Новости про Turing, видеокарты и трассировка лучей
NVIDIA внедряет трассировку лучей на старых видеокартах и игровых движках
Однако компания предупреждает, что будет ряд ограничений. К примеру, в Battlefield V можно получить улучшенное качество с минимальными потерями, в то время как в Metro Exodus в разрешении 1440p производительность может снизиться до неприемлемых 18 кадров в секунду.
Глобальное освещение с трасировокй лучей в Metro Exodus
NVIDIA представила игровые видеокарты на базе Turing
Как и ожидалось, компания NVIDIA провела презентацию новых игровых видеокарт на базе GPU Turing. Презентация прошла в понедельник вечером в преддверии Gamescom 2018.
Видеокарта NVIDIA GeForce RTX 2080 Ti
В своей речи исполнительный директор NVIDIA Дзень-Хсунь Хуан отмёл возникший поток слухов, заявив, что «всё что есть в Сети, все спецификации — неверны». Возможно, он немного переборщил, ведь перед самым анонсом официальный сайт NVIDIA опубликовал фотографии и спецификации ускорителей. Примечательно, что в таблицах спецификаций ничего не сказано о тензорных ядрах, хотя сам Хуан многократно говорит об их наличии.
В дополнение к таблице спецификаций можно отметить, что все карты на базе Turing получат новый интерфейс VirtualLink для шлемов виртуальной реальности, однако, некоторые производители могут от него отказаться, равно, как отказаться и от DisplayPort 1.4 с поддержкой 8K видео.
Основному анонсу видеокарт предшествовала речь Хуана, в которой он рассказал об усовершенствованиях в новых видеоплатах Turing. Главным из них стала технология NVIDIA RTX, обслуживаемая специальными ядрами для обеспечения высококачественного рендера в реальном времени с глобальным освещением. Также ядра Tensor обеспечат быстрое создание детальных изображений.
Project Sol: A Real-Time Ray-Tracing Cinematic Scene Powered by NVIDIA RTX
FAQ по видеокартам GeForce: что следует знать о графических картах?
Страница 4: GPU
Что скрывается за потоковым процессором, блоком шейдеров или ядром CUDA?
Потоковый процессор обрабатывает непрерывный поток данных, которых насчитываются многие сотни, причем они выполняются параллельно на множестве потоковых процессоров. Современные GPU оснащаются несколькими тысячами потоковых процессоров, они отлично подходят для задач с высокой степенью параллельности. Это и рендеринг графики, и научные расчеты. Что, кстати, позволило GPU закрепиться в серверном сегменте в качестве вычислительных ускорителей.

Еще одним шагом дальше можно назвать интеграцию ядер Tensor в архитектуру NVIDIA Ampere, которые способны эффективно вычислять менее сложные числа INT8 и INT4, но об этом мы поговорим чуть позже.
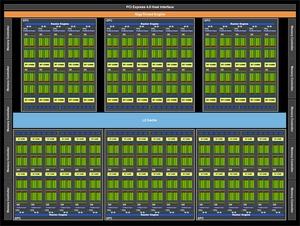
В составе GPU GA102 имеются семь кластеров Graphics Processing Clusters (GPC) с 12 потоковыми мультипроцессорами Streaming Multiprocessors (SM) каждый. Но на видеокартах GeForce RTX 3090 и GeForce RTX 3080 активны не все SM. GA102 GPU теоретически содержит 10.752 блоков FP32 (7 GPC x 12 SM x 128 блоков FP32). Но у GeForce RTX 3090 два SM отключены, поэтому видеокарта предлагает «всего» 10.496 блоков FP32. Такой подход повышает выход годных чипов NVIDIA, поскольку наличие одного-двух дефектных SM не приводит к отбраковке кристалла.
В случае GeForce RTX 3080 один кластер GPC полностью отключен, поэтому на GA102 GPU остаются шесть GPC, но только четыре из них содержат полные 12 SM, два ограничены десятью SM. Что дает в сумме 8.704 блока FP32 в составе 68 SM.
NVIDIA масштабирует архитектуру Ampere с видеокарты GeForce RTX 3060 вплоть до GeForce RTX 3090. Ниже представлен обзор видеокарт GeForce RTX 30:
| GeForce RTX 3090 | GeForce RTX 3080 Ti | GeForce RTX 3080 | GeForce RTX 3070 Ti | |
| GPU | Ampere (GA102) | Ampere (GA102) | Ampere (GA102) | Ampere (GA104) |
| Число транзисторов | 28 млрд. | 28 млрд. | 28 млрд. | 17,4 млрд. |
| Техпроцесс | 8 нм | 8 нм | 8 нм | 8 нм |
| Площадь кристалла | 628,4 мм² | 628,4 мм² | 628,4 мм² | 392,5 мм² |
| Число FP32 ALU | 10.496 | 10.240 | 8.704 | 6.144 |
| Число INT32 ALU | 5.248 | 5.120 | 4.352 | 3.072 |
| Число SM | 82 | 80 | 68 | 48 |
| Ядра Tensor | 328 | 320 | 272 | 192 |
| Ядра RT | 82 | 80 | 68 | 48 |
| Базовая частота | 1.400 МГц | 1.365 МГц | 1.440 МГц | 1.580 МГц |
| Частота Boost | 1.700 МГц | 1.665 МГц | 1.710 МГц | 1.770 МГц |
| Емкость памяти | 24 GB | 12 GB | 10 GB | 8 GB |
| Тип памяти | GDDR6X | GDDR6X | GDDR6X | GDDR6X |
| Частота памяти | 1.219 МГц | 1.188 МГц | 1.188 МГц | 1.188 МГц |
| Ширина шины памяти | 384 бит | 384 бит | 320 бит | 256 бит |
| Пропускная способность памяти | 936 Гбайт/с | 912 Гбайт/с | 760 Гбайт/с | 608 Гбайт/с |
| TDP | 350 Вт | 350 Вт | 320 Вт | 290 Вт |
| GeForce RTX 3070 | GeForce RTX 3060 Ti | GeForce RTX 3060 | |
| GPU | Ampere (GA104) | Ampere (GA104) | Ampere (GA106) |
| Число транзисторов | 17,4 млрд. | 17,4 млрд. | 12 млрд. |
| Техпроцесс | 8 нм | 8 нм | 8 нм |
| Площадь кристалла | 392,5 мм² | 392,5 мм² | 276 мм² |
| Число FP32 ALU | 5.888 | 4.864 | 3.584 |
| Число INT32 ALU | 2.944 | 2.432 | 1.792 |
| Число SM | 46 | 38 | 28 |
| Ядра Tensor | 184 | 152 | 112 |
| Ядра RT | 46 | 38 | 28 |
| Базовая частота | 1.500 МГц | 1.410 МГц | 1.320 МГц |
| Частота Boost | 1.730 МГц | 1.665 МГц | 1.780 МГц |
| Емкость памяти | 8 GB | 8 GB | 12 GB |
| Тип памяти | GDDR6 | GDDR6 | GDDR6 |
| Частота памяти | 1.725 МГц | 1.750 МГц | 1.875 МГц |
| Ширина шины памяти | 256 бит | 256 бит | 192 бит |
| Пропускная способность памяти | 448 Гбайт/с | 448 Гбайт/с | 360 Гбайт/с |
| TDP | 220 Вт | 200 Вт | 170 Вт |
Одновременное выполнение операций с целыми числами и числами с плавающей запятой
Как мы уже упоминали, вычислительные блоки FP32 могут работать в режиме 2x FP16, то же самое касается INT16. Чтобы увеличить вычислительную производительность и сделать ее более гибкой, в архитектуре NVIDIA Turing появилась возможность одновременного расчета чисел с плавающей запятой и целых чисел. Конечно, подобная возможность сохранилась и в архитектуре Ampere. NVIDIA проанализировала данные вычисления в конвейере рендеринга в десятках игр, обнаружив, что на каждые 100 расчетов FP выполняется примерно треть вычислений INT. Впрочем, значение среднее, на практике оно меняется от 20% до 50%. Конечно, если вычисления FP и INT будут выполняться одновременно, то конвейеру придется иногда «подтормаживать» в случае взаимных связей.

