L3VPN
Содержание
Routing (Control plane)
RD решает проблему с пересечением маршрутов между разными клиентами.
Если внутри RI будет все же указан RD, то для построения VPN будет использован более специфический RD (тот что внутри routing-instance).
RT решает проблему распространения маршрутов, задает топологию отдельного VPN. Имеет такую же структуру как и RD.
Определяет какому клиенту принадлежит префикс (routing-instance = routing-table конкретного клиента).
С помощью import policy либо явно заданного RT, можно принимать либо нет маршруты с определенным RT.
Рассмотрим такую схему:
В inet.0 хранятся IPv4, не получится туда залить наши префиксы, т.к. они имеют совсем другую структуру.
Под новые NLRI создается своя таблица: bgp.l3vpn.0. Префиксы хранятся вместе с RD. Таблица используется только на control plane, не для форвардинга.
Для форвардинга будет использоваться отдельная таблица для VRF. В ней префиксы будут храниться в обычном IPv4 формате. Для этого нужно убрать RD и разложить префиксы по нужным VRF. То есть в сети должен существовать некий идентификатор клиента.
С помощью RT можно для клиента обеспечить связность не только full mesh, но и более сложные топологии: 1 ко всем, 2 между собой, 3-й только с конкретным сайтом.
NLRI с RT прилетает на удаленный PE, префикс запихивается в нужный VRF, убирается RD, сохраняем префикс в виде IPv4. По настроенному протоколу PE<>CE передает префикс CE.
BGP: по дефолту передает только маршруты, полученные по BGP. Но с VRF другое поведение: если конфигурируем VRF и в VRF пишет target, а не policy, то роутер берет все маршруты из этого VRF, присоединяет к ним target, и отправляет по MP-BGP.
Когда проанонсированный префикс прилетает соседу (используя vpn family), тот: смотрит на target, ищет у себя target. Если VRF с таким target нет, то BGP-update отбрасывается (даже не попадают в hidden), он не знает в какую таблицу его запихнуть. Как проверить, что все-таки update прилетает: включить traceoptions. Т.е. на P роутере prefix клиента отбросится. Но до PE2 по iBGP все-равно анонс долетит, но будет скрытым (не отрезолвился next-hop, он не попал в inet.3). Если prefix все-таки не прилетает даже в hidden, то скорей всего проблема с RT.
Forwarding
Допустим, к CE1 подключено устройство с default route, пакет идет на CE1. CE1 по BGP передает трафик к PE1. На PE1 пакет попадает в vrf1.table.inet.0, т.к. на PE1 интерфейс в сторону CE1 добавлен в VRF клиента. Forwarding next-hop: P-router (по IGP). P-router принимает пакет и не знает что с ним дальше делать. Схема не рабочая
Будем туннелировать пакеты от PE1 (не обязательно в mpls). Но рассматриваем mpls.
Делаем так, чтобы PE2 понял, что lookup нужно производить внутри VRF. RT и RD не проканают, т.к. они существуют только на уровне control plane, и не причастны к передаче трафика.
Какой-нибудь header можем использовать как идентификатор, что нужно смотреть в определенной таблице. Берем MPLS заголовок.
На PE2 делается 2 lookup.
Такая схема будет работать только если включить vrf-table-label.
Cisco по дефолту назначает метки для prefix. Но это не очень удобно, когда от клиента приходит много префиксов и тем самым занимается ASIC для хранения всех этих меток.
When using network commands like ping, traceroute, and ssh, the routing-instance switch is used to specify the routing table that should be used to forward packets for the session. By default, the router will use the inet.O table not the VRF table.
By default, an egress PE that has an Ethernet VRF interface cannot perform both a pop of the MPLS label and an ARP for packets that come from the core. Therefore, an ARP must be performed by the egress router prior to receiving packet from the core. This can be achieved simply by receiving at least one route from the connected CE (which causes an ARP to occur to determine next hop). Also, a static route can be configured within the VRF instance that points to the connected CEo This is generally sufficient. However, if it is necessary to ping the VRF interface without adding routes to the VRF table, vrf-table-label or a VT interface can be used to allow for both a pop and ARP operation by the egress router.

Если вдруг вместо MPLS для форвардинга используется GRE, то:
VRF-import / VRF-export
Если требуется передача не всех маршрутов, а специфических маршрутов, то вместо vrf-target будем использовать vrf-import/vrf-export.
— export политика тоже должна иметь последний term: the reject. Лучше делать then community [target] add.
Сначала отработает VRF, потом BGP.
