ROLLBACK TRANSACTION (Transact-SQL)
Откатывает явные или неявные транзакции до начала или до точки сохранения транзакции. ROLLBACK TRANSACTION можно использовать для отмены всех изменений данных, произведенных с начала транзакции или до точки сохранения. Она также освобождает ресурсы, используемые транзакцией.
Сюда не входят изменения, внесенные в локальные или табличные переменные. Они не удаляются с помощью этой инструкции.
 Синтаксические обозначения в Transact-SQL
Синтаксические обозначения в Transact-SQL
Синтаксис
Ссылки на описание синтаксиса Transact-SQL для SQL Server 2014 и более ранних версий, см. в статье Документация по предыдущим версиям.
Аргументы
transaction_name
Имя, присвоенное транзакции в BEGIN TRANSACTION. Аргумент transaction_name должен соответствовать правилам для идентификаторов, однако используются только первые 32 символа имени транзакции. При вложении транзакций аргумент transaction_name должен быть именем транзакции из самой внешней инструкции BEGIN TRANSACTION. Аргумент transaction_name всегда учитывает регистр, даже если экземпляр SQL Server регистр не учитывает.
@ tran_name_variable
Имя определенной пользователем переменной, содержащей допустимое имя транзакции. Переменная должна быть объявлена с типом данных char, varchar, nchar или nvarchar.
savepoint_name
Аргумент savepoint_name из инструкции SAVE TRANSACTION. Аргумент savepoint_name должен соответствовать требованиям, предъявляемым к идентификаторам. Используйте аргумент savepoint_name, если откат по условию должен влиять только на часть транзакции.
@ savepoint_variable
Имя пользовательской переменной, содержащей допустимое имя точки сохранения. Переменная должна быть объявлена с типом данных char, varchar, nchar или nvarchar.
Обработка ошибок
Инструкция ROLLBACK TRANSACTION не выдает никаких сообщений пользователю. Если нужны предупреждения в хранимой процедуре или триггере, используйте инструкции RAISERROR или PRINT. Инструкция RAISERROR предпочтительна для отображения ошибок.
Общие замечания
Инструкция ROLLBACK TRANSACTION без аргумента savepoint_name или transaction_name откатывает изменения на начало транзакции. При наличии вложенных транзакций эта инструкция откатывает все внутренние транзакции к началу самой внешней инструкции BEGIN TRANSACTION. В обоих случаях инструкция ROLLBACK TRANSACTION уменьшает системную функцию @@TRANCOUNT до 0. Инструкция ROLLBACK TRANSACTION savepoint_name не уменьшает @@TRANCOUNT.
Инструкция ROLLBACK TRANSACTION не может ссылаться на аргумент savepoint_name в распределенных транзакциях, запущенных явно с помощью инструкции BEGIN DISTRIBUTED TRANSACTION или вызванных из локальной транзакции.
Нельзя выполнить откат транзакции после выполнения инструкции COMMIT TRANSACTION, кроме случая, когда инструкция COMMIT TRANSACTION связана с вложенной транзакцией, которая содержится внутри откатываемой транзакции. В этом случае будет выполнен откат вложенной транзакции, даже если для нее была выполнена инструкция COMMIT TRANSACTION.
Внутри транзакции допускается использование повторяющихся имен точки сохранения, но инструкция ROLLBACK TRANSACTION, использующая повторяющееся имя точки сохранения, откатывает транзакцию лишь к самой последней точке, установленной с помощью инструкции SAVE TRANSACTION для этого имени.
Совместимость
В хранимых процедурах инструкция ROLLBACK TRANSACTION без аргументов savepoint_name или transaction_name откатывает все инструкции к самой внешней инструкции BEGIN TRANSACTION. Вызов инструкции ROLLBACK TRANSACTION в хранимой процедуре является причиной того, что значение @@TRANCOUNT после завершения хранимой процедуры отличается от значения @@TRANCOUNT при выдаче хранимой процедурой информационного сообщения. Это сообщение не влияет на последующую обработку.
Если инструкция ROLLBACK TRANSACTION запускается в триггере, происходит следующее:
Все изменения данных, сделанные к настоящему времени в текущей базе данных, откатываются, включая изменения, сделанные триггером.
Триггер продолжает выполнять все оставшиеся инструкции после инструкции ROLLBACK. Если какая-нибудь из инструкций изменит данные, откат этих изменений выполнен не будет. Вложенные триггеры не выполняются при выполнении оставшихся инструкций.
