Правильный NLP: как работают и что умеют системы обработки естественного языка
Авторизуйтесь
Правильный NLP: как работают и что умеют системы обработки естественного языка

руководитель практики новых технологий компании Accenture в России
Основные факторы роста рынка NLP: стали больше использоваться интеллектуальные устройства, а также облачные решения и приложения на основе NLP, которые улучшают обслуживание клиентов, увеличились технологические инвестиции в отрасль здравоохранения.
Какие задачи сегодня может решать NLP?
Машинный перевод текстов с одного языка на другой

Это один из самых распространённых сценариев. Однако несмотря на значительный прогресс машинного перевода, современные решения до сих пор не всегда справляются с переводом устойчивых оборотов, игры слов, а также выбором подходящих падежей и правильным построением предложений.
Анализ текстов
Анализ текстов реализуется в трёх основных форматах: классификации, отражении содержания и анализе тональности.
Все задачи по классификации текстов (text classification) можно разделить на два типа:
Отражение содержания текста (text summarization) работает так: на вход NLP-система принимает текст большого размера, а на выходе отдаёт текст меньшего размера, отражающий содержание большого.
Например, от машины можно потребовать сгенерировать пересказ текста, заголовок или аннотацию. Чуть подробнее про генерацию текста можно почитать в материале «Генерируем заголовки фейковых новостей в стиле Ленты.ру» с подробным разбором способов, которыми можно обучить нейросети созданию осмысленных и забавных для человеческого восприятия заголовков.

Наконец, анализ тональности текста (sentiment analysis) позволяет находить в тексте мнения и выявлять их свойства. Какие именно свойства будут исследоваться, зависит от поставленной задачи. К примеру, целью анализа может быть сам автор — анализ тональности определяет типичный для него стиль, эмоциональную окраску текста и т. д.
Распознавание и синтез речи
Распознавание речи представляет собой процесс преобразования речевого сигнала в цифровую информацию, например в текст. Синтез речи работает в обратном направлении, формируя речевой сигнал по печатному тексту.
Синтез и распознавание речи применяются в самых разных областях, например, в работе голосовых ассистентов, IVR-систем и «умных домах».
Разработка диалоговых систем
Диалоговыми системами можно считать:
Все они опираются на NLP-инструменты: распознавание речи, выделение смысла, контекста, определение намерения, а затем выстраивание диалога, исходя из вышеперечисленного (в идеале — путём синтеза речи).
Выделение сущностей и фактов
Ещё одна популярная задача NLP — извлечение именованных сущностей (Named-entity recognition, NER) из текста. Представим, что у есть сплошной текст о покупке-продаже активов, и необходимо выделить персон, а также даты и активы.
На фоне роста аналитических прогнозов, миллиардер Иван Петров выкупил контрольный пакет акций компании « Рога и Копыта » в 1999 году.
Задача NER — понять, что участок текста «1999 года» является датой, «Иван Петров» — персоной, а «пакет акций» — активом.
Без NER тяжело представить решение многих задач NLP, допустим, разрешения местоименной анафоры или построения вопросно-ответных систем. Если задать в поисковике вопрос «Кто играл роль Бэтмена в фильме “Темный рыцарь”», то ответ находится как раз с помощью выделения именованных сущностей: выделяем сущности (фильм, роль и т. п.), понимаем, что спрашивается, и дальше ищем ответ в базе данных.