Для l2vpn в vrf-export нужно делать then community add [не set], потому что при настроенном set затрутся служебные L2-info extended community.
Либо можно использовать такой вариант, если нужны просто разные target на import и export:
Route-origin
По сути имеет только вид extended-community, но функционально не отличается от обычного. Обращаться с ним как с обычным!
Route-target filtering
Уменьшает кол-во служебного трафика. По сути удаленный PE->PE [или RR->PE] посылает только маршруты тех vrf, которые запрашивает локальный PE.
По дефолту на локальный PE приходят маршруты всех vrf на сети и устанавливаются в таблицы vrf только те, target которых есть на локальном роутере.
Используется таблица: bgp.rtarget.0. Предаются новые target NLRI вида: 200:200:102/96 = as:rt/mask
На локальном PE, где был создан vrf, сразу генерируется NLRI на основании vrf-import target. Остальные PE [или RR] узнают префиксы каких vrf слать этому PE.
Фильтрация включается на ibgp сессии между PE [или на ibgp c RR]. Ну понятно, что при включении новой family сессия флапает, так что осторожней!
Можно задавать дополнительные параметры:
PE_eBGP»> CE<>PE eBGP
В настройке особенностей нет, но возникают проблемы с AS.
У клиента одна и та же AS с двух сторон (AS 65000) => PE1 (AS 10) получает префикс с AS-path 65000 * => на PE2 сработает split horizing, и он не будет анонсировать CE2 => решаем проблему.
PE_OSPF»> CE<>PE OSPF
Общие сведения об OSPF
Внутренний порядок выбора маршрутов, до попадания в routing-table:
Sham-link
Если все это применить к L3VPN.
Делаем так, чтобы из PE2 VRF к клиенту вылетела LSA1. LSA1 содержит в себе линки, а мы при передаче от клиента к RI превратили эту информацию в маршруты, которые дальше стали анонсироваться по BGP. Из маршрутов линки обратно сделать не получится. Как исправить?
Обязательно нужно в policy (vrf-import, vrf-export) добавить адреса Lo. иначе ничего не заработает.
Все заработало, к CE2 улетел LSA1.
НО! произошло небольшое изменение: маршрут 10.0.0.1/32 прилетел на PE2 в RI, как известный по OSPF и был выбран активным.
НО! на удаленный PE2 обязательно должен прийти маршрут CE1, полученные по BGP (для форвардинга) и OSFP (для распространения LSA1). В итоге на удаленном PE в vrf.inet.0 должны быть hidden маршруты, изученные по ospf.
— Если используем policy, то нужно не забыть, что OSPF маршрут нужно отправить по BGP на удаленный PE.
Sham-link годится только в случае, когда объединяются роутеры клиента в одной area и когда критично принимать именно LSA1, как было бы без вмешательства ISP.
Configuration
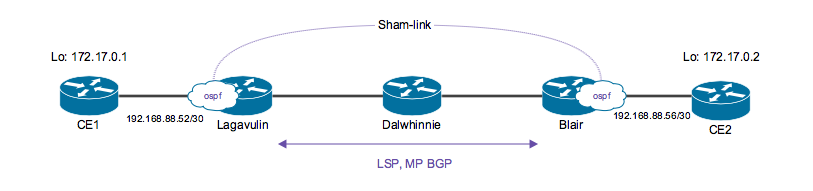
Со стороны удаленного РЕ конфиг аналочигный.
при использовании policy для vrf:
Также, если рассматривать топологию ospf домена клиента в целом, то наверняка между различными site, клиентские роутеры будут подключены не только через нашу сеть, но буду иметь дополнительные резервные/основные линки. Таким образом, клиент может попросить сделать линк через нашу сеть резервным/основным. Сделать это можно с помощью регулирования ospf-метрики на shamlink.
Проверка
До включения sham-link
После включения sham-link
т.к. соседство по OSPF должно быть внутри одной area, то shamlink не поднимется.
Domain ID
OSPF Domain ID используется, когда передаются маршруты между одинаковыми или разными доменами через MPLS сеть. Domain ID передается как extended community внутри MP-BGP вместе с OSPF route-type и OSPF router ID community.
Фича позволяет передавать на удаленный конец LSA1, LSA2, LSA3 как LSA3.
Также передаются LSA5, LSA7 как LSA5.
Stub и totally-stubby не поддерживают такую фичу.
Вводится правило трансляции типов LSA:
Как удаленный PE узнает что было с другой стороны?
BGP использует следующие extended community:
Генерируется автоматически. Когда iBGP передает OSPF маршрут, роутер смотрит как исходно пришел маршрут, создает для него соответствующее community, куда записывает тип LSA.