Инструкции в пакете, следующие за инструкцией, вызвавшей срабатывание триггера, не выполняются.
Значение @@TRANCOUNT увеличивается на единицу при срабатывании триггера даже в режиме автоматической фиксации. (Система обрабатывает триггер как неявную вложенную транзакцию.)
Инструкция ROLLBACK TRANSACTION в хранимой процедуре не влияет на последующие инструкции в пакете, вызвавшем процедуру; последующие инструкции в пакете выполняются. Инструкции ROLLBACK TRANSACTION в триггерах уничтожают пакет, содержащий инструкцию, вызвавшую триггер; последующие инструкции в пакете не выполняются.
Эффект, оказываемый инструкцией ROLLBACK на курсоры, определяется тремя правилами:
Если параметр CURSOR_CLOSE_ON_COMMIT установлен в ON, инструкция ROLLBACK закрывает, но не освобождает все открытые курсоры.
Если параметр CURSOR_CLOSE_ON_COMMIT установлен в OFF, инструкция ROLLBACK не влияет на открытые синхронные курсоры типа STATIC или INSENSITIVE или асинхронные курсоры типа STATIC, которые были полностью заполнены. Открытые курсоры любого другого типа закрываются, но не освобождаются.
Ошибка, которая уничтожает пакет и формирует внутренний откат, освобождает все курсоры, которые были объявлены в пакете, содержащем ошибочную инструкцию. Все курсоры освобождаются в зависимости от их типа или установок параметра CURSOR_CLOSE_ON_COMMIT. Это относится и к курсорам, объявленным в хранимых процедурах, вызываемых ошибочным пакетом. Курсоры, объявленные в пакете перед ошибочным, подчиняются правилам 1 и 2. Ошибка взаимоблокировки является примером ошибки такого типа. Инструкция ROLLBACK в триггере также автоматически формирует этот тип ошибки.
Режим блокировки
Инструкция ROLLBACK TRANSACTION с параметром savepoint_name освобождает все блокировки, полученные после точки сохранения, за исключением укрупненных блокировок и блокировок преобразования. Такие блокировки не освобождаются и не переводятся в прежний режим.
Разрешения
Необходимо быть членом роли public.
Примеры
В следующем примере демонстрируется эффект отката именованной транзакции: После создания таблицы следующие инструкции запускают именованную транзакцию, вставляют две строки и откатывают транзакцию, именованную в переменной @TransactionName. Другой оператор вне именованной транзакции вставляет две строки. Запрос возвращает результаты предыдущих инструкций.
Система управления базами данных SQLite. Изучаем язык запросов SQL и реляционные базы данных на примере библиотекой SQLite3. Курс для начинающих.
Часть 9.3: Команда ROLLBACK в базах данных SQLite (оператор ROLLBACK в SQLite3)
Привет, посетитель сайта ZametkiNaPolyah.ru! Продолжаем изучать базы данных и наше знакомство с библиотекой SQLite3. При разработке приложений, которые работают с базами данных и транзакциями, вы неизбежно будете сталкиваться с ситуациями, когда появляется необходимость не применять изменения, которые были совершены во время транзакции. Причины такому поведению могут быть разными: от банальной ошибки ввода данных оператором до каких-либо технических перебоев на удаленных узлах, которые работают с распределенной базой данных. Для таких ситуаций и была придумана команда ROLLBACK TRANSACTION, которая говорит СУБД о том, что изменения базы данных внутри транзакции применять не стоит.
![]()
Команда ROLLBACK в базах данных SQLite (оператор ROLLBACK в SQLite3)
Из этой статьи ты узнаешь о том, как реализован оператор ROLLBACK TRANSACTION в базах данных SQLite. Мы поговорим о синтаксисе команды ROLLBACK в SQLite3, посмотрим пример использования ROLLBACK, а так же поговорим о некоторых технических моментах использования команды ROLLBACK TRANSACTION в SQLite3.
Команда ROLLBACK в базах данных SQLite (оператор ROLLBACK в SQLite3)
Рассмотрим третью команду из группы управления транзакциями – команду ROLLBACK TRANSACTION. Команда ROLLBACK TRANSACTION в базах данных SQLite используется для отмены запросов, введенных после команды BEGIN. Если команда COMMIT подтверждает изменения, то оператор ROLLBACK TRANSACTION их откатывает и завершает транзакцию. Давайте посмотрим на синтаксис команды ROLLBACK в базах данных SQLite3.
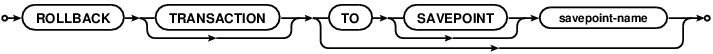
Синтаксис команды ROLLBACK TRANSACTION в SQLite. Синтаксис оператора ROLLBACK TRANSACTION в базах данных SQLite3
Синтаксис оператора ROLLBACK в SQLite3 очень прост: сначала идет ключевое слово ROLLBACK, а затем идет ключевое слово TRANSACTION, которое можно не писать. Сейчас не обращайте внимание на SAVEPOINT, на мой взгляд это отдельная конструкция, которую мы рассмотрим в следующей записи. Давайте рассмотрим пример использования команды ROLLBACK TRANSACTION в SQLite.
Пример использования оператора ROLLBACK TRANSACTION в SQLite3
Для примера использования оператора ROLLBACK TRANSACTION в SQLite3 будем использовать демонстрационную базу данных World.db3. Совет: если вы самостоятельно будете повторять пример ROLLBACK TRANSACTION в SQLite, то выполняйте все команды по очереди, а не копируйте весь листинг целиком.
А теперь давайте убедимся в том, что оператор ROLLBACK TRANSACTION сработал и мы не внесли никаких изменений в таблицу базы данных SQLite3. Для этого мы выведем записи со второй по одиннадцатую командой SELECT:
Обратите внимание: иногда я использую слово оператор, вместо слова команда, это не совсем правильно с формальной точки зрения, так как SQL операторы не являются командами, так же часто вы можете услышать словосочетание SQL запрос, когда на самом деле человек говорит про SQL предложение. Пока вы не выполните команду ROLLBACK, SQLite3 не завершит транзакцию и не отменит изменения, внесенные данной транзакцией. Как только вы сказали SQLite ROLLBACK, все изменения будут отменены, а транзакция завершена.
Не важно какие команды выполнялись внутри транзакции, команда ROLLBACK TRANSACTION отменит любые. Вы создали базу данных командой CREATE или вы добавили несколько строк в таблицу командой INSERT, да даже если вы удалили таблицу командой DROP. ROLLBACK TRANSACTION вернет базу данных к тому состоянию, в каком она была до транзакции.
Так же важно понимать, что если вы завершите транзакцию командой COMMIT, то оператор ROLLBACK вам уже не поможет, так как изменения были подтверждены. Обычно приложения, использующие базы данных и транзакции, принимают решения о том, как завершить транзакцию на основе действий пользователя или каких-либо внешних факторов, например, вы совершаете платеж картой в магазине, и тут неожиданно гаснет свет и терминал отключается: в этом случае деньги магазину переведены не будут, а вы не сможете забрать товар, так как его не оплатили.
Как работает rollback в базах данных
Всем привет, меня зовут Артём и я алкоголик долгое время не понимал базы данных. Ну, то есть я понимал концепт и как с ними работать, но всегда воспринимал их как чёрный ящик с понятным интерфейсом, который может сохранять и отдавать данные, если знать, как его об этом попросить. Механизмы, позволяющие магии случаться, были совершенно не понятны. И честно говоря, меня это особо не волновало. Бизнесу нужно, чтобы ты фичи фигачил, а не вот это вот всё.
Однако недавно я понял, что хватит это терпеть и настало время разобраться что происходит под капотом, как это происходит и зачем. Статья подойдёт тем, кто каждый день работает с базами данных и не особо вникает в подробности, людям, кто как и я заинтересовался тем, как всё работает и не знает откуда начать копать или просто тем, кто хочет немного освежить своё понимание баз данных.
Всё началось с того, что я задался вопросом, а как чёрт подери работает rollback, когда в результате работы моего воспалённого сознания получается такой код, который генерирует в базу кривые запросы и она вынуждена что-то делать, чтобы всё окончательно не сломалось? Прежде чем начинать копать в сторону механизма отката изменений, нужно понять что это вообще такое и зачем вообще оно нужно. И тут в игру вступает такая волшебная аббривиатура как ACID.
Так что же значит ACID? ACID это набор характеристик, которым должна соответствовать наша программа, чтобы считаться кошерным местом для хранения данных. Попробую в двух словах рассказать о каждой букве в аббривиатуре (ведь это не про кислоту в берлинских клубах):
A значит Atomicity — транзакция работает как единая команда и либо выполняется целиком, либо не выполняется вообще
С значит Consistency — по завершению транзакции данные не должны быть испорчены (такая противная штука как data corruption) или потеряны
I значит Isolation — по сути означает, что транзакции не должны пересекаться друг с другом. То есть если одна транзакция уже начала работу с данными, то следующая транзакция должна дождаться завершения предыдущей для того, чтобы начать выполнение операций с этими данными
D значит Durability — гарантия того, что по завершению транзакции данные будут сохранены и не подвержены риску потери. Тут нужно понимать, что это не только про программные ошибки, но и про потопы, цунами, отключения электричества и прочие ЧП
Однако тут стоит отметить, что не каждая база данных обладает всеми свойствами ACID и часто это осознанный выбор (а бывает и нет), направленный в сторону того, чтобы пожертвовать одними свойствами системы ради других.

Если сильно упростить, то при проектировании хранилища мы должны балансировать между скоростью и надёжностью.
Если мы хотим пойти по пути высокой скорости, то нам нужно хранить наши данные в как можно более быстром хранилище. Конечно, самым быстрым было бы хранить данные прямо в L1 кэше процессора, но объём хранилища не позволит нам развернуться. Следующее, что приходит на ум это RAM. Хранилище данных в оперативке несомненно даёт нам хорошую скорость, но о надёжности можно забыть, ведь любой скачок напряжения в датацентре будет означать неминуемую потерю данных. Примером такой базы данных может послужить какой-нибудь memcached.
Если же мы хотим получить высокую надёжность и нам не нужен частый и быстрый доступ к данным, то имеет смысл записывать все данные прямо на ssd или на hdd для хардкорных парней со специфическими задачами, например для хранения логов и редко запрашиваемой аналитики. Однако в таком случае придётся пожертвовать скоростью (что кстати может измениться с приходом быстрых nvm накопителей).
Популярные реляционные решения вроде Postgres и MySql используют гибридную схему, когда данные записываются на жёсткий диск, но также имеют слой, отвечающий за работы с кешированными в памяти данными для быстрого чтения. В этой статье мы будем говорить именно про этот тип хранилищ. Но прежде чем начинать лезть в гущи технической реализации, давайте с начала обозначим проблему.
Скажем, у нас есть заказчик Петя и фрилансер по имени Вася. Вася сделал Пете крутой лендос (одностраничный сайт) на тильде (конструктор сайтов) и ожидает, что Петя зашлёт ему за это денег. Петя не против и делает перевод через мобильный банкинг. Чтобы никто не присел нам нужно правильно выполнить несколько действий, а именно:
Найти таблицу с балансом Пети
Списать необходимую сумму с его баланса
Найти аккаунт Васи
Зачислить списанную у Пети сумму на счет Васи
Предположим, что первые два шага прошли хорошо. Однако потом выясняется, что Петя не правильно вбил реквизиты и мы не можем найти аккаунт Васи у нас в системе. Теперь мы имеем ситуацию, когда Петя стал беднее, а Вася богаче не стал. Тем самым мы нарушили правило консистентности, ведь данные испорчены. Это не очень крутая ситуация, ведь деньги не должны просто брать и исчезать.

Чтобы ответить на этот вопрос, нам нужно понять, что вообще представляет собой база данных и как она хранит записи. Тут нет единого ответа, ибо кто во что горазд, но если постараться обобщить, то база данных эта программа (ага, кто бы мог подумать) которая состоит из нескольких слоёв:
Transport layer — отвечает за общение базы с внешним миром (нашим замечательным сервером) и также за общение нод в кластере между собой (в случае если мы, скажем, применяем шардинг)
Query processor — ответственен за то, чтобы принять запрос, распарсить его, оптимизировать и превратить в список операций (execution plan), которые должны быть выполнены базой для успешного завершения транзакции
Execution engine — делает запрос на выполнение операций и агрегирует результаты
Storage engine — отвечает за исполнение операций
Ок, с этим этим разобрались, но теперь нам нужно погружаться ещё глубже в кроличью нору.

Дело в том, что storage engine тоже не так прост и состоит из нескольких частей, каждая из которых отвечает за то, чтобы наша база соответствовала злополучному ACID. Тут тоже нет единого консенсуса, но чаще всего выделяют следующие слои:
Transaction Manager — отвечает за очередь транзакций и проверяет, что транзакция полностью завершилась перед тем, как покинуть очередь. Отвечает за букву A и D.