Постановка задачи NER очень гибкая. Можно выделять любые нужные непрерывные фрагменты текста, которые чем-то отличаются от остального текста. В результате можно подобрать свой набор сущностей для конкретной практической задачи, обработать тексты этим набором и обучить модель. Такой сценарий встречается повсеместно, и это делает NER одной из самых часто решаемых задач NLP в индустрии.
Вот как выглядит подобный проект для крупной нефтяной компании. Перед заказчиком стояла задача подготовить данные об активах: промышленных установках, эксплуатируемом оборудовании, а также средствах измерения и контроля. Источниками данных служили текстовые документы — технические регламенты, наиболее полно описывающие техпроцессы и необходимые объекты производства.
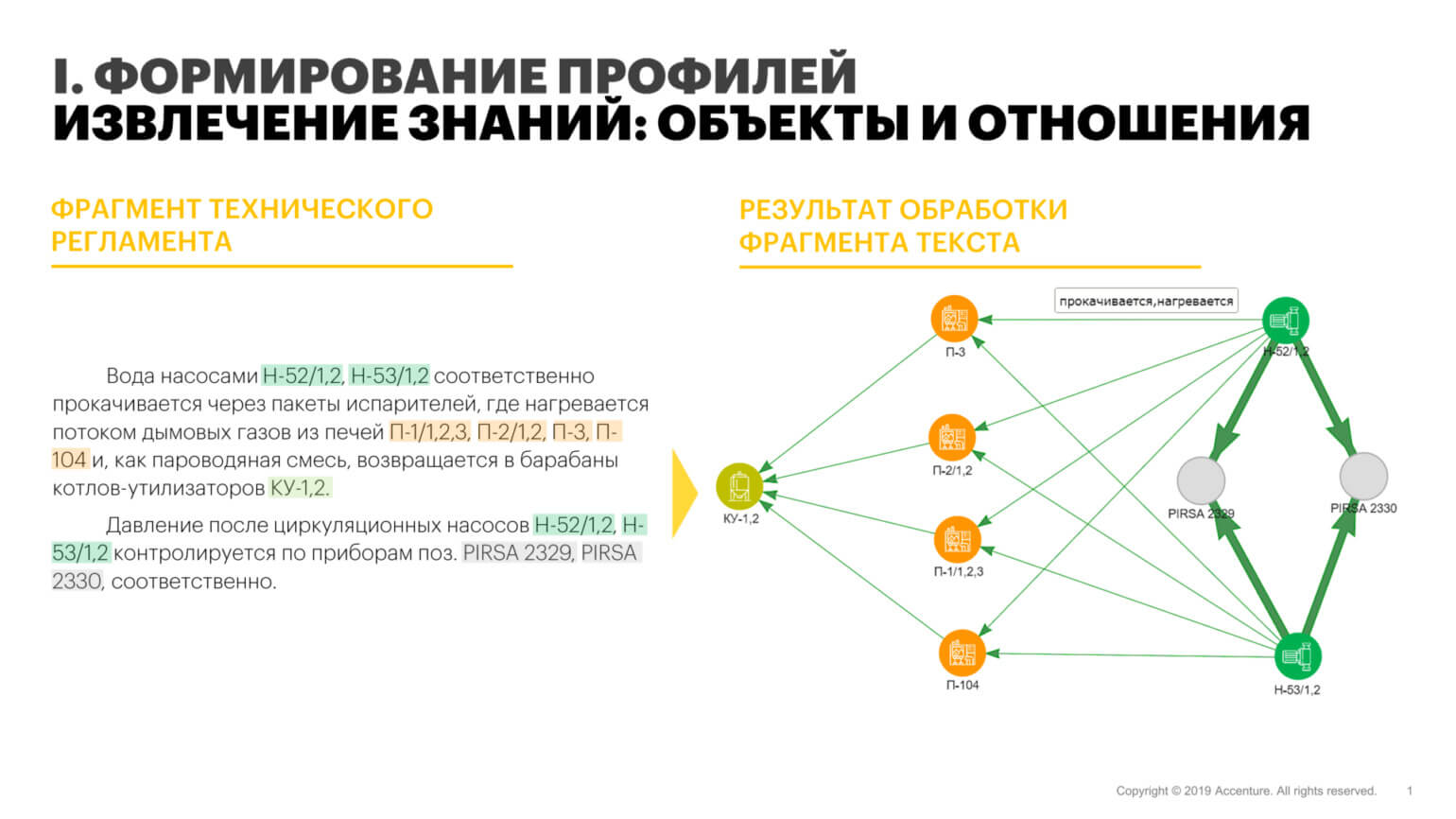
Мы продемонстрировали возможность применения технологий ML и NLP для извлечения информации из текстового описания (и формирования профилей оборудования на её основе). Сформированные профили были сопоставлены с результатами ручного маппинга, взятого за эталон — достигнутая точность составила 97,3%. Подход позволяет существенно снизить затраты труда и времени, а также свести к минимуму риски, связанные с ошибками ручной обработки текстов.
Как обрабатывается естественный язык?
Некоторые задачи NLP для естественного языка, в отличие от обработки изображений, до недавних пор решались с помощью классических алгоритмов машинного обучения.
Для решения большинства задач требовался тщательный выбор архитектуры, а также ручной сбор и обработка признаков. Однако в последнее время нейронные сети начали давать более точные результаты по сравнению с классическими моделями и сформировали общий подход для решения задач NLP.
Конвейер NLP
Реализация любой сложной задачи обычно означает построение пайплайна (конвейера).
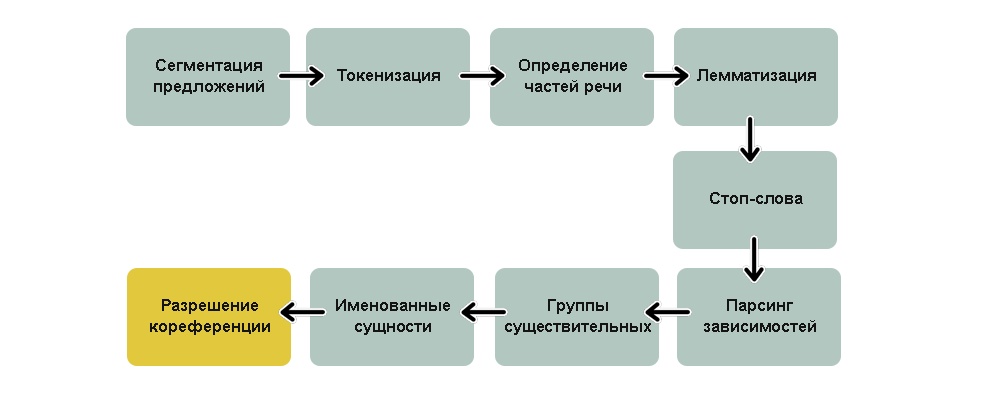
Суть этого подхода в том, чтобы разбить задачу на ряд последовательных подзадач и решать каждую из них отдельно. В построении пайплайна можно условно выделить две части: предобработку входных данных (обычно занимает больше всего времени) и построение модели. Основных этапов — семь.
1. Первые два шага пайплайна, которые выполняются для решения практически любых задач NLP, — это сегментация (деление текста на предложения) и токенизация (деление предложений на токены, то есть отдельные слова).
2. Вычисление признаков каждого токена. Вычисляются контекстно-независимые признаки токена. Это набор признаков, не зависящих от соседних с токеном слов.

Например: I had a pony. I had two ponies.
Оба предложения содержат существительное «pony», но с разными окончаниями. Если тексты обрабатывает компьютер, он должен знать начальную форму каждого слова, чтобы понимать, что речь идёт об одной и той же концепции пони. Иначе токены «pony» и «ponies» будут восприняты как совершенно разные. В NLP этот процесс называется лемматизацией.
3. Определение значимости и фильтрация стоп-слов. В русском и английском языках очень много вспомогательных слов, например «and», «the», «a». При статистическом анализе текста эти токены создают много шума, так как появляются чаще, чем остальные. Поэтому их отмечают как стоп-слова и отсеивают.

