Библиотека Requests: HTTP for Humans
Язык Python является универсальным языком программирования. С его помощью можно решать разнообразные задачи в сфере разработки.
Одной из таких сфер, в которой Python занял уверенную позицию, является веб-разработка. Немаловажную роль в этом сыграло обширное комьюнити, различные фреймворки и подключаемые библиотеки, созданные для облегчения жизни программистов. Об одной из таких библиотек сегодня пойдёт речь.
Библиотека Requests: HTTP for Humans
При решении различных задач в сфере веб-разработки, нам часто приходится взаимодействовать с HTTP. Это не самая простая задача для любого языка программирования и Python в этом не исключение. Язык, конечно, содержит встроенные модули, позволяющие отправлять HTTP запросы , но, как это ни парадоксально, их использование едва ли можно отнести к Pythonic-way.
В своё время чтобы обойти монструозность и сложность использования встроенных модулей появилась библиотека Requests . На данный момент она является одной из самых популярных библиотек на github: более 40 000 «звёзд» и используется более, чем в 20 000 open-source проектах. Нередко она используется и в коммерческой разработке.
Для чего и где мы можем применять Requests?
Как было отмечено выше, библиотека позволяет нам легко и с минимальным количеством кода взаимодействовать с веб-приложениями. Это необходимо нам для решения любых задач, связанных с передачей информации от пользователя к серверу и обратно. Но, чтобы что-то хорошо понять, необходимо закрепить теоретические знания практикой, поэтому перейдём от слов к делу.
Примеры использования библиотеки Requests
Я показываю использование командной строки, так как это полезный навык, который пригодится в дальнейшем, когда надо будет быстро что-то проверить.
Для начала, поскольку библиотека является внешней, нам необходимо её установить. Делается это очень просто в командной строке:
Продолжим использовать консоль. После установки в нашем расположении (у меня это диск D) введем команду:
Теперь можем проверить установку библиотеки произведя импорт:
Получаем ответ от сайта
Проверим, что возвращает нам данный запрос:
Как мы можем видеть, в качестве ответа мы получили объект класса Response и код 200. Этот код говорит, что ресурс работает и можно с ним взаимодействовать.
А что будет, если мы отправим неправильный запрос?
Теперь, когда мы познакомились с тем, как отправлять запрос GET с помощью Requests, мы можем продвинуться дальше и сделать что-то более интересное.
Скачаем изображение с сайта
В этом примере мы будем применять всё тот же запрос GET, но, в отличие от предыдущего, мы будем работать с содержимым ответа.
После выполнения данного скрипта, мы увидим новое изображение под названием new_image.png в директории, из которой у нас запущен скрипт.
Подробнее с классом Response и методами получения его содержимого можно ознакомиться на официальном сайте библиотеки Requests .
Отправим сообщение в WhatsApp
Для реализации этого примера воспользуемся сервисом, предоставляющим API для отправки сообщений. Я буду использовать сервис Chat-Api . Это платный сервис, но у них есть демо-режим, предоставляющий бесплатный доступ на 3 дня, чего нам для реализации этой задачи будет достаточно. После регистрации на сайте и получении Api URL и токена, мы сможем выполнить отправку сообщений в WhatsApp. Вот что нам для этого потребуется:
И проверим, отправлено ли сообщение:
Вы должны будете увидеть что-то вроде этого:
Загрузим файл на сервер
Для следующего примера воспользуемся сайтом для тестирования HTTP запросов Webhook.site . В качестве URL мы будем использовать ссылку, которая генерируется на сайте автоматически. У вас она будет отличаться от использованной в примере.
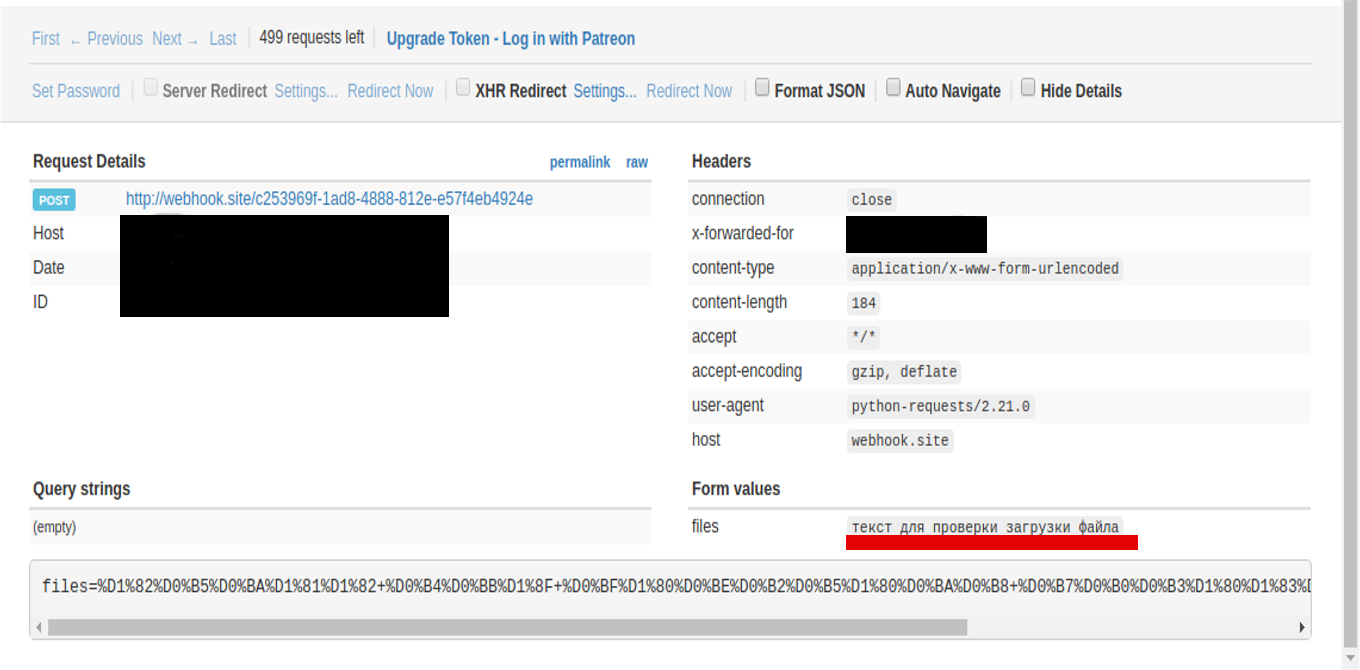
Авторизуемся на сайте
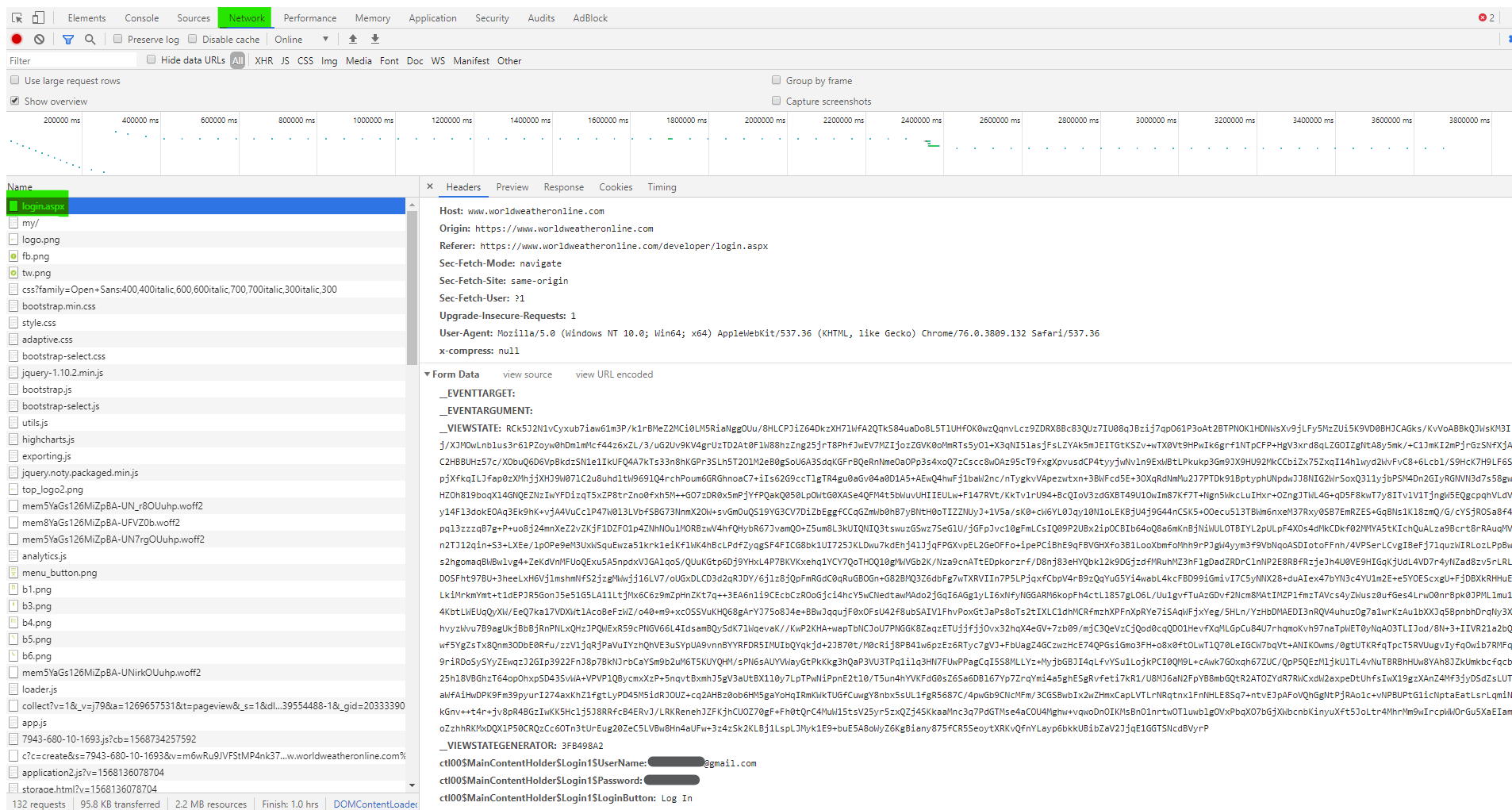
В этом примере будем использовать сайт, который нам также потребуется в следующем примере. Для начала зарегистрируемся на сайте WorldWeatherOnline . После удачной регистрации на сайте в личном кабинете вы увидите API KEY, который потребуется для следующего примера.