Lock Manager — блокирует объекты, которые участвуют в транзакции. Отвечает за букву I
Storage Structures — отвечает за доступ и организацию данных в хранилище. Не отвечает ни за какие буковки, но без него никуда
Buffer Manager — кэширует данные в памяти. Мы ведь хотим, чтобы наша база работала быстро, правда?
Recovery Manager — отвечает за то, чтобы откатить данные к исходному состоянию в случае, если что-то пошло не так.
Вот оно! Recovery Manager и есть та волшебная штука, которая может нам помочь сделать rollback и вернуть Пете его честно заработанные деньги, а нам избежать исков в суды и жалоб в тысячи всевозможных инстанций.

Теперь давайте вернёмся к сценарию, когда нам нужно провести несколько операций в рамках одной транзакции для того, чтобы Петя заплатил Васе за красивый лендинг. Для модификации хранилища используется семейство паттернов под названием write-ahead logging (WAL). В оперативной памяти создаётся специальный лог файл, в который вносится информация о том, в каких таблицах нужно изменить записи в рамках операции, а также старые и обновленные значения полей. Затем обновлённый лог файл сохраняется на диск. После чего следует изменение записей в таблицах с данными, хранимых в памяти. После чего измененные значения таблиц сохраняются на диск. Тут важно понимать, что цепочка событий отрабатывает не на уровне всей транзакции, а на уровне отдельных операций, которые сохраняются на диск с определённой периодичностью (fsync() kernel call).
Но чтоже происходит, если операция не успешна и по какой-то причине нам нужно откатить изменения и вернуть нашу базу в исходное состояние?
Для восстановления исходного состояния используется семейство алгоритмов под названием ARIES (Algorithms for Recovery and Isolation Exploiting Semantics).
Логику алгоритма можно описать следующими шагами:
Analysis — стадия анализа и выявления таблиц, которые были модифицированы в ходе транзакции, а также анализ операций проведённых в пределах транзакции и их состояния (чекаем где сломалось).
REDO — на этом этапе мы уже точно знаем где транзакция сломалась и в какие таблицы были внесены изменения. Однако пока не можем гарантировать, что наше хранилище находится в консистентном состоянии, так как не понимаем, какие данные уже были сохранены на диск, а какие нет. Так как ребята, которые писали ARIES, были большими любителями простоты, они решили не заморачиваться, а просто ещё раз пройтись по всем операциям необходимым для транзакции, с самого начала и до момента ошибки. И применить их ещё раз с сохранением на жёсткий диск. Это необходимо для того, чтобы гарантировать консистентность нашего хранилища и исключить возможность порчи данных.
UNDO — тут всё просто. На последнем этапе мы делаем очередной проход по лог файлу и перезаписываем значения в изменённых таблицах. Но в отличие от предыдущего этапа на этот раз мы сохраняем значения таблицы, которые были в ней до того, как мы начали выполнение транзакции. Как результат, хранилище возвращается к изначальному состоянию и все счастливы.
После этого transaction manager сообщает нашему клиенту (в нашем случае это наш сервер) о том, что транзакция не прошла и всё, что нам остаётся сделать, это показать Пете сообщение о том, что перевод не случился и ему следует перепроверить реквизиты и попытаться ещё раз.
На этом всё. Надеюсь, данная статья помогла вам немного лучше понять, что происходит под капотом в популярных базах данных, что такое принципы ACID и как они поддерживаются и какие шаги предпринимаются хранилищем для следования этим принципам. Книги на почитать, если вдруг захотите копнуть глубже:
Транзакции
Как уже знаете, данные в базе данных обычно используются совместно многими прикладными пользовательскими программами (приложениями). Ситуация, когда несколько прикладных пользовательских программ одновременно выполняют операции чтения и записи одних и тех же данных, называется одновременным конкурентным (параллельным) доступом (concurrency). Таким образом, каждая система управления базами данных должна обладать каким-либо типом механизма управления для решения проблем, возникающих вследствие одновременного конкурентного доступа.
В системе баз данных, которая может обслуживать большое число активных пользовательских приложений таким образом, чтобы эти приложения не мешали друг другу, возможен высокий уровень одновременного конкурентного доступа. И наоборот, система баз данных, в которой разные активные приложения мешают друг другу, поддерживает низкий уровень одновременного конкурентного доступа.
Модели одновременного конкурентного доступа
Компонент Database Engine поддерживает две разные модели одновременного конкурентного доступа:
пессимистический одновременный конкурентный доступ;
оптимистический одновременный конкурентный доступ.
В модели пессимистического одновременного конкурентного доступа для предотвращения одновременного доступа к данным, которые используются другим процессом, применяются блокировки. Иными словами, система баз данных, использующая модель пессимистического одновременного конкурентного доступа, предполагает, что между двумя или большим количеством процессов в любое время может возникнуть конфликт и поэтому блокирует ресурсы (строку, страницу, таблицу), как только они потребуются в течение периода транзакции. Модель пессимистического одновременного конкурентного доступа устанавливает блокировку с обеспечением разделяемого доступа, иначе немонопольную блокировку (shared lock) на считываемые данные, чтобы никакой другой процесс не мог изменить эти данные. Кроме этого, механизм пессимистического одновременного конкурентного доступа устанавливает монопольную блокировку (exclusive lock) на изменяемые данные, чтобы никакой другой процесс не мог их считывать или модифицировать.
Работа оптимистического одновременного конкурентного доступа основана на предположении маловероятности изменения данных одной транзакцией одновременно с другой. Компонент Database Engine применяет оптимистический одновременный конкурентный доступ, при котором сохраняются старые версии строк, и любой процесс при чтении данных использует ту версию строки, которая была активной, когда он начал чтение. Поэтому процесс может модифицировать данные без каких-либо ограничений, поскольку все другие процессы, которые считывают эти же данные, используют свою собственную сохраненную версию. Конфликтная ситуация возможна только при попытке двух операций записи использовать одни и те же данные. В таком случае система выдает ошибку, которая обрабатывается клиентским приложением.
Понятие оптимистического одновременного конкурентного доступа обычно определяется в более широком смысле. Работа управления оптимистического одновременного конкурентного доступа основана на предположении маловероятности конфликтов между несколькими пользователями, поэтому разрешается исполнение транзакций без установки блокировок. Только когда пользователь пытается изменить данные, выполняется проверка ресурсов, чтобы определить наличие конфликтов. Если таковые возникли, то приложение требуется перезапустить.
Использование транзакций
задает последовательность инструкций языка Transact-SQL, применяемую программистами базы данных для объединения в один пакет операций чтения и записи для того, чтобы система базы данных могла обеспечить согласованность данных. Существует два типа транзакций:
Понятие транзакции лучше всего объяснить на примере. Допустим, в базе данных SampleDb сотруднику «Василий Фролов» требуется присвоить новый табельный номер. Этот номер нужно одновременно изменить в двух разных таблицах. В частности, требуется одновременно изменить строку в таблице Employee и соответствующие строки в таблице Works_on. Если обновить данные только в одной из этих таблиц, данные базы данных SampleDb будут несогласованны, поскольку значения первичного ключа в таблице Employee и соответствующие значения внешнего ключа в таблице Works_on не будут совпадать. Реализация этой транзакции посредством инструкций языка Transact-SQL показана в примере ниже:
Согласованность данных, обрабатываемых в примере, можно обеспечить лишь в том случае, если выполнены обе инструкции UPDATE либо обе не выполнены. Успех выполнения каждой инструкции UPDATE проверяется посредством глобальной переменной @@error. В случае ошибки этой переменной присваивается отрицательное значение и выполняется откат всех выполненных на данный момент инструкций транзакции.
В следующем разделе мы познакомимся со свойствами транзакций ACID. Эти свойства обеспечивают согласованность данных, обрабатываемых прикладными программами.
Свойства транзакций
Транзакции обладают следующими свойствами, которые все вместе обозначаются сокращением ACID (Atomicity, Consistency, Isolation, Durability):
Свойство атомарности обеспечивает неделимость набора инструкций, который модифицирует данные в базе данных и является частью транзакции. Это означает, что или выполняются все изменения данных в транзакции, или в случае любой ошибки осуществляется откат всех выполненных изменений.
Свойство согласованности обеспечивает, что в результате выполнения транзакции база данных не будет содержать несогласованных данных. Иными словами, выполняемые транзакцией трансформации данных переводят базу данных из одного согласованного состояния в другое.
