Плавное введение в Natural Language Processing (NLP)
Введение в NLP с Sentiment Analysis в текстовых данных.
Люди общаются с помощью каких-либо форм языка и пользуются либо текстом, либо речью. Сейчас для взаимодействия компьютеров с людьми, компьютерам необходимо понимать естественный язык, на котором говорят люди. Natural language processing занимается как раз тем, чтобы научить компьютеры понимать, обрабатывать и пользоваться естественными языками.
В этой статье мы рассмотрим некоторые частые методики, применяющиеся в задачах NLP. И создадим простую модель сентимент-анализа на примере обзоров на фильмы, чтобы предсказать положительную или отрицательную оценку.
Что такое Natural Language Processing (NLP)?
NLP — одно из направлений искуственного интеллекта, которое работает с анализом, пониманем и генерацией живых языков, для того, чтобы взаимодействовать с компьютерами и устно, и письменно, используя естественные языки вместо компьютерных.
Применение NLP
Очистка данных (Data Cleaning):
При Data Cleaning мы удаляем из исходных данных особые знаки, символы, пунктуацию, тэги html <> и т.п., которые не содержат никакой полезной для модели информации и только добавляют шум в данные.
 Код на Python: Data cleaning
Код на Python: Data cleaning
Предварительная обработка данных (Preprocessing of Data)
Preprocessing of Data это этап Data Mining, который включает в себя трансформацию исходных данных в доступный для понимания формат.
Изменение регистра:
Одна из простейших форм предварительной обработки текста — перевод всех символов текста в нижний регистр.
 Источник изображения
Источник изображения
 Код на Python: перевод в нижний регистр
Код на Python: перевод в нижний регистр
Токенизация:
Токенизация — процесс разбиения текстового документа на отдельные слова, которые называются токенами.
 Код на Python: Токенизация
Код на Python: Токенизация
Как можно видеть выше, предложение разбито на слова (токены).
Natural language toolkit (библиотека NLTK) — популярный открытый пакет библиотек, используемых для разного рода задач NLP. В этой статье мы будем использовать библиотеку NLTK для всех этапов Text Preprocessing.
Вы можете скачать библиотеку NLTK с помощью pip:
Удаление стоп-слов:
Стоп-слова — это часто используемые слова, которые не вносят никакой дополнительной информации в текст. Слова типа «the», «is», «a» не несут никакой ценности и только добавляют шум в данные.
В билиотеке NLTK есть встроенный список стоп-слов, который можно использовать, чтобы удалить стоп-слова из текста. Однако это не универсальный список стоп-слов для любой задачи, мы также можем создать свой собствпнный набор стоп-слов в зависимости от сферы.
 Код на Python: Удаление стоп-слов
Код на Python: Удаление стоп-слов
В библиотеке NLTK есть заранее заданный список стоп-слов. Мы можем добавитьили удалить стоп-слова из этого списка или использовать его в зависимости от конкретной задачи.
Стеммизация:
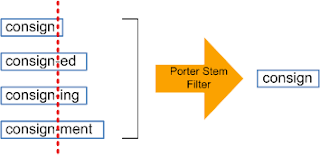
Стеммизация — процесс приведения слова к его корню/основе.
Он приводит различные вариации слова (например, «help», «helping», «helped», «helpful») к его начальной форме (например, «help»), удаляет все придатки слов (приставка, суффикс, окончание) и оставляет только основу слова.
 Источник изображения
Источник изображения
 Код на Python: Стеммизация
Код на Python: Стеммизация
Корень слова может быть существующим в языке словом, а может и не быть им. Например, «mov» корень слова «movie», «emot» корень слова «emotion».
Лемматизация:
Лемматизация похожа на стеммизацию в том, что она приводит слово к его начальной форме, но с одним отличием: в данном случае корень слова будет существующим в языке словом. Например, слово «caring» прекратится в «care», а не «car», как в стеммизаци.
 Код на Python: Лемматизация
Код на Python: Лемматизация
WordNet — это база существующих в английском языке слов. Лемматизатор из NLTK WordNetLemmatizer() использует слова из WordNet.
