Технический аудит сайта при помощи Screaming Frog SEO Spider

Для большинства людей общий аудит сайта – задача достаточно сложная и трудоемкая, однако с такими инструментами, как Screaming Frog SEO Spider (СЕО Паук) задача может стать значительно более простой как для профессионалов, так и для новичков. Удобный интерфейс Screaming Frog обеспечивает легкую и быструю работу, однако многообразие вариантов конфигурации и функциональности может затруднить знакомство с программой, первые шаги в общении с ней.
Нижеследующая инструкция призвана продемонстрировать различные способы использования Screaming Frog в первую очередь для аудита сайтов, но также и других задач.
Базовые принципы сканирования сайта
Как сканировать весь сайт.
По умолчанию Screaming Frog сканирует только поддомен, на который вы заходите. Любой дополнительный поддомен, с которым сталкивается Spider, рассматривается как внешняя ссылка. Для того чтобы сканировать дополнительные поддомены, необходимо внести корректировки в меню конфигурации Spider. Выбрав опцию «Crawl All Subdomains», вы можете быть уверены в том, что Паук проанализирует любые ссылки, которые встречаются на поддоменах вашего сайта.
Чтобы ускорить сканирование не используйте картинки, CSS, JavaScript, SWF или внешние ссылки.
Как сканировать один каталог.
Если вы хотите ограничить сканирование конкретной папкой, то просто введите URL и нажмите на кнопку «старт», не меняя параметры, установленные по умолчанию. Если вы внесли изменения в предустановленные настройки, то можно сбросить их при помощи меню «File».

Если вы хотите начать сканирование с конкретной папки, а после перейти к анализу оставшейся части поддомена, то перед тем, как начать работу с нужным вам URL, перейдите сначала в раздел Spider под названием «Configuration» и выберите в нем опцию «Crawl Outside Of Start Folder».
Как сканировать набор определеных поддоменов или подкатологов.
Чтобы взять в работу конкретный список поддоменов или подкатологов вы можете использовать RegEx, чтобы задать правила включения (Include settings) или исключения (Exclude settings) определенных элементов в меню «Configuration».

На показанном ниже примере были выбраны для сканирования все страницы сайта havaianas.com, кроме страниц «About» в каждом отдельном поддомене (исключение). Следующий пример показывает как можно просканировать именно англоязычные страницы поддоменов этого же сайта (включение).
Если требуется просканировать список всех страниц моего сайта.
По умолчанию, Screaming Frog сканирует все изображения JavaScript, CSS и флеш-файлы, с которыми сталкивается Паук. Чтобы анализировать исключительно HTML, вам нужно снять галочку с опций «Check Images», «Check CSS», «Check JavaScript» и «Check SWF» в меню «Configuration» Spider. Запуск Паука будет совершаться без учета указанных позиций, что позволит вам получить список всех страниц сайта, на которые имеются внутренние ссылки. После завершения сканирования перейдите во вкладку «Internal» и отфильтруйте результаты по стандарту HTML. Кликните по кнопке «Export», чтобы получить полный список в формате CSV.
Совет: Если вы намерены использовать заданные настройки для последующих сканирований, то Screaming Frog предоставит вам возможность сохранить заданные опции.
Если требуется просканировать список всех страниц в определенном подкаталоге.
В дополнение к «Check Images», «Check CSS», «Check JavaScript» и «Check SWF» в меню «Configuration» Spider вам нужно будет выбрать «Check Links Outside Folder». То есть вы исключите данные опции из Паука, что предоставит вам список всех страниц выбранной папки.
Если требуется просканировать список доменов, которые ваш клиент только что перенаправил на свой коммерческий сайт.
В ReverseInter.net добавьте URL этого сайта, после нажмите ссылку в верхней таблице, чтобы найти сайты, использующие те же IP-адрес, DNS-сервер, или код GA.
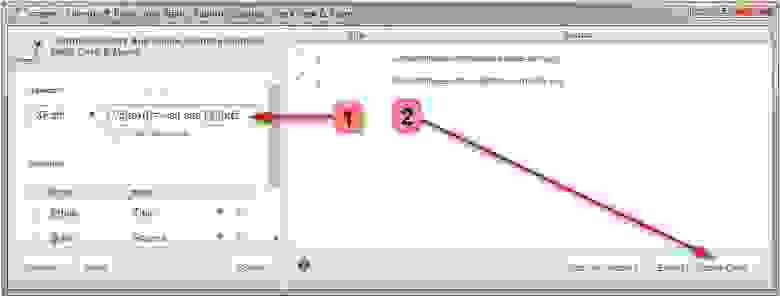
Далее используя расширение для Google Chrome под названием Scraper, вы сможете найти список всех ссылок с анкором «посетить сайт». Если Scraper уже установлен, то вы можете запустить его, кликнув кнопкой мыши в любом месте страницы и выбрав пункт «Scrape similar». Во всплывающем окне вам нужно будет изменить XPath-запрос на следующее:
//a[text()=’visit site’]/@href.
Далее этот список вы сможете загрузить в Spider и запустить сканирование. Когда Spider закончит работу, вы увидите соответствующий статус во вкладке «Internal». Либо же вы можете зайти в «Response Codes» и при помощи позиции «Redirection» отфильтровать результаты, чтобы увидеть все домены, которые были перенаправлены на коммерческий сайт или куда-либо еще.
Совет: Данный метод вы также можете использовать для того, чтобы идентифицировать домены ссылающиеся на конкурентов и выявить, каким образом они были использованы.
Как найти все поддомены сайта и проверить внутренние ссылки.
Внесите в ReverseInternet корневой URL-адрес домена, после кликните по вкладке «Subdomains», чтобы увидеть список поддоменов.
После этого задействуйте Scrape Similar, чтобы собрать список URL, используя запрос XPath:
Как сканировать коммерческий или любой другой большой сайт.
Screaming Frog не предназначена для того, чтобы сканировать сотни тысяч страниц, однако имеется несколько мер, позволяющих предотвратить сбои в программе при сканировании больших сайтов. Во-первых, вы можете увеличить объем памяти, используемой Пауком. Во-вторых, вы можете отключить сканирование подкаталога и работать лишь с определенными фрагментами сайта, задействуя инструменты включения и исключения. В-третьих, вы можете отключить сканирование изображений, JavaScript, CSS и флеш-файлов, сделав акцент на HTML. Это сбережет ресурсы памяти.
Совет: Если раньше при сканировании больших сайтов требовалось ждать весьма долго окончания выполнения операции, то Screaming Frog позволяет ставить паузу на процедуру использования больших объемов памяти. Эта ценнейшая опция позволяет вам сохранить уже полученные результаты до того момента, когда программа предположительно готова дать сбой, и увеличить размеры памяти.
На данный момент такая опция подключена по умолчанию, но если вы планируете сканировать большой сайт, то лучше все же убедиться, что в меню конфигурации Паука, во вкладке «Advanced» стоит галочка в поле «Pause On High Memory Usage».
Как сканировать сайт, размещенный на старом сервере.
В некоторых случаях старые серверы могут оказаться неспособны обрабатывать заданное количество URL-запросов в секунду. Чтобы изменить скорость сканирования в меню «Configuration» откройте раздел «Speed» и во всплывающем окне выберите максимальное число потоков, которые должны быть задействованы одновременно. В этом меню вы также можете выбрать максимальное количество URL-адресов, запрашиваемых в секунду.
Совет: Если в результатах сканирования вы обнаружите большое количество ошибок сервера, перейдите во вкладку «Advanced» в меню конфигурации Паука и увеличите значение времени ожидания ответа (Response Timeout) и число новых попыток запросов (5xx Response Retries). Это позволит получать лучшие результаты.
Как сканировать сайт, который требует cookies.
Хотя поисковые роботы не принимают cookies, если при сканировании сайта вам требуется разрешить cookies, то просто выберите «Allow Cookies» во вкладке «Advanced» меню «Configuration».
Как сканировать сайт, используя прокси или другой пользовательский агент.
В меню конфигурации выберите «Proxy» и внесите соответствующую информацию. Чтобы сканировать, задействуя иной агент, выберите в меню конфигурации «User Agent», после из выпадающего меню выберите поисковый бот или введите его название.
Как сканировать сайты, требующие авторизации.
Когда Паук Screaming Frog заходит на страницу, запрашивающую идентификацию, всплывает окно, в котором требуется ввести логин и пароль.
Для того чтобы впредь обходиться без данной процедуры, в меню конфигурации, во вкладке «Advanced» снимите флажок с опции «Request Authentication».
Внутренние ссылки
Что делать, когда требуется получить информацию о внешних и внутренних ссылках сайта (анкорах, директивах, перелинковке и пр.).
Если вам не нужно проверять на сайте изображения, JavaScript, Flash или CSS, то исключите эти опции из режима сканирования, чтобы сберечь ресурсы памяти.
После завершения Пауком сканирования, используйте меню «Advanced Export», чтобы из базы «All Links» экспортировать CSV. Это предоставит вам все ссылочные локации и соответствующие им анкорные вхождения, директивы и пр.
Для быстрого подсчета количества ссылок на каждой странице перейдите во вкладку «Internal» и отсортируйте информацию через опцию «Outlinks». Все, чтобы будет выше 100-ой позиции, возможно, потребует дополнительного внимания.
Как найти неработающие внутренние ссылки на страницу или сайт.
Как и всегда, не забудьте исключить изображения, JavaScript, Flash или CSS из объектов сканирования, дабы оптимизировать процесс.
После окончания сканировния Пауком, отфильтруйте результаты панели «Internal» через функцию «Status Code». Каждый 404-ый, 301-ый и прочие коды состояния будут хорошо просматриваться.
При нажатии на каждый отдельный URL в результатах сканирования в нижней части окна программы вы увидите информацию. Нажав в нижнем окне на «In Links», вы найдете список страниц, ссылающихся на выбранный URL-адрес, а также анкорные вхождения и директивы, используемые на этих страницах. Используйте данную функцию для выявления внутренних ссылок, требующих обновления.
Чтобы экспортировать в CSV формате список страниц, содержащих битые ссылки или перенаправления, используйте в меню «Advanced Export» опцию «Redirection (3xx) In Links» или «Client Error (4xx) In Links», либо «Server Error (5xx) In Links».
Как выявить неработающие исходящие ссылки на странице или сайте (или все битые ссылки одновременно).
Аналогично делаем сначала акцент на сканировании HTML-содержимого, не забыв при этом оставить галочку в пункте «Check External Links».
По завершении сканирования выберите в верхнем окне вкладку «External» и при помощи «Status Code» отфильтруйте содержимое, чтобы определить URL с кодами состояния, отличными от 200. Нажмите на любой отдельный URL-адрес в результатах сканирования и после выберите вкладку «In Links» в нижнем окне – вы найдете список страниц, которые указывают на выбранный URL. Используйте эту информацию для выявления ссылок, требующих обновления.
Чтобы экспортировать полный список исходящих ссылок, нажмите на «Export» во вкладке «Internal». Вы также можете установить фильтр, чтобы экспортировать ссылки на внешние изображения, JavaScript, CSS, Flash и PDF. Чтобы ограничить экспорт только страницами, сортируйте посредством опции «HTML».
Чтобы получить полный список всех локаций и анкорных вхождений исходящих ссылок, выберите в меню «Advanced Export» позицию «All Out Links», а после отфильтруйте столбец «Destination» в экспортируемом CSV, чтобы исключить ваш домен.
Как найти перенаправляющие ссылки.
По завершении сканирования выберите в верхнем окне панель «Response Codes» и после отсортируйте результаты при помощи опции «Redirection (3xx)». Это позволит получить список всех внутренних и исходящих ссылок, которые будут перенаправлять. Применив фильтр «Status Code», вы сможете разбить результаты по типам. При нажатии «In Links» в нижнем окне, вы сможете увидеть все страницы, на которых используются перенаправляющие ссылки.
Если экспортировать информацию прямо из этой вкладки, то вы увидите только те данные, которые отображаются в верхнем окне (оригинальный URL, код состояния и то место, в которое происходит перенаправление).
Чтобы экспортировать полный список страниц, содержащих перенаправляющие ссылки, вам следует выбрать «Redirection (3xx) In Links» в меню «Advanced Export». Это вернет CSV-файл, который включает в себя расположение всех перенаправляющих ссылок. Чтобы показать только внутренние редиректы, отфильтруйте содержимое в CSV-файле с данными о вашем домене при помощи колонки «Destination».
Совет: Поверх двух экспортированных файлов используйте VLOOKUP, чтобы сопоставить столбцы «Source» и «Destination» с расположением конечного URL-адреса.
Пример формулы выглядит следующим образом:
=VLOOKUP([@Destination],’response_codes_redirection_(3xx).csv’!$A$3:$F$50,6,FALSE). Где «response_codes_redirection_(3xx).csv» — это CSV-файл, содержащий перенаправляющие URL-адреса и «50» — это количество строк в этом файле.
Контент сайта
Как идентифицировать страницы с неинформативным содержанием (т.н. «thin content» − «токний контент»).
После завершения работы Spider перейдите в панель «Internal», задав фильтрацию по HTML, а после прокрутите вправо к столбцу «Word Count». Отсортируйте содержимое страниц по принципу количества слов, чтобы выявить те, на которых текста меньше всего. Можете перетащить столбец «Word Count» влево, поместив его рядом с соответствующими URL-адресами, сделав информацию более показательной. Нажмите на кнопку «Export» во вкладке «Internal», если вам удобнее работать с данными в формате CSV.
Помните, что Word Count позволяет оценить объем размещенного текста, однако не дает решительно никаких сведений о том, является ли этот текст просто названиями товаров/услуг или оптимизированным под ключевые слова блоком.
Если требуется выделить с конкретных страниц список ссылок на изображения.
Если вы уже просканировали весь сайт или отдельную папку, то просто выберите страницу в верхнем окне, после нажмите «Image Info» в нижнем окне, чтобы просмотреть изображения, которые были найдены на этой странице. Картинки будут перечисляться в столбце «To».
Совет: Щелкните правой кнопкой мыши на любую запись в нижнем окне, чтобы скопировать или открыть URL-адрес.
Вы можете просматривать изображения на отдельно взятой странице, сканируя именно этот URL-адрес. Убедитесь, что глубина сканирования в настройках конфигурации сканирования Паука имеет значение «1». После того, как страница просканируется, перейдите во вкладку «Images», и вы увидите все изображения, которые удалось обнаружить Spider.
Наконец, если вы предпочитаете CSV, используйте меню «Advanced Export», опцию «All Image Alt Text», чтобы увидеть список всех изображений, их местоположение и любой связанный с ними замещающий текст.
Как найти изображения, у которых отсутствует замещающий текст или изображения, имеющие длинный Alt-текст.
Прежде всего, вам нужно убедиться, что в меню Паука «Configuration» выбрана позиция «Check Images». По завершении сканирования перейдите во вкладку «Images» и отфильтруйте содержимое при помощи опций «Missing Alt Text» или «Alt Text Over 100 Characters». Нажав на вкладку «Image Info» в нижнем окне, вы найдете все страницы, на которых размещаются хотя бы какие-нибудь изображения. Страницы будут перечислены в столбце «From».

Вместе с тем, в меню «Advanced Export» вы можете сэкономить время и экспортировать «All Image Alt Text» (Все картинки, весь текст) или «Images Missing Alt Text» (Картинки без Alt-тега) в формат CSV.
Как найти на сайте каждый CSS-файл.
В меню конфигурации Паука перед сканированием выберите «Check CSS». По окончании процесса отфильтруйте результаты анализа в панели «Internal» при помощи опции «CSS».

Как найти файлы JavaScript.
В меню конфигурации Паука перед сканированием выберите «Check JavaScript». По окончании процесса отфильтруйте результаты анализа в панели «Internal» при помощи опции «JavaScript».
Как выявить все плагины jQuery, использованные на сайте, и их местоположение.
Прежде всего, убедитесь, что в меню конфигурации выбрано «Check JavaScript». По завершении сканирования примените в панели «Internal» фильтр «JavaScript», а после сделайте поиск «jQuery». Это позволит вам получить список файлов с плагинами. Отсортируйте перечень по опции «Address» для более удобного просмотра. Затем просмотрите «InLinks» в нижнем окне или экспортируйте информацию в CSV. Чтобы найти страницы, на которых используются файлы, поработайте со столбиком «From».
Вместе с этим, вы можете использовать меню «Advanced Export», чтобы экспортировать «All Links» в CSV и отфильтровать столбец «Destination», дабы просматривать исключительно URL-адреса с «jquery».
Совет: Плохими для СЕО являются не только все плагины jQuery. Если вы видите сайт, использующий jQuery, то разумно будет убедиться, что контент, который вы собираетесь проиндексировать, включен в исходный код страницы и выдается при загрузке страницы, а не после этого. Если вы не уверены в данном аспекте, то почитайте о плагине в интернете, чтобы побольше узнать о том, как он работает.
Как определить, где на сайте размещается flash.
Перед сканированием в меню конфигурации выберите «Check SWF». А по завершении работы Паука отфильтруйте результаты в панели «Internal» по значению «Flash».

Как найти на сайте внутренние PDF-документы.
После завершения сканирования отфильтруйте результаты работы Spider при помощи опции «PDF» в панели «Internal».
Как выявить сегментацию контента в пределах сайта или группы страниц.
Если вы хотите найти на сайте страницы, содержащие необычный контент, установите пользовательский фильтр, выявляющий печати HTML, не свойственные данной странице. Сделано это должно быть до запуска Паука.
Как найти страницы, имеющие кнопки социального обмена.
Для этого перед запуском Паука нужно будет установить пользовательский фильтр. Для его установки перейдите в меню конфигурации и нажмите «Custom». После этого введите любой фрагмент кода из исходного кода страницы.
Non-Indexable Pages
Non-indexable pages are pages that cannot be indexed by Google, in terms of the checks we perform these are pages that either have a noindex tag present and / or are disallowed from the robots.txt file.
Use this data to make sure that the content you want to be indexed can be indexed. Check out the video below for a short summary of what crawl data means.
Why Are URLs Not Indexable
There are several reasons why a page is not indexable, we cover all of these in this section. Pages that were once indexed but have had something implemented to prevent them from being indexed may take some time to be deindexed. Google needs to crawl a page or find a file and determine that it has changed before removing from its index.
NOINDEX TAG (Meta Robots Tag)
A meta robots tag is a page level tag that is added the head section of the source code … and these control aspects of indexation among other things. Adding a noindex meta robots tag to a page with prevent Google from indexing the page. They do however have to crawl the page to identify the tag.
The no index tag looks like this:
To prevent only Google web crawlers from indexing a page, you use the following met robots tag:
Disallow in Robots.txt
The robots.txt file primarily controls which content should be crawled by search engines and robots. This is not always obeyed by all web crawlers, but Google typically will obey this file. You can see an example of this on our site here robots.txt
The robots.txt file is just a plain text just file, the format for disallow looks like this:
User-agent: [user-agent name]
Disallow: [URL you don’t want crawled]
The specific code for preventing search engines and crawlers from crawling components of your site looks like this:
User-agent: googlebot
Disallow: /directory/page/
There are also many ways to manage this such as using wildcards to prevent any content with a file extension from being indexed.
Canonical Tag (Non-Canonical Page)
Canonical tags determine the canonical or preferred version of content, this is often when content is accessible from multiple URLs and you want to stipulate which is the right one. You can also use a canonical tag to reference another page if that page has been largely or completely copied.
Non-canonical pages, which are pages that have a canonical tag link that references another URL are unlikely to be indexed by Google bit this is not always the case. A canonical tag looks like this:
Redirects
There are several redirections such as permanent or temporary but in either case the page is inaccessible and as such will not be indexed by Google. Google will typically index the page being redirected to if that page is indexable.
Inaccessible Pages
Although we just mentioned redirects which are inaccessible, there are also pages which are inaccessible for other reasons such as pages that are broken. A page that returns a 404 status or a 5XX response code will not be indexed by Google because it cannot be accessed.
Flash Content
Flash content although rare nowadays will not be indexed by Google because they cannot read or understand it.
JavaScript Rendering
This is something which is becoming more indexable, but it can still cause the content to be non-indexable.
Content Behind a Login
If you have content that you sell or only want to give access to specific people, putting behind a paywall or a login. Unless the crawler has the login, credentials which Google will not, this content will be non-indexable. A good example of this are the SEO tools that we provide, you need to sign up for this, verify an email and make a password which you use to access the content. This means that all of the tools we have are not indexed by Google.
Why Use Non-Indexable Pages?
There are many reasons why a page is non-indexable. The first is accidental. Misapplying a tag or setting the contents of a tag incorrectly can result in content not being indexed.
Alternatively, you may have content that is used for pad landing pages for AdWords or native advertising, you many have a lot of duplicate content on your site or content accessible from multiple URLs. As such you may want to make this non-indexable to avoid other issues from Google such as duplicate content.
This guide is part of an extensive series of guides covering the data that we show in the summary tab of our SEO reporting feature. The following list of links shows all of the categories of data guides, videos and tutorials that we have. If you have any feedback on this or anything else, please fee free to get in touch:
Raptor is an SEO software provider, helping to automate as much of SEO as possible!