4. Разрешение кореференции. В русском и английском языках очень много местоимений вроде he, she, it или ты, я, он и т. д. Это сокращения, которыми мы заменяем на письме настоящие имена и названия. Человек может проследить взаимосвязь этих слов от предложения к предложению, основываясь на контексте. Но NLP-модель не знает, что означают местоимения, ведь она рассматривает всего одно предложение за раз.

5. Парсинг зависимостей. Конечная цель этого шага — построение дерева, в котором каждый токен имеет единственного родителя. Корнем может быть главный глагол. Также нужно установить тип связи между двумя словами:
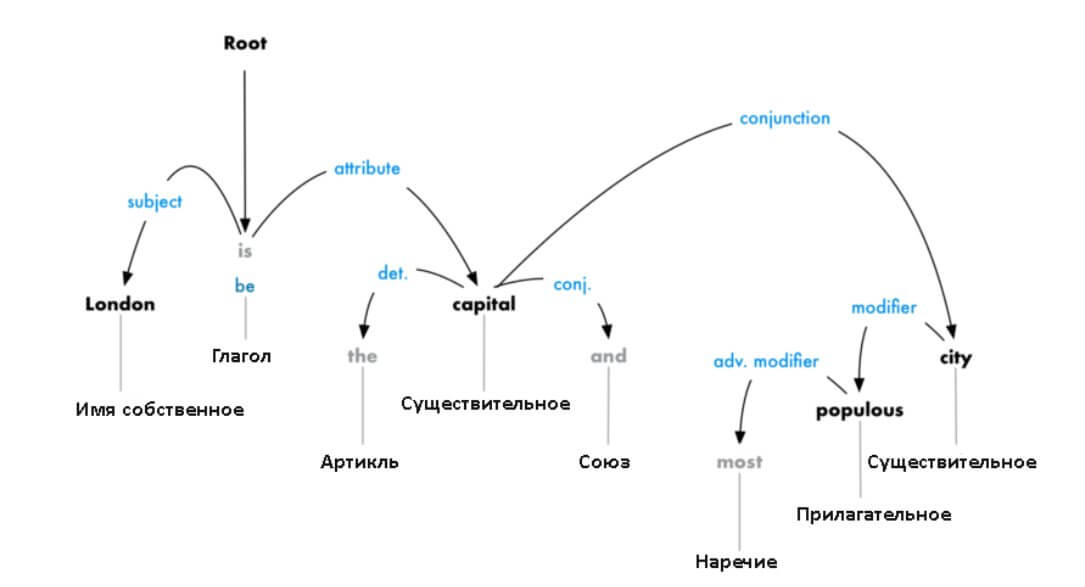
Это дерево парсинга демонстрирует, что главный субъект предложения — это существительное «London». Между ним и «capital» есть связь «be». Вот так мы узнали, что Лондон — это столица. Если бы мы проследовали дальше по веткам дерева (уже за границами схемы), то могли бы узнать, что «London is the capital of Great Britain».
6. Перевод обработанного текста в векторную форму. Данный шаг позволяет сформировать векторные представления слов. Таким образом, у слов, используемых в одном и том же контексте, похожие векторы.
7. Построение модели в зависимости от поставленной цели. Например, модель для классификации или генерации новых текстов.
Приведённый пример пайплайна не является единственно верным. Для решения конкретной задачи некоторые шаги можно исключить или добавить новые. Однако этот пайплайн содержит все наиболее типичные этапы и подходы, позволяющие извлекать практическую пользу из NLP.
NLP. Основы. Техники. Саморазвитие. Часть 1
Привет! Меня зовут Иван Смуров, и я возглавляю группу исследований в области NLP в компании ABBYY. О том, чем занимается наша группа, можно почитать здесь. Недавно я читал лекцию про Natural Language Processing (NLP) в Школе глубокого обучения – это кружок при Физтех-школе прикладной математики и информатики МФТИ для старшеклассников, интересующихся программированием и математикой. Возможно, тезисы моей лекции кому-то пригодятся, поэтому поделюсь ими с Хабром.
Поскольку за один раз все объять не получится, разделим статью на две части. Сегодня я расскажу о том, как нейросети (или глубокое обучение) используются в NLP. Во второй части статьи мы сконцентрируемся на одной из самых распространенных задач NLP — задаче извлечения именованных сущностей (Named-entity recognition, NER) и разберем подробно архитектуры ее решений.

Что такое NLP?
Это широкий круг задач по обработке текстов на естественном языке (т. е. на языке, на котором говорят и пишут люди). Существует набор классических задач NLP, решение которых несет практическую пользу.
Первый и один из самых важных с практической точки зрения способов применения — классификация писем на спам и хам (не спам).
Другой классический вариант — многоклассовая классификация новостей по категориям (рубрикация) — внешняя политика, спорт, шапито и т. п. Или, допустим, вам приходят письма, и вы хотите отделить заказы из интернет-магазина от авиабилетов и броней отелей.
Третий классический вариант применения задачи текстовой классификации — сентиментный анализ. Например, классификация отзывов на положительные, отрицательные и нейтральные.
Примерами других часто выделяемых отношений являются отношения купли/продажи (Purchase and Sale), владения (Ownership), факт рождения с атрибутами — датой, местом и т. д. (Birth) и некоторые другие.
Задача кажется не имеющей очевидного практического применения, но, тем не менее, она используется при структуризации неструктурированной информации. Кроме того, это важно в вопросно-ответных и диалоговых системах, в поисковиках — всегда, когда вам нужно анализировать вопрос и понимать, к какому типу он относится, а также, какие ограничения есть на ответ.
Почему решать задачи NLP сложно?
Формулировки задач не очень сложные, однако сами задачи вовсе не являются простыми, потому что мы работаем с естественным языком. Явления полисемии (многозначные слова имеют общий исходный смысл) и омонимии (разные по смыслу слова произносятся и пишутся одинаково) характерны для любого естественного языка. И если носитель русского хорошо понимает, что в теплом приеме мало общего с боевым приемом, с одной стороны, и теплым пивом, с другой, автоматической системе приходится долго этому учиться. Почему «Press space bar to continue» лучше перевести скучным «Для продолжения нажмите пробел», чем «Бар космической прессы продолжит работу».
Как решают задачи NLP
В отличие от обработки изображений, по NLP до сих пор можно встретить статьи, где описываются решения, использующие не нейросетки, а классические алгоритмы типа SVM или Xgboost, и показывающие результаты, не слишком сильно уступающие state-of-the-art решениям.
Тем не менее, несколько лет назад нейросети начали побеждать классические модели. Важно отметить, что для большинства задач решения на основе классических методов были уникальные, как правило, не похожие на решения других задач как по архитектуре, так и по тому, как происходит сбор и обработка признаков.
Однако нейросетевые архитектуры намного более общие. Архитектура самой сети, скорее всего, тоже отличается, но намного меньше, идет тенденция в сторону полной универсализации. Тем не менее, то, с какими признаками и как именно мы работаем, уже практически одинаково для большинства задач NLP. Отличаются только последние слои нейросеток. Таким образом, можно считать, что сформировался единый пайплайн NLP. Про то, как он устроен, мы сейчас расскажем подробнее.
Pipeline NLP
Этот способ работы с признаками, который более-менее одинаков для всех задач.
Когда речь идет о языке, основная единица, с которой мы работаем, это слово. Или более формально «токен». Мы используем этот термин, потому что не очень понятно, что такое 2128506 — это слово или нет? Ответ не очевиден. Токен обычно отделен от других токенов пробелами или знаками препинания. И как можно понять из сложностей, которые мы описали выше, очень важен контекст каждого токена. Есть разные подходы, но в 95% случаев таким контекстом, который рассматривается при работе модели, выступает предложение, включающее исходный токен.
Многие задачи вообще решаются на уровне предложения. Например, машинный перевод. Чаще всего, мы просто переводим одно предложение и никак не используем контекст более широкого уровня. Есть задачи, где это не так, например, диалоговые системы. Тут важно помнить, о чем систему спрашивали раньше, чтобы она могла ответить на вопросы. Тем не менее, предложение — тоже основная единица, с которой мы работаем.
Поэтому первые два шага пайплайна, которые выполняются практически для решения любых задач – это сегментация (деление текста на предложения) и токенизация (деление предложений на токены, то есть отдельные слова). Это делается несложными алгоритмами.
Дальше нужно вычислить признаки каждого токена. Как правило, это происходит в два этапа. Первый – вычислить контекстно-независимые признаки токена. Это набор признаков, которые никак не зависят от окружающих наш токен других слов. Обычные контекстно-независимые признаки – это:
Один из самых часто использующихся признаков — часть речи или POS-тег (part of speech). Такие признаки могут быть важны для решения многих задач, например задачи синтаксического парсинга. Для языков со сложной морфологией, типа русского языка, также важны морфологические признаки: например, в каком падеже стоит существительное, какой род у прилагательного. Из этого можно сделать разные выводы о структуре предложения. Также, морфология нужна для лемматизации (приведения слов к начальным формам), с помощью которой мы можем сократить размерность признакового пространства, и поэтому морфологический анализ активно используется для большинства задач NLP.
Когда мы решаем задачу, где важно взаимодействие между различными объектами (например, в задаче relation extraction или при создании вопросно-ответной системы), нам нужно многое знать про структуру предложения. Для этого нужен синтаксический разбор. В школе все делали разбор предложения на подлежащее, сказуемое, дополнение и др. Синтаксический разбор – это что-то в этом духе, но сложнее.
Еще одним примером дополнительного признака является позиция токена в тексте. Мы можем априори знать, что какая-то сущность чаще встречается в начале текста или наоборот в конце.
Все вместе – эмбеддинги, символьные и дополнительные признаки – формируют вектор признаков токена, который не зависит от контекста.
Контекстно-зависимые признаки
Контекстно-зависимые признаки токена — это набор признаков, который содержит информацию не только про сам токен, но и про его соседей. Есть разные способы вычислить эти признаки. В классических алгоритмах люди часто просто шли «окном»: брали несколько (например, три) токенов до исходного и несколько токенов после, а затем вычисляли все признаки в таком окне. Такой подход ненадежен, так как важная информация для анализа может находиться на расстоянии, превышающем окно, соответственно, мы можем что-то пропустить.
Поэтому сейчас все контекстно-зависимые признаки вычисляются на уровне предложения стандартным образом: с помощью двухсторонних рекуррентных нейросетей LSTM или GRU. Чтобы получить контекстно-зависимые признаки токена из контекстно-независимых, контекстно-независимые признаки всех токенов предложения подаются в Bidirectional RNN (одно- или несколько- слойный). Выход Bidirectional RNN в i-ый момент времени и является контекстно-зависимым признаком i-того токена, который содержит информацию как о предыдущих токенах (т.к. эта информация содержится в i-м значении прямого RNN), так и о последующих (т.к. эта информация содержится в соответствующем значении обратного RNN).
Дальше для каждой отдельной задачи мы делаем что-то свое, но первые несколько слоев — вплоть до Bidirectional RNN можно использовать для практически любых задач.
Такой способ получения признаков и называется пайплайном NLP.
Стоит отметить, что в последние 2 года исследователи активно пытаются усовершенствовать пайплайн NLP — как с точки зрения быстродействия (например, transformer — архитектура, основанная на self-attention, не содержит в себе RNN и поэтому способна быстрее обучаться и применяться), так и с точки зрения используемых признаков (сейчас активно используют признаки на основе предобученных языковых моделей, например ELMo, или используют первые слои предобученной языковой модели и дообучают их на имеющемся для задачи корпусе — ULMFit, BERT).
Словоформенные эмбеддинги
Давайте подробнее разберем, что же такое эмбеддинг. Грубо говоря, эмбеддинг — это сжатое представление о контексте слова. Почему важно знать контекст слова? Потому что мы верим в дистрибутивную гипотезу — что похожие по смыслу слова употребляются в сходных контекстах.
Давайте теперь попытаемся дать строгое определение эмбеддинга. Эмбеддинг – это отображение из дискретного вектора категориальных признаков в непрерывный вектор с заранее заданной размерностью.
Каноничный пример эмбеддинга – это эмбеддинг слова (словоформенный эмбеддинг).
Что обычно выступает в роли дискретного вектора признаков? Булев вектор, соответствующий всевозможным значениям какой-то категории (например, все возможные части речи или все возможные слова из какого-то ограниченного словаря).
Для словоформенных эмбеддингов такой категорией обычно выступает индекс слова в словаре. Допустим, есть словарь размерностью 100 тысяч. Соответственно, каждое слово имеет дискретный вектор признаков – булев вектор размерности 100 тысяч, где на одном месте (индексе данного слова в нашем словаре) стоит единичка, а на остальных – нули.
Почему мы хотим отображать наши дискретные вектора признаков в непрерывные заданной размерности? Потому что вектора размерностью 100 тысяч не очень удобно использовать для вычислений, а вот вектора целых чисел размерности 100, 200 или, например, 300, — намного удобнее.
В принципе, мы можем не пытаться накладывать никаких дополнительных ограничений на такое отображение. Но раз уж мы строим такое отображение, давайте попытаемся добиться, чтобы вектора похожих по смыслу слов также были в каком-то смысле близки. Это делается с помощью простой feed-forward нейросетки.
Обучение эмбеддингов
Как эмбеддинги обучаются? Мы пытаемся решить задачу восстановления слова по контексту (или наоборот, восстановления контекста по слову). В простейшем случае мы получаем на вход индекс в словаре предыдущего слова (булев вектор размерности словаря) и пытаемся определить индекс в словаре нашего слова. Делается это с помощью сетки с предельно простой архитектурой: два полносвязных слоя. Сначала идет полносвязный слой из булева вектора размерности словаря в скрытый слой размерности эмбеддинга (т.е. просто умножение булева вектора на матрицу нужной размерности). А потом наоборот, полносвязный слой с softmax из скрытого слоя размерности эмбеддинга в вектор размерности словаря. Благодаря функции активации softmax, мы получаем распределение вероятностей нашего слова и можем выбрать самый вероятный вариант.
Эмбеддингом i-го слова будет просто i-я строка в матрице перехода W.
В используемых на практике моделях архитектура сложнее, но ненамного. Главное отличие в том, что мы используем не один вектор из контекста для определения нашего слова, а несколько (например, все в окне размера 3). Несколько более популярным вариантом является ситуация, когда мы пытаемся предсказать не слово по контексту, а наоборот контекст по слову. Такой подход называется Skip-gram.
Давайте приведем пример применения задачи, которая решается во время обучения эмбеддингов (в варианте CBOW — предсказания слова по контексту). Например, пусть контекст токена состоит из 2 предыдущих слов. Если мы обучались на корпусе текстов про современную русскую литературу и контекст состоит из слов “поэт Марина”, то, скорее всего, самым вероятным следующим словом будет слово “Цветаева”.
Подчеркнем еще раз, эмбеддинги только обучаются на задаче предсказания слова по контексту (или наоборот контекста по слову), а применять их можно в любых ситуациях, когда нам нужно вычислить признак токена.
Какой бы вариант мы ни выбрали, архитектура эмбеддингов очень несложная, и их большой плюс в том, что их можно обучать на неразмеченных данных (действительно, мы используем только информацию о соседях нашего токена, а для их определения нужен только сам текст). Получившиеся эмбеддинги — усредненный контекст именно по такому корпусу.
Эмбеддинги словоформ, как правило, обучаются на максимально большом и доступном для обучения корпусе. Обычно это вся Википедия на языке, потому что ее всю можно выкачать, и любые другие корпуса, которые получится достать.
Похожие соображения используются и при предобучении для современных архитектур, упомянутых выше — ELMo, ULMFit, BERT. Они тоже используют при обучении неразмеченные данные, и поэтому обучаются на максимально большом доступном корпусе (хотя сами архитектуры, конечно, сложнее, чем у классических эмбеддингов).
Зачем нужны эмбеддинги?
Как уже было упомянуто, для использования эмбеддингов есть 2 основные причины.
В следующей части нашей статьи мы поговорим о задаче NER. Мы расскажем о том, что это за задача, зачем она нужна и какие подводные камни могут скрываться в ее решении. Мы расскажем подробно про то, как эту задачу решали с помощью классических методов, как ее стали решать с помощью нейросетей, и опишем современные архитектуры, созданные для ее решения.
Как решить 90% задач NLP: пошаговое руководство по обработке естественного языка
Неважно, кто вы — зарекомендовавшая себя компания, или же только собираетесь запустить свой первый сервис — вы всегда можете использовать текстовые данные для того, чтобы проверить ваш продукт, усовершенствовать его и расширить его функциональность.
Обработкой естественного языка (NLP) называется активно развивающаяся научная дисциплина, занимающаяся поиском смысла и обучением на основании текстовых данных.
Как вам может помочь эта статья
За прошедший год команда Insight приняла участие в работе над несколькими сотнями проектов, объединив знания и опыт ведущих компаний в США. Результаты этой работы они обобщили в статье, перевод которой сейчас перед вами, и вывели подходы к решению наиболее распространенных прикладных задач машинного обучения.
Мы начнем с самого простого метода, который может сработать — и постепенно перейдем к более тонким подходам, таким как feature engineering, векторам слов и глубокому обучению.
После прочтения статьи, вы будете знать, как:
К оригинальному посту прилагается интерактивный блокнот Jupyter, демонстрирующий применение всех упомянутых техник. Мы призываем вас воспользоваться им по мере того, как вы будете читать статью.
Применение машинного обучения для понимания и использования текста
Обработка естественного языка позволяет получать новые восхитительные результаты и является очень широкой областью. Однако, Insight идентифицировала следующие ключевые аспекты практического применения, которые встречаются гораздо чаще остальных:
Шаг 1: Соберите ваши данные
Примерные источники данных
Любая задача машинного обучения начинается с данных — будь то список адресов электронной почты, постов или твитов. Распространенными источниками текстовой информации являются:
Датасет «Катастрофы в социальных медиа»
Для иллюстрации описываемых подходов мы будем использовать датасет «Катастрофы в социальных медиа», любезно предоставленный компанией CrowdFlower.
Авторы рассмотрели свыше 10 000 твитов, которые были отобраны при помощи различных поисковых запросов вроде «в огне», «карантин» и «столпотворение». Затем они пометили, имеет ли твит отношение к событию-катастрофе (в отличие от шуток с использованием этих слов, обзоров на фильмы или чего-либо, не имеющего отношение к катастрофам).
Поставим себе задачу определить, какие из твитов имеют отношение к событию-катастрофе в противоположность тем твитам, которые относятся к нерелевантным темам (например, фильмам). Зачем нам это делать? Потенциальным применением могло бы быть эксклюзивное уведомление должностных лиц о чрезвычайных ситуациях, требующих неотложного внимания — при этом были бы проигнорированы обзоры последнего фильма Адама Сэндлера. Особая сложность данной задачи заключается в том, что оба этих класса содержат одни и те же критерии поиска, поэтому нам придется использовать более тонкие отличия, чтобы разделить их.
Далее мы будем ссылаться на твиты о катастрофах как «катастрофа», а на твиты обо всём остальном как «нерелевантные».
Метки (Labels)
Наши данные имеют метки, так что мы знаем, к каким категориям принадлежат твиты. Как подчеркивает Ричард Сочер, обычно быстрее, проще и дешевле найти и разметить достаточно данных, на которых будет обучаться модель — вместо того, чтобы пытаться оптимизировать сложный метод обучения без учителя.
Rather than spending a month figuring out an unsupervised machine learning problem, just label some data for a week and train a classifier.
Вместо того, чтобы тратить месяц на формулирование задачи машинного обучения без учителя, просто потратьте неделю на то, чтобы разметить данные, и обучите классификатор.
Шаг 2. Очистите ваши данные
Правило номер один: «Ваша модель сможет стать лишь настолько хороша,
насколько хороши ваши данные»
Одним из ключевых навыков профессионального Data Scientist является знание о том, что должно быть следующим шагом — работа над моделью или над данными. Как показывает практика, сначала лучше взглянуть на сами данные, а только потом произвести их очистку.
Чистый датасет позволит модели выучить значимые признаки и не переобучиться на нерелевантном шуме.
Далее следует чеклист, который используется при очистке наших данных (подробности можно посмотреть в коде).
Шаг 3. Выберите хорошее представление данных
В качестве ввода модели машинного обучения принимают числовые значения. Например, модели, работающие с изображениями, принимают матрицу, отображающую интенсивность каждого пикселя в каждом канале цвета.
Улыбающееся лицо, представленное в виде массива чисел
Наш датасет представляет собой список предложений, поэтому для того, чтобы наш алгоритм мог извлечь паттерны из данных, вначале мы должны найти способ представить его таким образом, чтобы наш алгоритм мог его понять.
One-hot encoding («Мешок слов»)
Естественным путем отображения текста в компьютерах является кодирование каждого символа индивидуально в виде числа (пример подобного подхода — кодировка ASCII). Если мы «скормим» подобную простую репрезентацию классификатору, он будет должен изучить структуру слов с нуля, основываясь лишь на наших данных, что на большинстве датасетов невозможно. Следовательно, мы должны использовать более высокоуровневый подход.
Например, мы можем построить словарь всех уникальных слов в нашем датасете, и ассоциировать уникальный индекс каждому слову в словаре. Каждое предложение тогда можно будет отобразить списком, длина которого равна числу уникальных слов в нашем словаре, а в каждом индексе в этом списке будет хранится, сколько раз данное слово встречается в предложении. Эта модель называется «Мешком слов» (Bag of Words), поскольку она представляет собой отображение полностью игнорирущее порядок слов предложении. Ниже иллюстрация такого подхода.
Представление предложений в виде «Мешка слов». Исходные предложения указаны слева, их представление — справа. Каждый индекс в векторах представляет собой одно конкретное слово.
Визуализируем векторные представления
В словаре «Катастрофы в социальных медиа» содержится около 20 000 слов. Это означает, что каждое предложение будет отражено вектором длиной 20 000. Этот вектор будет содержать преимущественно нули, поскольку каждое предложение содержит лишь малое подмножество из нашего словаря.
Для того, чтобы выяснить, захватывают ли наши векторные представления (embeddings), релевантную нашей задаче информацию (например, имеют ли твиты отношение к катастрофам или нет), стоит попробовать визуализировать их и посмотреть, насколько хорошо разделены эти классы. Поскольку словари обычно являются очень большими и визуализация данных на 20 000 измерений невозможна, подходы вроде метода главных компонент (PCA) помогают спроецировать данные на два измерения.
Визуализация векторных представлений для «мешка слов»
Судя по получившемуся графику, не похоже, что два класса разделены как следует — это может быть особенностью нашего представления или просто эффектом сокращения размерности. Для того, чтобы выяснить, являются ли для нас полезными возможности «мешка слов», мы можем обучить классификатор, основанный на них.