Для авторизации на сайте нам необходимо в запросе отправить пользовательские данные на сайт. Помимо логина и пароля, мы должны отправить сайту ключи, которые содержатся в заголовках пакета. Чтобы узнать эти ключи нужно выйти из нашей учётной записи, перейти на страницу входа, затем открыть в браузере Developer tools (F12), перейти на вкладку Network и снова авторизоваться. После того как страница загрузится в Developer tools во вкладке Network пролистайте вверх и найдите строчку login.aspx.
Как мы можем заметить во вкладке Headers, при входе мы осуществили запрос POST для передачи данных серверу. Пролистав вниз до блока Form Data, мы найдём все ключи, которые нам необходимо отправить сайту для авторизации.
Для проверки выполнения авторизации выведем содержание ответа сервера:
Неавторизованному пользователю данные кнопки недоступны.
Узнаем погоду в Москве
В этом примере мы будем использовать API KEY с сайта WorldWeatherOnline, на котором мы зарегистрировались в прошлом примере. В разделе документации на сайте WorldWeatherOnline приведено подробное описание параметров.
Теперь уже с использованием вашей любимой IDE напишем скрипт, который будет принимать в качестве аргумента из командной строки город, а возвращать значение температуры.
Создадим файл и назовём его weather.py. Запишем в него:
Запустим наш скрипт в командной строке:
В качестве ответа мы должны увидеть:
В этом примере мы не просто получили какую-то информацию от сервера, но и обработали содержимое полученного ответа. В следующем примере мы разберем еще один метод обработки полученного содержимого ответа.
Напишем простой парсер новостей
В качестве источника новостей будем использовать хаб о Python сайта Habr.com . В этом примере, помимо Requests нам также понадобится библиотека BeautifulSoup. С данной библиотеке можно подробно познакомиться на официальной странице документации Beautiful Soup . Устанавливается она также просто, как и Requests:
Создадим файл с названием news.py и запишем в него следующее:
Метод get_html() класса HabrPythonNews с помощью библиотеки Requests отправляет наш запрос GET к сайту Habr.com и возвращает содержимое страницы в виде текста. Иными словами, мы получаем html страницы. Если мы посмотрим на содержимое страницы (ctrl + U в Google Chrome), то обнаружим там различные блоки, в которых содержится информация. Нас интересуют только заголовки новостей и ссылки на них. Чтобы извлечь нужную нам информацию из содержимого страницы, мы воспользуемся библиотекой Beautiful Soup. Нужный нам блок называется:
Давайте теперь добавим функцию для работы с этим блоком:
Метод get_python_news() возвращает нам все элементы страницы, с тегом
И добавим завершающий блок нашего класса:
Итоговый код должен выглядеть у нас так:
При выполнении данного скрипта мы получим ссылки и заголовки новостей с первой страницы хаба. Изменяя параметры поиска
мы можем получать различные значения.
В качестве заключения
Использование библиотеки Requests не ограничивается приведенными выше примерами. Данная библиотека является очень удобным инструментом для взаимодействия с HTTP. Продолжить знакомство с библиотекой можно на официальном сайте Requests .
Автор: Виталий Калинин
Учимся использовать API сервиса Yandex SpeechKit
Описание, атрибуты и методы объекта requests.Response.
Синтаксис:
Параметры:
Описание:
Объект requests.Response модуля requests содержит всю информацию ответа сервера на HTTP-запрос requests.get(), requests.post() и т.д.
Объект ответа сервера requests.Response генерируется после того, как библиотека requests получают ответ от сервера. Объект ответа Response содержит всю информацию, возвращаемую сервером, а также объект запроса, который создали изначально.
Response.apparent_encoding :
Response.close() :
Метод Response.close() освобождает соединение с пулом. Как только этот метод был вызван, базовый необработанный объект больше не будет доступен.
Примечание: обычно не нужно вызывать явно.
Response.content :
Атрибут Response.content возвращает содержание ответа сервера, представленное в байтах.
Response.cookies = None :
Атрибут Response.cookies возвращает хранилище CookieJar файлов cookie, которые сервер отправил обратно.
Response.elapsed = None :
Атрибут Response.elapsed возвращает время, прошедшее между отправкой запроса и получением ответа (в виде timedelta ).
Response.encoding = None :
Response.headers = None :
Атрибут Response.headers возвращает словарь без учета регистра, с заголовками сервера, которые он вернул во время ответа.
Response.history = None :
Атрибут Response.history возвращает список объектов ответа сервера из истории запроса. Здесь окажутся все перенаправленные ответы.
Список сортируется от самого старого до самого последнего запроса.
