non-ASCII character
Смотреть что такое «non-ASCII character» в других словарях:
Non-English-based programming languages — are computer programming languages that, unlike better known programming languages, do not use keywords taken from, or inspired by, the English vocabulary. Contents 1 Prevalence of English based programming languages 2 International programming… … Wikipedia
ASCII art — Oldskool or Amiga style Newskool style … Wikipedia
ASCII — American Standard Code for Information Interchange « ASCII » redirige ici. Pour les autres significations, voir ASCII (homonymie) … Wikipédia en Français
Ascii — American Standard Code for Information Interchange « ASCII » redirige ici. Pour les autres significations, voir ASCII (homonymie) … Wikipédia en Français
Character encoding — Special characters redirects here. For the Wikipedia editor s handbook page, see Help:Special characters. A character encoding system consists of a code that pairs each character from a given repertoire with something else, such as a sequence of… … Wikipedia
Character encodings in HTML — For a list of character entity references, see List of XML and HTML character entity references. HTML HTML and HTML5 Dynamic HTML XHTML XHTML Mobile Profile and C HTML Canvas element Character encodings Document Object Model Font family HTML… … Wikipedia
Non-English usage of quotation marks — A Non English usage of quotation marks Punctuation apostrophe ( … Wikipedia
Non-breaking space — In computer based text processing and digital typesetting, a non breaking space or no break space (NBSP) is a variant of the space character that prevents an automatic line break (line wrap) at its position. In certain formats (such as HTML), it… … Wikipedia
Control character — In computing and telecommunication, a control character or non printing character is a code point (a number) in a character set, that does not in itself represent a written symbol. It is in band signaling in the context of character encoding. All … Wikipedia
Escape character — In computing and telecommunication, an escape character is a character which invokes an alternative interpretation on subsequent characters in a character sequence. An escape character is a particular case of metacharacters. Generally, the… … Wikipedia
Steam cannot run from a folder path with non-ASCII characters — как исправить?
Пользователей Стим с каждым годом становится всё больше. Этому поспособствовали разработчики компьютерных игр, которые ограничивают доступ к сети пиратские копии. Есть ряд других причин, но в этой статье мы поговорим о проблемах клиента, с которыми мы часто сталкиваемся. Вы узнаете, как решить ошибку «Steam cannot run from a folder path with non-ASCII characters». 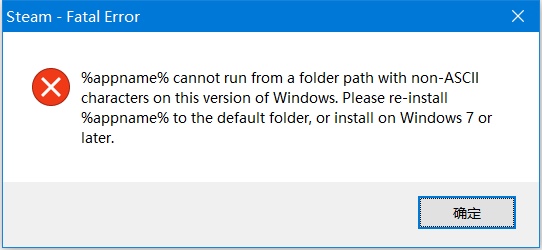
Причина ошибки в Steam
Данная проблема появляется у пользователей сразу после установки клиента популярной игровой библиотеки Steam. Как только мы выбираем иконку на рабочем столе — появляется системное сообщение. Часто в нём описана и причина, и даже решения ошибки. Но запутывает английский язык, который является родным для системы Windows. Есть и русскоязычная версия этого сообщения и оно выглядит приблизительно так: система не может запустить программу из папки, в имени которой есть символы не из английского языка.
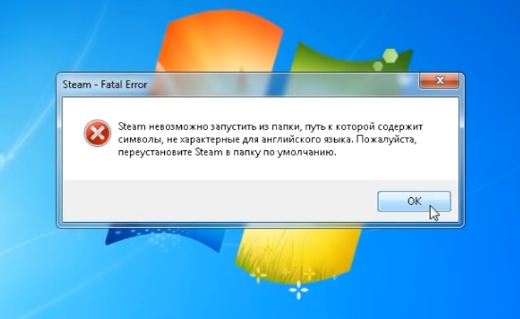
Это значит, что при установке Стима вы указали папку для установки, имя которой на русском. Или по пути к Steam есть такая папка. Запомните — папки в компьютере нужно называть только английскими символами. При этом можно использовать транслитерацию: «Moja Papka» или «Stim». Не исключены и другие причины, которые могут нарушать работу системы и вызывать ошибки.
Как исправить ошибку в Стим
Для того, чтобы исправить ошибку, вы можете попытаться просто переименовать папку на пути к Steam, в которой имя не соответствует требованиям. Есть способы, которые помогут вам быстро определить текущее расположение папки Steam.
Этот путь находится в верхней строке окна. Запомните его или не закрывайте эту папку, чтобы видеть, где она расположена. Чтобы дать папке новое имя, нужно снова нажать ПКМ и выбрать «Переименовать». После этого попробуйте запустить Steam. Если ошибка «Cannot run from a folder path with non-ASCII characters» снова появляется, переходим к следующему способу.
Переустановка Steam
Чтобы вы смогли запустить Стим без ошибок, нужно переустановить клиент. Но сделать это правильно. Каждая система Windows имеет, как правило два локальных диска — один для системы (C), другой для файлов пользователя (D). Это удобно и позволяет не засорять раздел с Виндовс пользовательскими данными. Лучше всего установить новый Стим на не системный том. Но перед установкой нужно удалить старый клиент.
После установки попробуйте запустить клиент. Ошибка не появится, так как в новом пути к файлам библиотеки нет непонятных для системы символов.
Что делать, если ошибка в Steam всё равно появляется
Если решить проблему с запуском Стим не удалось вышеизложенными способами,значит причина не в имени папок. Скорее всего в системе появился вирус, который мешает нормальной работе вашего ПК. А это проблема уже серьёзнее той, которую мы пытались решить. Вам нужно вернуться в окно для удаления программ и просмотреть весь список приложений. Найдите здесь все игры и программы, которыми вы не пользуетесь. И удалите их. Почистите также свои папки с файлами: музыку, изображения, видео.
Ваш встроенный антивирус скорее всего уже бессилен. Так как он не реагирует на вирус, поселившийся в компьютере. Поэтому вам нужен сторонний защитник. В таких случаях многие более опытные пользователи применяют сканирующие утилиты от популярных разработчиков. Можем порекомендовать утилиту от Лаборатории Касперского — https://www.kaspersky.com/downloads/thank-you/free-virus-removal-tool. Или одноразовое средство по этой ссылке https://free.drweb.ru/download+cureit+free/ от Dr.WEB.
Предложенные программы являются бесплатными и портативными. Это значит, что их не нужно устанавливать. Загрузите файл утилиты и запустите её, согласившись с правилами использования. Через некоторое время сканирование завершится, и вы сможете узнать результаты. Если подозрение падёт на одну из ваших игр или программ — не задумываясь удаляйте её. Это источник ваших проблем. После чистки ПК от вирусов перегрузите компьютер и запустите Steam. Если ошибка «Steam cannot run from a folder path with non-ASCII characters» снова появляется — переустановите клиент.
Юникод для чайников

Сам я не очень люблю заголовки вроде «Покемоны в собственном соку для чайников\кастрюль\сковородок», но это кажется именно тот случай — говорить будем о базовых вещах, работа с которыми довольно часто приводить к купе набитых шишек и уйме потерянного времени вокруг вопроса — «Почему же оно не работает?». Если вы до сих пор боитесь и\или не понимаете Юникода — прошу под кат.
Зачем?
Главный вопрос новичка, который встречается с впечатляющим количеством кодировок и на первый взгляд запутанными механизмами работы с ними (например, в Python 2.x). Краткий ответ — потому что так сложилось 🙂
Кодировкой, кто не знает, называют способ представления в памяти компьютера (читай — в нулях-единицах\числах) цифр, буков и всех остальных знаков. Например, пробел представляется как 0b100000 (в двоичной), 32 (в десятичной) или 0x20 (в шестнадцатеричной системе счисления).
Так вот, когда-то памяти было совсем немного и всем компьютерам было достаточно 7 бит для представления всех нужных символов (цифры, строчный\прописной латинский алфавит, куча знаков и так называемые управляемые символы — все возможные 127 номеров были кому-то отданы). Кодировка в это время была одна — ASCII. Шло время, все были счастливы, а кто не был счастлив (читай — кому не хватало знака «©» или родной буквы «щ») — использовали оставшиеся 128 знаков на свое усмотрение, то есть создавали новые кодировки. Так появились и ISO-8859-1, и наши (то есть кириличные) cp1251 и KOI8. Вместе с ними появилась и проблема интерпретации байтов типа 0b1******* (то есть символов\чисел от 128 и до 255) — например, 0b11011111 в кодировке cp1251 это наша родная «Я», в тоже время в кодировке ISO-8859-1 это греческая немецкая Eszett (подсказывает Moonrise) «ß». Ожидаемо, сетевая коммуникация и просто обмен файлами между разными компьютерами превратились в чёрт-знает-что, несмотря на то, что заголовки типа ‘Content-Encoding’ в HTTP протоколе, email-письмах и HTML-страницах немного спасали ситуацию.
В этот момент собрались светлые умы и предложили новый стандарт — Unicode. Это именно стандарт, а не кодировка — сам по себе Юникод не определяет, как символы будут сохранятся на жестком диске или передаваться по сети. Он лишь определяет связь между символом и некоторым числом, а формат, согласно с которым эти числа будут превращаться в байты, определяется Юникод-кодировками (например, UTF-8 или UTF-16). На данный момент в Юникод-стандарте есть немного более 100 тысяч символов, тогда как UTF-16 позволяет поддерживать более одного миллиона (UTF-8 — и того больше).
Ближе к делу!
Естественно, есть поддержка Юникода и в Пайтоне. Но, к сожалению, только в Python 3 все строки стали юникодом, и новичкам приходиться убиваться об ошибки типа:
Давайте разберемся, но по порядку.
Зачем кто-то использует Юникод?
Почему мой любимый html-парсер возвращает Юникод? Пусть возвращает обычную строку, а я там уже с ней разберусь! Верно? Не совсем. Хотя каждый из существующих в Юникоде символов и можно (наверное) представить в некоторой однобайтовой кодировке (ISO-8859-1, cp1251 и другие называют однобайтовыми, поскольку любой символ они кодируют ровно в один байт), но что делать если в строке должны быть символы с разных кодировок? Присваивать отдельную кодировку каждому символу? Нет, конечно, надо использовать Юникод.
Зачем нам новый тип «unicode»?
Вот мы и добрались до самого интересного. Что такое строка в Python 2.x? Это просто байты. Просто бинарные данные, которые могут быть чем-угодно. На самом деле, когда мы пишем что-нибудь вроде:интерпретатор не создает переменную, которая содержит первые четыре буквы латинского алфавита, но только последовательность с четырёх байт, и латинские буквы здесь используются исключительно для обозначения именно этого значения байта. То есть ‘a’ здесь просто синоним для написания ‘\x61’, и ни чуточку больше. Например:
И ответ на вопрос — зачем нам «unicode» уже более очевиден — нужен тип, который будет представятся символами, а не байтами.
Хорошо, я понял чем есть строка. Тогда что такое Юникод в Пайтоне?
«type unicode» — это прежде всего абстракция, которая реализует идею Юникода (набор символов и связанных с ними чисел). Объект типа «unicode» — это уже не последовательность байт, но последовательность собственно символов без какого либо представления о том, как эти символы эффективно сохранить в памяти компьютера. Если хотите — это более высокой уровень абстракции, чем байтовый строки (именно так в Python 3 называют обычные строки, которые используются в Python 2.6).
Как пользоваться Юникодом?
Как из юникод-строки получить обычную? Закодировать её:
Алгоритм кодирования естественно обратный приведенному выше.
Не кодируется 🙁
Разберем примеры с начала статьи. Как работает конкатенация строки и юникод-строки? Простая строка должна быть превращена в юникод-строку, и поскольку интерпретатор не знает кодировки, от использует кодировку по умолчанию — ascii. Если этой кодировке не удастся декодировать строку, получим некрасивую ошибку. В таком случае нам нужно самим привести строку к юникод-строке, используя правильную кодировку:
«UnicodeDecodeError» обычно есть свидетельством того, что нужно декодировать строку в юникод, используя правильную кодировку.
Теперь использование «str» и юникод-строк. Не используйте «str» и юникод строки 🙂 В «str» нет возможности указать кодировку, соответственно кодировка по умолчанию будет использоваться всегда и любые символы > 128 будут приводить к ошибке. Используйте метод «encode»:
«UnicodeEncodeError» — знак того, что нам нужно указать правильную кодировку во время превращения юникод-строки в обычную (или использовать второй параметр ‘ignore’\’replace’\’xmlcharrefreplace’ в методе «encode»).
Хочу ещё!
Хорошо, используем бабу-ягу из примера выше ещё раз:
Есть ещё способ использования «u»» для представления, например, кириллицы, и при этом не указывать кодировку или нечитабельные юникод-поинты (то есть «u’\u1234’»). Способ не совсем удобный, но интересный — использовать unicode entity codes:
Ну и вроде всё. Основные советы — не путать «encode»\«decode» и понимать различия между байтами и символами.
Python 3
Здесь без кода, ибо опыта нет. Свидетели утверждают, что там всё значительно проще и веселее. Кто возьмется на кошках продемонстрировать различия между здесь (Python 2.x) и там (Python 3.x) — респект и уважуха.
Полезно
Раз уж мы о кодировках, порекомендую ресурс, который время-от-времени помогает побороть кракозябры — http://2cyr.com/decode/?lang=ru.
Unicode HOWTO — официальный документ о том где, как и зачем Юникод в Python 2.x.
Спасибо за внимание. Буду благодарен за замечания в приват.
SyntaxError: Non-ASCII character ‘\xa3’ in file when function returns ‘£’
Say I have a function:
I want to print some stuff with a pound sign in front of it and it prints an error when I try to run this program, this error message is displayed:
Can anyone inform me how I can include a pound sign in my return function? I’m basically using it in a class and it’s within the ‘__str__’ part that the pound sign is included.

6 Answers 6

or use the magic available since Python 2.6 to make it automatic:
The error message tells you exactly what’s wrong. The Python interpreter needs to know the encoding of the non-ASCII character.
If you want to return U+00A3 then you can say
which represents this character in pure ASCII by way of a Unicode escape sequence. If you want to return a byte string containing the literal byte 0xA3, that’s
(where in Python 2 the b is implicit; but explicit is better than implicit).
The linked PEP in the error message instructs you exactly how to tell Python «this file is not pure ASCII; here’s the encoding I’m using». If the encoding is UTF-8, that would be
or the Emacs-compatible
If you don’t know which encoding your editor uses to save this file, examine it with something like a hex editor and some googling. The Stack Overflow character-encoding tag has a tag info page with more information and some troubleshooting tips.
In so many words, outside of the 7-bit ASCII range (0x00-0x7F), Python can’t and mustn’t guess what string a sequence of bytes represents. https://tripleee.github.io/8bit#a3 shows 21 possible interpretations for the byte 0xA3 and that’s only from the legacy 8-bit encodings; but it could also very well be the first byte of a multi-byte encoding. But in fact, I would guess you are actually using Latin-1, so you should have
as the first or second line of your source file. Anyway, without knowledge of which character the byte is supposed to represent, a human would not be able to guess this, either.
A caveat: coding: latin-1 will definitely remove the error message (because there are no byte sequences which are not technically permitted in this encoding), but might produce completely the wrong result when the code is interpreted if the actual encoding is something else. You really have to know the encoding of the file with complete certainty when you declare the encoding.
Python «SyntaxError: Non-ASCII character ‘\xe2’ in file» [duplicate]
I am writing some python code and I am receiving the error message as in the title, from searching this has to do with the character set.
Here is the line that causes the error
I cannot figure out what character is not in the ANSI ASCII set? Furthermore searching «\xe2» does not give anymore information as to what character that appears as. Which character in that line is causing the issue?
I have also seen a few fixes for this issue but I am not sure which to use. Could someone clarify what the issue is (python doesn’t interpret unicode unless told to do so?), and how I would clear it up properly?
EDIT: Here are all the lines near the one that errors
23 Answers 23

You’ve got a stray byte floating around. You can find it by running
where you should replace «x.py» by the name of your program. You’ll see the line number and the offending line(s). For example, after inserting that byte arbitrarily, I got:

Or you could just simply use:

\xe2 is the ‘-‘ character, it appears in some copy and paste it uses a different equal looking ‘-‘ that causes encoding errors. Replace the ‘-‘(from copy paste) with the correct ‘-‘ (from you keyboard button).
Change the file character encoding,
put below line to top of your code always

I had the same error while copying and pasting a comment from the web
For me it was a single quote (‘) in the word
I just erased it and re-typed it.
Please read more about the problem and its fix on below link, in this article problem and its solution is beautifully described : https://www.python.org/dev/peps/pep-0263/

I got this error for characters in my comments (from copying/pasting content from the web into my editor for note-taking purposes).
To resolve in Text Wrangler:
I had the same issue and just added this to the top of my file (in Python 3 I didn’t have the problem but do in Python 2

If it helps anybody, for me that happened because I was trying to run a Django implementation in python 3.4 with my python 2.7 command

In general I recommend to convert UTF-8 to ASCII using e.g. https://onlineasciitools.com/convert-utf8-to-ascii
However if you want to keep UTF-8 you can use
After about a half hour of looking through stack overflow, It dawned on me that if the use of a single quote » ‘ » in a comment will through the error:
After looking at the traceback i was able to locate the single quote used in my comment.


DSM’s code above provided the following:
1 ‘print \xe2\x80\x98version is\xe2\x80\x99, sys.version’
So the issue was that my text editor used SMART QUOTES, as John Y suggested. After changing the text editor settings and re-opening/saving the file, it works just fine.

I am trying to parse that weird windows apostraphe and after trying several things here is the code snippet that works.
I had the same issue but it was because I copied and pasted the string as it is. Later when I manually typed the string as it is the error vanished.
Copied string 10 + 3 * 5/(16 − 4)
you can clearly see there is a bit of difference between both the hyphens.
I think it’s because of the different formatting used by different OS or maybe just different software.

For me the problem had caused due to «’» that symbol in the quotes. As i had copied the code from a pdf file it caused that error. I just replaced «’» by this «‘».

If you want to spot what character caused this just assign the problematic variable to a string and print it in a iPython console.
for me, the problem was caused by typing my code into Mac Notes and then copied it from Mac Notes and pasted into my vim session to create my file. This made my single quotes the curved type. to fix it I opened my file in vim and replaced all my curved single quotes with the straight kind, just by removing and retyping the same character. It was Mac Notes that made the same key stroke produce the curved single quote.

I was unable to find what’s the issue for long but later I realised that I had copied a line «UTC-12:00» from web and the hyphen/dash in this was causing the problem. I just wrote this «-» again and the problem got resolved.
So, sometimes the copy pasted lines also give errors. In such cases, just re-write the copy pasted code and it works. On re-writing, it would look like nothing got changed but the error will be gone.

Plenty of good solutions here.
One challenge not really addressed in any of them is how to visually identify certain hard-to-spot non-ASCII characters that resemble other plain ASCII ones. For example, en dashes can appear almost exactly like hyphens and curly quotes look a lot like straight quotes, depending on your text editor’s font.
This one-liner, which should work on Mac or Linux, will strip characters not in the ASCII printable range and show you the differences side-by-side:
site design / logo © 2021 Stack Exchange Inc; user contributions licensed under cc by-sa. rev 2021.12.16.41042
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.