Удаленный PE смотрит тип, применяет правило трансляции.
Если Domain ID не задан с обоих концов в VRF, то это тоже является совпадением по Domain ID.
PE при передаче CE LSA также помечает из route tag. Пример: tag 3489662039. Рассчитывается автоматически, но можно и задать вручную.
Configuration
LSA3 дойдет до CE2 (area1), но ABR не отправит LSA3 в area0, т.к. это backbone area (splithorizing). Поднимаем virtual-link.
При использовании IS-IS все проще: редистрибьюция из BGP в ISIS. В любом случае в ISIS получим внешний маршрут.
PE_IPv6″> CE<>PE IPv6
на ядре MPLS на IPv4.
Нужно передавать ipv6 трафик.
Будут использоваться таблицы:
Exchanging routes between VRF tables
Если нам требуется передать маршруты из одного VRF в другой, в рамках одного маршрутизатора, можно осуществить такое двумя способами:
Либо если vrf-export одного instance будет совпадать c vrf-import другого instance.
Короче, в этом методе обмен маршрутов происходит только при совпадении targets, т.е. делается на per-table основе. Передаются ВСЕ маршруты.
Работает только на локальном роутере (не передается по MP-BGP). Правда если для route leaking править vrf-export политику (добавляя туда еще community таблицы, в которую будут передаваться маршруты) то маршрут улетит и на другие PE для этого vrf. В общем, если нужен обмен только на локальном PE через auto-export, то правь именно vrf-import политику в нужных vrf.
Последним термом в таких политиках должен быть then reject.
При подобной настройке: будут передаваться только интерфейсные маршруты.
Если требуется копировать статические маршруты, то rib-group добавляем в:
Если требуется копировать протоколы маршрутизации, то rib-group добавляем в:
[тут речь идет только от клиентов, включенных по тому или иному протоколу, НО не про маршруты, полученные по MP-BGP от RR]
Если требуется копировать маршруты, известные по протоколам маршрутизации, то потребуется также скопировать и direct маршруты, для резолвинга.
С помощью policy можно контролировать какими маршрутами обмениваться.
Hub-and-spoke
Смысл: spoke-spoke связь идет не напрямую, а обязательно проходит через hub.
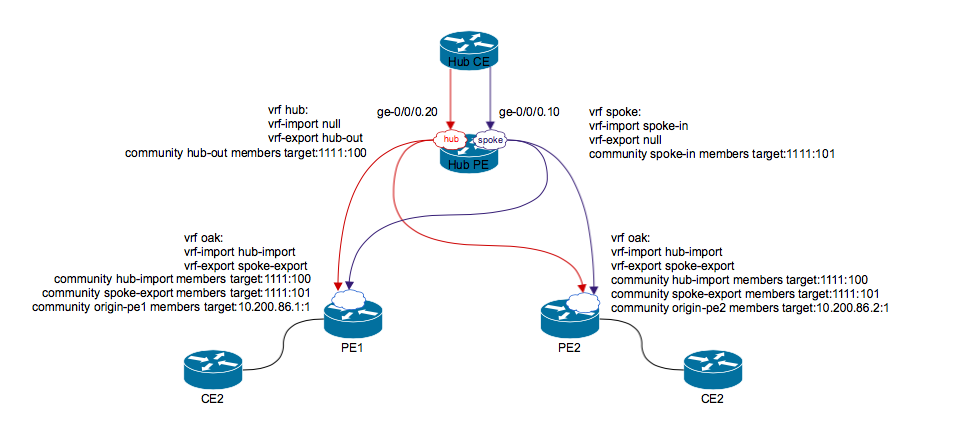
Как и для обычного L3VPN нужно решать проблему с AS path loop detection (as-override, remove-private).
Или при использовании OSPF между CE <> PE следить за правильностью Domain ID.
Могут возникнуть сложности, если в топологии будут spoke, подключенные напрямую к hub. Или к PE будет подключаться несколько spoke.
Требуется создание двух RI: hub, spoke. Hub PE будет иметь 2 линка в сторону CE (можно 2 unit на физическом линке).
2 RT, 2 RD (если в схеме используем RR).
Control plane: маршруты от spoke PE передаются в spoke vrf на hub PE. Hub PE передает маршруты hub CE. Hub CE в свою очередь передает эти маршруты в hub instance hub PE. Hub PE передает маршруты к Spoke site.
На ingress доступны: firewall filtering, classification, rate limiting, precedence mapping.
На egress можно использовать: filtering, но дополнительно добавив vrf-table-label, vt-interface.
