Что нового в pandas 1.0?
В конце января 2020 вышло большое обновление библиотеки pandas – 1.0. Представляем вам обзор изменений и дополнений, которые по нашему мнению являются интересными и заслуживают внимания.
Мажорный релиз 1.0 принес с собой улучшения существующих инструментов, новые дополнения (они пока имеют статус экспериментальных), ряд изменений в API, которые ломают обратную совместимость, багфиксы и изменения, увеличивающие производительность библиотеки.
pd.NA
Первое, с чего хотелось бы начать – это pd.NA – “значение”, которое pandas будет использовать для обозначения отсутствующих данных.
В предыдущих версиях pandas для обозначения отсутствующих данных использовались следующие значения: NaN, NaT и None. NaN – это отсутствующее значение в столбце с числовым типом данных, оно является аббревиатурой от Not a Number (пришло из numpy: np.NaN). NaT – это отсутствующее значение для данных типа DateTime, аббревиатура от Not a Time (является частью библиотеки pandas). None используется если тип данных object, такой тип имеют, например, элементы типа str (пришло из Python).
Рассмотрим работу с отсутствующими данными на примерах:

Если создать набор данных с целыми числами, не указывая явно тип, то будет использовано значение по умолчанию:
Если тип указать, то в pandas 1.0 будет использован pd.NA:
Либо можно задать pd.NA напрямую:
Для строковых и boolean значений это работает аналогично:
Типы pandas для работы со строками и boolean-значениями
Появился тип StringDtype для работы со строковыми данными (до этого строки хранились в object-dtype NumPy массивах). При создании структуры pandas необходимо указать тип StringDtype либо string:
Также добавлен тип BooleanDtype для хранения boolean значений. В предыдущих версиях столбец данных типа bool не мог содержать отсутствующие значения, тип BooleanDtype поддерживает эту возможность:
Инструмент конвертирования типов
Метод convert_dtypes поддерживает работу с новыми типами:


Конвертор в markdown
В pandas 1.0 добавлен метод to_markdown() для конвертирования структур pandas в markdown таблицы:
Еще изменения и дополнения…



Более подробно про остальные изменения и дополнения можете прочитать на официальной странице сайта pandas.
P.S.
Working with missing data¶
In this section, we will discuss missing (also referred to as NA) values in pandas.
The choice of using NaN internally to denote missing data was largely for simplicity and performance reasons. Starting from pandas 1.0, some optional data types start experimenting with a native NA scalar using a mask-based approach. See here for more.
See the cookbook for some advanced strategies.
Values considered “missing”¶
As data comes in many shapes and forms, pandas aims to be flexible with regard to handling missing data. While NaN is the default missing value marker for reasons of computational speed and convenience, we need to be able to easily detect this value with data of different types: floating point, integer, boolean, and general object. In many cases, however, the Python None will arise and we wish to also consider that “missing” or “not available” or “NA”.
To make detecting missing values easier (and across different array dtypes), pandas provides the isna() and notna() functions, which are also methods on Series and DataFrame objects:
So as compared to above, a scalar equality comparison versus a None/np.nan doesn’t provide useful information.
Integer dtypes and missing data¶
Because NaN is a float, a column of integers with even one missing values is cast to floating-point dtype (see Support for integer NA for more). pandas provides a nullable integer array, which can be used by explicitly requesting the dtype:
Alternatively, the string alias dtype=’Int64′ (note the capital «I» ) can be used.
Datetimes¶
Inserting missing data¶
You can insert missing values by simply assigning to containers. The actual missing value used will be chosen based on the dtype.
For example, numeric containers will always use NaN regardless of the missing value type chosen:
For object containers, pandas will use the value given:
Calculations with missing data¶
Missing values propagate naturally through arithmetic operations between pandas objects.
The descriptive statistics and computational methods discussed in the data structure overview (and listed here and here ) are all written to account for missing data. For example:
When summing data, NA (missing) values will be treated as zero.
If the data are all NA, the result will be 0.
Sum/prod of empties/nans¶
This behavior is now standard as of v0.22.0 and is consistent with the default in numpy ; previously sum/prod of all-NA or empty Series/DataFrames would return NaN. See v0.22.0 whatsnew for more.
The sum of an empty or all-NA Series or column of a DataFrame is 0.
The product of an empty or all-NA Series or column of a DataFrame is 1.
NA values in GroupBy¶
NA groups in GroupBy are automatically excluded. This behavior is consistent with R, for example:
See the groupby section here for more information.
Cleaning / filling missing data¶
pandas objects are equipped with various data manipulation methods for dealing with missing data.
Filling missing values: fillna¶
fillna() can “fill in” NA values with non-NA data in a couple of ways, which we illustrate:
Replace NA with a scalar value
Fill gaps forward or backward
Limit the amount of filling
If we only want consecutive gaps filled up to a certain number of data points, we can use the limit keyword:
To remind you, these are the available filling methods:
Fill values forward
Fill values backward
With time series data, using pad/ffill is extremely common so that the “last known value” is available at every time point.
ffill() is equivalent to fillna(method=’ffill’) and bfill() is equivalent to fillna(method=’bfill’)
Filling with a PandasObject¶
You can also fillna using a dict or Series that is alignable. The labels of the dict or index of the Series must match the columns of the frame you wish to fill. The use case of this is to fill a DataFrame with the mean of that column.
Same result as above, but is aligning the вЂfill’ value which is a Series in this case.
Dropping axis labels with missing data: dropna¶
You may wish to simply exclude labels from a data set which refer to missing data. To do this, use dropna() :
Interpolation¶
Both Series and DataFrame objects have interpolate() that, by default, performs linear interpolation at missing data points.
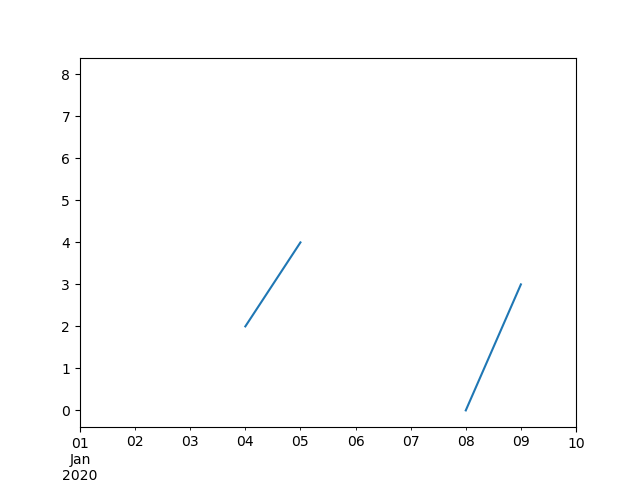
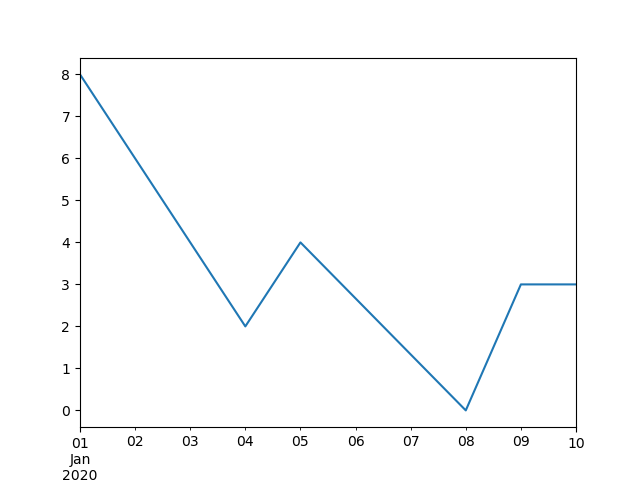
Index aware interpolation is available via the method keyword:
For a floating-point index, use method=’values’ :
You can also interpolate with a DataFrame:
If you are dealing with a time series that is growing at an increasing rate, method=’quadratic’ may be appropriate.