Соотношение 1/3 INT32 и 2/3 FP32 отражено в структуре Ampere Streaming Multiprocessor (SM), составляющем элементе архитектуры Ampere. NVIDIA удвоила число вычислительных блоков FP32 на каждый SM. Вместо 64 блоков FP32 на SM, их теперь насчитывается 128. Плюс 64 блока INT32. Теперь на квадрант SM насчитывается два пути данных, некоторые могут работать параллельно. Один из путей данных содержит 16 блоков FP32, то есть может выполнять 16 вычислений FP32 за такт. Второй путь данных содержит по 16 блоков FP32 и INT32. Каждый из квадрантов SM может выполнять либо 32 операции FP32, либо по 16 операций FP32 и INT32 за такт. Если же брать SM целиком, то возможно выполнение 128 операций FP32 или по 64 операции FP32 и INT32 за такт.
Параллельное выполнение продолжается и на других блоках. Например, ядра RT и Tensor могут работать параллельно в конвейере рендеринга, что снижает время, требующееся на рендеринг кадра.
Под термином «потоковые процессоры» сегодня подразумевают количество вычислительных блоков GPU, хотя следует помнить, что сложность вычислений бывает разной. Поэтому термин используется гибко, но обычно все равно описывает вычислительные блоки.
Текстурные блоки
Действительно, для рендеринга объекта простых текстур уже недостаточно, использование нескольких слоев позволяет, например, получить 3D-эффект вместо плоской текстуры. Раньше объекты приходилось рассчитывать на конвейере несколько раз, и каждый проход текстурный блок накладывал текстуру, сегодня достаточно одного процесса рендеринга, текстурный блок может получать данные объекта для многократной обработки из буфера.
Контроллер памяти
Помимо изменений в SM, новая архитектура NVIDIA получила оптимизированную структуру конвейеров растровых операций (ROP), а также соединения ROP и контроллера памяти. До поколения Turing ROP всегда подключались к интерфейсу памяти. И на каждый 32-битный контроллер памяти приходилось восемь ROP. Если число контроллеров памяти и ширина шины менялись, то же самое касалось и ROP. В архитектуре Ampere ROP перенесены в GPC. Используются два раздела ROP на GPC, каждый раздел содержит восемь ROP.
Что дает иную формулу вычисления ROP на GeForce RTX 3080. Шесть GPC с 2x 8 ROP на каждом дают 96 ROP. У GeForce RTX 3090 работают семь GPC с 2x 8 ROP, что дает 112 ROP. NVIDIA намеренно интегрировала ROP глубже, чтобы задняя часть конвейера рендеринга меньше зависела от интерфейса памяти. Например, видеокарта GeForce RTX 3080 использует 320-битный интерфейс памяти, но содержит 96 ROP, а не 80 ROP.
Интерфейс памяти разделен на 32-битные блоки. В зависимости от желаемой ширины интерфейса памяти или емкости, их можно набирать в произвольном количестве.
Ядра Tensor и RT
Ядра Tensor третьего поколения
С архитектурой Turing NVIDIA представила два новых вычислительных блока, ранее на GPU не использовавшихся. Конечно, ядра Tensor знакомы нам по архитектуре Volta, но там они использовались для научных расчетов. В случае GPU Ampere ядра Tensor перешли уже на третье поколение.
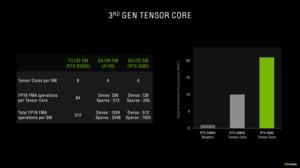
Ядра Tensor ранее использовались только для вычислений INT16 и FP16, но в третьем поколении они могут работать с FP32 и FP64. Что особенно важно для сегмента HPC с высокой точностью. Для игровых GPU GeForce намного важнее меньшая точность.
Ядра Tensor архитектуры Turing могут выполнять 64 операции FP16 Fused Multiply-Add (FMA) каждое. В случае Ampere число операций увеличено до 128 у GA102 GPU и до 256 у GA100 GPU с плотными матрицами. Если же используются разреженные матрицы, число операций FMA FP16 увеличивается до 256 у GA102 GPU и до 512 у GA100 GPU. Ядра Tensor архитектуры Turing разреженные матрицы не поддерживают.
Ядра RT второго поколения
Все они опираются на тот принцип, что удаленные от луча примитивы не могут с ним пересекаться. Следовательно, и смысла их просчитывать нет. Число лучей на сценах растет экспоненциально, поэтому на каждый луч следует обрабатывать как можно меньшее число примитивов, чтобы не увеличивать вычислительную нагрузку.
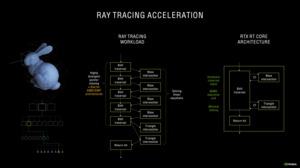
Поскольку NVIDIA не изменила число ядер RT на SM в архитектуре Ampere, количество блоков SM на GPU по-прежнему определяет производительность RT. Но в ядрах RT есть другие оптимизации.
Одна из проблем с расчетом пересечений при трассировке лучей связана с движущимися объектами, особенно если используется эффект размытия движения (motion blur). Для ядер RT в архитектуре Turing такой сценарий является «узким местом». Но второе поколение ядер RT уже лучше справляется с интерполяцией эффекта размытия движения. Пересечения просчитываются с упреждением, в итоге трассировка лучей рассчитываются только для тех областей, где она необходима.
Кэши L1 и L2
Между функциональными блоками (потоковые процессоры, ядра RT и Tensor) и видеопамятью располагаются еще два уровня хранения данных, без которых GPU не смог бы выдавать высокий уровень производительности. Цель этих кэшей заключается в том, чтобы хранить информацию как можно ближе к функциональным блокам. Данные передаются из видеопамяти сначала в кэш L2, а затем и в кэш L1.
NVIDIA с архитектурой Ampere вновь увеличила кэш L1 с 96 до 128 кбайт. Скорость работы L1 была вновь удвоена. NVIDIA реализовала такую же меру ранее при переходе с Pascal на Turing. Число 32-битных регистров не изменилось и осталось на уровне 16.384. То же самое касается числа блоков чтения/записи.
Двигатель истории. Обзор видеокарты GeForce RTX 2080 Ti: часть 1
⇡#Тензорные ядра в архитектурах Volta и Turing
Тензорные ядра — вот еще один подарок, полученный Turing от HPC-архитектуры Volta. В своей основе тензорное ядро представляет собой группу ALU, выполняющих тензорные математические операции, а именно FMA (Fused Multiply Add) над матрицами чисел с плавающей запятой. Конкретно в архитектурах Volta и Turing тензорное ядро перемножает две матрицы половинной точности (FP16) размером 4 × 4 и складывает результат с третьей матрицей 4 × 4 (FP16 или FP32), чтобы получить финальную матрицу FP32. Такого рода вычисления используются, главным образом, в задачах машинного обучения — как для формирования глубинных нейросетей, так и для их последующего применения (Inference).
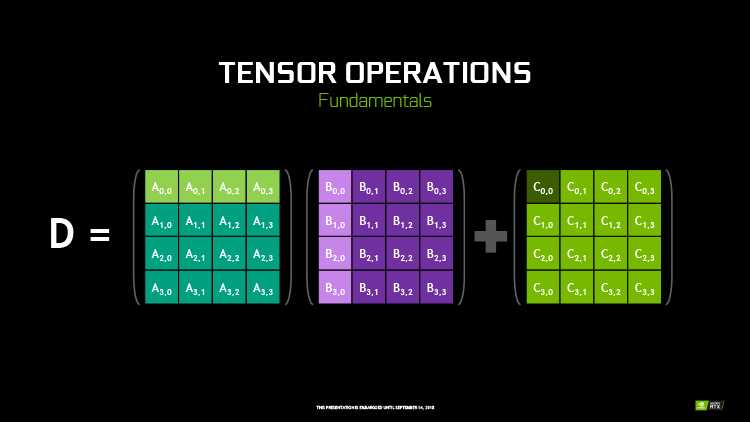
Функционально новые тензорные ядра не так уж отличаются от обычных шейдерных ALU, которые тоже способны выполнять операции FMA, лишь с той разницей, что шейдерные ALU оперируют скалярными величинами, организованными по принципу SIMT, а тензорные ядра — векторными в виде матриц. Однако тензорные ядра не могут выполнять каких-либо иные вычисления, помимо FMA, и как следствие, крайне упрощены: их компоненты размещаются с высокой плотностью на кристалле GPU и нуждаются в минимуме управляющей логики по сравнению с универсальными CUDA-ядрами. Благодаря узкой специализации одно тензорное ядро за такт процессора выполняет 64 инструкции FMA (128 FLOPS в пересчете на промежуточные операции), в то время как на шейдерных ALU целый потоковый мультипроцессор из 64 ядер CUDA, даже при условии работы с удвоенной скоростью за счет половинной точности FP16, выдает 256 FLOPS. В чипах Volta и Turing каждый SM содержит восемь тензорных ядер, а значит, если переложить задачу с CUDA-ядер на тензорные, то результатом будет не только разгрузка универсальных вычислительных ресурсов для других операций, но и четырехкратный рост быстродействия в собственно тензорных расчетах.
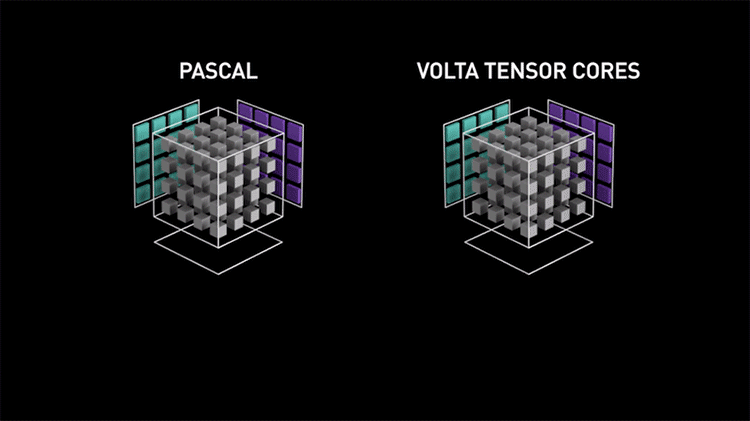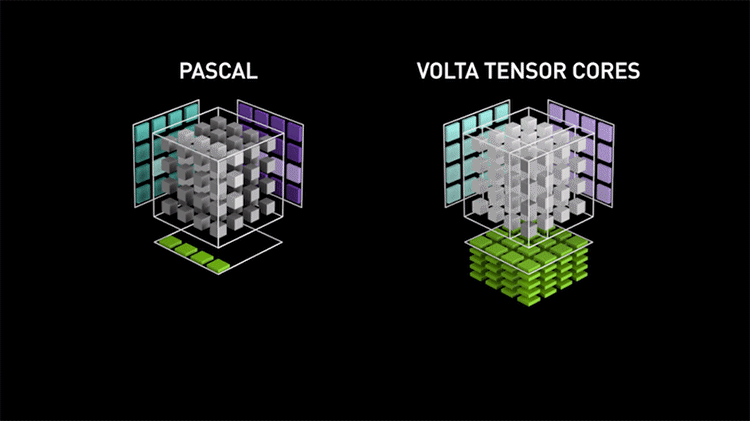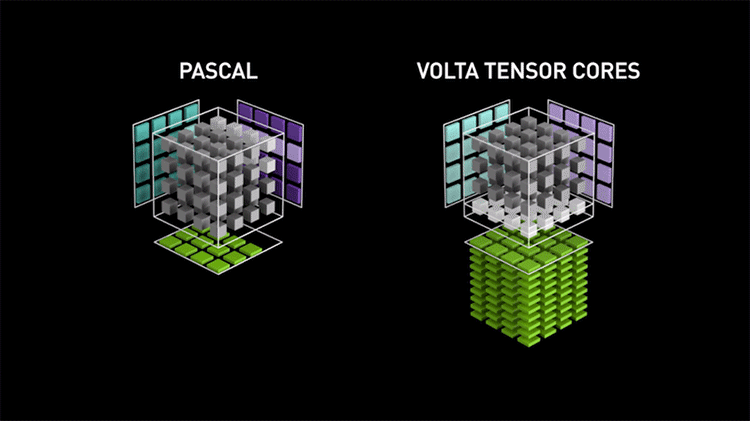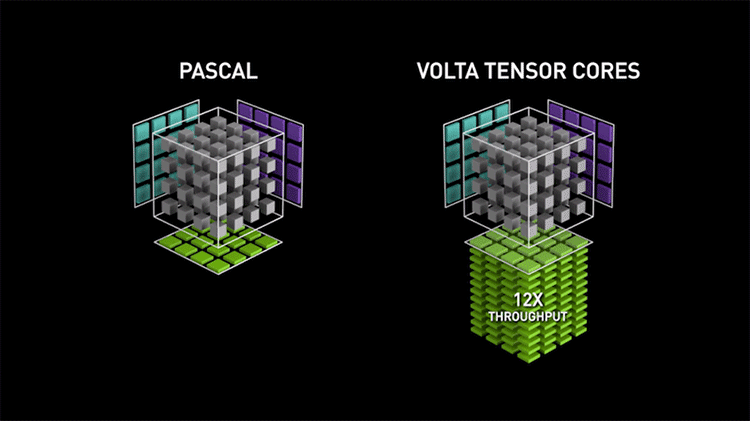
Более того, пусть Turing является, в первую очередь, архитектурой для графических задач, она обладает повышенной гибкостью и потенциально увеличенным быстродействием в тензорных вычислениях по сравнению с Volta за счет поддержки операций на целыми числами форматов INT8 и INT4. Подобные задачи подходят для применения нейросети (Inference), если ее математическая модель терпит квантизацию и не требует высокой точности представления данных, а скорость обработки (по сравнению с операциями FMA с результатом в формате FP16) возрастает в два и четыре раза для INT8 и INT4 соответственно.
Но как тензорные ядра можно использовать в компьютерных играх, не говоря уже конкретно о рендеринге графики? У NVIDIA есть масса идей на этот счет. Например, чрезвычайно быстрое полноэкранное сглаживание/масштабирование по алгоритму DLSS (Deep Learning Super Sampling). Тренировка нейросетей для задач такого рода выполняется на собственных серверах NVIDIA путем анализа множества кадров из конкретной игры с предельно возможной выборкой пикселов (64-кратный суперсемплинг). Затем графический процессор на клиентской машине, используя полученный профиль, выводит на экран изображение, приближенное по качеству к 64xSS.
Существует два режима работы Deep Learning Super Sampling. В режиме максимального качества (DLSS 2x) рендеринг оригинального кадра для обработки на тензорных ядрах выполняется в целевом разрешении экрана. При однократном DLSS берется сравнительно низкое исходное разрешение (к примеру, 1440p вместо целевого 2160p), а задачей нейросети становится масштабирование кадра до полного разрешения экрана. В последнем случае влияние DLSS на быстродействие столь велико, что GeForce RTX 2080 Ti достигает двукратной разницы в быстродействии с GeForce GTX 1080 Ti — результат, недостижимый за счет грубой силы дополнительных шейдерных ALU.

⇡#Основные принципы трассировки лучей
Большинству наших читателей не нужно рассказывать, что собой представляет трассировка лучей (Ray Tracing) в 3D-графике, но для полного понимания в контексте архитектуры Turing стоит объяснить принципиальное отличие от преобладающего в рендеринге реального времени метода растеризации. Оба подхода решают одну и ту же проблему проекции трехмерных объектов на плоский экран монитора, но делают это в противоположных направлениях. Программа растеризации, в узком смысле этого понятия, рассматривает один за другим геометрические примитивы сцены (полигоны) и определяет экранные пикселы, которые перекрывает каждый из них. Затем тем или иным из различных способов определяется цвет пиксела в соответствии с цветом соответствующего ему участка поверхности полигона.
В свою очередь, простейший алгоритм трассировки лучей (Ray Casting) начинает с плоскости экрана: через каждый пиксел из точки обзора отправляется луч, а вычислительная задача состоит в том, чтобы найти полигон, с которым он столкнется, и получить информацию о цвете поверхности в точке пересечения. Результаты обеих моделей в данном случае будут одинаковы, поскольку ни та, ни другая еще содержит информации об освещении объекта. Но все меняется, как только возникает задача эту информацию получить.
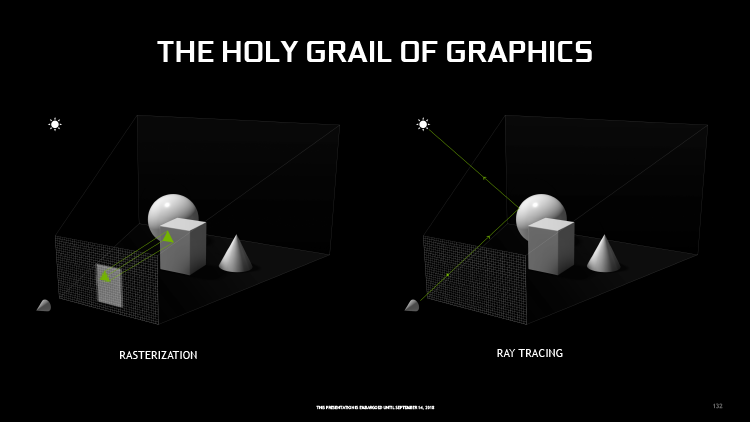
В модели Ray Tracing по уже известному принципу определяется траектория луча, отраженного от поверхности примитива. Если луч второго порядка пересекается с источником света, поверхность считается освещенной. Если обнаружено пересечение с другим примитивом, то поверхность в тени. Развитие этого алгоритма позволяет рассчитывать освещенность сколь угодно близко к физике реального мира, включая рассеянный и прямой свет, преломление лучей в прозрачной среде и т.д.
В методе трассировки лучей высокий реализм изображения достигается за счет автоматизации процесса. С другой стороны, растеризация в чистом виде просто не содержит столь же прямых и элегантных средств расчета освещения. Бесчисленные способы получить в изображении свет и тень, от простейших карт теней и вплоть до шейдерных программ, являются не более чем имитацией результата физических явлений с позиции наблюдателя, а задача их корректного применения ложится на плечи дизайнера (будь то статичная сцена, видеоролик или компьютерная игра). Можно сказать, что создание реалистичного изображения с помощью трассировки лучей — это фотография, а с помощью растеризации — рисунок.
Повышение качества Ray Tracing вызывает лавинообразный рост вычислительной нагрузки, пропорциональный количеству отслеживаемых лучей, в то время как алгоритмы растеризации могут быть математически и логически сложны, но сравнительно нетребовательны к вычислительной мощности. Поэтому ведущим методом в рендеринге реального времени является именно растеризация, а не трассировка лучей.
⇡#RT-ядра Turing
По мере того как растут возможности графических процессоров, то и дело возникают мысли о том, что Ray Tracing в реальном времени уже не за горами. NVIDIA еще в 2009 году представила функцию трассировки лучей на CUDA-ядрах в собственном API OptiX, а на стороне AMD есть аналогичные функции в библиотеках GPUOpen. Действительно, в профессиональной сфере трассировка лучей стала распространенным классом задач GP-GPU (General Purpose GPU), но выполнение таких расчетов силами шейдерных ALU все еще не достигло приемлемого быстродействия. NVIDIA собирается взять последний рубеж за счет интеграции в железо специализированных функциональных блоков — подобно тому, как аппаратное ускорение растеризации в свое время открыло компьютерным играм дорогу в полноценное 3D.
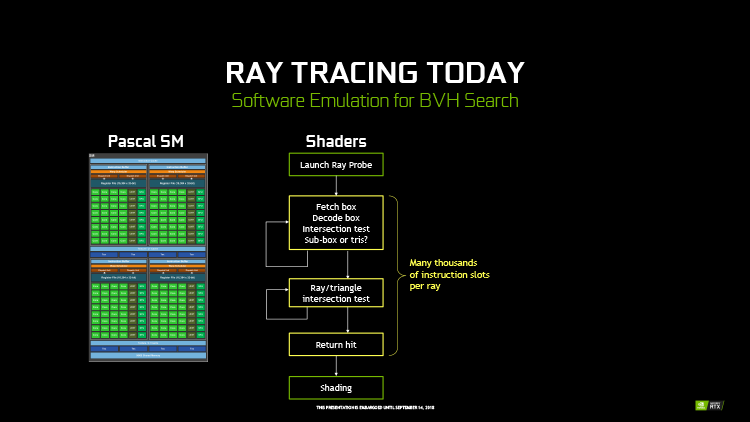
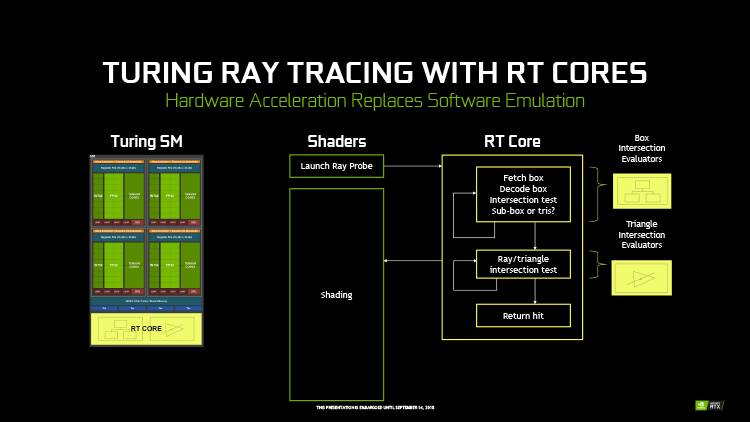
Каждый SM в архитектуре Turing содержит RT-ядро, которое выполняет поиск пересечений между лучом и полигонами сцены. В первых алгоритмах такая задача крайне неэффективно и ресурсоемко решалась путем перебора всех геометрических примитивов, но RT-движок Turing использует общепризнанный метод оптимизации под названием Bounding Volume Hierarchy. Алгоритм BVH перед тем, как сцена будет отрисована в первый раз, с помощью CUDA-ядер сортирует полигоны объектов по вложенным друг в друга «коробкам». Таким образом, чтобы кратчайшим путем определить точку пересечения луча с поверхностью примитива, программе нужно рекурсивным образом пройти сквозь полученную древовидную структуру. В статичной сцене генерация структуры BVH выполняется один раз для всех последующих кадров, но в большинстве случаев алгоритм допускает и динамическую коррекцию в ответ на преобразования геометрии.

За счет узкой специализации RT-ядра Turing несопоставимо более эффективны в поиске пересечений луча по сравнению с шейдерными ALU. NVIDIA приводит следующие данные: GeForce GTX 1080 Ti, задействовав 10 TFLOPS вычислительной мощности (из доступных 11,3 TFLOPS) исключительно для Ray Tracing, достигает производительности 1,1 млрд лучей/с. GeForce RTX 2080 Ti с помощью 68 RT-ядер превышает отметку в 10 млрд лучей/с, при этом его шейдерные ALU остаются свободны для другой работы.
⇡#Новые шейдерные функции (Turing Advanced Shading)
Мы рассказали о ключевых особенностях архитектуры Turing, но список усовершенствований, которые NVIDIA внедрила в новые GPU, далеко не исчерпан. Помимо новых функций в рамках Direct3D feature level12_1, связанных с управлением ресурсами, архитектура приобрела несколько эксклюзивных техник исполнения шейдеров и обработки геометрии, доступ к которым открывается через NVAPI.
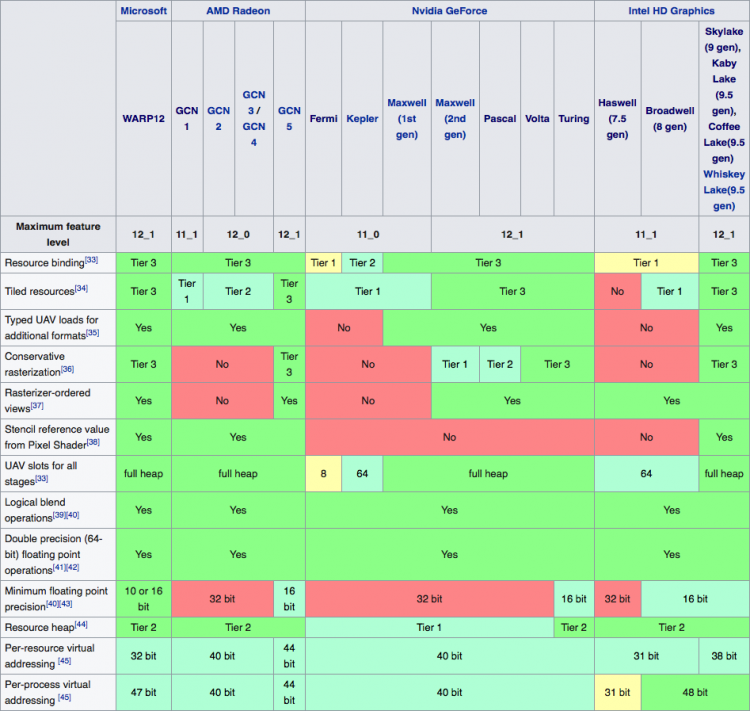
Поддержка функций рендеринга Direct3D в GPU различной архитектуры (Wikipedia)
Mesh Shading
Одной из новых возможностей в наборе инструкций Turing является Mesh Shading — гибкий способ насытить сцену геометрическими деталями и одновременно снизить нагрузку на центральный процессор системы. Переход с API Direct3D 11 на Direct3D 12, который медленно, но неуклонно происходит в компьютерных играх, начался под лозунгом освобождения CPU от избыточной нагрузки, связанной с подготовкой вызовов на отрисовку (draw call) множества отдельных объектов (полигональных сеток, meshes). Разработчики Turing предлагают более радикальное решение.
Модель Mesh Shading представляет собой альтернативный программный конвейер обработки геометрии, который запускается не вызовом на отрисовку отдельной сетки, а списком множества сеток. Затем на его основе многопоточный алгоритм, подобный вычислительным шейдерам, генерирует набор треугольников для растеризации. Одно это устраняет бутылочное горлышко в виде быстродействия центрального процессора, но GPU также самостоятельно варьирует LOD (Level of Detail) и глубину тесселяции моделей в зависимости от их размера на экране.
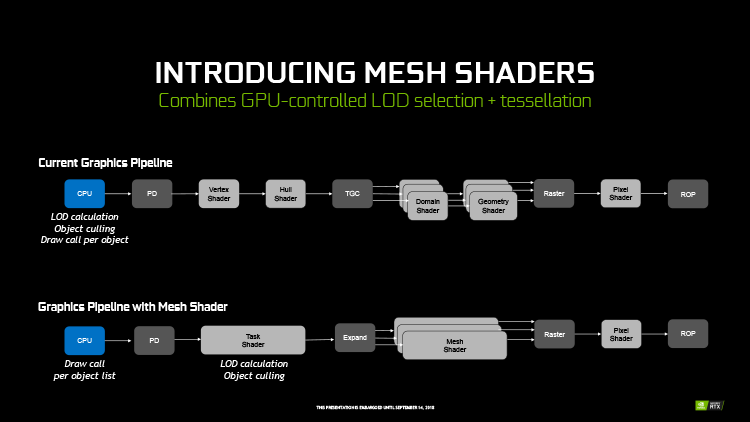
Variable Rate Shading
Функция Variable Rate Shading (VRS) опирается на идеи Multi-Resolution Shading (MRS) и Lens-Matched Shading (LMS), впервые реализованные в архитектуре Pascal для VR-среды. MRS и LMS позволяют разбить экран на 16 зон, размер пикселов в которых варьирует в соответствии с кривизной линз шлема. Метод VRS действует по такому же принципу, только оперирует участками экрана размером 4 × 4 пиксела, а изменяется не разрешение, а плотность выборки пикселов для шейдерных программ. Таким образом разработчики игры могут сэкономить ресурсы GPU на рендеринге тех участков цены, которые не нуждаются в точном определении цвета пикселов: однородные, бедные деталями текстуры, размытые движением объекты, а применительно к VR с отслеживанием глаз — периферийные области зрения. В отличие от иных проприетарных функций рендеринга, разработчикам будет очень просто реализовать VRS даже в тех играх, которые были выпущены до появления Turing.
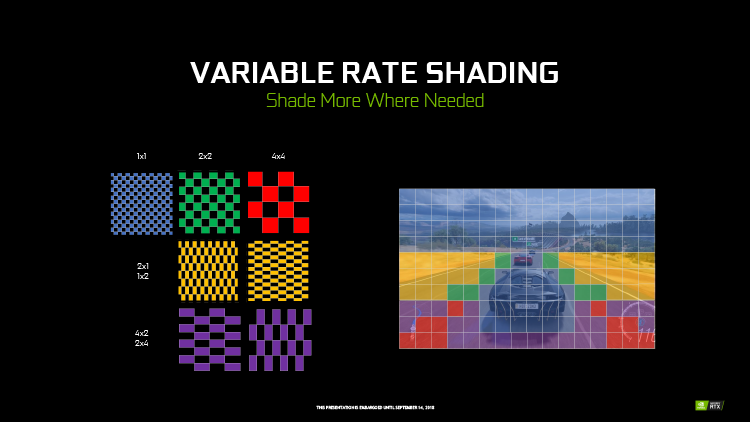
Texture Space Shading
В основе Texture Space Shading лежит догадка о том, что шейдерные программы можно применять не только к пикселам экрана после того, как сделана выборка из соответствующих им участков текстур, но и к текселам, то есть непосредственно в текстурном пространстве. Результат шейдера сохраняется в оперативной памяти как новая текстура и может быть заново использован в пределах того же кадра или одного из следующих. А если при этом в результате изменения позиции наблюдателя на экран проецируются текселы, не обработанные шейдером ранее, необходимо заново обработать только их вместо целой текстуры или всех пикселов в проекции соответствующего примитива, как происходит в стандартных шейдерных программах. Таким образом с помощью TSS можно существенно снизить шейдерную нагрузку в рендеринге стереоскопического изображения для VR, большая часть кадров для обеих глаз заполнена одними и теми же объектами и текстурами. И поскольку Texture Space Shading работает с текстурными данными, алгоритм неизбежно учитывает MIP-уровень, поэтому исполнение шейдеров на размытой копии текстуры, которая наложена на удаленный от точки зрения объект, автоматически происходит со сниженной выборкой образцов.
Multi-View Rendering
В архитектуре Pascal блоки обработки геометрии PolyMorph Engine были дополнены функцией Simultaneous Multi-Projection (SMP), за счет которой приложение может затребовать одновременную проекцию полигонов на экран с двух точек обзора, разнесенных по горизонтальной оси, и в 16 различных направлениях — главным образом для ускорения ранних этапов обработки геометрии в стереоскопическом 3D и мультимониторных системах.
В свою очередь, Multi-View Rendering (MVR) — это более гибкое расширение SMP, выполняющее за один проход проекцию полигонов с четырех произвольных точек, а количество направлений обзора по-прежнему составляет 16 на каждую точку. Технология MVR нужна в первую очередь для того, чтобы учесть при рендеринге внутреннюю геометрию VR-шлемов нового поколения с несколькими экранами и сверхшироким углом обзора, но может быть востребована и за пределами VR — например для быстрой генерации карт теней от нескольких источников света.

⇡#Гибридная модель рендеринга
Несмотря на высокую эффективность новой архитектуры в трассировке лучей, NVIDIA не призывает к полному переходу игровой графики на этот алгоритм. Более перспективно выглядит комбинированный подход, в котором RT-ядра привлекаются для таких задач, которые лучше всего решаются трассировкой лучей, а основную работу в построении изображения по-прежнему берет на себя растеризация. К примеру, растеризация с буфером глубины (z-буфером), преобладающая в играх, гораздо быстрее отсекает невидимые поверхности на раннем этапе рендеринга и полностью заменяет этап лучей первого порядка в RT. Затем при помощи лучей второго порядка можно получить любой набор эффектов освещения: начиная с дозированного формирования теней и отражений и заканчивая полным моделированием физически достоверного освещения. Трассировка лучей также является частью библиотек GameWorks для симуляции позиционного звука. Важную роль в алгоритмах RT сыграют тензорные ядра, за счет которых алгоритм нейросети сможет компенсировать нехватку плотности лучей путем аппроксимации недостающих результатов.
Для оценки производительности в рамках гибридной модели рендеринга NVIDIA предложила формулу, которая складывает пиковую пропускную способность (в TFLOPS) различных блоков GPU (ядра FP32, INT32, тензорные и RT-ядра) в показатель RTX-OPS. При этом учитывается, что в реальных приложениях GPU не может быть полностью загружен в силу ограничений TDP, конкуренции блоков за ПСП и другие общие ресурсы, а также практической необходимости задействовать в коде те или иные функции. Соответственно, слагаемым формулы RTX-OPS назначены веса в соответствии с тем, какую часть времени рендеринга кадра занимает определенный тип вычислений. К примеру, ядра FP32 активны в течение 80% времени кадра, и на примере GeForce RTX 2080 Ti Founders Edition их вклад в общее быстродействие составляет 14 TFLOPS × 0,8 = 11,2 Tera RTX-OPS.
Описанная математика опирается на массу предположений о том, как распределяется гибридная нагрузка в идеальном графическом движке, откалиброванном под соотношение блоков архитектуры Turing. А для расчета долей времени кадра и, соответственно, весов, назначенных слагаемым формулы, взят эталонный ускоритель (предположительно, GeForce RTX 2080 Ti), быстродействие которого не упирается ни в один из рассматриваемых типов ядер. Таким образом, формула RTX-OP не претендует на оценку производительности в реальных играх и годится лишь для сравнения между собой видеокарт семейства Turing. На референсных частотах GeForce RTX 2070, 2080 и 2080 Ti оцениваются в 42, 57 и 76 Tera RTX-OPS соответственно.

Модель гибридного рендеринга на архитектуре Turing уже доступна разработчикам через библиотеки трассировки лучей в составе Direct3D 12 (DXR) или OptiX — собственного API NVIDIA. Также ведутся работы по интеграции Ray Tracing в открытый стандарт Vulkan. На данный момент о поддержке функций трассировки лучей в адаптерах GeForce RTX объявили 11 игровых проектов, среди которых главными вестниками новой технологии станут Battlefield V, Metro Exodus и Shadow of the Tomb Raider. Намного больше игр присоединились к инициативе DLSS и со временем получат собственные профили нейросетей в драйвере NVIDIA.
| Игра | Ray Tracing | Deep Learning Super Sampling (DLSS) | Turing Advanced Shading |
| Ark: Survival Evolved | Да | ||
| Assetto Corsa Competizione | Да | ||
| Atomic Heart | Да | Да | |
| Battlefield V | Да | ||
| Control | Да | ||
| Darksiders III | Да | ||
| Dauntless | Да | ||
| Deliver Us The Moon: Fortuna | Да | ||
| Enlisted | Да | ||
| Fear the Wolves | Да | ||
| Final Fantasy XV | Да | ||
| Fractured Lands | Да | ||
| Hellblade: Senua’s Sacrifice | Да | ||
| Hitman 2 | Да | ||
| In Death | Да | ||
| Islands of Nyne | Да | ||
| Justice | Да | Да | |
| JX3 | Да | Да | |
| KINETIK | Да | ||
| MechWarrior 5: Mercenaries | Да | Да | |
| Metro Exodus | Да | ||
| Outpost Zero | Да | ||
| Overkill’s The Walking Dead | Да | ||
| PlayerUnknown’s Battlegrounds | Да | ||
| ProjectDH | Да | ||
| Remnant: From the Ashes | Да | ||
| SCUM | Да | ||
| Serious Sam 4: Planet Badass | Да | ||
| Shadow of the Tomb Raider | Да | ||
| Stormdivers | Да | ||
| The Forge Arena | Да | ||
| We Happy Few | Да | ||
| Wolfenstein II: The New Colossus | Да |
⇡#Кодирование/декодирование видео, интерфейсы вывода изображения
Наряду с фундаментальными архитектурными изменениями, описанными выше, чипы семейства Turing получили усовершенствованный мультимедийный блок. Новый декодер видеопотока способен обрабатывать HEVC с форматом цвета YUV444 и глубиной 10/12 бит при частоте 30 кадров/с, а в декодировании VP9 реализована поддержка 10/12-битной глубины цвета. Аппаратный кодировщик HEVC, в свою очередь, способен записывать видео в разрешении 8К с частотой 30 кадров/с, и было повышено качество кодирования в отношении к битрейту потока — как в формате HEVC, так и в H.264.
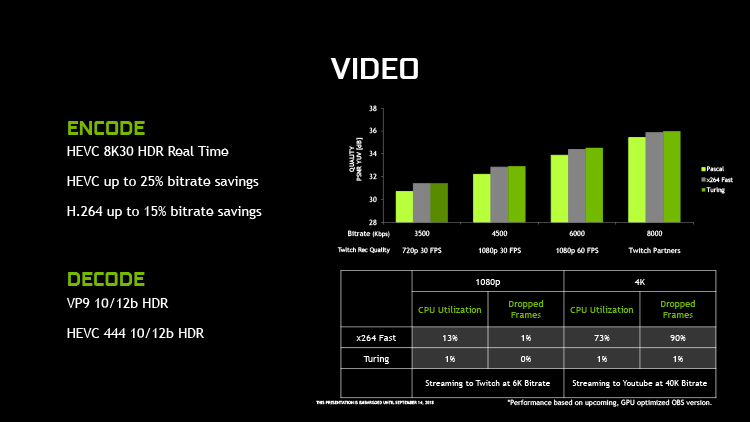
Видеовыход DisplayPort в видеокартах поколения GeForce 10 был сертифицирован в рамках версии 1.2, но по пропускной способности удовлетворяет требованиям DisplayPort 1.3/1.4 и поддерживает режимы экрана вплоть до 7680 × 4320 с кадровой частотой 30 Гц. GeForce RTX, напротив, имеет полную сертификацию DisplayPort 1.4a, в которую входит алгоритм компрессии данных VESA Display Stream Compression 1.2. За счет DSC по одному кабелю возможна передача видеопотока с разрешением 7680 × 4320 и частотой 60 Гц без цветовой субдискретизации (Chroma Subsampling). При этом DSC является алгоритмом сжатия с потерями, но, согласно разработчикам стандарта, визуально не влияет на качество изображения. В свою очередь, за счет совместной работы DSC 1.2 и Chroma Subsampling возможны более агрессивные комбинации разрешения экрана, кадровой частоты, глубины цвета и HDR.
Однако в данный момент на рынке еще нет устройств вывода изображения, совместимых с DSC 1.2. Высокая частота свыше 98 Гц в присутствии HDR и 10-битной глубины цвета достигается на 4К-панелях за счет Chroma Subsampling YCbCr 4:2:2. Конвертация цвета пикселов из RGB в данный формат, а также тоновая коррекция (Tone Mapping) для HDR-экранов требует определенных вычислительных ресурсов. В графических процессорах поколения Pascal эти задачи решаются силами CUDA-ядер и могут снижать быстродействие игр на несколько FPS. В новых чипах Chroma Subsampling и Tone Mapping выполняет специализированная логика и потери быстродействия практически устранены.
Вместе со стандартными выходами DisplayPort и HDMI все представленные видеокарты имеют контроллер USB 3.1 Gen 2, предназначенный для подключения шлемов виртуальной реальности нового стандарта VirtualLink. В принципе, спецификации USB 3.1 изначально допускают передачу сигнала DisplayPort в качестве одного из альтернативных режимов, но при использовании всех четырех линий DP пропускная способность USB ограничена возможностями версии 2.0. Режим DisplayLink, напротив, сохраняет скорость USB 3.1 Gen 2 для передачи иных типов данных. Минимальные требования к питанию устройств от порта USB Type-C в VirtualLink составляют 15 Вт мощности, но NVIDIA последовала опциональной рекомендации, обеспечив резерв в 27 Вт. И наконец, USB-порт на видеокарте можно использовать просто для подключения любых устройств с этим интерфейсом.

⇡#Промежуточные выводы
В результате подробного изучения архитектуры Turing и видеокарт семейства GeForce RTX 2080 Ti остается лишь повторить то, с чего мы начали эту статью. Похоже, NVIDIA и вправду удалось пусть не в одночасье поменять облик 3D-рендеринга в реальном времени, но, по крайней мере, обеспечить уверенный старт направлению, в котором пойдет дальнейшее развитие компьютерных игр. Теряет силу преобладающая парадигма рендеринга в реальном времени, которая зиждется на гибкой архитектуре множества программируемых вычислительных ядер. NVIDIA сделала ставку на принципиально иные алгоритмы, которые не могут обойтись без узкоспециализированного железа.
Дело не только в том, как трассировка лучей преображает графику, но и в том, что в долговременной перспективе борьба за сохранение закона Мура рано или поздно будет проиграна не только центральными процессорами, но и GPU. Переход к более эффективной архитектуре нужно совершить заранее, чтобы подготовиться к этому моменту. Ведь перемены такого масштаба не случаются быстро. Вспомните хотя бы, сколько лет понадобилось играм, чтобы начать использовать шейдеры. Но для трассировки лучей все сложилось как нельзя удачно. Новые процессоры обладают более чем достаточным быстродействием для таких задач и появились в условиях поддержки со стороны разработчиков API и игровых движков. А производителям других GPU и игровых консолей придется тоже рано или поздно объединиться с NVIDIA в развитии этих технологий.
Впрочем, не будем забывать, что большинство игр за время жизни семейства GeForce RTX 20 не смогут использовать его новые возможности, а цены передового железа NVIDIA как никогда высоки. Только тесты в реальных играх покажут, как GeForce GTX 2080 Ti справляется с вызовами сегодняшнего дня. Продолжение следует 19 сентября: не пропустите вторую, практическую часть этого обзора.


