Критические значения для проверки статистической гипотезы и как их вычислить в Python
Дата публикации 2018-06-11
Обычно, если не стандартно, интерпретируют результаты статистических проверок гипотез, используя p-значение.
Не все реализации статистических тестов возвращают p-значения. В некоторых случаях вы должны использовать альтернативы, такие как критические значения. Кроме того, критические значения используются при оценке ожидаемых интервалов для наблюдений от населения, например, в интервалах толерантности.
В этом руководстве вы узнаете критические значения, почему они важны, как они используются и как их рассчитать в Python с использованием SciPy.
После завершения этого урока вы узнаете:

Обзор учебника
Этот урок разделен на 4 части; они есть:
Зачем нам нужны критические ценности?
Многие статистические тесты гипотез возвращают p-значение, которое используется для интерпретации результатов теста.
Некоторые тесты не возвращают значение p, что требует альтернативного метода для прямой интерпретации вычисленной статистики теста.
Статистика, рассчитанная с помощью теста статистической гипотезы, может быть интерпретирована с использованием критических значений из распределения статистики теста.
Ниже приведены некоторые примеры тестов статистических гипотез и их распределений, из которых можно рассчитать критические значения:
Критические значения также используются при определении интервалов для ожидаемых (или неожиданных) наблюдений в распределениях. Расчет и использование критических значений может быть целесообразным при количественной оценке неопределенности оценочных статистических данных или интервалов, таких как доверительные интервалы и интервалы допуска.
Что такое критическая ценность?
критическое значениеопределяется в контексте распределения населения и вероятности.
Наблюдение от населения со значением, равным или меньшим, чем критическое значение с заданной вероятностью.
Мы можем выразить это математически следующим образом:
кудаPrэто расчет вероятности,Иксявляются наблюдениями от населения,critica_valueрассчитанное критическое значение, ивероятностьэто выбранная вероятность.
Критические значения рассчитываются с использованием математической функции, в которой вероятность указана в качестве аргумента. Для большинства распространенных распределений значение не может быть рассчитано аналитически; вместо этого он должен быть оценен с использованием численных методов. Исторически сложилось так, что таблицы предварительно рассчитанных критических значений приводятся в приложениях к учебникам статистики для справочных целей.
Критические значения используются в тестировании статистической значимости. Вероятность часто выражается как значение, обозначаемое как строчная греческая буква альфа (а), которая является перевернутой вероятностью.
Стандартные альфа-значения используются при расчете критических значений, выбираются по историческим причинам и постоянно используются по соображениям согласованности. Эти альфа-значения включают в себя:
Критические значения обеспечивают альтернативный и эквивалентный способ интерпретации статистических тестов гипотезр-значение,
Как использовать критические значения
Рассчитанные критические значения используются в качестве порога для интерпретации результатов статистического теста.
Значения наблюдений в популяции за пределами критического значения часто называют «критическая область» или «область отказа«.
Критическое значение: значение, указанное в таблицах для указанных статистических тестов, показывающее, при каком вычисленном значении нулевая гипотеза может быть отклонена (вычисленная статистика попадает в область отклонения).
Односторонний тест
Односторонний тест имеет одно критическое значение, например слева или справа от распределения.
Часто односторонний критерий имеет критическое значение справа от распределения для несимметричных распределений (таких как распределение хи-квадрат).
Статистика сравнивается с рассчитанным критическим значением. Если статистика меньше или равна критическому значению, нулевая гипотеза статистического теста не может быть отклонена. В противном случае он отклонен
Мы можем обобщить эту интерпретацию следующим образом:
Двусторонний тест
Двухсторонний тест имеет два критических значения, по одному на каждой стороне распределения, которое часто считается симметричным (например, распределение Гаусса и Стьюдента-t).
При использовании двустороннего теста уровень значимости (или альфа), используемый при расчете критических значений, должен делиться на 2. Критическое значение будет затем использовать часть этой альфа на каждой стороне распределения.
Чтобы сделать этот бетон, рассмотрите альфа 5%. Это будет разделено, чтобы получить два альфа-значения 2,5% по обе стороны от распределения с областью принятия в середине распределения 95%.
Мы можем обратиться к каждому критическому значению как к нижнему и верхнему критическим значениям для левого и правого распределения соответственно. Статистические значения теста, большие или равные нижнему критическому значению и меньшие или равные верхнему критическому значению, указывают на неспособность отклонить нулевую гипотезу. Принимая во внимание, что значения статистики теста меньше, чем нижнее критическое значение и больше, чем верхнее критическое значение, указывают на отклонение нулевой гипотезы для теста.
Мы можем обобщить эту интерпретацию следующим образом:
Если распределение тестовой статистики симметрично относительно среднего значения, равного нулю, то мы можем сократить проверку, сравнив абсолютное (положительное) значение тестовой статистики с верхним критическим значением.
куда| Тестовая статистика |является абсолютным значением вычисленной статистики теста.
Как рассчитать критические значения
Функции плотности возвращают вероятность наблюдения в распределении. Напомним определения PDF и CDF следующим образом:
Чтобы рассчитать критическое значение, нам требуется функция, которая с учетом вероятности (или значимости) будет возвращать значение наблюдения из распределения.
В частности, нам требуется обратная функция кумулятивной плотности, где с учетом вероятности нам дается значение наблюдения, которое меньше или равно вероятности. Это называется функцией процента (PPF), или, в более общем смысле,квантильная функция,
В частности, значение из распределения будет равно или меньше значения, возвращенного из PPF с указанной вероятностью.
Давайте сделаем этот бетон с тремя распределениями, из которых обычно требуется вычислять критические значения. А именно, распределение Гаусса, t-распределение Стьюдента и распределение хи-квадрат.
Мы можем рассчитать функцию процента в SciPy, используяППФ ()функция на данном распределении. Следует также отметить, что вы также можете рассчитатьППФ ()используя обратную функцию выживания под названиемISF ()в SciPy. Это упоминается, поскольку вы можете увидеть использование этого альтернативного подхода в стороннем коде.
Гауссовские критические значения
В приведенном ниже примере вычисляется функция процентной точки для 95% по стандартному распределению Гаусса.
При запуске примера сначала выводится значение, которое отмечает 95% или менее наблюдений из распределения около 1,65. Это значение затем подтверждается путем извлечения вероятности наблюдения из CDF, которая возвращает 95%, как и ожидалось.
Мы можем видеть, что значение 1,65 совпадает с нашими ожиданиями в отношении числа стандартных отклонений от среднего значения, которые покрывают 95% распределения в68–95–99,7 правило,
Студенческие т Критические ценности
В приведенном ниже примере вычисляется функция процентного пункта для 95% для стандартного t-распределения Стьюдента с 10 степенями свободы.
Выполнение примера возвращает значение около 1,812 или менее, которое покрывает 95% наблюдений из выбранного распределения. Вероятность значения затем подтверждается (с незначительной ошибкой округления) через CDF.
Критические значения хи-квадрат
В приведенном ниже примере вычисляется функция процентной точки для 95% для стандартного распределения Хи-квадрат с 10 степенями свободы.
При запуске примера сначала вычисляется значение 18,3 или менее, которое охватывает 95% наблюдений из распределения. Вероятность этого наблюдения подтверждается его использованием в качестве входных данных для CDF.
Дальнейшее чтение
Этот раздел предоставляет больше ресурсов по теме, если вы хотите углубиться.
книги
статьи
Резюме
В этом руководстве вы обнаружили критические значения, почему они важны, как они используются и как их вычислить в Python с использованием SciPy.
В частности, вы узнали:
У вас есть вопросы?
Задайте свои вопросы в комментариях ниже, и я сделаю все возможное, чтобы ответить.
How to use norm.ppf()?
I couldn’t understand how to properly use this function, could someone please explain it to me?
When I’m asked to calculate the (95%) margin of error using norm.ppf() will the code look like below?
or will it look like this?
Because I know it’s calculating the area of the curve to the right of the confidence interval (95%, 97.5% etc. see image below), but when I have a mean and a standard deviation, I get really confused as to how to use the function.

4 Answers 4
The method norm.ppf() takes a percentage and returns a standard deviation multiplier for what value that percentage occurs at.
It is equivalent to a, ‘One-tail test’ on the density plot.
ppf(q, loc=0, scale=1) Percent point function (inverse of cdf — percentiles).
Standard Normal Distribution
Returns a 95% significance interval for a one-tail test on a standard normal distribution (i.e. a special case of the normal distribution where the mean is 0 and the standard deviation is 1).
Our Example
To calculate the value for OP-provided example at which our 95% significance interval lies (For a one-tail test) we would use:
This will return a value (that functions as a ‘standard-deviation multiplier’) marking where 95% of data points would be contained if our data is a normal distribution.
To get the exact number, we take the norm.ppf() output and multiply it by our standard deviation for the distribution in question.
A Two-Tailed Test
If we need to calculate a ‘Two-tail test’ (i.e. We’re concerned with values both greater and less than our mean) then we need to split the significance (i.e. our alpha value) because we’re still using a calculation method for one-tail. The split in half symbolizes the significance level being appropriated to both tails. A 95% significance level has a 5% alpha; splitting the 5% alpha across both tails returns 2.5%. Taking 2.5% from 100% returns 97.5% as an input for the significance level.
Margin of Error
Margin of error is a significance level used when estimating a population parameter with a sample statistic. We want to generate our 95% confidence interval using the two-tailed input to norm.ppf() since we’re concerned with values both greater and less than our mean:
Next, we’d take the ppf and multiply it by our standard deviation to return the interval value:
Finally, we’d mark the confidence intervals by adding & subtracting the interval value from the mean:
Подбор закона распределения случайной величины по данным статистической выборки средствами Python
О чём могут «рассказать» законы распределения случайных величин, если научиться их «слушать»
Законы распределения случайных величин наиболее «красноречивы» при статистической обработке результатов измерений. Адекватная оценка результатов измерений возможна лишь в том случае, когда известны правила, определяющие поведение погрешностей измерения. Основу этих правил и составляют законы распределения погрешностей, которые могут быть представлены представлены в дифференциальной (pdf) или интегральной (cdf) формах.
К основным характеристикам законов распределения относятся: наиболее вероятное значение измеряемой величины под названием математическое ожидание (mean); мера рассеивания случайной величины вокруг математического ожидания под названием среднеквадратическое отклонение (std).
Дополнительными характеристиками являются – мера скученности дифференциальной формы закона распределения относительно оси симметрии под названием асимметрия (skew) и мера крутости, огибающей дифференциальной формы под названием эксцесс (kurt). Читатель уже догадался, что приведенные сокращения взяты из библиотек scipy. stats, numpy, которые мы и будем использовать.
Рассказ о законах распределения погрешности измерений был бы неполным, если не упомянуть об связи между энтропийным и среднеквадратичным значением погрешности. Не утомляя читателей длинными выкладками из информационной теории измерений [1], сразу сформулирую результат.
С точки зрения информации, нормальное распределение приводит к получению точно такого же количества информации, как и равномерное. Запишем выражение для погрешности delta0 с использованием функций приведённых выше библиотек для распределения случайной величины x.

Это позволяет заменить любой закон распределения погрешности равномерным с тем же значением delta0.
Введём ещё один показатель – энтропийный коэффициент k, который для нормального распределения равен:

Следует отметить, что любое распределение отличное от нормального, будет иметь меньший энтропийный коэффициент.
Лучше один раз увидеть, чем семь раз прочитать. Для дальнейшего сравнительного анализа интегральных распределений: равномерного, нормального и логистического модернизируем примеры, приведённые в документации [2].

