Всё об IP адресах и о том, как с ними работать
Доброго времени суток, уважаемые читатели Хабра!
Не так давно я написал свою первую статью на Хабр. В моей статье была одна неприятная шероховатость, которую моментально обнаружили, понимающие в сетевом администрировании, пользователи. Шероховатость заключается в том, что я указал неверные IP адреса в лабораторной работе. Сделал это я умышленно, так как посчитал что неопытному пользователю будет легче понять тему VLAN на более простом примере IP, но, как было, совершенно справедливо, замечено пользователями, нельзя выкладывать материал с ключевой ошибкой.
В самой статье я не стал править эту ошибку, так как убрав её будет бессмысленна вся наша дискуссия в 2 дня, но решил исправить её в отдельной статье с указание проблем и пояснением всей темы.
Для начала, стоит сказать о том, что такое IP адрес.
IP-адрес — уникальный сетевой адрес узла в компьютерной сети, построенной на основе стека протоколов TCP/IP (TCP/IP – это набор интернет-протоколов, о котором мы поговорим в дальнейших статьях). IP-адрес представляет собой серию из 32 двоичных бит (единиц и нулей). Так как человек невосприимчив к большому однородному ряду чисел, такому как этот 11100010101000100010101110011110 (здесь, к слову, 32 бита информации, так как 32 числа в двоичной системе), было решено разделить ряд на четыре 8-битных байта и получилась следующая последовательность: 11100010.10100010.00101011.10011110. Это не сильно облегчило жизнь и было решение перевести данную последовательность в, привычную нам, последовательность из четырёх чисел в десятичной системе, то есть 226.162.43.158. 4 разряда также называются октетами. Данный IP адрес определяется протоколом IPv4. По такой схеме адресации можно создать более 4 миллиардов IP-адресов.
Максимальным возможным числом в любом октете будет 255 (так как в двоичной системе это 8 единиц), а минимальным – 0.
Далее давайте разберёмся с тем, что называется классом IP (именно в этом моменте в лабораторной работе была неточность).
IP-адреса делятся на 5 классов (A, B, C, D, E). A, B и C — это классы коммерческой адресации. D – для многоадресных рассылок, а класс E – для экспериментов.
Класс А: 1.0.0.0 — 126.0.0.0, маска 255.0.0.0
Класс В: 128.0.0.0 — 191.255.0.0, маска 255.255.0.0
Класс С: 192.0.0.0 — 223.255.255.0, маска 255.255.255.0
Класс D: 224.0.0.0 — 239.255.255.255, маска 255.255.255.255
Класс Е: 240.0.0.0 — 247.255.255.255, маска 255.255.255.255
Теперь о «цвете» IP. IP бывают белые и серые (или публичные и частные). Публичным IP адресом называется IP адрес, который используется для выхода в Интернет. Адреса, используемые в локальных сетях, относят к частным. Частные IP не маршрутизируются в Интернете.
Публичные адреса назначаются публичным веб-серверам для того, чтобы человек смог попасть на этот сервер, вне зависимости от его местоположения, то есть через Интернет. Например, игровые сервера являются публичными, как и сервера Хабра и многих других веб-ресурсов.
Большое отличие частных и публичных IP адресов заключается в том, что используя частный IP адрес мы можем назначить компьютеру любой номер (главное, чтобы не было совпадающих номеров), а с публичными адресами всё не так просто. Выдача публичных адресов контролируется различными организациями.
Допустим, Вы молодой сетевой инженер и хотите дать доступ к своему серверу всем пользователям Интернета. Для этого Вам нужно получить публичный IP адрес. Чтобы его получить Вы обращаетесь к своему интернет провайдеру, и он выдаёт Вам публичный IP адрес, но из рукава он его взять не может, поэтому он обращается к локальному Интернет регистратору (LIR – Local Internet Registry), который выдаёт пачку IP адресов Вашему провайдеру, а провайдер из этой пачки выдаёт Вам один адрес. Локальный Интернет регистратор не может выдать пачку адресов из неоткуда, поэтому он обращается к региональному Интернет регистратору (RIR – Regional Internet Registry). В свою очередь региональный Интернет регистратор обращается к международной некоммерческой организации IANA (Internet Assigned Numbers Authority). Контролирует действие организации IANA компания ICANN (Internet Corporation for Assigned Names and Numbers). Такой сложный процесс необходим для того, чтобы не было путаницы в публичных IP адресах.

