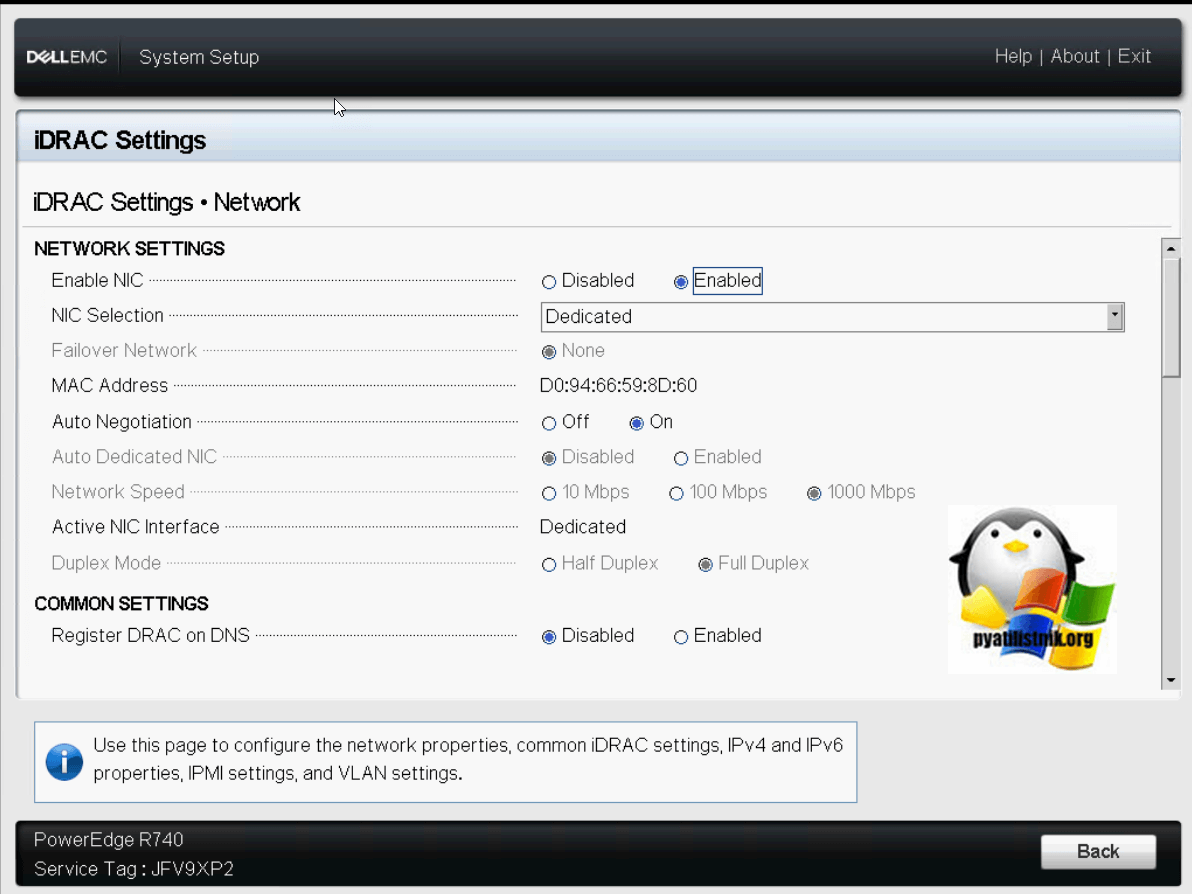
Обзор и настройка порта управления IDRAC Settings
Про порты управления серверами я уже рассказывал, о всех разновидностях, советую почитать. Переходим в пункт IDRAC Settings.
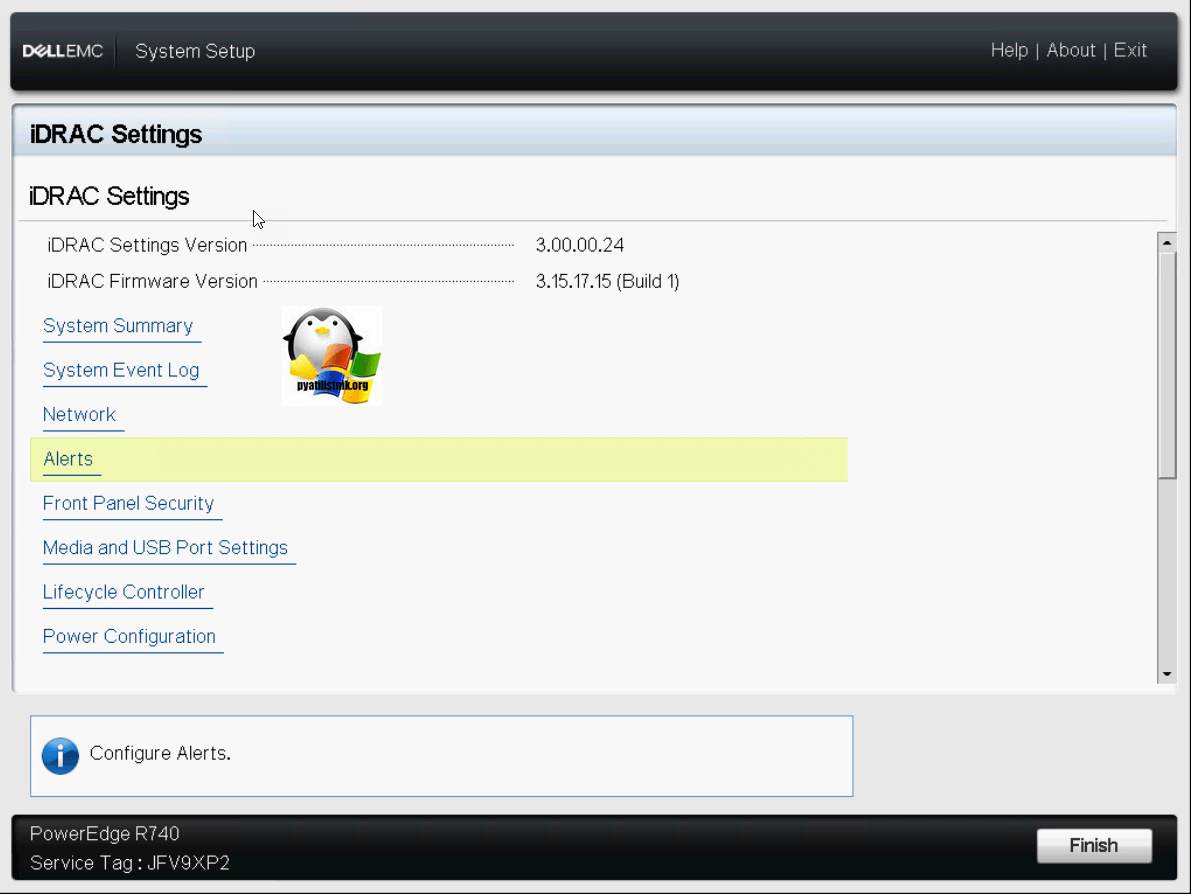
Заходим в System Summary, в данном разделе будет сводная информация:
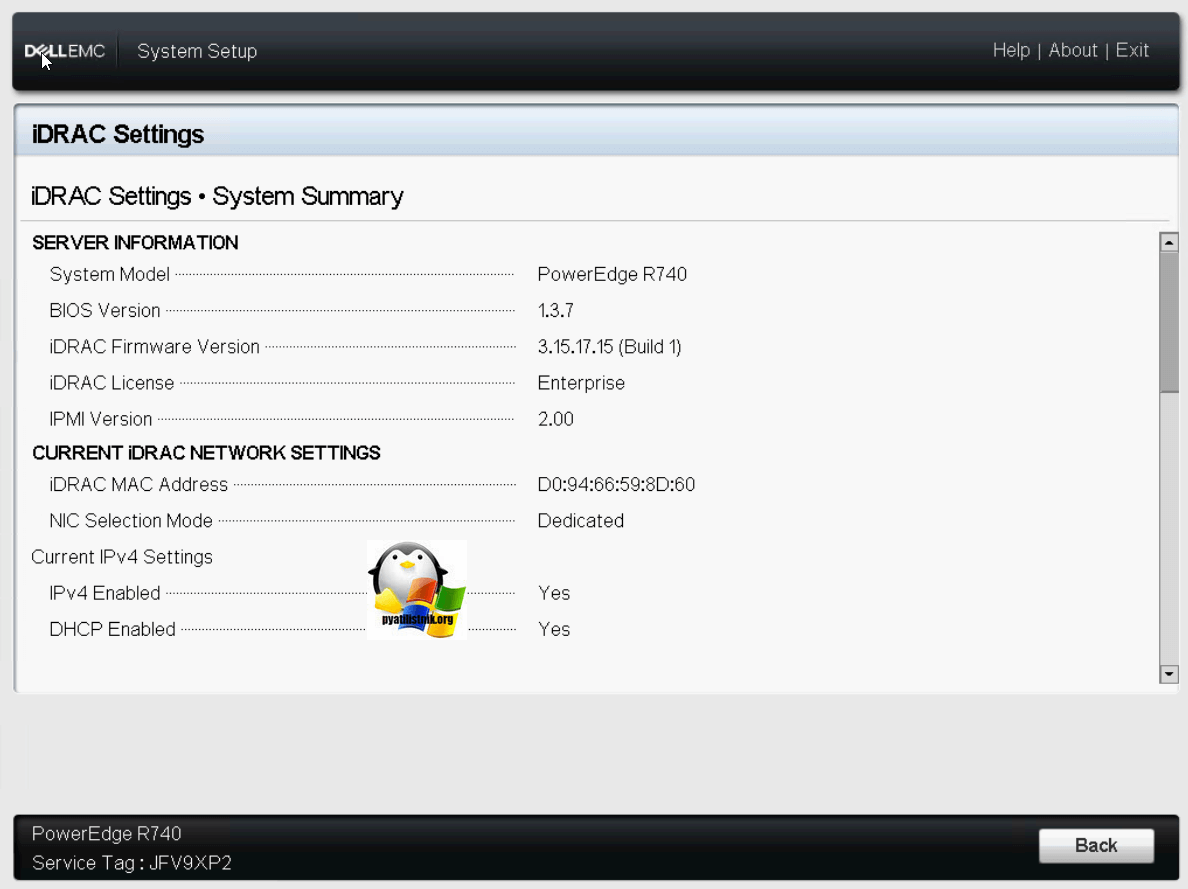
Видим полученный ip адрес, маску сети и шлюз.
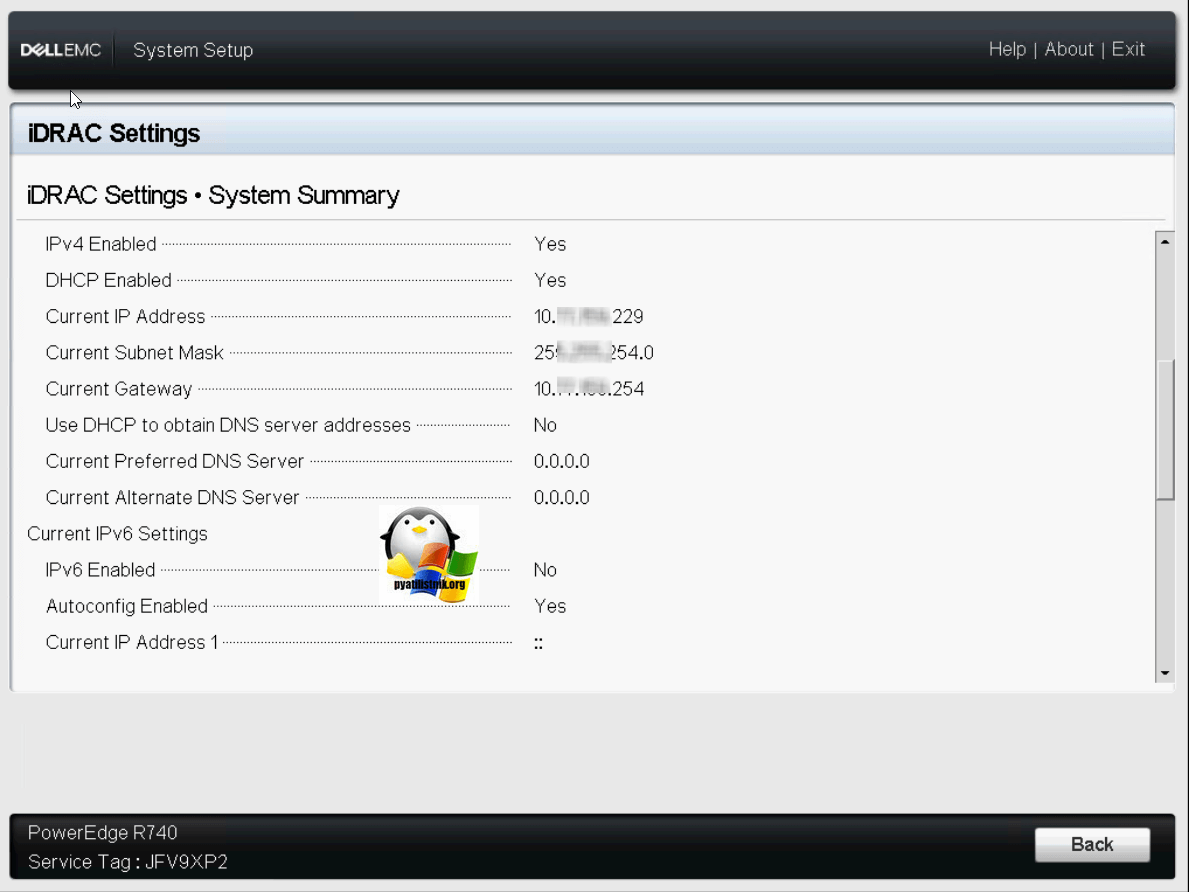
Пролистав ниже, вы можете отключить автоматическое получение настроек сети и задать статические настройки.
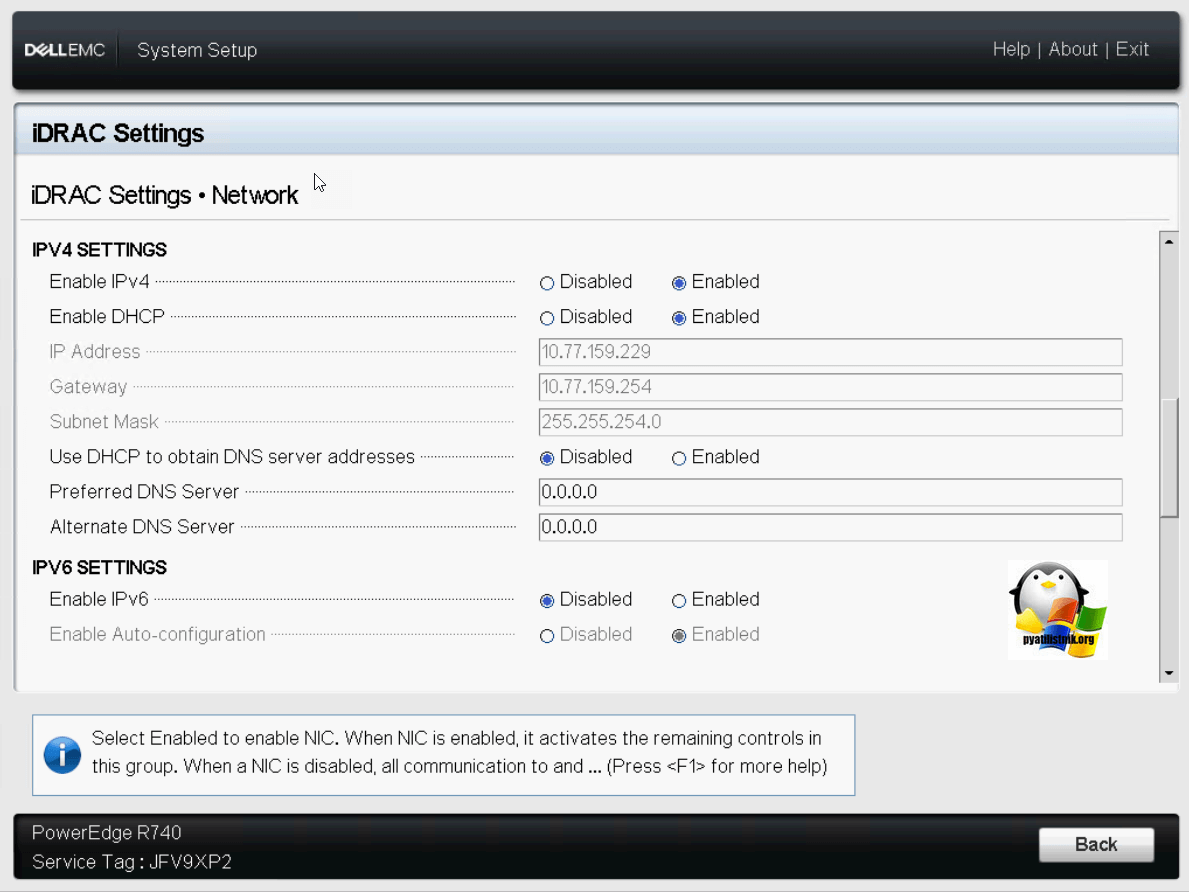
В самом низу вы обнаружите настройки IPMI. Тут вы можете включить IPMI Over LAN, то бишь по верх обычного сетевого интерфейса. Задать настройки VLAN ID.
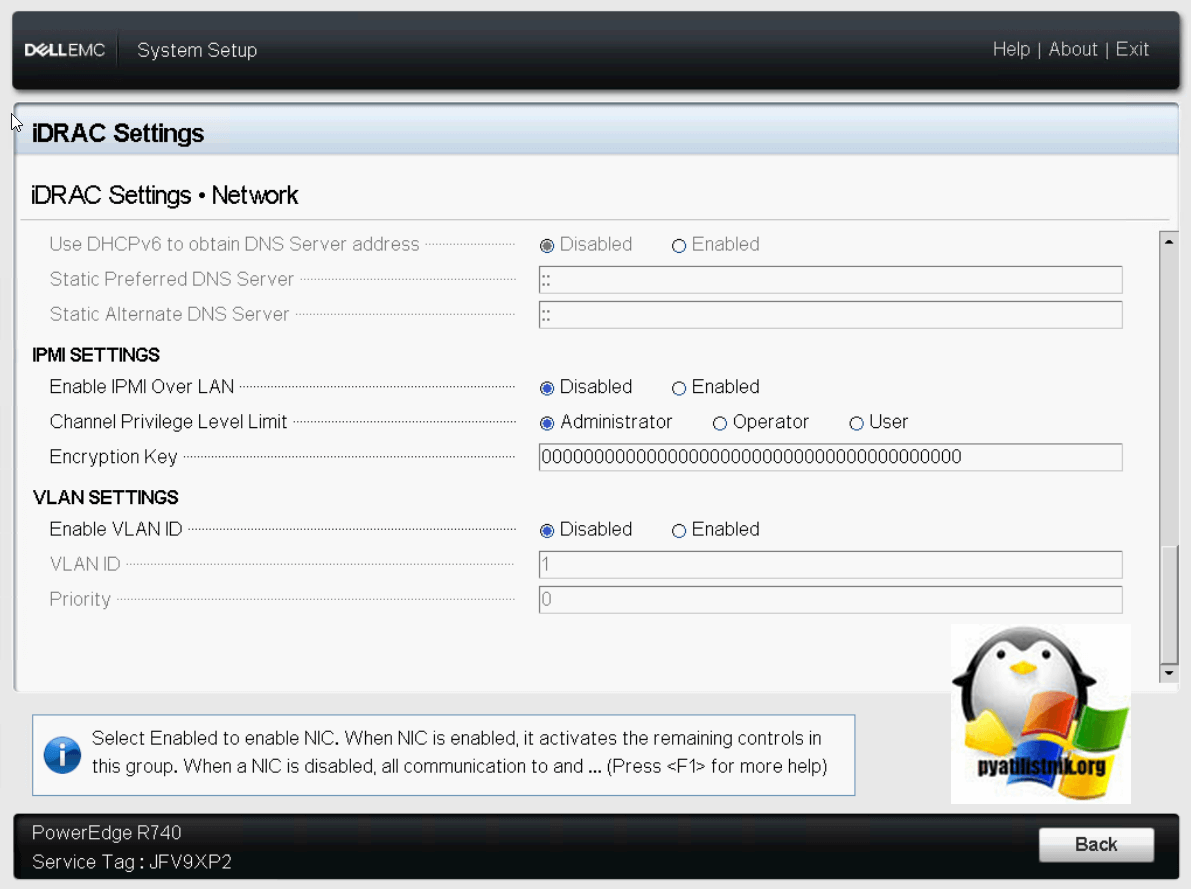
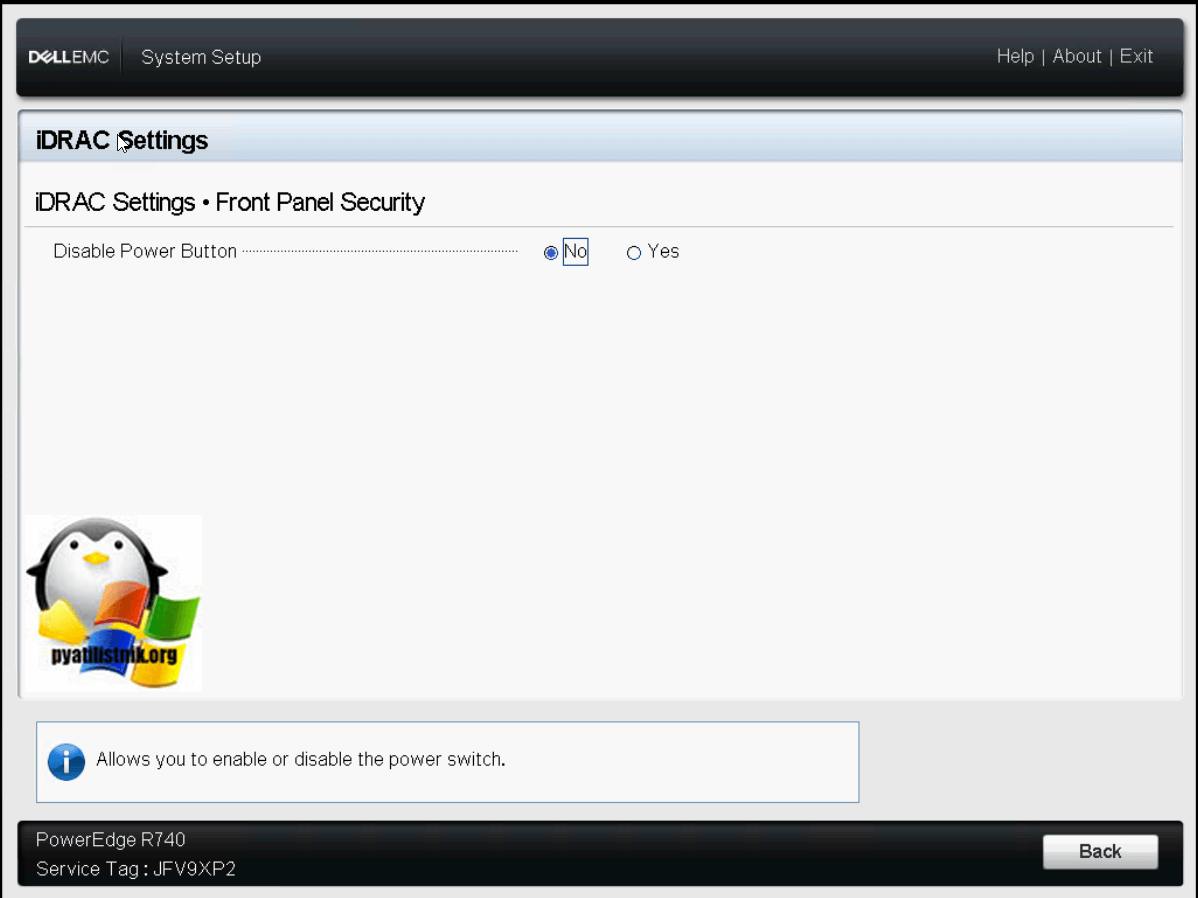
В пункте «Front Panel Security» вы можете задать настройку, которая может отключить на передней панели кнопку включения сервера. Делают это специально, чтобы избежать случаев случайного ее нажатия.
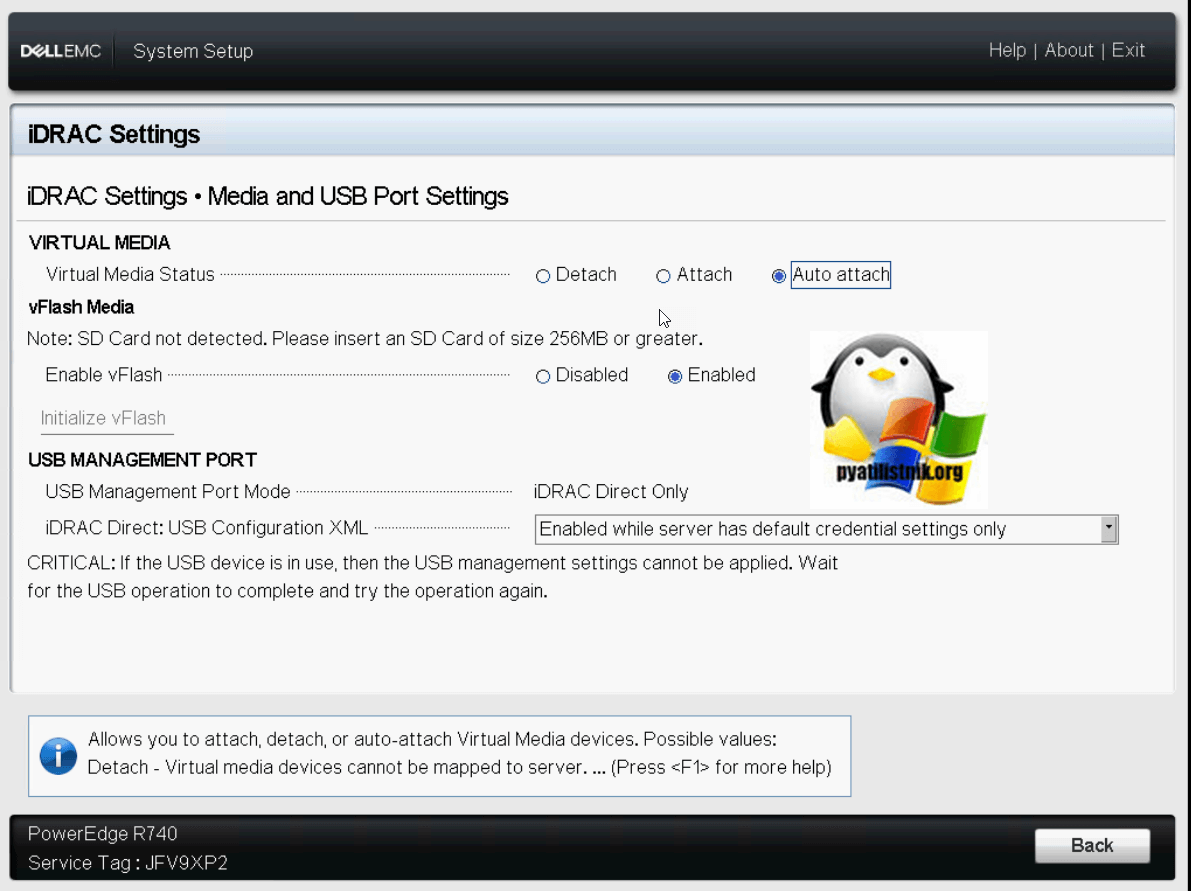
Выходим из данного меню и переходим в «Media and USB Port Settings», тут вы можете указать, будет ли активна встроенная карта памяти «Enable vFlash», на нее обычно ставят операционную систему, например, Vmware ESXI 6.5.
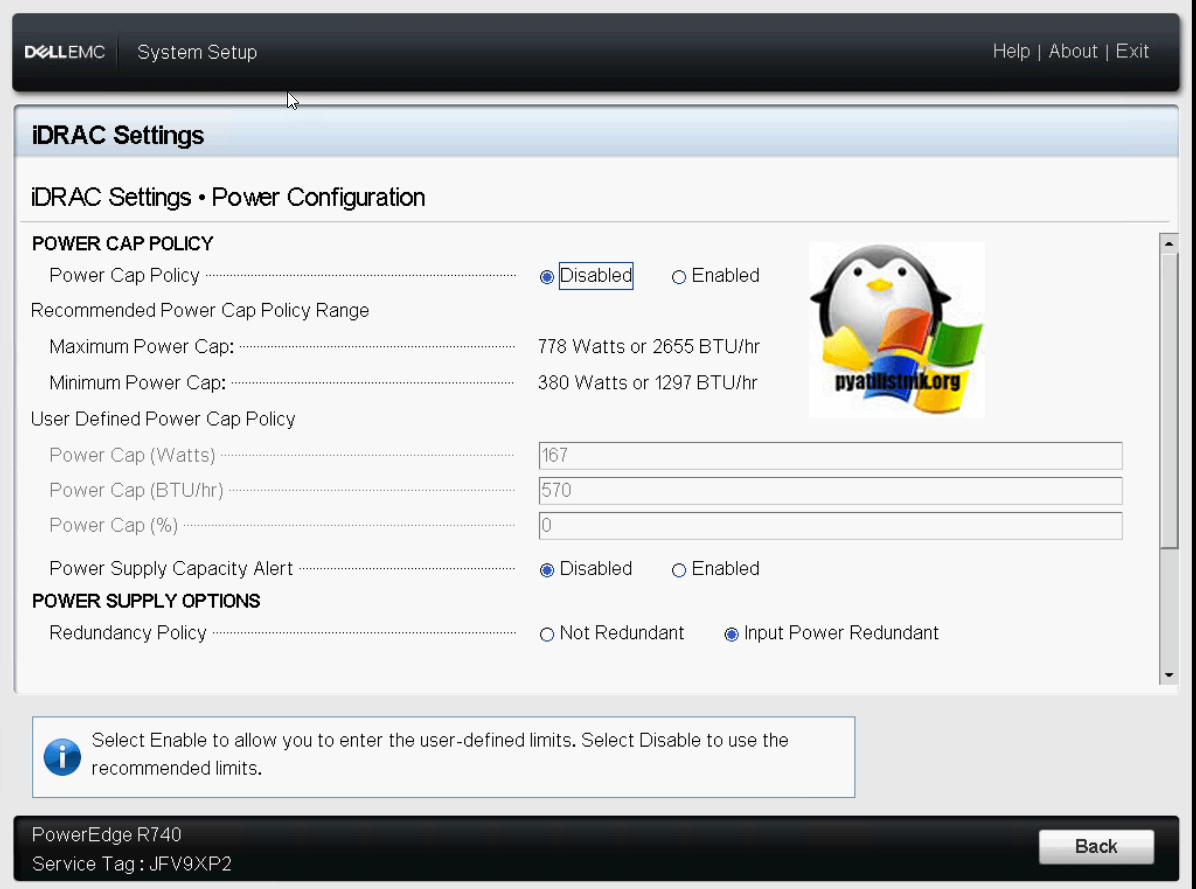
Переходим в настройки «Power Settings».
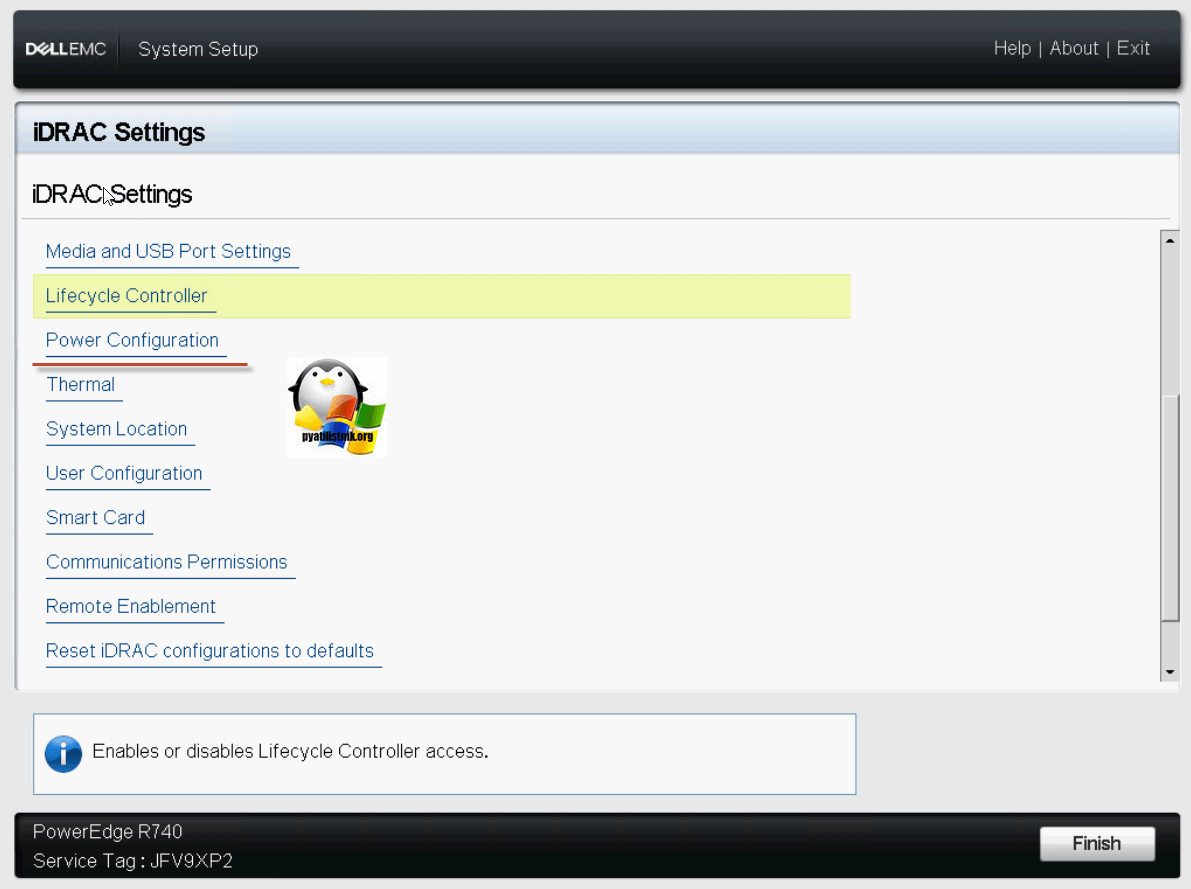
Тут вы можете задать политику ограничения питания «Power Cap Policy»
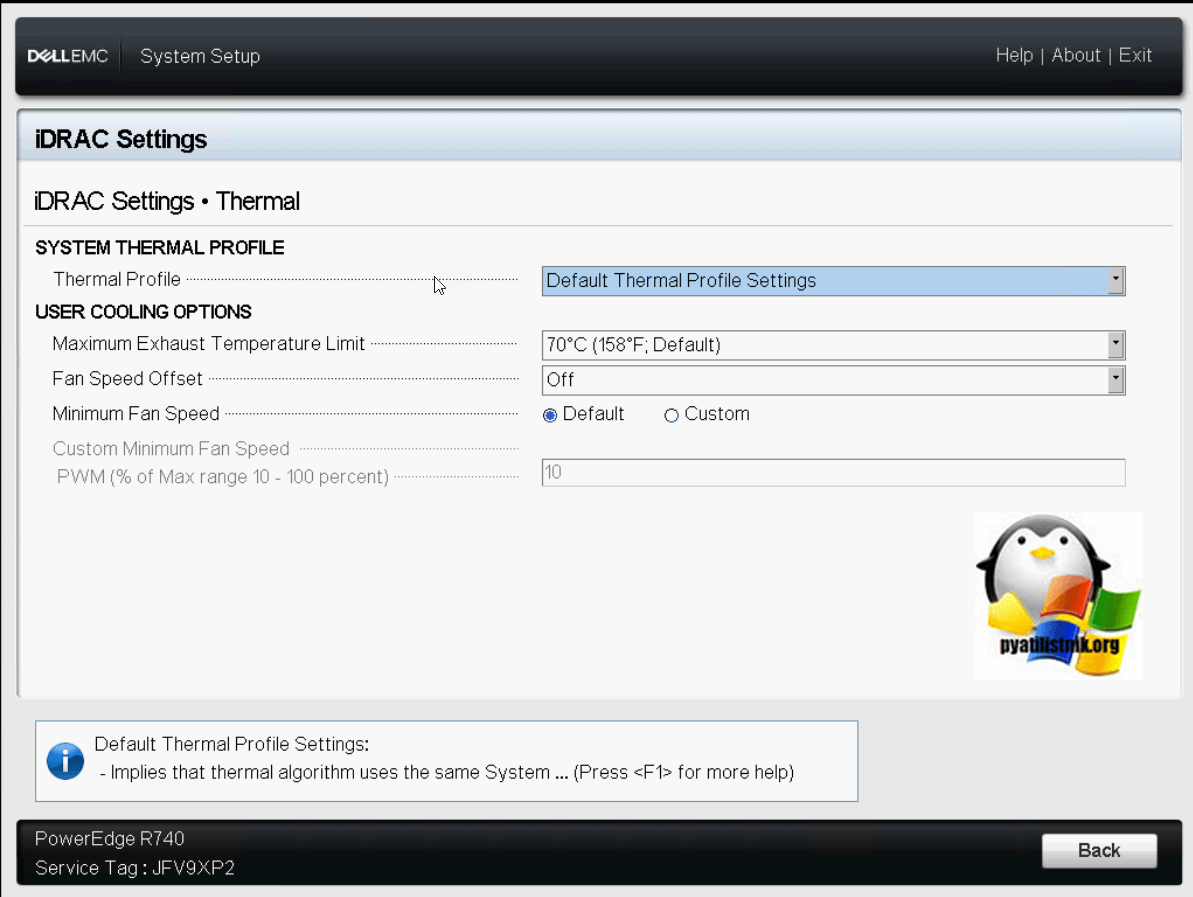
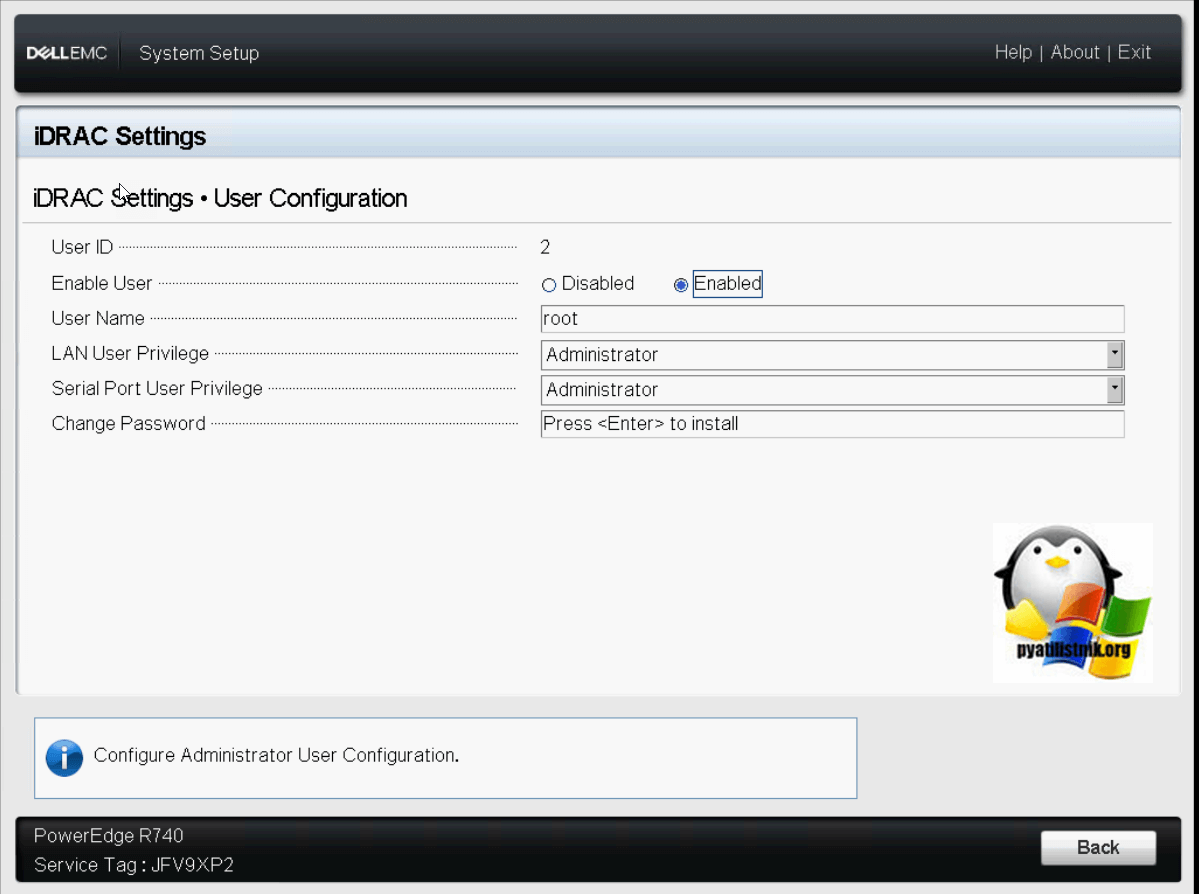
Выходим из Thermal» и переходим в настройки «User Configuration». Тут вы можете изменить логин root и его пароль.
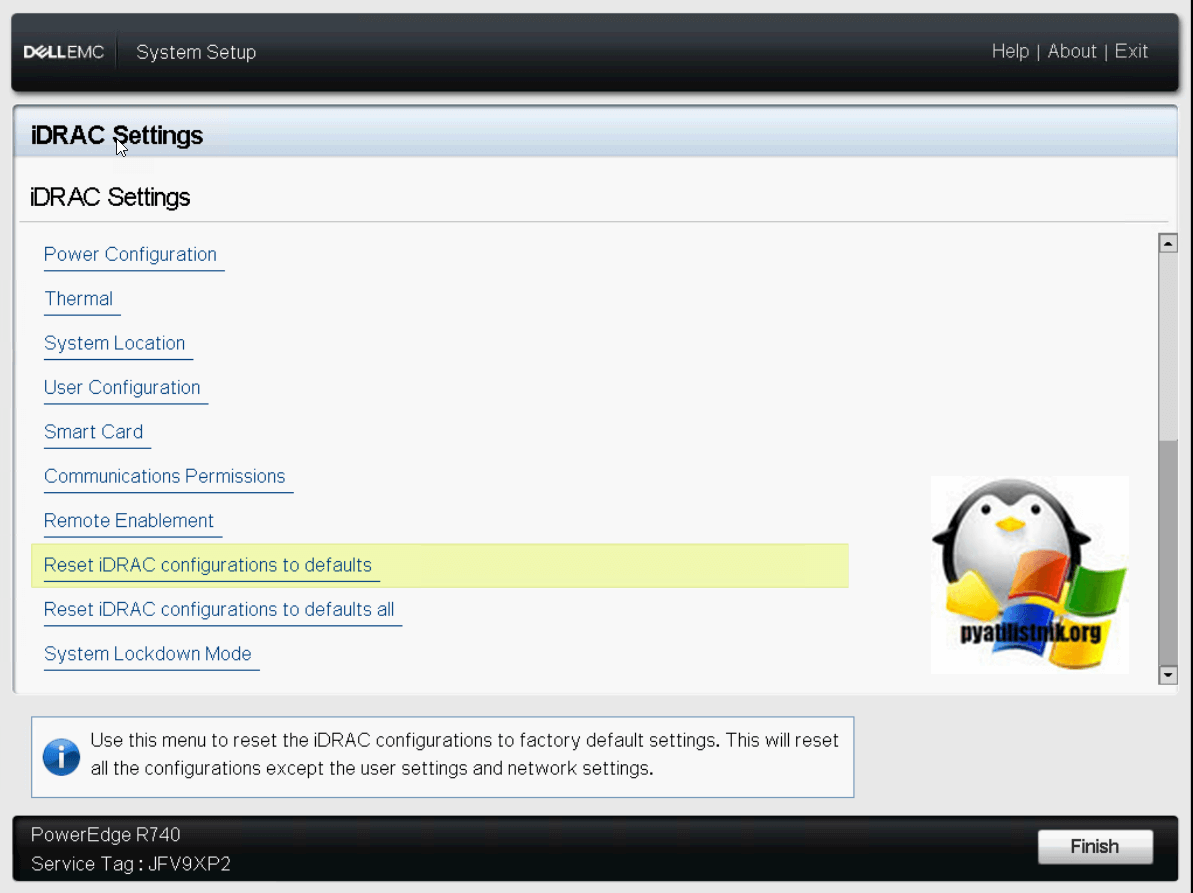
В данном случае будут сброшены только сетевые настройки.
Обзор настроек PERC H330 Adapter
Configuration Utility будет иметь вот такие пункты меню:
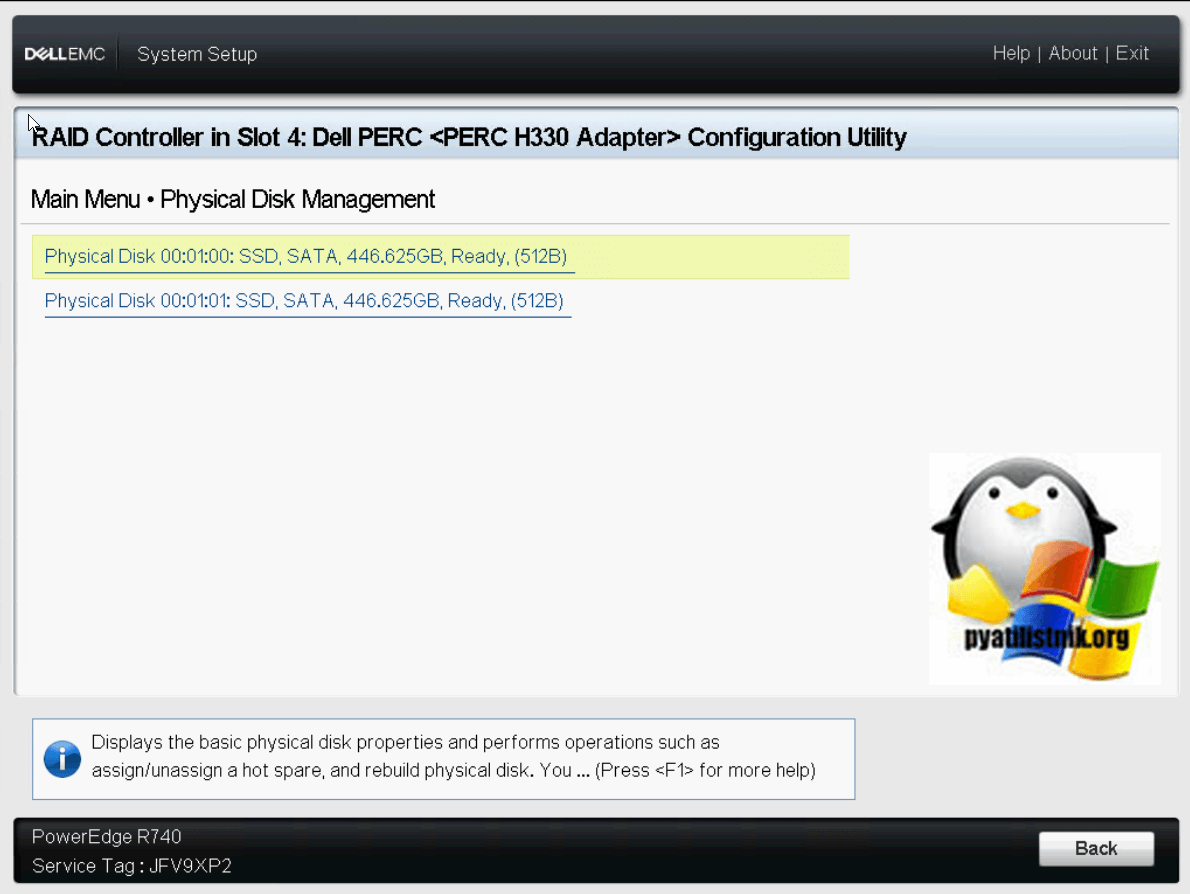
Пункт «Physical Disk Management» будет содержать список подключенных дисков и SSD.
Пункт «Controller Management» даст вам подробную информацию, о всех версиях прошивок и пакетов на PERC H330 Adapter и режиме его работы.
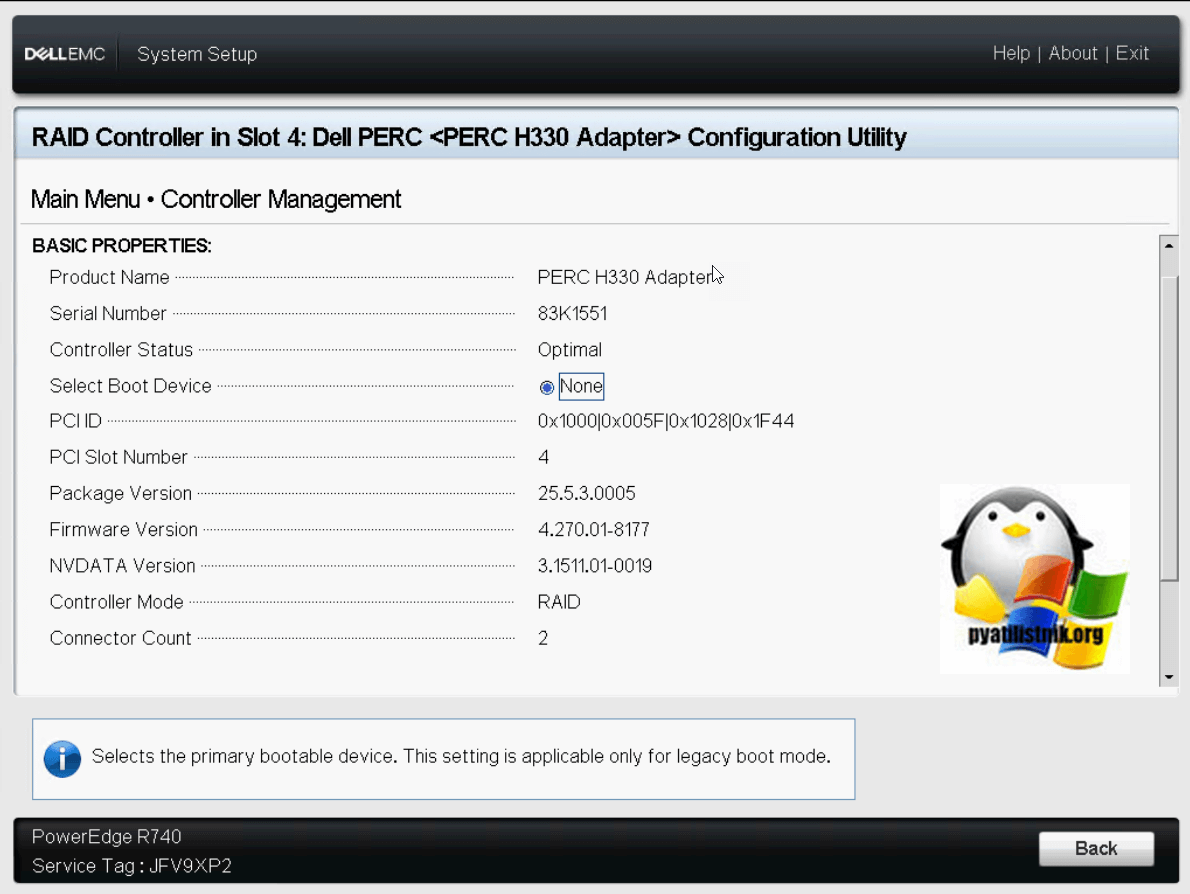
Чуть ниже вы сможете обнаружить пункты настроек:
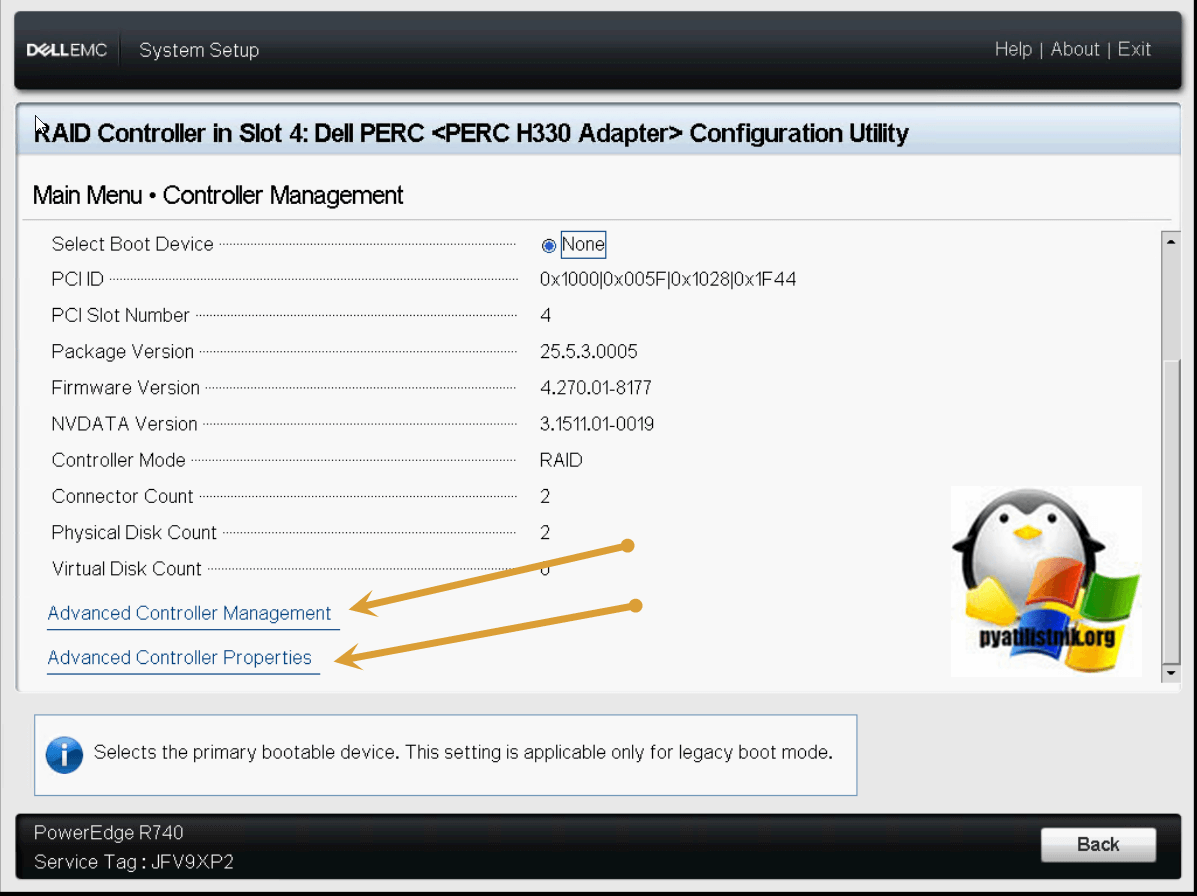
Открываем «Advanced Controller Management», тут будут пункты:
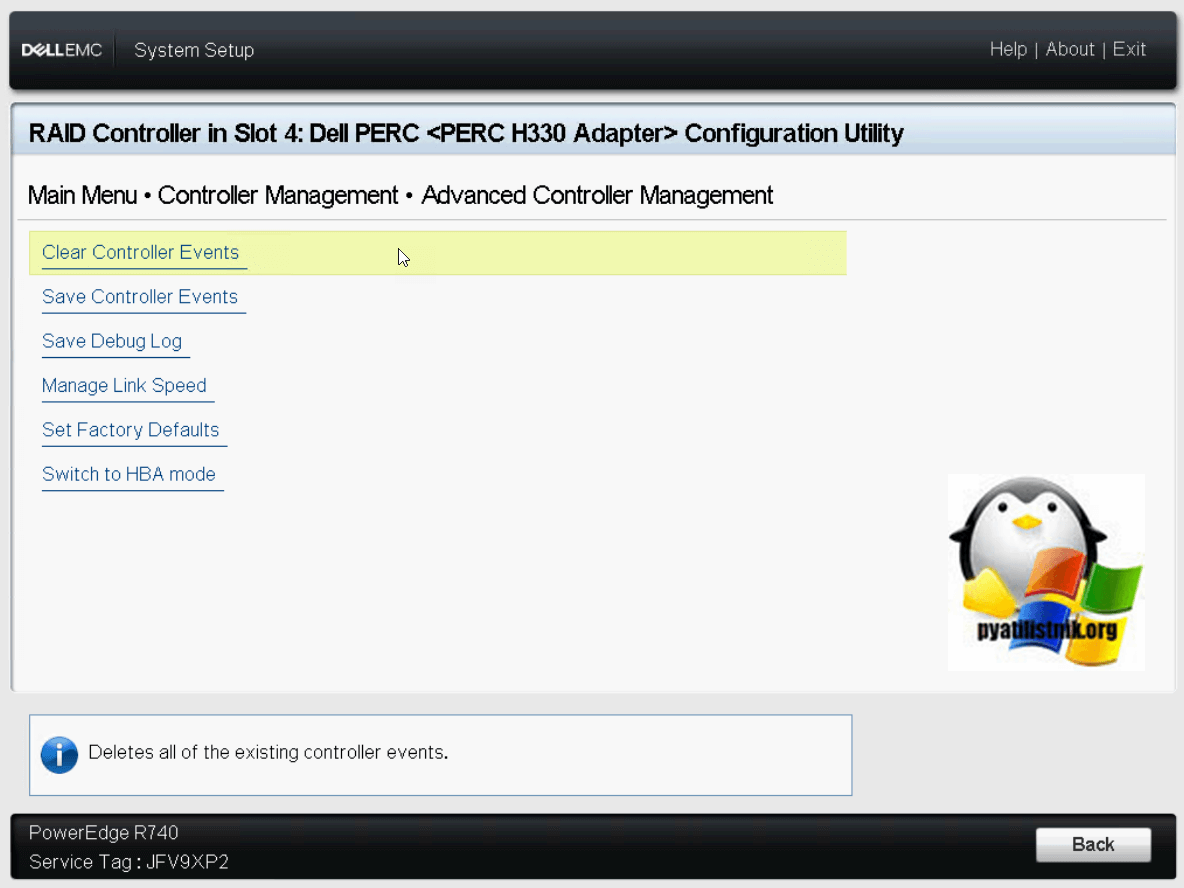
В «Manage Link Speed» вы можете выбрать нужную скорость
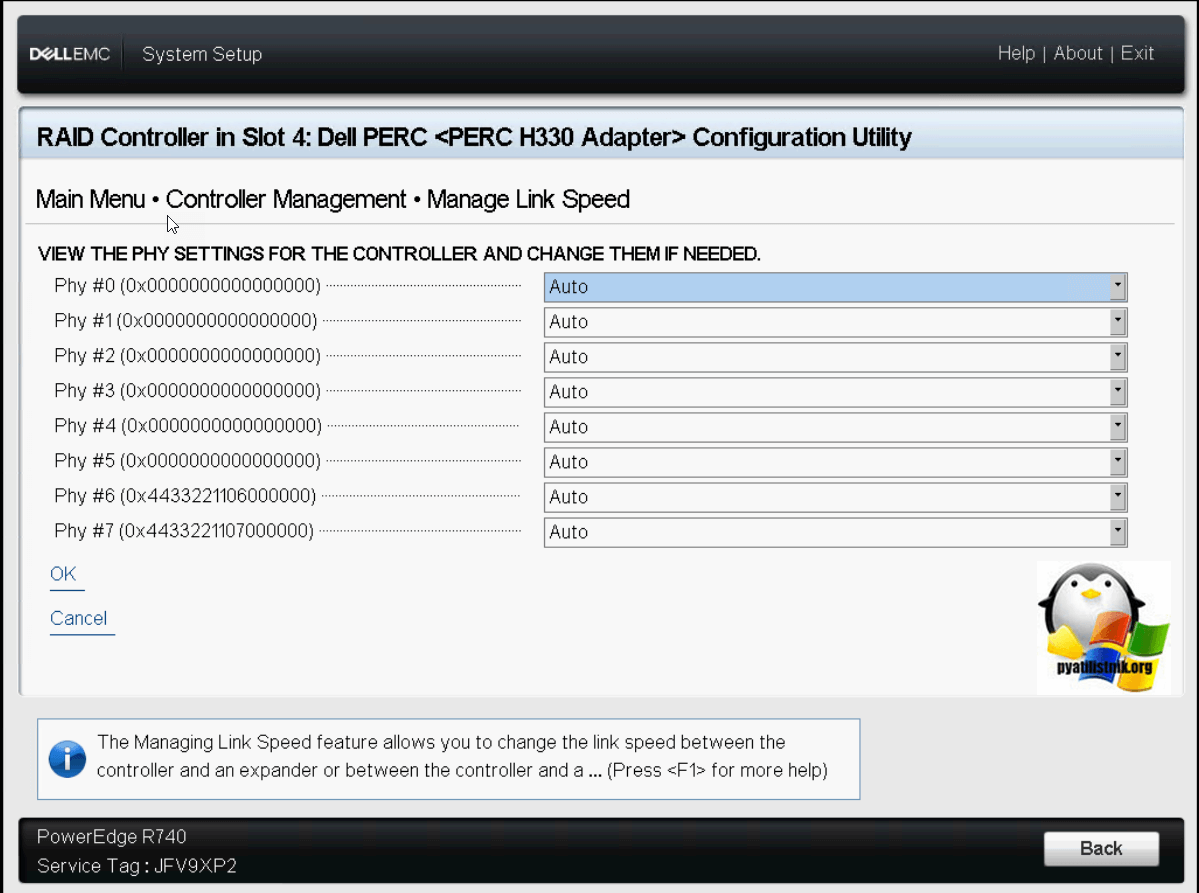
Если нужно будет сделать сброс настроек на заводские, то заходим в соответствующий пункт и подтверждаем действие.
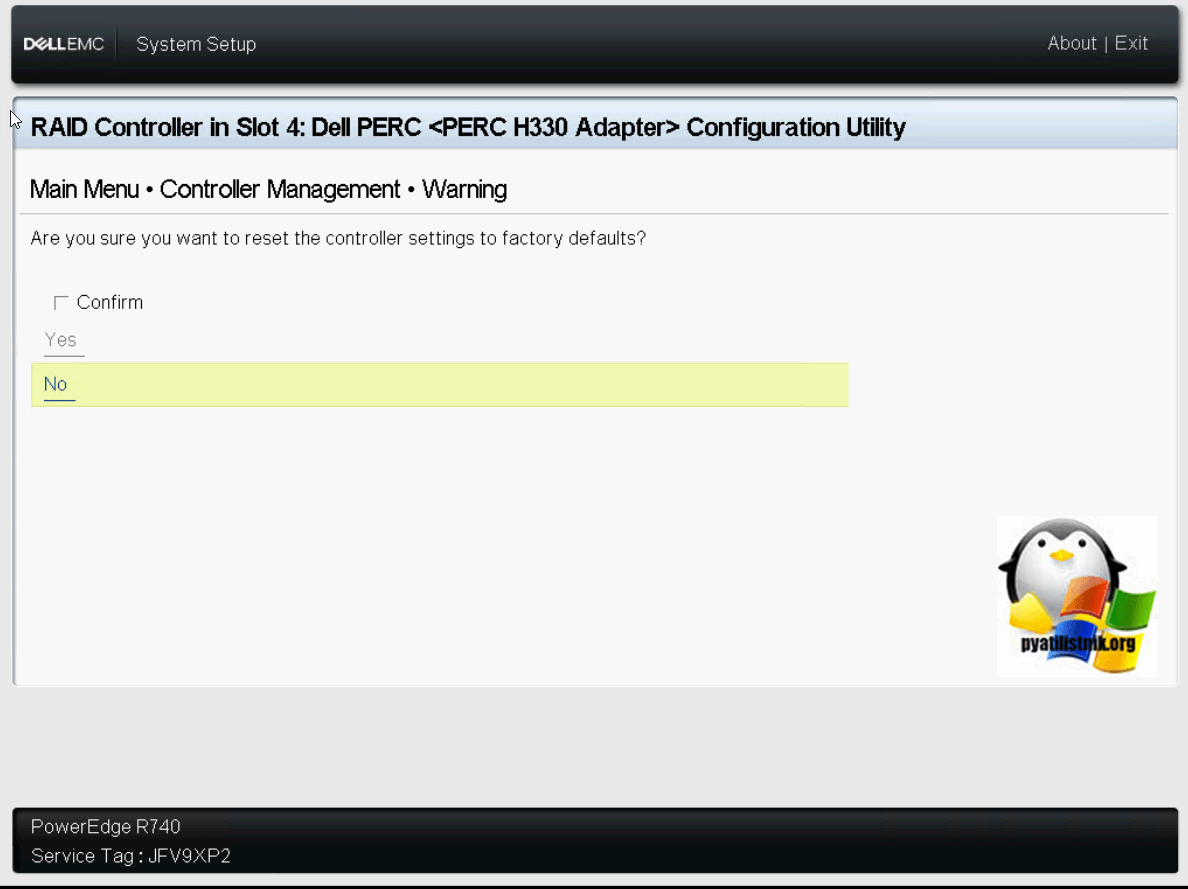
Пробежимся по дополнительным свойствам контроллера в пункте «Advanced Controller Properties». Тут можно управлять кэшем, импортировать предыдущие конфигурации «Import Foreign Configuration»
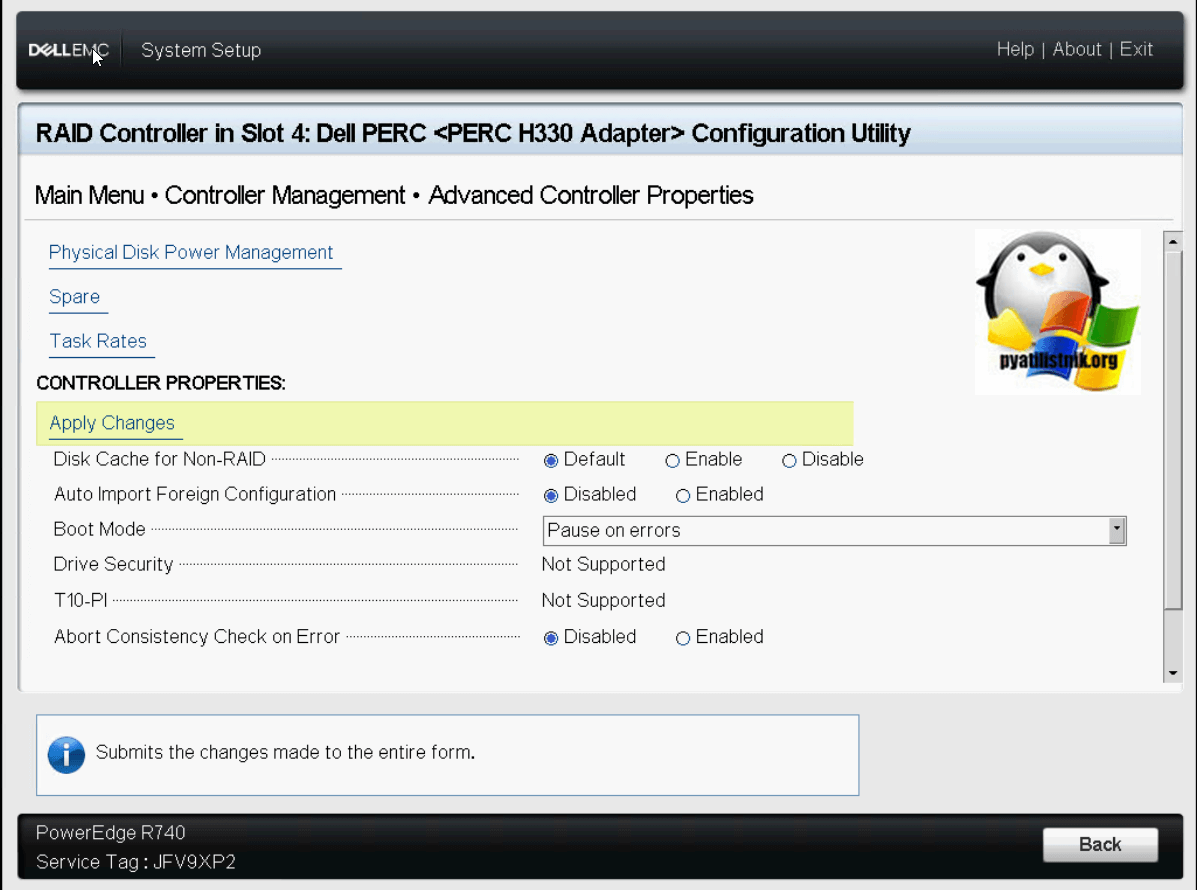
Посмотрим параметры пункта «Physical Disk Power Management». Тут можно включить функции горячей замены «Hot Spare», настроить балансировку питания.
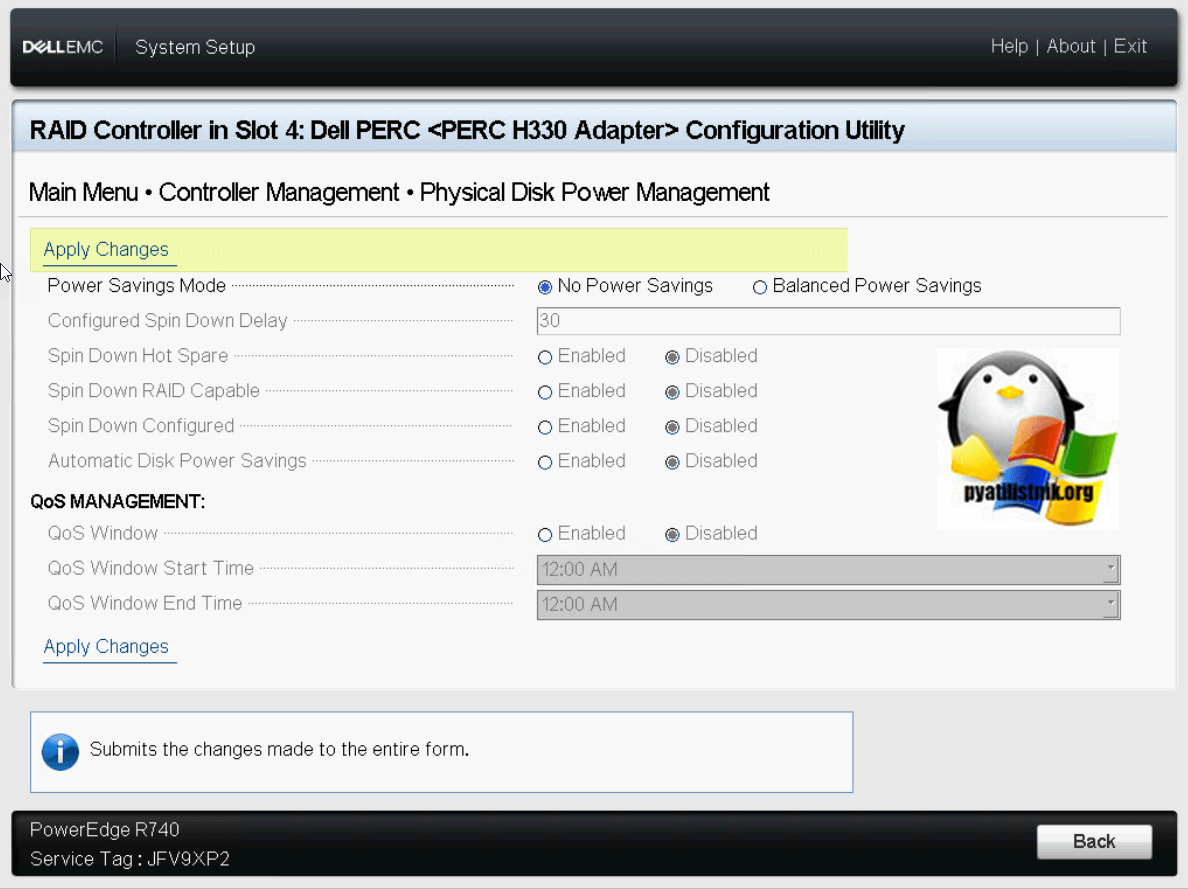
В меню «Spare» вы указываете поведение запасного диска в случае сбоя на RAID массиве.
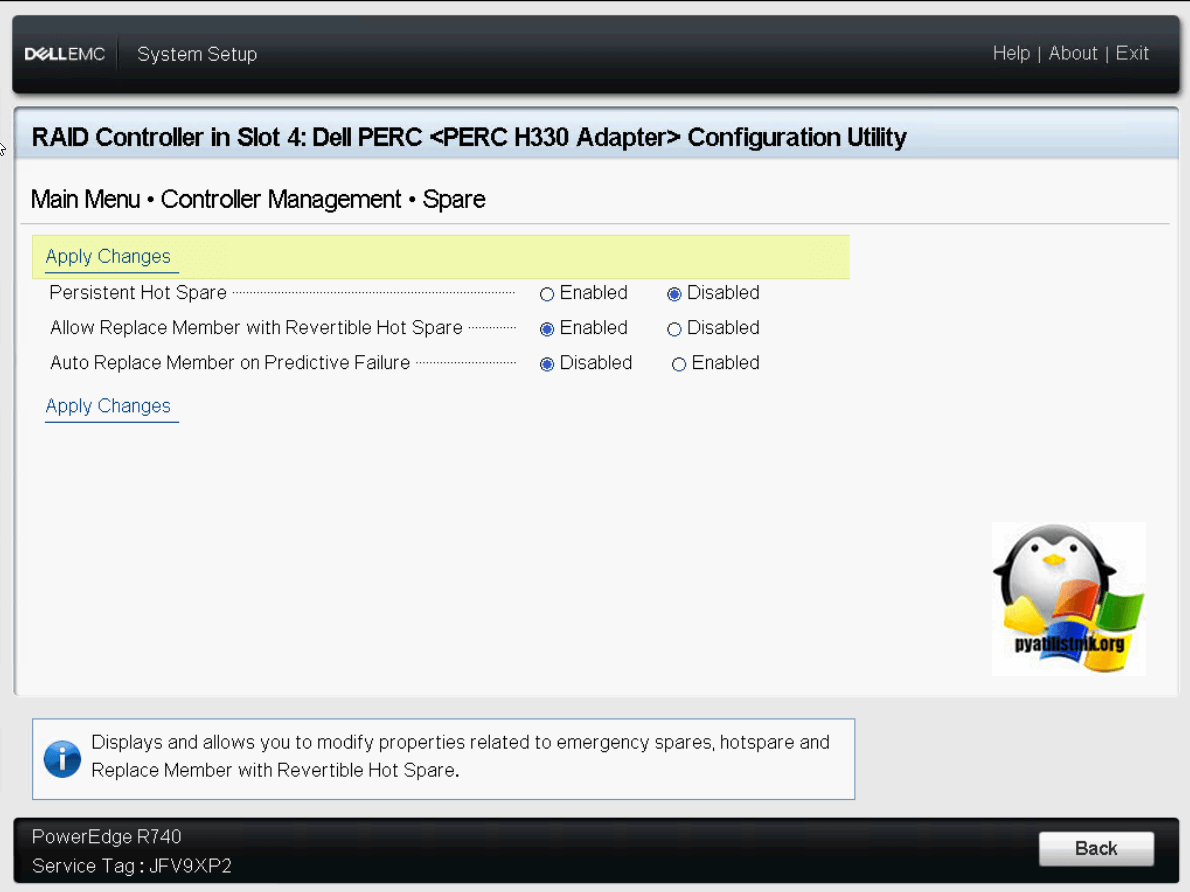
Ну и настройки производительности дисков при перестройке spare диска в RAID массиве.
Ceph: Настройка scrub и снижение его влияния на производительность
Обычно не пишу о том, что и так известно почти всем или если это хорошо освещено. Но недавно в одном популярном русскоязычном telegram-чате посвященном Ceph обсуждалась проблема scrubbing’а и я понял, что все таки знаю кое что, что еще не известно всем) Решил написать заметку посвященную данной теме.
Scrub — служебный механизм призванный проверять целостность копий данных в кластере RADOS. Процесс scrubbing’а идет фоном и циклически перебирает все данные сравнивая одну копию данных на одной OSD с другой копией на другой(или других) OSD.
Проверок бывает два типа: простая(scrubbing) и глубокая(scrubbing+deep)
В рамках простой проверки сверяются только атрибуты фалов и их размер, этот тип проверки безобиден и практически ни оказывает никакого влияния на работу кластера и по этому проводится с частотой в сутки.
При глубокой проверке(scrubbing+deep) проверяемые данные считываются с дисков, считается их контрольная сума и сверяется. Собственно чтение данных и есть проблема. Такие проверки идут с интервалом в неделю.
Естественно проверки не запускаются разом на все данные. В таком случае все вставало бы колом) Разные PG проверяются в разное время. Этот процесс идет не прерывно, сейчас одни проверяются, затем другие а через время опять первые и так без конца.
Так вот когда в кластере появляется нормальное количество данных и они активно используются то вы заметите влияние scrubbing’а даже без мониторинга)
Под нормальным объемом данных я подразумеваю не какой то общий объем данных в кластере а заполненность используемых дисков. Например если у вас диски размером в 2Tb и они заполнены на 50-60 или более процентов то у вас много данных в Ceph, даже если дисков всего шесть). Это моя субъективная метрика но по моему 3-х летнему опыту работы с Ceph в проде — это самый важный критерий.
Собственно когда наши диски достигли такой утилизации мы стали замечать просадки производительности и повышенные задержки во время идущего scrubbing’а. Возможно если бы у нас были SSD мы жили бы счастливо но у нас обычные SATA диски с журналами на SSD.
Так вот, scrubbing. Когда во время идущего скраббинга приходит пользовательская нагрузка на те же OSD что в процессе скраббирга, не заметить это сложно, особенно если у вас есть внешний мониторинг.
Изменение расписания scrubbing’а
Первое что можно сделать это задать расписание для scrubbing’а, отведя для него время где нибудь ночью, например с 00.00-08.00.
Задать в рантайме(без рестарта OSD):
Это сразу изменит ситуацию к лучшему но не надолго. Опять же если у вас много данных то они просто не будут успевать проходить scarbbing в отведенное время. Если какие то PG не успеют пройти scrubbing за 7 дней то он будет запущен принудительно в любое время. Так мы увидели идущий скраббинг в дневное время). Увеличивать установленное время без скраббинга нельзя т.к. он очень важен для сохранности данных. Так мы кстати еще раз получили подтверждение, что у нас много данных.
Раз скраббинг все же идет в итоге в дневное время и мешает нормальной работе сервиса то ничего не остается как искать пусти его ограничения.
Снижение приоритета с помощью CFQ
Необходимо сменить планировщик у всех OSD-дисков на CFQ:
и установить следующие параметры для всех OSD:
Задать в рантайме(без рестарта OSD):
Этот подход используют очень многие и кому то он помогает. Нам он не помог практически ни как. Мы довольно долго его тестировали но периодические просадки производительности и взлет летенси никуда не делись.
Уменьшение порции данных одного scrubbing’а
Это то ради чего написана эта заметка. Я нигде не видел статей или обсуждений на эту тему, но это то что избавило нас от проблем связанных со скраббингом.
Суть в том, что бы позволить scrubbing’у идти круглые сутки но читать данные очень мелкими порциями максимально снижая нагрузку на OSD в момент времени.
Задать в рантайме(без рестарта OSD):
При использовании этого подхода, на мой взгляд лучше сменить планировщик на deadline.
Данный подход представлен в этой статье как один из вариантов и возможно для вас окажется не таким эффективным как для нас. В общем попробуйте и решите сами.
Эксплуатация Ceph: что такое Scrub и как им управлять

Scrub — это процесс фоновой проверки консистентности данных в Ceph. Он позволяет выявить и устранить несоответствия в копиях, а также найти рассыпающиеся диски, чтобы вовремя их заменить. При этом сам Scrub может создавать высокую нагрузку на кластер и мешать другим процессам. Сегодня расскажем о настройках, которые помогут оптимизировать его работу и сделать нагрузку практически незаметной.
Статья подготовлена на основе лекции Александра Руденко, ведущего инженера в группе разработки «Облака КРОК». Лекция доступна в рамках курса по Ceph в «Слёрме».
Как работает Scrub
Scrub или scrubbing — это специальный фоновый процесс, который проверяет консистентность данных в placement group. Например, есть пул с тройной репликацией, то есть одна placement group в нём имеет три копии. Данные в этих копиях должны быть полностью идентичны, что и проверяет Scrub.
Если Scrub обнаруживает расхождения (например, в какой-то placement group объект имеет контрольную сумму не такую, как на двух других, либо вообще отсутствует), то возникает ошибка, администратор о ней узнаёт и может исправить.
В Erasure coded pool нет копий, но принцип тот же: Scrub выявляет расхождения в данных, неконсистентность, возникшую по тем или иным причинам. Одна из основных причин — «тихие» повреждения магнитных дисков. Вчера вы записали данные, а сегодня некоторые секторы на диске посыпались и данные оказались повреждены.
Scrub бывает двух типов: обычный и глубокий.
В примере на скриншоте четыре placement groups находятся в состоянии scrubbing, и они же находятся в состоянии scrubbing+deep. «Deep» — это значит глубокий Scrub.

Сначала всегда выполняется обычный Scrub, и только если он завершился успешно, запускается глубокий.
Обычный Scrub проверяет атрибуты и размер объектов. Он проходит быстро и незаметно с точки зрения нагрузки.
Глубокий Scrub читает практически каждый байтик объектов и сверяет их на всех OSD в рамках проверки одной placement group. То есть все данные читаются, проверяются их контрольные суммы и контрольные суммы сверяются. Это достаточно затратный по ресурсам процесс. Он может затрагивать несколько placement group сразу. В примере выше параллельно проверяются данные четырёх placement groups.
Максимальная частота проверки одной placement group — раз в сутки, чаще Scrub не запускается. При этом у процесса есть дедлайн: одна placement group должна быть проверена в течение недели. То есть Scrub может проходить раз в сутки, но не реже раза в семь дней. Если placement group не проверялась больше семи дней, то возникает сообщение об ошибке.
Пример такого сообщения на скриншоте. Здесь показано, сколько placement group не успело пройти проверку в отведённые 7 дней.
Когда Scrub находит различие в данных в одной placement group, возникает такая ошибка:
Первая строчка показывает, что есть ошибки scrub error, и сколько их. Вторая строчка говорит, в скольки placement group обнаружена неконсистентность данных. Такие алерты может выдавать только Scrub. По-другому вы не узнаете, что placement group в неконсистентном состоянии.
Фактически алерт говорит: по какой-то причине данные некорректно записались на одну OSD и нужно запустить процесс repair — восстановление консистентности.
Мы считаем процесс Scrub очень важным ещё и потому, что он позволяет выявлять повреждения дисков.
Во время проверки данные placement group читаются целиком. То есть в течение 7 дней 100% данных кластера оказываются прочитаны и сверены на разных OSD. В результате мы получаем проверку состояния дисков: способны ли они отдавать данные, работает ли чтение с них.
Scrub читает данные, которые пользователь, возможно, не читал несколько месяцев и не будет читать ещё год. Если при чтении на диске возникает проблема (например, сектор магнитного диска отказал), то это провоцирует ошибку.
В логе ядра Linux мы видим ошибку типа input/output error. Ceph сообщает, что возникла ошибка при проверке. В мониторинге появляется алерт, в котором фигурирует идентификатор диска. Мы понимаем, что на нём возникли input/output-ошибки, внимательно его смотрим и практически всегда меняем.
Управление проверкой
Если Scrub заканчивается с ошибкой, нужно выяснить детали: какая именно placement group в неконсистентном состоянии и на каких OSD она сейчас находится. Сделать это можно следующей командой:
Вывод будет примерно такой:
После этого можно пойти в логи ядра конкретной OSD и проверить. Скорее всего там обнаружится ошибка ввода/вывода и станет понятно, что диск нужно менять.
Чтобы узнать, какую именно ошибку выдал Scrub, используйте команду:
В длинном выводе будет примерно такая секция, как на скриншоте ниже. В ней показаны OSD и состояния проблемного объекта на них.
На скриншоте видно, что на двух OSD (875 и 925), в том числе и на primary, объект есть, у него есть есть контрольная сумма, а вот на третьей (463) его просто нет.
Когда есть primary-копия, и она корректная, можно запустить восстановление командой:
Процесс repair может идти несколько часов. После этого в логе Ceph можно будет найти эту placement group по id и увидеть результат восстановления. Там будет написано, сколько ошибок исправлено, а сколько нет. Но когда большинство данных в порядке и повреждена только одна копия, процесс repair без проблем восстанавливает объект, беря его из primary OSD.
Оптимизация проверки
При всей полезности у скраббинга есть недостаток — он создаёт большую нагрузку. Когда идёт глубокий Scrub, данные из placement group читаются, чтение этих данных никак не отражается в системах мониторинга (это внутреннее io) и этот идущий Scrub может создавать нагрузку сам по себе. Раньше это была колоссальная нагрузка.
Кластеры на более ранних версиях сильно страдали от проверки. Scrub был невероятной проблемой. Можно было встретить много статей, как его лимитировать, чтобы он шёл медленнее и не создавал такую нагрузку.
Сейчас Scrub в Ceph стал более интеллектуальным, к нему прикрутили много параметров, которые позволяют его оптимизировать и практически в любом кластере сделать так, чтобы нагрузка от него не была сильно заметна.
Рассмотрим некоторые из этих параметров. Посмотрим на osd параметры, в которых есть слово “scrub”, так увидим все связанные с ним настройки.
“osd_max_scrubs” — определяет, сколько placement group может параллельно «скрабить» одна OSD. По умолчанию стоит значение “1”, то есть Scrub максимально зажат.
Есть параметры, которые полезно настроить с самого начала:
“osd_scrub_begin_hour” и “osd_scrub_end_hour”. В нашем примере в первом параметре стоит значение “0”, во втором “24”, то есть процессу разрешено идти в любое время.
Поменяем значения: поставим время начала “02”, время окончания “08”:
Таким образом мы задаём желательный интервал времени для проверки.
Но есть важный момент: это будет работать хорошо только поначалу. Как только какие-то placement group не смогут из-за этого интервала успевать «скрабиться» в течение недели, Scrub будет запускаться сразу по истечении недельного срока, независимо от ограничений по времени. Дедлайн для Scrub критичнее, чем эти интервалы.
Иными словами, этими параметрами вы задаёте время, когда вы хотели бы, чтобы Ceph делал Scrub, если он может это делать. Если у него настал дедлайн для какой-то placement group, то он проигнорирует интервалы, потому что дедлайн критичен.
“osd_scrub_sleep” — ещё один важный параметр. Для обычного скраба его значение “0.00000”. Можно задать “0.1”, хотя для обычного Scrub это не особо важно.
“osd_debug_deep_scrub_sleep” — задаёт sleep для Deep Scrub. По умолчанию его значение тоже “0”, но мы его у себя ставим “0.2”.
Меняется значение параметра аналогично:
Нужно понимать, что настройки Scrub в каждом кластере индивидуальны. Очень большие кластеры могут даже с дефолтными настройками не испытывать проблем. На кластерах меньшего размера он может быть заметен сильно. А если это кластер небольшого размера и у него ещё очень интенсивное io, то Scrub может быть проблемой.
“osd_scrub_chunk_max” и “osd_scrub_chunk_min” — это самые важные параметры, определяющие интенсивность проверки; то, что сильно зажимает или отпускает Scrub.
Если задать такое значение, то интенсивность идущего скраба упадёт в 5 раз — настолько медленнее будут читаться данные.
Хотя скорее всего, вы не заметите никакого эффекта, но получите алерты о том, что placement group не успевают пройти Scrub вовремя. Просто потому что слишком мало объектов берётся за одну итерацию, слишком медленное чтение.
Этими параметрами вы можете играть, задавая различные значения, чтобы достигнуть того баланса, когда Scrub успевает проходить за неделю и при этом не создаёт видимой нагрузки. Они меняются на лету, и вы можете ими в любой момент ускорять или зажимать Scrub.
“osd_scrub_auto_repair” — ещё один интересный параметр. В начале статьи вы видели ошибку о том, что placement group в состоянии inconsistent. Если в значении этого параметра поставить “false”, то Ceph запустит repair на эту placement group, но только если количество ошибок до 5. Если ошибок больше, то он не запустит автоматический repair, будет висеть ошибка, и вам надо будет посмотреть, что же произошло. Ceph считает, что повреждённых объектов слишком много, чтобы их автоматически чинить. Нужно разобраться, в чём дело.
“osd_scrub_during_recovery” — это относительно новый параметр. Если он активирован, то Scrub не будет запускаться, когда на OSD запущен backfilling, то есть идёт recovery io. Если у вас будет настроен когда-нибудь мониторинг текущего количества скрабов, то вы сможете увидеть, как во время запущенного rebalance график скрабов начинает стремительно снижаться.
Scrubbing io старается не конфликтовать с recovery io, и это ещё одна причина, по которой Scrub может откладываться. Если вы в течение недели делаете сильный rebalance — увеличиваете число placement group, добавляете сервер — Scrub откладывается, и через неделю вы получите множество сообщений о том, что Scrub не успел пройти за неделю, и вам нужно будет его либо ускорить, либо ждать, пока он «рассосётся».
Общая рекомендация: если вы видите проблему аномальной производительности в кластере и не понимаете, в чём дело, вы всегда можете отключить Scrub с помощью флагов:
Кроме того, скраб можно отключать для конкретного пула. Если у вас несколько пулов, и вы хотите для конкретного пула отключить скраб, то это можно сделать командой:
Флаги отразятся в claster health:
Эти флаги блокируют новый Scrub, но уже запущенные проверки не отклоняются и будут завершены. Когда текущие проверки закончатся, вы сможете оценить, изменилась ли ситуация с производительностью.
Если проблема исчезла, значит вам нужно немного зажать Scrub. Если сохранилась, то дело не в Scrub, его можно запускать снова и искать другую причину аномальной производительности.