Теперь мы знаем, как выглядят интегральные формы нормального, равномерного и логистического законов и можем приступить к их сравнению с тестовым распределением поставив более общий вопрос — подбора закона распределения случайной величины по данным статистической выборки.
Как подобрать закон распределения, имея интегральное распределения вероятности тестовой выборки
Подготовим первую часть программы, которая будет осуществлять сравнение перечисленных интегральных распределений с тестовой выборкой. Для этого зададим общие для законов распределения основные параметры — математическое ожидание и среднеквадратичное отклонение, используя равномерное распределение.
Здесь и далее результаты для сравнения введены в функцию print для контроля за ходом вычислений.
Тестовое интегральное распределение и результаты сравнения приведены во второй части программы. В ней определяются коэффициенты корреляции между тестовым и каждым из трёх интегральных законов распределения.
Поскольку коэффициенты корреляции могут отличатся незначительно, введено дополнительное определение возвещённых квадратов отклонения.
Тестовая функция интегральной формы закона распределения построена в виде ступенчатого накопления –0+ 1/n +2/n+……+1
График и результат роботы программы.
Тестовое распределение вероятностей в интегральной форме является равномерным. При минимальном отличии по коэффициенту корреляции для равномерного распределения взвешенное отклонение от тестового в 5,6 раза меньше, чем у нормального и в 11 раз меньше, чем у логистического.
Вывод
Приведенная реализация подбора закона распределения случайной величины по данным статистической выборки возможно будет полезной при решении аналогичных задач.
Нормальное распределение в Python
Даже если вы не находитесь в области статистики, вы, должно быть, нашли термин «нормальное распределение».
Даже если вы не находитесь в области статистики, вы должны были настроить термин « Нормальное распределение ».
А Распределение вероятностей является статистической функцией, которая описывает вероятность получения возможных значений, что может принимать случайную величину. При этом мы имеем в виду диапазон значений, которые параметр может взять, когда мы случайно подберем значения от него.
Распределение вероятностей может быть дискретным или непрерывным.
Предположим, в городе у нас есть высоты взрослых между возрастной группой в 20-30 лет от 4,5 футов до 7 футов.
Если бы нас попросили забрать 1 взрослых случайным образом и спросил, что его/ее (предполагая пол не влияет на высоту) высота? Там нет способа знать, что будет высота. Но если у нас есть распределение высот взрослых в городе, мы можем сделать ставку на наиболее вероятный результат.
Что такое нормальное распределение?
А Нормальное распределение также известен как Гауссовое распределение или отлично Кривая колокола Отказ Люди используют оба слова взаимозаменяемо, но это означает то же самое. Это непрерывное распределение вероятностей.
Функция плотности вероятности (PDF) для нормального распределения:
Где, отклонение, ценность.
Выглядит непростой, не так ли? Но это очень просто.
1. Пример реализации нормального распределения
Давайте посмотрим на код ниже. Мы будем использовать numpy и matplotlib для этой демонстрации:
2. Свойства нормального распределения
Обычная функция плотности распределения просто принимает точку данных, а также среднее значение и стандартное отклонение и выбрасывает значение, которое мы называем плотность вероятности Отказ
Мы можем изменить форму кривой колоколов, изменив среднее и стандартное отклонение.
Изменение среднего смещения изменится к тому, что означает среднее значение, это означает, что мы можем изменить положение кривой, изменяя среднее значение, в то время как форма кривой остается неповрежденной.
Форма кривой может контролироваться значением стандартного отклонения. Меньшее стандартное отклонение приведет к тесному ограниченному кривой, в то время как высокое значение приведет к более широкому распределению кривой.
Некоторые отличные свойства нормального распределения:
Эмпирическое правило говорит нам, что:
Это безусловно, одно из самых важных распределений во всей статистике. Нормальное распределение волшебное, потому что большая часть явления встречающегося в природе следует нормальному распределению. Например, артериальное давление, баллы IQ, высота следуют нормальному распределению.