Response.is_permanent_redirect :
Response.is_redirect :
Атрибут Response.is_redirect возвращает True если этот ответ является хорошо сформированным HTTP-перенаправлением, которое могло бы быть обработано автоматически ( Session.resolve_redirects ).
Response.iter_content(chunk_size=1, decode_unicode=False) :
Response.iter_lines(chunk_size=512, decode_unicode=False, delimiter=None) :
Обратите внимание, что этот метод не является безопасным для повторного входа.
Response.json(**kwargs) :
Метод Response.json() возвращает закодированное в json содержимое ответа, если таковое имеется.
Response.links :
Атрибут Response.links возвращает проанализированные ссылки заголовка ответа, если таковые имеются.
Response.next :
Атрибут Response.next возвращает объект подготовленного запроса PreparedRequest для следующего запроса в цепочке перенаправления, если таковой имеется.
Response.ok :
Как работать с библиотекой Requests в Python
Многие веб-приложения подключаются к различным сторонним сервисам с помощью API. Используя эти API, вы можете получить доступ к таким данным, как информация о погоде, результаты спортивных соревнований, списки фильмов, твиты, результаты поиска и изображения. Вы можете использовать API, чтобы расширить функции своего приложения, например, добавить платежи, планирование, электронные письма, переводы, карты и передачу файлов. Чтобы создать какую-либо из этих функций самостоятельно, вы потратили бы уйму времени, но с помощью API вы потратите на это всего несколько минут.
В этом мануале мы расскажем о библиотеке Requests Python, которая позволяет отправлять HTTP-запросы в Python.
Requests позволяет использовать API в Python, поскольку использование API – это не что иное, как отправка HTTP-запросов и получение ответов. В мануале мы покажем, как использовать API для перевода текста с одного языка на другой.
Краткий обзор HTTP-запросов
HTTP-запросы – это основа работы сети. Каждый раз, когда вы переходите на веб-страницу, ваш браузер отправляет несколько запросов на сервер веб-страницы. Сервер в ответ отправляет все данные, необходимые для отображения страницы, а затем ваш браузер фактически отображает страницу.
Общий процесс таков:
Часть данных, которую клиент отправляет в запросе, является методом запроса. Распространенными методами запросов являются GET, POST и PUT. GET-запросы, как правило, предназначены только для чтения данных без внесения каких-либо изменений, а POST и PUT-запросы обычно используются для изменения данных на сервере. Так, например, Stripe API позволяет использовать POST-запросы для создания нового счета, чтобы пользователь мог что-то купить в вашем приложении.
Примечание: В этом мануале мы не будем изменять какие-либо данные на сервере, потому рассматриваем только запросы GET.
Отправляя запрос из скрипта Python или из веб-приложения, разработчик решает, что будет отправлено в каждом запросе и что делать с ответом.
Давайте попробуем поработать с библиотекой Requests. В этом мануале для примера мы сначала отправим запрос в Scotch.io, а затем используем API перевода.
1: Установка библиотеки requests
Сначала нужно установить библиотеку. Давайте установим ее с помощью пакетного менеджера pip.
Примечание: Рекомендуем создать виртуальную среду, если у вас ее еще нет, и установить библиотеку в нее.
pip install requests
2: Отправка запроса
Сначала мы воспользуемся библиотекой Requests для запроса сайта Scotch.io. Создайте файл нем script.py и вставьте в него следующий код.
import requests
res = requests.get(‘https://scotch.io’)
print(res)
Примечание: В данном мануале мы будем работать с маленькими фрагментами кода, поэтому вы можете просто обновить существующий код вместо добавления новых строк.
Итак, этот код отправляет запрос GET на Scotch.io. Это тот же тип запроса, который ваш браузер отправил для просмотра этой страницы, единственное отличие состоит лишь в том, что библиотека Requests не может фактически отображать HTML, поэтому вы получите просто необработанный HTML и другую информацию ответа.
Вы можете запустить файл script.py с помощью команды:
И вот что вы получите:
3: Коды состояния
Первое, что мы должны сделать, – это проверить код состояния. Коды HTTP представлены в диапазоне от 1XX до 5XX. Вы, вероятно, встречали коды состояния 200, 404 и 500.
Вот что означает каждый код:
Как правило, выполняя свои запросы, вы должны получать коды состояния 2ХХ.
Библиотека Requests понимает, что 4XX и 5XX являются ошибками, поэтому если возвращаются эти коды состояния, объект ответа из запроса оценивается как False.
Вы можете убедиться, что запрос успешно обработан, проверив ответ так:
if res:
print(‘Response OK’)
else:
print(‘Response Failed’)
Сообщение «Response Failed» появится только в случае возврата кода состояния 400 или 500. Попробуйте указать неверный URL-адрес, и тогда вы получите ошибку 404 и увидите сообщение «Response Failed».
Вы можете взглянуть на код состояния напрямую, добавив в script.py строку:
Это покажет вам код состояния напрямую, чтобы вы могли все проверить самостоятельно.
>python script.py
Response Failed
404
>
4: Заголовки
Также в ответе на запрос вы можете найти заголовки.
Используйте в файле строку:
Затем запустите файл.