EXP bits в VRF метке выставляются на основании: firewall classification, IP precedence, ingress interface.
outer label (RSVP), может быть назначена CoS конфигурацией.
Internet Access
Option 1
PE роутеры не участвуют в роутинге интернета, т.е. PE роутеры не обмениваются маршрутами между master и vrf таблицами маршрутизации. Предоставление интернета в рамках опции 1 называется «non-VRF Internet Access».
Настраиваются политики на PE + static route [в routing-instance routing-options] с next-hop table inet.0. Оттуда уже резолвиться в инет.
Option 1.1
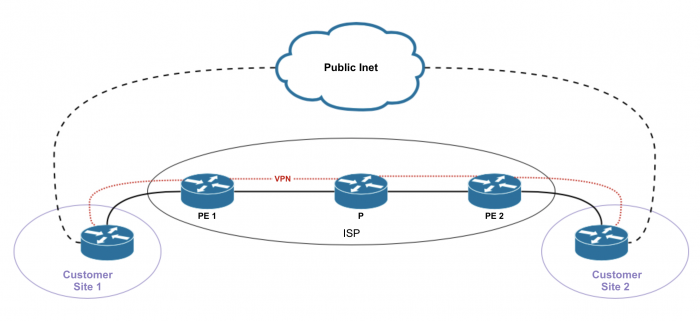
«Пусть строят как хотят». VPN-клиенты не получают интернет от провайдера VPN-услуг, а подключают в каждой локации IPS1 или ISP2 в отдельный маршрутизатор, и далее разруливают трафик как хотят. В каждой локации свой интернет.
По-умолчанию Juniper поддерживает именно эту опцию.
Option 1.2
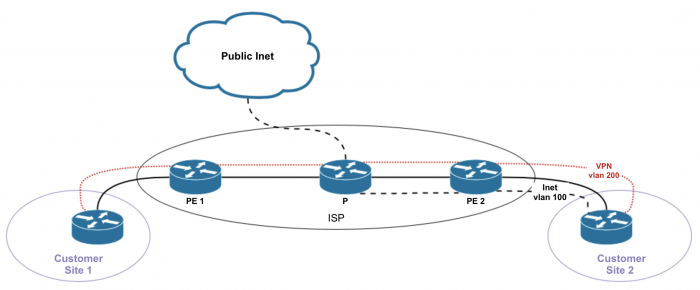
В отдельном влане (CE-PE) идет L2 по провайдерской сети до провайдерского роутера, который раздает интернет. Можно вообще отдельным кабелем воткнуться между CE и PE. Сам PE ничего не знает про интернет и не обязан хранить маршруты в интернет, либо маршруты клиента, чтобы маршрутизировать что-либо в ту или иную сторону. В Juniper для этого предусмотрено либо L2VPN либо CCC.
Все VPN-ы, подключенные к данному PE пойдут в интернет одинаковым путем.
Option 2
PE имеет частичный или полный доступ в инет. РЕ будет перемещать маршруты между VRF и main instance.
Option 2.1
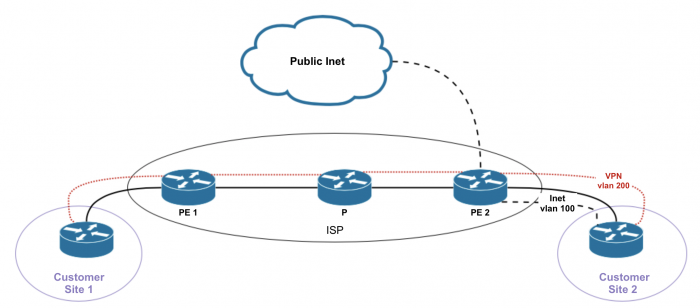
Option 2.2
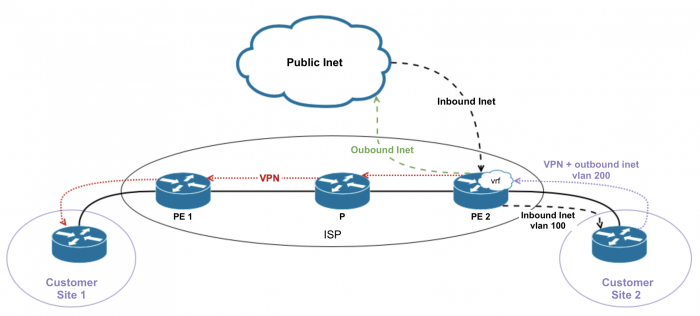
«Отдельный интерфейс для обратного (который идет от Интернета к клиенту) трафика».
Option 2.3
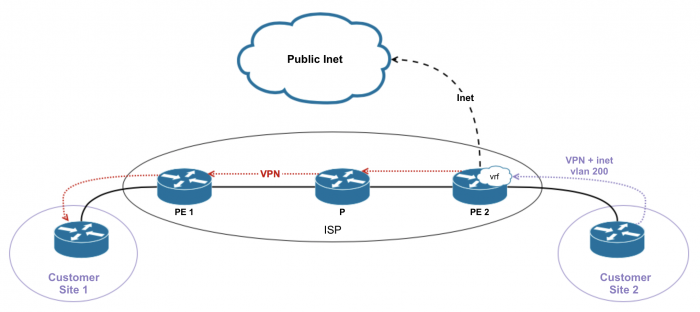
«Все через одну дырку (Single VRF for VPN and Internet Access)».
Отдельного интерфейса не требуется. Опять же, не-ВПН трафик клиента будет лукапиться в master-е и маршрутизироваться по тамошним маршрутам в интернет. А чтобы схема работала и в обратную сторону, все клиентские анонсы будут редистрибьюированы в master.
Если клиент не использует приватные адреса, то VPN и inet связность может быть достигнута с помощью одного VRF и с помощью копирования всех маршрутов из VRF в main instance (RIB-groups).
Если клиент использует приватную и публичную адресацию, то паблик и приватные будут разделяться разными community.
Option 3
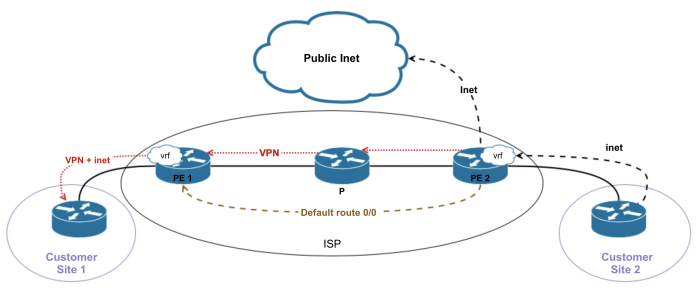
у Hub-PE в рамках vrf настраивается default, смотрящий в сторону ce-vpn. Дефолт анонсится остальным PE.
Если клиенту требуется NAT, то при такой схеме NAT делается на CE.
Разница между Route Distinguisher и Route Target
Когда-то, начиная изучать MPLS и реализуемые на его основе сервисы, я уперся в два понятия — Route Target и Route Distinguisher. Информация по этим понятиям была в основном на английском языке (спасибо родителям за то что заставляли меня учить английский), на русском был или машинный перевод или общая информация, которая порождала больше вопросов, чем давала ответов.
В статье буду использовать выводы с оборудования Juniper, так как испытываю большую симпатию к оборудованию данного производителя, нежели к Cisco, Huawei или Broсade. Статья написана полностью мной и не является переводом, дампы трафика и выводы с оборудования взяты с собранного в GNS3 стенда (для эмуляции использовал; vSRX, Cisco IOS-XR (vXR) и IOS).
Для того что бы перейти к пониманию назначения Route Target и Route Distinguisher, надо понять, что такое VRF, так как часть сетевых инженеров полностью не понимают принцип работы VRF (для некоторых даже открытием является то, что VRF используется и без MPLS).
Итак VRF — это не маршрутизатор в маршрутизаторе, а всего лишь изоляция таблицы маршрутизации одного клиента от другого и от основной таблицы маршрутизации роутера — это надо твердо усвоить (маршрутизатор в маршрутизаторе — это например logical systems в JunOS). По сути можно провести аналогию с VLAN — между различными VLAN пакеты напрямую не передаются (между VLAN пакеты должны идти через маршрутизируемый интерфейс), так же и два VRF, живущих на одном маршрутизаторе не могут общаться друг с другом без перераспределения маршрутов, так как их таблицы маршрутизации не имеют маршрутов к друг другу.