Расчет вероятностей с нормальным распределением
Чтобы найти вероятность значения, происходящего в пределах диапазона в обычном распределении, нам просто нужно найти область под кривой в этом диапазоне. I.e. Нам нужно интегрировать функцию плотности.
Поскольку нормальное распределение является непрерывным распределением, площадь под кривой представляет вероятности.
Прежде чем перейти к деталям, сначала давайте просто узнаем, какое стандартное нормальное распределение.
Стандартное нормальное распределение просто похоже на нормальное распределение с и стандартным.
Значение Z выше также известно как z-счет Отказ Z-оценка дает вам представление о том, как далеко от среднего является точка данных.
Если мы намерены рассчитать вероятности вручную, нам нужно будет посмотреть наше Z-значение в Z-таблица чтобы увидеть совокупное процентное значение. Python предоставляет нам модули для этой работы для нас. Давайте попадаем в это.
1. Создание нормальной кривой
Мы будем использовать Scipy.normorm Классная функция для расчета вероятностей из нормального распределения.
Предположим, у нас есть данные о высотах взрослых в городе, и данные следует нормальному распределению, у нас есть достаточный размер выборки со средним равным 5.3, а стандартное отклонение составляет 1.
Эта информация достаточно, чтобы сделать обычную кривую.
norm.pdf () Метод класса требует loc и масштаб Наряду с данными в качестве входного аргумента и дает значение плотности вероятности. loc это не что иное, кроме среднего и масштаб это стандартное отклонение данных. Код аналогичен тому, что мы создали в предыдущем разделе, но намного короче.
2. Расчет вероятности определенного возникновения данных
Теперь, если нас попросили выбирать одного человека случайным образом из этого распределения, то какова вероятность того, что высота человека будет меньше 4,5 футов.
Площадь под кривой, как показано на рисунке выше, будет вероятность того, что высота человека будет меньше 4,5 футов, если он выбран случайным образом из распределения. Посмотрим, как мы сможем рассчитать это в Python.
Единая строка кода выше находит вероятность того, что существует шанс на 21,18%, что если человек случайно выбран из нормального распределения со средним уровнем 5.3 и стандартным отклонением 1, то высота человека будет ниже 4,5 фута Отказ
Теперь, опять же, нас попросили выбрать один человек случайным образом из этого распределения, то какова вероятность того, что высота человека будет от 6,5 до 4,5 футов.
Теперь, что, если нас спросили о вероятности того, что высота избранного человека, выбранного случайным образом, будет выше 6,5 фута?
Это много, чтобы погрузиться, но я рекомендую всем продолжать практиковать эту важную концепцию наряду с реализацией с использованием Python.
Полный код из указанного выше реализации:
Заключение
В этой статье мы получили некоторую идею о нормальном распределении, как выглядит нормальная кривая, а главное ее реализация в Python.
Norm ppf python что это
Data science не только про обучении ML-моделей. В первую очередь, стоит понять данные: оценить взаимосвязи между переменными, определить их значимость и репрезентативность. Статистика – ключ к раскрытию ваших данных. В этой статье мы поговорим о статистике в Python, какие существуют библиотеки, и как их применять на реальных данных.
Датасет и Pandas для статистического анализа
В качестве анализа возьмем датасет c моллюсками вида abalone, доступный на сайте Kaggle — онлайн-площадке соревнований по машинному обучению. Датасет содержит физические параметры моллюсков: рост, диаметр, высоту, вес раковины и т.д. Также присутствует один категориальный признак — пол моллюска. Ключевым атрибутам является количество колец у моллюска, определяющего его возраст.
Для чтения данных будем использовать pandas. C основами работы pandas вы можете ознакомиться тут.
Первые строчки выглядят следующим образом:
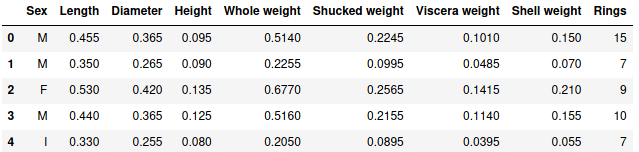 Первые пять строчек DataFrame
Первые пять строчек DataFrame
Описательная статистика в Pandas
Результатом является соответствующая таблица:
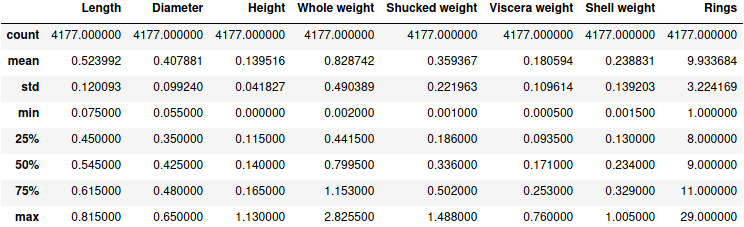 Описательная статистика pandas
Описательная статистика pandas
Проверка на нормальность в Scipy
В основе проверки на “нормальность” лежит проверка гипотез. Нулевая гипотеза – данные распределены нормально, альтернативная гипотеза – данные не имеют нормального распределения.
Проведем первый критерий Шапиро-Уилк [1], возвращающий значение вычисленной статистики и p-значение. В качестве критического значения в большинстве случаев берется 0.05. При p-значении меньше 0.05 мы вынуждены отклонить нулевую гипотезу.
Проверим распределение атрибута Rings, количество колец:
В результате мы получили низкое p-значение и, следовательно, отклоняем нулевую гипотезу:
Второй тест по критерию согласия Пирсона [2], который тоже возвращает соответствующее значение статистики и p-значение:
Этот критерий также отвергает нулевую гипотезу о нормальности распределения колец у моллюсков, так как p-значение меньше 0.05:
Оценка уровня статистической значимости
Результатом является значение t-статистики и p-значение:
В результате получили:
что превышает вычисленное значение t-статистики — 1.556. Это означает, что мы не можем отвергнуть нулевую гипотезу. Отсюда заключаем: средние двух выборок равны при условии их нормального распределения.
Линейная регрессия в Statsmodel
Если необходимо оценить связь между двумя атрибутами или более, можно использовать линейную регрессию. Например, с возрастанием одного атрибута увеличивается значение второго или наоборот. Python имеет библиотеку statsmodel, предоставляющую классы и функции для оценки статистических моделей [3].
Линейную регрессию можно построить с помощью метода наименьших квадратов. В statsmodel есть API, который дает возможность писать в R-стиле. Например, рассмотрим Rings, количество колец, и Diamеter, диаметр моллюска:
Метод ols принимает в качестве аргументов формулу для вычислений и DataFrame. summary вернет результат вычисленной модели:
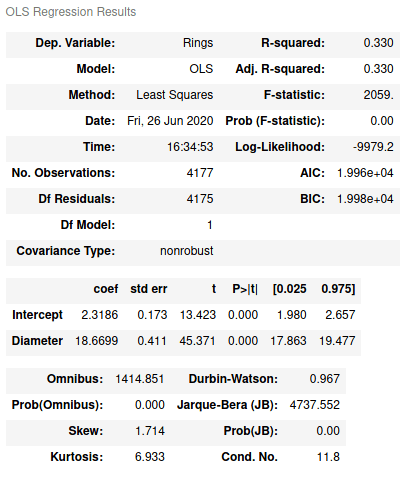 Резюме метода наименьших квадратов
Резюме метода наименьших квадратов
Отметим, что для построения линейной регрессии по двум независимым переменным формула бы выглядела так ‘Rings
Примеры кода выложены на github. В следующей статье мы поговорим об использовании лямбда-функций в Python. А подробные нюансы использования статистических Python-функций и модулей для применения в реальных проектах Data Science вы узнаете на наших курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.


