Oracle RAC. Общее описание / Часть 1
 Высоконагруженные сайты, доступность «5 nines». На заднем фоне (backend) куча обрабатываемой информации в базе данных. А что, если железо забарахлит, если вылетит какая-то давно не проявлявшаяся ошибка в ОС, упадет сетевой интерфейс? Что будет с доступностью информации? Из чистого любопытства я решил рассмотреть, какие решения вышеперечисленным проблемам предлагает Oracle. Последние версии, в отличие от Oracle 9i, называются Oracle 10g (или 11g), где g – означает «grid», распределенные вычисления. В основе распределенных вычислений «как ни крути» лежат кластера, и дополнительные технологии репликации данных (DataGuard, Streams). В этой статье в общих чертах описано, как устроен кластер на базе Oracle 10g. Называется он Real Application Cluster (RAC).
Высоконагруженные сайты, доступность «5 nines». На заднем фоне (backend) куча обрабатываемой информации в базе данных. А что, если железо забарахлит, если вылетит какая-то давно не проявлявшаяся ошибка в ОС, упадет сетевой интерфейс? Что будет с доступностью информации? Из чистого любопытства я решил рассмотреть, какие решения вышеперечисленным проблемам предлагает Oracle. Последние версии, в отличие от Oracle 9i, называются Oracle 10g (или 11g), где g – означает «grid», распределенные вычисления. В основе распределенных вычислений «как ни крути» лежат кластера, и дополнительные технологии репликации данных (DataGuard, Streams). В этой статье в общих чертах описано, как устроен кластер на базе Oracle 10g. Называется он Real Application Cluster (RAC).
Статья не претендует на полноту и всеобъемлемость, также в ней исключены настройки (дабы не увеличивать в объеме). Смысл – просто дать представление о технологии RAC.
Статью хотелось написать как можно доступнее, чтобы прочесть ее было интересно даже человеку, мало знакомому с СУБД Oracle. Поэтому рискну начать описание с аспектов наиболее часто встречаемой конфигурации БД – single-instance, когда на одном физическом сервере располагается одна база данных (RDBMS) Oracle. Это не имеет непосредственного отношения к кластеру, но основные требования и принципы работы будут одинаковы.
Введение. Single-instance.

Во всех современных реляционных БД данные хранятся в таблицах. Таблицы, индексы и другие объекты в Oracle хранятся в логических контейнерах – табличных пространствах (tablespace). Физически же tablespace располагаются в одном или нескольких файлах на диске. Хранятся они следующим образом:
Каждый объект БД (таблицы, индексы, сегменты отката и.т.п.) хранится в отдельном сегменте – области диска, которая может занимать пространство в одном или нескольких файлах. Сегменты в свою очередь, состоят из одного или нескольких экстентов. Экстент – это непрерывный фрагмента пространства в файле. Экстенты состоят из блоков. Блок – наименьшая единица выделения пространства в Oracle, по умолчанию равная 8K. В блоках хранятся строки данных, индексов или промежуточные результаты блокировок. Именно блоками сервер Oracle обычно выполняет чтение и запись на диск. Блоки имеют адрес, так называемый DBA (Database Block Address).

При любом обращении DML (Data Manipulation Language) к базе данных, Oracle подгружает соответствующие блоки с диска в оперативную память, а именно в буферный кэш. Хотя возможно, что они уже там присутствуют, и тогда к диску обращаться не нужно. Если запрос изменял данные (update, insert, delete), то изменения блоков происходят непосредственно в буферном кэше, и они помечаются как dirty (грязные). Но блоки не сразу сбрасываются на диск. Ведь диск – самое узкое место любой базы данных, поэтому Oracle старается как можно меньше к нему обращаться. Грязные блоки будут сброшены на диск автоматически фоновым процессом DBWn при прохождении контрольной точки (checkpoint) или при переключении журнала.


Когда в базу данных поступает запрос на изменение, то Oracle применяет его в буферном кэше, параллельно внося информацию, достаточную для повторения этого действия, в буфер повторного изменения (redo log buffer), находящийся в оперативной памяти. Как только транзакция завершается, происходит ее подтверждение (commit), и сервер сбрасывает содержимое redo buffer log на диск в redo log в режиме append-write и фиксирует транзакцию. Такой подход гораздо менее затратен, чем запись на диск непосредственно измененного блока. При сбое сервера кэш и все изменения в нем потеряются, но файлы redo log останутся. При включении Oracle начнет с того, что заглянет в них и повторно выполнит изменения таблиц (транзакции), которые не были отражены в datafiles. Это называется «накатить» изменения из redo, roll-forward. Online redo log сбрасывается на диск (LGWR) при подтверждении транзакции, при прохождении checkpoint или каждые 3 секунды (default).