Поскольку мы занимаемся созданием локальных вычислительных сетей (LAN — Local Area Network), мы будем пользоваться именно частными IP адресами. Для работы с ними необходимо понимать какие адреса частные, а какие нет. В таблице ниже приведены частные IP адреса, которыми мы и будем пользоваться при построении сетей.
Из вышесказанного делаем вывод, что пользоваться при создании локальной сеть следует адресами из диапазона в таблице. При использовании любых других адресов сетей, как например, 20.*.*.* или 30.*.*.* (для примера взял именно эти адреса, так как они использовались в лабе), будут большие проблемы с настройкой реальной сети.
Из таблицы частных IP адресов вы можете увидеть третий столбец, в котором написана маска подсети. Маска подсети — битовая маска, определяющая, какая часть IP-адреса узла сети относится к адресу сети, а какая — к адресу самого узла в этой сети.
У всех IP адресов есть две части сеть и узел.
Сеть – это та часть IP, которая не меняется во всей сети и все адреса устройств начинаются именно с номера сети.
Узел – это изменяющаяся часть IP. Каждое устройство имеет свой уникальный адрес в сети, он называется узлом.
Маску принято записывать двумя способами: префиксным и десятичным. Например, маска частной подсети A выглядит в десятичной записи как 255.0.0.0, но не всегда удобно пользоваться десятичной записью при составлении схемы сети. Легче записать маску как префикс, то есть /8.
Так как маска формируется добавлением слева единицы с первого октета и никак иначе, но для распознания маски нам достаточно знать количество выставленных единиц.
Таблица масок подсети
Высчитаем сколько устройств (в IP адресах — узлов) может быть в сети, где у одного компьютера адрес 172.16.13.98 /24.
172.16.13.0 – адрес сети
172.16.13.1 – адрес первого устройства в сети
172.16.13.254 – адрес последнего устройства в сети
172.16.13.255 – широковещательный IP адрес
172.16.14.0 – адрес следующей сети
Итого 254 устройства в сети
Теперь вычислим сколько устройств может быть в сети, где у одного компьютера адрес 172.16.13.98 /16.
172.16.0.0 – адрес сети
172.16.0.1 – адрес первого устройства в сети
172.16.255.254 – адрес последнего устройства в сети
172.16.255.255 – широковещательный IP адрес
172.17.0.0 – адрес следующей сети
Итого 65534 устройства в сети
В первом случае у нас получилось 254 устройства, во втором 65534, а мы заменили только номер маски.
Посмотреть различные варианты работы с масками вы можете в любом калькуляторе IP. Я рекомендую этот.
До того, как была придумана технология масок подсетей (VLSM – Variable Langhe Subnet Mask), использовались классовые сети, о которых мы говорили ранее.
Теперь стоит сказать о таких IP адресах, которые задействованы под определённые нужды.
Адрес 127.0.0.0 – 127.255.255.255 (loopback – петля на себя). Данная сеть нужна для диагностики.
169.254.0.0 – 169.254.255.255 (APIPA – Automatic Private IP Addressing). Механизм «придумывания» IP адреса. Служба APIPA генерирует IP адреса для начала работы с сетью.
Теперь, когда я объяснил тему IP, становиться ясно почему сеть, представленная в лабе, не будет работать без проблем. Этого стоит избежать, поэтому исправьте ошибки исходя из информации в этой статье.
Точка обмена трафиком: от истоков к созданию собственной IX

«We set up a telephone connection between us and the guys at SRI. », Kleinrock… said in an interview:
«We typed the L and we asked on the phone, „Do you see the L?“»
«Yes, we see the L,» came the response.
«We typed the O, and we asked, „Do you see the O.“»
«Yes, we see the O.»
«Then we typed the G, and the system crashed»…
Yet a revolution had begun.
The beginning of the internet.
Меня зовут Александр, я сетевой инженер в компании Linxdatacenter. В сегодняшней статье речь пойдет про точки обмена трафиком (Internet Exchange Point, IXP): о том, что предшествовало их появлению, какие задачи они решают и как строятся. Также в данной статье я продемонстрирую принцип работы IXP с помощью платформы EVE-NG и программного маршрутизатора BIRD, чтобы было понимание, как это работает «под капотом».