Свойство изолированности отделяет все параллельные транзакции друг от друга. Иными словами, активная транзакция не может видеть модификации данных в параллельной или незавершенной транзакции. Это означает, что для обеспечения изоляции для некоторых транзакций может потребоваться выполнить откат.
Свойство долговечности обеспечивает одно из наиболее важных требований баз данных: сохраняемость данных. Иными словами, эффект транзакции должен оставаться действенным даже в случае системной ошибки. По этой причине, если в процессе выполнения транзакции происходит системная ошибка, то осуществляется откат для всех выполненных инструкций этой транзакции.
Инструкции Transact-SQL и транзакции
Для работы с транзакциями язык Transact-SQL предоставляет некоторые инструкции. Инструкция BEGIN TRANSACTION запускает транзакцию. Синтаксис этой инструкции выглядит следующим образом:
Инструкция COMMIT WORK успешно завершает транзакцию, запущенную инструкцией BEGIN TRANSACTION. Это означает, что все выполненные транзакцией изменения фиксируются и сохраняются на диск. Инструкция COMMIT WORK является стандартной формой этой инструкции. Использовать предложение WORK не обязательно.
Язык Transact-SQL также поддерживает инструкцию COMMIT TRANSACTION, которая функционально равнозначна инструкции COMMIT WORK, с той разницей, что она принимает определяемое пользователем имя транзакции. Инструкция COMMIT TRANSACTION является расширением языка Transact-SQL, соответствующим стандарту SQL.
В противоположность инструкции COMMIT WORK, инструкция ROOLBACK WORK сообщает о неуспешном выполнении транзакции. Программисты используют эту инструкцию, когда они полагают, что база данных может оказаться в несогласованном состоянии. В таком случае выполняется откат всех произведенных инструкциями транзакции изменений. Инструкция ROOLBACK WORK является стандартной формой этой инструкции. Использовать предложение WORK не обязательно. Язык Transact-SQL также поддерживает инструкцию ROLLBACK TRANSACTION, которая функционально равнозначна инструкции ROOLBACK WORK, с той разницей, что она принимает определяемое пользователем имя транзакции.
Инструкция SAVE TRANSACTION устанавливает точку сохранения внутри транзакции. Точка сохранения (savepoint) определяет заданную точку в транзакции, так что все последующие изменения данных могут быть отменены без отмены всей транзакции. (Для отмены всей транзакции применяется инструкция ROLLBACK.) Инструкция SAVE TRANSACTION в действительности не фиксирует никаких выполненных изменений данных. Она только создает метку для последующей инструкции ROLLBACK, имеющей такую же метку, как и данная инструкция SAVE TRANSACTION.
Использование инструкции SAVE TRANSACTION показано в примере ниже:
Единственной инструкцией, которая выполняется в этом примере, является первая инструкция INSERT. Для третьей инструкции INSERT выполняется откат с помощью инструкции ROLLBACK TRANSACTION b, а для двух других инструкций INSERT будет выполнен откат инструкцией ROLLBACK TRANSACTION a.
Инструкция SAVE TRANSACTION в сочетании с инструкцией IF или WHILE является полезной возможностью, позволяющей выполнять отдельные части всей транзакции. С другой стороны, использование этой инструкции противоречит принципу работы с базами данных, гласящему, что транзакция должна быть минимальной длины, поскольку длинные транзакции обычно уменьшают уровень доступности данных.
Как вы уже знаете, каждая инструкция Transact-SQL всегда явно или неявно принадлежит к транзакции. Для удовлетворения требований стандарта SQL компонент Database Engine предоставляет поддержку неявных транзакций. Когда сеанс работает в режиме неявных транзакций, выполняемые инструкции неявно выдают инструкции BEGIN TRANSACTION. Это означает, что для того чтобы начать неявную транзакцию, пользователю или разработчику не требуется ничего делать. Но каждую неявную транзакцию нужно или явно зафиксировать или явно отменить, используя инструкции COMMIT или ROLLBACK соответственно. Если транзакцию явно не зафиксировать, то все изменения, выполненные в ней, откатываются при отключении пользователя.
Для разрешения неявных транзакций параметру implicit_transactions оператора SET необходимо присвоить значение ON. Это установит режим неявных транзакций для текущего сеанса. Когда для соединения установлен режим неявных транзакций и соединение в данный момент не используется в транзакции, выполнение любой из следующих инструкций запускает транзакцию:


