OCR API API Reference
The powerful Optical Character Recognition (OCR) APIs let you convert scanned images of pages into recognized text.
API Endpoint
Schemes: https
Version: v1
Authentication
Apikey
API Key Authentication
ImageOcr
Convert a scanned image into text
Converts an uploaded image in common formats such as JPEG, PNG into text via Optical Character Recognition. This API is intended to be run on scanned documents. If you want to OCR photos (e.g. taken with a smart phone camera), be sure to use the photo/toText API instead, as it is designed to unskew the image first. Note: for free tier API keys, it is required to add a credit card to your account for security reasons, to use the free tier key with this API.
Image file to perform OCR on. Common file formats such as PNG, JPEG are supported.
Optional; possible values are ‘Basic’ which provides basic recognition and is not resillient to page rotation, skew or low quality images uses 1-2 API calls; ‘Normal’ which provides highly fault tolerant OCR recognition uses 26-30 API calls; and ‘Advanced’ which provides the highest quality and most fault-tolerant recognition uses 28-30 API calls. Default recognition mode is ‘Advanced’
Optional, preprocessing mode, default is ‘Auto’. Possible values are None (no preprocessing of the image), and Auto (automatic image enhancement of the image before OCR is applied; this is recommended).
Free OCR API
Get Your Free OCR API Key
Register here for your free OCR API key. The OCR API provides a simple way of parsing images and multi-page PDF documents (PDF OCR) and getting the extracted text results returned in a JSON format. The OCR API has three tiers/levels. The free OCR API plan has a rate limit of 500 requests within one day per IP address to prevent accidental spamming.
For even faster response times and guaranteed 100% uptime PRO plans are available. The PRO OCR API runs on physically different servers than our free OCR API service. You receive the URLs for the global PRO endpoints and your API key in the welcome email directly after you have signed-up for the PRO or PRO PDF account. The PRO OCR API can also be purchased as a locally installable on-premise OCR software.
| API Plan | Free | PRO | PRO PDF | Enterprise |
|---|---|---|---|---|
| Pricing | Free | $30/month | $60/month | $299+/month |
| Register for free API key | Buy PRO API Key | Buy PRO PDF API Key | Contact Sales | |
| Requests/month | 25,000 | 300,000 | 300,000 | Custom |
| Additional conversions* | n/a | US$10/100,000 | US$20/100,000 | Included |
| File Size Limit | 1 MB | 5 MB | 100 MB+ | 100 MB+ |
| PDF Page Limit | 3 | 3 | 999+ | 999+ |
| Searchable PDF Creation | Yes (with watermark) | Yes | Yes | Yes |
| Speed | Fast | Faster (more servers, lower load) | Fastest (Your own server) | |
| Rate Limit** | 500 calls/DAY | 6000 calls/1h | 6000 calls/1h | Custom |
| Service-level agreement (SLA) | n/a | 100% uptime or money back (dedicated, redundant servers in USA/EU/Asia) | Custom location(s) | |
*Additional conversions: We do not charge for extra conversions automatically. Instead, if you reach the limit, we will contact you and you can decide if you want to pay for additional conversions or stop for the current billing period.
**For the PRO plans, we can adjust the default rate limit if needed.
You can check the API performance and uptime at the API status page.
Now it’s time to get started: Below you find example code for calling the API from Postman, AutoHotKey (AHK), cURL, C#, ASP.NET, Delphi, iOS, Java (Android app), Node.JS NPM, Python, C++/QT, Ruby, and Javascript. (If you have code examples for other languages, please let us know and we will add them to this list).
Faster OCR with the PRO plans
For our OCR PRO plans we use redundant high-performance API endpoints in the US, EU and Asia regions. We guarantee 100% uptime or money back. Our hosted PRO OCR plans:
In addition to connecting to our PRO OCR servers, you can also directly buy our OCR software and host it yourself. This option is described in the next paragraph below.
OCR.space Local Self-hosted, On-Premise OCR Server
The Free OCR API Endpoint (POST)
Free OCR APIhttps://api.ocr.space/parse/image The API supports https:// (SSL) and plain http:// connections.
«GET» OCR API Endpoint
Using an OCR API was never easier.
Besides the full-featured «POST» OCR API at /parse/image we provide an additional OCR API endpoint at /parse/ImageUrl for GET requests. While not as versatile as the POST API, it is easy to use. Everything you need for the api call is inside the URL.
The default OCR language is English. To use another language, add &language to the url. You can also request the x/y word coordinates with isOverlayRequired :
https://api.ocr.space/parse/imageurl?apikey=helloworld&url=http://i.imgur.com/s1JZUnd.gif&language=chs&isOverlayRequired=true
The important limitation of the GET api endpoint is it only allows image and PDF submissions via the URL method, as only HTTP POST requests can supply additional data to the server in the message body. GET requests include all required data in the URL. So by design, a GET api cannot support file uploads ( file parameter) or BASE64 strings ( base64image ).
The GET API is easy and fast to use. Just note that the URL with the api key might be stored in your browser’s history. But this is not a security problem because even if somebody gains access to your personal API key, he or she can not access any information about you or the OCR’ed documents, because we do not store such information in the first place. The worst-case scenario is that somebody uses all your free conversions. If this might be a problem for your application, simply continue to use the fully SSL-encrypted POST version of the API or switch to the PRO OCR API, which provides additional options.
Post Parameters
The table below lists all possible API parameters. As additional documentation, we published a sample api call collection that you can load into Postman. And last but not least: Our free online ocr form on the front page is nothing else than a POST call to the free OCR API endpoint and can be used for testing as well.
| Key | Value | Description |
|---|---|---|
| apikey | API Key (send in the header) | Get your free API key |
| url or file or base64Image | url : URL of remote image file (Make sure it has the right content type) file : Multipart encoded image file with filename base64Image : Image or PDF as Base64 encoded string | You can use three methods to upload the input image or PDF. We recommend the URL method for file sizes > 10 MB for faster upload speeds. |
| language | [Optional] Arabic= ara Bulgarian= bul Chinese(Simplified)= chs Chinese(Traditional)= cht Croatian = hrv Czech = cze Danish = dan Dutch = dut English = eng Finnish = fin French = fre German = ger Greek = gre Hungarian = hun Korean = kor Italian = ita Japanese = jpn Polish = pol Portuguese = por Russian = rus Slovenian = slv Spanish = spa Swedish = swe Turkish = tur | Language used for OCR. If no language is specified, English eng is taken as default. |
New: If you need to detect the status of checkboxes, please contact us about the Optical Mark Recognition (OMR) (Beta) features.
Select the best OCR Engine
The OCR API offers two different OCR engine with a different processing logic. We recommend that you try both and then use whatever engine gives you the best OCR result. You can use both OCR engines with our free online OCR service on the front page and with the OCREngine=1/2 parameter in your API call.
Features of OCR Engine 1:
Features of OCR Engine 2:
Enterprise Support: Both OCR engines are available for offline, self-hosting as On-Premise OCR!
The returned OCR result JSON response is identical for both engines! You can switch between both engines as needed. The features that are not mentioned in this OCR engine comparison are the same for both engines, for example PDF OCR, detect orientation and receipt scanning support. If you have any question about using Engine 1 or 2, please ask in our OCR API Forum.
Response
The API returns results in JSON format. The result typically contains the ExitCode, Error details (if occurred) and a bunch of parsed results for the Image / PDF pages. Please check below the response the Web API returns and definition of various parameters. The illustration below shows success and error responses.
| Key | Value | Description |
|---|---|---|
| ParsedResults | OCR results | The OCR results for the image or for each page of PDF. For PDF: Each page has its own OCR result and error message (if any) |
| OCRExitCode | Integer | The exit code shows if OCR completed successfully, partially or failed with error |
1: Parsed Successfully (Image / All pages parsed successfully)
2: Parsed Partially (Only few pages out of all the pages parsed successfully)
3: Image / All the PDF pages failed parsing (This happens mainly because the OCR engine fails to parse an image)
4: Error occurred when attempting to parse (This happens when a fatal error occurs during parsing )
0: File not found
1: Success
-10: OCR Engine Parse Error
-20: Timeout
-30: Validation Error
-99: Unknown Error
Searchable PDF
When used with the free OCR API tier, the generated PDF contains a watermark «Generated by OCR.space» in the lower right corner. With the PRO OCR API, no watermark is added to the PDF.
Code Examples
Test API with the Postman App
Getting started: Use the free Postman app for Windows, Mac and Linux to test the OCR API and play with the different parameters.
Tip: If you have Postman installed you can click the «Run in Postman» button above to import a set of six API test calls to Postman. The samples use the «helloworld» api key and are ready to run without any further edits.
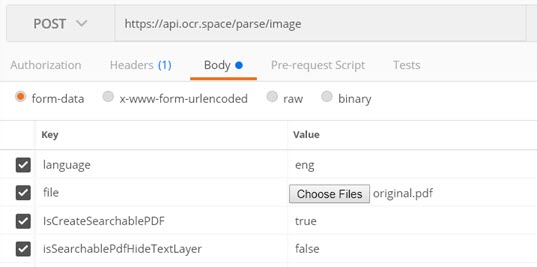
(a) Provide image/PDF to be OCR’ed via URL
The screenshots below show the settings for sending the image/PDF via a URL. Note that the encoding is set to multipart/form-data.
In all cases (file upload via URL, file or base64) the api key (password) is sent in header:
(b) Upload image/PDF to be OCR’ed from your server/PC
Same Postman app, but this time we are using the «File» setting to upload the image or PDF.
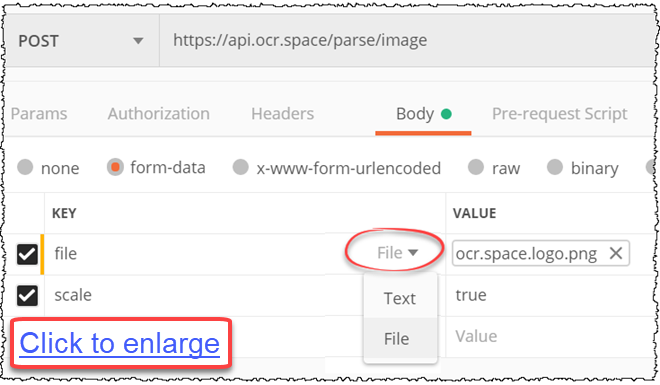
(c) Send image as Base64 string
Same Postman app, but this time, we are using the «Base64Image» parameter to send the image as string.
Tip: Make sure there is no extra «new line» after pasting a base64 string into Postman. If there is, the API will (rightfully) return a «Not a valid base64 image.» error.
Test BASE64 strings
The links open a text file in the browser: Image Base64 String, TIFF Base64 String, PDF as Base64 string. You can copy and paste the content of these text files directly into the «base64image» field of Postman, or any other test code.
cURL command-line
(a) Provide image/PDF to be OCR’ed via URL
curl is an open source command line tool and library for transferring data with URL syntax. The libcurl library is portable. It builds and works identically on nearly any platform (Windows, Mac, Linux. ).
(b) Upload image/PDF to be OCR’ed from your server/PC
Note: @screenshot.jpg assumes an image with name «screenshot.jpg» is in the same directory as cURL.exe. Note that the isOverlayrequired (default: no) and the language (default: eng) parameters are optional.
(c) Send image as string in Base64 format
The base64 string in this example is truncated. You can download the full command line as Windows batch file from GitHub.
We have some test base64 strings available for download.
C# (Visual Studio Project)
There is a ready-to-use Visual Studio C# sample project for using the OCR API from C# on GitHub.
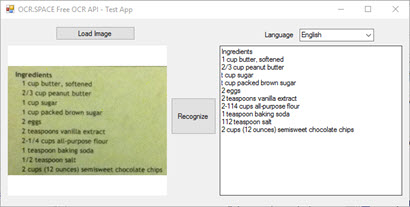
The test app allows you to upload and test any image quickly with the OCR API.
For a real-life example, look at the popular «ShareX» productivity tool:

ShareX uses the OCR.space PRO API and the full C# source code is available.
iOS: Objective-C and Swift
The user-provided code snippets for Objective-C and Swift are a good starting point for iPhone apps with OCR features.
Android: Java
Using Android? Look at this Android sample app that uses the free OCR API. The Java app shows how to call the API using HttpsURLConnection from user «bsuhas». And here is another, different Java repo from user «Globalizer». Thanks to both for providing this code snippet.
PHP OCR API Demo Web App
For PHP we have a complete, ready-to-run demo web app that allows the user to select a document and then uploads the image or PDF document to the OCR API.
Python
Here is an example of how to access the API from Python using the requests.post command.
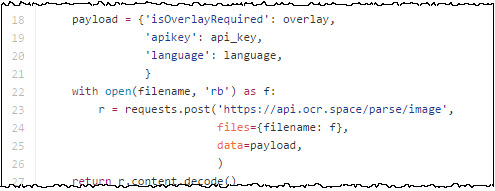
The full source code can be found on GitHub (thanks to user «Zaargh» for providing this code snippet). Another Python wrapper for our OCR SDK is available from GitHub user a4fr (thanks to everyone for creating code snippets).
AutoHotKey (AHK)
Using C++? Jhiroka from UCLA shared this example with us: C++/QT OCR API sample app.
If you are using the C++ Casablanca Library for the HTTP POST call, note that you need to url encode the image data on top of Base64 encoding. The C++ library Casablanca does not seem to do this automatically (unlike Postman does), so use the function web::uri::encode_data_string to encode the file data after Base64 encoding the request.
User Matteo made a Github repository with a Go module for the OCR API.
Using Ruby? Suyesh shared this Ruby gem (library) with us: OCR API Ruby gem.
Using Perl? Then have a look at this OCR API user submitted Perl OCR.space module.
Powershell
We have a Powershell OCR code snippet. This includes downloading the generated sandwich PDF.
Javascript
Chrome extension
The open-source Copyfish Chrome, Edge and Firefox extension uses our OCR API. You find its Javascript source code here. This includes code that shows how to process the returned text overlay data. Note the Copyfish extension uses the PRO OCR API version.

Test it: You can install the Copyfish OCR extension in Chrome, Edge, and Firefox.
NPM/Node.js
The latest OCR API Node.JS wrapper is from user DavideViolante. It allows you to specify the OCR Space API endpoints (Free and PRO). Older Node.JS wrappers: User Dennis.K published a NPM package for the OCR API and Anthony Luzquiños released an updated NPM package for the OCR API.
Jquery
This is a JQuery example showing how to make a request to the api using AJAX and get the image results for processing.
Free Online OCR Convert JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu to Text
Free OCR API
What is REST API
To make it simple, REST API defines a set of functions to which the develo3 can perform requests and receive responses. The interaction is performed via the HTTP protocol. An advantage of such an approach is the wide usage of HTTP. That is why REST API can be used practically for any programming language.
Common characteristics of Newocr.com REST API resources are as follows:
How to use API
Authentication
Authentication in API is realized using keys. The API key is provided for every request and is passed as a query string parameter. Request your free personal API key by filling form at the bottom of this page.
Upload Files
You can upload JPEG, PNG, GIF, BMP and multipage TIFF, PDF, DJVU files.
To use multipart upload, make a POST request to the method’s /v1/upload URI and add the query parameter key=api_key, for example:
If the request succeeds, the server returns the HTTP 200 OK status code along with any metadata:
Example: Curl upload
Example: PHP upload
After uploading the file, you can recognize the page.
To use OCR, make a GET request to the method’s /v1/ocr URI and add the query parameters, for example:
If the request succeeds, the server returns the HTTP 200 OK status code along with any metadata:
Query parameters
afr amh ara asm aze aze_cyrl bel ben bod bos bre bul cat ceb ces chi_sim chi_sim_vert chi_tra chi_tra_vert chr cym dan dan_frak deu deu_frak dzo ell eng enm epo equ est eus fas fin fra frk frm gle glg grc guj hat heb hin hrv hun iku ind isl ita ita_old jav jpn jpn_vert kan kat kat_old kaz khm kir kor kor_vert kur kur_ara lao lat lav lit ltz mal mar mkd mlt mon mri msa mya nep nld nor oci ori pan pol por pus que ron rus san sin slk slk_frak slv snd spa spa_old sqi srp srp_latn sun swa swe syr tam tat tel tgk tgl tha tir ton tur uig ukr urd uzb uzb_cyrl vie yid yor
Example: Curl
Example: PHP
API key status
To get the status of your API key, make a GET request to the method’s /v1/key/status URI and add the query parameters, for example:
If the request succeeds, the server returns the HTTP 200 OK status code along with any metadata:
Price and Payment
You can recognize 20 images (pages) for free.
If you want to recognize more, please purchase the paid version of the key.
You can pay by PayPal to admin@newocr.com and then email us your API key, and amount you paid
Please contact us about acquiring of paid key by filling the form below.
1. Do you store documents in your servers?
We do not store any docs/images on our servers, as explained in our privacy policy.
2. Is this service available 24/7?
3. Is it possible to use the free service in a commercial project?
Yes, you can use the free API in a commercial project, but it comes with no (uptime) guarantees.
4. What is the difference between the free OCR API and the commercial version?
5. What happens if you miss your 100% uptime guarantee?
6. What happens if I am unhappy with the PRO account for a reason other than uptime?
Please contact us. If we can not fix the issue, we will refund you the current month in full.
7. Do you store my credit card on your servers?
8. What are the URLs of the commercial OCR API access points?
You will receive the URLs of the three global access points and your API key in the welcome email directly after you have signed-up for the PRO or PRO PDF account.
9. Where are the access points located?
The free OCR API access point is in the EU, and the commercial version has also access points in the US and Asia. If you need a specific location, just let us know.
10. I am an indie developer. I am looking for a free/low cost OCR solution.
You found the right place 🙂
11. Would it be possible for you to alert me of an upcoming planned downtime?
Yes. There are two methods to get alerted: Follow us on twitter or register for the Free OCR API level. We email all registered users if a planned downtime is coming up.
12. I’m getting the message that the API key is invalid. Does it take a while until it is active?
13. If your question is not answered here.
Краткое руководство. Использование клиентской библиотеки оптического распознавания символов (OCR) или REST API
Начало работы с Компьютерное зрение чтения REST API или клиентских библиотек. Служба чтения предоставляет алгоритмы искусственного интеллекта для извлечения видимого текста из изображений и его возврата в виде структурированных строк. Выполните приведенные здесь действия, чтобы установить пакет SDK для приложения и протестировать пример кода для выполнения базовых задач.
Используйте клиентскую библиотеку OCR для чтения печатного и рукописного текста на изображениях.
Предварительные требования
Настройка
Создание нового приложения C#
Установка клиентской библиотеки
Измените каталог на созданную папку приложения. Чтобы создать приложение, выполните следующую команду:
Выходные данные сборки не должны содержать предупреждений или ошибок.
Установка клиентской библиотеки
Хотите просмотреть готовый файл с кодом для этого краткого руководства? Его можно найти на сайте GitHub, где размещены примеры кода для этого краткого руководства.
В каталоге проекта откройте файл Program.cs в предпочитаемом редакторе или интегрированной среде разработки.
Поиск ключа подписки и конечной точки
Перейдите на портал Azure. Если ресурс Компьютерного зрения, созданный с учетом предварительных требований, успешно развернут, нажмите кнопку Перейти к ресурсу в разделе Дальнейшие действия. Ключ подписки и конечную точку можно найти на странице Ключи и конечная точка ресурса в разделе Управление ресурсами.
Не забудьте удалить ключ подписки из кода, когда закончите, и никогда не публикуйте его в открытом доступе. Для рабочей среды рекомендуется использовать безопасный способ хранения и доступа к учетным данным. Например, хранилище ключей Azure.
В методе Main приложения добавьте вызовы методов, используемых в этом кратком руководстве. Они будут созданы позже.
Объектная модель
| Имя | Описание |
|---|---|
| ComputerVisionClient | Этот класс требуется для всех функций Компьютерного зрения. Вы создаете его экземпляр с информацией о подписке и используете его для выполнения большинства операций с образами. |
| ComputerVisionClientExtensions | Этот класс содержит дополнительные методы для ComputerVisionClient. |
Примеры кода
Аутентификация клиента
Чтение печатного и рукописного текста
Кроме того, можно извлечь текст из локального образа. Изучите информацию о методах класса ComputerVisionClient, например о ReadInStreamAsync. Либо просмотрите пример кода на GitHub для сценариев, включающих использование локальных изображений.
Настройка тестового изображения
В классе Program сохраните ссылку на URL-адрес изображения, из которого вы хотите извлечь текст. Этот фрагмент кода включает в себя примеры изображений печатного и рукописного текста.
Вызов API чтения
Определите новый метод для чтения текста. Добавьте приведенный ниже код, который вызывает метод ReadAsync для заданного изображения. Он возвращает идентификатор операции и запускает асинхронный процесс чтения содержимого образа.
Получение результатов чтения
Затем получите идентификатор операции, возвращенный из вызова ReadAsync, и получите от службы результаты операции по этому идентификатору. Следующий код проверяет операцию, пока не будут возвращены результаты. После этого извлеченные текстовые данные выводятся на консоль.
Отображение результатов чтения
Добавьте следующий код для анализа и отображения полученных текстовых данных и завершения определения метода.
Выполнение приложения
Запустите приложение, нажав кнопку Отладка в верхней части окна интегрированной среды разработки.
Очистка ресурсов
Если вы хотите очистить и удалить подписку Cognitive Services, вы можете удалить ресурс или группу ресурсов. При этом удаляются все ресурсы, связанные с ней.
Дальнейшие действия
Из этого краткого руководства вы узнали, как установить клиентскую библиотеку OCR и использовать API чтения. Теперь ознакомьтесь с дополнительными сведениями о функциях API чтения.
Используйте клиентскую библиотеку оптического распознавания символов для чтения печатных и рукописных текстов с помощью API чтения.
Предварительные требования
Получив подписку Azure, создайте ресурс Компьютерного зрения на портале Azure, чтобы получить ключ и конечную точку. После развертывания щелкните Перейти к ресурсам.
Настройка
Установка клиентской библиотеки
Клиентскую библиотеку можно установить с помощью следующей команды:
Также установите библиотеку Pillow.
Создание приложения Python
Хотите просмотреть готовый файл с кодом для этого краткого руководства? Его можно найти на сайте GitHub, где размещены примеры кода для этого краткого руководства.
Создайте файл Python, например quickstart-file.py. Затем откройте его в предпочитаемом редакторе или интегрированной среде разработки.
Поиск ключа подписки и конечной точки
Перейдите на портал Azure. Если ресурс Компьютерного зрения, созданный с учетом предварительных требований, успешно развернут, нажмите кнопку Перейти к ресурсу в разделе Дальнейшие действия. Ключ подписки и конечную точку можно найти на странице Ключи и конечная точка ресурса в разделе Управление ресурсами.
Не забудьте удалить ключ подписки из кода, когда закончите, и никогда не публикуйте его в открытом доступе. Для рабочей среды рекомендуется использовать безопасный способ хранения и доступа к учетным данным. Например, хранилище ключей Azure.
Объектная модель
Следующие классы и интерфейсы обрабатывают некоторые основные функции пакета SDK OCR для Python.
| Имя | Описание |
|---|---|
| ComputerVisionClientOperationsMixin | Этот класс напрямую обрабатывает все операции с изображениями, такие как анализ изображений, обнаружение текста и создание эскизов. |
| ComputerVisionClient | Этот класс требуется для всех функций Компьютерного зрения. Вы создаете его экземпляр с информацией о подписке и используете его для создания экземпляров других классов. Он реализует ComputerVisionClientOperationsMixin. |
| VisualFeatureTypes | Это перечисление определяет различные типы анализа изображений, которые можно выполнить в стандартной операции анализа. Набор значений VisualFeatureTypes указывается в зависимости от потребностей. |
Примеры кода
В следующих фрагментах кода показано выполнение следующих действий с помощью клиентской библиотеки OCR для Python:
Аутентификация клиента
Создайте экземпляр клиента с конечной точкой и ключом. Создайте объект CognitiveServicesCredentials с помощью своего ключа и используйте его с вашей конечной точкой для создания объекта ComputerVisionClient.
Чтение печатного и рукописного текста
Служба OCR может считывать видимый текст в образе и преобразовывать его в поток символов. Это необходимо выполнять двумя частями.
Вызов API чтения
Сначала выполните следующий код, чтобы вызвать метод read для предоставленного изображения. Он возвращает идентификатор операции и запускает асинхронный процесс чтения содержимого образа.
Кроме того, вы можете прочитать текст из локального образа. Изучите информацию о методах класса ComputerVisionClientOperationsMixin, например read_in_stream. Либо просмотрите пример кода на GitHub для сценариев, включающих использование локальных изображений.
Получение результатов чтения
Затем получите идентификатор операции, возвращенный из вызова read, и получите от службы результаты операции по этому идентификатору. Следующий код проверяет операцию с интервалами в одну секунду, пока не будут возвращены результаты. После этого извлеченные текстовые данные выводятся на консоль.
Выполнение приложения
Запустите приложение, выполнив команду python для файла quickstart.
Очистка ресурсов
Если вы хотите очистить и удалить подписку Cognitive Services, вы можете удалить ресурс или группу ресурсов. При этом удаляются все ресурсы, связанные с ней.
Дальнейшие действия
Из этого краткого руководства вы узнали, как установить клиентскую библиотеку OCR и использовать API чтения. Теперь ознакомьтесь с дополнительными сведениями о функциях API чтения.
Используйте клиентскую библиотеку оптического распознавания символов для чтения печатных и рукописных текстов в изображениях.
Предварительные требования
Настройка
Создание проекта Gradle
В окне консоли (например, cmd, PowerShell или Bash) создайте новый каталог для приложения и перейдите в него.
Выполните команду gradle init из рабочей папки. Эта команда создает необходимые файлы сборки для Gradle, включая build.gradle.kts, который используется во время выполнения для создания и настройки приложения.
Когда появится запрос на выбор предметно-ориентированного языка, выберите Kotlin.
Установка клиентской библиотеки
В этом кратком руководстве используется диспетчер зависимостей Gradle. Клиентскую библиотеку и информацию для других диспетчеров зависимостей можно найти в центральном репозитории Maven.
Найдите файл build.gradle.kts и откройте его в предпочитаемой интегрированной среде разработки или текстовом редакторе. Затем скопируйте и вставьте в файл приведенную ниже конфигурацию сборки. Эта конфигурация определяет проект как приложение Java, точкой входа которого является класс ComputerVisionQuickstart. Он импортирует библиотеку Компьютерного зрения.
Создание файла Java
В рабочей папке выполните следующую команду, чтобы создать исходную папку проекта.
Хотите просмотреть готовый файл с кодом для этого краткого руководства? Его можно найти на сайте GitHub, где размещены примеры кода для этого краткого руководства.
Перейдите в новую папку и создайте файл с именем ComputerVisionQuickstart.java. Откройте его в предпочитаемом редакторе или интегрированной среде разработки.
Поиск ключа подписки и конечной точки
Перейдите на портал Azure. Если ресурс Компьютерного зрения, созданный с учетом предварительных требований, успешно развернут, нажмите кнопку Перейти к ресурсу в разделе Дальнейшие действия. Ключ подписки и конечную точку можно найти на странице Ключи и конечная точка ресурса в разделе Управление ресурсами.
Не забудьте удалить ключ подписки из кода, когда закончите, и никогда не публикуйте его в открытом доступе. Для рабочей среды рекомендуется использовать безопасный способ хранения и доступа к учетным данным. Например, хранилище ключей Azure.
В методе main приложения добавьте вызовы методов, используемых в этом кратком руководстве. Они будут определены позже.
Объектная модель
Следующие классы и интерфейсы обрабатывают некоторые основные функции пакета SDK для OCR Java.
| Имя | Описание |
|---|---|
| ComputerVisionClient | Этот класс требуется для всех функций Компьютерного зрения. Вы создаете его экземпляр с информацией о подписке и используете его для создания экземпляров других классов. |
Примеры кода
Эти фрагменты кода демонстрируют выполнение следующих действий с помощью клиентской библиотеки оптического распознавания символов для Java:
Аутентификация клиента
В новом методе создайте экземпляр объекта ComputerVisionClient с использованием конечной точки и ключа.
Чтение печатного и рукописного текста
Кроме того, вы можете считать текст на удаленном изображении, на которое ссылается URL-адрес. См. подробные сведения о методах ComputerVision, например read. Пример кода для сценариев, в которых используются удаленные изображения, см. на сайте GitHub.
Настройка тестового изображения
Создайте папку resources/ в папке src/main/ вашего проекта и добавьте изображение, на котором нужно прочесть текст. Вы можете скачать пример изображения для использования.
Затем добавьте приведенное ниже определение метода в класс ComputerVisionQuickstart. Измените значение localFilePath в соответствии с вашим файлом изображения.
Вызов API чтения
Затем добавьте следующий код, чтобы вызвать метод readInStreamWithServiceResponseAsync для данного изображения.
Следующий блок кода извлекает идентификатор операции из ответа на вызов Read. Он использует этот идентификатор со вспомогательным методом для вывода результатов чтения текста на консоль.
Закройте блок try-catch и определение метода.
Получение результатов чтения
Затем добавьте определение для вспомогательного метода. Этот метод использует идентификатор операции из предыдущего шага для запроса операции чтения и получения результатов распознавания текста, когда они доступны.
Остальная часть метода анализирует результаты распознавания текста и выводит их на консоль.
Наконец, добавьте другой вспомогательный метод, который использовался выше, который извлекает идентификатор операции из начального ответа.
Выполнение приложения
Чтобы создать приложение, выполните следующую команду:
Запустите приложение, выполнив команду gradle run :
Очистка ресурсов
Если вы хотите очистить и удалить подписку Cognitive Services, вы можете удалить ресурс или группу ресурсов. При этом удаляются все ресурсы, связанные с ней.
Дальнейшие действия
Из этого краткого руководства вы узнали, как установить клиентскую библиотеку OCR и использовать API чтения. Теперь ознакомьтесь с дополнительными сведениями о функциях API чтения.
Используйте клиентскую библиотеку оптического распознавания символов для чтения печатных и рукописных текстов с помощью API чтения.
Предварительные требования
Настройка
создание приложения Node.js;
В окне консоли (например, cmd, PowerShell или Bash) создайте новый каталог для приложения и перейдите в него.
Установка клиентской библиотеки
Установите ms-rest-azure и пакет NPM @azure/cognitiveservices-computervision :
Установите также модуль async:
Файл package.json этого приложения будет дополнен зависимостями.
Хотите просмотреть готовый файл с кодом для этого краткого руководства? Его можно найти на сайте GitHub, где размещены примеры кода для этого краткого руководства.
Создайте новый файл, index. js и откройте его в текстовом редакторе.
Поиск ключа подписки и конечной точки
Перейдите на портал Azure. Если ресурс Компьютерного зрения, созданный с учетом предварительных требований, успешно развернут, нажмите кнопку Перейти к ресурсу в разделе Дальнейшие действия. Ключ подписки и конечную точку можно найти на странице Ключи и конечная точка ресурса в разделе Управление ресурсами.
Не забудьте удалить ключ подписки из кода, когда закончите, и никогда не публикуйте его в открытом доступе. Для рабочей среды рекомендуется использовать безопасный способ хранения и доступа к учетным данным. Например, хранилище ключей Azure.
Объектная модель
Следующие классы и интерфейсы обрабатывают некоторые основные функции пакета SDK для OCR Node.js.
| Имя | Описание |
|---|---|
| ComputerVisionClient | Этот класс требуется для всех функций Компьютерного зрения. Вы создаете его экземпляр с информацией о подписке и используете его для выполнения большинства операций с образами. |
Примеры кода
В следующих фрагментах кода показано выполнение следующих действий с помощью клиентской библиотеки OCR для Node.js:
Аутентификация клиента
Создайте экземпляр клиента с конечной точкой и ключом. Создайте объект ApiKeyCredentials с помощью своего ключа и конечной точкой для создания объекта ComputerVisionClient.
Затем определите функцию computerVision и объявите асинхронный ряд с первичной функцией и функцией обратного вызова. В конце скрипта вы заполните это определение функции и вызовите ее.
Чтение печатного и рукописного текста
Служба OCR может извлекать видимый текст на изображении и преобразовывать его в поток символов. В этом примере используются операции чтения.
Настройка тестовых изображений
Сохраните ссылку на URL-адрес изображений, из которых вы хотите извлечь текст.
Кроме того, вы можете прочитать текст из локального образа. См. подробные сведения о методах ComputerVisionClient, например readInStream. Либо просмотрите пример кода на GitHub ля сценариев, включающих использование локальных изображений.
Вызов API чтения
Определите следующие поля в функции, чтобы обозначить значения состояния вызова Read.
Добавьте приведенный ниже код, который вызывает функцию readTextFromURL для заданных изображений.
Закрытие функции
Завершите задание функции computerVision и вызовите ее.
Выполнение приложения
Запустите приложение, выполнив команду node для файла quickstart.
Очистка ресурсов
Если вы хотите очистить и удалить подписку Cognitive Services, вы можете удалить ресурс или группу ресурсов. При этом удаляются все ресурсы, связанные с ней.
Дальнейшие действия
Из этого краткого руководства вы узнали, как установить клиентскую библиотеку OCR и использовать API чтения. Теперь ознакомьтесь с дополнительными сведениями о функциях API чтения.
Используйте клиентскую библиотеку OCR для чтения печатного и рукописного текста на изображениях.
Предварительные требования
Настройка
Создание каталога проекта Go
Рабочая область будет содержать три папки:
Установка клиентской библиотеки для Go
Далее, установите клиентскую библиотеку для Go:
Или, если вы используете dep, выполните в репозитории такую команду:
Создание приложения Go.
Хотите просмотреть готовый файл с кодом для этого краткого руководства? Его можно найти на сайте GitHub, где размещены примеры кода для этого краткого руководства.
Откройте sample-app.go в любой среде разработки или текстовом редакторе.
Объявите контекст в корне скрипта. Этот объект потребуется для выполнения большинства вызовов функции Компьютерного зрения.
Поиск ключа подписки и конечной точки
Перейдите на портал Azure. Если ресурс Компьютерного зрения, созданный с учетом предварительных требований, успешно развернут, нажмите кнопку Перейти к ресурсу в разделе Дальнейшие действия. Ключ подписки и конечную точку можно найти на странице Ключи и конечная точка ресурса в разделе Управление ресурсами.
Не забудьте удалить ключ подписки из кода, когда закончите, и никогда не публикуйте его в открытом доступе. Для рабочей среды рекомендуется использовать безопасный способ хранения и доступа к учетным данным. Например, хранилище ключей Azure.
Далее вы будете добавлять код для выполнения различных операций OCR.
Объектная модель
Следующие классы и интерфейсы обрабатывают некоторые основные функции пакета SDK OCR для Go.
| Имя | Описание |
|---|---|
| BaseClient | Этот класс необходим для всех функций службы «Компьютерное зрение», как, например, анализ изображений и чтение текста. Вы создаете его экземпляр с информацией о подписке и используете его для выполнения большинства операций с образами. |
| ReadOperationResult | Этот тип содержит результаты операции пакетной службы чтения. |
Примеры кода
В следующих фрагментах кода показано выполнение следующих действий с помощью клиентской библиотеки OCR для Go:
Аутентификация клиента
В этом шаге предполагается, что вы уже создали переменные среды для ключа и конечной точки службы «Компьютерного зрения» с именами COMPUTER_VISION_SUBSCRIPTION_KEY и COMPUTER_VISION_ENDPOINT соответственно.
Создайте функцию main и добавьте в нее следующий код, чтобы создать экземпляр клиента с конечной точкой и ключом.
Чтение печатного и рукописного текста
Кроме того, можно извлечь текст из локального образа. Изучите информацию о методах класса BaseClient, например о BatchReadFileInStream. Либо просмотрите пример кода на GitHub для сценариев, включающих использование локальных изображений.
Вызов API чтения
Получение результатов чтения
Затем получите идентификатор операции, возвращенный из вызова BatchReadFile, и используйте его с методом GetReadOperationResult для запроса в службу для результатов операции. Следующий код проверяет операцию с интервалами в одну секунду, пока не будут возвращены результаты. После этого извлеченные текстовые данные выводятся на консоль.
Отображение результатов чтения
Добавьте следующий код для анализа и отображения полученных текстовых данных и завершения определения функции.
Выполнение приложения
Очистка ресурсов
Если вы хотите очистить и удалить подписку Cognitive Services, вы можете удалить ресурс или группу ресурсов. При этом удаляются все ресурсы, связанные с ней.
Дальнейшие действия
Из этого краткого руководства вы узнали, как установить клиентскую библиотеку OCR и использовать API чтения. Теперь ознакомьтесь с дополнительными сведениями о функциях API чтения.
Используйте возможности оптического распознавания символов REST API для чтения печатных и рукописных текстов.
В рамках этого краткого руководства для вызова REST API используются команды cURL. Вы также можете вызывать REST API с помощью языка программирования. Примеры см. в репозиториях GitHub для C#, Python, Java, JavaScript и Go.
Предварительные требования
Извлечение печатного и рукописного текста
Служба OCR может извлекать текст из изображений или документов и преобразовывать его в поток символов. Дополнительные сведения о распознавании текста см. в обзорной статье Оптическое распознавание текста (OCR).
Вызов API чтения
Чтобы создать и запустить пример, сделайте следующее.
Новые ресурсы, созданные после 1 июля 2019 г., будут использовать пользовательские имена поддоменов. Дополнительные сведения и полный список региональных конечных точек см. в статье Custom subdomain names for Cognitive Services (Пользовательские имена поддоменов для Cognitive Services).
Работа с функциями предварительных версий
Узнайте, как указать версию модели, чтобы получить доступ к языкам и функциям в предварительной версии. Модель предварительной версии содержит все улучшения для языков, которые поддерживаются общедоступной версией.
Получение результатов чтения
Изучите ответ.
Успешный ответ будет возвращен в формате JSON. После этого запустится синтаксический анализ примера приложения и в окне командной строки отобразится успешный ответ, аналогичный следующему.
Дальнейшие действия
Из этого краткого руководства вы узнали, как вызывать REST API чтения. Теперь ознакомьтесь с дополнительными сведениями о функциях API чтения.


