ORM: почему эта задача не имеет решения, но делать с этим, тем не менее, что-то нужно

Современные информационные технологии поражают своей мощью, ошеломляют открывающимися возможностями, обескураживают заложенным в них техническим совершенством, но есть один смехотворный пункт, об который IT раз за разом снова и снова ломает зубы. Показать пользователю данные из базы, получить от него ввод, положить обратно в базу, показать результат. Поля ввода, кнопочки, галочки, надписи — казалось бы, что в них может быть такого запредельно сложного, чтобы потребовалось городить головоломные конструкции типа фреймворков поверх шаблонизаторов поверх фреймворков поверх транспайлеров? И почему несмотря на все колоссальные усилия мы имеем то, что игрушечные примеры по туториалу, конечно, делаются легко и приятно, но как только инструментарий сталкивается с реальными задачами реальной жизни… как бы это сказать помягче… с ростом сложности решаемых задач наблюдается сильная нелинейность возрастания сложности реализации. Ладно бы речь шла о чём-то действительно головоломном уровня теоретической физики или космической техники, так ведь нет же — кнопочки и галочки. Почему эта ерунда десятилетиями продолжает отравлять жизнь гражданам и трудовым коллективам?
Причин, наверно, как всегда оно бывает, много. Наверно все они так или иначе достойны рассмотрения, но здесь и сейчас мы поговорим о задаче объектно-реляционного отображения (Object-Relational Mapping, ORM), которая всегда в каком-либо виде стоит за всеми этими «кнопочками и галочками».
Что мы знаем про ORM
Почему всё так причудливо
Идейная основа теории и практики реляционных баз данных — исчисление предикатов, то есть раздел математики. Что касается ООП, то аналогичная по прочности идейная основа там отсутствует. Базовую идею ООП можно попытаться сформулировать примерно так: поскольку мир состоит из объектов, то его, этот мир, было бы удобно моделировать созданием объектов внутри программной системы. В этом понимании сразу две ошибки. Во-первых, мир сам по себе не состоит и никогда не состоял из объектов. Во-вторых, извините, но зачем программа обязательно должна моделировать мир? То есть мы имеем концептуально неверное утверждение, прекрасно дополняемое бессмысленной постановкой задачи.
Всякий ORM – попытка чётко протянуть унифицированное соответствие между, по сути, разделом математики и рыхлым набором разнообразных практик, основанном на соображениях удобства, исторически сложившихся подходах, а также зачастую на легендах, мнениях авторитетов, да и просто заблуждениях. In vitro это можно заставить работать, но in vivo оно обречено выглядеть жалко и приносить больше горя, чем радости.
О неизбежности объектной ориентированности
Тем не менее, необходимость объектной ориентированности нашего софта — наша неизбежная реальность. Неизбежность эта основана в первую очередь на том, что оперирование объектами составляет суть и основу любой нашей деятельности. Мир сам по себе не состоит из объектов, но для того, чтобы что-то в этом мире понять и что-то с этим миром сделать, мы сами для себя объявляем его части объектами, называем их именами, пытаемся понять их поведение, прикладываем к ним усилия для получения желаемых результатов. Это наш способ функционирования, и уйти от него невозможно, да и не нужно. Всё есть объект не потому, что так оно и есть на самом деле, а потому, что мы по-другому не можем. То, что никоим образом не может являться объектом, полностью лежит за пределами нашей способности осмысления и не может служить предметом приложения наших усилий.
Даже если программа написана без использования техник ООП, в ней неизбежно присутствуют объекты (в широком смысле этого слова), манипулируя которыми разработчик решает свою задачу — переменные, типы данных, операторы, алгоритмы, синтаксические конструкции, функции, модули. С точки зрения пользователя программа тоже есть набор объектов, с которыми он взаимодействует — кнопки, надписи, поля ввода, страницы, сайты, да и вся система целиком.