Шаг 4. Классификация
Когда вы в первый раз принимаетесь за задачу, общепринятой практикой является начать с самого простого способа или инструмента, который может решить эту задачу. Когда дело касается классификации данных, наиболее распространенным способом является логистическая регрессия из-за своей универсальности и легкости толкования. Ее очень просто обучить, и ее результаты можно интерпретировать, поскольку вы можете с легкостью извлечь все самые важные коэффициенты из модели.
Разобьем наши данные на обучающую выборку, которую мы будем использовать для обучения нашей модели, и тестовую — для того, чтобы посмотреть, насколько хорошо наша модель обобщается на данные, которые не видела до этого. После обучения мы получаем точность в 75.4%. Не так уж и плохо! Угадывание самого частого класса («нерелеватно») дало бы нам лишь 57%.
Однако, даже если результата с 75% точностью было бы достаточно для наших нужд, мы никогда не должны использовать модель в продакшне без попытки понять ее.
Шаг 5. Инспектирование
Матрица ошибок
Первый шаг — это понять, какие типы ошибок совершает наша модель, и с какими видами ошибок нам в дальнейшем хотелось бы встречаться реже всего. В случае нашего примера, ложно-положительные результаты классифицируют нерелевантный твит в качестве катастрофы, ложно-отрицательные — классифицируют катастрофу как нерелевантный твит. Если нашим приоритетом является реакция на каждое потенциальное событие, то мы захотим снизить наши ложно-отрицательные срабатывания. Однако, если мы ограничены в ресурсах, то мы можем приоритезировать более низкую частоту ложно-отрицательных срабатываний для уменьшения вероятности ложной тревоги. Хорошим способом визуализации данной информации является использование матрицы ошибок, которая сравнивает предсказания, сделанные нашей моделью, с реальными метками. В идеале, данная матрица будет представлять собой диагональную линию, идущую из левого верхнего до нижнего правого угла (это будет означать, что наши предсказания идеально совпали с правдой).
Наш классификатор создает больше ложно-отрицательных, чем ложно-положительных результатов (пропорционально). Другими словами, самая частая ошибка нашей модели состоит в неточной классификации катастроф как нерелевантных. Если ложно-положительные отражают высокую стоимость для правоохранительных органов, то это может стать хорошим вариантом для нашего классификатора.
Объяснение и интерпретация нашей модели
Чтобы произвести валидацию нашей модели и интерпретировать ее предсказания, важно посмотреть на то, какие слова она использует для принятия решений. Если наши данные смещены, наш классификатор произведет точные предсказания на выборочных данных, но модель не сможет достаточно хорошо обобщить их в реальном мире. На диаграмме ниже показаны наиболее значимые слова для классов катастроф и нерелевантных твитов. Составление диаграмм, отражающих значимость слов, не составляет трудностей в случае использования «мешка слов» и логистической регрессии, поскольку мы просто извлекаем и ранжируем коэффициенты, которые модель использует для своих предсказаний.
«Мешок слов»: значимость слов
Наш классификатор верно нашел несколько паттернов (hiroshima — «Хиросима», massacre — «резня»), но ясно видно, что он переобучился на некоторых бессмысленных терминах («heyoo», «x1392»). Итак, сейчас наш «мешок слов» имеет дело с огромным словарем из различных слов и все эти слова для него равнозначны. Однако, некоторые из этих слов встречаются очень часто, и лишь добавляют шума нашим предсказаниям. Поэтому далее мы постараемся найти способ представить предложения таким образом, чтобы они могли учитывать частоту слов, и посмотрим, сможем ли мы получить больше полезной информации из наших данных.
Шаг 6. Учтите структуру словаря
TF-IDF
Чтобы помочь нашей модели сфокусироваться на значимых словах, мы можем использовать скоринг TF-IDF (Term Frequency, Inverse Document Frequency) поверх нашей модели «мешка слов». TF-IDF взвешивает на основании того, насколько они редки в нашем датасете, понижая в приоритете слова, которые встречаются слишком часто и просто добавляют шум. Ниже приводится проекция метода главных компонент, позволяющая оценить наше новое представление.
Визуализация векторного представления с применением TF-IDF.
Мы можем наблюдать более четкое разделение между двумя цветами. Это свидетельствует о том, что нашему классификатору должно стать проще разделить обе группы. Давайте посмотрим, насколько улучшатся наши результаты. Обучив другую логистическую регрессию на наших новых векторных представлениях, мы получим точность в 76,2%.
Очень незначительное улучшение. Может, наша модель хотя бы стала выбирать более важные слова? Если полученный результат по этой части стал лучше, и мы не даем модели «мошенничать», то можно считать этот подход усовершенствованием.
TF-IDF: Значимость слов
Выбранные моделью слова действительно выглядят гораздо более релевантными. Несмотря на то, что метрики на нашем тестовом множестве увеличились совсем незначительно, у нас теперь гораздо больше уверенности в использовании модели в реальной системе, которая будет взаимодействовать с клиентами.
Шаг 7. Применение семантики
Word2Vec
Наша последняя модель смогла «выхватить» слова, несущие наибольшее значение. Однако, скорее всего, когда мы выпустим ее в продакшн, она столкнется со словами, которые не встречались в обучающей выборке — и не сможет точно классифицировать эти твиты, даже если она видела весьма похожие слова во время обучения.
Чтобы решить данную проблему, нам потребуется захватить семантическое (смысловое) значение слов — это означает, что для нас важно понимать, что слова «хороший» и «позитивный» ближе друг к другу, чем слова «абрикос» и «континент». Мы воспользуемся инструментом Word2Vec, который поможет нам сопоставить значения слов.