If you have values approximating a cumulative distribution function, then method=’pchip’ should work well.
When interpolating via a polynomial or spline approximation, you must also specify the degree or order of the approximation:
Compare several methods:
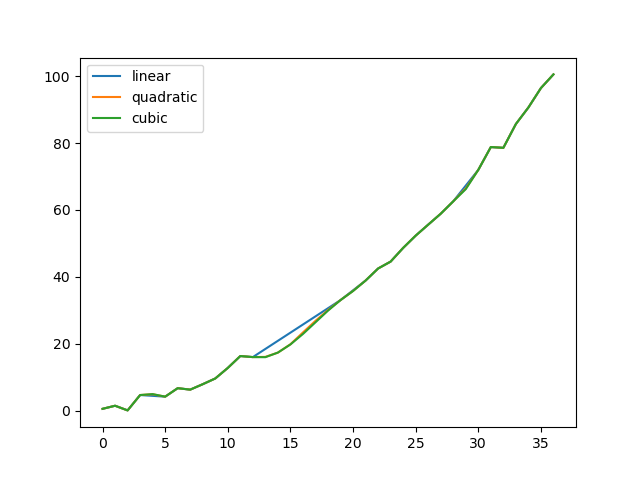
Another use case is interpolation at new values. Suppose you have 100 observations from some distribution. And let’s suppose that you’re particularly interested in what’s happening around the middle. You can mix pandas’ reindex and interpolate methods to interpolate at the new values.
Interpolation limits¶
Like other pandas fill methods, interpolate() accepts a limit keyword argument. Use this argument to limit the number of consecutive NaN values filled since the last valid observation:
By default, NaN values are filled in a forward direction. Use limit_direction parameter to fill backward or from both directions.
By default, NaN values are filled whether they are inside (surrounded by) existing valid values, or outside existing valid values. The limit_area parameter restricts filling to either inside or outside values.
Replacing generic values¶
Often times we want to replace arbitrary values with other values.
replace() in Series and replace() in DataFrame provides an efficient yet flexible way to perform such replacements.
For a Series, you can replace a single value or a list of values by another value:
You can replace a list of values by a list of other values:
You can also specify a mapping dict:
For a DataFrame, you can specify individual values by column:
Instead of replacing with specified values, you can treat all given values as missing and interpolate over them:
String/regular expression replacement¶
You can pass nested dictionaries of regular expressions that use regex=True :
Alternatively, you can pass the nested dictionary like so:
All of the regular expression examples can also be passed with the to_replace argument as the regex argument. In this case the value argument must be passed explicitly by name or regex must be a nested dictionary. The previous example, in this case, would then be:
This can be convenient if you do not want to pass regex=True every time you want to use a regular expression.
Anywhere in the above replace examples that you see a regular expression a compiled regular expression is valid as well.
Numeric replacement¶
Replacing more than one value is possible by passing a list.
You can also operate on the DataFrame in place:
Missing data casting rules and indexing¶
While pandas supports storing arrays of integer and boolean type, these types are not capable of storing missing data. Until we can switch to using a native NA type in NumPy, we’ve established some “casting rules”. When a reindexing operation introduces missing data, the Series will be cast according to the rules introduced in the table below.
Ordinarily NumPy will complain if you try to use an object array (even if it contains boolean values) instead of a boolean array to get or set values from an ndarray (e.g. selecting values based on some criteria). If a boolean vector contains NAs, an exception will be generated:
However, these can be filled in using fillna() and it will work fine:
Experimental NA scalar to denote missing values¶
Experimental: the behaviour of pd.NA can still change without warning.
New in version 1.0.0.
For example, when having missing values in a Series with the nullable integer dtype, it will use pd.NA :
Propagation in arithmetic and comparison operations¶
For example, pd.NA propagates in arithmetic operations, similarly to np.nan :
An exception on this basic propagation rule are reductions (such as the mean or the minimum), where pandas defaults to skipping missing values. See above for more.
Logical operations¶
For logical operations, pd.NA follows the rules of the three-valued logic (or Kleene logic, similarly to R, SQL and Julia). This logic means to only propagate missing values when it is logically required.
The behaviour of the logical “and” operation ( & ) can be derived using similar logic (where now pd.NA will not propagate if one of the operands is already False ):
NA in a boolean context¶
Since the actual value of an NA is unknown, it is ambiguous to convert NA to a boolean value. The following raises an error:
NumPy ufuncs¶
Currently, ufuncs involving an ndarray and NA will return an object-dtype filled with NA values.
The return type here may change to return a different array type in the future.
Conversion¶
In this example, while the dtypes of all columns are changed, we show the results for the first 10 columns.
The Weird World of Missing Values in Pandas
Let’s take a look at the three types of missing values and learn how to find them.
NaN s are always floats. So if you have an integer column and it has a NaN added to it, the column is upcasted to become a float column. This behavior may seem strange, but it is based on NumPy’s capabilities as of this writing. In general, floats take up very little space in memory, so pandas decided to treat them this way. The pandas dev team is hoping NumPy will provide a native NA solution soon.
What are these NaN values anyway?
NaN is a NumPy value. np.NaN
NaT is a Pandas value. pd.NaT
None is a vanilla Python value. None
Strange Things are afoot with Missing values

Behavior with missing values can get weird. Let’s make a Series with each type of missing value.
Pandas created the Series as a DateTime dtype. Ok.
You can cast it to an object dtype if you like.
But you can’t cast it to a numeric dtype.
Equality Check
Another bizarre thing about missing values in Pandas is that some varieties are equal to themselves and others aren’t.
Now let’s turn our attention finding missing values.
Finding Missing Values with df.isna()
A boolean DataFrame is returned if df.isna() is called on a DataFrame and a Series is returned if called on a Series.
Let’s see df.isna() in action! Here’s a DataFrame with all three types of missing values:

Here’s the code to return a boolean DataFrame with True for missing values.
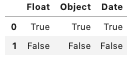
A one-liner to return a DataFrame of all your missing values is pretty cool. Deciding what to do with those missing values is a whole nother question that I’ll be exploring in my upcoming Memorable Pandas book.
Note that it’s totally fine to have all three Pandas missing value types in your DataFrame at the same time, assuming you are okay with missing values.
I hope you found this intro to missing values in the Python pandas library to be useful. 😀
If you did, please do all the nice things on Dev and share it on your favorite social media so other people can find it, too. 👏
I write about Python, Docker, and data science things. Check out my other guides if you’re into that stuff. 👍
You don’t want to MISS them! (Missing values. Get it?) 🙄
Thanks to Kevin Markham of Data School for suggestions on an earlier version of this article!
Not a Number — все о NaN / pd 5
В предыдущих разделах вы видели, как легко могут образовываться недостающие данные. В структурах они определяются как значения NaN (Not a Value). Такой тип довольно распространен в анализе данных.
Присваивание значения NaN
Если нужно специально присвоить значение NaN элементу структуры данных, для этого используется np.NaN (или np.nan ) из библиотеки NumPy.
Фильтрование значений NaN
Функцию фильтрации можно выполнить и прямо с помощью notnull() при выборе элементов.
В случае с Dataframe это чуть сложнее. Если использовать функцию pandas dropna() на таком типе объекта, который содержит всего одно значение NaN в колонке или строке, то оно будет удалено.
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | NaN | 6.0 |
| green | NaN | NaN | NaN |
| red | 2.0 | NaN | 5.0 |
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | NaN | 6.0 |
| red | 2.0 | NaN | 5.0 |
Заполнение NaN
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | 0.0 | 6.0 |
| green | 0.0 | 0.0 | 0.0 |
| red | 2.0 | 0.0 | 5.0 |
Или же NaN можно заменить на разные значения в зависимости от колонки, указывая их и соответствующие значения.
python-pandas: работа со значениями типа NaT в Столбцах даты pandas dataframe
У меня есть столбец dataframe со смешанным типом данных, и я применил pd.to_datetime(df[‘DATE’],coerce=True) и получил ниже dataframe
Теперь я хочу применить некоторую функцию agg (здесь я хочу сгруппировать mailid и взять min() даты, чтобы найти дату первой транзакции этого mailid).
если для любого customer_name в поле DATE будет только NaT, то для groupby и min() я согласен со значениями nan или Null.
2 ответа
У меня есть следующий диктат: td = <'q1':(111,222), 'q2':(333,444)>Я хотел бы преобразовать его в dataframe, который выглядит следующим образом: Query Value1 Value2 q1 111 222 q2 333 444 Я попробовал следующее: df = pd.DataFrame(td.items()) Результат выглядит так: 0 1 0 q1 (111,222) 1 q2.
Скажем, вы начинаете с чего-то вроде этого:
Затем следующее делает то, что вы просите:
Вот альтернативное решение:
Данные:
Решение:
Объяснение:
во-первых, давайте создадим новый виртуальный столбец D с усеченной частью времени:
теперь мы можем сгруппироваться по CUSTOMER_name и вычислить минимум D для каждой группы:
и, наконец, преобразуйте результирующий столбец в datetime64[ns] dtype:
Я пытаюсь создать dataframe дат в python. Я использую даты в качестве индекса : aDates.head(5) Out[114]: 0 2009-12-31 1 2010-01-01 2 2010-01-04 3 2010-01-05 4 2010-01-06 Name: Date, dtype: datetime64[ns] Затем я создаю пустой dataframe: dfAll_dates = pd.DataFrame(index = aDates) Затем я получил.
У меня есть dataframe в Pandas, и один столбец timeOff имеет некоторые значения NaT. Все, что я хочу сделать, это изменить все значения NaT на значения timeDelta с ’00:00:00′ в качестве значения. Это мой текущий выход: Выход с NaT значениями Я попытался запустить эту строку кода: replaceNaT =.
Похожие вопросы:
У меня есть dataframe со столбцом типа datetime64. В этом столбце есть несколько строк с датами как 1999-09-09 23:59:59, где, как и должно было быть на самом деле, они были представлены как.
У меня есть следующий диктат: td = <'q1':(111,222), 'q2':(333,444)>Я хотел бы преобразовать его в dataframe, который выглядит следующим образом: Query Value1 Value2 q1 111 222 q2 333 444 Я.
Я пытаюсь создать dataframe дат в python. Я использую даты в качестве индекса : aDates.head(5) Out[114]: 0 2009-12-31 1 2010-01-01 2 2010-01-04 3 2010-01-05 4 2010-01-06 Name: Date, dtype.
У меня есть dataframe в Pandas, и один столбец timeOff имеет некоторые значения NaT. Все, что я хочу сделать, это изменить все значения NaT на значения timeDelta с ’00:00:00′ в качестве значения.
Для загрузки немецких банковских праздников через веб-сайт api и преобразования данных json в pandas dataframe я использую следующий код (python 3): import datetime import requests import pandas as.
Я пытаюсь заменить значения NaT в Pandas dataframe на NaNs следующим образом df = df.replace([pd._libs.tslibs.nattype.NaTType], np.nan) но потом я проверяю его обратно print(df[col]).
Мне нужно прочитать целочисленный формат nullable date values (‘YYYYMMDD’) to pandas, а затем сохранить этот pandas dataframe в Parquet как формат Date32[Day], чтобы классификатор Athena Glue.