Что мы храним в своих базах данных
Как говорилось выше, реляционные базы данных основываются на исчислении предикатов. Предикат — это сформулированный и в нашем случае сохранённый на носитель факт. На всякий случай замечу, что реляционность базы данных — это не только и не столько про связи между таблицами по внешним ключам. В правильной терминологии отношениями (relations) называется то, что мы по-простому называем таблицами. То есть даже если в вашей базе всего одна таблица с двумя колонками (например, имя и номер телефона), у вас уже реляционная база, устанавливающая отношение между двумя множествами, в данном случае множествами имён и номеров телефонов. Реляционная база не хранит объекты, она хранит факты. Хранимые факты, конечно же, имеют предмет («о чём этот факт?»), и когда мы пытаемся научить систему отвечать на этот вопрос, у нас появляются сущности, то есть объекты, с которыми связаны факты. Если работать правильно, структура базы у нас рождается из серии ответов на вопрос «какого рода факты мы намерены сохранять?», и лишь на следующем этапе у нас появляется нечто, напоминающее объекты, придающие фактам предметность. Можно, конечно, проектировать и «от объектов», но я бы не рекомендовал так делать иначе как на лабораторных работах по предметам, не связанным напрямую с проектированием баз данных. Слишком велика опасность тяжёлых архитектурных просчётов. Кроме того, это как минимум неудобно.
Небольшое лирическое отступление про объектные базы данных. Очень простая мысль: если мы устали от проблем с ORM, то, может быть, нам сделать что-нибудь с той его частью, которая «R»? Пусть наша база данных будет не жёстким и требовательным реляционным чудовищем, а чем-нибудь модным молодёжным, специально заточенным на хранение объектов. Какая-нибудь бессхемная NoSQL-база, например. Но в конечном итоге внезапно оказывается, что NoSQL-ные ORM ещё кривее и противоестественнее, чем старые добрые SQL-ные. Да и вообще, иметь и с удовольствием эксплуатировать бессхемную СУБД мы можем, но бессхемных данных в природе не бывает. Нет ничего более беспомощного, безответственного и безнравственного, чем ORM для бессхемных баз данных.
Хороший ORM
Хороший ORM – отсутствующий ORM. Ну серьёзно. Посмотрите на любую из своих использующих ORM систем и честно попытайтесь ответить себе на вопрос: какие профиты приносит этот монстр? Чем обусловлено его применение кроме как несбывшимися обещаниями счастья и многократно дискредитировавшими себя предрассудками? Безусловно, найдутся некоторые полезные удобняшки, но что они на фоне привносимых архитектурных деформаций и постоянно возникающих на ровном месте проблем с производительностью?
Как правило, «низкоуровневый» API базы данных прост, удобен, полн и консистентен. Обычно хватает пальцев рук для того, чтобы перечислить все функции. Выучить их — не бог весть какая задача.
Попробую набросать набор архитектурных принципов, позволяющих замэппить объекты на базу данных без использования ORM:
Итого
ORM – очень больная для нашей индустрии тема. В эпоху, когда облачный искусственный интеллект бороздит просторы квантового блокчейна, подавляющее большинство трудовых ресурсов занято прикручиванием бизнес-логики и пользовательского интерфейса к базам данных. Миллионы строк ужасного кода, забивание гвоздей микроскопами, боль и отчаяние повсеместно сопровождают этот творческий процесс. Один из корней этого печального положения дел — чрезвычайно стойкое заблуждение, что универсальный ORM в принципе возможен. А он невозможен, и этому есть фундаментальная причина, не подлежащая устранению. Осознание этого факта — первый шаг по направлению к выходу из этого кошмара. Выход — возможен, альтернативы — есть, но сначала — осознать, прочувствовать и научиться держать в фокусе внимания.
ORM или как забыть о проектировании БД
От автора
Что такое ORM?
Прежде чем учить кого-то уму-разуму стоит понять что представляет из себя термин ORM. Согласно аналогу БСЭ, аббревиатура ORM скрывает буржуйское «Object-relational mapping», что в переводе на язык Пушкина означает «Объектно-реляционное отображение» и означает «технология программирования, которая связывает базы данных с концепциями объектно-ориентированных языков программирования»… т.е. ORM — прослойка между базой данных и кодом который пишет программист, которая позволяет созданые в программе объекты складывать/получать в/из бд.
Все просто! Создаем объект и кладем в бд. Нужен этот же объект? Возьми из бд! Гениально! НО! Программисты забывают о первой буковке абравиатуры и пхнут в одну и ту же табличку все! Начиная от свойств объектов, что логично, и, заканчивая foreign key, что никакого отношения к объекту не имеет! И, что самое страшное, многие тонны howto и example пропагандируют такой подход… мне кажется что первопричина кроется в постоянной балансировке между «я программист» и «я архитектор бд», а т.к. ORM плодятся и множатся — голос программиста давлеет над архитекторским. Все, дальше боли нет, только imho.
«Кто Вы, Мистер Брукс?» или «Что такое объект?»
Тяжкое наследие ООП
Критикам посвящается
После высказывания своих мыслей руководителю я получил вполне ожидаемую реакцию: «Зачем так усложнять? KISS!»
Пришлось «набраться опыта»:
Были случаи с циклическими связями между объектами содержащими среди свойств fkey и задачей «бекапа/сериализации» этого безобразия в xml/json. Нет, бекапы то делаются, вот восстанавливать потом это безобразие чертовски сложно… необходимо жестко отслеживать какие свойства создаются при восстановлении/десериализации, а потом повторно проходить по объектам и восстанавливать связи между ними. Придерживаясь правила выше — надо сначала восстановить объекты, а уж потом связи между ними. Т.к. хранится эта информация в разных таблицах/сущностях — логика была линейной и простой.
На каждый выпад «возьми монгу и не парься» или «документо-ориентированые бд рулят» я всегда приходил к одному и тому же результату который еще никто покрыть не смог:
Я смогу создать схему в реляционной бд которая будет сохранять произвольную структуру данных (произвольные документы), а вот сможете ли вы в документо-ориентированой бд гарантирвать целостность данных на уровне реляционых бд? Я не смог достич такого уровня.
Никого не смущает множественные куски повторяющихся документов с произвольным уровнем вложенности? Не, я знаю что их хранение оптимизировано и вобще, тебе какая разница? Но все же.
Python: Работа с базой данных, часть 2/2: Используем ORM
Это вторая часть моей статьи по работе с базой данных в Python. В первой части мы рассмотрели основные принципы коммуникации с SQL базой данных, а в этой познакомимся с инструментарием, позволяющим облегчить нам это взаимодействие и сократить количество нашего кода в типовых задачах.
Статья ориентирована в первую очередь на начинающих, она не претендует на исчерпывающе глубокое изложение, а скорее дает краткую вводную в тему, объясняет самые востребованные подходы для старта и иллюстрирует это простыми примерами базовых операций. 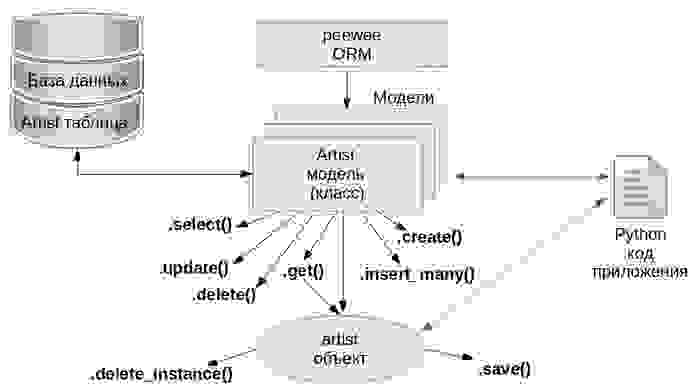
Требуемый уровень подготовки: базовое понимание SQL и Python (код статьи проверялся под Python 3.6). Желательно ознакомится с первой частью, так как к ней будут неоднократные отсылки и сравнения. В конце статьи есть весь код примеров под спойлером в едином файле и список ссылок для более углубленного изучения материала.
1. Общие понятия ORM
В нашем коде мы работаем с объектами разной природы, а при работе с SQL базой данных мы вынуждены постоянно генерировать текстовые запросы к базе, а получив ответ от базы обратно его преобразовывать в формат данных нашего приложения.
Хорошо было бы иметь некий механизм автоматического генерирования этих запросов исходя из заранее определенной структуры наших данных и приведения ответа к этой же структуре. Именно таким механизмом является добавление дополнительной ORM-прослойки между кодом нашего приложения и SQL базой.
В случае высоко нагруженных проектов использование такой прослойки может вызывать дополнительный расход ресурсов и требовать тонкой настройки, но это выходит за рамки нашей статьи.
Существуют два основных подхода к реализации ORM:
Active Record – более простой для понимания и реализации подход, суть которого сводится к отображению объекта данных на строку базы данных.
Data Mapper – в отличии от предыдущего подхода полностью разделяет представление данных в программе от его представления в базе данных.
У обоих подходов есть свои свои особенности, преимущества и недостатки, в зависимости от того, какого типа приложение Вы разрабатываете. В конце статьи есть несколько ссылок на статьи в которых подробно сравниваются эти два подхода с примерами.
В данном руководстве будет проиллюстрирован более простой и понятный для старта подход Active Record. Мы будем рассматривать основы работы с peewee – лёгкой, быстрой, гибкой ORM на Python, которая поддерживает SQLite, MySQL и PostgreSQL.
Безопасность и SQL-инъекции
По умолчанию peewee будет параметризовать запросы, поэтому любые параметры, передаваемые пользователем, будут экранированы и безопасны.
Единственное исключение этому правилу это передаваемые прямые SQL запросы, передаваемые в SQL объект, которые могут содержать небезопасные данные. Для защиты от такой уязвимости, передавайте данные как параметры запроса, а не как часть SQL запроса. Тема экранирования данных обсуждалась в первой части статьи.
2. Установка ORM, соединение с базой, получение курсора
В качестве тестовой базы данных будем использовать туже самую тестовую Chinook SQLite базу, что и в первой части статьи, там также в первой части есть примеры средств для наглядного просмотра содержимого этой базы.
В отличии от модуля sqlite из стандартной библиотеки, peewee прежде чем импортировать надо установить:
Для начала рассмотрим самый базовый шаблон DB-API, который будем использовать во всех дальнейших примерах:
Собственно говоря, этот шаблон крайне похож на тот, который мы использовали в первой статье, отличие в методе соединения с базой данных. Теперь мы подключаемся через метод библиотеки peewee:
В зависимости от типа нашей базы методы подключения отличаются: SqliteDatabase(),
MySQLDatabase(), PostgresqlDatabase() — какой для какой базы очевидно из имени, в скобках передаются параметры подключения, в нашем примере это просто имя файла базы.
Обратите внимание, подключение ORM в данном случае не отбирает возможность использовать курсор для обычных запросов к базе, как мы делали в первой статье. При этом ORM выполняет функцию драйвера базы и нет необходимости дополнительно импортировать отдельно модуль sqlite.
То есть, мы можем взять наш новый шаблон, вставить в него код из первой статьи и получить ровно тот же результат:
Это может быть очень удобно при постепенном переходе на ORM, так как мы можем сменить способ соединения с базой на работу через peewee и потом постепенно менять запросы к базе на новые, не нарушая работу старого кода!
3. Описание моделей и их связь с базой данных
Для работы с нашими данными через ORM мы для начала должны описать модели наших данных, чтобы построить связь между базой и объектами данных в нашем приложении.
Классы моделей, поля экземпляров и экземпляры моделей peewee соответствуют следующим концепциям базы данных:
| ORM концепция | Концепция базы данных |
|---|---|
| Класс модели | Таблица базы данных |
| Поле экземпляра (атрибут объекта) | Колонка в таблице базы данных |
| Экземпляр модели (объект) | Строка в таблице базы данных |
Для реальных проектов, имеет смысл вынести модели в отдельный файл или файлы, в нашем упрощенном учебном примере мы просто вставляем код определения модели сразу после строки соединения с базой данных, вместо строки # ТУТ БУДЕТ КОД НАШИХ МОДЕЛЕЙ
В данной статье не будем заострять внимание на различные типы полей и их связь с типами данных в различных базах данных. В документации к peewee есть детальная таблица связи между типом поля в нашей модели и в базе данных.
Обратите внимание, что требования сразу задать модели для всех таблиц нет. То есть в нашей тестовой базе есть несколько таблиц, но для наших примеров мы сейчас опишем только одну и будем дальше с ней работать, не трогая остальные. Таким образом, можно постепенно переводить код на ORM, не нарушая работу старого кода.
Замечание: Есть возможность автоматической генерации моделей из существующей базы данных, а также возможность генерации таблиц базы данных из заранее определенных моделей. Для подобных задач в peewee есть набор инструментария, так называемый Playhouse.
4. CRUD операции и общие подходы
Ниже мы рассмотрим так называемые CRUD операции с базой – создание (Create), чтение (Read), обновление (Update) и удаления (Delete) объектов/записей в базе. Мы не будем пытаться охватить все многообразие возможностей которые предоставляет нам peewee, рассмотрим только самые базовые вещи, которые позволят нам начать решать реальные задачи разработки. Более детальные описания можно найти в официальной документации.
Есть два основных подхода при работе с ORM peewee, в зависимости от того, какую задачу мы решаем и как нам удобней это делать:
Как это работает будем понятней из примеров CRUD операций ниже.
5. Чтение записей
5.1) Получение одиночной записи с методом модели Model.get()
Теперь у нас есть объект artist, с полями соответствующим данным исполнителя в конкретной строке, а также доступными методами модели исполнителя.
Этот объект можно использовать не только для чтения данных, но и для их обновления и удаления данной записи, в чем убедимся позже.
5.2) Получение набора записей через нашу модель Model.select()
Это похоже на стандартный select запрос к базе, но осуществляемый через нашу модель.
Обратите внимание, что к какой таблице обращаться и какие поля у нее есть
уже определено в нашей модели и нам не надо это указывать в нашем запросе.
Формируем запрос к базе с помощью нашей ORM прослойки и смотрим как этот запрос будет выглядеть:
Полезно добавить дополнительные параметры, уточняющие запрос, они очень похожи на SQL инструкции:
Теперь, определившись с запросом к базе, мы можем получить от нее ответ, для удобства делаем это сразу в виде словаря
Мы получили итератор по полученным из базы записям, который можно обходить в цикле
for artist in artists_selected и получать сразу словари, соответствующие структуре нашего исполнителя, каждая итерация соответствует одной строке таблицы и соответственно одному исполнителю:
Для упрощения дальнейшей визуализации изменений в базе при дальнейших наших операциях добавим в наш шаблон под определением моделей код следующей функции:
Из кода достаточно очевидно, что функция просто выводит на печать 5 последних записей исполнителей с базы, что позволит нам видеть какие данные добавились, обновились или удалились в примерах ниже.
Обращаем внимание, что вывод будет совпадать с примерами в статье, только если их выполнять последовательно, начиная с неизмененной Chinook базы, так как как примеры модифицируют базу!
6. Создание записи
6.1) Первый способ: Model.create() — передаем все требуемые параметры сразу
Визуализируем последние 5 записей в таблице исполнителей, чтобы убедится, что три примера выше доавили нам 4 новые записи:
7. Обновление записей
7.1) Первый способ обновления записей.
Выше, способом 6.2 мы создавали новую запись, но так можно не только создавать новую запись, но и обновлять существующую. Для этого нам надо для нашего объекта указать уже существующий в таблице первичный ключ.
Обзор ORM для Qt
Введение
Добрый день, уважаемые коллеги-программисты!
Вот уже год в мире Qt происходят очень интересные события. Здесь вам и недавний выпуск версии 4.7, и концепция QML, и значительная интеграция библиотеки в мобильные платформы. В Qt водятся самые правильные тролли; мне нравится то, что они делают, и куда развивается эта библиотека. Готов даже поспорить, что она – лучшая в своем классе, но те, кто пишут на Qt, и так это знают.
(Замечу сразу, что статья в некоторой степени рекламная, поскольку появилась она из-за моей собственной ORM; однако, справедливости ради, я не только пиарю себя, но и даю общую оценку того, что сейчас есть по теме. Прошу отнестись с пониманием: намерения самые благие).
QxOrm, ver. 1.1.1

Автор / владелец: «QxOrm France»
Сайты: официальный, на SourceForge
Лицензия: GPLv3 + коммерческая
Зависимости: Qt (4.5+), boost (1.38+)
Период разработки: начало 2010, последнее изменение – апрель 2010
Документация: неполная, на французском
Примеры: есть, самые базовые
Главная цель разработки – предоставить механизмы persistence (через QtSql), serialization (через boost::serialization) и reflection.
Библиотека выглядит весьма сильно и, кажется, умеет много всего. Построена по принципу DAO (Data Access Object), когда есть класс-отображение строки в таблице, и какими-то методами из БД извлекается список таких строк. Чтобы это было возможно, в QxOrm используются очень хитрые механизмы, в том числе шаблоны (очень много шаблонов), макросы, наследование простое и множественное. Код весьма интересен для ознакомления, если вы – любитель программистских ухищрений или, например, вам нравится Александреску.
Пример класса-маппера (весь код взят из документации):
class drug
<
public :
long id ;
QString name ;
QString description ;
drug ( ) : id ( 0 ) < ; >
virtual
QX_REGISTER_CPP_MY_TEST_EXE ( drug ) // This macro is necessary to register ‘drug’ class in QxOrm context
Пример использования:
// Create table ‘drug’ into database to store drugs
QSqlError daoError = qx :: dao :: create_table drug > ( ) ;
// Insert drugs from container to database
// ‘id’ property of ‘d1’, ‘d2’ and ‘d3’ are auto-updated
daoError = qx :: dao :: insert ( lst_drug ) ;
// Delete the first drug from database
daoError = qx :: dao :: delete_by_id ( d1 ) ;
// Count drugs into database
long lDrugCount = qx :: dao :: count drug > ( ) ;
// Export drugs from container to a file under xml format (serialization)
qx :: serialization :: xml :: to_file ( lst_drug, «./export_drugs.xml» ) ;
// Import drugs from xml file into a new container
type_lst_drug lst_drug_tmp ;
qx :: serialization :: xml :: from_file ( lst_drug_tmp, «./export_drugs.xml» ) ;
// Clone a drug
drug_ptr d_clone = qx :: clone ( * d1 ) ;
// Create a new drug by class name (factory)
boost :: any d_any = qx :: create ( «drug» ) ;
Автор: Jeremy Lainé, Bolloré telecom
Сайты: официальный, mailing list
Лицензия: GPLv3, LGPLv3
Зависимости: Qt (4.5+)
В разработке с 3 июня 2010
Документация: полная, на английском, doxygen-generated
Примеры: есть, самые базовые.
Главная цель: создать свободную ORM для Qt, максимально похожую на Django.
О достоинствах и недостатках данной разработки говорить пока рано, библиотека еще ничего не умеет. Судя по всему, это будет DAO / Active Record-ORM. Сейчас уже можно генерировать SELECT, извлекать данные в контейнер, создавать таблицы через генерацию CREATE TABLE. Автор сразу же начал прописывать генерацию WHERE; причем поддерживаются операторы AND и OR. То есть, можно создать многоуровневый фильтр, и синтаксис задания фильтров тоже удачный. В разработке активно используются те же методы, что и в QxOrm: шаблоны, наследование… На их основе, надо полагать, автор собирается создать огромные фермы хорошего ООП-кода.
Но это – и всё. Будем верить, что года через полтора из QDjango вырастет мощная ORM-система, а пока о ее применении в проектах говорить не приходится.
Пример использования, взятый у автора.
// all users
QDjangoQuerySet User > users ;
// get number of matching users
int numberOfUsers = someUsers. size ( ) ;
// retrieve the first matching user
User * firstUser = someUsers. at ( 0 ) ;
// free memory
delete firstUser ;
// retrieve list of usernames and passwords for matching users
QList QList QVariant > > propertyLists = someUsers. valuesList ( QStringList ( ) «username» «password» ) ;
// delete all the users in the queryset
someUsers. remove ( ) ;
Класс User:
class User : public QDjangoModel
<
Q_OBJECT
Q_PROPERTY ( QString username READ username WRITE setUsername )
Q_PROPERTY ( QString password READ password WRITE setPassword )
public :
QString username ( ) const ;
void setUsername ( const QString & username ) ;
QString password ( ) const ;
void setPassword ( const QString & password ) ;
private :
QString m_username ;
QString m_password ;
> ;
QtPersistence, ver. 0.1.1
Автор: Matt Rogers
Сайты: на SourceForge
Лицензия: LGPLv3
Зависимости: Qt (4.5+)
Период разработки: конец 2009 – начало 2010 г.
Документация: нет
Примеры: плохие в unit-тестах
Главная цель: создать ORM для Qt, основанную на подходе Active Record, похожую на некоторые (?) ORM для Ruby.
Еще одна библиотека, которая практически ничего не умеет. Что хуже: и не развивается; похоже, автор забросил этот проект. Собственно, все, что она может – это с помощью класса-маппера записывать данные в базу данных.
Единственные примеры использования найдены в unit-тестах (основанных на самописном модуле тестирвования).
class FakeBook : public QPersistantObject
<
Q_OBJECT
Q_PROPERTY ( QString author READ author WRITE setAuthor )
Q_PROPERTY ( int yearPublished READ yearPublished WRITE setYearPublished )
public :
Q_INVOKABLE FakeBook ( QObject * parent = 0 ) : QPersistantObject ( parent ) < >
virtual
void setAuthor ( const QString & a ) < m_author = a ; >
QString author ( ) const
void setYearPublished ( int year ) < m_yearPublished = year ; >
int yearPublished ( ) const
private :
QString m_author ;
int m_yearPublished ;
> ;
QsT SQL Tools (QST), ver. 0.4.2a release
Автор: Александр Гранин (я 🙂 )
Сайты: на SourceForge, форум
Лицензия: GPLv3, LGPLv3
Зависимости: Qt (4.5+)
В разработке с сентября 2009 г.
Документация: полная, doxygen-generated, только на русском
Примеры: есть, в коде, в unit-тестах; так же мною созданы специальные проекты-примеры TradeDB для версий 0.3 и 0.4 – полноценные приложения БД.
Главная цель – облегчить программирование приложений БД под Qt.
Говорить о своей ORM нелегко. Попал на Хабр я именно благодаря ей, написав статью в песочницу. Статья интерес не вызвала… Но то была версия 0.3 – и даже не релизная, а pre-alpha. Сейчас я далеко ушел в разработке QST, и доступна уже 0.5.1 pre-alpha; но всё же впереди есть очень много всего, что нужно сделать.
Прежде всего: это не обычная ORM. Библиотеку я начал писать, еще не зная этого термина; мне был нужен инструмент генерации запросов, чтобы не писать их, и чтобы они были сосредоточены в одном слое: так проще было за ними следить. О таких подходах, как Active Record, я и не знал. В итоге получилось то, что получилось: самобытная ORM, которая не совсем ORM. В ней нельзя настроить поля класса, которые бы отобразились на поля таблицы; в ней нельзя писать (читать) данные прямо в (из) БД, используя лишь присвоение. Зато можно много чего другого.
В целом, библиотека ещё в развитии, но уже умеет многое всего. Я её применяю в своей работе; и как фрилансер пишу на ней еще один проект. В целом, на программиста ложится гораздо меньше работы, чем с той с QxOrm или с QDjango, – это видно по исходникам примеров. Описал хэндлеры, загрузил в них view – получай возможности, которые почти все расположены в главном классе (QstAbstractModelHandler). Всё, что нужно, я внедряю потихоньку, но ко мне всегда можно обратиться, – обязательно помогу. В отличие от. Поэтому нескромно предлагаю поддержать меня в этом непростом начинании. Хоть даже пожеланием удачи; а лучше – любым отзывом. Буду признателен.
Пример класса-хэндлера и DFD-описателя для запроса SELECT.
// personshandler.h
const int PERSONS = 1 ;
const int PERSONS_FULL_NAME = 2 ;
class PersonsHandler : public QstAbstractModelHandler
<
private :
QstBatch _selector ( const int & queryNumber ) const ;
QstBatch _executor ( const int & queryNumber ) const ;
> ;
// personshandler.cpp
QstBatch PersonsHandler :: _selector ( const int & queryNumber ) const
<
QstBatch batch ;
if ( queryNumber == PERSONS )
<
batch. addSource ( «vPersons» ) ;
batch QstField ( RolePrimaryKey, «ID» )
QstField ( «Address_ID» )
QstField ( RolePrimaryKey, «ID» )
QstField ( «Address_ID» )
;
>
else
<
Q_ASSERT ( false ) ;
>
Настройка представления:
QVariant PersonsForm :: personID ( ) const
<
return _personsHandler. keyValueOfView ( ) ;
>