Теперь мы можем перейти к основной теме статьи. Начнем с Route Destingisher (дословно различитель маршрутов). Route Distinguisher представляет из себя 64-битную последовательность вида type (2 байта):administrator(2 или 4 байта):value(4 или 2 байта). Поле type указывает в каком формате будут следующие два поля, значения которых указаны ниже:

Что бы понять назначение RD, разберем топологию ниже:

К PE-маршрутизатору подключены два клиента, но есть проблема — оба клиента имеют одно и то же приватное адресное пространство — 10.0.0.0/24. Предположим что между CE1 и PE запущен OSPF, а между CE2 и PE — RIP. На PE нам необходимо сделать перераспределение маршрутов из IGP протоколов в BGP, что бы передать маршруты клиентов на другие PE-маршрутизаторы. Для BGP это один и тот же префикс 10.0.0.0/24, поэтому перераспределен и анонсирован соседям по BGP будет только один лучший маршрут. Но нам то надо анонсировать оба маршрута. Вот тут нам на помощь приходит Route Distinguisher. Его единственной, но очень важной задачей является сделать заведомо не уникальный префикс уникальным. Получается это с помощью добавления 64-битного Route Distinguisher к искомому префиксу:
К примеру, имея два одинаковых префикса 192.168.1.0/24 и Route Distinguisher 100:10 и 100:20, получаем уникальные VPNv4 unicast префиксы, длинной 96 бит.
Теперь эти префиксы можно передать другим PE маршрутизаторам. Но один из моих коллег задал вот такой вопрос: как PE маршрутизатор выделяет IPv4 префикс из полученного VPNv4 префикса, если не знает значение Route Distinguisher. Тут все просто, рассмотрим BGP Update message. Для начала посмотрим, как передается обычный IPv4 префикс:
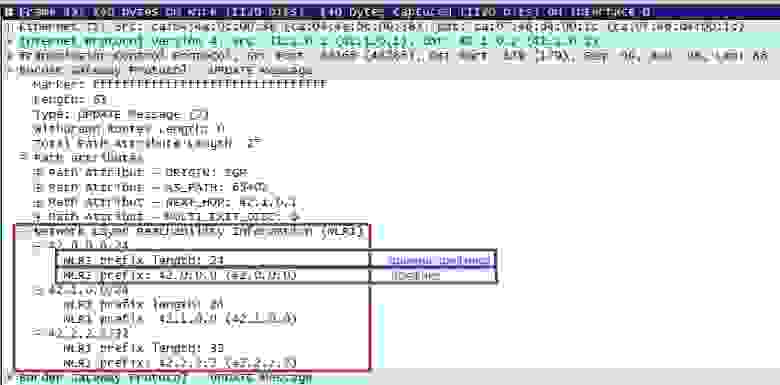
Как видно из BGP анонса, в теле сообщения в поле NLRI и находится префикс. С помощью расширения MP-BGP, данный протокол может обеспечивать обмен префиксами различных address family идентифицируя их различными значениями AFI/SAFI. Рассмотрим Update message, в котором будет содержаться VPNv4 префикс:
Так как маршрутизатор знает длину Route Distinguisher (она фиксирована и равна 64 битам) и начало VPNv4 префикса, то ему не составляет труда отбросить значение первых 64-х бит и поместить в таблицу маршрутизации клиента только IPv4 префикс:
Думаю, что с Route Distinguisher мы разобрались, поэтому перейдем к обсуждению Route Target.
Ниже показан вывод марштутов, анонсируемых по протоколу BGP, к которым прикреплены расширенные community:
Route Target делятся на два значения import и export. Первое предназначено для фильтрации префиксов PE маршрутизатором на приеме. Принятые префиксы в последствии будут установлены в таблицу маршрутизации соответствующего VRF ( как RT import может быть указано более одного значения, в случае его отсутствия ни одни из маршрутов не будет принят и установлен в таблицу маршрутизации). Что бы можно было на приеме произвести фильтрацию на основании community, надо, чтобы это community кто то добавил к анонсу. Для этого и используется Route Target export, значение которого будет добавлено как расширенное community к BGP анонсу (в случае отсутствия в конфигурации VRF данного занчения ни один из маршрутов данного VRF не будет передан на другие PE маршрутизаторы).
Теперь, понимая различи между этими понятиями расставим все точки над i. Рассмотрим схему:
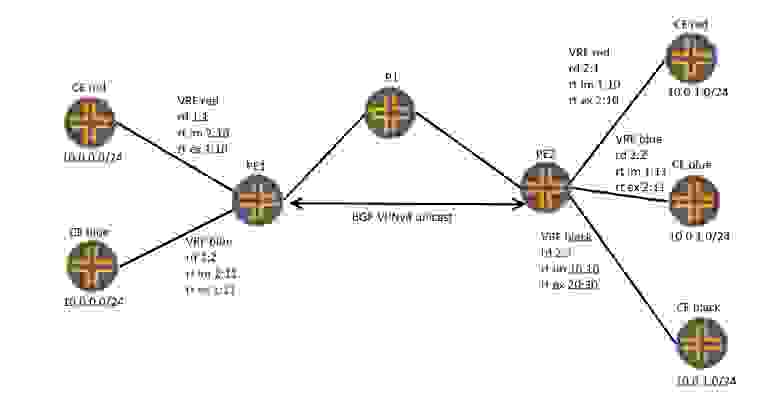
На схеме два PE маршрутизатора, между которыми установлена BGP сессия с address family vpnv4 unicast. На первом PE1 маршрутизаторе два VRF: red и blue, на PE2 три VRF: red, blue и black. Как видно, все сайты имеют одинаковое адресное пространство, но так как у нас сконфигурированы уникальные для данной сети RD, все префиксы становятся уникальными. Теперь надо понять, какие маршруты принимают и отдают PE маршрутизаторы.