Немного истории
Если посмотреть сюда, то можно заметить, что бурный рост количества точек обмена трафиком начался в 1993 году. Это связано с тем, что большинство трафика существовавших на тот момент операторов связи проходило через backbone-сеть США. Так, например, когда трафик шел от оператора во Франции до оператора в Германии, он из Франции сначала попадал в США, и только потом из США в Германию. Backbone-сеть в данном случае выступала транзитом между Францией и Германией. Даже трафик внутри одной страны часто проходил не напрямую, а через опорные сети американских операторов.
Такое положение вещей сказывалось не только на стоимости доставки транзитного трафика, но и на качестве каналов и задержке. Количество пользователей сети Интернет увеличивалось, появлялись новые операторы, объем трафика возрастал, интернет взрослел. Операторы по всему миру начали понимать, что нужен более рациональный подход к организации межоператорского взаимодействия. «Зачем мне, оператору А, платить за транзит через другую страну, чтобы доставить трафик оператору Б, который располагается на соседней улице?». Примерно такой вопрос задавали себе операторы связи в то время. Так, в разных частях мира в точках концентрации операторов начали появляться точки обмена трафиком:
Интернет и наши дни
Концептуально архитектура современного интернета представляет из себя множество автономных систем (autonomous system, AS) и множество связей между ними, как физических, так и логических, которые определяют путь прохождения трафика от одной AS к другой.
В качестве AS обычно выступают операторы связи, интернет-провайдеры, CDN, дата-центры, компании энтерпрайз сегмента. AS организуют логические связи (peering) между собой, как правило, средствами протокола BGP.
То, как автономные системы организуют эти связи, определяется рядом факторов:
Схематически это можно представить так:
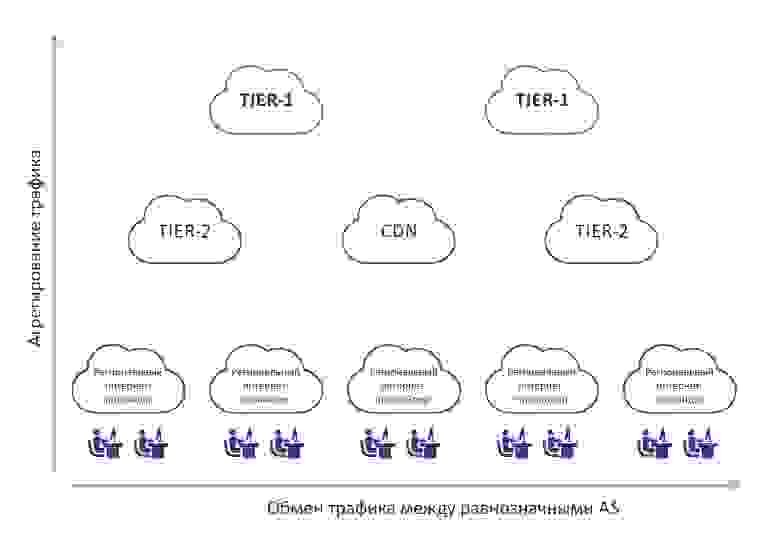
На данной картинке видно, что трафик агрегируется снизу вверх, т.е. от конечных пользователей к tier-1 операторам. Также имеет место горизонтальный обмен трафиком между примерно равнозначными между собой AS.
Неотъемлемой частью и одновременно недостатком данной схемы является некая беспорядочность связей между автономными системами, располагающимися ближе к конечному пользователю, в пределах географической зоны. Рассмотрим картинку ниже:

Предположим, что в крупном городе присутствует 5 операторов связи, пиринг между которыми, по тем или иным причинам, организован, как показано выше.
Если пользователь Петя, подключенный к интернет-провайдеру Go, захочет получить доступ к серверу, подключенному к провайдеру ASM, то трафик между ними будет вынужден проходить через 5 автономных систем. Таким образом увеличивается задержка, т.к. увеличивается количество сетевых устройств, через которые пойдет трафик, а также объем транзитного трафика на автономных системах между Go и ASM.
Как сократить количество транзитных AS, которые вынужден проходить трафик? Правильно – точка обмена трафиком.
В наши дни появление новых IXP обусловлено все теми же потребностями, что и в начале 90-х-2000-х, только в более мелком масштабе, в ответ на увеличивающееся количество операторов связи, пользователей и трафика, растущее количество контента, генерируемого CDN-сетями и дата-центрами.
Что такое точка обмена трафиком?
Точка обмена трафиком – это место со специальной сетевой инфраструктурой, где заинтересованные во взаимном обмене трафиком участники, организуют взаимный пиринг. Основные участники точек обмена трафиком: операторы связи, интернет-провайдеры, провайдеры контента и дата-центры. В точках обмена трафиком участники соединяются между собой напрямую. Это позволяет решить следующие задачи:
Если вышеописанную ситуацию с Петей решать с помощью IXP, то получится примерно так:

Как устроена точка обмена трафиком?
Как правило, IXP – это отдельная AS со своим блоком публичных IPv4/IPv6 адресов.
Сеть IXP чаще всего представляет из себя сплошной L2 домен. Иногда это просто VLAN, в котором размещаются все клиенты IXP. Когда же речь идет о более крупных, географически распределенных IXP, то для организации L2 домена могут использоваться такие технологии, как MPLS, VXLAN и т.д.
Элементы IXP
Например, хорошей практикой является пропуск трафика только с определенного mac-адреса участника IXP, который обговаривается заранее. Запрет трафика с полями ethertype, отличающимися от 0x0800(IPv4), 0x08dd(IPv6), 0x0806(ARP); это делается для того, чтобы отфильтровать трафик, которому нет места при BGP-пиринге. Также могут применяться такие механизмы как GTSM, RPKI и т.д.
Пожалуй, вышеперечисленное – это основные составляющие любой IXP вне зависимости от масштаба. Конечно, у крупных IXP могут применяться дополнительные технологии и решения.
Бывает, что IXP также предоставляет своим участникам дополнительные сервисы:
Принцип работы
Разберем принцип работы точки обмена трафиком на примере простейшей IXP, смоделированной средствами EVE-NG, а после рассмотрим базовую настройку программного маршрутизатора BIRD. Для упрощения схемы мы опустим такие важные вещи, как резервирование и отказоустойчивость.
Топология сети представлена на рисунке ниже.

Предположим, что мы администрируем небольшую точку обмена трафиком и предоставляем следующие варианты пиринга:
50.50.50.254 – IP-адрес, настроенный на интерфейс route server’а, с данным IP клиенты будут устанавливать BGP-сессию в случае пиринга через RS.
Также для пиринга через RS мы разработали простейшую политику маршрутизации на основе BGP community, которая дает возможность участникам IXP регулировать кому и какие маршруты отправлять:
| BGP community | Описание |
| LOCAL_AS:PEER_AS | Передать префиксы только PEER_AS |
| LOCAL_AS:IXP_AS | Передать префиксы всем участникам IXP |
| Клиент | Номер AS клиента | Анонсируемые клиентом префиксы | ip адрес выданный клиенту для подключения к IXP |
| ISP #1 | AS 100 | 1.1.0.0/16 | 50.50.50.10/24 |
| ISP #2 | AS 200 | 2.2.0.0/16 | 50.50.50.20/24 |
| ISP #3 | AS 300 | 3.3.0.0/16 | 50.50.50.30/24 |
Базовая настройка BGP на маршрутизаторе клиента:
Здесь стоит отметить настройку no bgp enforce-first-as. По умолчанию, BGP требует, чтобы в as-path принимаемого BGP апдейта, присутствовал номер as bgp пира, от которого данный апдейт был получен. Но поскольку route server не вносит изменения в as-path, его номер будет отсутствовать в as-path и апдейт будет отброшен. Данная настройка применяется, чтобы маршрутизатор начал игнорировать данное правило.
Также мы видим, что клиент установил bgp community 555:555 на данный префикс, что согласно нашей политике означает, что клиент хочет анонсировать данный префикс всем остальным участникам.
Для маршрутизаторов остальных клиентов настройка будет аналогичная, за исключением их уникальных параметров.
Пример конфигурации BIRD:
Далее описывается фильтр, который не принимает martians префиксы, а также префиксы самой IXP:
Данная функция реализует политику маршрутизации, которую мы описали ранее.
Настраиваем пиринг, применяем соответствующие фильтры и политики.
Стоит отметить, что на route server’e является хорошим тоном складывать маршруты от разных пиров в разные RIB. BIRD позволяет это делать. В нашем же примере для простоты все апдейты, принятые от всех клиентов, складываются в одну общую RIB.
Итак, проверим, что у нас получилось.
На route server’e видим, что со всеми тремя клиентами установлена BGP-сессия:
Видим, что мы получаем префиксы от всех клиентов:
На маршрутизаторе as 100 видим, что при наличии всего одной BGP-сессии с сервером маршрутов, мы получаем префиксы и от as 200 и от as 300, при этом BGP-атрибуты не поменялись, как если бы пиринг между клиентами осуществлялся напрямую:
Таким образом мы видим, что наличие сервера маршрутов значительно упрощает организацию пиринга на IXP.
Надеюсь, что данная демонстрация помогла вам лучше понять, как устроены точки обмена трафиком и как реализуется работа сервера маршрутов на IXP.
Linxdatacenter IX
В Linxdatacenter мы построили собственную IXP на базе отказоустойчивой инфраструктуры из 2-х коммутаторов и 2-х route-серверов. Сейчас наша IXP запущена в тестовом режиме, и мы приглашаем всех желающих подключиться к Linxdatacenter IX и принять участие в тестировании. При подключении вам будет предоставлен порт с пропускной способностью 1 Gbit/s, возможность пиринга через наши route-сервера, а также доступ в личный кабинет IX-портала, доступного по адресу ix.linxdatacenter.com.
Пишите в комментарии или личные сообщения для получения доступа к тестированию.
Вывод
Точки обмена трафиком возникли на заре интернета как инструмент решения вопроса неоптимального прохождения трафика между операторами связи. Сейчас с появлением новых глобальных сервисов и увеличением количества CDN трафика точки обмена все также продолжают оптимизировать работу глобальной сети. Увеличение количества IXP в мире несет пользу как для конечного пользователя сервиса, так и для операторов связи, операторов контента и т.д. Для участников IXP выгода выражается в сокращении расходов на организацию внешних пирингов, сокращении количества трафика, за который приходится платить вышестоящим операторам, оптимизации маршрутизации, возможности иметь прямой стык с операторами контента.
IPSec всемогущий
История вопроса
Изначально VPN планировался только для организации канала между мини-роутером родителей и домашним «подкроватным» сервером, по совместительству выступающим в роли маршрутизатора.
Спустя небольшой промежуток времени к этой компании из двух устройств добавился Keenetic.
Но единожды начав, остановиться оказалось сложно, и вскоре на схеме появились телефоны и ноутбук, которым захотелось скрыться от всевидящего рекламного ока MT_Free и прочих нешифрованных WiFi-сетей.
Потом у всеми любимого РКН наконец-то окреп банхаммер, которым он несказанно полюбил прилюдно размахивать во все стороны, и для нейтрализации его заботы о простых смертных пришлось поддержать иностранный IT-сектор приобрести VPS за рубежом.
К тому же некоей гражданке, внешне напоминающей Шапокляк, всюду бегающей со своим ридикюлем Пакетом и, вероятно, считающей что «Кто людям помогает — тот тратит время зря. Хорошими делами прославиться нельзя», захотелось тайком подглядывать в чужой трафик и брать его на карандаш. Придется тоже защищаться от такой непрошенной любви и VPN в данном случае именно то, что доктор прописал.
Подведем небольшой итог. Нужно было подобрать решение, которое в идеале способно закрыть сразу несколько поставленных задач:
Обзор существующих решений
Коротко пройдемся по тому что есть сейчас:
Дедушка Ленин всех протоколов. Умер, «разложился на плесень и на липовый мёд».
Кто-то, кроме одного провайдера, это использует?
Проект развивается. Активно пилится. Легко создать туннель между двумя пирами, имеющими статический IP. В остальных случаях на помощь всегда готовы придти костыли, велосипеды с квадратными колёсами и синяя изолента, но это не наш путь.
Приступаем к настройке
Определившись с решением приступаем к настройке. Схема сети в моем случае имеет следующий вид (убрал под спойлер)
ipsecgw.example.com — домашний сервер, являющийся центром сети. Внешний IP 1.1.1.1. Внутренняя сеть 10.0.0.0/23 и еще один адрес 10.255.255.1/30 для установки приватной BGP-сессии с VPS;
mama — Linux-роутер на базе маленького беззвучного неттопа, установленный у родителей. Интернет-провайдер выдает динамический IP-адрес. Внутренняя сеть 10.0.3.0/24;
keenetic — маршрутизатор Keenetic с установленным модулем IPSec. Интернет-провайдер выдает динамический IP-адрес. Внутренняя сеть 10.0.4.0/24;
road-warriors — переносные устройства, подключающиеся из недоверенных сетей. Адреса клиентам выдаются динамически при подключении из внутренного пула (10.1.1.0/24);
rkn.example.com — VPS вне юрисдикции уважаемого РКН. Внешний IP — 5.5.5.5, внутренний адрес 10.255.255.2/30 для установки приватной BGP-сессии.
Первый шаг. От простого к сложному: туннели с использованием pre-shared keys (PSK)
На обоих Linux-box устанавливаем необходимые пакеты:
На обоих хостах открываем порты 500/udp, 4500/udp и разрешаем прохождение протокола ESP.
Правим файл /etc/strongswan/ipsec.secrects (на стороне хоста ipsecgw.example.com) и вносим следующую строку:
На второй стороне аналогично:
В данном случае в качестве ID выступает вымышленный адрес элестронной почты. Больше информации можно подчерпнуть на официальной вики.
Секреты сохранены, движемся дальше.
На хосте ipsecgw.example.com редактируем файл /etc/strongswan/ipsec.conf:
Аналогично редактируем на удаленном пире /etc/strongswan/ipsec.conf:
Если сравнить конфиги, то можно увидеть что они почти зеркальные, перекрёстно поменяны местами только определения пиров.
Директива auto = route заставляет charon установить ловушку для трафика, подпадающего в заданные директивами left/rightsubnet (traffic selectors). Согласование параметров туннеля и обмен ключами начнутся немедленно после появления трафика, попадающего под заданные условия.
На сервере ipsecgw.example.com в настройках firewall запрещаем маскарадинг для сети 10.0.3.0/24. Разрешаем форвардинг пакетов между 10.0.0.0/23 и 10.0.3.0/24 и наоборот. На удаленном узле выполняем аналогичные настройки, запретив маскарадинг для сети 10.0.0.0/23 и настроив форвардинг.
Рестартуем strongswan на обоих серверах и пробуем выполнить ping центрального узла:
Нелишним будет так же убедиться что в файле /etc/strongswan/strongswan.d/charon.conf на всех пирах параметр make_before_break установлен в значение yes. В данном случае демон charon, обслуживающий протокол IKEv2, при выполнении процедуры смены ключей не будет удалять текущую security association, а сперва создаст новую.
Шаг второй. Появление Keenetic
Приятной неожиданностью оказался встроенный IPSec VPN в официальной прошивке Keenetic. Для его активации достаточно перейти в Настройки компонентов KeeneticOS и добавить пакет IPSec VPN.
Готовим настройки на центральном узле, для этого:
Правим /etc/strongswan/ipsec.secrects и добавляем PSK для нового пира:
Правим /etc/strongswan/ipsec.conf и добавляем в конец еще одно соединение:
Со стороны Keenetic настройка выполняется в WebUI по пути: Интернет → Подключения →
Другие подключения. Всё довольно просто.
Если планируется через тоннель гонять существенные объемы трафика, то можно попробовать включить аппаратное ускорение, которое поддерживается многими моделями. Включается командой crypto engine hardware в CLI. Для отключения и обработки процессов шифрования и хеширования при помощи инструкций CPU общего назначения — crypto engine software
После сохранения настроек рестрартуем strongswan и даём подумать полминуты Keenetic-у. После чего в терминале видим успешную установку соединения:
Шаг третий. Защищаем мобильные устройства
После чтения стопки мануалов и кучи статей решено было остановиться на связке бесплатного сертификата от Let’s Encrypt для проверки подлинности сервера и классической авторизации по логину-паролю для клиентов. Тем самым мы избавляемся от необходимости поддерживать собственную PKI-инфраструктуру, следить за сроком истечения сертификатов и проводить лишние телодвижения с мобильными устройствами, устанавливая самоподписанные сертификаты в список доверенных.
Устанавливаем недостающие пакеты:
Получаем standalone сертификат (не забываем предварительно открыть 80/tcp в настройках iptables):
После того как certbot завершил свою работу мы должны научить Strongswan видеть наш сертификат:
Перезапускаем Strongswan и при вызове sudo strongswan listcerts мы должны видеть информацию о сертификате:
После чего описываем новое соединение в ipsec.conf:
Не забываем отредактировать файл /etc/sysconfig/certbot указав, что обновлять сертификат тоже будем как standalone, внеся в него CERTBOT_ARGS=»—standalone».
Так же не забываем включить таймер certbot-renew.timer и установить хук для перезапуска Strongswan в случае выдачи нового сертификата. Для этого либо размещаем простенький bash-скрипт в /etc/letsencrypt/renewal-hooks/deploy/, либо еще раз редактируем файл /etc/sysconfig/certbot.
Перезапускаем Strongswan, включаем в iptables маскарадинг для сети 10.1.1.0/24 и переходим к настройке мобильных устройств.
Android
Устанавливем из Google Play приложение Strongswan.
Запускаем и создаем новый
Сохраняем профиль, подключаемся и, спустя секунду, можем не переживать о том, что кто-то сможет подсматривать за нами.
Windows
Windows актуальных версий приятно удивил. Вся настройка нового VPN происходит путем вызова двух командлетов PowerShell:
И еще одного, в случае если Strongswan настроен на выдачу клиентам IPv6 адреса (да, он это тоже умеет):
Часть четвертая, финальная. Прорубаем окно в Европу
Насмотревшись провайдерских заглушек «Сайт заблокирован по решению левой пятки пятого зампрокурора деревни Трудовые Мозоли Богозабытского уезда» появилась и жила себе одна маленькая неприметная VPS (с благозвучным доменным именем rkn.example.com) в тысяче километров от обезьянок, любящих размахивать банхаммером и блокировать сети размером /16 за раз. И крутилось на этой маленькой VPS прекрасное творение коллег из NIC.CZ под названием BIRD. Птичка первой версии постоянно умирала в панике от активности обезьянок с дубинками, забанивших на пике своей трудовой деятельности почти 4% интернета, уходя в глубокую задумчивость при реконфиге, поэтому была обновлена до версии 2.0.7. Если читателям будет интересно — опубликую статью по переходу с BIRD на BIRD2, в котором кардинально изменился формат конфига, но работать новая вервия стала намного быстрее и нет проблем с реконфигом при большом количестве маршрутов. А раз у нас используется протокол динамической маршрутизации, то должен быть и сетевой интерфейс, через который нужно роутить трафик. По умолчанию IPSec интерфейсов не создает, но за счет его гибкости мы можем воспользоваться классическими GRE-туннелями, которые и будем защищать в дальнейшем. В качестве бонуса — хосты ipsecgw.example.com и rkn.example.com будут аутентифицировать друга друга, используя самообновляемые сертификаты Lets Encrypt. Никаких PSK, только сертификаты, только хардкор, безопасности много не бывает.
Считаем что VPS подготовлена, Strongswan и Certbot уже установлены.
На хосте ipsecgw.example.com (его IP — 1.1.1.1) описываем новый интерфейс gif0:
Зеркально на хосте vps.example.com (его IP — 5.5.5.5):
Поднимаем интерфейсы, но поскольку в iptables нет правила, разрешающего GRE-протокол, трафик ходить не будет (что нам и надо, поскольку внутри GRE нет никакой защиты от любителей всяких законодательных «пакетов»).
Готовим VPS
Первым делом получаем еще один сертификат на доменное имя rkn.example.com. Создаем симлинки в /etc/strongswan/ipsec.d как описано в предыдущем разделе.