С undo немного посложнее. С каждой таблицей в соседнем сегменте хранится ассоциированный с ней сегмент отмены. При запросе DML вместе с блоками таблицы обязательно подгружаются данные из сегмента отката и хранятся также в буферном кэше. Когда данные в таблице изменяются в кэше, в кэше так же происходит изменение данных undo, туда вносятся «противодействия». То есть, если в таблицу был внесен insert, то в сегмент отката вносится delete, delete – insert, update – вносится предыдущее значение строки. Блоки (и соответствующие данные undo) помечаются как грязные и переходят в redo log buffer. Да-да, в redo журнал записываются не только инструкции, какие изменения стоит внести (redo), но и какие у них противодействия (undo). Так как LGWR сбрасывает redo log buffer каждые 3 секунды, то при неудачном выполнении длительной транзакции (на пару минут), когда после минуты сервер упал, в redo будут записи не завершенные commit. Oracle, как проснется, накатит их (roll-forward), и по восстановленным (из redo log) в памяти сегментам отката данных отменит (roll-back) все незафиксированные транзакции. Справедливость восстановлена.
Кратко стоит упомянуть еще одно неоспоримое преимущество undo сегмента. По второму сценарию (из схемы) когда select дойдет до чтения блока (DBA) 500, он вдруг обнаружит что этот блок в кэше уже был изменен (пометка грязный), и поэтому обратится к сегменту отката, для того чтобы получить соответствующее предыдущее состояние блока. Если такого предыдущего состояния (flashback) в кэше не присутствовало, он прочитает его с диска, и продолжит выполнение select. Таким образом, даже при длительном «select count(money) from bookkeeping» дебет с кредитом сойдется. Согласованно по чтению (CR).
Отвлеклись. Пора искать подступы к кластерной конфигурации. =)
Уровень доступа к данным. ASM.

Хранилищем (datastorage) в больших БД почти всегда выступает SAN (Storage Area Network), который предоставляет прозрачный интерфейс серверам к дисковым массивам.
Сторонние производители (Hitachi, HP, Sun, Veritas) предлагают комплексные решения по организации таких SAN на базе ряда протоколов (самым распространенным является Fibre Channel), с дополнительными функциональными возможностями: зеркалирование, распределение нагрузки, подключение дисков на лету, распределение пространства между разделами и.т.п.
Позиция корпорации Oracle в вопросе построения базы данных любого масштаба сводится к тому, что Вам нужно только соответствующее ПО от Oracle (с соответствующими лицензиями), а выбранное оборудование – по возможности (если средства останутся после покупки Oracle :). Таким образом, для построения высоконагруженной БД можно обойтись без дорогостоящих SPARC серверов и фаршированных SAN, используя сервера на бесплатном Linux и дешевые RAID-массивы.
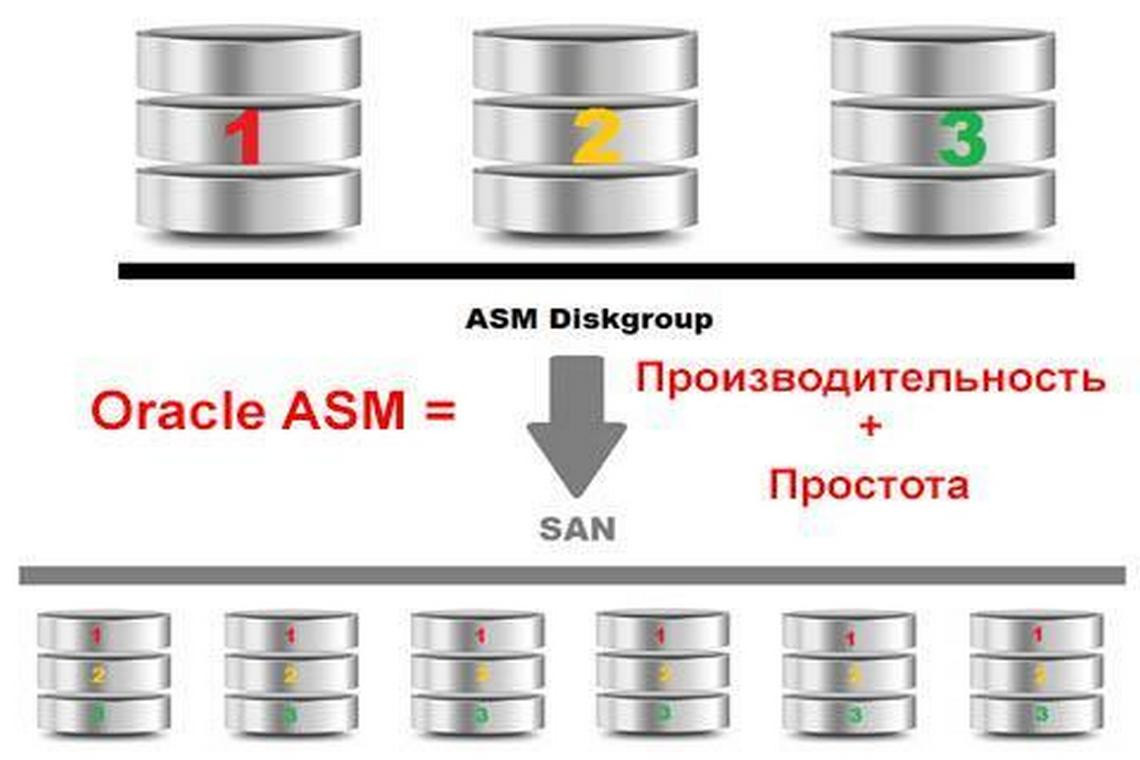
На уровне доступа к данным и дискам Oracle предлагает свое решение – ASM (Automatic Storage Management). Это отдельно устанавливаемый на каждый узел кластера мини-экземпляр Oracle (INSTANCE_TYPE = ASM), предоставляющий сервисы работы с дисками.
Oracle старается избегать обращений к диску, т.к. это является, пожалуй, основным bottleneck любой БД. Oracle выполняет функции кэширования данных, но ведь и файловые системы так же буферизуют запись на диск. А зачем дважды буферизировать данные? Причем, если Oracle подтвердил транзакцию и получил уведомления том, что изменения в файлы внесены, желательно, чтобы они уже находились там, а не в кэше, на случай «падения» БД. Поэтому рекомендуется использовать RAW devices (диски без файловой системы), что делает ASM.
Таким образом, кластер теперь может хранить и читать данные с общего файлового хранилища.
Пора на уровень повыше.
Clusterware. CRS.
На данном уровне необходимо обеспечить координацию и совместную работу узлов кластера, т.е. clusterware слой: где-то между самим экземпляром базы данных и дисковым хранилищем:
CRS (Cluster-Ready Services) – набор сервисов, обеспечивающий совместную работу узлов, отказоустойчивость, высокую доступность системы, восстановление системы после сбоя. CRS выглядит как «мини-экземпляр» БД (ПО) устанавливаемый на каждый узел кластера. Устанавливать CRS – в обязательном порядке для построения Oracle RAC. Кроме того, CRS можно интегрировать с решениями clusterware от сторонних производителей, таких как HP или Sun.
Опять немного «терминологии»…
Как уже стало ясно из таблички, самым главным процессом, «самым могущественным демоном», является CRSD (Cluster Ready Services Daemon). В его обязанности входит: запуск, остановка узла, генерация failure logs, реконфигурация кластера в случае падения узла, он также отвечает за восстановление после сбоев и поддержку файла профилей OCR. Если демон падает, то узел целиком перезагружается. CRS управляет ресурсами OCR: Global Service Daemon (GSD), ONS Daemon, Virtual Internet Protocol (VIP), listeners, databases, instances, and services.
Информатором в кластере выступает EVMD (Event Manager Daemon), который оповещает узлы о событиях: о том, что узел запущен, потерял связь, восстанавливается. Он выступает связующим звеном между CRSD и CSSD. Оповещения также направляются в ONS (Oracle Notification Services), универсальный шлюз Oracle, через который оповещения можно рассылать, например, в виде SMS или e-mail.
Стартует кластер примерно по следующей схеме: CSSD читает из общего хранилища OCR, откуда считывает кластерную конфигурацию, чтобы опознать, где расположен voting disk, читает voting disk, чтобы узнать сколько узлов (поднялось) в кластере и их имена, устанавливает соединения с соседними узлами по протоколу IPC. Обмениваясь heartbeat, проверяет, все ли соседние узлы поднялись, и выясняет, кто в текущей конфигурации определился как master. Ведущим (master) узлом становится первый запустившийся узел. После старта, все запущенные узлы регистрируются у master, и впоследствии будут предоставлять ему информацию о своих ресурсах.
Уровнем выше CRS на узлах установлены экземпляры базы данных.
Друг с другом узлы общаются по private сети – Cluster Interconnect, по протоколу IPC (Interprocess Communication). К ней предъявляются требования: высокая ширина пропускной способности и малые задержки. Она может строиться на основе высокоскоростных версий Ethernet, решений сторонних поставщиков (HP, Veritas, Sun), или же набирающего популярность InfiniBand. Последний кроме высокой пропускной способности пишет и читает непосредственно из буфера приложения, без необходимости в осуществлении вызовов уровня ядра. Поверх IP Oracle рекомендует использовать UDP для Linux, и TCP для среды Windows. Также при передаче пакетов по interconnect Oracle рекомендует укладываться в рамки 6-15 ms для задержек.
1 Раздел описывает концепции и возможности ASM
Вы можете добавлять или удалять диски из файловой группы во время использования её базой данных, при этом файлы автоматически перераспределятся для исключения простоя и обеспечения сропоставимой с сырыми устройствами производительности
ASM обеспечивает гибкое сервер-ориентированное зеркалирование, включая двойную и тройную избыточность, а также внешнее зеркалирпование через RAID, также возможно использование OMF для автоматического размещения и именования файлов. Заявлено уменьшение нагрузки на администратора путём консолидации в небольшом количестве дисковых груп разных дисков для множества баз данных и заявлено увеличение производительности ввода-вывода
Файлы, размещённые в ASM, могут сожительствовать с сырыми устройствами и сторонними файловыми системами, что облегчает переход на ASM
Управление ASM осуществляется через интерфейсы SQLplus, утилиты командной строки ASM и ASMCA (configuration assistent)
Кластерная система Oracle ACFS является масштабируемой и мультиплатформенной файловой системой и технологией управления хранением, и расширяет ASM для поддержки файлов заказчика. Динамический менеджер томов (ADVM) предоставляет сервисы управления томами и и интерфейс стандартного дискового драйвера для клиента
Экземпляр ASM построен на тех же технологиях, что и экземпляр БД, он имеет SGA и фоновые процессы, похожие на БД, однако в силу иных задач размер SGA. существенно меньше, чем у БД. ASM оказывает минимальный эффект на производительность сервера, экземпляр ASM монтирует дисковые группы для предоставления их экземпляру БД, но не монтирует базу
В отличие от отказа файлового драйвера отказ ASM не требует рестарта БД, в RAC окружении экземпляры БД и ASM выживших узлов проводят автоматическое восстановление отказавшего экземпляра ASM
Для разделения дисковой группы по нескольким узлам необходимо установить на всех них Clusterware, независимо от установки или неустановки RAC. Экземпляр ASM ни отдельном узле не требует включения в кластер, но без него не сможет общаться с другими экземплярами. Множественные ноды, не являющиеся частью ASM кластера, не могут разделять дисковые группы
Дисковые группы содержат множество дисков и являются фундаментальным объектом управления ASM. Каждая дисковая группа содержит метаданные для управления местом в группе, компоненты дисковой группы включают диски, файлы, единицы размещения (allocation unit)ю Файлы размещаются в дисковых группах, каждый ASM файл размещён в одной дисковой группе, однако дисковая группа может содержать файлы разных баз, и разные базы могут хранить файлы в нескольких дисковых группах. Для большинства инсталляций нужно немного групп, обычно две и редко больше трёх
Защита целостности данных резервированием заключается в хранении копий данных на нескольких дисках. При создании дисковой группы указывается один из трёх видов избыточности: Normal (2 копии), High (3 копии) или Extertnal (защита внешним решением типа RAID). Уровень избыточности определяет, сколько дисковых ошибок допустимо до размонтирпования группы и потери даных. Тип дисковой группы определяет, как в ней будут создаваться файлы (расширенная информация в разделе о шаблонах дисковых групп). Зеркалирование ASM гибче традиционного RAID. Для дисковой группы с уровнем избыточности NORMAL можно переопределить его для каждого файла
Дисками могут быть диск или партиция массива, диск или партиция диска, логический том, сетевой диск (NFS). Перед добавлением диска в группу нужно назначить ему имя, или оно будет назначено автоматически. Имя должно отличаться от пути, используемого в операционной системе. В кластере диск модет подключаться отличающимися именами операционной системы, но имеет одинаковое ASM имя на всех узлах. В кластере диск должен быть доступен всем экземплярам, разделяющим дисковую группу
ASM распределяет файлы пропорционально по всем дискам, входящим в дисковую группу, что обеспечивает одинаковый уровень заполнения дисков и даёт уверенность в равномерной нагрузке по вводу-выводу. По причине загрузки балансировщиком всех дисков, диски ASM не должны разделять физический даск
Сохраняемые в ASM файлы называются файлами ASM. Каждый ASM файл находится в одной файловой группе, база данных общается с ASM в терминах файлов. Это упрощает понятия использования базой любой файловой системы. Сохранять можно разные типы файлов: контрольные файлы, файлы данных, временные файлы и копии файлов данных, SP файлы, оперативные и архивные журналы, журналы Flashback, бэкапы RMAN, конфигурации аварийных восстановлений, битовые карты change tracking, дампы DataPump. ASM самостоятельно генерирует имена файлов при создании файлов и табличных пространств, начиная их с символа плюс и имени дисковой группы, вы можете создать удобные алиасы и выстроить их в иерархическую структуру каталогов для алиасов
Содержимое файлов ASM сохраняется в дисковой группе как набор или коллекция экстентов, расположенных на отдельных дисках группы, каждый экстент находится на одном диске группы, и содержит один или несколько allocation units. Для приспосабливания к увеличивающимся файлам используется переменный размер экстента, включающий поддержку наибольших файлов, уменьшая требования к SGA для очень больших баз и увеличавает производительность при операциях создания и открытия больших файлов. Начальный размер экстента равен размеру заданного для дисковой группы allocation unit и увеличивается с множителем 4 или 16 до заданного порога. Для дисковых групп с AU = 4 Мб, или параметр RDBMS compatiblity больше или равен 11.2.0.4, по количество экстентов каждого вида (AU, 4*AU, 16*AU) вычисляется для обеспечения максимального размера файла. Эта опция включается для новых или изменяемых групп с параметром совместимости 11.1 или выше (про совместимость отдельный раздел)
Распределение в ASM нужно для балансировки нагрузки (крупнозернистый с размером страйпа = размер AU) и уменьшения времени отклика (мелкозернистый с размером страйпа 128 Кб для оптимизации мелких операций ввода/вывода за счёт более широкого распределения нагрузки), при этом файл разбивается на куски (chunk), размещаемые в экстентах на разных дисках. В случае мелкозернистого распределения сначала заполняются по куску на диск первые экстенты, дробя AU на более мелкие куски, переходя ко вторым и т.д., а в случае крупнозернисторо распределение счёт идет на целые AU
Шаблоны являются коллекциями значений атрибутов, определяющих дисковые диапазоны, зеркалирование и страйпинг и существуют для каждого типа файлов по умолчанию, возможна кастомизация. При создании файла можно применить отдельный шаблон вместо шаблона для типа файлов
Вы можете добавить диск в существующую группу для расширения ёмкости или увеличения производительности. Строка обнаружения обуславливает диски, которые можно добавить, и добавляемые диски должны обнаруживаться каждым экземпляром ASM через установку инициализационного параметра ASM_DISKSTRING. После добавления диска опреация ребеленсировки перемещает данные на новый диск, и для оптимизации ввода-вывода оптимально добавлять несколько дисков сразу
Также можно удалить диск из группы после отказа или по иным причинам, для чего необходимо использовать ASM имя диска, но не имя строки обнаружения. Если ASM зафиксирует ошибки записи на диск, такой диск будет исключён из группы автоматически
Ребалансировка дисколвой группы приводит к перемещению файлов по дискам группы для того, чтобы быть уверенным в равномерном распределении данных по всем дискам группы. Если файлы равномерно распределены и диски заполнены с одним процентом заполнения, то это обеспечивает балансировку нагрузки. Ребалансировка не перемещает данные на основании статистики ввода/вывода, и не стартует на основании статистики ввода/вывода, операция ребалансировки ASM контролируется размером дисков в группе
2 Особенности хранилища ASM
важные мысли. Перед подготовкой вашего хранилища к ASM определите опции хранения и готовьте дисковое хранилище под окружение вашей ОС. Вы должны учитывать текущую ёмкость и будущие потребности. ASM упрощает задачу, но есть зависимости, например от размера дисков, пропускной способности канала между хранилкой и сервером, также при масштабировании кластера нужно не забыть смасштабировать хранилище
Множественный доступ (multipathing) резервирует канал между хранилищем и сервером, увеличивает производительность и реализован на уровне драйвера ОС, создавая суммирующее псевдоустройство. ASM работает со множественным доступом, отдавая всю кухню опреационной системе, при этом псевдоустройство должно обнаруживаться посредством указания корректной строки обнаружения ASM_DISKSTRING. Если будет обнаружено несколько путей к дисковому устройству, будет ошибка
3 Администрирование экземпляра
SELECT SUM(bytes)/(1024*1024*1024) FROM V$DATAFILE;
SELECT SUM(bytes)/(1024*1024*1024) FROM V$LOGFILE a, V$LOG b WHERE a.group#=b.group#;
SELECT SUM(bytes)/(1024*1024*1024) FROM V$TEMPFILE WHERE status=’ONLINE’;
Oracle Restart повышает доступность БД и работает из отдельного от HOME СУБД каталога. При установке инфраструктуры на одиночный сервер она включает и ASM, и Restart, позволяющий перезапускать упавшие сервисы и управляемый утилитой srvctl
Если путь к конфигурационному файлу некорректен, можно создать файл, например /oracle/dbs/spfileasm_init.ora со строчкой SPFILE=’+DATA/asm/asmparameterfile/asmspfile.ora’ и стартовать экземпляр ASM командой STARTUP PFILE=/oracle/dbs/spfileasm_init.ora. После успешного старта поправить путь командой ASMCMD> spset +DATA/asm/asmparameterfile/asmspfile.ora
Также утилитой SRVCTL можно модифицировать ресурсы в кластерном регистре, включать, выключать, останавливать и стартовать экземпляры ASM, запрашивать статус и конфигурацию ASM. Обновление версии для 11.2 возможно только в новый каталог, in-place не поддерживается. После установки запускается заполняющий CRSCONFIG_PARAMS мастер, ASH доступно через V$ACTIVE_SESSION_HISTORY
Прокручиваемое обновление позволяет обновлять отдельные узлы с минимальным временем простоя, используя заложенные возможности эксплуатации нод с разными версиями, рекомендуется обновлять ASM после обновления кластерного ПО. Окружение готовят, кластерное ПО должно быть обновлено до обновления ASM, кластерное ПО должно быть подготовлено rolling обновлению. Этот режим доступен только для кластерной конфигурации с 11.2. Обновляется по обному узлу за раз, команды старта ALTER SYSTEM START ROLLING PATCH; и стопа ALTER SYSTEM STOP ROLLING PATCH; Увидеть статус можно, запросив SYS_CONTEXT, SELECT SYS_CONTEXT(‘SYS_CLUSTER_PROPERTIES’, ‘CLUSTER_STATE’) FROM DUAL; SELECT SYS_CONTEXT(‘SYS_CLUSTER_PROPERTIES’, ‘CURRENT_PATCHLVL’) FROM DUAL; версии патчей доступны в V$PATCHES, есть также команда ASMCMD> showclusterstate ; showpatches ; showversion
С версии 12c можно обновить standart ASM до Flex с помощью asmca, что описано в текущем разделе (не перводил скриншоты)
В обоих случаях диски с ASMLIB должны подхватиться
Для удаления фильтр драйвера существуют процедуры для кластерной и некластерной конфигурации
У экземпляра нет словаря и коннектиться к нему можно через системные привелегии SYSASM, SYSDBA, SYSOPER локально через авторизацию JC или пароль, и удаленно через Oracle Net Service с авторизацие по паролю. ASM и БД должны иметь права на ввод-вывод на уровне операционной системы (ОС) к дисковым группам, в юниксе это обычно разделяемая группа OSASM, в Win ASM сервис должен быть запущен от администратора. При установке ASM можно назначить пользователям одну группу или разделить группы для администраторов БД, хранилищ и операторов БД. Независимо от выбора для администрирования ASM нужно использовать группу SYSASM. Привилегия SYSDBA не может использоваться для администрирования ASM, попытка даёт ошибки, но используется для доступа базы к дисковым группам. Oracle рекомендует использовать пользователя с меньшим уровнем привилегий вроде ASMSNMP и SYSDBA для мониторинга. Аутентификация через группы ОС OSDBA, OSOPER, OSASM работает во всех юниксах, а подключение с грантом SYSASM отдают доступ ко всем группам и функциям управления. Если группы не выделены, обычно unix группу dba назначают для OSDBA, OSOPER, OSASM. Если разделяют, то группе OSASM назначают привилегию SYSASM (полный административный доступ), имя гшруппы в ОС может быть, например, asmadmin. OSDBA назначают привилегию SYSDBA, допускающую к данным ASM, это подмножество OSASM и выбирают отличную от группы dba для базы данных, например asmdba. OSOPER получает привилегию SYSOPER для экземпляра ASM, это права на операции старта и остановки, монтирования, размонтирования и проверки групп, подмнодество OSASM, имя может быть, например, asmoper
В процессе новой инсталляции СУБД Oracle и ASM можно сразу создать базу и выбрать опции ASM. Если БД уже есть и жувёт на ФС ОС, её можн мигрировать в ASM полностью или частично. Для миграции нужно обновиться хотя бы до 10 версии. Варианты миграции различны, в т.ч. RMAN позволяет сделать полную миграцию БД, или только табличное пространство, или файл данных. приводится ссылка на web страницы с лучшими практиками
. последующие разделы до 11 содержат непосредственное описание команд и представлений и, как любой производственный справочник Oracle, читаются мной из оригинальной англоязычной книги

Андрей Волков
Системное, сетевое администрирование +DBA. И немного программист!)) Профиль автора.
3 способа задания избыточности:
Архитектура ASM
Для увеличения производительности и надежности ASM делит файлы данных и другие структуры базы данных на экстенты и распределяет эти экстенты по всем дисковым устройствам, входящим в дисковую группу. Вместо зеркалирования всего дискового тома ASM подвергает зеркалированию объекты базы данных для придания зеркалированию гибкости или рассредоточению объектов базы данных способом, наиболее подходящего для их типа.
Автоматическая регулировка нагрузки является еще одной ключевой характеристикой ASM. Когда требуется увеличение объема дискового пространства, к дисковой группе могут быть добавлены новые дисковые устройства, a ASM перенесет пропорциональное количество файлов с одного или с нескольких имевшихся ранее дисков на новые диски для поддержания общего баланса ввода/вывода для всех имеющихся дисков. Если влияние, оказываемое во время выполнения операций по перенастройке на подсистему ввода /вывода, велико, скорость перенастройки может быть уменьшена за счет применения параметров инициализации.
Однако использование ASM не избавляет от необходимости смешивать дисковые группы ASM с «ручными» методами управления файлами данных, описанными выше. Тем не менее, простота использования и высокая производительность ASM становятся веским доводом в пользу применения ASM для всех потребностей хранения.
Для поддержки экземпляров ASM появились два новых фоновых процесса Oracle: RBAL и ORBn. Процесс RBAL координирует всю дисковую активность для дисковых групп, в то время как ORBn, где n может быть числом от 0 до 9, выполняет фактическое перемещение экстентов между дисками, входящими в дисковую группу.
Для баз данных, использующих ASM, также появились два новых фоновых процесса: OSMB и RBAL. Процесс OSMB осуществляет взаимодействие между базой данных и экземпляром ASM, в то время как RBAL от имени базы данных выполняет открытие и закрытие дисков в составе дисковой группы.
Для ASM требуется выделенный экземпляр Oracle для управления дисковыми группами. Обычно экземпляр ASM требует очень немного места в оперативной памяти в диапазоне от 60 до 120 Мбайт. При специфицировании ASM как способа хранения файлов данных во время инсталляции программного обеспечения Oracle этот экземпляр конфигурируется автоматически, если к этому моменту экземпляра ASM еще не существовало.
После создания базы данных Oracle будут запущены и обычный экземпляр, и экземпляр ASM.
Параметры инициализации ASM
INSTANCE_TYPE
Для экземпляра ASM параметр INSTANCE_TYPE принимает значение ASM. Значением по умолчанию, используемым для традиционных экземпляров Oracle, является RDBMS.
DB_UNIQUE_NAME
Значение по умолчанию параметра DB_UNIQUE_NAME равно +ASM и является уникальным именем группы экземпляров ASM для кластера или одиночного узла; значение по умолчанию должно быть модифицировано, только если делается попытка эксплуатировать на одном узле несколько экземпляров ASM.
ASM_POWER_LIMIT
Значения этого параметра лежат в диапазоне от 1 до 11, причем 11 является максимальным возможным значением, а 1 значением по умолчанию (обеспечивающим низкие накладные расходы для ввода/ вывода). Поскольку этот параметр является динамическим, в рабочее время (в дневные часы) его значение- можно изменять на более низкое, а в ночное время (когда можно выделять больше времени на операции по перенастройке дисковых трупп) задать более высокое значение.
ASM_DISKSTRING
Параметр ASM_DISKSTRING специфицирует одну или несколько строк (в зависимости от операционной системы) для ограничения количества дисковых устройств, которые могут быть использованы для создания дисковых групп. Если это значение есть NULL, потенциальными кандидатами на включение в состав создаваемой дисковой группы являются все видимые ASM дисковые устройства.
ASM_DISKGROUPS
Параметр ASM_DISKGROUPS специфицирует список, содержащий имена дисковых групп, которые должны быть автоматически смонтированы экземпляром ASM при запуске или командой alter diskgroup all mount. Даже если в момент запуска экземпляра этот список пуст, любые имеющиеся в наличии дисковые группы могут быть смонтированы вручную.
LARGE_POOL_SIZE
Параметр LARGE_POOL_SIZE полезен как для обычных экземпляров, так и для экземпляров ASM: однако для экземпляров ASM этот пул используется по-другому. Из этого пула выполняются внутренние пакеты ASM, так что этот параметр должен быть равен, по меньшей мере, 8 Мбайт.
Запуск и остановка экземпляра ASM
Запуск экземпляра ASM во многом похож на запуск обычного экземпляра, за тем исключением, что значением по умолчанию для команды startup является startup mount. Поскольку для этого экземпляра отсутствуют управляющий файл, база данных или словарь данных, которые можно было бы смонтировать, вместо базы данных монтируются группы дисков ASM. Команда startup nomount запускает экземпляр, но при этом не монтирует никаких дисков ASM. Помимо этого можно указать startup restrict, чтобы временно запретить экземплярам базы данных подключаться к экземпляру ASM для монтирования дисковых групп.
Динамические представления производительности ASM
Администрирование дисковых групп ASM
Использование дисковых групп ASM оказывается выгодным по нескольким причинам: повышается производительность ввода/вывода, увеличивается доступность, а простота, с которой можно добавить диск в дисковую группу или добавить абсолютно новую дисковую группу, позволяет за то же самое время справляться с управлением большим числом баз данных. Понимание компонент дисковой группы, а также ее соответствующее конфигурирование являются весьма важными задачами для успешного АБД.
Архитектура дисковых групп
Дисковой группой называется совокупность (collection) физических дисков, управляемая как единый элемент. У каждого диска ASM как у части дисковой группы имеется имя диска ASM, которое либо назначается АБД, либо присваивается ему автоматически при включении в дисковую группу.
Файлы в дисковой группе рассредоточены по дискам с применением либо крупноблочного, либо мелкоблочного расщепления. При крупноблочном расщеплении (coarse striping) файлы рассредоточиваются но всем доступным дискам блоками по 1 Мбайт. Такое расщепление оказывается подходящим для системы с высокой степенью одновременно выполняющихся небольших по объему запросов на ввод/вывод, например для сред OLTP.
При мелкоблочном расщеплении файлы разбиваются па блоки размером 128 Кбайт. Такое расщепление более всего подходит для традиционных сред хранилищ данных или для систем OLTP с не слишком высоким конкурентным доступом, так как при этом минимизируется время отклика на индивидуальные запросы ввода/вывода.
Зеркалирование дисковых групп и групп отказа
Прежде чем определить тип зеркалирования в дисковой группе, необходимо сгруппировать диски в так называемые группы отказа. Группой отказа называется один или несколько входящих в состав дисковой группы дисков, разделяющих некоторый общий ресурс, например контроллер дисков, выход которого из строя делает недоступным для дисковой группы весь этот набор дисков. В большинстве случаев экземпляр ASM не знает об аппаратных и программных зависимостях для данного диска. Следовательно, если только специально не приписать диск к группе отказа, каждому диску будет назначена собственная труппа отказа.
После определения группы отказа можно определить зеркалирование для дисковых групп; тип зеркалирования, доступный для дисковой группы, может быть ограничен числом имеющихся в дисковой группе групп отказа. Есть всего три типа зеркалирования: внешняя, обычная и высокая избыточность.
Внешняя избыточность
Для внешней избыточности требуется наличие только одной группы отказа. Предполагается, что дисковая группа не является критичной для продолжения функционирования базы данных или что диск является управляемым внешним образом с помощью специализированного программного обеспечения, гарантирующего высокую доступность, например с помощью контроллера RAID.
Обычная избыточность
Обычная избыточность обеспечивает двукратное зеркалирование и требует, чтобы в группе дисков было, по крайней мере, две группы отказа. Выход из строя одного из дисков в группе отказа не вызывает никакого простоя дисковой группы и не приводит к потере данных, разве что к небольшой потере производительности запросов к объектам из этой дисковой группы.
Высокая избыточность
Для обеспечения высокой избыточности предлагается трехкратное зеркалирование, для чего требуется, чтобы в группе дисков было не менее трех групп отказа. Выход из строя дисков в двух группах отказа из имеющихся трех в большинстве случаев останется прозрачным для пользователей базы данных, как и в случае зеркалирования с обычной избыточностью.
Управление зеркалированием осуществляется на очень низком уровне. Зеркалируются не диски, а экстенты. Кроме того, на каждом диске должна храниться смесь первичных и зеркалированных (вторичных и третичных) экстентов. И хотя для управления зеркалированием на уровне экстентов не обойтись без небольших накладных расходов, зеркалирование обеспечивает преимущества рассредоточения нагрузки с вышедшего из строя диска на все оставшиеся диски, а не на один диск.
