filecheck .ru
Вот так, вы сможете исправить ошибки, связанные с ScheduleAgent.exe
Информация о файле ScheduleAgent.exe
Важно: Некоторые вредоносные программы маскируют себя как ScheduleAgent.exe, особенно, если они расположены в каталоге c:\windows или c:\windows\system32. Таким образом, вы должны проверить файл ScheduleAgent.exe на вашем ПК, чтобы убедиться, что это угроза. Мы рекомендуем Security Task Manager для проверки безопасности вашего компьютера.
Комментарий пользователя
Лучшие практики для исправления проблем с ScheduleAgent
Если у вас актуальные проблемы, попробуйте вспомнить, что вы делали в последнее время, или последнюю программу, которую вы устанавливали перед тем, как появилась впервые проблема. Используйте команду resmon, чтобы определить процесс, который вызывает проблемы. Даже если у вас серьезные проблемы с компьютером, прежде чем переустанавливать Windows, лучше попробуйте восстановить целостность установки ОС или для Windows 8 и более поздних версий Windows выполнить команду DISM.exe /Online /Cleanup-image /Restorehealth. Это позволит восстановить операционную систему без потери данных.
ScheduleAgent сканер

Security Task Manager показывает все запущенные сервисы Windows, включая внедренные скрытые приложения (например, мониторинг клавиатуры или браузера, авто вход). Уникальный рейтинг надежности указывает на вероятность того, что процесс потенциально может быть вредоносной программой-шпионом, кейлоггером или трояном.
Бесплатный aнтивирус находит и удаляет неактивные программы-шпионы, рекламу, трояны, кейлоггеры, вредоносные и следящие программы с вашего жесткого диска. Идеальное дополнение к Security Task Manager.
Reimage бесплатное сканирование, очистка, восстановление и оптимизация вашей системы.
Scheduling: мифы и реальность. Опыт Яндекса
В последние пару лет я занимаюсь построением различных планировщиков, и мне пришло в голову поделиться своим нелёгким опытом с коллегами. Речь идёт о двух категориях коллег. Первые — это желающие узнать, как разработать свой scheduler за 21 день. Вторые — те, кому нужен новый scheduler совсем без смс и регистрации, просто чтобы работал. Особенно хотелось бы помочь второй категории людей.

Сначала, как водится, стоит сказать несколько общих слов. Что такое scheduler (планировщик, или, для простоты, «шедулер»)? Это такая компонента системы, которая занимается распределением ресурса или ресурсов системы по потребителям. Разделение ресурса может происходить в двух измерениях: в пространстве и времени. Планировщики чаще всего фокусируются на втором измерении. Обычно под ресурсом подразумевают процессор, диск, память и сеть. Но, что греха таить, шедулить можно и любую виртуальную ерунду. Конец общих слов.
Вместе со словом «планировщик» часто мелькают другие слова, вызывающие куда больший интерес публики: изоляция, честность, гарантии, задержки, дедлайны. Встречаются и некоторые словосочетания: quality of service (QoS), real time, temporal protection. Люди, как показывает практика, часто ждут от планировщиков магических сочетаний свойств, которые не могут быть достигнуты одновременно — с шедулером или без него. Если же нужные свойства достигаются, то обычно планировщики всё равно остаются непредсказуемой вещью в себе и во время их эксплуатации список вопросов только увеличивается. Я попытаюсь приоткрыть завесу тайны их поведения. Но обо всем по порядку.
Миф №1. Что тут сложного?
Чтобы объяснить и предсказать поведение систем, где есть шедулер, люди написали очень много книг, а также разработали целую теорию — и даже не одну. Как минимум стоит упомянуть scheduling theory (теорию расписаний) и queueing theory (неожиданно: в русском варианте это теория массового обслуживания). Все подобные теории довольно сложные и, если честно, просто необозримые. Одних формулировок задач планирования существует целый зоопарк со специальной классификацией. Дело не облегчается тем, что про бóльшую часть задач известно, что они NP-полные или NP-трудные. Даже в удачных случаях, когда есть полиномиальный алгоритм поиска оптимального решения или его неплохое приближение, частенько выясняется: для онлайн-версии задачи (когда заранее неизвестно, какие запросы нужно шедулить или когда они появятся) оптимального алгоритма вообще не существует и надо быть оракулом, чтобы отшедулить всё «как надо». Тем не менее, дела обстоят не так плохо, как может показаться. Человечество уже очень много знает о шедулерах, а некоторые из них даже работают.
Миф №2. Шедулеры решают все проблемы
Отличная иллюстрация непредсказуемого поведения системы с шедулером — сегодняшний интернет. Это система с множеством шедулеров и абсолютным отсутствием гарантий по полосе и задержке, отсутствием изоляции и подобием справедливости в формате протокола TCP — который, кстати, даже сейчас, спустя десятилетия, изучают и улучшают, и такие улучшения могут давать значимые результаты.

Вспомним TCP BBR от Google. Авторы неожиданно говорят, что создать TCP BBR было невозможно без последних достижений в теории управления, основа которых — нестандартная max-plus-алгебра. Вот, оказывается, куда ушло 30 с лишним лет.
Но это же всё не про шедулер, скажете вы, а про flow control. И будете абсолютно правы. Дело в том, что они очень сильно связаны. В обычных системах шедулеры ставят перед некоторым узким местом — ограниченным ресурсом. Логично: ресурс в дефиците и вроде бы его надо делить справедливо. Допустим, у вас есть такой ресурс — дорожная сеть города — и вы хотите сделать для него шедулер (условно, на выезде из гаража), чтобы уменьшить среднее время в пути. Так вот, оказывается, что среднее время в пути легко вычислить, применив теорему Литтла: оно равно отношению количества машин в системе к скорости их поступления в систему. Если уменьшить делимое, то при прежней пропускной способности время в пути падает. Получается, чтобы не было пробок, надо попросту сделать так, чтобы машин на дорогах стало меньше (ваш капитан). Шедулер с такой задачей не поможет, если нет flow control. В интернете описанную проблему называют bufferbloat.
Если бы я писал свод правил «шедулеростроения», то первое правило было бы таким: контролируй очереди, возникающие за шедулером. Самый часто встречающийся мне способ контролировать размер очереди — MaxInFlight (его продвинутая версия называется MaxInFlightBytes). С ним есть проблема: дело в том, что невозможно правильно выбрать число. Выбор любого фиксированного числа будет гарантировать вам либо неполное использование полосы (1), либо излишнюю буферизацию (2) и, как следствие, увеличение среднего latency, либо, если вам очень повезёт, таймауты и потерю полосы.
Хороший flow control должен удерживать систему в точке Кляйнрока между режимами (1) и (2), максимизируя отношение throughput/latency (см. TCP BBR).
Миф №3. Справедливость нужна для изоляции
Есть две классические области применения справедливого планирования — сеть и процессор. GPS — не система позиционирования, а идеальный шедулер, одновременно обслуживающий всех своих пользователей бесконечно малыми порциями. Такой шедулер обеспечивает справедливость max-min. Настоящие шедулеры (WFQ, DRR, SFQ, SCFQ, WF2Q) обслуживают потребителей порциями конечного размера — пакетами, если мы говорим про сеть, или квантами времени, если про процессор. Эти шедулеры разрабатывают так, чтобы их поведение было максимально приближено к идеальному и чтобы они минимизировали лаг — разницу в объёме обслуживания, полученного разными пользователями. Затем для управления выделенной полосой разработчик вводит веса пользователей и начинает говорить, будто они находятся в изолированных системах с меньшей пропускной способностью. Здесь-то и кроется обман. На самом деле изоляции нет.
Пусть у нас есть процессор, который мы хотим потенциально разделять между ста пользователями. Допустим, Витя — хороший пользователь. Он отправляет на обслуживание задачи, которые выполняются за 10 мс, и готов подождать 1 с, потому что понимает: есть еще 99 пользователей. Однако другие могут отправлять задачи, которые иногда выполняются до 1 с. Предположим, что preemption невозможен. Тогда Вите в худшем случае придётся ждать 99 с. Витя, скорее всего, захочет выйти из подобной системы.
Так неинтересно, скажете вы. Что за система такая — без preemption? Система должна уметь обижать, и будет ей счастье. Хорошо, пусть при времени выполнения запроса более 10 мс мы будем включать preemption, передавать управление следующему запросу и вообще использовать лучший из известных науке справедливых шедулеров. Увидит ли Витя ответ за 1 с, как будто он в изоляции? 10 мс (текущий запрос в обслуживании) + 99*10 мс (запросы других пользователей) + 10 мс (Витин запрос) = 1010 мс. Это максимум времени ожидания — другими словами, в такой системе дела обстоят получше.
Витя говорит — отличная система! — и отправляет запрос на 1 мс. А он опять выполняется за 1 с (в худшем случае). В идеально изолированной системе такой запрос выполнился бы за 100 мс, а здесь получилось в 10 раз хуже. Мало того, что от этой секунды никуда ни деться, так ещё и в реальной системе обязательно встретятся другие проблемы:
Миф №4. Справедливость нужна, чтобы разделить полосу в соответствии с весом
Получается, справедливость не обеспечивает настоящую изоляцию, зато хорошо делит полосу. Но не тут-то было. Справедливость в таких классических шедулерах мгновенная. Это означает, что, не прислав запрос, когда придёт ваша очередь, вы не получите ресурс, и он будет разделён между остальными желающими. По прошествии длительного промежутка времени (например, 24 часов) может оказаться, что ресурс съелся совсем не в той пропорции, в которой веса были заданы потребителям. В худшем случае потребители могут приходить в любых пропорциях только в те моменты, когда нет других потребителей. В результате веса и потреблённый ресурс могут оказаться вообще никак не связаны. Это шутка, скажете вы, — так никогда не бывает. Но пусть у нас есть распределённая система со своим шедулером на каждой машине. Запросы двух пользователей приходят на две разные машины и никогда не конкурируют за ресурс, потому что на самом деле здесь два ресурса.
Если вы хотите увидеть на графиках ровные линии для агрегированного потока, стоит использовать историческую (long-term) справедливость или квотирование. Но вначале спросите себя, зачем вам это надо.
Миф №5. Выдели мне узенький канал для приоритетного трафика
Предположим, у вас есть справедливый шедулер с весами и вы хотите выделить 0,1% полосы для какого-нибудь служебного трафика, а оставшиеся 99,9% — для остального. В итоге вы получите максимальную задержку x1000. Такой феномен называется bandwidth-latency coupling. Он является прямым следствием из предыдущего рассуждения. Максимальное время задержки обратно пропорционально ширине выделенной полосы. Значит, для приоритетного трафика нужны другие механизмы.
Миф №6. Я загрузил систему на полную и начал мерить задержку
Теорема. В любой системе, загруженной больше чем на 100%, задержка ответов не ограничена сверху никаким числом. Доказательство, я надеюсь, очевидно. Очереди будут копиться, пока что-то не лопнет. Как неправильно измерять и сравнивать временны́е характеристики систем (в том числе с шедулером), рассказывает Гил Тене (можно посмотреть или почитать). Я оставлю тут только иллюстрацию:
Миф №7. Real-time scheduler может гарантировать выполнение моих дедлайнов
Если вам больше не нужен справедливый шедулер, вам, возможно, нужен шедулер, который используется в системах реального времени. Уж там-то всё наверняка хорошо и быстро. Помимо прочего, корректность работы системы реального времени зависит от выполнения задач в заданные сроки. Однако это вовсе не значит, что всё происходит быстро. Например, сроки и задачи бывают вида «сделать и внедрить новый шедулер до начала весеннего ревью». Более того — среднее время ответа в таких системах может быть очень близким к худшему случаю.
Отличительная черта RT-систем: они заранее проверяют расписание на осуществимость. «Осуществимость» здесь означает возможность соблюдения дедлайнов всех задач, а «заранее» — это, скажем, при сборке, при конфигурации системы или при запуске в ней новой задачи. Далее, есть простой способ соблюдать все дедлайны в системе, где это принципиально возможно. Речь идёт про real-time-шедулер. Например, доказано, что алгоритмы EDF (Earliest Deadline First) являются оптимальными для одного процессора. Оптимальность означает, что если для данного набора задач существует хоть какое-то выполнимое расписание, то EDF выполнит задачи до дедлайнов.
Но есть условия, при которых стройная картина мира рушится и система перестаёт укладываться в дедлайны.
Миф №8. Систему нельзя загрузить больше чем на 100%
Для определения загрузки (load factor) в RT-системах используется простая периодическая модель следующего вида. Есть задачи, которые поступают раз в Ti мс и требуют эксклюзивного владения ресурсом в течение Ci мс в худшем случае. Тогда load factor определяется как запрошеное время ресурса на одну секунду реального времени, то есть U = C1/T1 +… + Cn/Tn. В такой простой модели всё понятно, но как подсчитать load factor, если у нас нет никаких периодов, а есть только текущие задачи и их дедлайны?
Тогда load factor определяется иначе. Текущие задачи сортируются по дедлайнам. Далее, начав с одного запроса с наименьшим дедлайном во множестве M, проходим по всем запросам и добавляем их в это множество. М на каждом шаге содержит запросы, которые должны быть полностью выполнены к определённому моменту времени t. Делим их суммарную остаточную стоимость (если вдруг мы уже частично выполнили какие-то из них) на оставшееся время t – now. Полученная величина — load factor U множества M. Чтобы получить текущий load factor, остаётся найти максимум из всех полученных U. Найденная величина, как несложно догадаться, сильно меняется во времени и легко может оказаться больше 1. Расписание невыполнимо c помощью EDF тогда и только тогда, когда load factor > 1.
Если вам важно соблюдать дедлайны, то в качестве метрики, за которой стоит следить, нужно использовать описанный load factor, а не традиционную утилизацию (долю времени, когда система находилась в занятом состоянии).
Что умеет планировщик заданий в Postgres Pro
Планировщик заданий (scheduler) не во все времена считался обязательным инструментом в мире баз данных. Все зависело от назначения и происхождения СУБД. Классические коммерческие СУБД (Oracle, DB2, MS SQL) представить себе без планировщика решительно невозможно. С другой стороны, трудно вообразить потенциального пользователя MongoDB, который откажется от выбора этой модной NoSQL-СУБД из-за отсутствия планировщика. (Кстати, термин «планировщик заданий» в русском контексте СУБД употребляют, чтобы отличить его от планировщика запросов — query planner, мы же для краткости будем звать его здесь планировщиком).
PostgreSQL, будучи Open Source и впитав традиции сообщества с образом жизни DIY («сделай сам»), в наше время регулярно претендует на место как минимум заместителя коммерческой СУБД. Из этого автоматически следует, что PostgreSQL просто обязана иметь планировщик, и что этот планировщик должен быть удобен для администратора базы и для пользователя. И что желательно воспроизвести полностью функциональные возможности коммерческих СУБД, хотя неплохо было бы и добавить что-то свое.
Необходимость в планировщике очевиднее всего проявляется при работе с базой в промышленной эксплуатации. Разработчику, которому выделили сервер для экспериментов с БД, планировщик, в общем-то и ни к чему: если нужно, он сам, средствами ОС (cron или at в Unix) распланирует все необходимые операции. Но к рабочей базе его в серьезной фирме не подпустят на пушечный выстрел. Есть и важный административный нюанс, то есть уже не нюанс, а серьезная, если не решающая причина: администратор базы данных и сисадмин не просто разные люди с разными задачами. Не исключено, что они принадлежат к разным подразделениям компании, и, может быть, даже сидят на разных этажах. В идеале администратор базы поддерживает ее жизнеспособность и следит за ее эволюцией, а зона ответственности сисадмина — жизнеспособность ОС и сети.
Следовательно, у администратора базы должен быть инструмент для выполнения необходимого набора возможных работ на сервере. Недаром в материалах о планировщике Oracle сказано, что «Oracle Scheduler отменяет необходимость использовать специфичные для разных платформ планировщики заданий ОС (cron, at) при построении БД-центричного приложения». То есть админ базы может всё, тем более, что трудно себе представить админа Oracle, не ориентирующегося в механизмах ОС. Ему не надо каждый раз бежать к сисадмину или писать ему письма, когда требуются рутинные операции средствами ОС.
Вот требования к планировщику, типичные для коммерческих СУБД, таких как Oracle, DB2, MS SQL:
Планировщик должен уметь
PostgreSQL и его агент
Решать поставленные задачи можно по-разному: «вне» и «внутри» самой СУБД. Самая серьезная попытка сделать полнофункциональный планировщик — это pgAgent, распространяемый вместе с pgAdmin III/IV. В коммерческом варианте — в дистрибутиве EnterpriseDB — он интегрирован в графический интерфейс pgAdmin и может использоваться кроссплатформенно.
У такого подхода есть недостатки. Среди них важные:
Все задания, запущенные pgAgent, будут исполняться с правами пользователя, запустившего агента. SQL-запросы будут исполняться с правами пользователя, соединившегося с базой. Скрипты shell будут исполняться с правами пользователя, от имени которого запущен демон (или сервис в Windows) pgAgent. Поэтому для безопасности придется контролировать пользователей, которые могут создавать и запускать задания. Кроме того, пароль нельзя включать в строку конфигурации соединения (connection string), так как в Unix он будет виден в выводе команды ps и в скрипте старта БД, а в Windows будет хранится в реестре как незашифрованный текст.
(из документации pgAdmin 4 1.6).
В этом решении pgAgent через заданные промежутки времени опрашивает сервер базы (поскольку информация о работах хранится в таблицах базы): нет ли в наличии работ. Поэтому, если по каким-то причинам агент не будет работать в момент, когда работа должна запуститься, она не запустится до тех пор, пока агент не заработает.
К тому же любое подключение к серверу расходует пул возможных соединений, максимальное количество которых определяется конфигурационным параметром max_connections. Если агент порождает много процессов, а администратор не проявил должную бдительность, это может стать проблемой.
Создание планировщика целиком интегрированного в СУБД («внутри» СУБД) избавляет от этих проблем. И особенно удобно это тем пользователям, которые привыкли к минималистским интерфейсам для обращения к базе, таким как psql.
pgpro_scheduler и его расписание
В конце 2016 года в компании Postgres Professional приступили к созданию собственного планировщика, полностью интегрированного в СУБД. Сейчас он используется заказчиками и подробно документирован. Планировщик был создан как расширение (дополнительный модуль), получил название pgpro_scheduler и поставляется в составе коммерческой версии Postgres Pro Enterprise начиная с первой же ее версии. Разработчик — Владимир Ершов.
С самого начала решено было создавать pgpro_scheduler в современном стиле, органичном для компании — с записью конфигурации в JSON. Это удобно, например, для создателей Web-сервисов, которые смогут интегрировать планировщик в свои приложения. Но для не желающих использовать JSON, есть функции, принимающие параметры в виде обычных переменных. Планировщик поставляется вместе с дистрибутивом СУБД и он кросс-платформенный.
pgpro_scheduler не запускает внешних демонов или сервисов, а создает дочерние по отношению к postmaster процессы background worker — фоновые процессы. Количество «рабочих» задается в конфигурации pgpro_scheduler, но ограничивается общей конфигурацией сервера. На вход планировщика фактически поступают самые обычные команды SQL, без всяких ограничений, поэтому можно запускать функции на любых доступных Postgres языках. Если в структуру JSON входит несколько SQL-запросов, то они могут (при следовании определенному синтаксису) исполняться внутри единой транзакции:
SELECT schedule.create_job( ‘<"commands": [ "SELECT 1", "SELECT 2", "SELECT 3" ], "cron": "23 23 */2 * *" >‘ ); — то есть без последнего параметра, по умолчанию.
Допустим, во второй по списку команде произойдет ошибка (конечно, в SELECT 2 она произойдет вряд ли, но вообразим себе какой-нибудь «стремный» запрос). В случае исполнения в одной транзакции все результаты откатятся, но в логе планировщика появится сообщение о крахе второй команды. То же сообщение появится и в случае исполнения раздельных транзакций, но результат первой будет сохранен (третья транзакция не будет исполнена).
При запуске pgpro_scheduler всегда приступает к работе группа фоновых процессов-рабочих (background workers) со своей иерархией: один рабочий, в чине супервизора планировщика, контролирует рабочих в чине менеджеров баз данных — по одному на каждую базу данных, прописанную в строке конфигурации. Менеджеры, в свою очередь, контролируют рабочих, непосредственно обслуживающих задания. Супервизор и менеджеры довольно легкие процессы, поэтому если планировщик обслуживают даже десятки баз, это не сказывается на общей загрузке системы. И далее рабочие запускаются в каждой базе по потребностям в обработке запросов. В сумме они должны укладываться в ограничение СУБД max_worker_processes. Группа команд для мгновенного исполнения заданий пользуется ресурсами по-другому, но об этом позже.

Рис.1 Основной режим работы pgpro_scheduler
pgpro_scheduler это расширение (extension) Postgres. Следовательно, оно устанавливается на конкретную базу данных. При этом создается несколько системных таблиц в схеме schedule, по умолчанию они не видны пользователю. База данных знает теперь 2 новых, специальных типа данных: cron_rec и cron_job, с которыми можно будет работать через SQL-запросы. Есть таблица-лог, которая не дублирует журнал СУБД. Информация об успешной или неуспешной работе заданий планировщика доступна только через функции расширения pgpro_scheduler. Это сделано для того, чтобы один пользователь планировщика не знал о деятельности другого пользователя планировщика. Функции дают возможность избирательного просмотра лога, начиная с определенной даты, например:
Этот объект может содержать следующие ключи, некоторые из которых могут быть опущены:
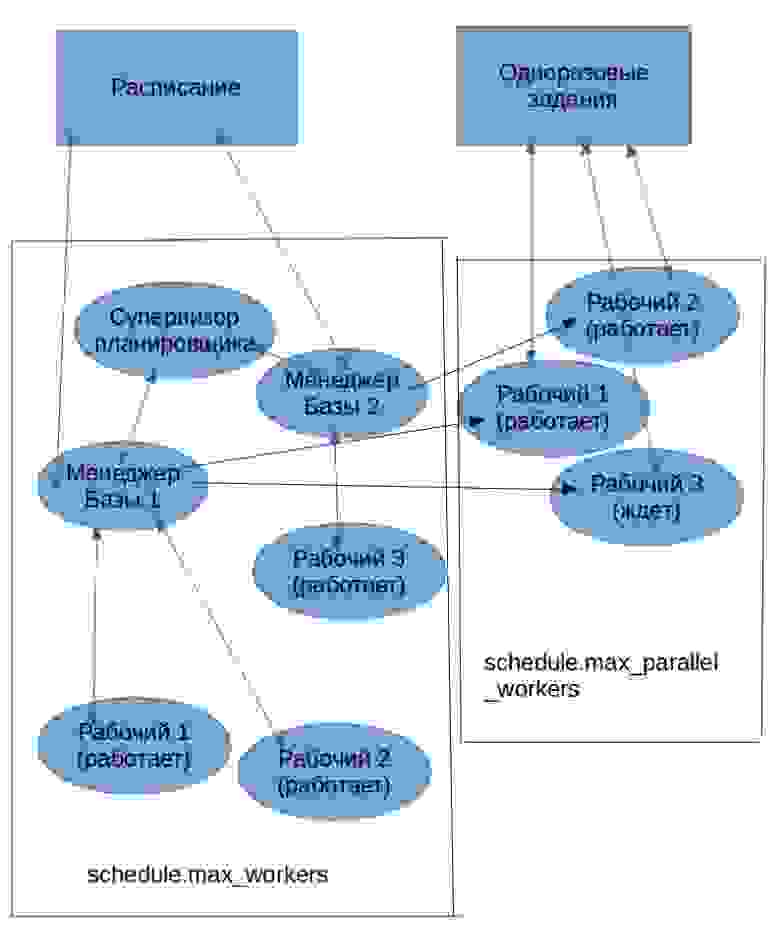
Схема 1. Иерархия процессов планировщика
Поле next_time_statement может содержать SQL-запрос, который будет выполняться после основной транзакции для вычисления времени следующего запуска. Если этот ключ определён, время первого запуска задания будет рассчитано по методам, описанным выше, но следующий запуск будет запланирован на то время, которое вернёт этот запрос. Данный запрос должен вернуть запись, содержащую в первом поле значение типа timestamp with time zone. Если возвращаемое значение имеет другой тип или при выполнении запроса происходит ошибка, задание помечается как давшее сбой, и дальнейшее его выполнение отменяется.
Этот запрос будет выполняться при любом состоянии завершения основной транзакции. Получить состояние завершения транзакции в нём можно из переменной Postgres Pro Enterprise schedule.transaction_state:
Один раз, зато без очереди
Как говорилось, есть еще важный класс задач для планировщика: формирование отдельных, непериодических заданий, использующих механизм one-time job. Если не задан параметр run_after, то в этом режиме планировщик умеет приступать к выполнению задания сразу в момент поступления — с точностью до временного интервала опроса таблицы, в которую записывается задание. В текущей реализации интервал фиксирован и равен 1 секунде. background worker-ы запускаются заранее и ждут «под парАми» появления задания, а не запускаются по мере необходимости, как в режиме расписания. Их количество определено параметром schedule.max_parallel_workers. Соответствующее число запросов может обрабатываться параллельно.

Рис.2 Режим one-time job.
Основная функция, формирующая задание, выглядит так:
schedule.submit_job(query text [options. ])
У этой функции есть, в соответствии с ее спецификой, о которой было в начале, тонкие настройки. Параметр max_duration задает максимальное время исполнения. Если за отведенное время работа не сделана, задание снимается (по умолчанию время исполнения неограниченно). max_wait_interval относится не к времени работы, а к времени ожидания начала работы. Если СУБД не находит за этот промежуток времени «рабочих», готовых взяться за исполнение, задание снимается. Интересный параметр depends_on задает массив работ (в режиме one-time), после завершения которых надо запустить данную работу.
Полезный параметр — resubmit_limit — устанавливает максимальное количество попыток перезапуска. Скажем, задание запускает процедуру, которая начинает высылать сообщение на почту. Почтовый сервер, однако, не торопится его принимать, и по таймауту или вообще из-за отсутствия связи процесс завершается, чтобы возобновиться вновь сразу или через заданное время. Без ограничения в resubmit_limit попытки будут продолжаться до победного конца.
Приправы и десерты
В начале были упомянуты отсоединенные задания — detached jobs. В текущей версии процесс, запустивший одноразовое задание, влачит свое существование в ожидании результата. Накладные расходы на работу background worker невелики, останавливать его нет смысла. Важно, что исполнение или неисполнение задания не пройдет бесследно, о его судьбе мы сможем узнать из запроса к логу планировщика, доступного нам, а не только администратору базы. Это не единственный способ выследить транзакцию даже в случае ее отката: в Postgres Pro Enterprise работает механизм автономных транзакций, который можно использовать для тех же целей. Но в этом случае результат запишут в лог СУБД, а не в «личный» лог пользователя, запустившего планировщик.
Если пользователю планировщика понадобится запланировать или просто запустить некоторые команды ОС с теми правами, которые доступны ему внутри ОС, он может легко сделать это через планировщик, воспользовавшись доступными ему языками программирования. Допустим, он решил воспользоваться untrusted Perl:
CREATE LANGUAGE plperlu;
После этого в можно записать как обычный запрос такую, например, функцию:
Пример из жизни: 1. складирование неактуальных логов
Для начала упрощенный пример управления секциями (партициями) из планировщика. Допустим, мы разбили логи посещения сайта на секции по месяцам. Мы не хотим хранить на дорогих быстрых дисках секции двухлетней свежести и моложе, а остальные сбрасываем в другое табличное пространство, соответствующее другим, более дешевым носителям, сохраняя, однако, полноценные возможности поиска и других операций по всем логам (с не поделенной на секции таблицей такое невозможно). Используем удобные функции управления секциями в расширении pg_pathman. В файле postgresql.conf должна быть строка shared_preload_libraries = ‘pg_pathman, pgpro_scheduler’.
CREATE EXTENSION pg_pathman; CREATE EXTENSION pgpro_scheduler;
ALTER SYSTEM SET schedule.enabled = on ;
ALTER SYSTEM SET schedule.database = ‘test_db’ ;
Баз может быть несколько. В этом случае они перечисляются через запятую внутри кавычек.
SELECT pg_reload_conf(); — перечитать изменения в конфигурации, не перезапуская Postgres.
Только что мы создали родительскую таблицу, которую будем разбивать на секции. Это дань традиционному синтаксису PostgreSQL, основанному на наследовании таблиц. Сейчас, в Postgres Pro Enterprise можно создавать секции не в 2 этапа (сначала пустую родительскую таблицу, потом задавать секции), а сразу определять секции. В данном случае мы воспользуемся удобной функцией pg_pathman, позволяющей сначала задавать приблизительное количество секций. По мере заполнения нужные секции будут создаваться автоматически:
Мы задали 10 начальных секций по одной на месяц, начиная с 1 янв. 2015. Заполним их каким-то количеством данных.
INSERT INTO partitioned_log SELECT i, ‘2015-01-01’ :: date + 60*60*i*random():: int * ‘1 second’ :: interval visit FROM generate_series(1,24*365) AS g(i);
Следить за количеством секций можно так:
SELECT count (*) FROM pathman_partition_list WHERE parent=’partitioned_log’:: regclass ;
Создаем каталог в ОС и соответствующее табличное пространство, куда будут складироваться устаревшие логи:
CREATE TABLESPACE archive LOCATION ‘/tmp/archive’ ;
И, наконец, функцию, которую ежедневно будет запускать планировщик:
Для разминки поставим одноразовое задание:
Ее можно запустить тоже из планировщика, но используя параметр run_after, который задает время задержки в секундах — чтобы у нас осталось время подумать, правильно ли мы поступили:
а если неправильно, то можно отменить ее функцией schedule.cancel_job(id) ;
Убедившись, что всё работает так, как задумано, можно поместить задание (теперь в синтаксисе JSON) уже в расписание:
То есть каждое утро в без пяти минут восемь планировщик будет проверять, не пора ли переместить устаревшие партиции в «холодный» архив и перемещать, если пора. Статус на этот раз можно проверять по логу планировщика: schedule.get_log() ;
Пример из жизни: 2. раскладываем баннеры по серверам
Покажем, как решается одна из типичных задач, в которых требуется выполнение работ по расписанию и используются одноразовые задания.
У нас есть сеть доставки контента (CDN). Мы собираемся разложить по нескольким входящим в нее сайтам баннеры, которые пользователи из рекламных агентств автоматически сгрузили в отведенный для них каталог.
DROP SCHEMA IF EXISTS banners CASCADE ;
CREATE SCHEMA banners;
SET search_path TO ‘banners’ ;
CREATE INDEX banner_on_cdn_banner_server_idx ON banner_on_cdn (banner_id, server_id);
CREATE INDEX banner_on_cdn_url_idx ON banner_on_cdn (url);
Создадим функцию, которая инициализирует загрузку баннера на сервера. Для каждого сервера она создает задачу загрузки, а также задачу, которая ожидает все созданные загрузки и проставляет правильный статус баннеру, когда загрузки завершатся:
А эта функция имитирует посылку баннера на сервер (на самом деле просто какое-то время спит):
RETURN TRUE ;
END ;
$BODY$
LANGUAGE plpgsql set search_path FROM CURRENT ;
Эта функция на основе статусов загрузок баннера на сервер будет определять какой статус поставить баннеру:
Эта функция будет по расписанию проверять, есть ли необработанные баннеры. И, если нужно, запускать обработку баннера:
CREATE FUNCTION check_banners () RETURNS int AS
$BODY$
DECLARE
r record ;
N int ;
BEGIN
N := 0;
FOR r IN SELECT * from banners WHERE status = ‘submitted’ FOR UPDATE LOOP
PERFORM start_banner_upload(r.id);
N := N + 1;
END LOOP ;
RETURN N;
END ;
$BODY$
LANGUAGE plpgsql SET search_path FROM CURRENT ;
Теперь займемся данными. Создадим список серверов:
Создадим пару баннеров:
И, наконец, поставим в расписание задачу по проверке вновь поступивших баннеров, которые надо разложить на сервера. Задача будет выполняться каждую минуту:
Вот и всё, картинки будут разложены по сайтам, можно отдохнуть.
Послесловие
В качестве Post Scriptum сообщаем, что планировщик pgpro_scheduler работает не только на отдельном сервере, но и в конфигурации кластера multimaster. Но это тема отдельного разговора.
А в качестве Post Post Scriptum — что в дальнейших планах встраивание планировщика в создаваемую сейчас графическую оболочку администрирования.