Правим ipsec.secrets, внося в него единственную строку:
На стороне хоста ipsecgw.example.com тоже добавляем в ipsec.conf в секцию setup параметр strictcrlpolicy = yes, включающий строгую проверку CRL. И описываем еще одно соединение:
Конфиги почти зеркальные. Внимательный читатель мог сам уже обратить внимание на пару моментов:
/rkn.example.com.pem, после чего при помощи scp перекрестно копируем их между серверами в расположения, указаные в конфиге
Не забываем настроить файрвол и автообновление сертификатов. После перезапуска Strongswan на обоих серверах, запустим ping удаленной стороны GRE-туннеля и увидим успешную установку соединения. На VPS (rkn):
И на стороне хоста ipsecgw
Туннель установлен, пинги ходят, в tcpdump видно что между хостами ходит только ESP. Казалось бы можно радоваться. Но нельзя расслабляться не проверив всё до конца. Пробуем перевыпустить сертификат на VPS и…
Шеф, всё сломалось
Начинаем разбираться и натыкаемся на одну неприятную особенность прекрасного во всём остальном Let’s Encrypt — при любом перевыпуске сертификата меняется так же ассоциированный с ним закрытый ключ. Изменился закрытый ключ — изменился и открытый. На первый взгляд ситуация для нас безвыходная: если даже открытый ключ мы можем легко извлечь во время перевыпуска сертификата при помощи хука в certbot и передать его удаленной стороне через SSH, то непонятно как заставить удаленный Strongswan перечитать его. Но помощь пришла откуда не ждали — systemd умеет следить за изменениями файловой системы и запускать ассоциированные с событием службы. Этим мы и воспользуемся.
Создадим на каждом из хостов служебного пользователя keywatcher с максимально урезанными правами, сгенерируем каждому из них SSH-ключи и обменяемся ими между хостами.
На хосте ipsecgw.example.com создадим каталог /opt/ipsec-pubkey в котором разместим 2 скрипта.
На VPS (хосте rkn.example.com) аналогично создаем каталог с тем же именем, в котором тоже создаем аналогичные скрипты, изменяя только название ключа. Код, чтобы не загромождать статью, под
sudo vi /opt/ipsec-pubkey/pubkey-copy.sh
Скрипт pubkey-copy.sh нужен для извлечения открытой части ключа и копирования его удаленному хосту во время выпуска нового сертификата. Для этого в каталоге /etc/letsencrypt/renewal-hooks/deploy на обоих серверах создаем еще один микроскрипт:
Половина проблемы решена, сертификаты перевыпускаются, публичные ключи извлекаются и копируются между серверами и пришло время systemd с его path-юнитами.
На сервере ipsecgw.example.com в каталоге /etc/systemd/system создаем файл keyupdater.path
Аналогично на VPS хосте:
И, напоследок, на каждом сервере создаем ассоциированную с данным юнитом службу, которая будет запускаться при выполнении условия (PathChanged) — изменении файла и его закрытии его после записи. Создаем файлы /etc/systemd/system/keyupdater.service и прописываем:
Не забываем перечитать конфигурации systemd при помощи sudo systemctl daemon-reload и назначить path-юнитам автозапуск через sudo systemctl enable keyupdater.path && sudo systemctl start keyupdater.path.
Как только удаленный хост запишет файл, содержащий публичный ключ, в домашний каталог пользователя keywatcher и файловый дескриптор будет закрыт, systemd автоматически запустит соответствующую службу, которая скопирует ключ в нужное расположение и перезапустит Strongswan. Туннель будет установлен, используя правильный открытый ключ второй стороны.
Можно выдохнуть и наслаждаться результатом.
Вместо заключения
Как мы только что увидели чёрт IPSec не так страшен, как его малюют. Всё, что было описано — полностью рабочая конфигурация, которая используется в настоящее время. Даже без особых знаний можно настроить VPN и надежно защитить свои данные.
Конечно за рамками статьи остались моменты настройки iptables, но и сама статья уже получилась и без того объемная и про iptables написано много.
Есть в статье и моменты, которые можно улучшить, будь-то отказ от перезапусков демона Strongswan, перечитывая его конфиги и сертификаты, но у меня не получилось этого добиться.
Впрочем и рестарты демона оказались не страшны: происходит потеря одного-двух пингов между пирами, мобильные клиенты тоже сами восстанавливают соединение.
Надеюсь коллеги в комментариях подскажут правильное решение.