Динамическая перенастройка дисковой группы
Всякий раз, когда конфигурация дисковой группы изменяется если вы добавляете в нее или удаляете из нее труппу отказа или диск, в составе группы отказа автоматически производится динамическая перенастройка для пропорционального перераспределения данных с других дисков, являющихся членами дисковой группы, па новый ее член. Перенастройка происходит в то время, когда база данных находится в оперативном состоянии и доступна для пользователей; любое влияние на непрекращающиеся операции ввода/вывода пользователей может быть взято под контроль посредством настройки значения параметра инициализации ASM_POWER_LIMIT в сторону более низких значений.
Динамическая перенастройка не только освобождает от утомительной и зачастую подверженной ошибкам процедуры определения «горячих точек» для дисковой группы, но и предлагает способ автоматического переноса всей базы данных с набора более медленных дисков на набор более высокоскоростных дисков без остановки базы данных. Более высокоскоростные диски добавляются как новая группа отказа в существующую дисковую группу наряду с имеющимися «медленными» дисками, после чего происходит автоматическая перенастройка. После завершения этой перенастройки группы отказа, в которые входят медленные диски, удаляются, так что будут оставлены только труппы отказа, состоящие из высокоскоростных дисков. Чтобы сделать эту операцию еще более быстрой, обе операции add (добавить) и drop (удалить) могут быть инициированы внутри одной команды alter diskgroup (изменить дисковую группу).
Предположим, что требуется создать новую ДИСКОВУЮ группу с высокой избыточностью, где будут храниться табличные пространства Сданными для нового приложения по авторизации кредитных карт. С помощью представления V$ASM_DISK можно, применив параметр инициализации V$ASM_DISKSTRING и статус диска, просмотреть все обнаруженные диски (другими словами, выяснить, был ли этот диск назначен существующей дисковой группе или остался нераспределенным):
Из шести доступных для ASM дисков только два назначены для одиночной дисковой группы, причем каждый из них образует собственную группу отказа. Имя дисковой группы может быть получено из представления V$ASM_DISKGROUP:
Если есть некоторое количество дисков и дисковых групп ASM, можно объединить эти два представления по столбцу GROUP_NUMBER и отфильтровать результаты запроса по этому же столбцу. Кроме того, из V$ASM_DISKCROUP можно видеть, что дисковая группа DATA1 является состоящей из двух дисков группой с обычной избыточностью (NORMAL REDUNDANCY).
На первом шаге создадим дисковую группу:
Взглянув на динамические представления производительности, из представления V$ASM_DISKGROUP можно увидеть ставшую доступной новую дисковую группу, а из представления V$ASM_DISK ознакомиться с группами отказа:
Однако, если дискового пространства маловато, можно отказаться от четырех членов; для дисковой группы с высокой избыточностью достаточно трех групп отказа, так что можно удалить эту дисковую группу и заново создать ее только с тремя членами:
Если в дисковой группе есть какие-либо объекты базы данных, кроме метаданных дисковой группы, необходимо специфицировать в команде drop diskgroup фразу including contents. Это является дополнительной мерой предосторожности, позволяющей убедиться, что дисковые группы с объектами базы данных не будут случайно удалены:
Теперь, когда конфигурирование новой дисковой группы закончено, в новой дисковой группе можно создать табличное пространство (из экземпляра базы данных):
Поскольку файлы ASM являются управляемыми Oracle файлами, при создании табличного пространства не требуется задавать никаких других его характеристик.
Изменение дисковых групп
В дисковую группу можно добавлять диски и удалять их оттуда; кроме того, многие характеристики дисковой группы могут быть изменены без повторного ее создания и не оказывая влияния на транзакции пользователей над объектами из дисковой группы.
Немедленно осуществляется выход из команды, а форматирование и перенастройка продолжаются в фоновом режиме. После этого можно проверить статус операции перенастройки, проверив представление V$ASM_OPERATION :
Поскольку оценочное время завершения операции перенастройки составляет 10 мин, принимается решение выделить для этой операции больше ресурсов и изменить предельную «мощность» этой конкретной операции перенастройки:
Проверка статуса операции перенастройки подтверждает, что оценочное время до завершения операции сократилось с 16 до 4 минут:
Спустя четыре минуты проверим статус задания еще раз:
И, наконец, подтвердим конфигурацию нового диска из представлений V$ASM _DISK и V$ASM DISKGROUP:
Избыточность дисковой группы остается нормальной, несмотря па то, что в ней есть три группы отказа. Однако производительность ввода/вывода оператора select относительно объектов из этой дисковой группы возрастает благодаря наличию дополнительных копий экстентов, ставших доступными для дисковой группы.
Другие команды alter для дисковых групп
Миграция базы данных в среду ASM
Поскольку к файлам ASM нельзя получить доступ средствами операционной системы, для перемещения в дисковую группу ASM объектов базы данных, хранящихся не в среде ASM, необходимо использовать диспетчер восстановления (RMAN). Для перемещения таких объектов нужно выполнить следующие шаги:


