Методы распознавания текста
Немного теории
Тема распознавания текста попадает под раздел распознавания образов. И для начала коротко о самом распознавании образов.
Распознавание образов или теория распознавания образов это раздел информатики и смежных дисциплин, развивающий основы и методы классификации и идентификации предметов, явлений, процессов, сигналов, ситуаций и т. п. объектов, которые характеризуются конечным набором некоторых свойств и признаков. Данное определение нам дает Wikipedia.
Итак, моя тема — это распознавание текста на графических изображениях и сейчас говорить о важности данного подраздела не приходиться. Всем давно известно, что существуют миллионы старых книг, которые хранятся в хранилищах строгого режима, доступ к которым имеет только специализированный персонал. Использование этих книг запрещено по причине их ветшалости и дряхлости, так как возможно, что они могут рассыпаться прямо в руках читателя, но знания которые они хранят, представляют, несомненно, большой клад для человечества и поэтому оцифровка этих книг столь важна. Именно этим в частности занимаются специалисты в области обработки данных.
Теперь о самой работе. Было написано приложение, способное распознавать текст при использовании изображений высокого либо среднего качества, со слабым шумом либо без него. Приложение способно распознавать буквы английского алфавита, верхнего и нижнего регистра. Изображение подается для распознавания непосредственно из самого приложения.
Фильтрация и обработка

Сегментация
Непосредственно перед распознаванием изображение нормализуется и приводится до размеров шаблонов, подготовленных заранее.
Далее наступает сам процесс распознавания. Для пользователя имеется два выбора, при помощи метрик и при помощи нейронной сети.
Распознавание
Рассмотрим первый случай — распознавание при помощи метрик.
Метрика – некоторое условное значение функции, определяющее положение объекта в пространстве. Таким образом, если два объекта расположены близко друг от друга, то есть похожи (например, две буквы А написанные разным шрифтом), то метрики для таких объектов будут совпадать или быть предельно похожими. Для распознавания в этом режиме была выбрана метрика Хэмминга.
Метрика Хэмминга – метрика которая показывает, как сильно объекты не похожи между собой.
Данную метрику часто используют при кодировании информации и передаче данных. Например, после сеанса передачи на выходе имеется следующая последовательность бит (1001001), также нам известно, что должна прийти другая последовательность бит (1000101). Мы вычисляем метрику путем сравнения частей последовательности с соответствующими местами из другой последовательности. Таким образом метрика Хэмминга в нашем случае равна 2. Так как объекты отличаются в двух позициях. 2- это степень непохожести, чем больше, тем хуже в нашем случае.
Следовательно, чтобы определить какая буква изображена нужно найти ее метрику со всеми готовыми шаблонами. И тот шаблон, чья метрика окажется наиболее близкой к 0 будет ответом.
Но как показала практика подсчет одной лишь метрики не дает положительного результата, так многие буквы похожи между собой. например «j» «i», что приводит к ошибочному распознаванию.
Тогда было принято решение придумать новые метрики, позволяющие разграничить некоторое множество букв в отдельный класс. В частности, были реализованы метрики (Отражения горизонтального и вертикального, преобладания веса горизонтального и вертикального).
Экспериментом было выяснено, что такие буквы как «H» «I» «i» «O» «o» «X» «x» «l» обладают суперсимметрией (полностью совпадают со своими отражениями и значимые пиксели распределены равномерно по всему изображению), поэтому они были вынесены в отдельный класс, что сокращает перебор всех метрик примерно в 6 раз. Аналогичные действия были проведены в отношении других букв. В среднем уменьшение перебора достигает примерно 3 раза.
Также есть уникальная буква такая как «J», которая находится в своем классе одна, и значит идентифицируются однозначно. Далее, для каждого класса высчитывается метрика Хэмминга, которая на данном этапе дает лучшие показатели чем при прямом применении.
При создании шаблонов использовался шрифт «consolas», поэтому, если распознаваемый текст написан этим шрифтом, распознавание имеет точность порядка 99 процентов. При изменении шрифта, точность падает до 70 процентов.
Второй способ распознавания – при помощи нейронной сети.
Что такое нейронная сеть и в биологическом понимании, и в математическом я рассказывать не буду, так как данного материала полно в интернете и повторять его не хочется. Сказать лишь можно то, что в математическом смысле нейронная сеть — это лишь модель биологического определения.
Существуют также множества разновидностей этих моделей. В своей работе я использовал однослойную сеть Кохонена.
Принцип работы нейронной сети таков, что поучив на входной слой нейронов новое изображение сеть реагирует импульсом того или иного нейрона. Так как все нейроны поименованы значениями букв, следовательно, среагировавший нейрон и несет ответ распознавания. Углубляясь в терминологию сетей можно сказать, что нейрон помимо выхода имеет также множество входов. Данные входы описывают значение пикселя изображения. То есть, если имеется изображение 16х16, входов у сети должно быть 256.
Каждый вход воспринимается с определенным коэффициентом и в результате, по окончанию распознавания на каждом нейроне скапливается определенный заряд, чем заряд будет больше тот нейрон и испустит импульс.
Но что бы коэффициенты входов были правильно настроены необходимо сначала обучить сеть. Этим занимается отдельный модуль обучения. Данный модуль берет очередное изображение из обучающей выборки и скармливает сети. Сеть анализирует все позиции черных пикселей и выравнивает коэффициенты минимизируя ошибку совпадения методом градиента, после чего определенному нейрону сопоставляется данное изображение.
Все коэффициенты выровнены и готовы воспринимать изображения.
Точность распознавания при этом методе достигает 80 процентов. Следует заметить, что точность распознавания зависит от обучающей выборки, как от количества, так и от качества.
Сервисы для распознавания текста — подборка лучших


Заказчик прислал сканы рабочих документов, в университете скинули фотку конспекта? Когда-то тексты умели распознавать только сканеры и то далеко не все. Сейчас же даже приложения на смартфоне могут перевести визуальный текст в редактируемый документ. А в этом материале ищем лучшие сервисы по распознаванию текста для вашего компьютера и смартфона тоже.
Finereaderonline.com
Компания ABBYY идет в плане распознавания текстов и обработки цифровых документов впереди всех. В арсенале их софта даже цифровые подписи, которые почти невозможно отличить от настоящих. Finereaderonline поддерживает почти 200 языков, работает быстро и онлайн — ничего не надо устанавливать. Можно выбрать разные форматы для сохранения текста, обработка текста происходит очень быстро и достаточно точно. Единственный нюанс — лимит на загрузку файлов до 100 Мб. Но никто не запрещает вам загрузить несколько документов подряд. Сервис работает полностью онлайн, русифицирован и интуитивно понятен в управлении.
Sodapdf.com
Еще один неплохой сервис, хотя тут нам предлагают скачать прогу отдельно. Правда, чуть менее обученный, чем софт от ABYYY — Sodapdf знает только 46 языков. Впрочем, если вам не нужно переводить с ацтекского или зулу, то проблем не возникнет. Программа условно бесплатная — есть триальная версия, полный функционал стоит от 7 до 17 евро в месяц в зависимости от пакета. Soda умеет конвертировать разные форматы, распознавать тексты, ставить электронные подписи и имеет большой набор инструментов для работы с PDF файлами и изображениями.

WinScan2PDF
Элементарная, простая маленькая утилита, которая состоит из трех кнопок: «выбрать источник», «сканировать» и подтвердить или отменить операцию. Поддерживает 23 языка, работает с многостраничными файлами и сохраняет обработанный файл в формате PDF. У этой программы есть одна особенность — она не работает с готовыми файлами и считывает документы только с подключенного сканера.

Free Online OCR
Не такой симпатичный, как Finereader, но тоже вполне умелый онлайн-сервис. Англоязычный, слегка устаревший интерфейс, в котором, впрочем, несложно разобраться. Free Online OCR поддерживает 106 языков и распознает текст с большинства самых популярных форматов файлов: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu. Сохранять готовые доки может не только в PDF, но и в стандарных doc и txt. Кроме текста, может распознать математические уравнения, правильно форматировать текст в колонках и столбцах или обработать только выделенный фрагмент. Качество распознавания довольно высокое даже c картинок низкого качества.

Microsoft OneNote
Распознавание текста здесь скорее дополнительная фича, а не основная задача. Вы можете вставить картинку в текущую запись OneNote и правой кнопкой мыши выбрать «Копировать текст из рисунка». Цифровая записная книжка от Microsoft однозначно не подойдет для обработки больших файлов, документов и постоянной работы с файлами. Но может помочь в мелких повседневных задачах — перевести небольшой текст с картинки, скриншота, рекламного макета, чтобы не вводить вручную. Качество распознавания у OneNote не очень высокое, а добавлять в файл многостраничные документы неудобно. Но OneNote и не для этого все-таки.

Readiris
Мощный и удобный конкурент ABBYY FineReader. Быстро и очень чисто распознает даже едва различимые тексты, при этом поддерживает 137 языков, включая русский. Работает очень быстро и легко обрабатывает даже большие объемы текста. Сохраняет исходное форматирование, не игнорируя кавычки, размеры шрифта и стиль написания. Может почистить текст от помарок и предложить исправления в словах. Знает символы, уравнения. Контактирует со сканерами, облачными сервисами, поддерживает кучу форматов. В общем, полноценный и удобный сервис, который не умеет разве что редактировать итоговый файл PDF. Правда, за полный инструментарий придется платить, но есть бесплатная триальная версия.

Img2txt.com
Приятный дизайн, понятный интерфейс и высокая скорость обработки текста — что еще нужно для работы? Продвинутые алгоритмы распознавания помогают считывать документы даже плохого качества. Молниеносно конвертирует большие объемы текста, но при желании можно выбрать отдельную область файла для работы. Есть интеграция с Google Documents, хороший инструментарий для работы с документами PDF. Маловато языков — всего 35, но для основных задач этого может вполне хватить.

OCR CuneiForm
Шустро и тщательно распознает сфотографированные или отсканированные тексты, графические файлы. Старается сохранить исходную структуру текста, элементов и шрифты. Переводит все в редактируемые форматы на выбор. В общем, стандартный набор функционала. И, что самое главное, полностью бесплатный.
TextGrabber 6
Полностью бесплатное приложение для смартфонов за авторством компании ABBYY. Собственно, этим все сказано — в TextGrabber 6 все хорошо с распознаванием текста, есть встроенный модуль переводчика. Программа работает с помощью камеры и на распознавание, и на перевод. Поддерживает кучу языков, работает быстро и выглядит приятно.
Сканирование и распознавание текста
Наверное, каждый из нас сталкивался с задачей, когда нужно перевести бумажный документ в электронный вид. Особенно это часто нужно делать тем кто учиться, работает с документацией, переводит тексты при помощи электронных словарей и т.д.
В этой статье мне хотелось бы поделиться некоторыми азами этого процесса. Вообще, сканирование и распознавание текста — довольно трудоемко, так, как большинство операций придется делать вручную. Мы попытаемся разобраться по шагам, что, как и почему.
Не все сразу понимают одну вещь. После сканирования (пригона всех листов на сканере) у вас будут картинки формата BMP, JPG, PNG, GIF (могут быть и другие форматы). Так вот с этой картинки нужно получить текст — это процедура называется распознаванием. В таком порядке и будет изложение ниже.
1. Что нужно для сканирования и распознавания?
Для перевода печатных документов в текстовый вид, вам для начала нужен сканер и соответственно, «родные» программы и драйверы, которые с ним шли. При помощи них можно будет сканировать документ и сохранить его для дальнейшей обработки.
Можно воспользоваться и другими аналогами, но софт, который шел со сканером в комплекте, обычно работает быстрее и имеет больше опций.
В зависимости от того, какой у вас сканер — скорость работы может существенно различаться. Есть сканеры, которые могут получить картинку с листа за 10 сек., есть которые будут получать за 30 сек. Если сканируете книгу на 200-300 листов — думаю, не трудно подсчитать во сколько раз будет разница во времени?
2) Программа для распознавания
В нашей статье я буду показывать вам работу в одной из лучших программ для сканирования и распознавания абсолютно любых документов — ABBYY FineReader. Т.к. программа платная, то сразу дам ссылку и на другую — ее бесплатный аналог Cunei Form. Правда, я бы не стал их сравнивать, ввиду того, что FineReader выигрывает по всем параметрам, рекомендую все же попробовать именно ее.

ABBYY FineReader 11
Одна из лучших программ в своем роде. Она предназначена для того, чтобы распознать текст на картинке. Встроено множество опций и функций. Может разобрать кучу шрифтов, поддерживает даже рукописные варианты (правда, лично не пробовал, думаю, хорошо вряд ли будет распознавать рукописный вариант, если только у вас не идеальный каллиграфический почерк). Более подробно о работе с ней будет рассказано ниже. Здесь же отметим, что в статье будет рассказано о работе в программе 11 версии.
Как правило, разные версии ABBYY FineReader не сильно отличаются друг от друга. Вы без труда сделаете то же самое и в другой. Главные отличия могут быть в удобстве, быстроте работы программы и ее возможностях. Например, более ранние версии отказываются открывать документ PDF и DJVU…
3) Документы для сканирования
Да, вот так вот, решил вынести документы отдельной графой. В большинстве случаев сканируют какие-нибудь учебники, газеты, статьи, журналы и пр. Т.е. те книги и ту литературу которая пользуется спросом. Я это к чему веду? Из личного опыта могу сказать, что многое, что вы захотите сканировать — возможно уже есть в сети! Сколько раз лично я экономил время, когда находил ту или иную книгу уже сканированную в сети. Мне оставалось только скопировать текст в документ и продолжить с ним работу.
Из этого простой совет — прежде чем что-то сканировать, проверьте, может уже кто-то отсканировал и вам не нужно терять свое время.
2. Параметры сканирования текста
Здесь я не будут рассказывать о ваших драйверах для сканера, программах, которые вместе с ним шли, ибо все модели сканеров разные, ПО тоже везде разное и угадать и тем более показать наглядно как выполнять операцию — нереально.
Но во всех сканерах есть одни и те же настройки, которые сильно могут повлиять на скорость и качество вашей работы. Вот о них таки как раз и поговорим здесь. Буду перечислять по порядку.
1) Качество сканирования — DPI
Во-первых, качество сканирования поставьте в опциях не ниже 300 DPI. Желательно даже выставить побольше, если это возможно. Чем выше показатель DPI — тем четче получиться ваша картинка, ну и тем самым, быстрее пройдет дальнейшая обработка. К тому же чем выше качество сканирования — тем меньше ошибок вам в последствии придется исправлять.
Оптимальный вариант обеспечивает, обычно, 300-400 DPI.
Этот параметр очень сильно влияет на время сканирования (кстати, DPI тоже влияет, но те так сильно, и только когда пользователь ставит высокие значения).
Обычно выделяют три режима:
— черно-белый (отлично подойдет для простого текста);
— серый ( подойдет для текста с таблицами и картинками);
— цветной (для цветных журналов, книг, в общем, документов, где важна цветность).
Обычно от выбора цветности зависит время сканирования. Ведь если документ у вас большой, то даже лишние 5-10 секунд на странице в целом выльются в приличное время…
Документ вы можете получить не только сканированием, но и сфотографировав его. Как правило, в этом случае у вас будут некоторые другие проблемы: искажение картинки, смазанность. Из-за этого может потребоваться более длительная дальнейшая правка и обработка полученного текста. Лично я не рекомендую пользоваться фотоаппаратами для этого дела.
Важно отметить, что не каждый такой документ получится распознать, т.к. качество сканирования у него может быть крайне низким…
3. Распознавание текста документа
Будем считать, что заветные сканированные страницы вы получили. Чаще всего они представляют собой форматы: tif, bmb, jpg, png. В общем-то, для ABBYY FineReader — это не сильно важно…
После открытия в ABBYY FineReader картинки, программа, как правило, на автомате начинает выделять области и распознавать их. Но иногда она делает это не правильно. Для этого-то мы и рассмотрим выделение нужных областей вручную.
Важно! Не все сразу понимают, что после открытия документа в программе, слева в окне отображается исходный документ, в котором вы и выделяете различные области. После нажатия на кнопку «распознавания» программа в окне справа выведет вам готовый текст. После распознавания, кстати, целесообразно проверить текст на ошибки в том же самом FineReader.
3.1 Текст
Эта область используется для выделения текста. Картинки и таблицы нужно исключать из нее. Редкие и необычный шрифты придется вводить вручную…
Для выделения текстовой области, обратите внимание на панель в верхней части FineReader. Там есть кнопка «Т» (см. скриншот ниже, указатель мышки как раз на этой кнопке). Щелкаете по ней, затем на картинке ниже выделяете аккуратно прямоугольную область, в которой располагается текст. Кстати, в некоторых случаях нужно создавать текстовых блоков по 2-3, а иногда по 10-12 на страницу, т.к. форматирование текста может быть разным и одним прямоугольником всю область не выделить.
Важно отметить, что в текстовую область не должны попадать картинки! В дальнейшем это вам сэкономит кучу времени…
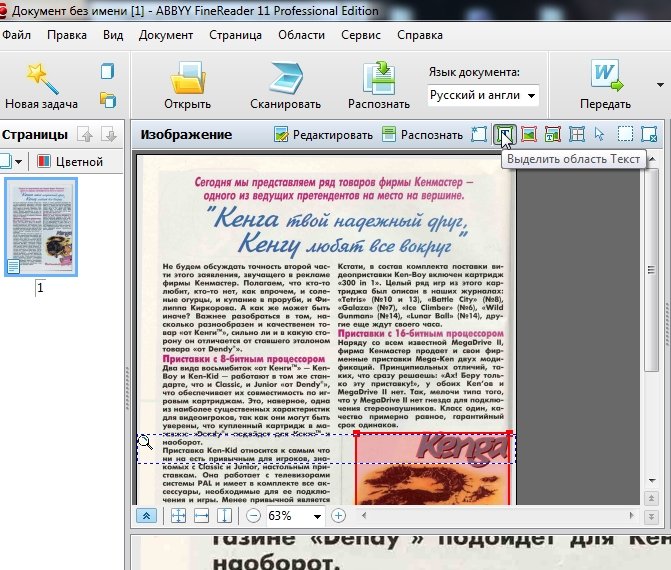
3.2 Картинки
Используется для выделения картинок и тех областей, которые тяжело распознать из-за плохого качества, или необычности шрифта.
На скриншоте ниже указатель мышки находится на кнопке, используемой для выделения области «картинка». Кстати, в эту область можно выделить абсолютно любую часть страницы, а FineReader вставит ее потом в документ как обычную картинку. Т.е. просто «тупо» скопирует…
Обычно эту область используют для выделения плохо отсканированных таблиц, для выделения нестандартного текста и шрифта, само-собой картинок.
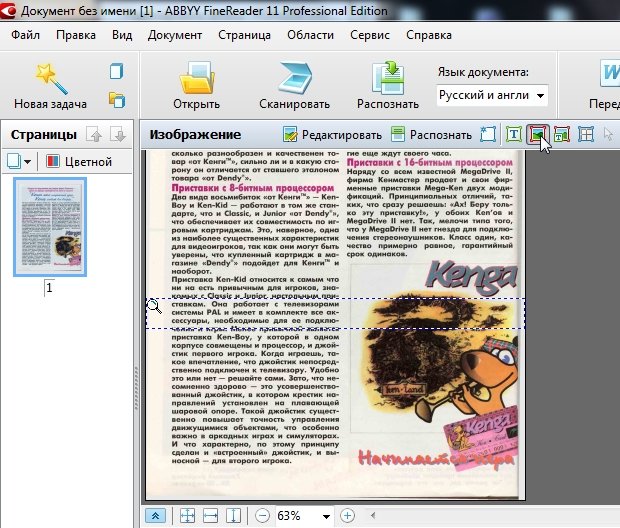
3.3 Таблицы
На скриншоте ниже показана кнопка для выделения таблиц. Вообще, лично я ее использую крайне редко. Дело в том, что вам придется довольно рутинно рисовать (фактически) каждую линию на таблице и показывать что и как программе. Если таблица небольшая и в не очень хорошем качестве, я рекомендую для этих целей использовать область «картинка». Тем самым сэкономите кучу времени, а таблицу можно потом в Word сделать быстренько на основе картинки.

3.4 Ненужные элементы
Важно отметить. Иногда на странице есть ненужные элементы, которые мешают распознать текст, или вообще не дают вам выделить нужную область. Их можно при помощи «ластика» удалить вовсе.
Для этого переходим в режим редактирования изображения.

Выбираем инструмент «ластик» и выделяем ненужную область. Она сотрется и на ее месте будет белый лист бумаги.
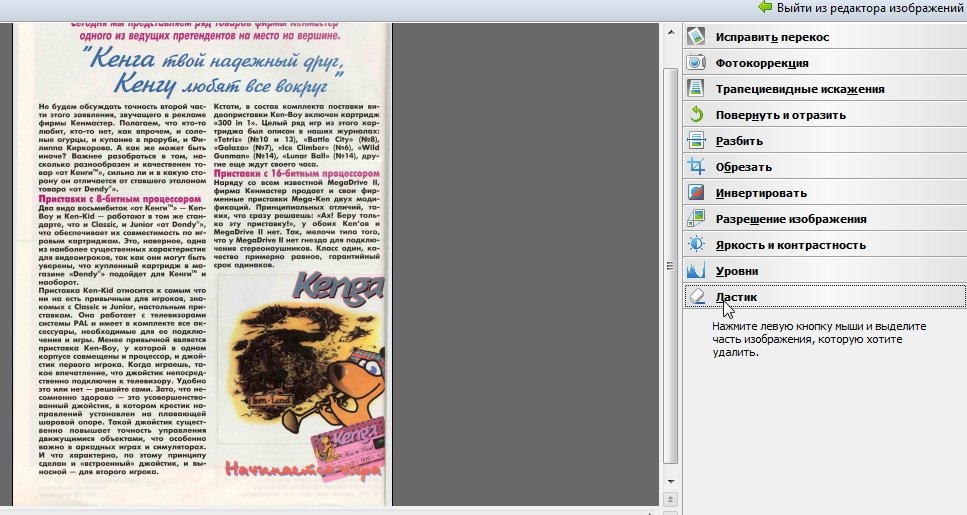
Кстати, рекомендую использовать вам эту опцию как можно чаще. Старайтесь все текстовые области которые вы выделили, где вам не нужен кусок текста, или присутствуют любые ненужные точки, размытости, искажения — удалять ластиком. Благодаря этому распознавание будет быстрее!
4. Распознавание файлов PDF/DJVU
Вообще, этот формат распознавания не будет отличаться ничем другим от остальных — т.е. работать с ним можно так же как с картинками. Единственное, программа не должна быть слишком старой версии, если файлы PDF/DJVU у вас не открываются — обновите версию до 11.
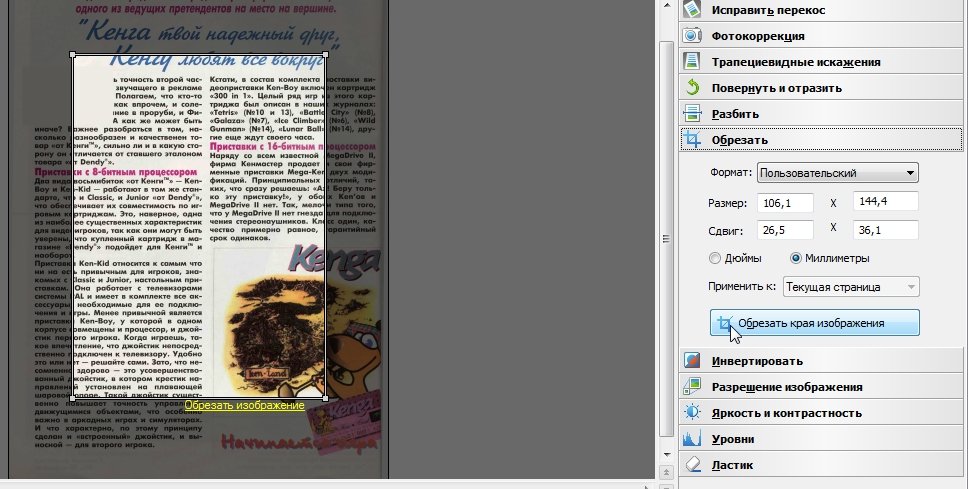
Небольшой совет. После открытия документа в FineReader — он автоматически начнет распознавать документ. Часто в файлах PDF/DJVU определенная область страницы не нужна во всем документе! Чтобы удалить такую область на всех страницах сделайте следующее:
1. Зайдите в раздел редактирования изображения.
2. Включите опция «обрезки».
3. Выделите область, нужную вам на всех страницах.
4. Нажмите применить ко всем страницам и обрежьте.
5. Проверка ошибок и сохранение результатов работы
Казалось бы, какие еще могут быть проблемы, когда все области были выделены, затем распознаны — бери да сохраняй… Не тут то было!
Во-первых, нужна проверка документа!
Чтобы ее включить, после распознавания, в окне справа, будет кнопка «проверка», см. скриншот ниже. После ее нажатия программа FineReader будет автоматически показывать вам те области, где у программы возникли ошибки и она не смогла достоверно определить тот или иной символ. Вам останется только выбирать, либо вы согласны с мнением программы, либо вводите свой символ.
Кстати, в половине случаев, примерно, программа будет вам предлагать готовое правильное слово — вам останется толкьо мышкой выбрать нужный вариант.
Во-вторых, после проверки вам нужно выбрать формат, в который вы сохраните результат своей работы.
Здесь FineReader дает вам развернуться на полную катушку: можно просто передать информацию в Word один в один, а можно сохранить ее в одном из десятков форматов. Но хотелось бы выделить другой важный аспект. Какой формат бы не выбрали, более важно выбрать тип копии! Рассмотрим самые интересные варианты…
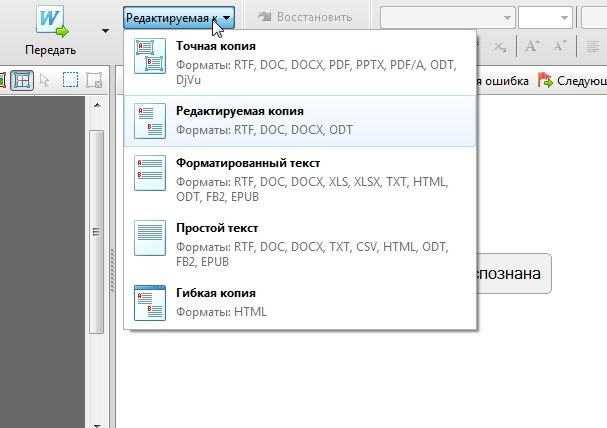
Все области, которые вы выделяли на странице в распознанном документе будут соответствовать точь в точь исходному документу. Очень удобный вариант, когда вам важно не потерять форматирование текста. Кстати, шрифты так же будут очень похожи на оригинал. Рекомендую при таком варианте передавать документ в Word, чтобы уже там продолжить дальнейшую работу.
Этот вариант хорош тем, что вы получите уже форматированный вариант текста. Т.е. отступов с «километр», которые возможно были в исходном документе — вы не встретите. Полезная опция, когда вы будете значительно редактировать информацию.
Правда, не стоит выбирать, если вам важно сохранить стилистику оформления, шрифты, отступы. Иногда, если распознавание прошло не очень успешно — ваш документ может «перекосить» из-за измененного форматирования. В этом случае целесообразно выбрать точную копию.
Вариант для тех, кому нужен просто текст со странице без всего остального. Подойдет для документов без картинок и таблиц.
На этом статья по сканированию и распознаванию документа подошла к концу. Надеюсь, что при помощи этих простых советов вы сможете решить свои задачи…