PE1 имеет два VRF, согласно RT import, он должен принимать все BGP анонсы с расширенными community 2:10 и 2:11, а так же отправлять BGP анонсы с расширенными community 1:10 и 1:11 согласно RT export. Маршруты с расширенными community, не соответствующие сконфигурированным RT-import, маршрутизатор просто отбрасывает. Маршруты с RT import 2:10 маршрутизатор помещает в таблицу маршрутизации клиента red, а с RT 2:11 — в таблицу маршрутизации клиента blue. Оправляя маршруты клиента red, маршрутизатор «навешивает» на анонс расширенное community 1:10, и соответственно для анонсов клиента blue — 1:11.
PE2 имеет три VRF, и согласно RT import он принимает BGP анонсы с расширенными community 1:10, 1:11 и 10:10, и отправляет BGP анонсы с расширенными community 2:10, 2:11 и 20:30.
Так как на PE1 не сконфигурирован VRF black, то маршруты данного клиента ему не нужны, а значит, получая маршрут с расширенными community 20:30, PE1 их просто отбрасывает на основании того, что указанное в анонсе расширенное community не задано для данного маршрутизатора.
Бывает случаи, когда необходимо принимать маршруты со всеми расширенными community (например interAS-option B). При настройке маршрутизатора необходимо разрешить принимать все анонсы, так как это не дефолтное поведение маршрутизатора. Если маршрутизатор сконфигурирован как route-reflector, то он принимает и отдает все анонсы в не зависимости от расширенных community. Кроме того сам PE маршрутизатор может ограничить получаемые анонсы от других PE маршрутизаторов или роут-рефлекторов, тем самым уменьшая количество сигнальной информации. Но это уже тема другой статьи.
Спасибо за внимание! Надеюсь, я смог донести данную до читателя разницу между двумя этими с виду идентичными, но абсолютно разными по назначению понятиями.
Присутствие Route Target в BGP-анонсах между PE и CE
Статья предполагает, что у читателя уже есть понимание основ MPLS L3VPN.
Вернемся к вопросу о том, что может произойти, если CE будет анонсировать на PE маршруты, помеченные RT (BGP-политики на PE отсутствуют). Немного подумав можно предположить, что существуют 3 различных исхода:
Но довольно предполагать, давайте проверять. Для большего интереса проверять будем сразу на нескольких Network OS. В Eve-NG была собрана вот такая схема:
Список участников тестирования:
Анонсы CE->PE
Итак, эксперимент прост: с CE анонсируем маршруты, помеченные RT:65001:200, на Remote-PE смотрим, появятся ли эти маршруты в таблице маршрутизации VRF-200.
Для начала проверим таблицу маршрутизации VRF-100:
Нам пришли маршруты от всех 5 PE. Теперь проверим, попали ли какие-то из этих маршрутов в VRF-200:
Маршруты от CHR, vMX и VSR попали в VRF-200. Это означает, что добавленное на CE комьюнити RT:65001:200 было сохранено этими PE.
В это же время маршруты от XRv и 3725 есть только в VRF-100. Это означает, что циско-роутеры удалили комьюнити RT:65001:200 из анонса.
Анонсы PE->CE
Не будем останавливаться на достигнутом и проверим, как ведут себя анонсы в обратную сторону, т.е. от PE к CE. Немного изменим существующие конфигурации.
На Remote_PE создадим loopback, адрес которого 100.100.100.100/32 проанонсируем другим PE:
На vMX вспомним, что MPLS-транспорт мы не настраивали, а значит таблица inet.3 пустая, и маршрут от Remote_PE попадет в hidden. Скопируем маршруты OSPF в inet.3.
На остальных роутерах текущих настроек должно быть достаточно.
Смотрим маршруты на CE:
Все роутеры, кроме Cisco, оставили Route Target в анонсе маршрута. Cisco этого не сделали только по причине того, что на них по умолчанию выключена отправка любых community. Исправим это.
3725:*
*Применение данных команд никак не меняет результаты первого опыта с CE->PE анонсами.
Теперь смотрим маршрут на CE еще раз:
Теперь абсолютно все PE посылают в сторону CE маршруты с указанием RT.
Подобный результат лично мне показался несколько странным. Если сохранению RT в анонсе CE->PE теоретически можно придумать применение, то вот в анонсе PE->CE RT выглядит как явно лишняя информация.
Кроме того, существование явлений сохранения RT как в сторону CE->PE, так и в сторону PE->CE, потенциально может оказать негативное влияние на сценарии Inter-AS Option A.
Рубрика «Что нам говорит RFC»
If the PE and the CE are themselves BGP peers, then
the SP may allow the customer, within limits, to specify how its
routes are to be distributed. The SP and the customer would need to
agree in advance on the set of RTs that are allowed to be attached to
the customer’s VPN routes. The CE could then attach one or more of
those RTs to each IP route that it distributes to the PE. This gives
the customer the freedom to specify in real time, within agreed-upon
limits, its route distribution policies. If the CE is allowed to
attach RTs to its routes, the PE MUST filter out all routes that
contain RTs that the customer is not allowed to use. If the CE is
not allowed to attach RTs to its routes, but does so anyway, the PE
MUST remove the RT before converting the customer’s route to a VPN-
IPv4 route.
Таким образом, сохранение RT в анонсах CE->PE имеет под собой вполне легальную основу, хоть практическое применение подобного и кажется лично мне несколько сомнительным.
Про RT в анонсах PE->CE в RFC ничего не сказано.
Убираем RT из сессий с CE
С Циско все понятно заранее. В анонсах CE->PE все RT удаляются безапелляционно (мне не удалось найти команды, которая бы изменила это поведение), в PE->CE анонсах RT отсутствует по умолчанию, достаточно не включать отправку расширенных комьюнити.
Разберемся, как избавиться от RT на других участниках нашего тестирования.
Juniper
Все, что нужно сделать, чтобы удалить RT из анонсов (как PE->CE, так и CE->PE), так это составить политику и самым первым термом удалить все комьюнити, начинающиеся с «target:», отдав при этом префикс на обработку следующими термами.
Например, если мы хотим принимать и анонсировать все маршруты, просто удаляя из них RT:
Nokia
Для отключения отправки расширенных комьюнити BGP-пиру можно воспользоваться командой:
Для того, чтобы убрать RT из анонсов от CE, нужно создать политику аналогичному тому, как это было сделано в Juniper, и применить ее к сессии с CE.
Mikrotik
А вот с Микротиком нас ждет разочарование. Механизма, позволяющего удалить RT из анонса, просто нет. Казалось бы, в routing filter есть параметр set-route-targets, и сделать бы что-то типа
но, к сожалению, set-route-targets=»» означает, что данный параметр (set-route-targets) нужно вовсе убрать из правила. Пример:
В данном случае все же стоит помнить, что Mikrotik — в первую очередь продвинутый SOHO-роутер, и требовать от него того же функционала, что есть в маршрутизаторе Carrier-класса, наверное, не совсем правильно. Остается уповать на RouterOS 7.
Выводы
Добавляя нужный RT к своим анонсам, ваш клиент все же не сможет получить доступ в ваш MGMT VRF, например, т.к. связность будет односторонней. Тем не менее, нарушить работу маршрутизации в MGMT VRF клиенту вполне под силу (конечно, для этого нужно угадать с RT и с анонсируемыми маршрутами).
Кроме этого, при реализации Inter-AS Option A возможна ситуация, когда маршрут от провайдера A попадет в сеть провайдера B, сохранив свой RT. При этом если в сети провайдера B данный RT уже используется под какой-то другой VRF, маршрут утечет в этот VRF, что, конечно же, не является желаемым поведением.
Таким образом, проблема не являются уж слишком значительной, т.к. для того, чтобы она «выстрелила», должно совпасть вместе несколько факторов. С другой стороны, исправить данное нежелательное поведение гораздо проще, чем потом разбираться, почему вдруг «не работает».
Итак, еще раз, очень кратко:
1. По возможности вырезайте RT из анонсов между PE и CE (если, конечно, у вас нет в них необходимости).
2. Судя по результатам тестов, владельцы циско-PE могут спать спокойно, у них RT вырезается на автомате. Однако, я бы на всякий случай перепроверил. Возможно, в других версиях IOS поведение отличается.


