Что такое распределенные системы? Краткое введение
В свете последних технологических изменений и достижений распределенные системы становятся все более популярными. Многие ведущие компании создали сложные распределенные системы для обработки миллиардов запросов и обновления без простоев.
Распределенные проекты могут показаться сложными и сложными для создания, но в 2021 году они становятся все более важными для обеспечения экспоненциального масштабирования. Начиная сборку, важно оставить место для базовой, высокодоступной и масштабируемой распределенной системы.
Когда дело доходит до распределенных систем, есть много чего. Итак, сегодня мы просто познакомим вас с распределенными системами. Мы объясним различные категории, проблемы дизайна и соображения, которые необходимо учесть.
Что такое распределенная система?
На базовом уровне распределенная система — это совокупность компьютеров, которые работают вместе, образуя единый компьютер для конечного пользователя. Все эти распределенные машины имеют одно общее состояние и работают одновременно.
Они могут выходить из строя независимо, не повреждая всю систему, как и микросервисы. Эти взаимозависимые автономные компьютеры связаны сетью, чтобы легко обмениваться информацией, общаться и обмениваться информацией.
Примечание. Распределенные системы должны иметь общую сеть для подключения своих компонентов, которые могут быть подключены с помощью IP-адреса или даже физических кабелей.
В отличие от традиционных баз данных, которые хранятся на одной машине, в распределенной системе пользователь должен иметь возможность связываться с любой машиной, не зная, что это только одна машина. Большинство приложений сегодня используют ту или иную форму распределенной базы данных и должны учитывать их однородный или неоднородный характер.
В однородной распределенной базе данных каждая система использует модель данных, а также систему управления базой данных и модель данных. Как правило, ими легче управлять, добавляя узлы. С другой стороны, гетерогенные базы данных позволяют иметь несколько моделей данных или различные системы управления базами данных, использующие шлюзы для трансляции данных между узлами.
Как правило, существует три типа распределенных вычислительных систем со следующими целями:
Примечание. Важной частью распределенных систем является теорема CAP, которая утверждает, что распределенное хранилище данных не может одновременно быть согласованным, доступным и устойчивым к разделам.
Децентрализованные и распределенные
Существует довольно много споров о разнице между децентрализованными и распределенными системами. Децентрализованная система по существу распределена на техническом уровне, но обычно децентрализованная система не принадлежит одному источнику.
Управлять децентрализованной системой сложнее, поскольку вы не можете управлять всеми участниками, в отличие от распределенного единого курса, где все узлы принадлежат одной команде / компании.
Преимущества распределенной системы
Распределенные системы могут быть сложными в развертывании и обслуживании, но такая конструкция дает много преимуществ. Давайте рассмотрим некоторые из этих льгот.

Масштабируемость — самое большое преимущество распределенных систем. Горизонтальное масштабирование означает добавление дополнительных серверов в пул ресурсов. Вертикальное масштабирование означает масштабирование за счет увеличения мощности (ЦП, ОЗУ, хранилища и т. Д.) На ваших существующих серверах.
Горизонтальное масштабирование легче динамически масштабировать, а вертикальное масштабирование ограничено мощностью одного сервера.
Хорошими примерами горизонтального масштабирования являются Cassandra и MongoDB. Они упрощают горизонтальное масштабирование за счет добавления дополнительных машин. Примером вертикального масштабирования является MySQL, когда вы масштабируете, переключаясь с меньших компьютеров на большие.
Проблемы проектирования с распределенными системами
Несмотря на то, что распределенные системы имеют много преимуществ, важно также отметить проблемы проектирования, которые могут возникнуть. Ниже мы кратко изложили основные соображения по поводу дизайна.
Распределенные системы нелегко установить и запустить, и часто эта мощная технология оказывается слишком «избыточной» для многих систем. Распространение данных, обеспечивающих выполнение различных требований в непредвиденных обстоятельствах, сопряжено с множеством проблем.
Точно так же ошибки труднее обнаружить в системах, которые разбросаны по разным местам.
Облако против распределенных систем
Облачные вычисления и распределенные системы разные, но в них используются похожие концепции. Распределенные вычисления используют распределенные системы, распределяя задачи по множеству машин. С другой стороны, облачные вычисления используют серверы, размещенные в сети, для хранения, обработки и управления данными.
