Как проверить, не взломали ли вашу учетную запись ВКонтакте
Социальные сети и мессенджеры уже давно на прицеле у разного рода злоумышленников. Одни взламывают учетные записи и начинают рассылать спам по списку друзей. Другие действуют более аккуратно и после взлома начинают сливать к себе личную переписку, фото и видео. Так в лапы бандитов может попасть очень личная информация, которой делятся обычно с самыми близкими родственниками. Ниже вы узнаете, как проверить свою учетную запись и защитить ее от подобных атак.

Разработчики VK уже достаточно давно реализовали ряд средств защиты, но знают об их существовании далеко не все пользователи. Самый простой и достоверный способ проверки учетной записи – «История активности».
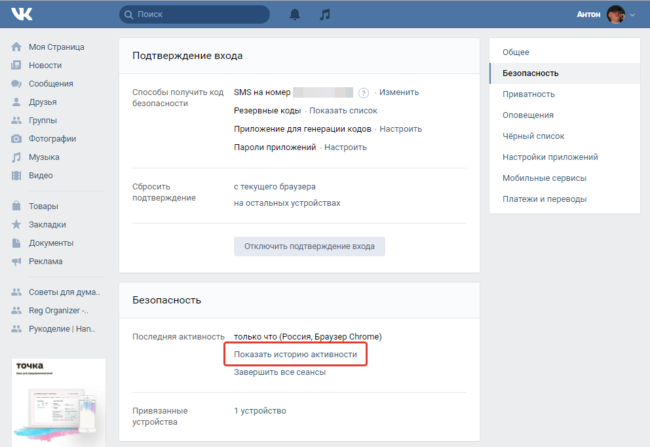
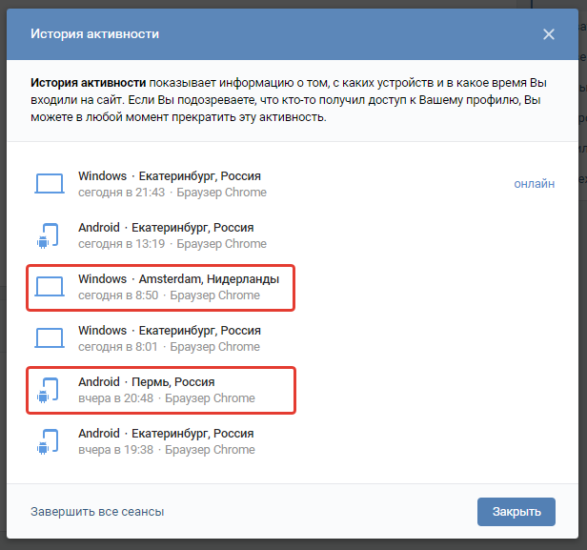
Тут вы увидите все устройства и время, когда входили в вашу учетную запись. Если вы заметите в этом списке незнакомые устройства или время и место, когда вас не было в сети – вас кто-то уже взломал и успешно сливает инфу на свой ПК или ждет для этого подходящего момента. В этом случае необходимо прервать все активные сеансы с подозрительных устройств и принять дополнительные меры по защите учетной записи.
Также злоумышленники могут привязать к учетной записи мобильное устройство и успешно следить за вами через него. Проверить это можно в списке «Привязанные устройства».
Для просмотра списка подключенных устройств потребуется ввести пароль учетной записи.
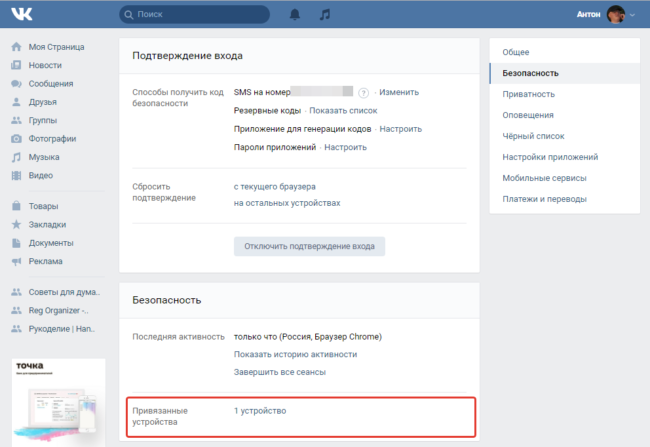
Тут вы можете увидеть список устройств и отключить ненужные.
Как защититься?
Для защиты учетной записи достаточно выполнить четыре простых шага:
1. Удаляем привязку всех неизвестных вам устройств и тех, которые более не используются вами (например, по причине продажи)
3. Активируем двухфакторную авторизацию (лучше всего использовать SMS-авторизацию, но можно и через мобильное приложение).
4. Очищаем все активные сеансы и подтверждения входа
После этого за безопасность учетной записи VK можно не беспокоиться, но не забывать о ней навсегда.
Не стоит забывать и о банальных правилах размещения информации в сети. Если вы что-то где-то публикуете, то будьте готовы к тому, что данная информация в любой момент может стать достоянием общественности даже в том случае, если она опубликована где-то в закрытых альбомах.
Как быстро проверить, взломали ли ваш аккаунт в «ВКонтакте», Gmail и Facebook
Для пользователя, который хотя бы год «провисел» в Facebook, оброс контактами в VK и привык к общению через Gmail, потеря контроля над учетной записью всегда будет трагедией. Существует множество способов обезопасить себя от взлома, сами социальные сети, к примеру, настойчиво предлагают привязку к мобильному телефону.
Наиболее простой способ проверить, использует ли кто-то еще ваш аккаунт, доступен в самих настройках безопасности веб-сервиса. Продвинутые пользователи не узнают ничего нового, но для новичков будет нелишним напомнить об этом методе.
Для «ВКонтакте»
В этой социальной сети можно зайти в настройки (меню в левом нижнем углу), выбрать, собственно, пункт меню «Настройки» и в нем — раздел «Безопасность Вашей страницы». Кликом по кнопке «Посмотреть историю активности» можно увидеть данные о последних «логинах» под вашей учетной записью, причем будут учитываться и распознаваться все залогиненные устройства.
Чтобы завершить подозрительное подключение, нужно нажать кнопку Завершить все сеансы. После этого сообщить о проблеме администрации ВКонтакте и сменить пароль.
Для Gmail
Аналогичная схема доступна и любому пользователю почтового ящика Gmail. Если прокрутить список сообщений до конца, справа внизу появится ссылка «Последние действия в аккаунте», где будут перечислены страны, браузеры и IP-адреса, с которых осуществлялся доступ к почте, а также указано время авторизации в сервисе.
Для Facebook
В этой социальной сети можно зайти в настройки (значок шестеренки в верхнем правом углу), выбрать, собственно, пункт меню «Настройки», и в нем — вкладку о безопасности. В настройках безопасности будут данные о последних «логинах» в ваш аккаунт. Будут учитываться и распознаваться все залогиненные устройства. Здесь также можно прекратить любую подозрительную активность.
Не установлен браузер для открытия ссылки на Андроид что делать?
Многие пользователи выходят в интернет с помощью своего смартфона. Популярность гаджетов сейчас очень легко объяснить – они немного весят, всегда находятся под рукой, их можно быстро достать.
Однако некоторые пользователи, получив СМС-сообщение или сообщение в мессенджере с ссылкой, могут столкнуться с выскакивающим уведомлением вроде «нет браузера для перехода по веб-ссылке». Что значит это уведомление, как пользователь может самостоятельно поставить браузер и с какими подводными камнями можно столкнуться во время установки?
Для чего нужен браузер по умолчанию
Одна из самых полезных особенностей интерфейса ОС Андроид – это интеграция ОС со всеми теми приложениями, которые установлены на телефоне. Один из примеров такой интеграции – это способность телефона не просто открывать ссылки в различных приложениях, но и способность быстро включать то приложение, посредством которого ссылки могут быть открыты.
Однако никто не застрахован от случаев, при которых любая попытка открыть ссылку приводит лишь к сообщению о том, что «этот тип ссылок не сопряжен с браузером». Обычно система может выдать запрос на запуск браузера и установку его в качестве программы, работающей и запускающей ссылки.
Как поставить мобильный браузер в качестве приложения по умолчанию
Известно, что базовым браузером в мобильной операционной системе Андроид является Google Chrome. Связано это с тем, что OS Android и Google Chrome – это продукты компании Google. Но, даже с учетом этого, функционал мобильной системы дает пользователю возможность установить другой веб-браузер для открытия ссылок.
Все, что нужно сделать пользователю – это:
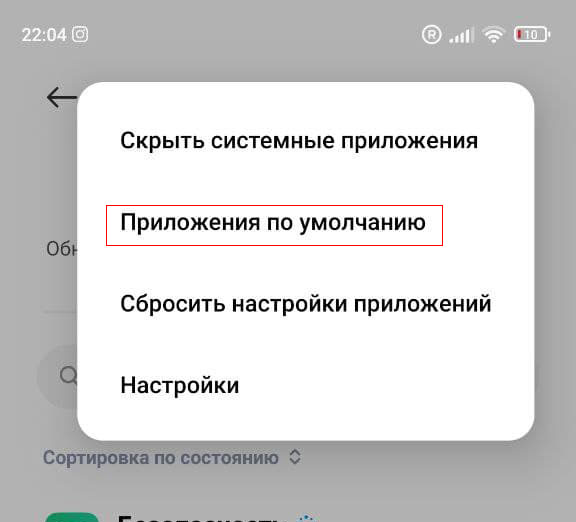
Приложения по умолчанию
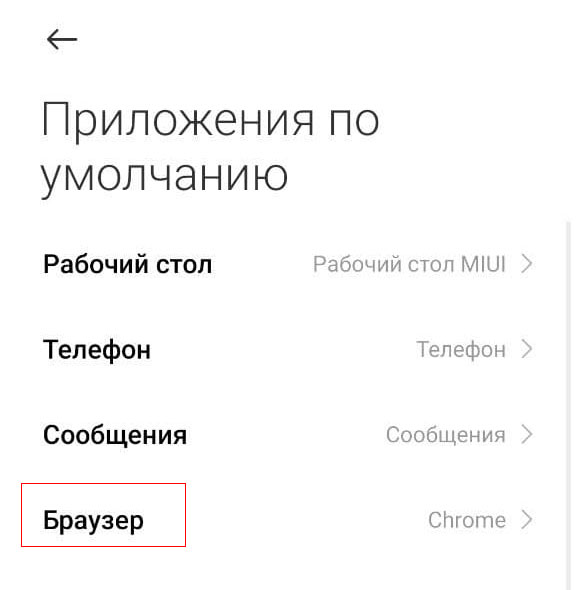

Выбираем браузер по умолчанию
Важно: если на телефоне не был установлен мобильный веб-браузер по умолчанию, с помощью которого можно было бы открывать ссылки, то система при открытии ссылок, полученных по СМС или через мессенджеры, каждый раз будет спрашивать, как и через что открыть ссылку? Однако уже на первом таком запросе пользователь может нажать на «Всегда», и тогда операционная система запомнит выбор. В таком случае при следующем открытии ссылки браузер будет открываться самостоятельно.

Также можно настроить перенаправления по внутренним ссылкам. Для этого нужно в настройках выбрать опцию, показывающую те приложения, которые настроены на открытие определенных ссылок. К примеру, ссылки, связанные с Инстаграм, открываются через одноименное приложение. Для этого в меню приложений по умолчанию ищем пункт «открытие ссылок». Название данного пункта в зависимости от бренда телефона, может немного отличаться.
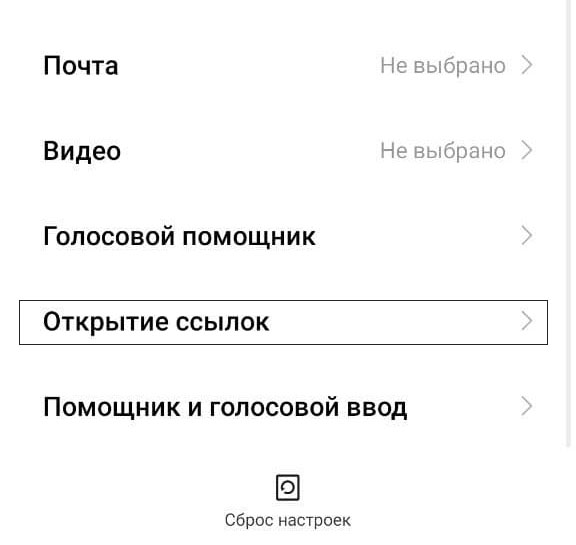
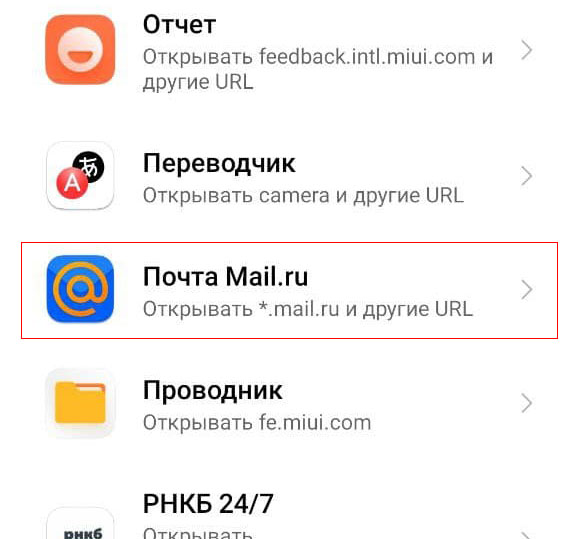
Если нужно отключить возможность открытия определенных ссылок определенным приложением, пользователь всегда может выбрать это приложение в общем списке, вызвать меню и соответствующим образом настроить опцию «Открытие поддерживаемых ссылок».
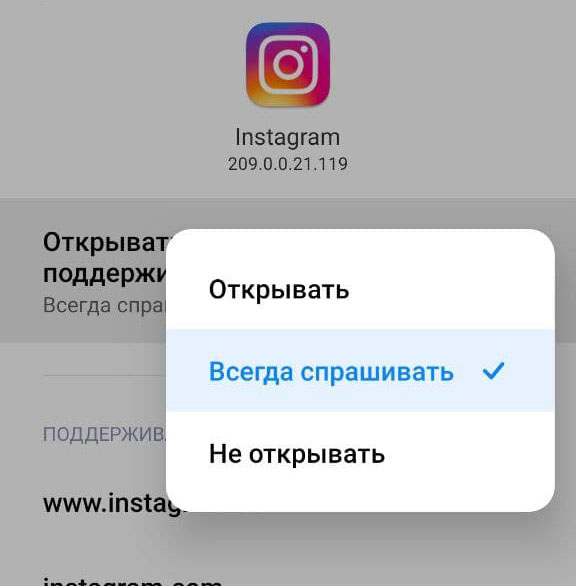
открытие поддерживаемых ссылок
Установка браузера для ссылок mail.ru
Можно настроить систему таким образом, чтобы браузер (как штатный, так и установленным самим пользователем) открывал ссылки, относящиеся к почте mail.ru. Также это поможет в том случае, если ссылки mail.ru открываются в приложении, но нужно настроить для этого браузер.
Пользователю для правильной настройки необходимо выполнить следующие действия:
Приложения по умолчанию
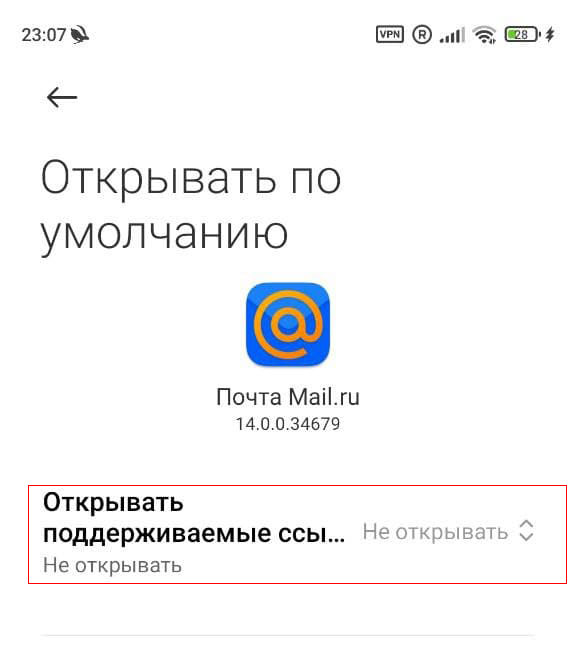
Открывать поддерживаемые ссылки
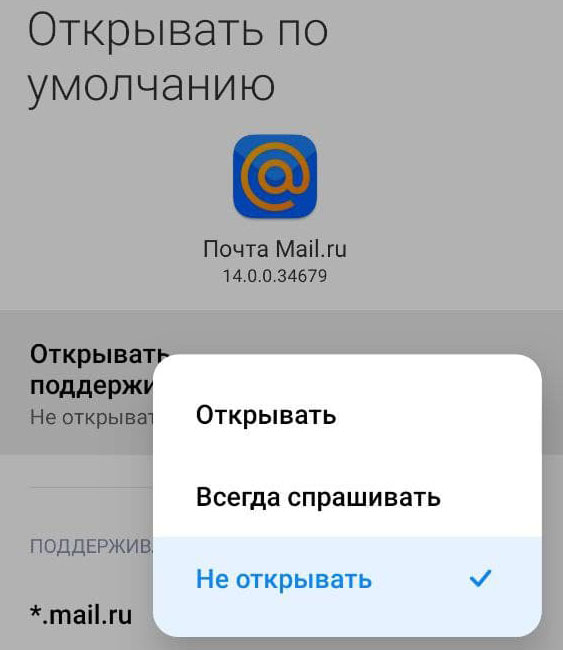
На этом все – теперь каждый раз, когда пользователь будет нажимать на ссылку, открывающую mail.ru, система попросит выбрать браузер. После этого останется лишь выбрать нужных браузер, нажать на «Всегда» и пользоваться устройством.
Важный момент: этот алгоритм работает на всех телефонах, однако при работе с продуктами Xiaomi в некоторых случаях может потребоваться приложение под названием Hidden Settings for MIUI.
Как настроить браузер по умолчанию в самом браузере
Многие мобильные версии браузеров также можно настроить так, чтобы они были браузерами по умолчанию. В зависимости от того, о каком мобильном браузере идет речь (Яндекс, Мозила, Опера), пользователю предстоит выполнить следующие действия
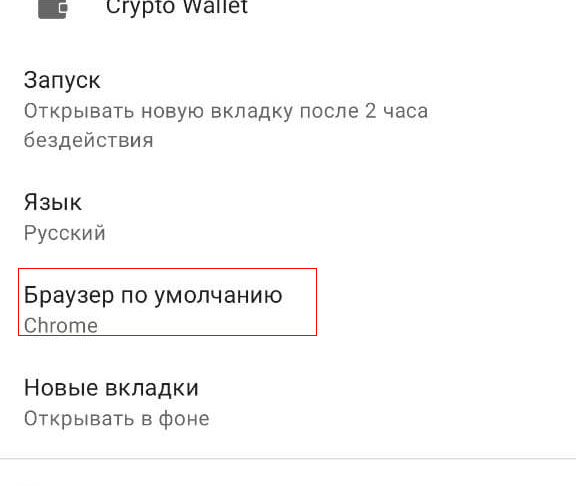
Выбор браузера по умолчанию
В целом во всех браузерах важно просто зайти в настройки и найти опцию «Браузер по умолчанию». Как показывает практика, вызов настроек и поиск опции во всех версиях браузеров примерно одинаков.
Заключение
Современные телефоны способны выполнять множество самых разных функций, однако некоторые из них (как раз вроде проблем с открытием ссылок) могут или не работать должным образом, или работать совсем не так, как хочет пользователь. К счастью, решить проблему с некорректной настройкой устройства и браузера можно в несколько движений. А если система сама спрашивает, с помощью чего открыть стороннюю ссылку в СМС-сообщении или мессенджере, всегда можно в окошке запроса поставить галочку на «запомнить выбор».
Важные аспекты работы браузера для разработчиков. Часть 1

Автор: Антон Реймер
Статья основана на вебинаре, который я проводил некоторое время назад. Рассчитана она, в первую очередь на тех, кто не знает, как работают браузеры, или тех, у кого есть пробелы в знаниях. Вероятно, здесь будет много очевидного для тех кто не первый день в веб-разработке. Статью я решил разделить на две части. В первой рассмотрим общие принципы работы браузера. Во второй части я акцентирую внимание на некоторых важных моментах: reflow и repaint, event loop.
Что такое браузер?
Браузер — программа, работающая в операционной системе. Большинство браузеров написано на языке C++. Основное предназначение браузера — воспроизводить контент с веб-ресурсов. В качестве веб-ресурса в большинстве случаев выступает html-страница. Это также может быть pdf-файл, png, jpeg, xml-файлы и другие типы. Среди огромного количества браузеров можно выделить самые популярные: Chrome, Safari, Firefox, Opera и Internet Explorer. Мы рассмотрим браузеры с открытым исходным кодом: Chrome, Firefox, Safari.
Из чего состоит и как работает браузер?
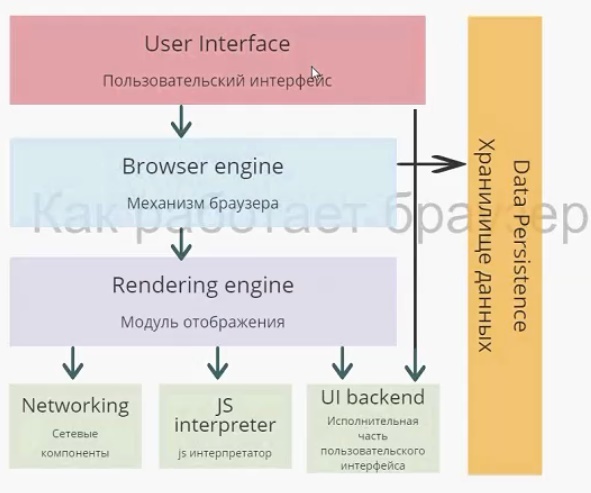
На схеме изображены модули браузера, каждый выполняет собственную функцию. Начнем с пользовательского интерфейса.
Пользовательский интерфейс — то, что видит перед собой пользователь, т. е. адресная строка, элементы навигации, собственное меню и т. д. Несмотря на то что пользовательские интерфейсы очень похожи друг на друга, никакого стандарта, который их описывал бы, не существует. Так исторически сложилось, что браузеры постепенно перенимали интерфейс друг у друга и становились все более похожими.
Механизм браузера отвечает за взаимодействие пользовательского интерфейса и модуля отображения, а также за сохранение данных в памяти.
Модуль отображения. Этот модуль — самый важный для разработчиков. Работа разработчика, в первую очередь, происходит именно с ним, а как можно понять по названию — отвечает он за отображение информации на экране.
Когда мы говорим о браузерных движках, таких как Webkit или Gecko (первый находится «под капотом» у Safari и до 2013 года был у Chrome, второй у Firefox), в первую очередь имеем в виду модуль отображения. Далее мы подробно рассмотрим модуль отображения и более детально разберем, как он работает.
Следующий модуль — сетевые компоненты. Он отвечает за запросы по сети, берет данные с внешних ресурсов и взаимодействует с модулем отображения.
Модуль JS Interpreter отвечает за интерпретацию скрипта, и его выполнение. Существует несколько JS-движков. Самые известные это V8 и JavaScriptCore. Важно не путать движок браузера и JS-движок, который работает в модуле JS Interpreter.
Следующий модуль — исполнительная часть пользовательского интерфейса (UI backend). Она отвечает за отрисовку всего на экране и работу пользовательского интерфейса.
Последний модуль — хранилище данных. Браузеру нужно где-то хранить данные, обычно для этого используется оперативная память. Какие данные нужно хранить? Например, кэш, собственные настройки. Также к хранилищу данных можно отнести indexedDB, который появился в стандарте html5 — собственные базы данных браузера.
Модуль отображения

Модуль отображения получает данные от сетевого модуля. Данные поступают пакетами по 8 Кб. Что важно — модуль отображения не ждет, пока придут все данные, он начинает обрабатывать и выводить их на экран по мере поступления. В случае с html-страницами, он начинает их анализировать, происходит парсинг html (это отдельная большая тема, я на ней останавливаться не буду). Главное, что нужно понимать: в результате парсинга у нас появляется DOM-дерево. Также по окончании парсинга срабатывает событие load, которое можно обрабатывать в скрипте. Это значит, что документ готов и скрипт может с ним работать.
DOM-дерево — document object model. По большому счету, «интерфейс», который предоставляет браузер JS-движку для работы с тем или иным html-документом. На основе DOM-дерева происходит конструирование дерева отображения (render tree). Дерево отображения — тоже важная часть модуля отображения. По большому счету, два этих дерева — DOM-дерево и дерево отображения — наиболее важные элементы для разработчика. Дерево отображения во многом повторяет структуру DOM-дерева (далее будет пример, где это будет представлено нагляднее), но имеет некоторые отличия:
Дерево отображения служит для того, чтобы браузер понимал, что выводить на экран. Оно содержит информацию о том, из каких блоков состоит страница. Дальше в тексте для простоты я буду называть составные части дерева отображения прямоугольниками, чтобы не путать с html блоками.
Дерево отображения — совокупность прямоугольников, которая должна быть выведена на экране. После того как дерево отображения сконструировано, следует этап компоновки. На этом этапе всем прямоугольникам присваиваются размеры и координаты. Каждый прямоугольник получает свои ширину и высоту, координаты в окне браузера. После компоновки происходит отрисовка дерева отображения. Пользователь видит уже конечный результат. Модуль отображения в каждом браузере устроен по-своему, но схема работы схожая.
Предлагаю рассмотреть два браузерных движка: Webkit и Gecko. 
Webkit. Модуль отображения получает html и стили. В результате парсинга html возникает DOM-дерево. В результате парсинга CSS возникает дерево правил таблиц стилей (Style Rules). Далее идет важный этап, который называется Attachment, можно перевести, как «совмещение». На этом этапе CSS-стили накладываются на DOM-дерево, в результате чего появляется Render Tree. После чего происходит компоновка дерева. Называется она здесь Layout. И в завершении происходит отрисовка (Painting).

Если посмотреть на Gecko, можно заметить, что схемы очень похожи. Главные отличия — в терминологии. Здесь тоже парсятся HTML, CSS. В результате чего создается DOM-дерево, которое здесь называется Content Model. Парсятся стили, образуется дерево стилей. Этап Attachment здесь называется Frame Constructor, но, по сути, это тоже самое. В результате совмещения образуется дерево отображения, здесь оно называется Frame Tree. Компоновка здесь называется Reflow. А отрисовка называется Painting, так же, как и в Webkit.
Пример

Здесь у нас есть теги:

Пример
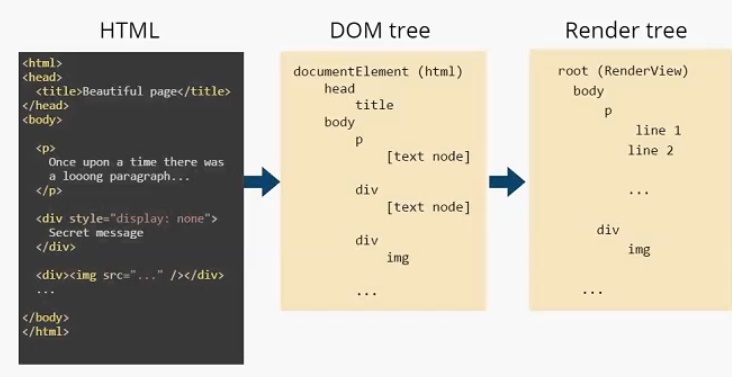
, есть только
Текст в дереве отображения разделился на две строки и представляет собой два элемента: line 1 и line2. Как я писал выше, узлы дерева отображения мы будем называть прямоугольниками. Для наглядности я так и отобразил их на иллюстрации.
Пример

Каждый прямоугольник имеет своего «родителя», кроме корневого элемента root.
Модуль отображения также занимается обработкой скриптов.
Порядок обработки скриптов и таблиц стилей
Важно понимать порядок, в котором происходит обработка скриптов. Рассмотрим следующий пример, где я попытался продемонстрировать все возможные способы подключения скриптов и стилей.
Скрипт 1. Первое, что нужно знать про скрипты, — когда при парсинге html анализатор встречает скрипт, он останавливает дальнейший парсинг документа. Т. е., как только анализатор дошел до скрипта 1, браузеру ничего неизвестно о том, что будет дальше. И пока скрипт 1 не выполнится, дальнейший анализ документа происходить не будет.
Но при этом браузер продолжает выполнять ориентировочный синтаксический анализ. Что это значит? Браузер все равно смотрит, что следует за скриптом. Если находятся ссылки на внешние ресурсы, которые нужно скачать и загрузить, он подгрузит эти данные, пока выполняется скрипт 1. Сделано это для оптимизации.
В случае с defer скрипт 4 всегда выполняется после скрипта 1. С атрибутом async неизвестно, когда он будет выполнен и какая часть документа уже будет проанализирована к этому моменту.
Стили, в отличие от скриптов, никак не могут повлиять на документ. Если скрипты могут добавить дополнительные узлы или теги, то стили этого сделать не могут. Поэтому никакой надобности для браузера блокировать дальнейший анализ документа нет.
При этом есть небольшой нюанс. Например, скрипт 1 может работать с теми или иными стилям, и может потребоваться доступ к ним. Т.е. если мы хотим поменять (или узнать) какие-то стили, но при выполнении скрипта 1 они ещё не подгружены — может случиться ошибка.
Браузеры стараются этот нюанс учесть. Firefox, например, если находит какие-то не подгруженные стили в процессе ориентировочного синтаксического анализа, блокирует выполнение скрипта, подгружает стили, после чего завершает выполнение скрипта. Chrome действует аналогичным образом, но чуть более оптимизировано. Он останавливает скрипт, только если понимает, что в этом скрипте происходит работа с не подгруженными стилями.
Компоновка окон

Окно = Прямоугольник = Узел дерева отображения
Компоновка окон — это этап компоновки дерева отображения. Я думаю многим верстальщикам знакома эта схема, она называется “Box model”. Я не буду подробно на ней останавливаться.
При компоновке окон учитываются следующее факторы:
CSS-свойство display. Два основных типа — inline и block. Другие, такие как inline-block table и прочие, появились уже позже. Отличие в том, что display:block, указывает, что ширина прямоугольника будет вычисляться в зависимости от ширины «родителя». А display:inline указывает, что ширина прямоугольника будет вычисляться в зависимости от его содержимого. Если в элементе два слова, ширина прямоугольника будет равна ширине, необходимой для вывода этих слов. Inline-элементы выстраиваются друг за другом. А блочные элементы — друг под другом.
Следующее, что влияет на компоновку элемента, — свойства position и float. Position по умолчанию static, при этом прямоугольник идет в стандартном потоке компоновки. Также есть position:relative и position:absolute. Position:relative указывает, что прямоугольнику выделяется место в стандартном потоке компоновки. При этом позиция элемента может быть сдвинута относительно этого места: влево, вправо, вверх, вниз с помощью соответствующего свойства.
Абсолютное позиционирование, к которому относится position:absolute и position:fixed, указывает, что элемент выходит за пределы своего прямоугольника из общего потока компоновки. Остальные прямоугольники его не учитывают. Он также не учитывает соседние элементы. Координаты его вычисляются относительно корневого элемента страницы, либо относительно предка, у которого position не static. Размеры же вычисляются тоже относительно родителя. Также на позиционирование влияет свойство float. Оно указывает, что наш прямоугольник идет в стандартном потоке, но при этом занимает либо крайнюю левую, либо крайнюю правую позиции. При этом все остальные прямоугольники «обтекают» этот элемент.
В заключение этой части стоит сказать что, основной поток браузера представляет собой бесконечный цикл, поддерживающий рабочие процессы. Он ожидает отправки событий, таких как reflow и repaint. Эти события ему приходят от модуля отображения. Получив их, он выполняет соответствующие действия.
В Firefox модуль отображения работает в одном потоке. Он един на весь браузер. В Chrome все немного иначе: модуль отображения и поток выполнения у каждой вкладки свои.
Важно, что сетевой модуль работает в отдельных параллельных потоках, которые не связаны с модулем отображения. Следовательно, сетевой компонент может использовать ресурсы независимо от того, что происходит в модуле отображения. Обычно у такого компонента есть возможность работать одновременно с несколькими подключениями и подгружать сразу несколько файлов. В Firefox, например, может быть шесть параллельных потоков, с помощью которых можно подгружать контент, скрипты и т. д.
В следующей части мы детально рассмотрим события reflow и repaint и попытаемся понять как грамотная работа с ними может повысить скорость работы приложения.
Browser Fingerprint – анонимная идентификация браузеров

Валентин Васильев (Machinio.com)
Что же такое Browser Fingerprint? Или идентификация браузеров. Очень простая формулировка — это присвоение идентификатора браузеру. Формулировка простая, но идея очень сложная и интересная. Для чего она используется? Для чего мы хотим присвоить браузеру идентификатор?
Почему бы для этой цели не использовать просто http cookie? Ведь это очень просто, и все это умеют делать. Работает это, вы все знаете как.
Пользователь приходит на ваш сайт, мы читаем его cookie, если там есть какой-то идентификатор, значит, он у нас уже был, и мы знаем, кто он такой. Мы выполняем всю нашу аналитику, трекинг и т.д. в привязке к этому пользователю.
Если там идентификатора нет, значит, пользователь пришел к нам впервые. Мы генерируем идентификатор уникальный, GUI, бинарную строку какую-то, записываем это в cookie, и потом, когда пользователь придет в следующий раз, мы этот cookie прочитаем и поймем, что этот пользователь к нам пришел во второй, третий и последующий разы.
У сookie есть один большой недостаток — его можно очистить. Любой, даже технически неподкованный пользователь знает, как очищать cookie. Он нажимает «Настройки», заходит и очищает. Все, пользователь становится опять для вас анонимным, вы не знаете, кто он такой.
Все современные браузеры, даже Internet Explorer, кажется, предлагают режим инкогнито. Это такой режим, когда ничего не сохраняется, и когда пользователь посетил ваш сайт в этом режиме, он не оставляет никаких следов. Следующий раз, когда он зайдет в режиме инкогнито, вы опять же не узнаете, кто он такой и был ли он у вас до этого. Т.е. в режиме инкогнито http cookie работать не будут.
В настоящее время в связи с популярностью таких персонажей как Сноуден и т.д. многие предпочитают разные режимы приватности, анонимности в Интернете, режимы, плагины и что угодно. Все это препятствует трекингу и идентификации в Интернете. Многие пользователи этим пользуются, даже не понимая, зачем. Просто устанавливают, просто потому, что это модно. И они становятся для вас опять же анонимными. Http cookie в этом случае работать не будут.
Как программисты пытались и пытаются решить эту проблему?
Наиболее успешным проектом в сфере сохранения информации в cookie так, чтобы невозможно было ее удалить, на мой взгляд, является проект evercookie, или persistent cookie — неудаляемый cookie, трудно удаляемый cookie. Суть его заключается в том, что evercookie не просто хранит информацию в одном хранилище, таком как http cookie, он использует все доступные хранилища современных браузеров. И хранит вашу информацию, например, идентификатор. Начинает он использовать http cookies, записывает идентификатор туда, затем, если в браузере доступен Flash, он использует local shared objects для записи информации в т.н. Flash cookies.
Flash cookies до недавнего времени не очищались, когда вы очищали cookie. Лишь последние версии Google Chrome умеют очищать Flash cookie, когда вы очищаете обычные cookie. Т.е. до недавнего времени Flash cookies были практически неудаляемыми. Существовала специальная страница на сайте macromedia, куда нужно было зайти, нажать кнопку: «Да, я хочу очистить Flash cookies», и тогда они очищаются, т.е. без этой страницы было очистить невозможно.
Далее, evercookie использует Silverlight Cookies. По-другому они называются Isolated Storage. Это специальное выделенное место на жестком диске компьютера пользователя, куда пишется cookie информация. Найти это место невозможно, если вы не знаете точный путь. Оно прячется где-то в документах, Setting’ах, если на Windows, глубоко в недрах компьютера. И эти данные удалить, при помощи очистки cookie невозможно.
Далее. Evercookie использует такую инновационную технику как PNG Cookies. Суть заключается в том, что браузер отдает картинку, в которой в байты этой картинки закодирована информация, которую вы сохранили, например, идентификатор. Эта картинка отдается с директивой кэширования навсегда, допустим, на следующие 50 лет. Браузер кэширует эту картинку, а затем при последующем посещении пользователем при помощи Canvas API считываются байты из этой картинки, и восстанавливается та информация, которую вы хотели сохранить в cookie. Т.о. даже если пользователь очистил cookie, эта картинка с закодированным cookie в PNG по-прежнему будет находиться в кэше браузера, и Canvas API сможет ее считать при последующем посещении.
Evercookie использует все доступные хранилища браузера — современный HTML 5 стандарт, Session Storage, Local Storage, Indexed DB и другие.
Также используется ETag header — это http заголовок, очень короткий, но в нем можно закодировать какую-то информацию, и если установлен Java, то используется java presistence API.
Evercookie — очень умный плагин, который может сохранять ваши данные практически везде. Для обычного пользователя, который не знает всего этого, удалить эти cookies просто невозможно. Нужно посетить 6-8 мест на жестком диске, проделать ряд манипуляций для того, чтобы только их очистить. Поэтому обычный пользователь, когда посещает сайт, который использует evercookie, наверняка не будет анонимным.
Несмотря на все это, evercookie не работает в инкогнито режиме. Как только вы зашли в инкогнито режим, никакие данные не сохраняются на диске, потому что это основополагающая суть инкогнито режима — вы должны быть анонимными. А еvercookie использует хранение на жестком диске, которое в этом режиме не работает.
FingerprintJS — это маленькая библиотечка, которую я написал, и которая пытается решить эти проблемы. Я расскажу, как она это делает, и что из этого получилось.
Написал я ее в 2012 году. Я тогда работал в «КупиКупон» Ruby разработчиком. И у меня была задача сделать такую систему аналитики, чтобы учитывать не просто залогиненных пользователей, т.е. тех пользователей, которые есть у нас в системе, а также анонимных пользователей. Конкретно на сайте «КупиКупон» было много анонимных пользователей, потому что люди часто приходили извне посмотреть на какие-то купоны, скидки, предложения, у них ни у кого не было учетной записи, и поэтому система трекинга, система отслеживания посещаемых страниц, нажатия на кнопки — все это не работало, потому что пользователи были анонимными.
FingerprintJS, вообще, не использует cookie. Никакая информация не сохраняется на жестком диске компьютера, где установлен браузер. Работает в инкогнито режиме, потому что в принципе не использует хранение на жестком диске. Не имеет зависимостей, работает даже без jQuery, и размер — 1,2 Кб gzipped.
На данный момент используется в таких компаниях как Baidu, это Google в Китае, MasterCard, сайт президента США, AddThis — сайт размещениz виджетов и т.д.
Эта библиотека быстро стала очень популярной. Она используется примерно на 6-7% всех самых посещаемых сайтов в Интернете на данный момент.
Как она работает, расскажу детально. Суть ее в том, что код этой библиотеки опрашивает браузер пользователя на предмет всех специфичных и уникальных настроек и данных для этого браузера и для этой системы, для компьютера. Эти данные объединяются в огромную строку, затем они подаются на вход функции хэширования. Функция хэширования берет эти данные и превращает их в компактные красивые идентификаторы. Как детально это работает, я расскажу.
Сначала считывается userAgent navigator. Допустим, тут он обрезан, это присоединяется к итоговой строке отпечатка.
Считывается язык браузера — какой у вас язык — английский, русский, португальский и т.д. Тоже присоединяется к строке отпечатка.
Считывается часовой пояс, это количество минут от UTC:
Это –3, получается Москва.
Далее получается размер экрана, массив, глубина цвета экрана.
Затем происходит получение всех поддерживаемых HTML5 технологий, т.е. у каждого браузера поддержка отличается. FingerprintJS пытается определить, какие поддерживаются, какие — нет, и для каждой технологии результат опроса наличия этой технологии и степень ее поддержки прибавляется к итоговой функции отпечатка.
SessionStorage, LocalStorage, IndexedDB, OpenDatabase и другие всевозможные.
Опрашиваются данные, специфичные для пользователя и для платформы, такие как настройка doNotTrack (очень иронично, что настройка doNotTrack используется как раз для трекинга), cpuClass процессора, platform и другие данные.
Здесь у вас может возникнуть закономерный вопрос — ведь у очень многих пользователей эти данные они одинаковые? Допустим, пользователь живет в Москве, у него будет одинаковый язык, последний Chrome, у него будет все практически одинаково, и все эти строки, которые были получены на данном этапе, будут одинаковые. Как это поможет идентифицировать пользователя?
Есть еще 2 способа, которые добавляют уникальности.
Тут показано, как это работает. Мы получаем все эти данные. Потом мы передаем их в функцию хэширования, в FingerprintJS используется nomo hash2, и на выходе мы получаем 32-х битное число. Это и есть ваш идентификатор. Т.о., когда пользователь заходит на наш сайт, ему присваивается номер. Этот номер вы считываете и используете, как хотите, — вы базируете на нем свою аналитику и т.д.
Тут вопрос: насколько уникально и точно определение? Исследование, за основу которого было взято, было сделано компанией Electronic Frontier Foundation, у них был проект Panopticlick. Оно говорит, что уникальность составляет порядка 94%, но на реальных данных, которые были у меня, уникальность составляла около 90%-91%.
Библиотеку стало использовать много людей и компаний, и с течением времени выявился ряд недостатков. Т.е. она неидеальна, у нее есть недостатки. Самый главный недостаток — то, что точность идентификации только 90%, но есть и другие недостатки.
Я ее начал делать совсем недавно, разработка ведется на github.
Как она решает существующие проблемы? Самое главное — используется фазихэширование или localsensitivehash, или нечеткое хэширование. Такое хэширование, которое не меняется, даже если в обычном хэшировании, если вы измените хотя бы один байт входящей информации, выходящая строка тоже изменится, причем кардинальным образом. В фазихэшировании этого не происходит, тут есть порог чувствительности, когда определенный процент входящих данных может измениться, что не повлияет на исходящий отпечаток. Допустим, если поменялась в UserAgent только версия браузера, это случается очень часто, допустим, в Chrome, то результирующий отпечаток будет одинаковым, потому что версия составляет 3 или 5 % от общей длины от UserAgent.
Второе — в FingerprintJS 2 используется определение установленных шрифтов, всех шрифтов, которые установлены в системе. Чем это полезно? Если вы поставили программу, допустим, adobe pdf, то вы добавляете в систему шрифты.
Если вы поставили Microsoft Office, вы добавляете в систему шрифты; если вы поставили какой-нибудь Quick office, который имеет собственные шрифты, вы опять же добавляете в систему шрифты. И поэтому у вас может быть два абсолютно одинаковых компьютера, но на одном установлен Office, а на другом — нет. Это значит, что на первом, где нет Office, будет 320 доступных шрифтов, а, где есть Office — 1700 шрифтов. И значит, что вы сможете получить все шрифты, которые есть на этом компьютере, опять же, для итогового отпечатка. Это будет два разных отпечатка, потому что шрифты разные.
По умолчанию используется Flash, маленький swf файл размером 916 байт. Он получает список всех установленных шрифтов, причем в платформозависимом порядке, т.к. они доступны в системе, так они и будут возвращены. Если Flash не установлен, используется такая техника, она называется site chanel technic. Она впервые была опубликована на сайте lalit.org. Это определение наличия шрифта с помощью javascript only. Как это делается? Для каждого референтного шрифта, который задан по умолчанию в браузере или в системе, измеряется его ширина и высота, и этот массив ширины и высоты сохраняется. Затем к скрытому тексту (текст, кстати, огромный, допустим, 72 пикселя) применяется другой шрифт. Если этот шрифт есть в системе, текст изменит свои габариты правильно, и код, который изменяет высоту и ширину, получит новый массив, с высотой и шириной. Если он отличается от референтного, от того, который был получен при запросе дефолтного шрифта, значит, этот шрифт установлен. Если не отличается, значит, этого шрифта нет.
Очень простая идея, но она работает. На данный момент этот код может достоверно определить около 500 шрифтов без использования Flash. И, соответственно, тот компьютер, где есть Microsoft Office, и тот, где его нет, будут по-разному определены в FingerprintJS 2 за счет этой техники.
Третье отличие — WebGL Fingerprint. Это развитие идеи Сanvas Fingerprint. Суть его заключается в том, что рисуются 3D треугольники (на слайде не очень хорошо видно, но это 3D). На него накладываются эффекты, градиент, разная анизотропная фильтрация и т.д. И затем он преобразуется в байтовый массив. Результирующий байтовый массив, как и в случае с Canvas Fingerprint, будет разный на многих компьютерах. Потом к этому байтовому массиву еще добавляется информация о платформозависимых константах, которые определены в WebGL. Т.е. в WebGL есть набор констант, которые должны быть обязательно в реализации. Это глубина цвета, максимальный размер текстур… Этих констант очень много, их десятки. Код опрашивает все эти константы и, понятное дело, что на android-девайсах эти константы будут отличаться, там глубина цвета может быть другой, чем на Windows или чем на linux’е. Он опрашивает все эти константы, все это опять же складывается в огромный массив, и все это добавляется к сериализованному изображению 3D треугольника, который нарисован при помощи аппаратных эффектов.
Тут тоже такой вопрос: как это помогает идентифцировать? 3D графика очень платформозависима, версия драйверов, версия видеокарты, стандарт OpenGL в системе, версия шейдерного языка, — все это будет влиять на то, как внутри будет нарисовано это изображение. И когда оно будет преобразовано в байтовый массив, оно будет разное на многих компьютерах.
Почему WebGl Fingerprint важен? Потому что IOS 8.1 поддерживает WebGL, а это помогает идентифицировать IOS девайсы, о проблеме идентификации которых я упоминал. Поэтому WebGL повышает точность Fingerprint.
Что еще предстоит реализовать?
Как я говорил, библиотека находится в разработке и не все вещи, которые я бы хотел в ней сделать, сделаны. Вокруг нее уже есть небольшое сообщество разработчиков. Я, кстати, приглашаю всех желающих участвовать в разработке — она очень интересная, мы очень неформальны, каждый предлагает идеи, там достаточно интересно.
Что предстоит еще реализовать? WebRTC Fingerprinting.
WebRTC — это стандарт peer-to-peer коммуникаций через аудиопотоки, или это стандарт аудиокоммуникаций в современных браузерах. Он позволяет делать аудиозвонки и т.д., он поддерживается в FireFox и будет скоро поддерживаться в других браузерах.
Реализация WebRTC стандарта тоже платформозависима, она будет зависеть от той видеокарты, которая установлена в системе, от драйверов на звук и т.д. Поэтому, измеряя разные уровни латентности, разные уровни поддержки WebRTC и констант, которые зашиты в этом формате, можно получить разные итоговые отпечатки для разных компьютеров.
Будет использоваться больше плагинов для IE. Будут использованы те плагины, которые популярны в разных странах — Китае, Индии и т.д., т.е. растущие информационные рынки. В первой версии недостаточно внимания было уделено этой проблеме, а во второй версии это будет решено.
Больше информации будет собираться об ОС. Как мы это будем делать? Будет использоваться интеграция с Flash и Silverlight. Flash позволяет получать информацию о системе, такую как версия ядра, патч левел ядра. Silverlight, если на Windows, позволяет получить версию Windows, bild, номер Windows, все это доступно через Silverlight.
Пару слов о Silverlight, почему интеграция с sliverlight тоже достаточно важна? Может быть, в России Silverlight плагин не очень популярен, но в США, например, есть сервис стримингового видео Netflix, который транслирует видео, и я знаю точно, что они используют Silverlight. Ввиду того, что он поддерживает DRM (это система ограничения цифровых прав на контент), т.к. Netflix часто показывают разные свежие голливудские фильмы, они используют Silverlight для того, чтобы это видео не расходилось по Интернету. Поэтому в США у многих десктопных пользователей Интернета установлен Silverlight плагин, который, кстати, доступен и на Mac’е тоже, помимо Windows.
Будет реализовано определение наличия нескольких мониторов. Если мы запросим размеры через javascript, то получим просто два числа — это ширина и высота экрана. Если мы сделаем то же самое через Flash API, Actionscript API, мы получим массив массивов. Это значит, что если установлено несколько мониторов, где каждый подмассив — это будет размер экрана каждого монитора. Если разработчик сидит за пятью мониторами, он получит массив массивов из пяти элементов, т. о., мы узнаем, что человек сидит за пятью мониторами, а не за основным монитором, который вернул бы javascript.
Все эти данные в совокупности позволяют на данный момент получить точность определения порядка 94-95%. Но, как вы понимаете, это недостаточная точность идентификации. Тут встает вопрос: каким образом это можно улучшить, и можно ли это улучшить? Я считаю, что можно. Цель этого проекта — достичь 100% идентификации так, чтобы можно было опираться на Fingerprint в 100% случаях и гарантированно сказать: «Да, этот пользователь к нам приходил; да, я все о нем знаю, несмотря на то, что он использует инкогнито mode, tor сеть…». Не важно, все это будет определено.
Контакты
Этот доклад — расшифровка одного из лучших выступлений на конференции фронтенд-разработчиков FrontendConf.
Ну и главная новость — мы начали подготовку весеннего фестиваля «Российские интернет-технологии», в который входит восемь конференций, включая FrontendConf.