Заголовки отправляются вместе с запросом и возвращаются в ответе. Заголовки нужны, чтобы и клиент, и сервер знали, как интерпретировать данные, отправляемые и получаемые в ответах.
На экране вы увидите длинный список возвращаемых заголовков. Чаще всего вам не нужно напрямую использовать информацию заголовков, но вы можете получить ее, если она вам понадобилась. Обычно из всех заголовков вам может понадобиться только тип контента, поскольку он показывает формат данных, например HTML, JSON, PDF и так далее. Но тип контента обычно обрабатывается библиотекой Requests, поэтому вы можете получить доступ к возвращаемым данным.
5: Текст ответа
Обратите внимание на res.text (это касается текстовых данных, таких как HTML-страница, которую мы просматриваем). Здесь вы можете увидеть весь HTML-код, необходимый для создания домашней страницы Scotch. Он не будет обработан, но мы видим, что он принадлежит Scotch. Если вы сохраните этот код в файл и откроете его, вы увидите нечто похожее на сайт Scotch. В реальной ситуации на одну веб-страницу делается несколько запросов для загрузки разных компонентов (таких, как изображения, скрипты и таблицы стилей). Поэтому если вы сохраните в файл только HTML, страница не будет выглядеть так, как выглядит Scotch.io как в браузере, потому что для получения данных HTML был выполнен только один запрос.
6: Использование Translate API
Теперь давайте попробуем использовать Yandex Translate API для выполнения запроса на перевод текста на другой язык.
Чтобы использовать API, сначала необходимо зарегистрироваться. После регистрации перейдите в Translate API и создайте ключ API. Получив ключ, добавьте его в свой файл script.py как константу.
API_KEY = ‘your yandex api key’
Вот ссылка, по которой можно все сделать.
Ключ API нужен нам потому, что с его помощью Яндекс сможет аутентифицировать нас каждый раз, когда мы хотим использовать его API. Ключ API представляет собой упрощенную форму аутентификации, он добавляется в конец URL-адреса запроса при отправке.
Узнать, какой URL нужно отправить, чтобы использовать API, можно в документации Яндекса.
Там можно найти всю информацию, необходимую для использования Translate API для перевода текста.
Если в URL вы видите амперсанды (&), вопросительные знаки (?) и знаки равенства (=), вы можете быть уверены, что такой URL предназначен для запросов GET. Эти символы задают соответствующие параметры URL-адреса.
Обычно в квадратных скобках ([]) указываются опциональные фрагменты. В этом случае таковыми являются format, options и callback, в то время как key, text, and lang обязательно должны присутствовать в запросе.
Давайте добавим код для отправки запроса на этот URL. Вы можете заменить первый созданный нами запрос в файле script.py следующим кодом:
url = ‘https://translate.yandex.net/api/v1.5/tr.json/translate’
res = requests.get(url)
Есть два способа добавить параметры. Их можно добавить в конец URL-адреса напрямую, а можно сделать так, чтобы запросы делали это за нас. Чтобы сделать последнее, мы можем создать словарь для наших параметров. Обязательными элементами будут ключ, текст и язык. Давайте создадим словарь, используя ключ API, текст ‘Hello’ и языки ‘en-es’ (то есть текст нужно перевести с английского на испанский).
Другие языковые коды вы можете найти здесь в столбце 639-1.
Давайте создадим словарь параметров, используя функцию dict(), и передадим ей ключи и значения, которые должны быть в этом словаре. Добавьте в файл script.py:
params = dict(key=API_KEY, text=’Hello’, lang=’en-es’)
res = requests.get(url, params=params)
После этого запросы начнут добавляться к URL-адресу самостоятельно.
Теперь давайте добавим оператор print для текста ответа и посмотрим, что вернется в результате.
Здесь мы видим три вещи. Сначала идет код состояния, который в точности совпадает с кодом состояния самого ответа; затем идет язык, который мы выбрали; в конце мы видим переведенный текст.
Попробуйте еще раз, указав в качестве языка en-fr, и вы должны увидеть «Bonjour» в ответе.
params = dict(key=API_KEY, text=’Hello’, lang=’en-fr’)
Давайте посмотрим на заголовки для этого конкретного ответа.
Очевидно, заголовки будут отличаться, потому что мы обращаемся к другому серверу. В этом случае тип контента – application/json, а не text/html. Это означает, что данные могут быть интерпретированы как JSON.
Когда application/json является типом контента, мы можем сделать так, чтобы запросы преобразовывали ответ в словарь и список, чтобы легче получать доступ к данным.
Если вы отобразите его, вы увидите, что данные выглядят так же, но формат немного отличается.
json = res.json()
print(json)
Теперь это не простой текст, который вы получаете из res.text, а версия словаря.
Допустим, мы хотим получить доступ к тексту. Поскольку теперь это словарь, мы можем использовать ключ text.
И теперь мы увидим только данные для этого ключа. В этом случае мы получим список из одного элемента. Если вам нужно получить этот текст в списке, можно получить к нему доступ по индексу.
И теперь на экране будет только переведенное слово.
Меняя параметры, вы будете получать разные результаты. Давайте изменим текст, вместо Hello будет Goodbye, а также изменим целевой язык на испанский и отправим запрос снова.
params = dict(key=API_KEY, text=’Goodbye’, lang=’en-es’)
Также можно попробовать перевести более длинный текст на другие языки и посмотреть, какие ответы дает API.
7: Ошибки Translate API
Осталось рассмотреть ошибки.
Попробуйте изменить ключ API, удалив один символ. После этого ваш ключ API станет недействительным. Затем попробуйте отправить запрос.
Если вы посмотрите на код состояния, вот что вы получите:
print(res.status_code)
> python script.py
403
>
Когда вы используете API, вам нужно проверять выполнение некоторых операций, чтобы обрабатывать ошибки в соответствии с потребностями вашего приложения.
Заключение
В этом мануале вы узнали:
В этом списке вы найдете другие доступные API. Попробуйте использовать их с библиотекой Requests.
Advanced Usage¶
This document covers some of Requests more advanced features.
Session Objects¶
The Session object allows you to persist certain parameters across requests. It also persists cookies across all requests made from the Session instance, and will use urllib3 ’s connection pooling. So if you’re making several requests to the same host, the underlying TCP connection will be reused, which can result in a significant performance increase (see HTTP persistent connection).
A Session object has all the methods of the main Requests API.
Let’s persist some cookies across requests:
Sessions can also be used to provide default data to the request methods. This is done by providing data to the properties on a Session object:
Any dictionaries that you pass to a request method will be merged with the session-level values that are set. The method-level parameters override session parameters.
Note, however, that method-level parameters will not be persisted across requests, even if using a session. This example will only send the cookies with the first request, but not the second:
Sessions can also be used as context managers:
This will make sure the session is closed as soon as the with block is exited, even if unhandled exceptions occurred.
Remove a Value From a Dict Parameter
Sometimes you’ll want to omit session-level keys from a dict parameter. To do this, you simply set that key’s value to None in the method-level parameter. It will automatically be omitted.
All values that are contained within a session are directly available to you. See the Session API Docs to learn more.
Request and Response Objects¶
Whenever a call is made to requests.get() and friends, you are doing two major things. First, you are constructing a Request object which will be sent off to a server to request or query some resource. Second, a Response object is generated once Requests gets a response back from the server. The Response object contains all of the information returned by the server and also contains the Request object you created originally. Here is a simple request to get some very important information from Wikipedia’s servers:
If we want to access the headers the server sent back to us, we do this:
However, if we want to get the headers we sent the server, we simply access the request, and then the request’s headers:
Prepared Requests¶
Whenever you receive a Response object from an API call or a Session call, the request attribute is actually the PreparedRequest that was used. In some cases you may wish to do some extra work to the body or headers (or anything else really) before sending a request. The simple recipe for this is the following:
When you are using the prepared request flow, keep in mind that it does not take into account the environment. This can cause problems if you are using environment variables to change the behaviour of requests. For example: Self-signed SSL certificates specified in REQUESTS_CA_BUNDLE will not be taken into account. As a result an SSL: CERTIFICATE_VERIFY_FAILED is thrown. You can get around this behaviour by explicitly merging the environment settings into your session:
SSL Cert Verification¶
Requests verifies SSL certificates for HTTPS requests, just like a web browser. By default, SSL verification is enabled, and Requests will throw a SSLError if it’s unable to verify the certificate:
I don’t have SSL setup on this domain, so it throws an exception. Excellent. GitHub does though:
You can pass verify the path to a CA_BUNDLE file or directory with certificates of trusted CAs:
If verify is set to a path to a directory, the directory must have been processed using the c_rehash utility supplied with OpenSSL.
This list of trusted CAs can also be specified through the REQUESTS_CA_BUNDLE environment variable. If REQUESTS_CA_BUNDLE is not set, CURL_CA_BUNDLE will be used as fallback.
Requests can also ignore verifying the SSL certificate if you set verify to False:
By default, verify is set to True. Option verify only applies to host certs.
Client Side Certificates¶
You can also specify a local cert to use as client side certificate, as a single file (containing the private key and the certificate) or as a tuple of both files’ paths:
If you specify a wrong path or an invalid cert, you’ll get a SSLError:
The private key to your local certificate must be unencrypted. Currently, Requests does not support using encrypted keys.
CA Certificates¶
Requests uses certificates from the package certifi. This allows for users to update their trusted certificates without changing the version of Requests.
Before version 2.16, Requests bundled a set of root CAs that it trusted, sourced from the Mozilla trust store. The certificates were only updated once for each Requests version. When certifi was not installed, this led to extremely out-of-date certificate bundles when using significantly older versions of Requests.
For the sake of security we recommend upgrading certifi frequently!
Body Content Workflow¶
By default, when you make a request, the body of the response is downloaded immediately. You can override this behaviour and defer downloading the response body until you access the Response.content attribute with the stream parameter:
At this point only the response headers have been downloaded and the connection remains open, hence allowing us to make content retrieval conditional:
Keep-Alive¶
Excellent news — thanks to urllib3, keep-alive is 100% automatic within a session! Any requests that you make within a session will automatically reuse the appropriate connection!
Note that connections are only released back to the pool for reuse once all body data has been read; be sure to either set stream to False or read the content property of the Response object.
Streaming Uploads¶
Requests supports streaming uploads, which allow you to send large streams or files without reading them into memory. To stream and upload, simply provide a file-like object for your body:
Chunk-Encoded Requests¶
Requests also supports Chunked transfer encoding for outgoing and incoming requests. To send a chunk-encoded request, simply provide a generator (or any iterator without a length) for your body:
POST Multiple Multipart-Encoded Files¶
You can send multiple files in one request. For example, suppose you want to upload image files to an HTML form with a multiple file field ‘images’:
To do that, just set files to a list of tuples of (form_field_name, file_info) :
Event Hooks¶
Requests has a hook system that you can use to manipulate portions of the request process, or signal event handling.
The response generated from a Request.
You can assign a hook function on a per-request basis by passing a
That callback_function will receive a chunk of data as its first argument.
Your callback function must handle its own exceptions. Any unhandled exception won’t be passed silently and thus should be handled by the code calling Requests.
If the callback function returns a value, it is assumed that it is to replace the data that was passed in. If the function doesn’t return anything, nothing else is affected.
Let’s print some request method arguments at runtime:
You can add multiple hooks to a single request. Let’s call two hooks at once:
You can also add hooks to a Session instance. Any hooks you add will then be called on every request made to the session. For example:
A Session can have multiple hooks, which will be called in the order they are added.
Custom Authentication¶
Requests allows you to specify your own authentication mechanism.
Any callable which is passed as the auth argument to a request method will have the opportunity to modify the request before it is dispatched.
Let’s pretend that we have a web service that will only respond if the X-Pizza header is set to a password value. Unlikely, but just go with it.
Then, we can make a request using our Pizza Auth:
Streaming Requests¶
With Response.iter_lines() you can easily iterate over streaming APIs such as the Twitter Streaming API. Simply set stream to True and iterate over the response with iter_lines :
iter_lines is not reentrant safe. Calling this method multiple times causes some of the received data being lost. In case you need to call it from multiple places, use the resulting iterator object instead:
Proxies¶
If you need to use a proxy, you can configure individual requests with the proxies argument to any request method:
Alternatively you can configure it once for an entire Session :
To use HTTP Basic Auth with your proxy, use the http://user:password@host/ syntax in any of the above configuration entries:
Storing sensitive username and password information in an environment variable or a version-controlled file is a security risk and is highly discouraged.
To give a proxy for a specific scheme and host, use the scheme://hostname form for the key. This will match for any request to the given scheme and exact hostname.
Note that proxy URLs must include the scheme.
Finally, note that using a proxy for https connections typically requires your local machine to trust the proxy’s root certificate. By default the list of certificates trusted by Requests can be found with:
You override this default certificate bundle by setting the standard curl_ca_bundle environment variable to another file path:
SOCKS¶
New in version 2.10.0.
In addition to basic HTTP proxies, Requests also supports proxies using the SOCKS protocol. This is an optional feature that requires that additional third-party libraries be installed before use.
You can get the dependencies for this feature from pip :
Once you’ve installed those dependencies, using a SOCKS proxy is just as easy as using a HTTP one:
Using the scheme socks5 causes the DNS resolution to happen on the client, rather than on the proxy server. This is in line with curl, which uses the scheme to decide whether to do the DNS resolution on the client or proxy. If you want to resolve the domains on the proxy server, use socks5h as the scheme.
Compliance¶
Requests is intended to be compliant with all relevant specifications and RFCs where that compliance will not cause difficulties for users. This attention to the specification can lead to some behaviour that may seem unusual to those not familiar with the relevant specification.
Encodings¶
When you receive a response, Requests makes a guess at the encoding to use for decoding the response when you access the Response.text attribute. Requests will first check for an encoding in the HTTP header, and if none is present, will use charset_normalizer or chardet to attempt to guess the encoding.
If chardet is installed, requests uses it, however for python3 chardet is no longer a mandatory dependency. The chardet library is an LGPL-licenced dependency and some users of requests cannot depend on mandatory LGPL-licensed dependencies.
When you install request without specifying [use_chardet_on_py3]] extra, and chardet is not already installed, requests uses charset-normalizer (MIT-licensed) to guess the encoding. For Python 2, requests uses only chardet and is a mandatory dependency there.
HTTP Verbs¶
Requests provides access to almost the full range of HTTP verbs: GET, OPTIONS, HEAD, POST, PUT, PATCH and DELETE. The following provides detailed examples of using these various verbs in Requests, using the GitHub API.
We will begin with the verb most commonly used: GET. HTTP GET is an idempotent method that returns a resource from a given URL. As a result, it is the verb you ought to use when attempting to retrieve data from a web location. An example usage would be attempting to get information about a specific commit from GitHub. Suppose we wanted commit a050faf on Requests. We would get it like so:
We should confirm that GitHub responded correctly. If it has, we want to work out what type of content it is. Do this like so:
So, GitHub returns JSON. That’s great, we can use the r.json method to parse it into Python objects.
So far, so simple. Well, let’s investigate the GitHub API a little bit. Now, we could look at the documentation, but we might have a little more fun if we use Requests instead. We can take advantage of the Requests OPTIONS verb to see what kinds of HTTP methods are supported on the url we just used.
Uh, what? That’s unhelpful! Turns out GitHub, like many API providers, don’t actually implement the OPTIONS method. This is an annoying oversight, but it’s OK, we can just use the boring documentation. If GitHub had correctly implemented OPTIONS, however, they should return the allowed methods in the headers, e.g.
Turning to the documentation, we see that the only other method allowed for commits is POST, which creates a new commit. As we’re using the Requests repo, we should probably avoid making ham-handed POSTS to it. Instead, let’s play with the Issues feature of GitHub.
This documentation was added in response to Issue #482. Given that this issue already exists, we will use it as an example. Let’s start by getting it.
Cool, we have three comments. Let’s take a look at the last of them.
Well, that seems like a silly place. Let’s post a comment telling the poster that he’s silly. Who is the poster, anyway?
OK, so let’s tell this Kenneth guy that we think this example should go in the quickstart guide instead. According to the GitHub API doc, the way to do this is to POST to the thread. Let’s do it.
Huh, that’s weird. We probably need to authenticate. That’ll be a pain, right? Wrong. Requests makes it easy to use many forms of authentication, including the very common Basic Auth.
Brilliant. Oh, wait, no! I meant to add that it would take me a while, because I had to go feed my cat. If only I could edit this comment! Happily, GitHub allows us to use another HTTP verb, PATCH, to edit this comment. Let’s do that.
Excellent. Now, just to torture this Kenneth guy, I’ve decided to let him sweat and not tell him that I’m working on this. That means I want to delete this comment. GitHub lets us delete comments using the incredibly aptly named DELETE method. Let’s get rid of it.
Excellent. All gone. The last thing I want to know is how much of my ratelimit I’ve used. Let’s find out. GitHub sends that information in the headers, so rather than download the whole page I’ll send a HEAD request to get the headers.
Excellent. Time to write a Python program that abuses the GitHub API in all kinds of exciting ways, 4995 more times.
Custom Verbs¶
Utilising this, you can make use of any method verb that your server allows.
Link Headers¶
Many HTTP APIs feature Link headers. They make APIs more self describing and discoverable.
GitHub uses these for pagination in their API, for example:
Requests will automatically parse these link headers and make them easily consumable:
Transport Adapters¶
As of v1.0.0, Requests has moved to a modular internal design. Part of the reason this was done was to implement Transport Adapters, originally described here. Transport Adapters provide a mechanism to define interaction methods for an HTTP service. In particular, they allow you to apply per-service configuration.
Requests enables users to create and use their own Transport Adapters that provide specific functionality. Once created, a Transport Adapter can be mounted to a Session object, along with an indication of which web services it should apply to.
The mount call registers a specific instance of a Transport Adapter to a prefix. Once mounted, any HTTP request made using that session whose URL starts with the given prefix will use the given Transport Adapter.
Example: Specific SSL Version¶
The Requests team has made a specific choice to use whatever SSL version is default in the underlying library (urllib3). Normally this is fine, but from time to time, you might find yourself needing to connect to a service-endpoint that uses a version that isn’t compatible with the default.
Blocking Or Non-Blocking?¶
With the default Transport Adapter in place, Requests does not provide any kind of non-blocking IO. The Response.content property will block until the entire response has been downloaded. If you require more granularity, the streaming features of the library (see Streaming Requests ) allow you to retrieve smaller quantities of the response at a time. However, these calls will still block.
If you are concerned about the use of blocking IO, there are lots of projects out there that combine Requests with one of Python’s asynchronicity frameworks. Some excellent examples are requests-threads, grequests, requests-futures, and httpx.
Header Ordering¶
In unusual circumstances you may want to provide headers in an ordered manner. If you pass an OrderedDict to the headers keyword argument, that will provide the headers with an ordering. However, the ordering of the default headers used by Requests will be preferred, which means that if you override default headers in the headers keyword argument, they may appear out of order compared to other headers in that keyword argument.
Timeouts¶
Most requests to external servers should have a timeout attached, in case the server is not responding in a timely manner. By default, requests do not time out unless a timeout value is set explicitly. Without a timeout, your code may hang for minutes or more.
The connect timeout is the number of seconds Requests will wait for your client to establish a connection to a remote machine (corresponding to the connect()) call on the socket. It’s a good practice to set connect timeouts to slightly larger than a multiple of 3, which is the default TCP packet retransmission window.
Once your client has connected to the server and sent the HTTP request, the read timeout is the number of seconds the client will wait for the server to send a response. (Specifically, it’s the number of seconds that the client will wait between bytes sent from the server. In 99.9% of cases, this is the time before the server sends the first byte).
If you specify a single value for the timeout, like this:
The timeout value will be applied to both the connect and the read timeouts. Specify a tuple if you would like to set the values separately:
If the remote server is very slow, you can tell Requests to wait forever for a response, by passing None as a timeout value and then retrieving a cup of coffee.
Requests is an elegant and simple HTTP library for Python, built for human beings. You are currently looking at the documentation of the development release.