Распределенные вычисления направлены на создание совместного использования ресурсов и обеспечение размера и географической масштабируемости. Облачные вычисления — это предоставление среды по запросу с использованием прозрачности, мониторинга и безопасности.
По сравнению с распределенными системами облачные вычисления имеют следующие преимущества:
Однако облачные вычисления, возможно, менее гибки, чем распределенные вычисления, поскольку для построения системы вы полагаетесь на другие сервисы и технологии. Это дает вам меньше контроля.
Такие приоритеты, как балансировка нагрузки, репликация, автоматическое масштабирование и автоматическое резервное копирование. Могут быть упрощены с помощью облачных вычислений. Инструменты создания облака, такие как Docker, Amazon Web Services (AWS), Google Cloud Services или Azure, позволяют быстро создавать такие системы, и многие команды предпочитают создавать распределенные системы вместе с этими технологиями.
Примеры распределенных систем
Распределенные системы используются во всех сферах, от электронных банковских систем до сенсорных сетей и многопользовательских онлайн-игр. Многие организации используют распределенные системы для поддержки сетевых служб доставки контента.
В сфере здравоохранения распределенные системы используются для хранения и доступа, а также для телемедицины. В сфере финансов и торговли многие сайты онлайн-покупок используют распределенные системы для онлайн-платежей или системы распространения информации в финансовой торговле.
Распределенные системы также используются для транспорта в таких технологиях, как GPS, системы поиска маршрутов и системы управления дорожным движением. Сотовые сети также являются примерами распределенных сетевых систем из-за их базовой станции.
Google использует сложную и изощренную инфраструктуру распределенной системы для своих возможностей поиска. Некоторые говорят, что это самая сложная распределенная система на сегодняшний день.
Распределенные системы: определение, особенности и основные принципы
Общее представление о системе


 Вам будет интересно: Терминология. Что такое руина?
Вам будет интересно: Терминология. Что такое руина?
Распределенная система позволяет реализовать совместное использование ресурсов (включая программное обеспечение), подключенных к сети в одно и то же время.
Примеры распространения системы:
Распределенная система позволяет масштабироваться горизонтально и вертикально. Например, единственным способом обработки большего трафика будет обновление оборудования, на котором работает база данных. Это называется масштабированием по вертикали. Масштабирование по вертикали хорошо до определенного предела, после которого даже лучшее оборудование не справляется с обеспечением требуемого трафика.
Масштабирование по горизонтали означает добавление большего количества компьютеров, а не обновление аппаратного обеспечения на одном. Вертикальное масштабирование повышает производительность до новейших возможностей аппаратного обеспечения в распределенных системах. Эти возможности оказываются недостаточными для технологических компаний с умеренной и большой нагрузкой. Самое лучшее в горизонтальном масштабировании состоит в том, что нет ограничений на размер. Когда производительность ухудшается, просто добавляется другая машина, что, в принципе, возможно делать до бесконечности.
 Вам будет интересно: Что такое Камелот: происхождение и история легендарного замка
Вам будет интересно: Что такое Камелот: происхождение и история легендарного замка
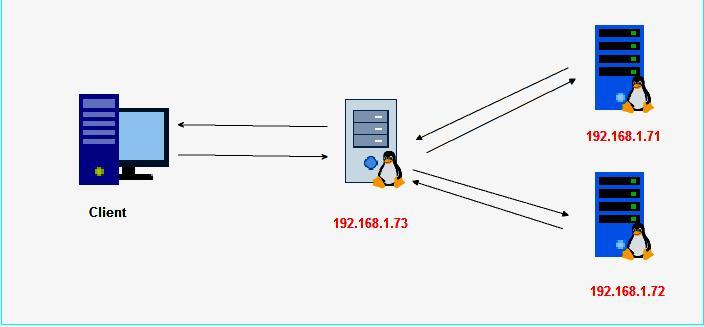
На корпоративном уровне распределенная система управления часто подразумевает выполнение различных шагов. В бизнес-процессах в наиболее эффективных местах сети компьютеров предприятия. Например, в типичном распределении с использованием трехуровневой модели распределенной системы обработки данных выполняется на ПК в месте нахождения пользователя, обработка бизнеса выполняется на удаленном компьютере, а доступ к базе данных и обработка данных осуществляется совершенно на другом компьютере, который обеспечивает централизованный доступ для многих бизнес-процессов. Как правило, этот вид распределенных вычислений использует модель взаимодействия «клиент-сервер».
Основные задачи
К основным задачам распределенной системы управления относятся:
 Вам будет интересно: Если речь косноязычная — это как?
Вам будет интересно: Если речь косноязычная — это как?
К задачам распредсистем относятся:
Распределенная вычислительная среда

(DCE) является широко используемым отраслевым стандартом, поддерживающим подобные распределенные вычисления. В Интернете сторонние поставщики предлагают некоторые обобщенные услуги, которые вписываются в эту модель.
Крупнейшим проектом grid-вычислений является SETI@home, в котором отдельные владельцы компьютеров добровольно выполняют некоторые из своих циклов обработки многозадачности, используя свой компьютер для проекта поиска внеземного интеллекта (SETI). Эта компьютерная проблема использует тысячи компьютеров для загрузки и поиска данных радиотелескопа.
Одним из первых применений grid-вычислений было нарушение криптографического кода группой, которая теперь известна как distributed.net. Эта группа также описывает свою модель как распределенные вычисления.
Масштабирование базы данных

Распространение новой информации от ведущего к ведомому не происходит мгновенно. На самом деле существует временное окно, в котором можно получить устаревшую информацию. Если бы это было не так, производительность записи пострадала бы, так как пришлось бы синхронно ждать распространения данных распределенных систем. Они поставляются с несколькими компромиссами.
Другой метод называется sharding (разделение). С помощью него сервер разбивается на несколько меньших серверов, называемых осколками. Эти осколки имеют разные записи, создаются правила о том, какие записи попадают в какой осколок. Очень важно создать такое правило, чтобы данные распространялись равномерно. Возможным подходом к этому является определение диапазонов в соответствии с некоторой информацией о записи.
 Вам будет интересно: Линейная скорость: формула нахождения
Вам будет интересно: Линейная скорость: формула нахождения
Этот осколочный ключ следует выбирать очень осторожно, так как нагрузка не всегда равна основам произвольных столбцов. Единственный осколок, который получает больше запросов, чем другие, называется горячей точкой, и стараются не допустить ее образования. После разделения данные перекалибровки становятся невероятно дорогими и могут привести к значительному простою.
Алгоритмы консенсуса базы данных

БД сложны для реализации в распределенных системах защиты, поскольку они требуют, чтобы каждый узел согласовывал правильное действие прерывания или фиксации. Это качество известно как консенсус, и он является фундаментальной проблемой в строительстве распредсистемы. Достижение типа соглашения, необходимого для проблемы «фиксации транзакции», является простым, если участвующие процессы и сеть полностью надежны. Тем не менее реальные системы подвержены ряду возможных сбоев процессов разбиения на сети, потерянные, искаженные или дублированные сообщения.
Это создает проблему, и невозможно гарантировать, что правильный консенсус будет достигнут в течение ограниченного периода времени в ненадежной сети. На практике существуют алгоритмы, которые довольно быстро достигают консенсуса в ненадежной сети. Кассандра фактически обеспечивает легкие транзакции посредством использования алгоритма Paxos для распределенного консенсуса.
В настоящее время MapReduce несколько устарела и приносит некоторые проблемы. Появились другие архитектуры, которые решают эти проблемы. А именно, Lambda Architecture для распределенной системы обработки потоков. Достижения в этой области принесли новые инструменты: Kafka Streams, Apache Spark, Apache Storm, Apache Samza.
Файловые системы хранения и тиражирования

Например, Yahoo известна тем, что работает HDFS на более чем 42 000 узлов для хранения 600 петабайт данных, еще с 2011 года. «Википедия» определяет разницу в том, что распределенные файловые системы разрешают доступ к файлам с использованием тех же интерфейсов и семантики, что и локальные файлы, а не через пользовательский API, такой как язык запросов Cassandra (CQL).
NameNodes несет ответственность за сохранение метаданных о кластере, например, какой узел содержит блоки файлов. Они выступают в качестве координаторов сети, выясняя, где лучше хранить и копировать файлы, отслеживая состояние системы. DataNodes просто хранят файлы и выполняют команды, такие как репликация файла, новая запись и другие.
Межпланетная файловая система (IPFS) представляет собой захватывающий новый одноранговый протокол/сеть для распределенной файловой системы. Используя технологию Blockchain, она может похвастаться полностью децентрализованной архитектурой без единого владельца или точки отказа.
IPFS предлагает систему именования (аналогичную DNS), называемую IPNS, и позволяет пользователям легко получать информацию. Она хранит файл через историческое управление версиями, подобно тому, как делает Git. Это позволяет получить доступ ко всем предыдущим состояниям файла. Он все еще переживает тяжелое развитие (v0.4 на момент написания), но уже видел проекты, заинтересованные в его создании (FileCoin).
Система передачи сообщений
Системы обмена сообщениями обеспечивают центральное место для хранения и распространения сообщений внутри общей системы. Они позволяют отделить прикладную логику от непосредственного общения с другими системами.
Проще говоря, платформа обмена сообщениями работает следующим образом:
Есть несколько популярных первоклассных платформ обмена сообщениями.
Приложения по взаимодействию машин
 Вам будет интересно: «Почаще»: слитно или раздельно? Как написание зависит от части речи?
Вам будет интересно: «Почаще»: слитно или раздельно? Как написание зависит от части речи?
Эта распредсистема представляет собой группу компьютеров, работающих вместе, чтобы отображаться как отдельный компьютер для конечного пользователя. Эти машины имеют общее состояние, работают одновременно и могут работать независимо, не влияя на время безотказной работы всей системы.
Если считать базу данных как распределенную, только в том случае, если узлы взаимодействуют друг с другом для координации своих действий. Она является в этом случае чем-то вроде приложения, выполняющего его внутренний код в одноранговой сети, и классифицируется как распределенное приложение.

Примеры таких приложений:
Распределенные регистры можно рассматривать как неизменяемую, доступную только для приложений базу данных, которая реплицируется, синхронизируется и делится на всех узлах распредсети.
Примеры распределенных операционных систем
Типы систем появляются для пользователя, поскольку они являются однопользовательскими системами. Они делят свою память, диск и пользователь не испытывают затруднений при навигации по данным. Пользователь хранит что-то в своем ПК, и файл хранится в нескольких местах, то есть на присоединенных компьютерах, так что потерянные данные могут легко восстановиться.
Примеры распределенных операционных систем:
Если какой-либо компьютер загружается выше, то есть если многие запросы обмениваются между отдельными ПК, так происходит балансировка нагрузки. В этом случае запросы распространяются на соседний ПК. Если в сети становится больше нагрузки, тогда ее можно расширить, добавив в сеть больше систем. В сетевом файле и папках синхронизируются, и соглашения об именах используются таким образом, чтобы при извлечении данных не возникало ошибок.
Кэширование также используется при манипулировании данными. Для наименования файлов на всех компьютерах используется одно пространство имени. Но файловая система действует для каждого компьютера. Если в файле появляются обновления, то он записывается на один компьютер, и изменения передаются на все компьютеры, поэтому файл выглядит таким же.
В процессе чтения / записи происходит блокировка файлов, поэтому между разными компьютерами не происходит взаимоблокировки. Также происходят сеансы, такие как чтение, запись файлов за один сеанс и закрытие сеанса, а затем другой пользователь может сделать то же самое и так далее.
Преимущества использования
Операционная система разработана для облегчения повседневной жизни людей. Для пользовательских преимуществ и потребностей операционная система может быть однопользовательской или распределенной. В системе распределенных ресурсов многие компьютеры связаны друг с другом и совместно используют свои ресурсы.
Преимущества такой работы:
Это кратко о распредсистеме, почему ее используют. Некоторые важные вещи, которые нужно запомнить: они сложны и выбираются по соотношению масштаба и цены, и с ними труднее работать. Данные системы распределены в нескольких категориях хранилищ: вычислительные, файловые и системы обмена сообщениями, регистры, приложения. И все это только очень поверхностно о сложной информационной системе.
Введение в распределенные системы
1.1. Понятие распределенной системы
Такой подход к определению распределенной системы имеет свои недостатки. Например, все используемое в такой распределенной системе программное обеспечение могло бы работать и на одном единственном компьютере, однако с точки зрения приведенного выше определения такая система уже перестанет быть распределенной. Поэтому понятие распределенной системы, вероятно, должно основываться на анализе образующего такую систему программного обеспечения.
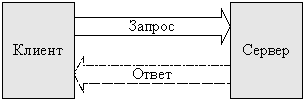
Взаимодействие в рамках модели клиент сервер может быть как синхронным, когда клиент ожидает завершения обработки своего запроса сервером, так и асинхронным, при котором клиент посылает серверу запрос и продолжает свое выполнение без ожидания ответа сервера. Модель клиента и сервера может использоваться как основа описания различных взаимодействий. Для данного курса важно взаимодействие составных частей программного обеспечения, образующего распределенную систему.
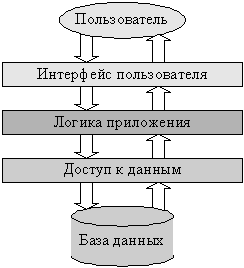
Поскольку на практике разных пользователей системы обычно интересует доступ к одним и тем же данным, наиболее простым разнесением функций такой системы между несколькими компьютерами будет разделение логических уровней приложения между одной серверной частью приложения, отвечающим за доступ к данным, и находящимися на нескольких компьютерах клиентскими частями, реализующими интерфейс пользователя. Логика приложения может быть отнесена к серверу, клиентам, или разделена между ними (рис. 1.3).
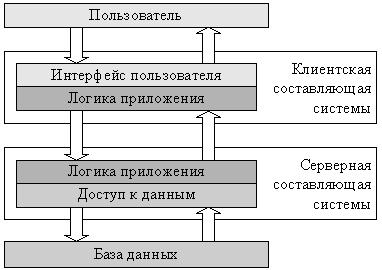
Архитектуру построенных по такому принципу приложений называют клиент серверной или двухзвенной. На практике подобные системы часто не относят к классу распределенных, но формально они могут считаться простейшими представителями распределенных систем.
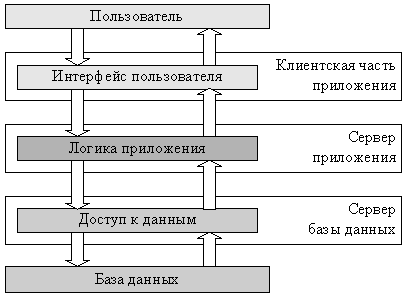
Запрос пользователя в подобных системах последовательно обрабатывается клиентской частью системы, сервером логики приложения и сервером баз данных. Однако обычно под распределенной системой понимают системы с более сложной архитектурой, чем трехзвенная.

Применительно к приложениям автоматизации деятельности предприятия, распределенными обычно называют системы с логикой приложения, распределенной между несколькими компонентами системы, каждая из которых может выполняться на отдельном компьютере. Например, реализация логики приложения системы розничных продаж должна использовать запросы к логике приложения третьих фирм, таких как поставщики товаров, системы электронных платежей или банки, предоставляющие потребительские кредиты (рис. 1.5).
Таким образом, в обиходе под распределенной системой часто подразумевают рост многозвенной архитектуры «в ширину», когда запросы пользователя не проходят последовательно от интерфейса пользователя до единственного сервера баз данных.
В качестве другого примера распределенной системы можно привести сети прямого обмена данными между клиентами ( peer-to-peer networks ). Если предыдущий пример имел «древовидную» архитектуру, то сети прямого обмена организованы более сложным образом, рис. 1.6. Подобные системы являются в настоящий момент, вероятно, одними из крупнейших существующих распределенных систем, объединяющие миллионы компьютеров.
Распределенные системы
В системе могут быть не только попарные связи, но и связи троек элементов. Такие связи описываются тернарными отношениями 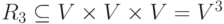 . Например, связь «ребенок и его родители» – связь трех элементов.
. Например, связь «ребенок и его родители» – связь трех элементов.
В общем случае в системе могут быть также связи, задаваемые отношениями  . Здесь n – количество элементов в системе.
. Здесь n – количество элементов в системе.
Подчеркнем, что бинарных отношений в системе может быть несколько. Например, в цилиндре двигателя автомобиля газ (бензино-воздушная смесь), загораясь, толкает поршень и, одновременно, нагревает его. Т.е. существует отношение «x толкает y» и отношение «x нагревает y». Ясно, что в зависимости от целей исследования системы одни отношения рассматриваются как существенные, а другие – как второстепенные.
Распределенные системы могут быть непрерывными и дискретными.
Непрерывные распределенные системы характеризуются бесконечным количеством элементов, а также тем, что в любой малой окрестности любого элемента (в смысле предикатов местоположения) находится, по крайней мере, еще один элемент.
Дискретные распределенные системы характеризуются тем, что элементы системы четко «очерчены», отделены друг от друга. Один из видов отношений – бинарное отношение «быть соседними элементами». Между двумя соседними элементами других элементов нет. Это не означает, что между ними нельзя включить какой-либо третий элемент. Но тогда первые два перестают быть соседними.
В дальнейшем рассматриваются в основном дискретные системы.
Примеры распределенных систем.
Сеть газопроводов состоит из газоперекачивающих станций, газораспределительных узлов, трубопроводов. Трубопроводы соединяют между собой станции и узлы. Трубопроводы проложены также к источникам (месторождениям) газа и к потребителям газа.
Основное отношение в системе – это соединение (направленное) элементов: соединение трубопровода и газоперекачивающей станции, соединение трубопровода и газораспределительного узла. Важными параметрами элементов являются их местоположения (в географическом смысле). Для трубопровода местоположение задается более сложным образом, чем для станций и узлов: как минимум, это две точки – начало и конец трубопровода, в общем случае – это кривая в трехмерном пространстве (разница высот должна приниматься во внимание при перекачке газа).
Для эксплуатации сети газопроводов должны постоянно решаться задачи измерения давления в различных точках сети, определения объемов пропущенного газа, регулирования потоков газа. Характерно, что эти задачи, с одной стороны, распределены в сети (т.е. ставятся и решаются в различных точках системы), с другой стороны, являются частями общей задачи управления сетью, связывающей источники газа с потребителями.
Для управления сетью необходимо знать значения электрического напряжения в различных точках сети, падение напряжения в ЛЭП, значения потребляемого тока. Вся эта информация распределена по сети. По сети распределены также устройства управления участками сети – различные коммутаторы, переключатели, выключатели. Задача управления сетью с точки зрения оптимизации потоков электроэнергии решается централизованно, но иногда она разбивается на подзадачи, решаемые в определенных секторах сети. Например, известные «веерные отключения» при перегрузке сети, перенаправление потоков из одних регионов в другие в соответствии с временем суток и т.д.
Кроме этого решаются задачи для совместной работы сетей разных стран. В этом случае орган, принимающий централизованные решения, отсутствует, и задача решается как распределенная.
Это один из ярких примеров распределенных систем, особенно в тех случаях, когда сети связи используются для передачи компьютерной информации, т.е. в качестве компьютерных сетей.
Каждый узел сети характеризуется скоростью обработки информации. В сетях связи – это скорость коммутации (переключения) каналов связи. В компьютерных сетях в узле сети может находиться сервер, который выполняет определенное обслуживание по поступающим запросам. Время этого обслуживания – дополнительная характеристика узла сети.
Каналы связи, соединяющие узлы, различаются своей пропускной способностью – скоростью передачи информации и иными техническими характеристиками (оптоволоконные, кабельные, спутниковые каналы, радиоканалы и др.). В зависимости от этого они могут требовать различных процедур обслуживания.
В целом сеть связи должна обеспечить передачу сообщения от одного узла к другому. Причем эти узлы могут быть не связаны непосредственно друг с другом каналом связи. Тогда требуется проложить маршрут от одного узла к другому, проходящий через промежуточные узлы.
Задача маршрутизации – типичная распределенная задача оптимизационного характера. Она имеет многообразные постановки.
Простейший вариант – статическое решение. По заданной топологии сети, известным пропускным способностям каналов и средним задержкам в узлах можно для каждой пары узлов vi и vj найти оптимальный маршрут и всегда им пользоваться.
Задача маршрутизации входит как составная часть в более общую задачу управления сетью связи.
Система перевозки грузов включает транспортные средства (грузовики, поезда, самолеты, корабли), транспортные пути (автомобильные, железные дороги, морские и речные пути и др.), склады, порты, станции, погрузочно-разгрузочные механизмы и проч.
При транспортировке конкретного груза от поставщика к получателю логистическая цепочка может включать довольно большое количество элементов системы, в том числе многочисленные перегрузки с одного вида транспорта на другой. При этом транспортное средство зачастую везет одним рейсом грузы от разных поставщиков разным получателям. Каждый элемент логистической системы характеризуется определенным набором параметров – грузоподъемностью, скоростью, размером грузов, объемом складских помещений, количеством причалов в порту и т.д.
Если к этому добавить то, что чуть ли не каждый элемент имеет своего собственника, то станет понятно, что централизованно решать задачу оптимизации доставки грузов (минимальное время при ограничении на стоимость или минимальная стоимость при ограничении на время) невозможно.
Почти каждый банк самостоятелен. Банковская система распределена по всему Земному шару. Но у всех банков есть общая задача – обслужить клиента, где бы он ни был. Клиент должен иметь возможность получить свои деньги даже там, где о его банке никогда не слышали. Или сделать банковский перевод в далекую страну. Для осуществления этих операций банки связаны между собой системой договоров и поддерживающими эту систему техническими средствами.
Клиент, находящийся в пункте A, ставит задачу проводки платежа из своего банка, находящегося в пункте B, в банк получателя, находящийся в пункте C. При этом получатель, находящийся в пункте D, должен получить уведомление. Это общая задача, которая разделяется банками на части, решаемые в разных местах, т.е. превращается в распределенную задачу.
Крупные фирмы (и даже не очень крупные) имеют офисы и производства, рассредоточенные в пределах города, страны и даже всей планеты, а в будущем с освоением полезных ископаемых на Луне или Марсе, заберутся и туда. Причины рассредоточенности различны. Может быть, это отсутствие достаточных помещений в одном месте или другие подобные факторы.
Но есть и совершенно объективные причины создания удаленных подразделений (отделений) корпораций. Прежде всего, это приближение к рынку сбыта продукции. Рынок, по определению, является рассредоточенной системой по большим территориям. Для того чтобы эффективно работать на рынке, корпорация создает региональные отделения. Например, транснациональные корпорации обычно открывают отделения по Западной Европе, Восточной Европе, Африке и Ближнему Востоку, Азии, Америке. При большом рынке происходит еще большее географическое дробление.
Вторая причина создания удаленных подразделений – вынесение производств в другие страны. Штаб-квартира корпорации, как правило, находится в высокоразвитой стране, в которой законодательно закреплена довольно высокая заработная плата наемных работников. Производства же выносятся в те страны, где работники довольствуются весьма скромной оплатой. Соответственно, прибыли корпорации растут. Это касается и высокотехнологичных областей.
Например, в некоторых американских исследованиях утверждается, что в США профессия программиста в ближайшие десятилетия будет неперспективной: рост потребности в труде программистов будет отставать от роста потребности в труде многих других специалистов. Он будет отставать даже от среднего (по всем специальностям) роста потребности в специалистах. Причина простая – работа по программированию будет заказываться работникам в других странах. В настоящее время Индия стала одной из таких стран. Программный продукт при этом выпускается не с маркой «made in India», а под маркой корпорации – заказчика.
Наличие отделений у корпорации приводит к необходимости создания распределенных информационных систем.
Государственное и муниципальное управление.
Системы государственного и муниципального управления, что называется, «по определению» являются распределенными системами. Или можно сказать «естественными распределенными системами». Такими же естественными, как и газовые и электросети. Управление, выработанное в столице, может достигать своих целей только при помощи своих уполномоченных на местах. Равно, как и сбор информации, необходимой для выработки управления, также производится на местах.