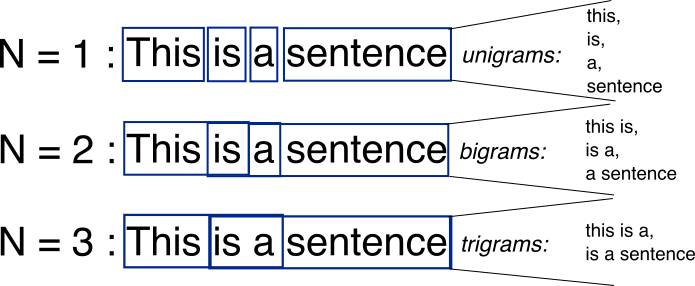
N-граммы:
 Источник изображения
Источник изображения
N-граммы — это комбинации из нескольких слов, использующихся вместе, N-граммы, где N=1 называются униграммами (unigrams). Подобным же образом, биграммы (N=2), триграммы (N=3) и дальше можно продолдать аналогичным способом.
N-граммы могут использоваться, когда нам нужно сохранить какую-то последовательность данных, например, какое слово чаще следует за заданным словом. Униграммы не содержат никкой последовательности данных, так как каждое слово берется индивидуально.
Векторизация текстовых данных (Text Data Vectorization):
Процесс конвертации текста в числа называется векторизацией. Теперь после Text Preprocessing, нам нужно представить текст в числовом виде, то есть закодировать текстовые данные в виде чисел, которые в дальнейшем могут использоваться в алгоритмах.
«Мешок слов» (Bag of words (BOW)):
Это одна из самых простых методик векторизации текста. В логике BOW два предложения могут называться одинаковыми, если содержат один и тот же набор слов.
Рассмотрим два предложения:
 Источник изображения
Источник изображения
В задачах NLP, каждое текстовое предложение называется документом, а несколько таких документов называют корпусом текстов.
BOW создает словарь уникальных d слов в корпусе (собрание всех токенов в данных). Например, корпус на изображении выше состоит из всех слов предложений S1 и S2.
Теперь мы можем создать таблицу, где столбцы соответствуют входящим в корпус уникальным d словам, а строки предложениям (документам). Мы устанавливаем значение 1, если слово в предложении есть, и 0, если его там нет.
 Источник изображения
Источник изображения
Это позволит создать dxn матрицу, где d это общее число уникальных токенов в корпусе и n равно числу документов. В примере выше матрица будет иметь форму 11×2.
TF-IDF:
 Источник изображения
Источник изображения
Это расшифровывается как Term Frequency (TF)-Inverse Document Frequency (IDF).
Частота слова (Term Frequency):
Term Frequency высчитывает вероятность найти какое-то слово в документе. Ну, например, мы хотим узнать, какова вероятрность найти слово wi в документе dj.
Term Frequency (wi, dj) =
Количество раз, которое wi встречается в dj / Общее число слов в dj
Обратная частота документа (Inverse Document Frequency):
В логике IDF, если слово встречается во всех документах, оно не очень полезно. Так определяется, насколько уникально слово во всем корпусе.
Здесь Dc = Все документы в корпусе,
N = Общее число документов,
ni = документы, которые содержат слово (wi).
Если wi встречается в корпусе часто, значение IDF снижается.
Если wi используется не часто, то ni снижается и вследствие этого значение IDF возрастает.
TF-IDF — умножение значений TF и IDF. Больший вес получат слова, которые встречаются в документе чаще, чем во всем остальном корпусе.
Sentiment Analysis: Обзоры фильмов на IMDb
 Источник изображения
Источник изображения
Краткая информация
Набор данных содержит коллекцию из 50 000 рецензий на сайте IMDb, с равным количеством положительных и отрицательных рецензий. Задача — предсказать полярность (положительную или отрицательную) данных отзывов (тексты).
1. Загрузка и исследование данных
Набор данных IMDB можно скачать здесь.
Обзор набора данных:
 Положительные рецензии отмечены 1, а отрицательные 0.
Положительные рецензии отмечены 1, а отрицательные 0.
Пример положительной рецензии:

Пример отрицательной рецензии:

2. Data Preprocessing
 На этом этапе мы совершаем все шаги очистки и предварительной обработки данных тем методом, который был описан выше. Мы используем лемматизацию, а не стеммизацию, потому что в процессе тестирования результатов обоих случаев лемматизация дает лучшие результаты, чем стеммизация.
На этом этапе мы совершаем все шаги очистки и предварительной обработки данных тем методом, который был описан выше. Мы используем лемматизацию, а не стеммизацию, потому что в процессе тестирования результатов обоих случаев лемматизация дает лучшие результаты, чем стеммизация.
Использовать ли стеммизацию или лемматизацию или и то, и другое — зависит от поставленной задачи, так что нам стоит попробовать и решить, какой способ сработает лучше для данной задачи.
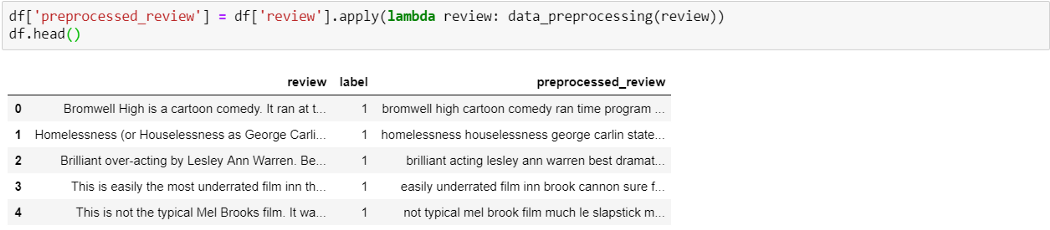
Добавляем новую колонку preprocessed_review в dataframe, применяя data_preprocessing() ко всем рецензиям.
3. Vectorizing Text (рецензии)
Разделяем набор данных на train и test (70–30):

Используем train_test_split из sklearn, чтобы разделить данные на train и test. Здесь используем параметр stratify,чтобы иметь равную пропорцию классов в train и test.
BOW

Здесь мы использовали min_df=10, так как нам нужны были только те слова, которые появляются как минимум 10 раз во всем корпусе.
TF-IDF

4. Создание классификаторов ML
Наивный байесовский классификатор (Naive Bayes) с рецензиями, закодированными BOW

Naive Bayes c BOW выдает точность 84.6%. Попробуем с TF-IDF.
Наивный байесовский классификатор (Naive Bayes) с рецензиями, закодированными TF-IDF

TF-IDF выдает результат немного лучше (85.3%), чем BOW. Теперь давайте попробуем TF-IDF с простой линеарной моделью, Logistic Regression.
Logistic Regression с рецензиями, закодированными TF-IDF

Logistic Regression с рецензиями, закодированными TF-IDF, выдает результат лучше, чем наивный байемовский — точность 88.0%.
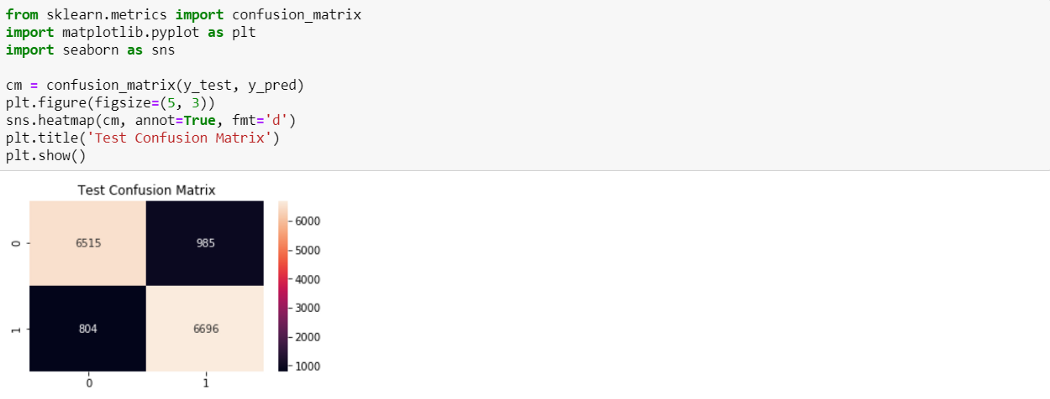 Построение матрицы неточностей даст нам информацию о том, сколько точек данных верны и сколько неверны, классифицированную с помощью модели.
Построение матрицы неточностей даст нам информацию о том, сколько точек данных верны и сколько неверны, классифицированную с помощью модели.
Из 7500 отрицательных рецензий 6515 были верно классифицированы как отрицательные и 985 были неверно классифицированы как положительные. Из 7500 положительных рацензий 6696 были верно классифицированы как положительные, и 804 неверно классифицированы как отрицательные.
Итоги
Мы узнали основные задачи NLP и создали простые модели ML для сентимент-анализа рецензий на фильмы. В дальнейшем усоверешенствований можно добиться с помощью Word Embedding с моделями Deep Learning.
Благодарю за внимание! Полный код смотрите здесь.
NLP. Основы. Техники. Саморазвитие. Часть 1
Привет! Меня зовут Иван Смуров, и я возглавляю группу исследований в области NLP в компании ABBYY. О том, чем занимается наша группа, можно почитать здесь. Недавно я читал лекцию про Natural Language Processing (NLP) в Школе глубокого обучения – это кружок при Физтех-школе прикладной математики и информатики МФТИ для старшеклассников, интересующихся программированием и математикой. Возможно, тезисы моей лекции кому-то пригодятся, поэтому поделюсь ими с Хабром.
Поскольку за один раз все объять не получится, разделим статью на две части. Сегодня я расскажу о том, как нейросети (или глубокое обучение) используются в NLP. Во второй части статьи мы сконцентрируемся на одной из самых распространенных задач NLP — задаче извлечения именованных сущностей (Named-entity recognition, NER) и разберем подробно архитектуры ее решений.

Что такое NLP?
Это широкий круг задач по обработке текстов на естественном языке (т. е. на языке, на котором говорят и пишут люди). Существует набор классических задач NLP, решение которых несет практическую пользу.
Первый и один из самых важных с практической точки зрения способов применения — классификация писем на спам и хам (не спам).
Другой классический вариант — многоклассовая классификация новостей по категориям (рубрикация) — внешняя политика, спорт, шапито и т. п. Или, допустим, вам приходят письма, и вы хотите отделить заказы из интернет-магазина от авиабилетов и броней отелей.
Третий классический вариант применения задачи текстовой классификации — сентиментный анализ. Например, классификация отзывов на положительные, отрицательные и нейтральные.
Примерами других часто выделяемых отношений являются отношения купли/продажи (Purchase and Sale), владения (Ownership), факт рождения с атрибутами — датой, местом и т. д. (Birth) и некоторые другие.
Задача кажется не имеющей очевидного практического применения, но, тем не менее, она используется при структуризации неструктурированной информации. Кроме того, это важно в вопросно-ответных и диалоговых системах, в поисковиках — всегда, когда вам нужно анализировать вопрос и понимать, к какому типу он относится, а также, какие ограничения есть на ответ.
Почему решать задачи NLP сложно?
Формулировки задач не очень сложные, однако сами задачи вовсе не являются простыми, потому что мы работаем с естественным языком. Явления полисемии (многозначные слова имеют общий исходный смысл) и омонимии (разные по смыслу слова произносятся и пишутся одинаково) характерны для любого естественного языка. И если носитель русского хорошо понимает, что в теплом приеме мало общего с боевым приемом, с одной стороны, и теплым пивом, с другой, автоматической системе приходится долго этому учиться. Почему «Press space bar to continue» лучше перевести скучным «Для продолжения нажмите пробел», чем «Бар космической прессы продолжит работу».
Как решают задачи NLP
В отличие от обработки изображений, по NLP до сих пор можно встретить статьи, где описываются решения, использующие не нейросетки, а классические алгоритмы типа SVM или Xgboost, и показывающие результаты, не слишком сильно уступающие state-of-the-art решениям.
Тем не менее, несколько лет назад нейросети начали побеждать классические модели. Важно отметить, что для большинства задач решения на основе классических методов были уникальные, как правило, не похожие на решения других задач как по архитектуре, так и по тому, как происходит сбор и обработка признаков.
Однако нейросетевые архитектуры намного более общие. Архитектура самой сети, скорее всего, тоже отличается, но намного меньше, идет тенденция в сторону полной универсализации. Тем не менее, то, с какими признаками и как именно мы работаем, уже практически одинаково для большинства задач NLP. Отличаются только последние слои нейросеток. Таким образом, можно считать, что сформировался единый пайплайн NLP. Про то, как он устроен, мы сейчас расскажем подробнее.
Pipeline NLP
Этот способ работы с признаками, который более-менее одинаков для всех задач.
Когда речь идет о языке, основная единица, с которой мы работаем, это слово. Или более формально «токен». Мы используем этот термин, потому что не очень понятно, что такое 2128506 — это слово или нет? Ответ не очевиден. Токен обычно отделен от других токенов пробелами или знаками препинания. И как можно понять из сложностей, которые мы описали выше, очень важен контекст каждого токена. Есть разные подходы, но в 95% случаев таким контекстом, который рассматривается при работе модели, выступает предложение, включающее исходный токен.
Многие задачи вообще решаются на уровне предложения. Например, машинный перевод. Чаще всего, мы просто переводим одно предложение и никак не используем контекст более широкого уровня. Есть задачи, где это не так, например, диалоговые системы. Тут важно помнить, о чем систему спрашивали раньше, чтобы она могла ответить на вопросы. Тем не менее, предложение — тоже основная единица, с которой мы работаем.
Поэтому первые два шага пайплайна, которые выполняются практически для решения любых задач – это сегментация (деление текста на предложения) и токенизация (деление предложений на токены, то есть отдельные слова). Это делается несложными алгоритмами.
Дальше нужно вычислить признаки каждого токена. Как правило, это происходит в два этапа. Первый – вычислить контекстно-независимые признаки токена. Это набор признаков, которые никак не зависят от окружающих наш токен других слов. Обычные контекстно-независимые признаки – это:
Один из самых часто использующихся признаков — часть речи или POS-тег (part of speech). Такие признаки могут быть важны для решения многих задач, например задачи синтаксического парсинга. Для языков со сложной морфологией, типа русского языка, также важны морфологические признаки: например, в каком падеже стоит существительное, какой род у прилагательного. Из этого можно сделать разные выводы о структуре предложения. Также, морфология нужна для лемматизации (приведения слов к начальным формам), с помощью которой мы можем сократить размерность признакового пространства, и поэтому морфологический анализ активно используется для большинства задач NLP.
Когда мы решаем задачу, где важно взаимодействие между различными объектами (например, в задаче relation extraction или при создании вопросно-ответной системы), нам нужно многое знать про структуру предложения. Для этого нужен синтаксический разбор. В школе все делали разбор предложения на подлежащее, сказуемое, дополнение и др. Синтаксический разбор – это что-то в этом духе, но сложнее.
Еще одним примером дополнительного признака является позиция токена в тексте. Мы можем априори знать, что какая-то сущность чаще встречается в начале текста или наоборот в конце.
Все вместе – эмбеддинги, символьные и дополнительные признаки – формируют вектор признаков токена, который не зависит от контекста.
Контекстно-зависимые признаки
Контекстно-зависимые признаки токена — это набор признаков, который содержит информацию не только про сам токен, но и про его соседей. Есть разные способы вычислить эти признаки. В классических алгоритмах люди часто просто шли «окном»: брали несколько (например, три) токенов до исходного и несколько токенов после, а затем вычисляли все признаки в таком окне. Такой подход ненадежен, так как важная информация для анализа может находиться на расстоянии, превышающем окно, соответственно, мы можем что-то пропустить.
Поэтому сейчас все контекстно-зависимые признаки вычисляются на уровне предложения стандартным образом: с помощью двухсторонних рекуррентных нейросетей LSTM или GRU. Чтобы получить контекстно-зависимые признаки токена из контекстно-независимых, контекстно-независимые признаки всех токенов предложения подаются в Bidirectional RNN (одно- или несколько- слойный). Выход Bidirectional RNN в i-ый момент времени и является контекстно-зависимым признаком i-того токена, который содержит информацию как о предыдущих токенах (т.к. эта информация содержится в i-м значении прямого RNN), так и о последующих (т.к. эта информация содержится в соответствующем значении обратного RNN).
Дальше для каждой отдельной задачи мы делаем что-то свое, но первые несколько слоев — вплоть до Bidirectional RNN можно использовать для практически любых задач.
Такой способ получения признаков и называется пайплайном NLP.
Стоит отметить, что в последние 2 года исследователи активно пытаются усовершенствовать пайплайн NLP — как с точки зрения быстродействия (например, transformer — архитектура, основанная на self-attention, не содержит в себе RNN и поэтому способна быстрее обучаться и применяться), так и с точки зрения используемых признаков (сейчас активно используют признаки на основе предобученных языковых моделей, например ELMo, или используют первые слои предобученной языковой модели и дообучают их на имеющемся для задачи корпусе — ULMFit, BERT).
Словоформенные эмбеддинги
Давайте подробнее разберем, что же такое эмбеддинг. Грубо говоря, эмбеддинг — это сжатое представление о контексте слова. Почему важно знать контекст слова? Потому что мы верим в дистрибутивную гипотезу — что похожие по смыслу слова употребляются в сходных контекстах.
Давайте теперь попытаемся дать строгое определение эмбеддинга. Эмбеддинг – это отображение из дискретного вектора категориальных признаков в непрерывный вектор с заранее заданной размерностью.
Каноничный пример эмбеддинга – это эмбеддинг слова (словоформенный эмбеддинг).
Что обычно выступает в роли дискретного вектора признаков? Булев вектор, соответствующий всевозможным значениям какой-то категории (например, все возможные части речи или все возможные слова из какого-то ограниченного словаря).
Для словоформенных эмбеддингов такой категорией обычно выступает индекс слова в словаре. Допустим, есть словарь размерностью 100 тысяч. Соответственно, каждое слово имеет дискретный вектор признаков – булев вектор размерности 100 тысяч, где на одном месте (индексе данного слова в нашем словаре) стоит единичка, а на остальных – нули.
Почему мы хотим отображать наши дискретные вектора признаков в непрерывные заданной размерности? Потому что вектора размерностью 100 тысяч не очень удобно использовать для вычислений, а вот вектора целых чисел размерности 100, 200 или, например, 300, — намного удобнее.
В принципе, мы можем не пытаться накладывать никаких дополнительных ограничений на такое отображение. Но раз уж мы строим такое отображение, давайте попытаемся добиться, чтобы вектора похожих по смыслу слов также были в каком-то смысле близки. Это делается с помощью простой feed-forward нейросетки.
Обучение эмбеддингов
Как эмбеддинги обучаются? Мы пытаемся решить задачу восстановления слова по контексту (или наоборот, восстановления контекста по слову). В простейшем случае мы получаем на вход индекс в словаре предыдущего слова (булев вектор размерности словаря) и пытаемся определить индекс в словаре нашего слова. Делается это с помощью сетки с предельно простой архитектурой: два полносвязных слоя. Сначала идет полносвязный слой из булева вектора размерности словаря в скрытый слой размерности эмбеддинга (т.е. просто умножение булева вектора на матрицу нужной размерности). А потом наоборот, полносвязный слой с softmax из скрытого слоя размерности эмбеддинга в вектор размерности словаря. Благодаря функции активации softmax, мы получаем распределение вероятностей нашего слова и можем выбрать самый вероятный вариант.
Эмбеддингом i-го слова будет просто i-я строка в матрице перехода W.
В используемых на практике моделях архитектура сложнее, но ненамного. Главное отличие в том, что мы используем не один вектор из контекста для определения нашего слова, а несколько (например, все в окне размера 3). Несколько более популярным вариантом является ситуация, когда мы пытаемся предсказать не слово по контексту, а наоборот контекст по слову. Такой подход называется Skip-gram.
Давайте приведем пример применения задачи, которая решается во время обучения эмбеддингов (в варианте CBOW — предсказания слова по контексту). Например, пусть контекст токена состоит из 2 предыдущих слов. Если мы обучались на корпусе текстов про современную русскую литературу и контекст состоит из слов “поэт Марина”, то, скорее всего, самым вероятным следующим словом будет слово “Цветаева”.
Подчеркнем еще раз, эмбеддинги только обучаются на задаче предсказания слова по контексту (или наоборот контекста по слову), а применять их можно в любых ситуациях, когда нам нужно вычислить признак токена.
Какой бы вариант мы ни выбрали, архитектура эмбеддингов очень несложная, и их большой плюс в том, что их можно обучать на неразмеченных данных (действительно, мы используем только информацию о соседях нашего токена, а для их определения нужен только сам текст). Получившиеся эмбеддинги — усредненный контекст именно по такому корпусу.
Эмбеддинги словоформ, как правило, обучаются на максимально большом и доступном для обучения корпусе. Обычно это вся Википедия на языке, потому что ее всю можно выкачать, и любые другие корпуса, которые получится достать.
Похожие соображения используются и при предобучении для современных архитектур, упомянутых выше — ELMo, ULMFit, BERT. Они тоже используют при обучении неразмеченные данные, и поэтому обучаются на максимально большом доступном корпусе (хотя сами архитектуры, конечно, сложнее, чем у классических эмбеддингов).
Зачем нужны эмбеддинги?
Как уже было упомянуто, для использования эмбеддингов есть 2 основные причины.
В следующей части нашей статьи мы поговорим о задаче NER. Мы расскажем о том, что это за задача, зачем она нужна и какие подводные камни могут скрываться в ее решении. Мы расскажем подробно про то, как эту задачу решали с помощью классических методов, как ее стали решать с помощью нейросетей, и опишем современные архитектуры, созданные для ее решения.