Использование результатов предварительного обучения
Word2Vec — это техника для поиска непрерывных отображений для слов. Word2Vec обучается на прочтении огромного количества текста с последующим запоминанием того, какое слово возникает в схожих контекстах. После обучения на достаточном количестве данных, Word2Vec генерирует вектор из 300 измерений для каждого слова в словаре, в котором слова со схожим значением располагаются ближе друг к другу.
Авторы публикации на тему непрерывных векторных представлений слов выложили в открытый доступ модель, которая была предварительно обучена на очень большом объеме информации, и мы можем использовать ее в нашей модели, чтобы внести знания о семантическом значении слов. Предварительно обученные векторы можно взять в репозитории, упомянутом в статье по ссылке.
Отображение уровня предложений
Быстрым способом получить вложения предложений для нашего классификатора будет усреднение оценок Word2Vec для всех слов в нашем предложении. Это все тот же подход, что и с «мешком слов» ранее, но на этот раз мы теряем только синтаксис нашего предложения, сохраняя при этом семантическую (смысловую) информацию.
Векторные представления предложений в Word2Vec
Вот визуализация наших новых векторных представлений после использования перечисленных техник:
Визуализация векторных представлений Word2Vec.
Теперь две группы цветов выглядят разделенными еще сильнее, и это должно помочь нашему классификатору найти различие между двумя классами. После обучения той же модели в третий раз (логистическая регрессия), мы получаем точность в 77,7% — и это наш лучший результат на данный момент! Настало время изучить нашу модель.
Компромисс между сложностью и объяснимостью
Поскольку наши векторные представления более не представлены в виде вектора с одним измерением на слово, как было в предыдущих моделях, теперь тяжелее понять, какие слова наиболее релевантны для нашей классификации. Несмотря на то, что мы по-прежнему обладаем доступом к коэффициентам нашей логистической регрессии, они относятся к 300 измерениям наших вложений, а не к индексам слов.
Для столь небольшого прироста точности, полная потеря возможности объяснить работу модели — это слишком жесткий компромисс. К счастью, при работе с более сложными моделями мы можем использовать интерпретаторы наподобие LIME, которые применяются для того, чтобы получить некоторое представление о том, как работает классификатор.
LIME доступен на Github в виде открытого пакета. Данный интерпретатор, работающий по принципу черного ящика, позволяет пользователям объяснять решения любого классификатора на одном конкретном примере при помощи изменения ввода (в нашем случае — удаления слова из предложения) и наблюдения за тем, как изменяется предсказание.
Давайте взглянем на пару объяснений для предложений из нашего датасета.
Правильные слова катастроф выбраны для классификации как «релевантные».
Здесь вклад слов в классификацию выглядит менее очевидным.
Впрочем, у нас нет достаточного количества времени, чтобы исследовать тысячи примеров из нашего датасета. Вместо этого, давайте запустим LIME на репрезентативной выборке тестовых данных, и посмотрим, какие слова встречаются регулярно и вносят наибольший вклад в конечный результат. Используя данный подход, мы можем получить оценки значимости слов аналогично тому, как мы делали это для предыдущих моделей, и валидировать предсказания нашей модели.
Похоже на то, что модель выбирает высоко релевантные слова и соответственно принимает понятные решения. По сравнению со всеми предыдущими моделями, она выбирает наиболее релевантные слова, поэтому лучше будет отправить в продакшн именно ее.
Шаг 8. Использование синтаксиса при применении end-to-end подходов
Мы рассмотрели быстрые и эффективные подходы для генерации компактных векторных представлений предложений. Однако, опуская порядок слов, мы отбрасываем всю синтаксическую информацию из наших предложений. Если эти методы не дают достаточных результатов, вы можете использовать более сложную модель, которая принимает целые выражения в качестве ввода и предсказывает метки, без необходимости построения промежуточного представления. Распространенный для этого способ состоит в рассмотрении предложения как последовательности индивидуальных векторов слов с использованием или Word2Vec, или более свежих подходов вроде GloVe или CoVe. Именно этим мы и займемся далее.
Высокоэффективная архитектура обучения модели без дополнительной предварительной и последующей обработки (end-to-end, источник)
Сверточные нейронные сети для классификации предложений (CNNs for Sentence Classification) обучаются очень быстро и могут сослужить отличную службу в качестве входного уровня в архитектуре глубокого обучения. Несмотря на то, что сверточные нейронные сети (CNN) в основном известны своей высокой производительностью на данных-изображениях, они показывают превосходные результаты при работе с текстовыми данными, и обычно гораздо быстрее обучаются, чем большинство сложных подходов NLP (например, LSTM-сети и архитектуры Encoder/Decoder ). Эта модель сохраняет порядок слов и обучается ценной информации о том, какие последовательности слов служат предсказанием наших целевых классов. В отличии от предыдущих моделей, она в курсе существования разницы между фразами «Лёша ест растения» и «Растения едят Лёшу».
Обучение данной модели не потребует сильно больше усилий по сравнению с предыдущими подходами (смотрите код), и, в итоге, мы получим модель, которая работает гораздо лучше предыдущей, позволяя получить точность в 79,5%. Как и с моделями, которые мы рассмотрели ранее, следующим шагом должно быть исследование и объяснение предсказаний с помощью методов, которые мы описали выше, чтобы убедиться в том, что модель является лучшим вариантом, который мы можем предложить пользователям. К этому моменту вы уже должны чувствовать себя достаточно уверенными, чтобы справиться с последующими шагами самостоятельно.
В заключение
Итак, краткое содержание подхода, который мы успешно применили на практике:
Как уже отмечалось в статье, кто угодно может извлечь пользу, применив методы машинного обучения, тем более в мире интернета, со всем разнообразием аналитических данных. Поэтому темы искусственного интеллекта и машинного обучения непременно обсуждаются на наших конференциях РИТ++ и Highload++, причем с совершенно практической точки зрения, как и в этой статье. Вот, например, видео нескольких прошлогодних выступлений:


